Flink 引擎
快速入門
本文檔是在Flink中使用Paimon的指南。
相關JAR包
Paimon目前支持Flink 1.20、1.19、1.18、1.17、1.16、1.15 。為獲得更好的體驗,我們推薦使用最新的Flink版本。
下載對應版本的JAR文件。
目前,Paimon提供兩種類型的JAR包:一種(捆綁JAR包)用于讀取/寫入數據,另一種(操作JAR包)用于手動壓縮等操作。
| 版本 | 類型 | JAR包 |
|---|---|---|
| Flink 1.20 | Bundled Jar | paimon-flink-1.20-0.9.0.jar |
| Flink 1.19 | Bundled Jar | paimon-flink-1.19-0.9.0.jar |
| Flink 1.18 | Bundled Jar | paimon-flink-1.18-0.9.0.jar |
| Flink 1.17 | Bundled Jar | paimon-flink-1.17-0.9.0.jar |
| Flink 1.16 | Bundled Jar | paimon-flink-1.16-0.9.0.jar |
| Flink 1.15 | Bundled Jar | paimon-flink-1.15-0.9.0.jar |
| Flink Action | Action Jar | paimon-flink-action-0.9.0.jar |
你也可以從源代碼手動構建捆綁JAR包。
要從源代碼構建,克隆git倉庫。
使用以下命令構建捆綁JAR包:
mvn clean install -DskipTests
你可以在./paimon-flink/paimon-flink-<flink-version>/target/paimon-flink-<flink-version>-0.9.0.jar找到捆綁JAR包,在./paimon-flink/paimon-flink-action/target/paimon-flink-action-0.9.0.jar找到操作JAR包。
開始使用
步驟1:下載Flink 如果你還沒有下載Flink,可以下載Flink,然后使用以下命令解壓歸檔文件:
tar -xzf flink-*.tgz
步驟2:復制Paimon捆綁JAR包 將Paimon捆綁JAR包復制到Flink安裝目錄的lib目錄中:
cp paimon-flink-*.jar /lib/
步驟3:復制Hadoop捆綁JAR包 如果機器處于Hadoop環境,請確保環境變量HADOOP_CLASSPATH的值包含常見Hadoop庫的路徑,這種情況下無需使用以下預捆綁的Hadoop JAR包。
下載預捆綁的Hadoop JAR包,并將其復制到Flink安裝目錄的lib目錄中:
cp flink-shaded-hadoop-2-uber-*.jar /lib/
步驟4:啟動Flink本地集群 為了同時運行多個Flink作業,你需要修改<FLINK_HOME>/conf/flink-conf.yaml中的集群配置:
taskmanager.numberOfTaskSlots: 2
要啟動本地集群,運行Flink自帶的bash腳本:
<FLINK_HOME>/bin/start-cluster.sh
你應該能夠通過localhost:8081訪問Web界面,查看Flink儀表板并確認集群已啟動并正在運行。
現在你可以啟動Flink SQL客戶端來執行SQL腳本:
<FLINK_HOME>/bin/sql-client.sh
步驟5:創建目錄和表
目錄
-- if you're trying out Paimon in a distributed environment,
-- the warehouse path should be set to a shared file system, such as HDFS or OSS
CREATE CATALOG my_catalog WITH ('type'='paimon','warehouse'='file:/tmp/paimon'
);USE CATALOG my_catalog;-- create a word count table
CREATE TABLE word_count (word STRING PRIMARY KEY NOT ENFORCED,cnt BIGINT
);步驟6:寫入數據
-- create a word data generator table
CREATE TEMPORARY TABLE word_table (word STRING
) WITH ('connector' = 'datagen','fields.word.length' = '1'
);-- paimon requires checkpoint interval in streaming mode
SET 'execution.checkpointing.interval' = '10 s';-- write streaming data to dynamic table
INSERT INTO word_count SELECT word, COUNT(*) FROM word_table GROUP BY word;步驟7:OLAP查詢
-- use tableau result mode
SET 'sql-client.execution.result-mode' = 'tableau';-- switch to batch mode
RESET 'execution.checkpointing.interval';
SET 'execution.runtime-mode' = 'batch';-- olap query the table
SELECT * FROM word_count;你可以多次執行查詢并觀察結果的變化。
步驟8:流查詢
-- switch to streaming mode
SET 'execution.runtime-mode' = 'streaming';-- track the changes of table and calculate the count interval statistics
SELECT `interval`, COUNT(*) AS interval_cnt FROM(SELECT cnt / 10000 AS `interval` FROM word_count) GROUP BY `interval`;步驟9:退出 在localhost:8081取消流作業,然后執行以下SQL腳本退出Flink SQL客戶端:
-- uncomment the following line if you want to drop the dynamic table and clear the files
-- DROP TABLE word_count;-- exit sql-client
EXIT;停止Flink本地集群:
./bin/stop-cluster.sh
使用Flink管理內存
Paimon任務可以基于執行器內存創建內存池,該內存池將由Flink執行器管理,例如Flink任務管理器中的管理內存。通過執行器為多個任務管理寫入器緩沖區,這將提高接收器的穩定性和性能。
如果使用Flink管理內存,可以設置以下屬性:
| 選項 | 默認值 | 描述 |
|---|---|---|
| sink.use-managed-memory-allocator | false | 如果為true,Flink接收器將為合并樹使用管理內存;否則,它將創建一個獨立的內存分配器,這意味著每個任務分配并管理自己的內存池(堆內存)。如果一個執行器中有太多任務,可能會導致性能問題甚至內存溢出(OOM)。 |
| sink.managed.writer-buffer-memory | 256M | 管理內存中寫入器緩沖區的權重,Flink將根據該權重計算寫入器的內存大小,實際使用的內存取決于運行環境。目前,此屬性中定義的內存大小等于運行時分配給寫入緩沖區的實際內存。 |
在SQL中使用時,用戶可以在SQL中為Flink管理內存設置內存權重,然后Flink接收器操作符將獲取內存池大小并為Paimon寫入器創建分配器:
INSERT INTO paimon_table /*+ OPTIONS('sink.use-managed-memory-allocator'='true', 'sink.managed.writer-buffer-memory'='256M') */
SELECT * FROM ....;設置動態選項
與Paimon表交互時,可以在不更改目錄選項的情況下調整表選項。Paimon將提取作業級動態選項,并在當前會話中生效。動態選項的鍵格式為paimon.${catalogName}.${dbName}.${tableName}.${config_key} 。catalogName/dbName/tableName可以是*,表示匹配所有特定部分。
例如:
-- set scan.timestamp-millis=1697018249000 for the table mycatalog.default.T
SET 'paimon.mycatalog.default.T.scan.timestamp-millis' = '1697018249000';
SELECT * FROM T;-- set scan.timestamp-millis=1697018249000 for the table default.T in any catalog
SET 'paimon.*.default.T.scan.timestamp-millis' = '1697018249000';
SELECT * FROM T;拓展:
分桶追加表:在大數據存儲和處理中,分桶追加表通過定義桶和桶鍵,將數據按照一定規則分布到不同桶中。這種方式不僅可以在流處理中保證同一桶內數據的順序,便于按序處理數據,還能在批處理查詢時優化性能,如避免數據混洗,提高查詢效率。例如,在電商數據分析中,按商品ID分桶存儲訂單數據,在分析特定商品的銷售趨勢時,同一桶內的數據按時間順序排列,方便快速獲取相關信息。
桶內壓縮策略:桶內壓縮策略通過控制文件數量來優化存儲和查詢性能。
write-only選項用于跳過壓縮和快照過期,適用于與專用壓縮作業配合使用的場景。compaction.min.file-num和compaction.max.file-num分別從最小和最大文件數的角度觸發壓縮,平衡了壓縮成本和性能。full-compaction.delta-commits則控制完全壓縮的觸發頻率。在實際應用中,合理調整這些參數能有效管理存儲資源,提高系統整體性能。流讀取順序:明確的流讀取順序保證了數據在不同分區和桶之間的處理順序,有助于確保數據處理結果的一致性。例如,在實時數據分析任務中,按順序處理數據對于正確計算指標和分析趨勢至關重要。不同的順序規則(如按分區值、創建時間或寫入順序)適用于不同的業務場景,用戶可以根據實際需求進行配置。
水印定義與應用:水印在流處理中用于處理亂序數據和定義窗口操作。通過為Paimon表定義水印,結合Flink水印對齊功能,可以更好地控制數據處理的進度和準確性。有界流模式下,水印還可以作為流讀取的結束條件,確保在處理完特定范圍的數據后停止讀取。例如,在實時監控系統中,通過水印機制可以準確計算一段時間內的事件統計信息,同時避免因亂序數據導致的計算錯誤。
批處理中的分桶優化:在Spark SQL中,為V2數據源啟用分桶功能后,當兩個表具有相同的分桶策略和桶數時,在連接操作中可以避免數據混洗。數據混洗通常是一個代價高昂的操作,涉及數據的重新分區和傳輸,而分桶優化可以顯著減少這種開銷,提高批處理查詢的性能。例如,在大規模數據的關聯分析中,通過合理的分桶策略,可以將需要連接的數據預先分布在相同的桶中,直接進行連接操作,節省大量時間和資源。
SQL數據定義語言(SQL DDL)
創建目錄(Create Catalog)
Paimon目錄目前支持三種類型的元存儲:
-
文件系統元存儲(默認),它在文件系統中同時存儲元數據和表文件。
-
Hive元存儲,它額外將元數據存儲在Hive元存儲中。用戶可以直接從Hive訪問這些表。
-
JDBC元存儲,它額外將元數據存儲在關系型數據庫中,如MySQL、Postgres等。 創建目錄時的詳細選項請參考CatalogOptions。
創建文件系統目錄(Create Filesystem Catalog)
以下Flink SQL注冊并使用一個名為my_catalog的Paimon目錄。元數據和表文件存儲在hdfs:///path/to/warehouse下。
CREATE CATALOG my_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs:///path/to/warehouse'
);USE CATALOG my_catalog;你可以使用前綴table-default.為在該目錄中創建的表定義任何默認表選項。
創建Hive目錄(Creating Hive Catalog)
通過使用Paimon Hive目錄,對該目錄的更改將直接影響相應的Hive元存儲。在此目錄中創建的表也可以直接從Hive訪問。
要使用Hive目錄,數據庫名、表名和字段名應為小寫。
Flink中的Paimon Hive目錄依賴于Flink Hive連接器捆綁JAR包。你應首先下載Hive連接器捆綁JAR包并將其添加到類路徑中。
| 元存儲版本 | 捆綁包名稱 | SQL客戶端JAR包 |
|---|---|---|
| 2.3.0 - 3.1.3 | Flink Bundle | Download |
| 1.2.0 - x.x.x | Presto Bundle | Download |
以下Flink SQL注冊并使用一個名為my_hive的Paimon Hive目錄。元數據和表文件存儲在hdfs:///path/to/warehouse下。此外,元數據也存儲在Hive元存儲中。
如果你的Hive需要安全認證,如Kerberos、LDAP、Ranger,或者你希望Paimon表由Apache Atlas管理(在hive-site.xml中設置‘hive.metastore.event.listeners’)。你可以將hive-conf-dir和hadoop-conf-dir參數指定為hive-site.xml文件路徑。
CREATE CATALOG my_hive WITH ('type' = 'paimon','metastore' = 'hive',-- 'uri' = 'thrift://<hive-metastore-host-name>:<port>', default use 'hive.metastore.uris' in HiveConf-- 'hive-conf-dir' = '...', this is recommended in the kerberos environment-- 'hadoop-conf-dir' = '...', this is recommended in the kerberos environment-- 'warehouse' = 'hdfs:///path/to/warehouse', default use 'hive.metastore.warehouse.dir' in HiveConf
);USE CATALOG my_hive;你可以使用前綴table-default.為在該目錄中創建的表定義任何默認表選項。
此外,你可以創建FlinkGenericCatalog。
當使用Hive目錄通過alter table更改不兼容的列類型時,你需要配置hive.metastore.disallow.incompatible.col.type.changes=false。詳見HIVE-17832。
如果你正在使用Hive3,請禁用Hive ACID:
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false將分區同步到Hive元存儲(Synchronizing Partitions into Hive Metastore)
默認情況下,Paimon不會將新創建的分區同步到Hive元存儲。用戶在Hive中看到的將是一個未分區的表。分區下推將通過過濾器下推來實現。
如果你希望在Hive中看到一個分區表,并且也將新創建的分區同步到Hive元存儲,請將表屬性metastore.partitioned-table設置為true。另見CoreOptions。
向Hive表添加參數(Adding Parameters to a Hive Table)
使用表選項有助于方便地定義Hive表參數。以hive.為前綴的參數將自動在Hive表的TBLPROPERTIES中定義。例如,使用選項hive.table.owner = Jon將在創建過程中自動向表屬性中添加參數table.owner = Jon。
在屬性中設置位置(Setting Location in Properties)
如果你正在使用對象存儲,并且不希望Paimon表/數據庫的位置通過Hive的文件系統訪問,這可能會導致諸如 “No FileSystem for scheme: s3a” 之類的錯誤。你可以通過location-in-properties配置在表/數據庫的屬性中設置位置。詳見在屬性中設置表/數據庫的位置。
創建JDBC目錄(Creating JDBC Catalog)
通過使用Paimon JDBC目錄,對該目錄的更改將直接存儲在關系型數據庫中,如SQLite、MySQL、postgres等。
目前,鎖配置僅支持MySQL和SQLite。如果你使用不同類型的數據庫進行目錄存儲,請不要配置lock.enabled。
Flink中的Paimon JDBC目錄需要正確添加連接數據庫的相應JAR包。你應首先下載JDBC連接器捆綁JAR包并將其添加到類路徑中,例如MySQL、postgres。
| 數據庫類型 | 捆綁包名稱 | SQL客戶端JAR包 |
|---|---|---|
| mysql | mysql-connector-java | Download |
| postgres | postgresql | Download |
CREATE CATALOG my_jdbc WITH ('type' = 'paimon','metastore' = 'jdbc','uri' = 'jdbc:mysql://<host>:<port>/<databaseName>','jdbc.user' = '...', 'jdbc.password' = '...', 'catalog-key'='jdbc','warehouse' = 'hdfs:///path/to/warehouse'
);USE CATALOG my_jdbc;你可以通過“jdbc.”配置任何已由JDBC聲明的連接參數,不同數據庫之間的連接參數可能不同,請根據實際情況進行配置。
你還可以通過指定“catalog-key”對多個目錄下的數據庫進行邏輯隔離。
此外,在創建JdbcCatalog時,你可以通過配置“lock-key-max-length”指定鎖鍵的最大長度,默認值為255。由于此值是{catalog-key}.{database-name}.{table-name}的組合,請相應調整。
你可以使用前綴table-default.為在該目錄中創建的表定義任何默認表選項。
創建表(Create Table)
使用Paimon目錄后,你可以創建和刪除表。在Paimon目錄中創建的表由該目錄管理。當從目錄中刪除表時,其表文件也將被刪除。
以下SQL假設你已注冊并正在使用Paimon目錄。它在目錄的默認數據庫中創建一個名為my_table的管理表,該表有五列,其中dt、hh和user_id是主鍵。
CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);你可以創建分區表:
CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);如果你需要跨分區插入更新(主鍵不包含所有分區字段),請參見跨分區插入更新模式。
通過配置partition.expiration-time,可以自動刪除過期分區。
指定統計模式(Specify Statistics Mode)
Paimon將自動收集數據文件的統計信息以加速查詢過程。支持四種模式:
-
full:收集完整的指標:null_count(空值計數)、min(最小值)、max(最大值)。
-
truncate(length):length可以是任意正整數,默認模式是truncate(16),這意味著收集空值計數、截斷長度為16的最小/最大值。這主要是為了避免過大的列,以免增大清單文件。
-
counts:僅收集空值計數。
-
none:禁用元數據統計信息收集。 統計信息收集器模式可以通過'metadata.stats-mode'配置,默認是'truncate(16)'。你可以通過設置'fields.{field_name}.stats-mode'來配置字段級別。
字段默認值(Field Default Value)
Paimon表目前支持通過'fields.item_id.default-value'在表屬性中為字段設置默認值,請注意,分區字段和主鍵字段不能指定默認值。
Create Table As Select
可以根據查詢結果創建并填充表,例如,我們有這樣一個SQL:CREATE TABLE table_b AS SELECT id, name FORM table_a,結果表table_b將等同于使用以下語句創建表并插入數據:CREATE TABLE table_b (id INT, name STRING); INSERT INTO table_b SELECT id, name FROM table_a;
當使用CREATE TABLE AS SELECT時,我們可以指定主鍵或分區,語法請參考以下SQL。
/* For streaming mode, you need to enable the checkpoint. */CREATE TABLE my_table (user_id BIGINT,item_id BIGINT
);
CREATE TABLE my_table_as AS SELECT * FROM my_table;/* partitioned table */
CREATE TABLE my_table_partition (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING
) PARTITIONED BY (dt, hh);
CREATE TABLE my_table_partition_as WITH ('partition' = 'dt') AS SELECT * FROM my_table_partition;/* change options */
CREATE TABLE my_table_options (user_id BIGINT,item_id BIGINT
) WITH ('file.format' = 'orc');
CREATE TABLE my_table_options_as WITH ('file.format' = 'parquet') AS SELECT * FROM my_table_options;/* primary key */
CREATE TABLE my_table_pk (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);
CREATE TABLE my_table_pk_as WITH ('primary-key' = 'dt,hh') AS SELECT * FROM my_table_pk;/* primary key + partition */
CREATE TABLE my_table_all (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);
CREATE TABLE my_table_all_as WITH ('primary-key' = 'dt,hh', 'partition' = 'dt') AS SELECT * FROM my_table_all;Create Table Like
要創建一個與另一個表具有相同模式、分區和表屬性的表,可以使用CREATE TABLE LIKE。
CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);CREATE TABLE my_table_like LIKE my_table (EXCLUDING OPTIONS);Work with Flink Temporary Tables
Flink臨時表僅在當前Flink SQL會話中記錄而不受其管理。如果刪除臨時表,其資源不會被刪除。Flink SQL會話關閉時,臨時表也會被刪除。
如果你想在使用Paimon目錄的同時使用其他表,但又不想將它們存儲在其他目錄中,可以創建一個臨時表。以下Flink SQL創建一個Paimon目錄和一個臨時表,并展示了如何同時使用這兩個表。
CREATE CATALOG my_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs:///path/to/warehouse'
);USE CATALOG my_catalog;-- Assume that there is already a table named my_table in my_catalogCREATE TEMPORARY TABLE temp_table (k INT,v STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs:///path/to/temp_table.csv','format' = 'csv'
);SELECT my_table.k, my_table.v, temp_table.v FROM my_table JOIN temp_table ON my_table.k = temp_table.k;拓展:
Paimon目錄類型:Paimon提供多種目錄類型,每種都有其特點和適用場景。文件系統元存儲簡單直接,適用于基礎的文件系統存儲場景;Hive元存儲方便與Hive集成,便于在Hive生態中共享數據;JDBC元存儲則將元數據存儲在關系型數據庫,可利用數據庫的一些特性,如事務支持等。不同類型目錄的選擇取決于項目的數據管理需求和現有技術棧。
Hive目錄細節:使用Hive目錄時,與Hive的集成需要注意諸多細節。例如,名稱大小寫規范、依賴的JAR包下載及添加、安全認證配置等。同時,在處理Hive相關配置時,如更改列類型的配置以及禁用Hive ACID的設置,都是為了確保Paimon與Hive之間的兼容性和數據處理的正確性。
JDBC目錄配置:JDBC目錄的配置涉及數據庫連接相關的眾多參數,如數據庫URI、用戶名、密碼等,不同數據庫類型還需下載相應的JDBC連接器捆綁JAR包。鎖配置的支持情況以及鎖鍵最大長度的設置,為數據的并發訪問和管理提供了控制手段。通過“catalog-key”進行邏輯隔離,則增加了多目錄多數據庫管理的靈活性。
表的創建與操作:Paimon表的創建方式多樣,包括基本創建、按查詢結果創建、像其他表一樣創建等。每種方式都提供了豐富的可配置選項,如主鍵、分區、統計模式、字段默認值等。這些選項的設置不僅影響表的結構,還對數據存儲、查詢性能等方面產生重要作用。例如,合理選擇統計模式可以在保證查詢性能的同時,控制元數據的存儲開銷。
臨時表的使用:Flink臨時表為用戶在特定SQL會話中提供了一種臨時存儲和處理數據的方式,它與Paimon目錄結合使用,使得用戶可以在不改變Paimon目錄結構的前提下,靈活地與其他外部數據源進行聯合查詢,增強了數據處理的靈活性和便捷性。
SQL寫入(SQL Write)
語法(Syntax)
INSERT { INTO | OVERWRITE } table_identifier [ part_spec ] [ column_list ] { value_expr | query };
更多信息,請查看語法文檔:Flink INSERT語句
INSERT INTO
使用INSERT INTO將記錄和更改應用到表中。
INSERT INTO my_table SELECT ...
