一、什么是 N-gram
????????核心定義:N-gram 是來自給定文本或語音序列的?N 個連續項(如單詞、字符)?的序列。它是一種通過查看一個項目的前后文來建模序列的概率模型。
N:?代表連續項的數量。
項(Item):?通常是單詞(Word),也可以是字符(Character)或音節。
????????核心思想:N-gram 模型基于一個簡化的假設:一個詞的出現概率只與它前面有限數量的詞有關。這被稱為馬爾可夫假設。
例如,在一個 Trigram(3-gram)模型中,一個詞的出現概率只由它前面的兩個詞決定,而不是整個句子的歷史。這極大地簡化了計算,使得處理大規模文本成為可能。
二、為什么需要 N-gram
????????在自然語言中,句子的概率是極其復雜的。要計算整個句子 P(“我今天學習N-gram”)?的聯合概率,理論上需要知道所有詞共同出現的概率,這在數據稀疏的現實世界中是不可能的。
????????N-gram 模型通過近似這個聯合概率來解決這個問題。它將一個長序列的概率分解為一系列更短、更易計算的概率的乘積。
三、N-gram 的類型與示例
假設我們有一個句子:“我喜歡吃蘋果”
Unigram (1-gram):
將文本視為獨立的單詞,不考慮任何上下文。
示例: [“我”], [“喜歡”], [“吃”], [“蘋果”]
特點: 丟失了所有詞序信息。
Bigram (2-gram):
每兩個連續的單詞作為一個單元。當前詞的概率只依賴于前一個詞。
示例: [“我”, “喜歡”], [“喜歡”, “吃”], [“吃”, “蘋果”]
公式: P(句子) ≈ P(我) * P(喜歡|我) * P(吃|喜歡) * P(蘋果|吃)
Trigram (3-gram):
每三個連續的單詞作為一個單元。當前詞的概率只依賴于前兩個詞。
示例: [“我”, “喜歡”, “吃”], [“喜歡”, “吃”, “蘋果”]
公式: P(句子) ≈ P(我) * P(喜歡|我) * P(吃|我,喜歡) * P(蘋果|喜歡,吃)
Four-gram (4-gram), Five-gram (5-gram)...
以此類推。N 越大,模型考慮的上下文就越長,理論上也越精確,但數據稀疏性問題也越嚴重。
示例:基于西雅圖酒店數據集分析
import?pandas?as?pd
from?sklearn.metrics.pairwise?import?linear_kernel
from?sklearn.feature_extraction.text?import?CountVectorizer
from?sklearn.feature_extraction.text?import?TfidfVectorizer
import?re
pd.options.display.max_columns =?30
import?matplotlib.pyplot?as?plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] ?# 用來正常顯示中文標簽
df = pd.read_csv('Seattle_Hotels.csv', encoding="latin-1")
# 數據探索
print(df.head())
print('數據集中的酒店個數:',?len(df))
