前文:從零到一訓練一個 0.6B 的 MoE 大語言模型,本次升級完全重新從零開始重新訓練。主要升級如下:
- 替換預訓練數據集,使用序列猴子通用文本數據集進行預訓練。
- 使用更先進的訓練方法。
- 新增思考模式控制,可通過添加/think和/no think控制是否思考。
- 新增思考預算功能,可控制思考token長度。
效果展示
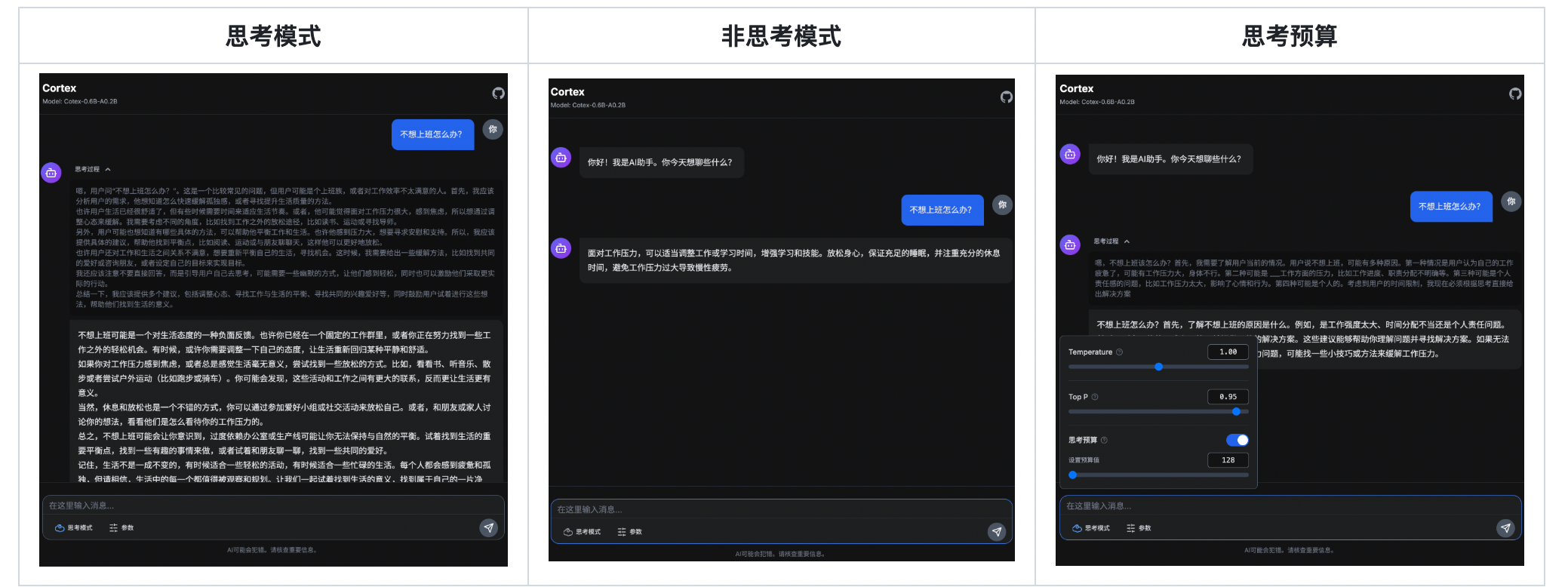
快速開始
- 確保本機已安裝python3
- clone或下載項目:https://github.com/qibin0506/Cortex
- 安裝依賴 pip3 install -r requirements.txt
- 下載checkpoint https://www.modelscope.cn/models/qibin0506/Cortex-V2/resolve/master/dpo.bin,并放置到項目根目錄
- 執行 python3 app.py運行項目,訪問鏈接http://0.0.0.0:8080/ 即可體驗
訓練細節
Cortex V2采用更加先進的訓練方式進行訓練,具體情況如下;
預訓練
預訓練過程采用兩階段訓練模式
| 階段1 | 階段2 |
|---|---|
| train_pretrain_stage0.py | train_pretrain_stage1.py |
| 上下文長度為512,在較短訓練文本上進行訓練 | 采用YaRN技術將上下文擴展至2048,并在長文本序列上繼續訓練 |
后訓練
后訓練過程采用四階段訓練模式
| 階段1 | 階段2 | 階段3 | 階段4 |
|---|---|---|---|
| train_cot.py | train_grpo.py | train_mix.py | train_dpo.py |
| 在純COT數據集上進行SFT,讓模型原生支持思考模式 | 采用GSPO技術,提升模式的邏輯思考能力 | 使用COT和非COT混合數據集上進行SFT,讓模式支持思考控制和思考預算能力 | 使用DPO進行對齊訓練 |
繼續訓練
本項目提供各個階段訓練完成后的checkpoint, 可根據自己需求選擇checkpoint繼續訓練。
checkpoint下載:https://www.modelscope.cn/models/qibin0506/Cortex-V2/files
訓練方式:
- 確定繼續訓練的階段,修改
file_dataset.py中對應階段的FileDataset中的文件,然后使用smart_train進行訓練,例如重新進行dpo,則執行smart_train train_dpo.py - 本項目GSPO階段是在4x5090進行訓練,其他階段都是在4x4090進行訓練,同時
utils.py中的配置數據也是按照對應硬件配置確定,如有不同的訓練設備可自行修改utils.py進行適配。 file_dataset.py文件用來管理數據集文件,可按需修改,數據集文件會自動下載,使用完成后會自動刪除,無需人工管理。





)

排序自定義切片)

路由策略-實驗)


)



 方法詳解, 幫助子組件向父組件傳遞事件)

-策略(policy))