INSERT INTO同時支持批處理模式和流處理模式。在流處理模式下,默認情況下,它還會在Flink Sink中執行壓縮、快照過期,甚至分區過期操作(如果已配置)。
對于多個作業寫入同一個表的情況,你可以參考專用壓縮作業獲取更多信息。
聚類(Clustering)
在Paimon中,聚類是一項功能,它允許你在寫入過程中根據某些列的值對追加表中的數據進行聚類。這種數據組織方式可以顯著提高下游任務讀取數據時的效率,因為它能夠實現更快且更有針對性的數據檢索。此功能僅支持追加表(bucket = -1)和批處理執行模式。
要使用聚類功能,你可以在創建表或寫入表時指定要聚類的列。以下是啟用聚類的簡單示例:
CREATE TABLE my_table (a STRING,b STRING,c STRING,
) WITH ('sink.clustering.by-columns' = 'a,b',
);你也可以使用SQL提示動態設置聚類選項:
INSERT INTO my_table /*+ OPTIONS('sink.clustering.by-columns' = 'a,b') */
SELECT * FROM source;數據使用自動選擇的策略(如ORDER、ZORDER或HILBERT)進行聚類,但你可以通過設置sink.clustering.strategy手動指定聚類策略。聚類依賴于采樣和排序。如果聚類過程耗時過長,你可以通過設置sink.clustering.sample-factor減少總采樣數,或者通過設置sink.clustering.sort-in-cluster為false禁用排序步驟。
有關上述配置的更多信息,你可以參考FlinkConnectorOptions。
覆蓋整個表(Overwriting the Whole Table)
對于未分區表,Paimon支持覆蓋整個表。(或者對于禁用了dynamic-partition-overwrite選項的分區表)。
使用INSERT OVERWRITE覆蓋整個未分區表。
INSERT OVERWRITE my_table SELECT ...
覆蓋一個分區(Overwriting a Partition)
對于分區表,Paimon支持覆蓋一個分區。
使用INSERT OVERWRITE覆蓋一個分區。
INSERT OVERWRITE my_table PARTITION (key1 = value1, key2 = value2, ...) SELECT ...
動態覆蓋(Dynamic Overwrite)
Flink的默認覆蓋模式是動態分區覆蓋(這意味著Paimon僅刪除被覆蓋數據中出現的分區)。你可以配置dynamic-partition-overwrite將其更改為靜態覆蓋。
-- MyTable is a Partitioned Table-- Dynamic overwrite
INSERT OVERWRITE my_table SELECT ...-- Static overwrite (Overwrite whole table)
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite' = 'false') */ SELECT ...截斷表(Truncate tables)
-
Flink 1.17及以下: 你可以使用
INSERT OVERWRITE通過插入空值來清空表數據。
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */ SELECT * FROM my_table WHERE false;
-
Flink 1.18及以上:
TRUNCATE TABLE my_table;
清除分區(Purging Partitions)
目前,Paimon支持兩種清除分區的方法。
- 與清除表類似,你可以使用
INSERT OVERWRITE通過向分區插入空值來清除分區數據。 - 方法1不支持刪除多個分區。如果你需要刪除多個分區,可以通過
flink run提交drop_partition作業。
-- Syntax
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */
PARTITION (key1 = value1, key2 = value2, ...) SELECT selectSpec FROM my_table WHERE false;-- The following SQL is an example:
-- table definition
CREATE TABLE my_table (k0 INT,k1 INT,v STRING
) PARTITIONED BY (k0, k1);-- you can use
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */
PARTITION (k0 = 0) SELECT k1, v FROM my_table WHERE false;-- or
INSERT OVERWRITE my_table /*+ OPTIONS('dynamic-partition-overwrite'='false') */
PARTITION (k0 = 0, k1 = 0) SELECT v FROM my_table WHERE false;更新表(Updating tables)
重要的表屬性設置:
-
僅主鍵表支持此功能。
-
MergeEngine需要是deduplicate或partial-update才能支持此功能。 -
不支持更新主鍵。
目前,Paimon在Flink 1.17及更高版本中支持使用UPDATE更新記錄。你可以在Flink的批處理模式下執行UPDATE。
-- Syntax
UPDATE table_identifier SET column1 = value1, column2 = value2, ... WHERE condition;-- The following SQL is an example:
-- table definition
CREATE TABLE my_table (a STRING,b INT,c INT,PRIMARY KEY (a) NOT ENFORCED
) WITH ( 'merge-engine' = 'deduplicate'
);-- you can use
UPDATE my_table SET b = 1, c = 2 WHERE a = 'myTable';從表中刪除(Deleting from table)
-
Flink 1.17及以上: 重要的表屬性設置:
-
僅主鍵表支持此功能。
-
如果表有主鍵,
MergeEngine需要是deduplicate才能支持此功能。 -
不支持在流處理模式下從表中刪除數據。
-- Syntax
DELETE FROM table_identifier WHERE conditions;-- The following SQL is an example:
-- table definition
CREATE TABLE my_table (id BIGINT NOT NULL,currency STRING,rate BIGINT,dt String,PRIMARY KEY (id, dt) NOT ENFORCED
) PARTITIONED BY (dt) WITH ( 'merge-engine' = 'deduplicate'
);-- you can use
DELETE FROM my_table WHERE currency = 'UNKNOWN';分區標記完成(Partition Mark Done)
對于分區表,每個分區可能需要被調度以觸發下游批處理計算。因此,有必要選擇合適的時機表明該分區已準備好調度,并盡量減少調度期間的數據漂移量。我們將這個過程稱為:“分區標記完成”。
標記完成的示例:
CREATE TABLE my_partitioned_table (f0 INT,f1 INT,f2 INT,...dt STRING
) PARTITIONED BY (dt) WITH ('partition.timestamp-formatter'='yyyyMMdd','partition.timestamp-pattern'='$dt','partition.time-interval'='1 d','partition.idle-time-to-done'='15 m'
);- 首先,你需要定義分區的時間解析器和分區之間的時間間隔,以便確定何時可以正確標記分區完成。
- 其次,你需要定義空閑時間,它決定了分區在沒有新數據的情況下經過多長時間后將被標記為完成。
- 第三,默認情況下,分區標記完成會創建
_SUCCESS文件,_SUCCESS文件的內容是一個JSON,包含creationTime和modificationTime,它們可以幫助你了解是否有延遲數據。你也可以配置其他操作。
拓展:
SQL寫入操作:在數據處理中,SQL寫入操作是將數據持久化到表中的關鍵步驟。Paimon提供了豐富的寫入方式,如
INSERT INTO用于常規寫入,INSERT OVERWRITE用于覆蓋寫入,這些操作在批處理和流處理模式下的行為和適用場景不同,用戶可根據需求靈活選擇。聚類功能:聚類是Paimon針對追加表在批處理模式下的優化功能。通過對特定列進行聚類,數據在存儲時會按照指定策略組織,這在大數據場景下能顯著提升查詢性能,減少數據檢索時間。例如在一個包含大量用戶行為數據的追加表中,按照用戶ID和時間列進行聚類,可以快速定位和分析特定用戶在某個時間段內的行為。
覆蓋與清除操作:覆蓋整個表、分區以及動態/靜態覆蓋模式,為數據更新和管理提供了多種選擇。而截斷表和清除分區功能則用于刪除數據,不同版本的Flink在實現方式上略有差異,用戶需根據實際情況選擇合適的方法。這些操作對于數據的清理和維護十分重要,比如在數據過期或錯誤數據處理場景中。
更新與刪除操作:更新和刪除操作針對主鍵表,且對
MergeEngine有特定要求。這確保了數據的一致性和完整性,因為主鍵表中的數據更新和刪除需要更嚴格的控制。例如在用戶信息表中,當用戶信息發生變化時,可以使用更新操作修改相應記錄;當用戶注銷時,可以使用刪除操作移除相關記錄。分區標記完成:在分區表的場景下,分區標記完成機制用于協調下游批處理計算的調度。通過合理設置時間解析器、時間間隔和空閑時間等參數,可以確保分區在合適的時機被標記為完成,減少數據漂移,保證批處理計算的準確性和高效性。比如在按天分區的銷售數據分區表中,通過設置這些參數,可以確保每天的數據在處理完成且無延遲數據后,被正確標記為完成,以便下游進行準確的統計分析。
SQL查詢(SQL Query)
與所有其他表一樣,Paimon表可以使用SELECT語句進行查詢。
批處理查詢(Batch Query)
Paimon的批處理讀取會返回表某個快照中的所有數據。默認情況下,批處理讀取返回最新的快照。
-- Flink SQL
SET 'execution.runtime-mode' = 'batch';批處理時間旅行(Batch Time Travel)
Paimon的批處理時間旅行讀取可以指定一個快照或標簽,并讀取相應的數據。
- Flink(動態選項):
-- read the snapshot with id 1L
SELECT * FROM t /*+ OPTIONS('scan.snapshot-id' = '1') */;-- read the snapshot from specified timestamp in unix milliseconds
SELECT * FROM t /*+ OPTIONS('scan.timestamp-millis' = '1678883047356') */;-- read the snapshot from specified timestamp string ,it will be automatically converted to timestamp in unix milliseconds
-- Supported formats include:yyyy-MM-dd, yyyy-MM-dd HH:mm:ss, yyyy-MM-dd HH:mm:ss.SSS, use default local time zone
SELECT * FROM t /*+ OPTIONS('scan.timestamp' = '2023-12-09 23:09:12') */;-- read tag 'my-tag'
SELECT * FROM t /*+ OPTIONS('scan.tag-name' = 'my-tag') */;-- read the snapshot from watermark, will match the first snapshot after the watermark
SELECT * FROM t /*+ OPTIONS('scan.watermark' = '1678883047356') */; - Flink 1.18及以上:
-- read the snapshot from specified timestamp
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00';-- you can also use some simple expressions (see flink document to get supported functions)
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00' + INTERVAL '1' DAY批處理增量讀取(Batch Incremental)
讀取起始快照(不包含)和結束快照之間的增量更改。
例如:
‘5,10’表示快照5和快照10之間的更改。‘TAG1,TAG3’表示TAG1和TAG3之間的更改。
-- incremental between snapshot ids
SELECT * FROM t /*+ OPTIONS('incremental-between' = '12,20') */;-- incremental between snapshot time mills
SELECT * FROM t /*+ OPTIONS('incremental-between-timestamp' = '1692169000000,1692169900000') */;默認情況下,對于生成變更日志文件的表,將掃描變更日志文件。否則,掃描新更改的文件。你也可以強制指定'incremental-between-scan-mode'。
在批處理SQL中,不允許返回DELETE記錄,因此帶有 -D的記錄將被丟棄。如果你想查看DELETE記錄,可以使用audit_log表:
SELECT * FROM t$audit_log /*+ OPTIONS('incremental-between' = '12,20') */;
流處理查詢(Streaming Query)
默認情況下,流處理讀取在首次啟動時生成表上的最新快照,然后繼續讀取最新的更改。
Paimon默認確保你的啟動過程能夠正確處理所有數據。
流處理模式下的Paimon源是無界的,就像一個永遠不會結束的隊列。
-- Flink SQL
SET 'execution.runtime-mode' = 'streaming';你也可以不讀取快照數據進行流處理讀取,你可以使用最新掃描模式:
-- Continuously reads latest changes without producing a snapshot at the beginning.