# 創建英文停用詞列表
ENGLISH_STOPWORDS = {'i',?'me',?'my',?'myself',?'we',?'our',?'ours',?'ourselves',?'you',?"you're",?"you've",?"you'll",?"you'd",?'your',?'yours',?'yourself',?'yourselves',?'he',?'him',?'his',?'himself',?'she',?"she's",?'her',?'hers',?'herself',?'it',?"it's",?'its',?'itself',?'they',?'them',?'their',?'theirs',?'themselves',?'what',?'which',?'who',?'whom',?'this',?'that',?"that'll",?'these',?'those',?'am',?'is',?'are',?'was',?'were',?'be',?'been',?'being',?'have',?'has',?'had',?'having',?'do',?'does',?'did',?'doing',?'a',?'an',?'the',?'and',?'but',?'if',?'or',?'because',?'as',?'until',?'while',?'of',?'at',?'by',?'for',?'with',?'about',?'against',?'between',?'into',?'through',?'during',?'before',?'after',?'above',?'below',?'to',?'from',?'up',?'down',?'in',?'out',?'on',?'off',?'over',?'under',?'again',?'further',?'then',?'once',?'here',?'there',?'when',?'where',?'why',?'how',?'all',?'any',?'both',?'each',?'few',?'more',?'most',?'other',?'some',?'such',?'no',?'nor',?'not',?'only',?'own',?'same',?'so',?'than',?'too',?'very',?'s',?'t',?'can',?'will',?'just',?'don',?"don't",?'should',?"should've",?'now',?'d',?'ll',?'m',?'o',?'re',?'ve',?'y',?'ain',?'aren',?"aren't",?'couldn',?"couldn't",?'didn',?"didn't",?'doesn',?"doesn't",?'hadn',?"hadn't",?'hasn',?"hasn't",?'haven',?"haven't",?'isn',?"isn't",?'ma',?'mightn',?"mightn't",?'mustn',?"mustn't",?'needn',?"needn't",?'shan',?"shan't",?'shouldn',?"shouldn't",?'wasn',?"wasn't",?'weren',?"weren't",?'won',?"won't",?'wouldn',?"wouldn't"
}
def?print_description(index):example = df[df.index == index][['desc',?'name']].values[0]if?len(example) >?0:print(example[0])print('Name:', example[1])
print('第10個酒店的描述:')
print_description(10)
# 得到酒店描述中n-gram特征中的TopK個
def?get_top_n_words(corpus, n=1, k=None):# 統計ngram詞頻矩陣,使用自定義停用詞列表vec = CountVectorizer(ngram_range=(n, n), stop_words=list(ENGLISH_STOPWORDS)).fit(corpus)bag_of_words = vec.transform(corpus)"""print('feature names:')print(vec.get_feature_names())print('bag of words:')print(bag_of_words.toarray())"""sum_words = bag_of_words.sum(axis=0)words_freq = [(word, sum_words[0, idx])?for?word, idx?in?vec.vocabulary_.items()]# 按照詞頻從大到小排序words_freq =sorted(words_freq, key =?lambda?x: x[1], reverse=True)return?words_freq[:k]
common_words = get_top_n_words(df['desc'], n=2, k=20)
#print(common_words)
df1 = pd.DataFrame(common_words, columns = ['desc'?,?'count'])
df1.groupby('desc').sum()['count'].sort_values().plot(kind='barh', title='去掉停用詞后,酒店描述中的Top20單詞')
plt.show()
# 文本預處理
REPLACE_BY_SPACE_RE = re.compile('[/(){}\[\]\|@,;]')
BAD_SYMBOLS_RE = re.compile('[^0-9a-z #+_]')
# 使用自定義的英文停用詞列表替代nltk的stopwords
STOPWORDS = ENGLISH_STOPWORDS
# 對文本進行清洗
def?clean_text(text):# 全部小寫text = text.lower()# 用空格替代一些特殊符號,如標點text = REPLACE_BY_SPACE_RE.sub(' ', text)# 移除BAD_SYMBOLS_REtext = BAD_SYMBOLS_RE.sub('', text)# 從文本中去掉停用詞text =?' '.join(word?for?word?in?text.split()?if?word?not?in?STOPWORDS)?return?text
# 對desc字段進行清理,apply針對某列
df['desc_clean'] = df['desc'].apply(clean_text)
#print(df['desc_clean'])
# 建模
df.set_index('name', inplace =?True)
# 使用TF-IDF提取文本特征,使用自定義停用詞列表
tf = TfidfVectorizer(analyzer='word', ngram_range=(1,?3), min_df=0.01, stop_words=list(ENGLISH_STOPWORDS))
# 針對desc_clean提取tfidf
tfidf_matrix = tf.fit_transform(df['desc_clean'])
print('TFIDF feature names:')
#print(tf.get_feature_names_out())
print(len(tf.get_feature_names_out()))
#print('tfidf_matrix:')
print(tfidf_matrix.shape)
# 計算酒店之間的余弦相似度(線性核函數)
cosine_similarities = linear_kernel(tfidf_matrix, tfidf_matrix)
#print(cosine_similarities)