SELECT * FROM t /*+ OPTIONS('scan.mode' = 'latest') */;流處理時間旅行(Streaming Time Travel)
如果你只想處理從今天開始及以后的數據,你可以使用分區過濾器來實現:
SELECT * FROM t WHERE dt > '2023-06-26';
如果它不是一個分區表,或者你不能通過分區進行過濾,你可以使用時間旅行的流讀取。
- Flink(動態選項):
-- read changes from snapshot id 1L
SELECT * FROM t /*+ OPTIONS('scan.snapshot-id' = '1') */;-- read changes from snapshot specified timestamp
SELECT * FROM t /*+ OPTIONS('scan.timestamp-millis' = '1678883047356') */;-- read snapshot id 1L upon first startup, and continue to read the changes
SELECT * FROM t /*+ OPTIONS('scan.mode'='from-snapshot-full','scan.snapshot-id' = '1') */;-
Flink 1.18及以上:
-- read the snapshot from specified timestamp
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00';-- you can also use some simple expressions (see flink document to get supported functions)
SELECT * FROM t FOR SYSTEM_TIME AS OF TIMESTAMP '2023-01-01 00:00:00' + INTERVAL '1' DAY時間旅行的流讀取依賴于快照,但默認情況下,快照僅保留1小時內的數據,這可能會阻止你讀取更舊的增量數據。因此,Paimon還為流讀取提供了另一種模式scan.file-creation-time-millis,它提供一種粗略的過濾方式,保留在timeMillis之后生成的文件。
SELECT * FROM t /*+ OPTIONS('scan.file-creation-time-millis' = '1678883047356') */;
消費者ID(Consumer ID)
你可以在對流讀取表時指定consumer-id:
SELECT * FROM t /*+ OPTIONS('consumer-id' = 'myid', 'consumer.expiration-time' = '1 d', 'consumer.mode' = 'at-least-once') */;
對流讀取Paimon表時,下一個快照ID會記錄到文件系統中。這有幾個優點:
- 當先前的作業停止時,新啟動的作業可以從先前的進度繼續消費,而無需從狀態恢復。新的讀取將從消費者文件中找到的下一個快照ID開始讀取。如果你不想要這種行為,可以將
'consumer.ignore-progress'設置為true。 - 在決定某個快照是否過期時,Paimon會查看文件系統中該表的所有消費者,如果有消費者仍然依賴這個快照,那么這個快照將不會因過期而被刪除。
注意1:消費者會阻止快照過期。你可以指定'consumer.expiration-time'來管理消費者的生命周期。
注意2:如果你不想影響檢查點時間,你需要配置'consumer.mode' = 'at-least-once'。這種模式允許讀取器以不同的速率消費快照,并將所有讀取器中最慢的快照ID記錄到消費者中。這種模式可以提供更多功能,如水印對齊。
注意3:關于'consumer.mode',由于exactly-once模式和at-least-once模式的實現完全不同,Flink的狀態是不兼容的,并且在切換模式時無法從狀態恢復。
你可以使用給定的消費者ID和下一個快照ID重置一個消費者,并使用給定的消費者ID刪除一個消費者。首先,你需要停止使用這個消費者ID的流處理任務,然后執行重置消費者動作作業。
運行以下命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \reset-consumer \--warehouse <warehouse-path> \--database <database-name> \ --table <table-name> \--consumer_id <consumer-id> \[--next_snapshot <next-snapshot-id>] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]如果你想刪除消費者,請不要指定 -next_snapshot參數。
讀取覆蓋(Read Overwrite)
默認情況下,流處理讀取將忽略由INSERT OVERWRITE生成的提交。如果你想讀取OVERWRITE的提交,可以配置streaming-read-overwrite。
讀取并行度(Read Parallelism)
默認情況下,批處理讀取的并行度與分片數相同,而流處理讀取的并行度與桶數相同,但不大于scan.infer-parallelism.max。
禁用scan.infer-parallelism后,將使用全局并行度進行讀取。
你也可以通過scan.parallelism手動指定并行度。
| 鍵 | 默認值 | 類型 | 描述 |
|---|---|---|---|
| scan.infer-parallelism | true | 布爾值 | 如果為false,源的并行度由全局并行度設置。否則,源并行度從分片數(批處理模式)或桶數(流處理模式)推斷得出。 |
| scan.infer-parallelism.max | 1024 | 整數 | 如果 |
| scan.parallelism | (none) | 整數 | 為掃描源定義自定義并行度。默認情況下,如果未定義此選項,規劃器將通過考慮全局配置為每個語句單獨推導并行度。如果用戶啟用 |
查詢優化(Query Optimization)
強烈建議在查詢時指定分區和主鍵過濾器,這將加速查詢的數據跳過。
能夠加速數據跳過的過濾函數有:
-
= -
< -
<= -
> -
>= -
IN (...) -
LIKE 'abc%' -
IS NULL
Paimon將按主鍵對數據進行排序,這會加速點查詢和范圍查詢。當使用復合主鍵時,最好讓查詢過濾器形成主鍵的最左前綴,以實現良好的加速效果。
假設一個表有以下定義:
CREATE TABLE orders (catalog_id BIGINT,order_id BIGINT,.....,PRIMARY KEY (catalog_id, order_id) NOT ENFORCED -- composite primary key
);通過為主鍵的最左前綴指定范圍過濾器,查詢可以獲得良好的加速效果。
SELECT * FROM orders WHERE catalog_id=1025;SELECT * FROM orders WHERE catalog_id=1025 AND order_id=29495;SELECT * FROM ordersWHERE catalog_id=1025AND order_id>2035 AND order_id<6000;然而,以下過濾器不能很好地加速查詢。
SELECT * FROM orders WHERE order_id=29495;SELECT * FROM orders WHERE catalog_id=1025 OR order_id=29495;拓展:
Paimon的SQL查詢功能:Paimon在SQL查詢方面提供了豐富的特性,涵蓋批處理和流處理兩種模式。批處理查詢能獲取表快照的全部數據,并通過時間旅行功能指定特定快照或標簽進行查詢,還能實現增量讀取,這對于分析數據變化和版本回溯非常有用。流處理查詢則可以實時獲取最新數據,通過不同的掃描模式和時間旅行選項,滿足對實時數據處理的多樣化需求。
消費者ID機制:消費者ID機制為流處理讀取提供了斷點續傳和快照管理的功能。它允許作業在停止后從上次的進度繼續讀取,同時通過消費者對快照的依賴關系來控制快照的過期,有效避免了數據丟失。不同的消費者模式(如
at-least-once和exactly-once)在實現和功能上有所差異,用戶需根據實際需求選擇合適的模式。讀取覆蓋與并行度:讀取覆蓋配置決定了流處理讀取是否包含
INSERT OVERWRITE的提交,這在數據一致性要求較高的場景中很關鍵。而讀取并行度的設置則直接影響查詢性能,通過不同的參數配置,用戶可以根據系統資源和數據規模靈活調整批處理和流處理讀取的并行度,以達到最優的查詢效率。查詢優化策略:通過合理使用分區和主鍵過濾器,利用Paimon按主鍵排序的特性,可以顯著提升查詢性能。特別是在處理復合主鍵時,遵循最左前綴原則能更有效地加速查詢。了解哪些過濾函數能實現數據跳過,有助于用戶編寫高效的查詢語句,減少數據掃描范圍,提高大數據量下的查詢響應速度。
SQL查找連接(SQL Lookup Joins)
查找連接是流查詢中的一種連接類型。它用于使用從Paimon查詢到的數據豐富一個表。這種連接要求一個表具有處理時間屬性,另一個表由查找源連接器支持。
Paimon在Flink中支持對主鍵表和追加表進行查找連接。以下示例說明了此功能。
準備(Prepare)
首先,我們創建一個Paimon表并實時更新它。
-- Create a paimon catalog
CREATE CATALOG my_catalog WITH ('type'='paimon','warehouse'='hdfs://nn:8020/warehouse/path' -- or 'file://tmp/foo/bar'
);USE CATALOG my_catalog;-- Create a table in paimon catalog
CREATE TABLE customers (id INT PRIMARY KEY NOT ENFORCED,name STRING,country STRING,zip STRING
);-- Launch a streaming job to update customers table
INSERT INTO customers ...-- Create a temporary left table, like from kafka
CREATE TEMPORARY TABLE orders (order_id INT,total INT,customer_id INT,proc_time AS PROCTIME()
) WITH ('connector' = 'kafka','topic' = '...','properties.bootstrap.servers' = '...','format' = 'csv'...
);普通查找(Normal Lookup)
現在你可以在查找連接查詢中使用customers表。
-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;重試查找(Retry Lookup)
如果由于customers(查找表)的相應數據尚未準備好,導致orders(主表)的記錄連接失敗。你可以考慮使用Flink的查找延遲重試策略。僅適用于Flink 1.16及以上版本。
-- enrich each order with customer information
SELECT /*+ LOOKUP('table'='c', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='1s', 'max-attempts'='600') */
o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;異步重試查找(Async Retry Lookup)
同步重試的問題在于一條記錄會阻塞后續記錄,導致整個作業被阻塞。你可以考慮使用異步 + allow_unordered來避免阻塞,連接失敗的記錄將不再阻塞其他記錄。
-- enrich each order with customer information
SELECT /*+ LOOKUP('table'='c', 'retry-predicate'='lookup_miss', 'output-mode'='allow_unordered', 'retry-strategy'='fixed_delay', 'fixed-delay'='1s', 'max-attempts'='600') */
o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers /*+ OPTIONS('lookup.async'='true', 'lookup.async-thread-number'='16') */
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;如果主表(orders)是CDC流,Flink SQL將忽略allow_unordered(僅支持追加流),你的流作業可能會被阻塞。你可以嘗試使用Paimon的audit_log系統表功能來解決(將CDC流轉換為追加流)。
動態分區(Dynamic Partition)
在傳統數據倉庫中,每個分區通常維護最新的完整數據,因此這個分區表只需要連接最新的分區。Paimon針對這種場景專門開發了max_pt特性。
-
創建Paimon分區表:
CREATE TABLE customers (id INT,name STRING,country STRING,zip STRING,dt STRING,PRIMARY KEY (id, dt) NOT ENFORCED
) PARTITIONED BY (dt);-
查找連接:
SELECT o.order_id, o.total, c.country, c.zip
FROM orders AS o
JOIN customers /*+ OPTIONS('lookup.dynamic-partition'='max_pt()', 'lookup.dynamic-partition.refresh-interval'='1 h') */
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;查找節點將自動刷新最新的分區并查詢最新分區的數據。
查詢服務(Query Service)
你可以運行一個Flink流作業來啟動表的查詢服務。當查詢服務存在時,Flink查找連接將優先從它獲取數據,這將有效地提高查詢性能。
Flink SQL
CALL sys.query_service('database_name.table_name', parallelism);
Flink Action
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \query_service \--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--parallelism <parallelism>] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]拓展:
查找連接在流處理中的應用:查找連接在流處理場景中非常實用,它允許在實時流數據處理過程中,通過從另一個表(如Paimon表)中查詢相關數據來豐富主表數據。例如,在一個電商訂單處理系統中,訂單流數據(orders表)可以通過查找連接從客戶信息表(customers表)中獲取客戶的詳細信息,從而實現對訂單數據的補充和增強,為后續的分析和處理提供更完整的數據。
不同查找連接策略:普通查找連接按照常規方式使用處理時間屬性進行連接操作。重試查找策略則針對查找表數據可能延遲到達的情況,通過設置重試條件(如
retry-predicate)、重試策略(如retry-strategy)、重試延遲(如fixed-delay)和最大重試次數(如max-attempts)等參數,確保在數據準備好后能夠成功連接。異步重試查找進一步優化了同步重試可能導致的阻塞問題,通過異步處理和allow_unordered設置,避免了單個連接失敗記錄對整個作業的阻塞,提高了流處理的效率和響應性。動態分區的優化:在處理分區表時,動態分區的
max_pt特性能夠自動識別并連接最新分區,這對于需要獲取最新數據的場景非常有用。例如,在每日更新的銷售數據分區表中,通過動態分區查找連接,可以確保每次查詢都能獲取到最新一天的銷售數據,無需手動指定分區,簡化了查詢邏輯并提高了數據的實時性。查詢服務的作用:啟動查詢服務為Flink查找連接提供了一種優化機制。通過優先從查詢服務獲取數據,可以減少查詢延遲,提高查詢性能。特別是在大規模數據和高并發查詢的場景下,查詢服務可以緩存和預處理數據,使得查找連接能夠更快速地獲取所需信息,從而提升整個流處理系統的效率和響應能力。
SQL修改表結構(Altering Tables)
修改/添加表屬性(Changing/Adding Table Properties)
以下SQL將write-buffer-size表屬性設置為256MB。
ALTER TABLE my_table SET ('write-buffer-size' = '256 MB'
);刪除表屬性(Removing Table Properties)
以下SQL刪除write-buffer-size表屬性。
ALTER TABLE my_table RESET ('write-buffer-size');
修改/添加表注釋(Changing/Adding Table Comment)
以下SQL將表my_table的注釋修改為“table comment”。
ALTER TABLE my_table SET ('comment' = 'table comment');刪除表注釋(Removing Table Comment)
以下SQL刪除表注釋。
ALTER TABLE my_table RESET ('comment');
重命名表名(Rename Table Name)
以下SQL將表名重命名為my_table_new。
ALTER TABLE my_table RENAME TO my_table_new;
如果你使用對象存儲,如S3或OSS,請謹慎使用此語法,因為對象存儲的重命名操作不是原子性的,操作失敗時可能僅部分文件被移動。
添加新列(Adding New Columns)
以下SQL向表my_table添加兩列c1和c2。
ALTER TABLE my_table ADD (c1 INT, c2 STRING);
重命名列名(Renaming Column Name)
以下SQL將表my_table中的列c0重命名為c1。
ALTER TABLE my_table RENAME c0 TO c1;
刪除列(Dropping Columns)
以下SQL從表my_table中刪除兩列c1和c2。在Hive目錄中,你需要確保在Hive服務器中禁用hive.metastore.disallow.incompatible.col.type.changes,否則此操作可能失敗,并拋出類似“以下列的類型與各自位置上的現有列不兼容”的異常。
ALTER TABLE my_table DROP (c1, c2);
刪除分區(Dropping Partitions)
以下SQL刪除Paimon表的分區。
對于Flink SQL,你可以指定分區列的部分列,也可以同時指定多個分區值。
ALTER TABLE my_table DROP PARTITION (`id` = 1);ALTER TABLE my_table DROP PARTITION (`id` = 1, `name` = 'paimon');ALTER TABLE my_table DROP PARTITION (`id` = 1), PARTITION (`id` = 2);修改列的可空性(Changing Column Nullability)
以下SQL修改列coupon_info的可空性。
CREATE TABLE my_table (id INT PRIMARY KEY NOT ENFORCED, coupon_info FLOAT NOT NULL);-- Change column `coupon_info` from NOT NULL to nullable
ALTER TABLE my_table MODIFY coupon_info FLOAT;-- Change column `coupon_info` from nullable to NOT NULL
-- If there are NULL values already, set table option as below to drop those records silently before altering table.
SET 'table.exec.sink.not-null-enforcer' = 'DROP';
ALTER TABLE my_table MODIFY coupon_info FLOAT NOT NULL;目前將可空列修改為NOT NULL僅在Flink中支持。
修改列注釋(Changing Column Comment)
以下SQL將列buy_count的注釋修改為“buy count”。
ALTER TABLE my_table MODIFY buy_count BIGINT COMMENT 'buy count';
添加列位置(Adding Column Position)
要添加具有指定位置的新列,使用FIRST或AFTER col_name。
ALTER TABLE my_table ADD c INT FIRST;ALTER TABLE my_table ADD c INT AFTER b;修改列位置(Changing Column Position)
要將現有列修改到新位置,使用FIRST或AFTER col_name。
ALTER TABLE my_table MODIFY col_a DOUBLE FIRST;ALTER TABLE my_table MODIFY col_a DOUBLE AFTER col_b;修改列類型(Changing Column Type)
以下SQL將列col_a的類型修改為DOUBLE。
ALTER TABLE my_table MODIFY col_a DOUBLE;
添加水印(Adding watermark)
以下SQL從現有列log_ts添加一個計算列ts,并在列ts上添加一個水印策略為ts-INTERVAL '1' HOUR,該列ts被標記為表my_table的事件時間屬性。
ALTER TABLE my_table ADD (ts AS TO_TIMESTAMP(log_ts) AFTER log_ts,WATERMARK FOR ts AS ts - INTERVAL '1' HOUR
);刪除水印(Dropping watermark)
以下SQL刪除表my_table的水印。
ALTER TABLE my_table DROP WATERMARK;
修改水印(Changing watermark)
以下SQL將水印策略修改為ts-INTERVAL '2' HOUR。
ALTER TABLE my_table MODIFY WATERMARK FOR ts AS ts - INTERVAL '2' HOUR
拓展:
表結構修改操作的重要性:在數據庫管理和數據處理中,修改表結構是一項常見且重要的操作。它允許用戶根據業務需求的變化,靈活地調整表的屬性、列結構、分區等,以優化數據存儲和查詢性能。例如,通過修改表屬性可以調整數據寫入的緩沖區大小,從而影響數據寫入的效率;添加或刪除列能夠適應業務數據的增減需求。
不同修改操作的細節與注意事項:
表屬性與注釋:修改表屬性和注釋操作相對直接,但在實際應用中需要準確理解每個屬性的含義和作用。比如
write-buffer-size屬性直接影響數據寫入的性能和資源使用情況。而表注釋則有助于文檔化表的用途和特點,方便團隊成員理解和維護。重命名操作:表名重命名在對象存儲環境下需謹慎,因為非原子性操作可能導致數據不一致。這提醒用戶在進行此類操作時,要考慮到存儲環境的特性,并做好相應的備份或恢復策略。
列操作:添加、重命名、刪除列以及修改列的可空性、注釋、位置和類型等操作,為表結構的精細調整提供了豐富手段。但在執行這些操作時,尤其是涉及到類型修改或刪除列操作時,需要特別注意數據兼容性和潛在的數據丟失風險。例如,在Hive目錄中刪除列時,需關注Hive元存儲的相關配置,避免因類型不兼容而導致操作失敗。
分區與水印操作:刪除分區操作可以清理不再需要的數據分區,優化存儲和查詢性能。而水印的添加、刪除和修改操作則與流處理中的事件時間處理緊密相關,正確設置水印策略能夠有效地處理亂序數據,確保流處理結果的準確性和一致性。
變更數據捕獲攝入(CDC Ingestion)
概述
Paimon支持多種方式將數據攝入到具有模式演變功能的Paimon表中。這意味著新增的列會實時同步到Paimon表,并且同步作業無需為此重啟。
我們目前支持以下同步方式:
-
MySQL 表同步:將一個或多個 MySQL 表同步到一個 Paimon 表中。
-
MySQL 數據庫同步:將整個 MySQL 數據庫同步到一個 Paimon 數據庫中。
-
程序 API 同步:將自定義的 DataStream 輸入同步到一個 Paimon 表中。
-
Kafka 表同步:將一個 Kafka 主題中的表同步到一個 Paimon 表中。
-
Kafka 數據庫同步:將包含多個表的一個 Kafka 主題或每個主題包含一個表的多個 Kafka 主題同步到一個 Paimon 數據庫中。
-
MongoDB 集合同步:將 MongoDB 中的一個集合同步到一個 Paimon 表中。
-
MongoDB 數據庫同步:將整個 MongoDB 數據庫同步到一個 Paimon 數據庫中。
-
Pulsar 表同步:將一個 Pulsar 主題中的表同步到一個 Paimon 表中。
-
Pulsar 數據庫同步:將包含多個表的一個 Pulsar 主題或每個主題包含一個表的多個 Pulsar 主題同步到一個 Paimon 數據庫中。
什么是模式演進
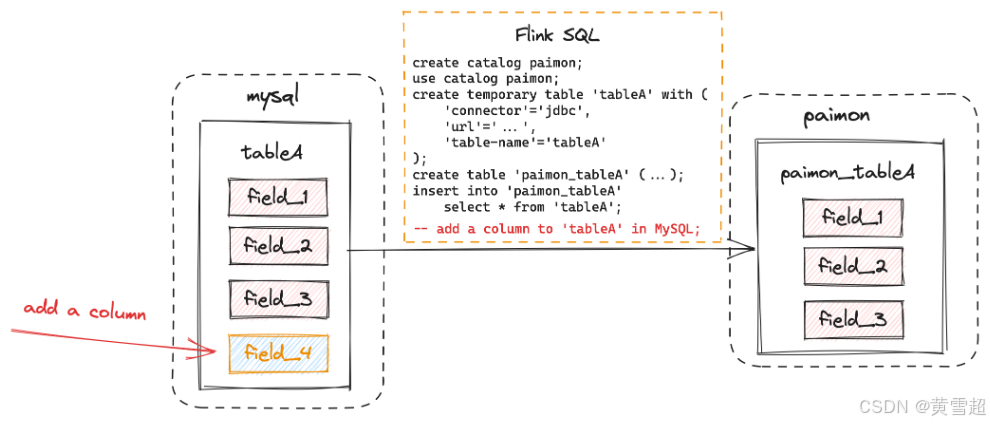
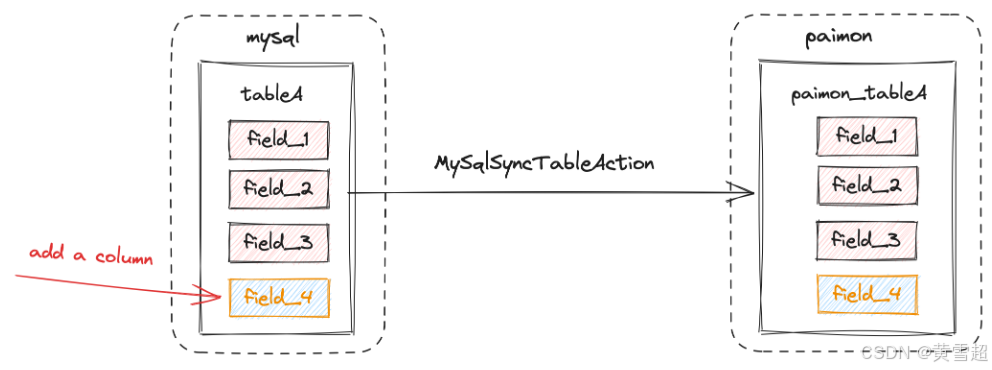
假設我們有一個名為 tableA 的 MySQL 表,它有三個字段:field_1、field_2、field_3。當我們想將這個 MySQL 表加載到 Paimon 時,可以在 Flink SQL 中操作,也可以使用 MySqlSyncTableAction。
Flink SQL:
在 Flink SQL 中,如果在數據攝入后更改 MySQL 表的表模式,表模式的更改不會同步到 Paimon。
MySqlSyncTableAction:
在 MySqlSyncTableAction中,如果在數據攝入后更改 MySQL 表的表模式,表模式的更改會同步到 Paimon,新添加的 field_4 字段的數據也會同步到 Paimon。
模式變更演進
CDC 攝取支持有限數量的模式變更。目前,該框架無法重命名表、刪除列,因此 RENAME TABLE(重命名表)和 DROP COLUMN(刪除列)操作將被忽略,RENAME COLUMN(重命名列)操作將添加一個新列。目前支持的模式變更包括:
-
添加列。
-
修改列類型。更具體地說,支持以下變更:
-
從一種字符串類型(char、varchar、text)變更為長度更長的另一種字符串類型;
-
從一種二進制類型(binary、varbinary、blob)變更為長度更長的另一種二進制類型;
-
從一種整數類型(tinyint、smallint、int、bigint)變更為范圍更廣的另一種整數類型;
-
從一種浮點類型(float、double)變更為范圍更廣的另一種浮點類型。
-
計算函數
--computed_column 是計算列的定義。參數字段來自源表字段名。
時間函數
時間函數可以將日期和紀元時間轉換為另一種形式。一個常見的用例是生成分區值。
| 函數 | 描述 |
|---|---|
| year(temporal-column [, precision]) | 從輸入中提取年份。輸出是一個表示年份的 INT 值。 |
| month(temporal-column [, precision]) | 從輸入中提取一年中的月份。輸出是一個表示月份的 INT 值。 |
| day(temporal-column [, precision]) | 從輸入中提取月份中的日期。輸出是一個表示日期的 INT 值。 |
| hour(temporal-column [, precision]) | 從輸入中提取小時。輸出是一個表示小時的 INT 值。 |
| minute(temporal-column [, precision]) | 從輸入中提取分鐘。輸出是一個表示分鐘的 INT 值。 |
| second(temporal-column [, precision]) | 從輸入中提取秒。輸出是一個表示秒的 INT 值。 |
| date_format(temporal-column, format-string [, precision]) | 將輸入轉換為所需格式的字符串。輸出類型為 STRING。 |
時間列的數據類型可以是以下幾種情況之一:
-
日期、日期時間或時間戳。(DATE, DATETIME or TIMESTAMP)
-
任何整數類型(例如 INT 和 BIGINT)。在這種情況下,數據將被視為 1970-01-01 00:00:00 的紀元時間。你應該設置值的精度(默認精度為 0)。
-
字符串。在這種情況下,如果你未設置時間單位,數據將被視為日期、日期時間或時間戳值的格式化字符串。否則,數據將被視為紀元時間的字符串值。所以在后一種情況下,你必須設置時間單位。
精度表示紀元時間的單位。目前,有四種有效的精度:0(表示紀元秒)、3(表示紀元毫秒)、6(表示紀元微秒)和9(表示紀元納秒)。以時間點1970-01-01 00:00:00.123456789為例,紀元秒為0,紀元毫秒為123,紀元微秒為123456,紀元納秒為123456789。精度應與輸入值匹配。你可以通過以下方式設置精度:date_format(epoch_col, yyyy-MM-dd, 0) 。
date_format是一個靈活的函數,它能夠使用不同的格式字符串將時間值轉換為各種格式。最常見的格式字符串是yyyy-MM-dd HH:mm:ss.SSS。另一個例子是yyyy-ww,它可以從輸入中提取年份和當年的周數。請注意,輸出受區域設置的影響。例如,在某些地區,一周的第一天是星期一,而在其他地區是星期日,所以如果你使用date_format(date_col, yyyy-ww) ,并且date_col的輸入是2024-01-07(星期日),輸出可能是2024-01(如果一周的第一天是星期一)或2024-02(如果一周的第一天是星期日)。
其他函數
| 函數 | 描述 |
|---|---|
| substring(column, beginInclusive) | 獲取column.substring(beginInclusive) 。輸出是一個字符串。 |
| substring(column, beginInclusive, endExclusive) | 獲取column.substring(beginInclusive, endExclusive) 。輸出是一個字符串。 |
| truncate(column, width) | 按寬度截斷column 。輸出類型與column相同。如果column是一個字符串,truncate(column, width)會將字符串截斷為width個字符,即 |
| cast(value, dataType) | 獲取一個常量值。輸出是一種原子類型,如字符串、整數、布爾值等。 |
特殊數據類型映射
-
MySQL的TINYINT(1)類型默認將映射為布爾值。如果你想像MySQL一樣在其中存儲數字(- 128 ~ 127),可以指定類型映射選項tinyint1-not-bool(使用--type_mapping),然后該列將在Paimon表中映射為TINYINT。
-
你可以使用類型映射選項to-nullable(使用--type_mapping)來忽略所有非空約束(主鍵除外)。
-
你可以使用類型映射選項to-string(使用--type_mapping)將所有MySQL數據類型映射為字符串。
-
你可以使用類型映射選項char-to-string(使用--type_mapping)將MySQL的CHAR(length)/VARCHAR(length)類型映射為字符串。
-
你可以使用類型映射選項longtext-to-bytes(使用--type_mapping)將MySQL的LONGTEXT類型映射為BYTES。
-
MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL默認將映射為DECIMAL(20, 0) 。你可以使用類型映射選項bigint-unsigned-to-bigint(使用--type_mapping)將這些類型映射為Paimon的BIGINT,但存在潛在的數據溢出風險,因為BIGINT UNSIGNED最多可以存儲20位整數值,而Paimon的BIGINT最多只能存儲19位整數值。所以在使用此選項時,你應確保不會發生溢出。
-
MySQL的BIT(1)類型將映射為布爾值。
-
當使用Hive目錄時,MySQL的TIME類型將映射為字符串。
-
MySQL的BINARY將映射為Paimon的VARBINARY。這是因為二進制值在binlog中是以字節形式傳遞的,所以它應該映射為字節類型(BYTES或VARBINARY)。我們選擇VARBINARY是因為它可以保留長度信息。
自定義作業設置
檢查點:使用-Dexecution.checkpointing.interval = <interval> 來啟用檢查點并設置間隔。對于0.7及更高版本,如果你沒有啟用檢查點,Paimon將默認啟用檢查點并將檢查點間隔設置為180秒。
作業名稱:使用-Dpipeline.name = <job-name> 來設置自定義同步作業名稱。
表配置:你可以使用--table_conf來設置表屬性和一些Flink作業屬性(如sink.parallelism)。如果表是由CDC作業創建的,表的屬性將與給定的屬性相同。否則,作業將使用給定的屬性來更改表的屬性。但請注意,不可變選項(如merge-engine)和桶數不會被更改。
拓展:
DataStream:在流計算領域,DataStream代表一個連續的數據流。在Apache Flink等流計算框架中,DataStream是處理無界數據的基本抽象。它可以從各種數據源(如Kafka、文件等)獲取數據,然后通過一系列的轉換操作(如過濾、映射、聚合等)進行處理,最終輸出到各種數據接收器(如文件系統、數據庫等)。DataStream處理模型允許開發者對實時數據流進行低延遲、高吞吐的處理,適用于許多實時應用場景,如實時監控、實時分析等。
Kafka:是一個分布式流平臺,由Apache軟件基金會開發。它主要用于處理和存儲大量的實時數據流。Kafka具有高吞吐量、可擴展性、容錯性等特點。它以主題(topic)為單位來組織數據,生產者(producer)將消息發送到特定的主題,消費者(consumer)從主題中拉取消息進行處理。Kafka常用于日志收集、消息隊列、流處理等場景,許多大數據和實時應用都依賴Kafka來處理和傳輸數據。
MySQL:是最流行的開源關系型數據庫管理系統之一。它基于SQL(結構化查詢語言),廣泛應用于各種Web應用程序和企業級應用中。MySQL具有高性能、可靠性和易用性等優點,支持事務處理、數據備份與恢復等功能。在數據同步場景中,常作為數據源,將其中的數據同步到其他數據存儲或處理系統,如Paimon。
MongoDB:是一個基于分布式文件存儲的開源文檔數據庫。與傳統的關系型數據庫不同,MongoDB以BSON(一種類似JSON的二進制格式)文檔的形式存儲數據,這種數據模型更靈活,適合處理半結構化和非結構化數據。它具有高可擴展性、高可用性等特點,常用于大數據存儲、內容管理、實時分析等場景,同樣在數據同步場景中可作為數據源。
Pulsar:是一個云原生分布式消息流平臺,由Apache軟件基金會開發。它提供了統一的消息和流處理原語,支持多租戶、持久化消息、高吞吐量等特性。Pulsar的架構設計使其能夠在大規模集群環境下高效運行,在消息隊列、流處理等領域有廣泛應用,在數據同步中可作為數據源,將其主題中的數據同步到Paimon。
Schema(模式):在數據庫和數據處理領域,模式定義了數據的結構和組織方式。例如在關系型數據庫中,表模式包括表名、列名、列的數據類型等信息。在大數據領域,像 Avro、JSON Schema 等定義了數據記錄的結構規范。模式演進則指隨著業務發展,模式需要動態更新,比如添加新列、修改數據類型等,而不影響已有數據處理邏輯或盡可能少影響。
DataStream(數據流):是 Apache Flink 等流處理框架中的核心概念,表示連續不斷的數據流。數據以事件序列的形式在 DataStream 中流動,框架可以對這些數據流進行實時的轉換、聚合等操作。常見的 DataStream 來源有 Kafka、Pulsar 等消息隊列,以及文件流等。
CDC(Change Data Capture,變更數據捕獲):是一種用于捕獲數據庫中數據更改的技術。它可以實時或近實時地檢測到數據庫表中的插入、更新和刪除操作,并將這些變更數據提取出來用于其他目的,如數據同步、數據集成、實時數據分析等。例如,在微服務架構中,不同服務的數據庫之間可能需要通過 CDC 技術來保持數據的一致性。
Ingestion(攝取):在這里指將數據引入到特定的系統或流程中。在數據處理場景下,數據攝取通常涉及從各種數據源(如數據庫、文件系統、消息隊列等)獲取數據,并將其轉換和加載到目標存儲或處理系統中,比如數據倉庫或大數據處理平臺。
Computed Column(計算列):在數據庫中,計算列的值是通過表達式基于同一表中其他列的值計算得出的。例如,在一個 “訂單” 表中有 “單價” 和 “數量” 列,你可以創建一個計算列 “總價”,其值通過 “單價 * 數量” 計算得到。計算列并不實際存儲數據,而是在查詢時實時計算。這有助于減少數據冗余,并在需要時快速獲取派生數據。
Temporal Functions(時間函數):主要用于處理日期和時間相關的數據。在數據庫和數據處理場景中,經常需要對時間數據進行格式化、提取特定部分(如年、月、日等)的操作。例如在數據分析中,按年、月對銷售數據進行分組統計時,就會用到這些時間函數。
Epoch Time(紀元時間):也稱為 Unix 時間,是一種表示時間的方式,定義為從 1970 年 1 月 1 日 00:00:00 UTC 到特定時間點所經過的秒數。在編程和數據庫中廣泛用于時間戳的存儲和計算,因為它是一種簡單且標準化的時間表示方法,便于在不同系統和編程語言之間進行數據交換和處理。
MySQL變更數據捕獲(CDC)
Paimon支持使用變更數據捕獲(CDC)從不同數據庫同步數據變更。此功能需要Flink及其CDC連接器。
準備CDC捆綁包JAR
下載CDC捆綁包JAR并將其放置在<FLINK_HOME>/lib/目錄下。
| 版本 | 捆綁包JAR |
|---|---|
| 2.3.x | 僅0.8.2以下版本支持 flink-sql-connector-mysql-cdc-2.3.x.jar |
| 2.4.x | 僅0.8.2以下版本支持 flink-sql-connector-mysql-cdc-2.4.x.jar |
| 3.0.x | 僅0.8.2以下版本支持 flink-sql-connector-mysql-cdc-3.0.x.jar flink-cdc-common-3.0.x.jar |
| 3.1.x | flink-sql-connector-mysql-cdc-3.1.x.jar mysql-connector-java-8.0.27.jar |
同步表
通過在Flink DataStream作業中使用MySqlSyncTableAction,或直接通過flink run,用戶可以將一個或多個MySQL表同步到一個Paimon表中。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--type_mapping <option1,option2...>] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--metadata_column <metadata-column>] \[--mysql_conf <mysql-cdc-source-conf> [--mysql_conf <mysql-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何將MySQL數據類型映射到Paimon類型。 支持的選項: “tinyint1-not-bool”:將MySQL的TINYINT(1)映射為TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空約束(主鍵除外)。這用于解決Flink無法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的問題。 “to-string”:將所有MySQL類型映射為STRING。 “char-to-string”:將MySQL的CHAR(length)/VARCHAR(length)類型映射為STRING。 “longtext-to-bytes”:將MySQL的LONGTEXT類型映射為BYTES。 “bigint-unsigned-to-bigint”:將MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射為BIGINT。使用此選項時應確保不會發生溢出。 |
| --computed_column | 計算列的定義。參數字段來自MySQL表字段名。有關完整的配置列表,請參閱此處。 |
| --metadata_column | --metadata_column用于指定在連接器的輸出模式中包含哪些元數據列。元數據列提供與源數據相關的附加信息,例如:--metadata_column table_name,database_name,op_ts。有關可用元數據的完整列表,請參閱其文檔。 |
| --mysql_conf | Flink CDC MySQL源的配置。每個配置應采用“key = value”的格式指定。hostname、username、password、database-name和table-name是必需的配置,其他是可選的。有關完整的配置列表,請參閱其文檔。 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
如果指定的Paimon表不存在,此操作將自動創建該表。其模式將從所有指定的MySQL表派生而來。如果Paimon表已存在,將把它的模式與所有指定MySQL表的模式進行比較。
示例1:將表同步到一個Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name='source_db' \--mysql_conf table-name='source_table1|source_table2' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如示例所示,mysql_conf的table-name支持正則表達式,以監控滿足正則表達式的多個表。所有表的模式將合并為一個Paimon表模式。
示例2:將分片同步到一個Paimon表?你還可以使用正則表達式設置database-name以捕獲多個數據庫。一個典型的場景是,表“source_table”被拆分到數據庫“source_db1”、“source_db2”等中,然后你可以將所有“source_table”的數據同步到一個Paimon表中。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name='source_db.+' \--mysql_conf table-name='source_table' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4同步數據庫
通過在Flink DataStream作業中使用MySqlSyncDatabaseAction,或直接通過flink run,用戶可以將整個MySQL數據庫同步到一個Paimon數據庫中。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database--warehouse <warehouse-path> \--database <database-name> \[--ignore_incompatible <true/false>] \[--merge_shards <true/false>] \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <mysql-table-name|name-regular-expr>] \[--excluding_tables <mysql-table-name|name-regular-expr>] \[--mode <sync-mode>] \[--metadata_column <metadata-column>] \[--type_mapping <option1,option2...>] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--mysql_conf <mysql-cdc-source-conf> [--mysql_conf <mysql-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --ignore_incompatible | 默認值為false,在這種情況下,如果MySQL表名在Paimon中存在且它們的模式不兼容,將拋出異常。你可以顯式地將其指定為true以忽略不兼容的表和異常。 |
| --merge_shards | 默認值為true,在這種情況下,如果不同數據庫中的某些表具有相同的名稱,它們的模式將被合并,并且它們的記錄將被同步到一個Paimon表中。否則,每個表的記錄將被同步到相應的Paimon表中,并且Paimon表將被命名為'databaseName_tableName'以避免潛在的名稱沖突。 |
| --table_prefix | 要同步的所有Paimon表的前綴。例如,如果你希望所有同步的表都有“ods_”作為前綴,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后綴。用法與“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必須使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法與“--including_tables”相同。如果同時指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的優先級。 |
| --mode | 用于指定同步模式。 可能的值: “divided”(如果你未指定,則為默認模式):為每個表啟動一個接收器,新表的同步需要重新啟動作業。 “combined”:為所有表啟動一個單一的組合接收器,新表將自動同步。 |
| --metadata_column | --metadata_column用于指定在連接器的輸出模式中包含哪些元數據列。元數據列提供與源數據相關的附加信息,例如:--metadata_column table_name,database_name,op_ts。有關可用元數據的完整列表,請參閱其文檔。 |