print(cosine_similarities.shape)
indices = pd.Series(df.index)?#df.index是酒店名稱
# 基于相似度矩陣和指定的酒店name,推薦TOP10酒店
def?recommendations(name, cosine_similarities = cosine_similarities):recommended_hotels = []# 找到想要查詢酒店名稱的idxidx = indices[indices == name].index[0]print('idx=', idx)# 對于idx酒店的余弦相似度向量按照從大到小進行排序score_series = pd.Series(cosine_similarities[idx]).sort_values(ascending =?False)# 取相似度最大的前10個(除了自己以外)top_10_indexes =?list(score_series.iloc[1:11].index)# 放到推薦列表中for?i?in?top_10_indexes:recommended_hotels.append(list(df.index)[i])return?recommended_hotels
print(recommendations('Hilton Seattle Airport & Conference Center'))
print(recommendations('The Bacon Mansion Bed and Breakfast'))
#print(result)Unigram (1-gram)結果:
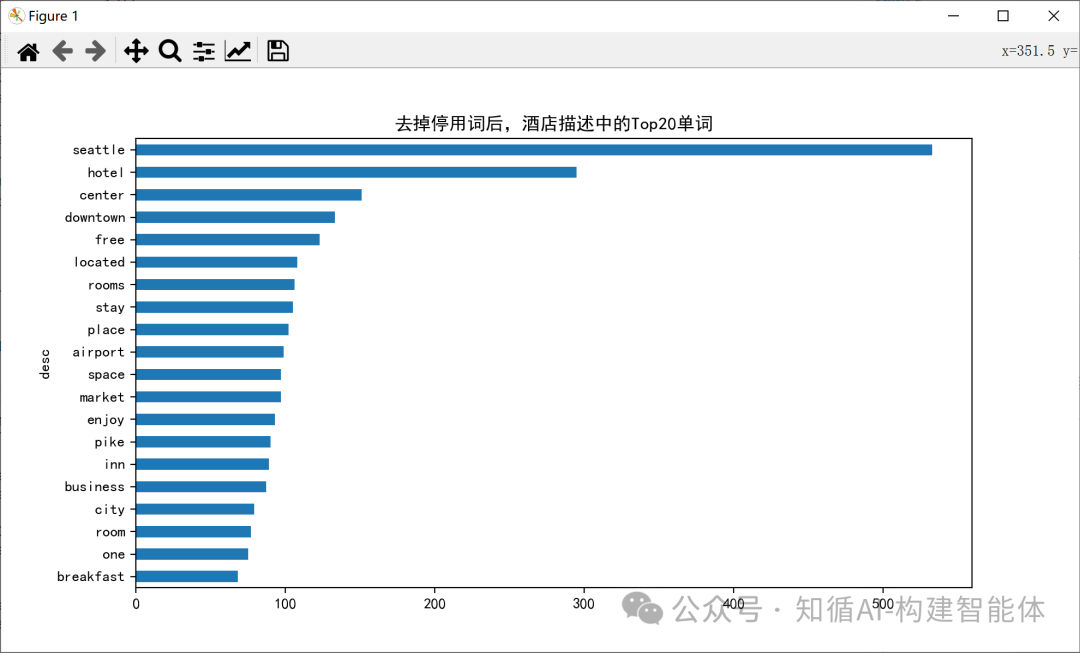
Bigram (2-gram)結果:
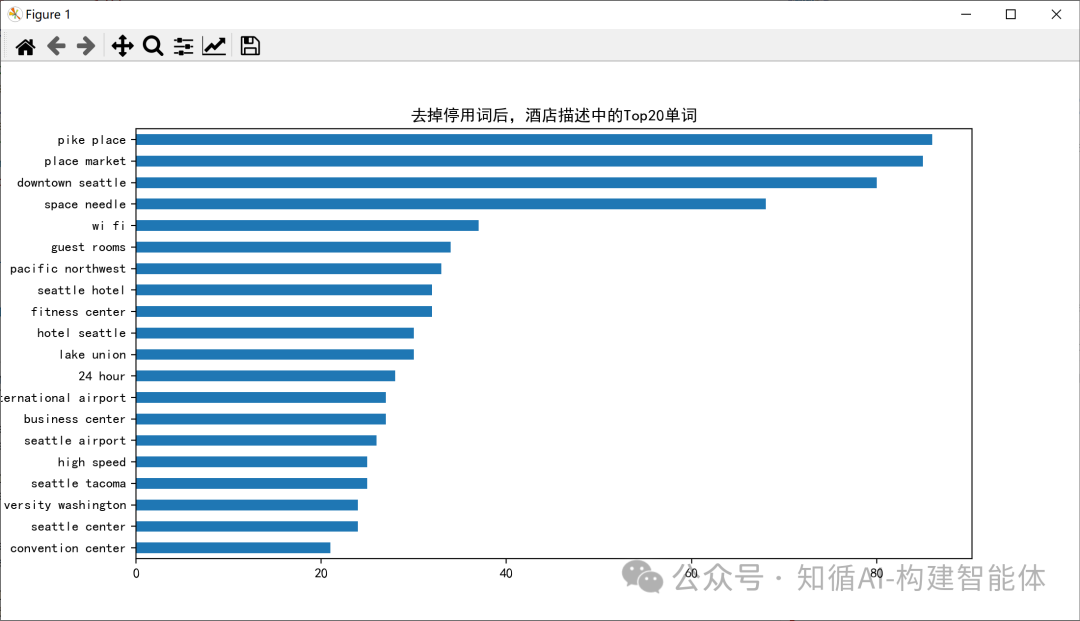
Trigram (3-gram)結果:
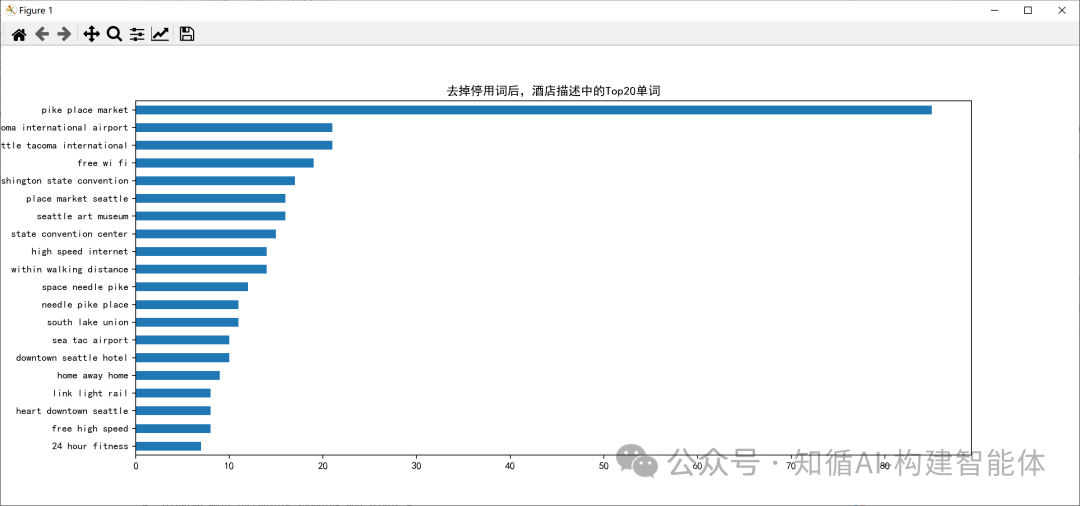
四、N-gram 的概率計算
N-gram 模型的核心是計算條件概率。我們通過在大型語料庫中計數來估計這些概率。
最大似然估計(MLE)公式
對于 Bigram:
P(w_i | w_{i-1}) = Count(w_{i-1}, w_i) / Count(w_{i-1})
Count(w_{i-1}, w_i)?是序列 ?(w_{i-1}, w_i)?在語料庫中出現的次數。
Count(w_{i-1})?是單詞 w_{i-1}?在語料庫中出現的總次數。
具體示例:
假設我們的語料庫由以下三個句子組成(<s>?和 </s>?是句首和句尾標記):
<s> 我喜歡吃蘋果 </s>
<s> 我喜歡讀書 </s>
<s> 你喜歡什么 </s>
現在,我們來計算一些概率:
P(喜歡 | 我)?= Count(我, 喜歡) / Count(我)
?Count(我, 喜歡) ?= 2 (在句子1和2中,“我喜歡”都出現了)
?Count(我) = 2 (“我”作為第一個詞出現了2次)
所以,P(喜歡 | 我) = 2 / 2 = 1.0
P(吃 | 喜歡)?= Count(喜歡, 吃) / Count(喜歡)
Count(喜歡, 吃) = 1 (只在句子1中出現)
Count(喜歡) = 3 (在三個句子中都出現了“喜歡”)
所以,P(吃 | 喜歡) = 1 / 3 ≈ 0.33
P(蘋果 | 吃)?= Count(吃, 蘋果) / Count(吃)
Count(吃, 蘋果) = 1
Count(吃) = 1
所以,P(蘋果 | 吃) = 1 / 1 = 1.0
現在,計算整個句子?“我喜歡吃蘋果”?的 Bigram 概率:
P(句子) = P(我 | <s>) * P(喜歡 | 我) * P(吃 | 喜歡) * P(蘋果 | 吃) * P(</s> | 蘋果)?