| --type_mapping | 用于指定如何將MySQL數據類型映射到Paimon類型。 支持的選項: “tinyint1-not-bool”:將MySQL的TINYINT(1)映射為TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空約束(主鍵除外)。這用于解決Flink無法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的問題。 “to-string”:將所有MySQL類型映射為STRING。 “char-to-string”:將MySQL的CHAR(length)/VARCHAR(length)類型映射為STRING。 “longtext-to-bytes”:將MySQL的LONGTEXT類型映射為BYTES。 “bigint-unsigned-to-bigint”:將MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射為BIGINT。使用此選項時應確保不會發生溢出。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。如果這些鍵不在源表中,接收器表將不設置分區鍵。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。如果這些鍵不在源表中,但源表有主鍵,接收器表將使用源表的主鍵。否則,接收器表將不設置主鍵。 |
| --mysql_conf | Flink CDC MySQL源的配置。每個配置應采用“key = value”的格式指定。hostname、username、password、database-name和table-name是必需的配置,其他是可選的。有關完整的配置列表,請參閱其文檔。 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
只有具有主鍵的表才會被同步。
對于每個要同步的MySQL表,如果相應的Paimon表不存在,此操作將自動創建該表。其模式將從所有指定的MySQL表派生而來。如果Paimon表已存在,將把它的模式與所有指定MySQL表的模式進行比較。
示例1:同步整個數據庫
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4示例2:同步數據庫下新添加的表 假設一開始一個Flink作業正在同步source_db數據庫下的[product, user, address]表。提交作業的命令如下:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4 \--including_tables 'product|user|address'之后,我們希望作業也同步包含歷史數據的[order, custom]表。我們可以通過從作業的先前快照恢復來實現這一點,從而重用作業的現有狀態。恢復的作業將首先對新添加的表進行快照,然后自動從先前的位置繼續讀取變更日志。
從先前快照恢復并添加新表進行同步的命令如下:
<FLINK_HOME>/bin/flink run \--fromSavepoint savepointPath \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--including_tables 'product|user|address|order|custom'你可以設置--mode combined以啟用在不重啟作業的情況下同步新添加的表。
示例3:同步并合并多個分片 假設你有多個數據庫分片db1、db2等,并且每個數據庫都有表tbl1、tbl2等。你可以通過以下命令將所有db.+.tbl.+同步到test_db.tbl1、test_db.tbl2等表中:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mysql_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mysql_conf hostname=127.0.0.1 \--mysql_conf username=root \--mysql_conf password=123456 \--mysql_conf database-name='db.+' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4 \--including_tables 'tbl.+'通過將database-name設置為正則表達式,同步作業將捕獲匹配數據庫下的所有表,并將同名表合并為一個表。
你可以設置--merge_shards false以防止合并分片。同步后的表將命名為‘databaseName_tableName’以避免潛在的名稱沖突。
常見問題解答
從MySQL攝入的記錄中的中文字符出現亂碼。 嘗試在flink-conf.yaml中設置env.java.opts: -Dfile.encoding=UTF-8(自Flink-1.17起,該選項已更改為env.java.opts.all)。
拓展:
CDC(Change Data Capture,變更數據捕獲):這是一種用于捕獲數據庫中數據更改的技術。在數據集成、數據同步和實時數據分析等場景中廣泛應用。通過CDC,系統可以實時感知數據庫表的插入、更新和刪除操作,并將這些變化傳播到其他系統或存儲中。例如,在微服務架構中,不同服務之間的數據同步就可以借助CDC技術,使得數據在多個服務間保持一致。
Flink:Apache Flink是一個分布式流批一體化的開源平臺,專為高吞吐、低延遲的流處理應用而設計。它提供了豐富的API,支持多種編程語言,能夠在不同的集群環境(如YARN、Kubernetes等)上運行。Flink具備強大的狀態管理和容錯機制,適合處理實時數據和復雜的事件處理。例如,在電商實時數據分析場景中,Flink可以實時處理用戶的點擊流數據、訂單數據等,實現實時的銷售統計、用戶行為分析等功能。
正則表達式:在文本處理中,正則表達式是一種描述字符模式的工具。在上述場景中,用于指定要同步的數據庫名或表名,能夠方便地匹配一組符合特定規則的數據庫或表。例如
source_db. +表示匹配以source_db開頭的所有數據庫名;tbl. +表示匹配以tbl開頭的所有表名。不同編程語言和工具對正則表達式的支持略有差異,但基本的語法和功能相似。在Python中,通過re模塊可以使用正則表達式進行字符串匹配、搜索、替換等操作。Flink CDC連接器:是Flink用于連接各種數據源并捕獲其數據變更的組件。針對不同的數據庫(如MySQL、PostgreSQL等),有相應的CDC連接器。這些連接器負責與數據庫進行交互,監聽數據的變化,并將變更數據傳遞給Flink進行后續處理。例如
flink-sql-connector-mysql-cdc就是用于連接MySQL數據庫并捕獲其數據變更的連接器。元數據列(Metadata Column):在數據同步過程中,元數據列提供了與源數據相關的額外信息。比如
table_name表示數據來自哪個源表,database_name表示來自哪個源數據庫,op_ts可能表示數據操作的時間戳等。這些元數據對于數據的追蹤、審計和進一步處理非常有幫助。例如,在數據質量監控中,可以根據操作時間戳來分析數據變更的頻率和趨勢,以發現潛在的數據問題。
PostgreSQL變更數據捕獲(CDC)
Paimon支持使用變更數據捕獲(CDC)從不同數據庫同步數據變更。此功能需要Flink及其CDC連接器。
準備CDC捆綁包JAR
flink-connector-postgres-cdc-*.jar
同步表
通過在Flink DataStream作業中使用PostgresSyncTableAction,或直接通過flink run,用戶可以將一個或多個PostgreSQL表同步到一個Paimon表中。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \postgres_sync_table--warehouse <warehouse_path> \--database <database_name> \--table <table_name> \[--partition_keys <partition_keys>] \[--primary_keys <primary_keys>] \[--type_mapping <option1,option2...>] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--metadata_column <metadata_column>] \[--postgres_conf <postgres_cdc_source_conf> [--postgres_conf <postgres_cdc_source_conf> ...]] \[--catalog_conf <paimon_catalog_conf> [--catalog_conf <paimon_catalog_conf> ...]] \[--table_conf <paimon_table_sink_conf> [--table_conf <paimon_table_sink_conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何將PostgreSQL數據類型映射到Paimon類型。 支持的選項: “to-string”:將所有PostgreSQL類型映射為STRING。 |
| --computed_column | 計算列的定義。參數字段來自PostgreSQL表字段名。有關完整的配置列表,請參閱此處。 |
| --metadata_column | --metadata_column用于指定在連接器的輸出模式中包含哪些元數據列。元數據列提供與源數據相關的附加信息,例如:--metadata_column table_name,database_name,schema_name,op_ts。有關可用元數據的完整列表,請參閱其文檔。 |
| --postgres_conf | Flink CDC Postgres源的配置。每個配置應采用“key = value”的格式指定。hostname、username、password、database-name、schema-name、table-name和slot.name是必需的配置,其他是可選的。有關完整的配置列表,請參閱其文檔。 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
如果指定的Paimon表不存在,此操作將自動創建該表。其模式將從所有指定的PostgreSQL表派生而來。如果Paimon表已存在,將把它的模式與所有指定PostgreSQL表的模式進行比較。
示例1:將表同步到一個Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \postgres_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--postgres_conf hostname=127.0.0.1 \--postgres_conf username=root \--postgres_conf password=123456 \--postgres_conf database-name='source_db' \--postgres_conf schema-name='public' \--postgres_conf table-name='source_table1|source_table2' \--postgres_conf slot.name='paimon_cdc' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如示例所示,postgres_conf的table-name支持正則表達式,以監控滿足正則表達式的多個表。所有表的模式將合并為一個Paimon表模式。
示例2:將分片同步到一個Paimon表 你還可以使用正則表達式設置‘schema-name’以捕獲多個模式。一個典型的場景是,表“source_table”被拆分到模式“source_schema1”、“source_schema2”等中,然后你可以將所有“source_table”的數據同步到一個Paimon表中。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \postgres_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--postgres_conf hostname=127.0.0.1 \--postgres_conf username=root \--postgres_conf password=123456 \--postgres_conf database-name='source_db' \--postgres_conf schema-name='source_schema.+' \--postgres_conf table-name='source_table' \--postgres_conf slot.name='paimon_cdc' \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4拓展:
PostgreSQL:一種強大的開源關系型數據庫管理系統,以其對SQL標準的廣泛支持、豐富的數據類型和強大的擴展性而聞名。在數據處理場景中,常用于存儲和管理復雜的數據結構與業務邏輯相關的數據。例如,在一些對數據完整性和事務處理要求較高的企業級應用中,PostgreSQL可以作為后端數據庫存儲關鍵業務數據。
flink-connector-postgres-cdc-*.jar:這是Flink用于連接PostgreSQL數據庫并進行變更數據捕獲的連接器JAR包。它負責與PostgreSQL數據庫建立連接,監聽數據庫中的數據變化,并將這些變更數據傳遞給Flink進行后續處理。在使用時,需要將該JAR包放置在Flink的相關目錄下,以便Flink能夠加載并使用其中的功能。
PostgreSQL模式(Schema):在PostgreSQL中,模式是數據庫對象(如表、視圖、函數等)的邏輯分組。類似于命名空間,它可以幫助用戶更好地組織和管理數據庫中的對象。不同模式中的對象可以有相同的名稱而不會沖突。在數據同步場景中,通過設置
schema-name并結合正則表達式,可以靈活地選擇需要同步的模式及其下的表,這在處理大型、復雜的數據庫結構時非常有用。Slot.name:在PostgreSQL的邏輯復制中,Slot(槽)用于標識一個復制流。slot.name是在配置Flink CDC Postgres源時必須指定的參數之一,它定義了用于捕獲變更數據的邏輯復制槽的名稱。每個邏輯復制槽會跟蹤數據庫的更改,并將這些更改提供給訂閱者(如Flink作業)。例如,在上述配置中使用
paimon_cdc作為槽名,該槽將負責捕獲相關表的變更數據并傳遞給Flink進行同步到Paimon表的操作。
Kafka變更數據捕獲(CDC)
準備Kafka捆綁包JAR
flink-sql-connector-kafka-*.jar
支持的格式
Flink提供了幾種Kafka CDC格式:Canal Json、Debezium Json、Debezium Avro、Ogg Json、Maxwell Json和普通Json。如果Kafka主題中的消息是使用變更數據捕獲(CDC)工具從其他數據庫捕獲的變更事件,那么你可以使用Paimon Kafka CDC,將解析后的INSERT、UPDATE、DELETE消息寫入Paimon表。
| 格式 | 是否支持 |
|---|---|
| Canal CDC | True |
| Debezium CDC | True |
| Maxwell CDC | True |
| OGG CDC | True |
| JSON | True |
JSON源可能缺少一些信息。例如,Ogg和Maxwell格式標準不包含字段類型;當你將JSON源寫入Flink Kafka接收器時,它將只保留數據和行類型,而丟棄其他信息。同步作業將盡力按如下方式處理該問題:
-
通常,debezium-json包含“schema”字段,Paimon將從中檢索數據類型。請確保你的debezium json有此字段,否則Paimon將使用“STRING”類型。
-
如果缺少字段類型,Paimon將默認使用“STRING”類型。
-
如果缺少數據庫名或表名,你無法進行數據庫同步,但仍可以進行表同步。
-
如果缺少主鍵,作業可能會創建無主鍵表。你可以在提交表同步作業時設置主鍵。
同步表
通過在Flink DataStream作業中使用KafkaSyncTableAction,或直接通過flink run,用戶可以將Kafka一個主題中的一個或多個表同步到一個Paimon表中。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--type_mapping to-string] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--kafka_conf <kafka-source-conf> [--kafka_conf <kafka-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何將MySQL數據類型映射到Paimon類型。 支持的選項: “tinyint1-not-bool”:將MySQL的TINYINT(1)映射為TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空約束(主鍵除外)。這用于解決Flink無法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的問題。 “to-string”:將所有MySQL類型映射為STRING。 “char-to-string”:將MySQL的CHAR(length)/VARCHAR(length)類型映射為STRING。 “longtext-to-bytes”:將MySQL的LONGTEXT類型映射為BYTES。 “bigint-unsigned-to-bigint”:將MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射為BIGINT。使用此選項時應確保不會發生溢出。 |
| --computed_column | 計算列的定義。參數字段來自Kafka主題的表字段名。有關完整的配置列表,請參閱此處。 |
| --kafka_conf | Flink Kafka源的配置。每個配置應采用 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
如果指定的Paimon表不存在,此操作將自動創建該表。其模式將從所有指定的Kafka主題的表派生而來,它從主題中獲取最早的非DDL數據解析模式。如果Paimon表已存在,將把它的模式與所有指定的Kafka主題的表的模式進行比較。
示例1:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=order \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=canal-json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如果在啟動同步作業時Kafka主題不包含消息,則必須在提交作業前手動創建表。你可以僅定義分區鍵和主鍵,其余列將由同步作業添加。
注意:在這種情況下,你不應使用–partition_keys或–primary_keys,因為這些鍵在創建表時已定義且無法修改。此外,如果你指定了計算列,還應定義計算列使用的所有參數字段。
示例2:如果你想同步一個主鍵為id INT的表,并且想計算一個分區鍵part = date_format(create_time,yyyy-MM-dd),你可以先創建這樣一個表(其他列可以省略):
CREATE TABLE test_db.test_table (id INT, -- primary keycreate_time TIMESTAMP, -- the argument of computed column partpart STRING, -- partition keyPRIMARY KEY (id, part) NOT ENFORCED
) PARTITIONED BY (part);然后你可以提交同步作業:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--computed_column 'part=date_format(create_time,yyyy-MM-dd)' \... (other conf)示例3:對于一些追加數據(如日志數據),它可以被視為僅包含INSERT操作類型的特殊CDC數據,因此你可以使用format = json將此類數據同步到Paimon表。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--computed_column 'pt=date_format(event_tm, yyyyMMdd)' \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=test_log \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf sink.parallelism=4同步數據庫
通過在Flink DataStream作業中使用KafkaSyncDatabaseAction,或直接通過flink run,用戶可以將多個主題或一個主題同步到一個Paimon數據庫。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_database--warehouse <warehouse-path> \--database <database-name> \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <table-name|name-regular-expr>] \[--excluding_tables <table-name|name-regular-expr>] \[--type_mapping to-string] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--kafka_conf <kafka-source-conf> [--kafka_conf <kafka-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --ignore_incompatible | 默認值為false,在這種情況下,如果MySQL表名在Paimon中存在且它們的模式不兼容,將拋出異常。你可以顯式地將其指定為true以忽略不兼容的表和異常。 |
| --table_prefix | 要同步的所有Paimon表的前綴。例如,如果你希望所有同步的表都有“ods_”作為前綴,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后綴。用法與“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必須使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法與“--including_tables”相同。如果同時指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的優先級。 |