我們需要額外計算:
P(我 | <s>) = Count(<s>, 我) / Count(<s>) = 2 / 3(3個句子,2個以“我”開頭)
P(</s> | 蘋果) = Count(蘋果, </s>) / Count(蘋果) = 1 / 1 = 1.0(假設“蘋果”只在句尾出現一次)
最終:
P(句子) = (2/3) * 1.0 * (1/3) * 1.0 * 1.0 ≈ 0.222
馬爾可夫假設
N-Gram基于一個巧妙而有效的簡化:一個詞的出現概率只與它前面有限個詞有關。這一假設使得復雜的語言建模問題變得可計算。例如,在Bigram模型中,我們假設:P(天氣|今天) ≈ P(天氣|今天)
N-Gram模型的核心是計算序列概率。對于一個句子"今天天氣真好",其概率可以表示為:
P(今天天氣真好) = P(今天) × P(天氣|今天) × P(真|天氣) × P(好|真)
假設語料庫中有以下句子:
今天天氣真好
今天心情真好
明天天氣不錯
計算P(天氣|今天):
Count(今天, 天氣)?=?1(第1句)
Count(今天)?=?2(第1、2句)
P(天氣|今天)?=?1/2?=?0.5參考代碼:
from?collections?import?defaultdict, Counter
import?numpy?as?np
# 簡單語料庫
corpus = [['今天',?'天氣',?'真好'],['今天',?'心情',?'真好'],?['明天',?'天氣',?'不錯']
]
# 構建Bigram模型
def?build_bigram_model(corpus):bigram_counts = defaultdict(Counter)unigram_counts = Counter()for?sentence?in?corpus:for?i?in?range(len(sentence)-1):current_word = sentence[i]next_word = sentence[i+1]bigram_counts[current_word][next_word] +=?1unigram_counts[current_word] +=?1# 計算概率bigram_probs = {}for?prev_word, next_words?in?bigram_counts.items():total = unigram_counts[prev_word]bigram_probs[prev_word] = {next_word: count/total?for?next_word, count?in?next_words.items()}return?bigram_probs
# 構建模型
model = build_bigram_model(corpus)
print("P(天氣|今天) =", model['今天']['天氣'])
print("P(心情|今天) =", model['今天']['心情'])輸出結果:
P(天氣|今天) =?0.5
P(心情|今天) =?0.5基于以上基礎繼續實現文本自動生成:???????
def?generate_text(seed_word, model, length=10):current_word = seed_wordgenerated_text = [current_word]for?_?in?range(length-1):if?current_word?not?in?model:breaknext_words =?list(model[current_word].keys())probabilities =?list(model[current_word].values())# 按概率選擇下一個詞next_word = np.random.choice(next_words, p=probabilities)generated_text.append(next_word)current_word = next_wordreturn?''.join(generated_text)
# 生成文本
print("生成示例:", generate_text('今天', model,?5))輸出結果:
生成示例: 今天天氣真好參考經典的硬幣投擲問題加深理解:
????????最大似然估計(MLE)是統計學中一種常用的參數估計方法。它的核心思想是:在已知數據集的情況下,尋找最有可能產生這些數據的參數值。
????????舉個例子,假設我們有一個硬幣,我們想估計擲硬幣時正面朝上的概率p。我們擲了10次硬幣,結果有7次正面朝上,3次反面朝上。我們可以將每次擲硬幣看作是一個伯努利試驗,那么正面朝上的次數X服從二項分布,即X ~ Binomial(n=10, p)。
????????我們的目標是估計參數p。似然函數就是給定參數p時,觀察到當前數據的概率。對于二項分布,似然函數為:
??????????????????????????L(p) = P(X=7 | p) = C(10,7) * p^7 * (1-p)^3
????????最大似然估計就是要找到使L(p)最大的p值。通常,我們會取似然函數的對數(因為對數函數是單調的,最大化對數似然等價于最大化似然),然后求導并令導數為0。
對數似然函數為:log L(p) = log(C(10,7)) + 7*log(p) + 3*log(1-p)
對p求導并令導數為0:d(log L(p))/dp = 7/p - 3/(1-p) = 0
解方程:7/p = 3/(1-p) ?=> 7(1-p) = 3p ?=> 7 - 7p = 3p ?=> 7 = 10p ?=> p = 0.7
因此,p的最大似然估計值是0.7。
下面我們用Python代碼來演示這個過程,包括繪制似然函數曲線。
mport?numpy?as?np
import?matplotlib.pyplot?as?plt
from?scipy.optimize?import?minimize_scalar
# 設置matplotlib支持中文顯示
plt.rcParams['font.sans-serif'] = ['SimHei'] ?# 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] =?False??# 用來正常顯示負號
# 觀測數據:7次正面,3次反面
data = np.array([1,?1,?1,?1,?1,?1,?1,?0,?0,?0])
n_heads = np.sum(data)
n_tails =?len(data) - n_heads
# 定義似然函數
def?likelihood(p):return?p**n_heads * (1-p)**n_tails
# 定義負對數似然函數(因為我們要最小化)
def?neg_log_likelihood(p):return?- (n_heads * np.log(p) + n_tails * np.log(1-p))