| --type_mapping | 用于指定如何將MySQL數據類型映射到Paimon類型。 支持的選項: “tinyint1-not-bool”:將MySQL的TINYINT(1)映射為TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空約束(主鍵除外)。這用于解決Flink無法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的問題。 “to-string”:將所有MySQL類型映射為STRING。 “char-to-string”:將MySQL的CHAR(length)/VARCHAR(length)類型映射為STRING。 “longtext-to-bytes”:將MySQL的LONGTEXT類型映射為BYTES。 “bigint-unsigned-to-bigint”:將MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射為BIGINT。使用此選項時應確保不會發生溢出。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。如果這些鍵不在源表中,接收器表將不設置分區鍵。 |
| --multiple_table_partition_keys | 每個不同Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如: --multiple_table_partition_keys tableName1 = col1,col2.col3 --multiple_table_partition_keys tableName2 = col4,col5.col6 --multiple_table_partition_keys tableName3 = col7,col8.col9 如果這些鍵不在源表中,接收器表將不設置分區鍵。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。如果這些鍵不在源表中,但源表有主鍵,接收器表將使用源表的主鍵。否則,接收器表將不設置主鍵。 |
| --kafka_conf | Flink Kafka源的配置。每個配置應采用 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
此操作將為所有表構建一個單一的組合接收器。對于每個要同步的Kafka主題的表,如果相應的Paimon表不存在,此操作將自動創建該表,并且其模式將從所有指定的Kafka主題的表派生而來。如果Paimon表已存在且其模式與從Kafka記錄解析的模式不同,此操作將嘗試進行模式演進。
示例:
-
從一個Kafka主題同步到Paimon數據庫:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=order \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=canal-json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4-
從多個Kafka主題同步到Paimon數據庫:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=order\;logistic_order\;user \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=canal-json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4額外的Kafka配置
有一些用于構建Flink Kafka源的有用選項,但它們未在flink-kafka-connector文檔中提供。它們是:
| 鍵 | 默認值 | 類型 | 描述 |
|---|---|---|---|
| schema.registry.url | (none) | 字符串 | 當配置“value.format = debezium-avro”時,這需要使用Confluence模式注冊表模型進行Apache Avro序列化,你需要提供模式注冊表URL。 |
拓展:
Kafka:是一個分布式流平臺,常用于處理實時數據。它具有高吞吐量、可擴展性和容錯性等特點,在大數據生態系統中被廣泛應用于數據的收集、傳輸和分發。例如,在電商系統中,Kafka可以收集用戶的各種行為數據(如點擊、購買等),然后將這些數據分發給不同的分析系統進行實時處理。
Flink Kafka連接器:
flink-sql-connector-kafka-*.jar是Flink與Kafka集成的關鍵組件。它允許Flink從Kafka主題中讀取數據,并將處理后的數據寫回到Kafka主題。在CDC場景下,該連接器負責從Kafka獲取包含變更數據的消息,并將其傳遞給Flink進行進一步處理,如解析消息并同步到Paimon表。這涉及到對Kafka消息格式的理解和處理,以及與Flink的流處理邏輯相結合。Canal:是阿里巴巴開發的一款基于MySQL數據庫增量日志解析,提供增量數據訂閱和消費的開源工具。Canal模擬MySQL主從復制架構中的slave節點,通過解析MySQL的二進制日志(binlog)來獲取數據變更,然后將這些變更以特定格式(如Canal Json)發送到Kafka等消息隊列中。在數據同步場景中,Canal為捕獲MySQL數據變化提供了一種高效可靠的方式。
Debezium:是一個開源的分布式平臺,用于捕獲數據庫的變更數據。它支持多種數據庫,如MySQL、PostgreSQL等。Debezium將數據庫的更改記錄轉換為事件流,并以特定格式(如Debezium Json、Debezium Avro)輸出到消息代理(如Kafka)。Debezium提供了豐富的元數據信息,如數據庫名、表名、字段類型等,這對于數據同步和處理非常有幫助。例如,在異構數據庫之間的數據同步場景中,Debezium可以將源數據庫的變更準確地傳遞到目標系統。
Maxwell:是一個用于從MySQL數據庫捕獲數據變更并將其作為JSON格式消息發送到Kafka等消息隊列的工具。它通過解析MySQL的binlog來實現數據捕獲。Maxwell的JSON格式消息相對簡潔,但可能缺少一些像字段類型這樣的詳細元數據信息,在使用時需要額外處理。
OGG(Oracle GoldenGate):是甲骨文公司的一款數據集成和復制軟件,能夠在異構數據庫之間實現數據的實時復制和同步。OGG可以捕獲源數據庫的變更,并將其傳輸到目標數據庫或其他消息系統。當使用OGG與Kafka結合時,OGG會將捕獲到的數據變更以OGG Json格式發送到Kafka,后續Flink可以從Kafka獲取這些數據進行進一步處理。
Avro:是一種數據序列化系統,它提供了豐富的數據結構類型,并且支持數據的壓縮和模式演變。在Kafka CDC中,當使用Debezium Avro格式時,數據會以Avro格式進行序列化,并通過Kafka傳輸。Avro的模式信息可以存儲在Schema Registry中,這有助于確保數據的一致性和可解析性。例如,在處理大規模數據傳輸和存儲時,Avro的壓縮功能可以有效減少數據傳輸量和存儲空間。
Schema Registry:是一個存儲和管理Avro、Protobuf等序列化格式的模式(Schema)的服務。在使用Debezium Avro格式時,Flink Kafka源需要從Schema Registry獲取相應的模式信息,以便正確解析Kafka消息中的數據。Schema Registry提供了版本管理、兼容性檢查等功能,確保數據生產者和消費者之間的模式一致性。例如,當數據結構發生變化時,Schema Registry可以幫助管理新模式的注冊和版本控制,使得消費者能夠正確處理新的數據格式。
MongoDB變更數據捕獲(CDC)
準備MongoDB捆綁包JAR
flink-sql-connector-mongodb-cdc-*.jar
僅支持3.1+版本的CDC
同步表
通過在Flink DataStream作業中使用MongoDBSyncTableAction,或直接通過flink run,用戶可以將MongoDB中的一個集合同步到一個Paimon表中。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--mongodb_conf <mongodb-cdc-source-conf> [--mongodb_conf <mongodb-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。 |
| --computed_column | 計算列的定義。參數字段來自MongoDB集合字段名。有關完整的配置列表,請參閱此處。 |
| --mongodb_conf | Flink CDC MongoDB源的配置。每個配置應采用“key = value”的格式指定。hosts、username、password、database和collection是必需的配置,其他是可選的。有關完整的配置列表,請參閱其文檔。 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
這里有幾點需要注意:
-
mongodb_conf在MongoDB CDC源配置的基礎上引入了schema.start.mode參數。schema.start.mode提供兩種模式:dynamic(默認)和specified。在dynamic模式下,MongoDB模式信息在一個層級上進行解析,這構成了模式變更演進的基礎。在specified模式下,同步根據指定的標準進行。這可以通過配置field.name來指定同步字段,并通過parser.path指定這些字段的JSON解析路徑來實現。兩者的區別在于,specified模式要求用戶明確標識要使用的字段,并基于這些字段創建映射表。而dynamic模式則確保Paimon和MongoDB始終保持頂級字段一致,無需關注特定字段。在使用嵌套字段的值時,需要對數據表進行進一步處理。 -
mongodb_conf在MongoDB CDC源配置的基礎上引入了default.id.generation參數。default.id.generation設置提供兩種不同的行為:設置為true和設置為false時。當default.id.generation設置為true時,MongoDB CDC源遵循默認的_id生成策略,即去除外部的$oid嵌套,以提供更簡潔的標識符。這種模式簡化了_id的表示,使其更直接且用戶友好。相反,當default.id.generation設置為false時,MongoDB CDC源保留原始的_id結構,不進行任何額外處理。這種模式為用戶提供了使用MongoDB提供的原始_id格式的靈活性,保留了任何嵌套元素,如$oid。兩者之間的選擇取決于用戶的偏好:前者用于更簡潔、簡化的_id,后者用于直接表示MongoDB的_id結構。
| 操作符 | 描述 |
|---|---|
|
| 查詢的根元素。所有路徑表達式由此開始。 |
|
| 由過濾謂詞處理的當前節點。 |
|
| 通配符。可用于任何需要名稱或數字的地方。 |
|
| 深度掃描。可用于任何需要名稱的地方。 |
|
| 點表示法的子節點。 |
|
| 方括號表示法的一個或多個子節點。 |
|
| 方括號表示法的一個或多個子節點。 |
|
| 數組索引或索引范圍。 |
|
| 過濾表達式。表達式必須計算為布爾值。 |
函數可以在路徑末尾調用-函數的輸入是路徑表達式的輸出。函數輸出由函數本身決定。
| 函數 | 描述 | 輸出類型 |
|---|---|---|
|
| 提供數字數組的最小值。 | Double |
|
| 提供數字數組的最大值。 | Double |
|
| 提供數字數組的平均值。 | Double |
|
| 提供數字數組的標準偏差值 | Double |
|
| 提供數組的長度 | Integer |
|
| 提供數字數組的總和值。 | Double |
|
| 提供屬性鍵(終端波浪號 | Set |
|
| 提供路徑輸出與新項的連接版本。 | like input |
|
| 向json路徑輸出數組添加一個項 | like input |
|
| 向json路徑輸出數組添加一個項 | like input |
|
| 提供數組的第一項 | Depends on the array |
|
| 提供數組的最后一項 | Depends on the array |
|
| 提供數組中索引為 | Depends on the array |
路徑示例
{"store": {"book": [{"category": "reference","author": "Nigel Rees","title": "Sayings of the Century","price": 8.95},{"category": "fiction","author": "Evelyn Waugh","title": "Sword of Honour","price": 12.99},{"category": "fiction","author": "Herman Melville","title": "Moby Dick","isbn": "0-553-21311-3","price": 8.99},{"category": "fiction","author": "J. R. R. Tolkien","title": "The Lord of the Rings","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"color": "red","price": 19.95}},"expensive": 10
}| JsonPath | 結果 |
|---|---|
|
| 提供數字數組的最小值。(此處描述疑似有誤,應為獲取 |
|
| 所有作者。 |
|
| 所有事物,包括書籍和自行車。 |
|
| 提供數字數組的標準偏差值。(此處描述疑似有誤,應為獲取 |
|
| 第三本書。 |
|
| 倒數第二本書。 |
|
| 前兩本書。 |
|
| 從索引0(包含)到索引2(不包含)的所有書籍。 |
|
| 從索引1(包含)到索引2(不包含)的所有書籍 |
|
| 最后兩本書 |
|
| 從索引2(包含)到最后的所有書籍 |
|
| 所有有ISBN編號的書籍 |
|
| 商店中所有價格低于10的書籍 |
|
| 商店中所有價格不“昂貴”的書籍 |
|
| 所有匹配正則表達式(忽略大小寫)的書籍 |
|
| 獲取所有內容 |
|
| 書籍的數量 |
- 同步表需要將其主鍵設置為
_id。這是因為MongoDB的變更事件在消息中是在更新之前記錄的。因此,我們只能將它們轉換為Flink的UPSERT變更日志流。而UPSERT流需要一個唯一鍵,這就是為什么我們必須將_id聲明為主鍵。將其他列聲明為主鍵是不可行的,因為刪除操作僅包含_id和分片鍵,不包括其他鍵值對。 - MongoDB變更流旨在返回簡單的JSON文檔,不包含任何數據類型定義。這是因為MongoDB是一個面向文檔的數據庫,其核心特性之一是動態模式,文檔可以包含不同的字段,并且字段的數據類型可以是靈活的。因此,變更流中不存在數據類型定義是為了保持這種靈活性和可擴展性。出于這個原因,我們將從MongoDB同步到Paimon的所有字段數據類型都設置為字符串,以解決無法獲取數據類型的問題。
如果指定的Paimon表不存在,此操作將自動創建該表。其模式將從MongoDB集合派生而來。
示例1:將集合同步到一個Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--computed_column '_year=year(age)' \--mongodb_conf hosts=127.0.0.1:27017 \--mongodb_conf username=root \--mongodb_conf password=123456 \--mongodb_conf database=source_db \--mongodb_conf collection=source_table1 \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4示例2:根據指定的字段映射將集合同步到Paimon表
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--mongodb_conf hosts=127.0.0.1:27017 \--mongodb_conf username=root \--mongodb_conf password=123456 \--mongodb_conf database=source_db \--mongodb_conf collection=source_table1 \--mongodb_conf schema.start.mode=specified \--mongodb_conf field.name=_id,name,description \--mongodb_conf parser.path=$._id,$.name,$.description \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4同步數據庫
通過在Flink DataStream作業中使用MongoDBSyncDatabaseAction,或直接通過flink run,用戶可以將整個MongoDB數據庫同步到一個Paimon數據庫。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_database--warehouse <warehouse-path> \--database <database-name> \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <mongodb-table-name|name-regular-expr>] \[--excluding_tables <mongodb-table-name|name-regular-expr>] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--mongodb_conf <mongodb-cdc-source-conf> [--mongodb_conf <mongodb-cdc-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --table_prefix | 要同步的所有Paimon表的前綴。例如,如果你希望所有同步的表都有“ods_”作為前綴,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后綴。用法與“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必須使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法與“--including_tables”相同。如果同時指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的優先級。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。如果這些鍵不在源表中,接收器表將不設置分區鍵。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。如果這些鍵不在源表中,但源表有主鍵,接收器表將使用源表的主鍵。否則,接收器表將不設置主鍵。 |
| --mongodb_conf | Flink CDC MongoDB源的配置。每個配置應采用“key = value”的格式指定。hosts、username、password、database是必需的配置,其他是可選的。有關完整的配置列表,請參閱其文檔。 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
所有要同步的集合都需要將_id設置為主鍵。對于每個要同步的MongoDB集合,如果相應的Paimon表不存在,此操作將自動創建該表。其模式將從所有指定的MongoDB集合派生而來。如果Paimon表已存在,將把它的模式與所有指定的MongoDB集合的模式進行比較。任務開始后創建的任何MongoDB表將自動包含在內。
示例1:同步整個數據庫
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \mongodb_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--mongodb_conf hosts=127.0.0.1:27017 \--mongodb_conf username=root \--mongodb_conf password=123456 \--mongodb_conf database=source_db \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4示例2:同步指定的表
<FLINK_HOME>/bin/flink run \
--fromSavepoint savepointPath \
/path/to/paimon-flink-action-0.9.0.jar \
mongodb_sync_database \
--warehouse hdfs:///path/to/warehouse \
--database test_db \
--mongodb_conf hosts=127.0.0.1:27017 \
--mongodb_conf username=root \
--mongodb_conf password=123456 \
--mongodb_conf database=source_db \
--catalog_conf metastore=hive \
--catalog_conf uri=thrift://hive-metastore:9083 \
--table_conf bucket=4 \
--including_tables 'product|user|address|order|custom'拓展:
MongoDB:是一款流行的開源文檔型數據庫,以其高可擴展性、靈活的數據模型和出色的性能在大數據和Web應用開發中廣泛應用。與傳統的關系型數據庫不同,MongoDB使用BSON(Binary JSON)格式來存儲數據,這使得它非常適合存儲半結構化或非結構化數據。例如,在內容管理系統中,MongoDB可以輕松存儲和管理各種格式的文章、圖片和多媒體文件的相關信息。
Flink SQL連接器 for MongoDB CDC:
flink-sql-connector-mongodb-cdc-*.jar是Flink用于連接MongoDB并捕獲變更數據的組件。它基于MongoDB的變更流功能,能夠實時監聽數據庫的變化,并將這些變更數據傳遞給Flink進行處理,實現數據從MongoDB到Paimon等存儲系統的同步。MongoDB變更流(Change Streams):這是MongoDB提供的一項功能,允許應用程序實時響應數據庫中的數據更改。變更流會返回描述數據庫操作(如插入、更新、刪除)的文檔,應用程序可以訂閱這些變更并進行相應處理。在數據集成場景中,變更流為捕獲MongoDB數據的實時變化提供了高效的途徑。
JSON路徑(JsonPath):是一種用于在JSON文檔中定位特定元素的表達式語言。在處理MongoDB數據時,JsonPath非常有用,因為MongoDB以文檔形式存儲數據,結構類似于JSON。通過JsonPath,可以方便地從復雜的文檔結構中提取所需的數據字段,例如在配置
parser.path時使用JsonPath來指定字段的解析路徑。UPSERT變更日志流:在Flink中,UPSERT流結合了插入(INSERT)和更新(UPDATE)操作,用于處理數據的變化。對于MongoDB的變更數據,由于其記錄方式,轉換為Flink的UPSERT變更日志流可以有效地處理數據的更新和插入操作,確保數據的一致性。而設置唯一的主鍵(如
_id)對于UPSERT流的正確處理至關重要。
Pulsar變更數據捕獲(CDC)
準備Pulsar捆綁包JAR
flink-connector-pulsar-*.jar
支持的格式
Flink提供了幾種PulsarCDC格式:Canal Json、Debezium Json、Debezium Avro、Ogg Json、Maxwell Json和普通Json。如果Pulsar主題中的消息是使用變更數據捕獲(CDC)工具從其他數據庫捕獲的變更事件,那么你可以使用PaimonPulsarCDC,將解析后的INSERT、UPDATE、DELETE消息寫入Paimon表。