# 使用優化方法找到最大似然估計
result = minimize_scalar(neg_log_likelihood, bounds=(0.01,?0.99), method='bounded')
mle_p = result.x
print(f"最大似然估計值: p =?{mle_p:.3f}")
# 可視化似然函數
p_values = np.linspace(0.01,?0.99,?100)
likelihood_values = [likelihood(p)?for?p?in?p_values]
plt.figure(figsize=(10,?6))
plt.plot(p_values, likelihood_values, label='似然函數')
plt.axvline(mle_p, color='r', linestyle='--', label=f'MLE估計值: p={mle_p:.3f}')
plt.xlabel('p (正面概率)')
plt.ylabel('似然值')
plt.title('硬幣投擲問題的似然函數')
plt.legend()
plt.grid(True)
plt.show()結果展示:
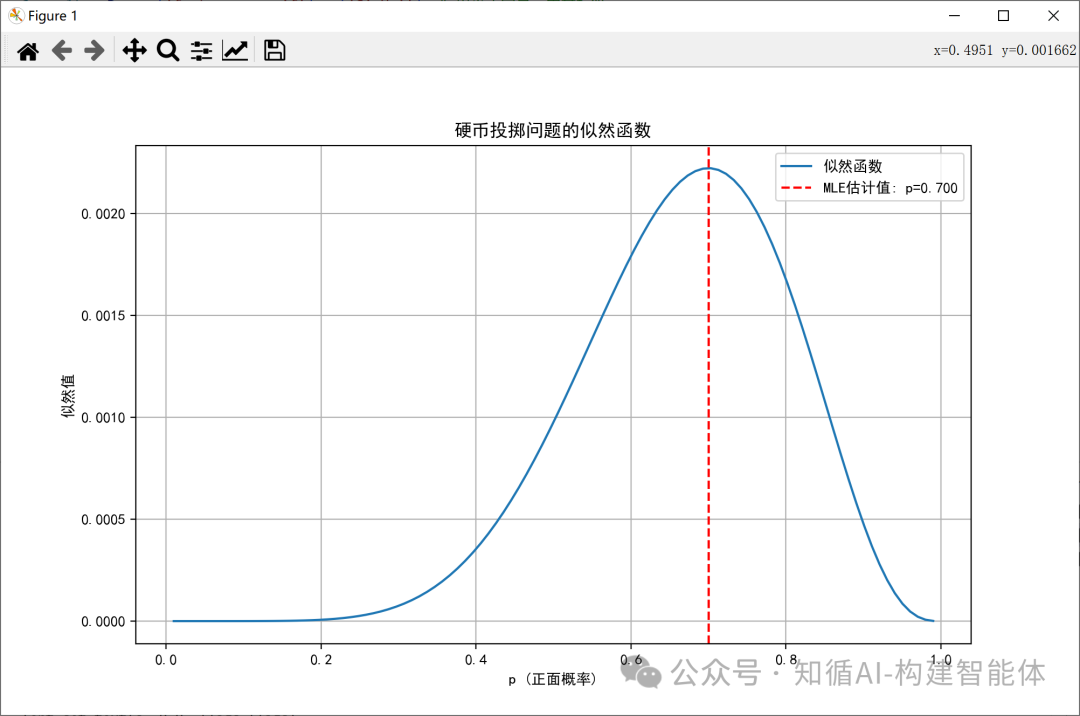
五、數據稀疏與平滑技術
如果語料庫中從未出現過 (w_{i-1}, w_i) 這個組合,那么 P(w_i | w_{i-1}) = 0,這會導致整個句子的概率為0。例如,語料庫中如果沒有“吃香蕉”,那么句子“我喜歡吃香蕉”的概率就是0,這顯然不合理。
解決方案: 平滑(Smoothing)技術。其核心思想是從已知概率中“偷”一點概率質量分配給未出現過的序列。
常見平滑方法:
加一平滑(Add-One / Laplace Smoothing):?將所有計數加1,避免0概率。
古德-圖靈估計(Good-Turing Estimation):?用出現一次的事物的數量來估計未出現事物的概率。
回退(Backoff):?如果N-gram不存在,就回退到使用 (N-1)-gram 的概率。
插值(Interpolation):?將不同階數的N-gram(如unigram, bigram, trigram)的概率加權混合起來。
六、N-gram 的應用
文本生成:
給定一個起始詞,根據N-gram概率選擇下一個最可能的詞,依此類推,生成連貫的文本。
示例: 輸入“今天”,模型可能根據語料庫生成“今天天氣真好”。
語法檢查與糾錯:
低概率的單詞序列很可能存在語法錯誤或拼寫錯誤。
示例: “吃飛機”這個Bigram的概率極低,系統會提示“吃飛機”可能應為“坐飛機”。
輸入法預測:
當你輸入“wo”時,輸入法會預測“我”;當你輸入“wo xihuan”時,它會預測“我喜歡”以及后續可能接的詞“讀書”、“吃”等。
語音識別:
幫助系統在發音相近的候選詞中選擇最符合上下文語境的詞。
示例: 識別到發音為“shi4 jian4”,在“事件”和“時間”之間,如果上文是“漫長的”,則選擇“時間”的概率更高。
機器翻譯:
用于評估翻譯輸出的流暢度,選擇那些聽起來更自然、更符合目標語言N-gram習慣的譯文。
信息檢索:
處理短語查詢(如“紐約時報”),將其視為一個Bigram,比單獨搜索“紐約”和“時報”能返回更精確的結果。
七、總結
????????N-gram 是一個簡單而強大的概率模型,用于表示文本中的連續序列。通過有限的上下文來捕捉語言的局部規律,平衡了模型的復雜度和計算可行性。雖然如今Transformer(如BERT, GPT)等深度學習模型在大多數NLP任務上超越了N-gram,但N-gram因其輕量、可解釋、不需要訓練(僅需計數)的特性,在資源受限的場景、快速原型開發以及作為大型模型的補充組件中,依然發揮著重要作用。理解N-gram是理解更復雜NLP模型的基礎。
)



精講)


:構建企業知識庫,深入ETL與RAG實現)


)


基本控件應用)