| 格式 | 是否支持 |
|---|---|
| Canal CDC | True |
| Debezium CDC | True |
| Maxwell CDC | True |
| OGG CDC | True |
| JSON | True |
JSON源可能缺少一些信息。例如,Ogg和Maxwell格式標準不包含字段類型;當你將JSON源寫入FlinkPulsar接收器時,它將只保留數據和行類型,而丟棄其他信息。同步作業將盡力按如下方式處理該問題:
- 如果缺少字段類型,Paimon將默認使用“STRING”類型。
- 如果缺少數據庫名或表名,你無法進行數據庫同步,但仍可以進行表同步。
- 如果缺少主鍵,作業可能會創建無主鍵表。你可以在提交表同步作業時設置主鍵。
同步表
通過在Flink DataStream作業中使用PulsarSyncTableAction,或直接通過flink run,用戶可以將Pulsar一個主題中的一個或多個表同步到一個Paimon表中。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_table--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--type_mapping to-string] \[--computed_column <'column-name=expr-name(args[, ...])'> [--computed_column ...]] \[--pulsar_conf <pulsar-source-conf> [--pulsar_conf <pulsar-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --table | Paimon表名。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。 |
| --type_mapping | 用于指定如何將MySQL數據類型映射到Paimon類型。 支持的選項: “tinyint1-not-bool”:將MySQL的TINYINT(1)映射為TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空約束(主鍵除外)。這用于解決Flink無法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的問題。 “to-string”:將所有MySQL類型映射為STRING。 “char-to-string”:將MySQL的CHAR(length)/VARCHAR(length)類型映射為STRING。 “longtext-to-bytes”:將MySQL的LONGTEXT類型映射為BYTES。 “bigint-unsigned-to-bigint”:將MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射為BIGINT。使用此選項時應確保不會發生溢出。 |
| --computed_column | 計算列的定義。參數字段來自Pulsar主題的表字段名。有關完整的配置列表,請參閱此處。 |
| --pulsar_conf | FlinkPulsar源的配置。每個配置應采用 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
如果指定的Paimon表不存在,此操作將自動創建該表。其模式將從所有指定的Pulsar主題的表派生而來,它從主題中獲取最早的非DDL數據解析模式。如果Paimon表已存在,將把它的模式與所有指定的Pulsar主題的表的模式進行比較。
示例1:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--primary_keys pt,uid \--computed_column '_year=year(age)' \--pulsar_conf topic=order \--pulsar_conf value.format=canal-json \--pulsar_conf pulsar.client.serviceUrl=pulsar://127.0.0.1:6650 \--pulsar_conf pulsar.admin.adminUrl=http://127.0.0.1:8080 \--pulsar_conf pulsar.consumer.subscriptionName=paimon-tests \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4如果在啟動同步作業時Pulsar主題不包含消息,則必須在提交作業前手動創建表。你可以僅定義分區鍵和主鍵,其余列將由同步作業添加。
注意:在這種情況下,你不應使用–partition_keys或–primary_keys,因為這些鍵在創建表時已定義且無法修改。此外,如果你指定了計算列,還應定義計算列使用的所有參數字段。
示例2:如果你想同步一個主鍵為id INT的表,并且想計算一個分區鍵part = date_format(create_time,yyyy-MM-dd),你可以先創建這樣一個表(其他列可以省略):
CREATE TABLE test_db.test_table (id INT, -- primary keycreate_time TIMESTAMP, -- the argument of computed column partpart STRING, -- partition keyPRIMARY KEY (id, part) NOT ENFORCED
) PARTITIONED BY (part);然后你可以提交同步作業:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--computed_column 'part=date_format(create_time,yyyy-MM-dd)' \... (other conf)示例3:對于一些追加數據(如日志數據),它可以被視為僅包含INSERT操作類型的特殊CDC數據,因此你可以使用format = json將此類數據同步到Paimon表。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \kafka_sync_table \--warehouse hdfs:///path/to/warehouse \--database test_db \--table test_table \--partition_keys pt \--computed_column 'pt=date_format(event_tm, yyyyMMdd)' \--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \--kafka_conf topic=test_log \--kafka_conf properties.group.id=123456 \--kafka_conf value.format=json \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf sink.parallelism=4(此處示例3開頭kafka_sync_table疑似錯誤,應為pulsar_sync_table)
同步數據庫
通過在Flink DataStream作業中使用PulsarSyncDatabaseAction,或直接通過flink run,用戶可以將多個主題或一個主題同步到一個Paimon數據庫。
要通過flink run使用此功能,運行以下Shell命令:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_database--warehouse <warehouse-path> \--database <database-name> \[--table_prefix <paimon-table-prefix>] \[--table_suffix <paimon-table-suffix>] \[--including_tables <table-name|name-regular-expr>] \[--excluding_tables <table-name|name-regular-expr>] \[--type_mapping to-string] \[--partition_keys <partition_keys>] \[--primary_keys <primary-keys>] \[--pulsar_conf <pulsar-source-conf> [--pulsar_conf <pulsar-source-conf> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-sink-conf> [--table_conf <paimon-table-sink-conf> ...]]| 配置 | 描述 |
|---|---|
| --warehouse | Paimon倉庫的路徑。 |
| --database | Paimon目錄中的數據庫名稱。 |
| --ignore_incompatible | 默認值為false,在這種情況下,如果MySQL表名在Paimon中存在且它們的模式不兼容,將拋出異常。你可以顯式地將其指定為true以忽略不兼容的表和異常。 |
| --table_prefix | 要同步的所有Paimon表的前綴。例如,如果你希望所有同步的表都有“ods_”作為前綴,你可以指定“--table_prefix ods_”。 |
| --table_suffix | 要同步的所有Paimon表的后綴。用法與“--table_prefix”相同。 |
| --including_tables | 用于指定要同步哪些源表。必須使用' |
| --excluding_tables | 用于指定不同步哪些源表。用法與“--including_tables”相同。如果同時指定了“--excluding_tables”和“--including_tables”,“--excluding_tables”具有更高的優先級。 |
| --type_mapping | 用于指定如何將MySQL數據類型映射到Paimon類型。 支持的選項: “tinyint1-not-bool”:將MySQL的TINYINT(1)映射為TINYINT而不是BOOLEAN。 “to-nullable”:忽略所有非空約束(主鍵除外)。這用于解決Flink無法接受MySQL的“ALTER TABLE ADD COLUMN column type NOT NULL DEFAULT x”操作的問題。 “to-string”:將所有MySQL類型映射為STRING。 “char-to-string”:將MySQL的CHAR(length)/VARCHAR(length)類型映射為STRING。 “longtext-to-bytes”:將MySQL的LONGTEXT類型映射為BYTES。 “bigint-unsigned-to-bigint”:將MySQL的BIGINT UNSIGNED、BIGINT UNSIGNED ZEROFILL、SERIAL映射為BIGINT。使用此選項時應確保不會發生溢出。 |
| --partition_keys | Paimon表的分區鍵。如果有多個分區鍵,用逗號連接,例如“dt,hh,mm”。如果這些鍵不在源表中,接收器表將不設置分區鍵。 |
| --primary_keys | Paimon表的主鍵。如果有多個主鍵,用逗號連接,例如“buyer_id,seller_id”。如果這些鍵不在源表中,但源表有主鍵,接收器表將使用源表的主鍵。否則,接收器表將不設置主鍵。 |
| --pulsar_conf | FlinkPulsar源的配置。每個配置應采用 |
| --catalog_conf | Paimon目錄的配置。每個配置應采用“key = value”的格式指定。有關目錄配置的完整列表,請參閱此處。 |
| --table_conf | Paimon表接收器的配置。每個配置應采用“key = value”的格式指定。有關表配置的完整列表,請參閱此處。 |
只有具有主鍵的表才會被同步。
此操作將為所有表構建一個單一的組合接收器。對于每個要同步的Pulsar主題的表,如果相應的Paimon表不存在,此操作將自動創建該表,并且其模式將從所有指定的Pulsar主題的表派生而來。如果Paimon表已存在且其模式與從Pulsar記錄解析的模式不同,此操作將嘗試進行模式演進。
示例:
-
從一個Pulsar主題同步到Paimon數據庫:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--pulsar_conf topic=order \--pulsar_conf value.format=canal-json \--pulsar_conf pulsar.client.serviceUrl=pulsar://127.0.0.1:6650 \--pulsar_conf pulsar.admin.adminUrl=http://127.0.0.1:8080 \--pulsar_conf pulsar.consumer.subscriptionName=paimon-tests \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4-
從多個Pulsar主題同步到Paimon數據庫:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \pulsar_sync_database \--warehouse hdfs:///path/to/warehouse \--database test_db \--pulsar_conf topic=order,logistic_order,user \--pulsar_conf value.format=canal-json \--pulsar_conf pulsar.client.serviceUrl=pulsar://127.0.0.1:6650 \--pulsar_conf pulsar.admin.adminUrl=http://127.0.0.1:8080 \--pulsar_conf pulsar.consumer.subscriptionName=paimon-tests \--catalog_conf metastore=hive \--catalog_conf uri=thrift://hive-metastore:9083 \--table_conf bucket=4 \--table_conf changelog-producer=input \--table_conf sink.parallelism=4額外的Pulsar配置
有一些用于構建FlinkPulsar源的有用選項,但它們未在flink-pulsar-connector文檔中提供。它們是:
| 鍵 | 默認值 | 類型 | 描述 |
|---|---|---|---|
| value.format | (none) | String | 定義用于編碼值數據的格式標識符。 |
| topic | (none) | String | 從中讀取數據的主題名稱。它也支持通過分號分隔主題列表,如'topic-1;topic-2'。注意,“topic-pattern”和“topic”只能指定一個。 |
| topic-pattern | (none) | String | 要讀取的主題名稱模式的正則表達式。當作業開始運行時,所有名稱與指定正則表達式匹配的主題都將被消費者訂閱。注意,“topic-pattern”和“topic”只能指定一個。 |
| pulsar.startCursor.fromMessageId | EARLIEST | String | 使用單個消息的唯一標識符來定位起始位置。常見格式是三元組 'ledgerId,entryId,partitionIndex'。特別地,你可以將其設置為 EARLIEST (-1, -1, -1) 或 LATEST (Long.MAX_VALUE, Long.MAX_VALUE, -1)。 |
| pulsar.startCursor.fromPublishTime | (none) | Long | 使用消息發布時間來定位起始位置。 |
| pulsar.startCursor.fromMessageIdInclusive | true | Boolean | 是否包含給定的消息ID。此選項僅在消息ID不是EARLIEST或LATEST時有效。 |
| pulsar.stopCursor.atMessageId | (none) | String | 當消息ID等于或大于指定的消息ID時停止消費。等于指定消息ID的消息將不會被消費。常見格式是三元組 'ledgerId,entryId,partitionIndex'。特別地,你可以將其設置為LATEST (Long.MAX_VALUE, Long.MAX_VALUE, -1)。 |
| pulsar.stopCursor.afterMessageId | (none) | String | 當消息ID大于指定的消息ID時停止消費。等于指定消息ID的消息將被消費。常見格式是三元組 'ledgerId,entryId,partitionIndex'。特別地,你可以將其設置為LATEST (Long.MAX_VALUE, Long.MAX_VALUE, -1)。 |
| pulsar.stopCursor.atEventTime | (none) | Long | 當消息事件時間大于或等于指定的時間戳時停止消費。事件時間等于指定時間戳的消息將不會被消費。 |
| pulsar.stopCursor.afterEventTime | (none) | Long | 當消息事件時間大于指定的時間戳時停止消費。事件時間等于指定時間戳的消息將被消費。 |
| pulsar.source.unbounded | true | Boolean | 指定流的有界性。 |
| schema.registry.url | (none) | String | 當配置“value.format=debezium-avro”時,這需要使用Confluence模式注冊表模型進行Apache Avro序列化,你需要提供模式注冊表URL。 |
拓展:
Apache Pulsar:是一個開源的分布式消息流平臺,旨在為現代云原生應用程序提供高性能、低延遲和可擴展性的消息傳遞解決方案。與Kafka類似,Pulsar 也支持發布-訂閱模型,但它在架構設計上有一些獨特之處,例如采用分層存儲架構,將消息存儲和元數據管理分離,這使得 Pulsar 在處理大規模數據和高并發場景時表現出色。常用于構建實時數據管道、微服務之間的異步通信以及事件驅動的應用程序等。
Flink-Pulsar 連接器:
flink-connector-pulsar-*.jar?是 Apache Flink 與 Apache Pulsar 集成的關鍵組件。它允許 Flink 作業從 Pulsar 主題中讀取數據,并將處理后的數據寫回到 Pulsar 主題,從而實現數據在 Flink 和 Pulsar 之間的高效交互。在 CDC 場景下,該連接器負責從 Pulsar 獲取包含變更數據的消息,并將其傳遞給 Flink 進行處理,例如解析消息并同步到 Paimon 表。CDC 格式在 Pulsar 中的應用:Canal Json、Debezium Json 等格式在 Pulsar 的 CDC 場景中用于編碼和傳輸數據庫的變更數據。這些格式各自有其特點和適用場景,例如 Debezium Json 通常會包含豐富的元數據信息,方便在數據處理過程中理解數據的結構和變化,而 Canal Json 則在與基于 Canal 的數據捕獲系統集成時具有良好的兼容性。
Pulsar 配置參數的作用: -
pulsar.client.serviceUrl?和?pulsar.admin.adminUrl?分別指定了 Pulsar 客戶端連接服務的 URL 和管理接口的 URL,它們是 Flink 與 Pulsar 建立連接的重要配置。 -pulsar.consumer.subscriptionName?定義了消費者訂閱的名稱,通過設置不同的訂閱名稱,可以實現不同的消費策略,例如獨占消費、共享消費等。 -與消息起始和停止位置相關的配置參數,如?pulsar.startCursor.fromMessageId、pulsar.stopCursor.atMessageId?等,為用戶提供了精確控制消息消費范圍的能力。這在數據恢復、數據重放以及處理特定時間段內的數據等場景中非常有用。
過期分區(Expiring Partitions)
在創建分區表時,你可以設置partition.expiration-time。Paimon 流接收器會定期檢查分區狀態,并根據時間刪除過期分區。
如何確定一個分區是否過期:在創建分區表時,你可以設置partition.expiration-strategy,該策略決定了如何提取分區時間,并將其與當前時間進行比較,以查看存活時間是否超過partition.expiration-time。支持的過期策略值有:
-
values-time:該策略將從分區值中提取的時間與當前時間進行比較,此為默認策略。 -
update-time:該策略將分區的最后更新時間與當前時間進行比較。此策略適用于以下場景: -你的分區值不是日期格式。 -你只想保留最近 n 天/月/年更新過的數據。 -數據初始化時導入了大量歷史數據。
注意:分區過期后,會被邏輯刪除,最新的快照無法查詢其數據。但文件系統中的文件不會立即被物理刪除,這取決于相應快照何時過期。請參閱“過期快照”。
單分區字段示例:
-
values-time策略:
CREATE TABLE t (...) PARTITIONED BY (dt) WITH ('partition.expiration-time' = '7 d','partition.expiration-check-interval' = '1 d','partition.timestamp-formatter' = 'yyyyMMdd' -- this is required in `values-time` strategy.
);
-- Let's say now the date is 2024-07-09,so before the date of 2024-07-02 will expire.
insert into t values('pk', '2024-07-01');-- An example for multiple partition fields
CREATE TABLE t (...) PARTITIONED BY (other_key, dt) WITH ('partition.expiration-time' = '7 d','partition.expiration-check-interval' = '1 d','partition.timestamp-formatter' = 'yyyyMMdd','partition.timestamp-pattern' = '$dt'
);-
update-time策略:
CREATE TABLE t (...) PARTITIONED BY (dt) WITH ('partition.expiration-time' = '7 d','partition.expiration-check-interval' = '1 d','partition.expiration-strategy' = 'update-time'
);-- The last update time of the partition is now, so it will not expire.
insert into t values('pk', '2024-01-01');
-- Support non-date formatted partition.
insert into t values('pk', 'par-1');
更多選項:
| 選項 | 默認值 | 類型 | 描述 |
|---|---|---|---|
|
|
| String | 指定分區過期的過期策略。可能的值有: |
|
|
| Duration | 分區過期的檢查間隔。 |
|
| (none) | Duration | 分區的過期間隔。如果分區的存在時間超過此值,該分區將過期。分區時間從分區值中提取。 |
|
| (none) | String | 用于將字符串格式化為時間戳的格式化器。它可以與 |
|
| (none) | String | 你可以指定一個模式從分區中獲取時間戳。格式化模式由 |
|
|
| Boolean | 在批處理模式或有界流作業完成后,是否檢查分區過期。 |
拓展:
分區過期機制在大數據存儲中的意義:在大數據處理場景中,數據量通常會隨著時間不斷增長。通過設置分區過期機制,可以自動清理不再需要的歷史數據分區,從而有效控制存儲成本,同時提升查詢性能。例如,在日志數據存儲中,老的日志分區可能不再被頻繁查詢,將其過期刪除可以減少存儲資源占用。
values-time策略實現原理:values-time策略依賴于從分區值中提取時間信息。這要求分區值必須以某種可解析的時間格式存儲,通過partition.timestamp-formatter和partition.timestamp-pattern配合,將分區值解析為時間戳,再與當前時間比較以判斷分區是否過期。這種策略適用于分區值天然帶有時間屬性且以時間為維度進行過期管理的場景,如按日期分區的銷售數據。
update-time策略應用場景拓展:除了上述提到的場景,update-time策略在數據倉庫環境中也很有用。例如,某些維度表的數據更新頻率較低,但數據量較大。通過update-time策略,只保留最近更新的分區,可以確保數據倉庫中的維度數據是最新且有效的,避免查詢到陳舊數據。同時,在數據導入大量歷史數據后,使用該策略可以逐步清理未更新的舊數據分區,優化存儲結構。
partition.expiration-check-interval對系統性能的影響:該參數決定了檢查分區過期的頻率。如果設置過短,系統會頻繁進行過期檢查,增加系統開銷;若設置過長,可能導致過期分區不能及時被清理,占用過多存儲資源。因此,需要根據數據的更新頻率和存儲資源情況,合理調整該參數,以平衡系統性能和存儲成本。
存儲過程(Procedures)
Flink 1.18及更高版本支持調用語句(Call Statements),這使得通過編寫SQL而不是提交Flink作業來操作Paimon表的數據和元數據變得更加容易。
在1.18版本中,存儲過程僅支持按位置傳遞參數。你必須按順序傳遞所有參數,如果你不想傳遞某些參數,必須使用空字符串 '' 作為占位符。例如,如果你想以并行度4壓縮表default.t,但不想指定分區和排序策略,調用語句應該是:?CALL sys.compact('default.t', '', '', '', 'sink.parallelism=4')
在更高版本中,存儲過程支持按名稱傳遞參數。你可以按任意順序傳遞參數,并且可以省略任何可選參數。對于上述示例,調用語句為:?CALL sys.compact(table?=> 'default.t', options => 'sink.parallelism=4')
指定分區:我們使用字符串來表示分區過濾器。“,” 表示 “AND”,“;” 表示 “OR”。例如,如果你想指定兩個分區date = 01和date = 02,你需要寫'date = 01;date = 02';如果你想指定一個分區date = 01且day = 01,你需要寫'date = 01,day = 01'。
表選項語法:我們使用字符串來表示表選項。格式為 'key1 = value1,key2 = value2…'。
以下是所有可用的存儲過程列表:
| 存儲過程名稱 | 用法 | 解釋 | 示例 |
|---|---|---|---|
| compact |
| 用于壓縮表。參數: | -- 使用分區過濾器 |
| compact_database |
| 用于壓縮數據庫。參數: | `CALL sys.compact_database('db1 |
| create_tag | -- 基于指定的快照 | 基于給定的快照創建一個標簽。參數: |
|
| create_tag_from_timestamp | -- 從提交時間大于指定時間戳的第一個快照創建一個標簽。 | 基于給定的時間戳創建一個標簽。參數: | -- 對于Flink 1.18 |
| create_tag_from_watermark | -- 從水印大于指定時間戳的第一個快照創建一個標簽。 | 基于給定的水印時間戳創建一個標簽。參數: | -- 對于Flink 1.18 |
| delete_tag |
| 刪除一個標簽。參數: |
|
| merge_into |
| 執行 “MERGE INTO” 語法。有關參數的詳細信息,請參閱merge_into操作。 | -- 對于匹配的訂單行, -- 增加價格, -- 如果沒有匹配項, -- 從源表插入訂單 |
| remove_orphan_files |
| 刪除孤立的數據文件和元數據文件。參數: |
|
| reset_consumer | -- 在消費者中重置新的下一個快照ID | 重置或刪除消費者。參數: |
|
| rollback_to | -- 回滾到一個快照 | 回滾到目標表的特定版本。參數: |
|
| expire_snapshots | -- 對于Flink 1.18 | 過期快照。參數: | -- 對于Flink 1.18 |
| expire_partitions |
| 過期分區。參數: | -- 對于Flink 1.18 |
| repair | -- 修復目錄中的所有數據庫和表 | 將文件系統中的信息同步到元存儲。參數: 空:目錄中的所有數據庫和表。 |
|
| rewrite_file_index |
| 重寫表的文件索引。參數: | -- 重寫整個表的文件索引 |
| create_branch | -- 基于指定的標簽 | 基于給定的標簽創建一個分支,或者僅創建空分支。參數: |
|
| delete_branch |
| 刪除一個分支。參數: |
|
| fast_forward |
| 將一個分支快速合并到主分支。參數: |
|
拓展:
Flink Call Statements:Flink從1.18版本引入對Call Statements的支持,這極大地增強了Flink SQL的功能。通過存儲過程,用戶可以直接在SQL層面完成復雜的數據和元數據操作,無需編寫復雜的Java或Scala代碼來提交Flink作業。這使得數據工程師和分析師能夠更便捷地與Paimon表進行交互,提升了工作效率。例如,在數據倉庫場景中,定期壓縮表(compact操作)以優化存儲和查詢性能,可以通過簡單的SQL調用實現,而無需重新部署Flink作業。
表壓縮(compact):表壓縮是提升Paimon表性能的重要操作。通過
compact存儲過程,可以對表數據進行整理和優化。不同的排序策略(order_strategy)如zorder、hilbert等,能夠以特定方式對數據進行排序,從而在查詢時提高數據掃描效率。例如,在分析按時間序列存儲的數據時,使用zorder策略對時間列進行排序,可以使查詢特定時間范圍的數據更加高效。此外,通過指定分區進行壓縮,能夠針對性地處理特定分區的數據,減少不必要的計算資源消耗。標簽(tag)和分支(branch)管理:標簽和分支是Paimon中版本控制和數據管理的重要手段。標簽允許用戶為特定的快照(snapshot)命名,方便快速定位和回滾到某個特定版本的數據狀態。而分支則提供了一種并行的數據演進路徑,例如在進行數據實驗或開發新功能時,可以基于某個標簽創建分支,在分支上進行操作而不影響主數據分支。通過
create_tag、delete_tag、create_branch和delete_branch等存儲過程,用戶能夠靈活地管理標簽和分支,確保數據的可追溯性和開發過程的靈活性。MERGE INTO操作:
merge_into存儲過程實現了SQL中強大的MERGE INTO語法。這在數據集成和ETL(Extract,Transform,Load)過程中非常有用,例如將源表數據根據特定條件合并到目標表中。它可以同時處理匹配行的更新(matchedUpsertCondition)和不匹配行的插入(notMatchedInsertCondition),避免了傳統方式中需要分別編寫插入和更新語句的繁瑣過程,提高了數據處理的原子性和效率。孤兒文件清理(remove_orphan_files):在數據處理過程中,由于各種原因(如任務失敗、數據遷移等)可能會產生孤兒文件,即不再被表元數據引用的數據文件或元數據文件。這些文件不僅占用存儲資源,還可能導致數據不一致。
remove_orphan_files存儲過程提供了一種清理這些孤兒文件的機制。通過設置olderThan參數,可以控制只刪除特定時間之前產生的孤兒文件,避免誤刪新生成的文件。而dryRun參數則提供了一種預覽模式,方便用戶在實際刪除文件之前查看哪些文件將被刪除。分區和快照管理:
expire_partitions和expire_snapshots存儲過程分別用于管理分區和快照的過期。在大數據存儲中,隨著時間推移,舊的分區和快照可能不再需要,通過設置合適的過期策略,可以自動清理這些不再使用的數據,釋放存儲資源。例如,對于按時間分區的表,通過expire_partitions設置過期時間,可以定期刪除舊的時間分區。而expire_snapshots則可以根據保留的最大或最小快照數量,以及時間條件,刪除不再需要的快照版本。
動作JAR(Action Jars)
在啟動Flink本地集群后,你可以使用以下命令執行動作JAR。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \<action><args>以下命令用于壓縮表。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \compact \--path <TABLE_PATH>合并到表
Paimon支持通過flink run提交merge_into作業來實現“MERGE INTO”。
重要的表屬性設置:
- 只有主鍵表支持此功能。
- 此動作不會生成UPDATE_BEFORE,因此不建議設置
'changelog-producer' = 'input'。
該設計參考了如下語法:
MERGE INTO target-tableUSING source_table | source-expr AS source-aliasON merge-conditionWHEN MATCHED [AND matched-condition]THEN UPDATE SET xxxWHEN MATCHED [AND matched-condition]THEN DELETEWHEN NOT MATCHED [AND not_matched_condition]THEN INSERT VALUES (xxx)WHEN NOT MATCHED BY SOURCE [AND not-matched-by-source-condition]THEN UPDATE SET xxxWHEN NOT MATCHED BY SOURCE [AND not-matched-by-source-condition]THEN DELETEmerge_into動作使用“upsert”語義而非“update”,這意味著如果行存在,則執行更新;否則執行插入。例如,對于非主鍵表,你可以更新每一列,但對于主鍵表,如果你想更新主鍵,則必須插入一個主鍵與表中現有行不同的新行。在這種情況下,“upsert”很有用。
運行以下命令為表提交一個merge_into作業。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table <target-table> \[--target_as <target-table-alias>] \--source_table <source_table-name> \[--source_sql <sql> ...]\--on <merge-condition> \--merge_actions <matched-upsert,matched-delete,not-matched-insert,not-matched-by-source-upsert,not-matched-by-source-delete> \--matched_upsert_condition <matched-condition> \--matched_upsert_set <upsert-changes> \--matched_delete_condition <matched-condition> \--not_matched_insert_condition <not-matched-condition> \--not_matched_insert_values <insert-values> \--not_matched_by_source_upsert_condition <not-matched-by-source-condition> \--not_matched_by_source_upsert_set <not-matched-upsert-changes> \--not_matched_by_source_delete_condition <not-matched-by-source-condition> \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]You can pass sqls by '--source_sql <sql> [, --source_sql <sql> ...]' to config environment and create source table at runtime.-- Examples:
-- Find all orders mentioned in the source table, then mark as important if the price is above 100
-- or delete if the price is under 10.
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_table S \--on "T.id = S.order_id" \--merge_actions \matched-upsert,matched-delete \--matched_upsert_condition "T.price > 100" \--matched_upsert_set "mark = 'important'" \--matched_delete_condition "T.price < 10" -- For matched order rows, increase the price, and if there is no match, insert the order from the
-- source table:
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_table S \--on "T.id = S.order_id" \--merge_actions \matched-upsert,not-matched-insert \--matched_upsert_set "price = T.price + 20" \--not_matched_insert_values * -- For not matched by source order rows (which are in the target table and does not match any row in the
-- source table based on the merge-condition), decrease the price or if the mark is 'trivial', delete them:
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_table S \--on "T.id = S.order_id" \--merge_actions \not-matched-by-source-upsert,not-matched-by-source-delete \--not_matched_by_source_upsert_condition "T.mark <> 'trivial'" \--not_matched_by_source_upsert_set "price = T.price - 20" \--not_matched_by_source_delete_condition "T.mark = 'trivial'"-- A --source_sql example:
-- Create a temporary view S in new catalog and use it as source table
./flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into \--warehouse <warehouse-path> \--database <database-name> \--table T \--source_sql "CREATE CATALOG test_cat WITH (...)" \--source_sql "CREATE TEMPORARY VIEW test_cat.`default`.S AS SELECT order_id, price, 'important' FROM important_order" \--source_table test_cat.default.S \--on "T.id = S.order_id" \--merge_actions not-matched-insert\--not_matched_insert_values *“matched”術語解釋:
- matched:更改的行來自目標表,并且每行都可以基于合并條件和可選的匹配條件與源表行匹配(源 ∩ 目標)。
- not matched:更改的行來自源表,并且基于合并條件和可選的不匹配條件,所有行都無法與目標表中的任何行匹配(源-目標)。
- not matched by source:更改的行來自目標表,并且基于合并條件和可選的源不匹配條件,所有行都無法與源表中的任何行匹配(目標-源)。
參數格式:
- matched_upsert_changes:
col = <source_table>.col | expression [, …](表示用給定值設置<target_table>.col。不要在col前添加<target_table>.)。特別地,你可以使用'*'用所有源列設置列(要求目標表的模式與源表相同)。 - not_matched_upsert_changes與
matched_upsert_changes類似,但你不能引用源表的列或使用'*'。 - insert_values:
col1, col2, …, col_end。必須指定所有列的值。對于每一列,你可以引用<source_table>.col或使用表達式。特別地,你可以使用'*'用所有源列插入(要求目標表的模式與源表相同)。 - not_matched_condition不能使用目標表的列來構造條件表達式。
- not_matched_by_source_condition不能使用源表的列來構造條件表達式。
1.目標別名不能與已存在的表名重復。
2.如果源表不在當前目錄和當前數據庫中,則源表名必須是限定的(如果創建了新目錄,則為 database.table 或 catalog.database.table)。例如:
(1) 如果源表 “my_source” 在 “my_db” 中,對其進行限定:
--source_table “my_db.my_source”
(2) SQL 示例:
當 SQL 語句更改了當前目錄和數據庫時,源表名無需限定:
--source_sql “CREATE CATALOG my_cat WITH (…)"
--source_sql “USE CATALOG my_cat”
--source_sql “CREATE DATABASE my_db”
--source_sql “USE my_db”
--source_sql “CREATE TABLE S …"
--source_table S
但在以下情況下必須對其進行限定:
--source_sql “CREATE CATALOG my_cat WITH (…)"
--source_sql “CREATE TABLE my_cat.default.S …"
--source_table my_cat.default.S
在以下參數中,你可以僅使用 “S” 作為源表名。
3.必須至少指定一個合并操作。
4.如果同時存在匹配時插入(matched-upsert)和匹配時刪除(matched-delete)操作,它們的條件也都必須存在(對于不匹配源時插入(not-matched-by-source-upsert)和不匹配源時刪除(not-matched-by-source-delete)也是如此)。否則,所有條件都是可選的。
5.所有條件、設置更改和值都應使用 Flink SQL 語法。為確保整個命令在 Shell 中正常運行,請用雙引號將它們引起來以轉義空格,并使用反斜杠 “\” 轉義語句中的特殊字符。例如:
--source_sql “CREATE TABLE T (k INT) WITH (‘special-key’ = ‘123!')”
有關merge_into的更多信息,請查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \merge_into --help從表中刪除
在Flink 1.16及更早版本中,Paimon僅支持通過flink run提交delete作業來刪除記錄。
運行以下命令為表提交一個delete作業。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \delete \--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \--where <filter_spec> \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]filter_spec is equal to the 'WHERE' clause in SQL DELETE statement. Examples:age >= 18 AND age <= 60animal <> 'cat'id > (SELECT count(*) FROM employee)有關delete的更多信息,請查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \delete --help刪除分區
運行以下命令為表提交一個drop_partition作業。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \drop_partition \--warehouse <warehouse-path> \--database <database-name> \--table <table-name> \[--partition <partition_spec> [--partition <partition_spec> ...]] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]partition_spec:
key1=value1,key2=value2...有關drop_partition的更多信息,請查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \drop_partition --help重寫文件索引
運行以下命令為表提交一個rewrite_file_index作業。
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \rewrite_file_index \--warehouse <warehouse-path> \--identifier <database.table> \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]]有關rewrite_file_index的更多信息,請查看:
<FLINK_HOME>/bin/flink run \/path/to/paimon-flink-action-0.9.0.jar \rewrite_file_index --help拓展:
MERGE INTO操作在數據處理中的應用:MERGE INTO操作在數據集成場景中極為常見,例如將來自不同數據源的數據合并到數據倉庫的目標表中。通過Paimon的
merge_into作業,能夠實現復雜的業務邏輯,如根據業務規則對匹配和不匹配的數據進行不同處理。在電商數據處理中,將實時訂單數據與歷史訂單表進行合并時,可對已存在的訂單更新其狀態或金額等信息,對新訂單則插入到表中,確保數據的完整性和實時性。DELETE操作的優化考量:在大數據環境下,從表中刪除數據需要謹慎操作。通過
delete作業,用戶可以基于復雜的條件過濾來刪除數據。然而,在執行刪除操作時,需要考慮對系統性能和存儲的影響。例如,如果刪除的數據量較大,可能會導致存儲碎片,影響后續的查詢性能。因此,在實際應用中,可能需要結合數據的使用頻率、存儲策略等因素,合理安排刪除操作的時機和條件。DROP PARTITION操作與存儲管理:
drop_partition操作對于管理分區表的存儲非常重要。在數據按時間分區存儲的場景下,隨著時間推移,舊的分區數據可能不再需要,通過刪除這些分區,可以釋放大量的存儲資源。但在執行此操作時,要確保不會影響到依賴這些分區數據的業務流程,如某些歷史數據分析任務可能仍需要訪問舊分區數據。REWRITE FILE INDEX操作與查詢性能:
rewrite_file_index作業主要用于優化表的文件索引結構。文件索引對于查詢性能至關重要,當表數據發生大量的插入、刪除或更新操作后,文件索引可能變得碎片化或不準確,從而影響查詢效率。通過重寫文件索引,可以重新組織索引結構,提高查詢時的數據定位速度,進而提升整體查詢性能。
保存點(Savepoint)
Paimon有自己的快照管理機制,這可能會與Flink的檢查點管理產生沖突,導致從保存點恢復時出現異常(不過不用擔心,這不會造成存儲損壞)。
建議你使用以下方法進行保存點操作:
-
使用Flink的帶保存點停止(Stop with savepoint)功能。
-
將Paimon標簽與Flink保存點結合使用,并在從保存點恢復之前回滾到指定標簽。
帶保存點停止(Stop with savepoint)
Flink的此功能可確保最后一個檢查點得到完全處理,這意味著不會再有未提交的元數據殘留。這種方式非常安全,因此我們推薦使用此功能來停止和啟動作業。
保存點與標簽結合(Tag with Savepoint)
在Flink中,我們可能從Kafka消費數據,然后寫入Paimon。由于Flink的檢查點僅保留有限數量,我們會在特定時間(如代碼升級、數據更新等)觸發保存點,以確保狀態能夠保留更長時間,從而使作業可以增量恢復。
Paimon的快照與Flink的檢查點類似,兩者都會自動過期,但Paimon的標簽功能允許快照長時間保留。因此,我們可以結合Paimon的標簽和Flink的保存點這兩個功能,實現作業從指定保存點的增量恢復。
從Flink 1.15開始,中間保存點(除使用stop-with-savepoint創建的保存點之外的其他保存點)不用于恢復,并且不會提交任何副作用。
對于使用stop-with-savepoint創建的保存點,會自動創建標簽。對于其他保存點,將在下一個檢查點成功后創建標簽。
步驟1:啟用為保存點自動創建標簽功能
你可以將sink.savepoint.auto-tag設置為true,以啟用為保存點自動創建標簽的功能。
步驟2:觸發保存點
你可以參考flink savepoint?文檔,了解如何配置和觸發保存點。
步驟3:選擇與保存點對應的標簽
與保存點對應的標簽將以savepoint-${savepointID}的形式命名。你可以參考標簽表進行查詢。
步驟4:回滾Paimon表
將Paimon表回滾到指定標簽。
步驟5:從保存點重啟
你可以參考此處,了解如何從指定保存點重啟。
拓展:
Flink保存點與檢查點的區別:Flink的檢查點是一種定期進行的輕量級狀態備份,主要用于故障恢復,確保作業在發生故障時能夠從最近的檢查點恢復執行,減少數據丟失。而保存點是用戶手動觸發的一種特殊的檢查點,通常用于計劃內的作業暫停、遷移或升級等場景。保存點可以長時間保留,并且包含作業的完整狀態,包括所有算子的狀態和數據流的位置等信息。在大數據處理中,例如在進行集群升級時,使用保存點可以安全地停止作業,升級完成后從保存點恢復作業,保證數據處理的連續性。
Paimon快照與Flink檢查點沖突的原因:Paimon的快照管理和Flink的檢查點管理在數據一致性和狀態管理的實現機制上存在差異。Paimon的快照主要關注表數據的版本管理和元數據一致性,而Flink的檢查點更側重于作業執行狀態的恢復。當從保存點恢復時,Flink期望作業的狀態與保存點創建時完全一致,但Paimon的快照管理可能導致表的元數據狀態與Flink預期的不一致,從而引發異常。例如,Paimon可能在Flink保存點創建后對表結構或數據進行了一些內部調整,而Flink在恢復時未正確處理這些變化。
結合Paimon標簽與Flink保存點的優勢:通過結合Paimon的標簽和Flink的保存點,能夠實現更靈活和可靠的作業恢復策略。Paimon的標簽可以長期保留特定的快照版本,方便用戶在需要時準確回滾到某個特定的數據狀態。而Flink的保存點則提供了作業執行狀態的完整備份。在實際應用中,比如在進行數據處理邏輯更新時,先觸發Flink保存點并結合Paimon標簽記錄當前數據狀態,更新完成后,如果出現問題,可以通過回滾Paimon表到指定標簽,再從保存點重啟作業,確保作業恢復到更新前的準確狀態,同時避免了Paimon快照與Flink檢查點沖突帶來的問題。




場:鄭州輕工業大學)
API 接口實戰指南)






的用法說明)


之Wake-up Interrupt Controller (WIC))
:從零構建一個功能完備的Todo List應用)


