關注gongzhonghao【CVPR頂會精選】
1.導讀
1.1 論文基本信息
論文標題:《HOLODECK: Language Guided Generation of 3D Embodied AI Environments》
作者:Yue Yang*1, Fan-Yun Sun*2, Luca Weihs*4, Eli Vanderbilt4, Alvaro Herrasti4,Winson Han4, Jiajun Wu2, Nick Haber2, Ranjay Krishna3,4, Lingjie Liu1,Chris Callison-Burch1, Mark Yatskar1, Aniruddha Kembhavi3,4, Christopher Clark4
作者單位:賓夕法尼亞大學、斯坦福大學、華盛頓大學、艾倫人工智能研究所等
發表會議:CVPR(計算機視覺與模式識別會議)
論文鏈接:https://arxiv.org/abs/2312.09067
圖靈學術論文輔導
2.論文概述
2.1 問題與背景
該論文提出了一種名為HOLODECK的系統,旨在通過文本描述自動生成多樣化、可定制且可交互的3D具身智能環境,以解決現有3D環境生成方法需要大量人工投入且多樣性受限的問題。HOLODECK利用大型語言模型的常識知識來理解復雜的用戶查詢,并通過約束優化方法來合理布局場景中的物體,從而確保生成環境的物理合理性和語義一致性

2.2 系統模塊核心
HOLODECK系統的核心在于其模塊化設計,它將復雜的3D場景生成任務分解為四個子模塊:樓層與墻體、門窗、物體選擇和基于約束的布局設計。這種方法使其能夠根據用戶輸入的提示詞,自動生成符合特定風格或包含精細化需求的場景。論文通過大規模人類評估,證明HOLODECK生成的住宅場景優于現有的程序化基線方法,并且能夠生成高質量的多樣化場景。此外,研究還展示了HOLODECK在具身智能中的應用,證明了使用HOLODECK生成的新穎場景訓練智能體,可以顯著提升其在零樣本物體導航任務中的泛化能力 。
3.研究背景及相關工作
3.1 具身智能環境的挑戰
具身智能體的訓練通常依賴于模擬器環境。然而,現有的3D環境生成方法面臨著諸多挑戰。傳統方法如人工設計或3D掃描,需要耗費大量人力和專業知識,且難以大規模擴展和保證場景的多樣性。雖然程序化生成框架能夠生成大規模交互式環境,但其依賴于硬編碼規則,限制了場景的豐富性和可定制性。
3.3 2D基礎模型與3D場景生成
一些工作嘗試將2D基礎模型應用于文本驅動的3D場景生成。然而,這些方法通常會產生網格失真等明顯偽影,且缺乏具身智能所需的交互性。另一些模型雖然專注于特定的任務,如平面圖生成或物體排列,但它們通常缺乏整體場景的一致性,且嚴重依賴于特定任務的數據集。

3.3 文本驅動的3D生成
早期的文本驅動3D生成工作主要側重于從類別特定的數據集中學習3D形狀或紋理。隨著大型視覺-語言模型的出現,實現了零樣本的3D紋理和物體生成。但這些方法在生成復雜3D場景時表現不佳。與這些方法不同,HOLODECK利用了一個包含海量資產的3D數據庫,以生成語義精確、空間高效且可交互的3D環境 。
4.實驗設計和方法
4.1 總體架構設計
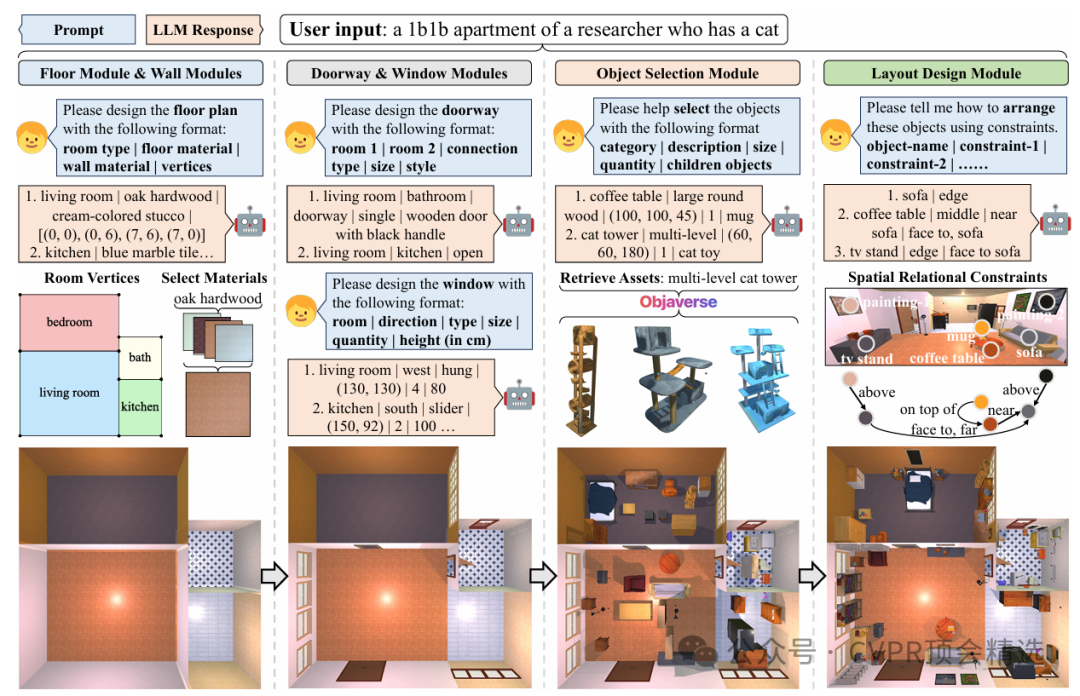
HOLODECK是一個基于A12-THOR框架并結合了Objaverse海量資產的系統,其核心思想是利用大型語言模型將高級別的自然語言描述轉化為一系列用于構建3D場景的低級別指令。整個場景的生成過程被分解為四個相互協作的模塊,每個模塊都通過與LLM進行多輪對話來完成特定的任務。
樓層與墻體模塊:
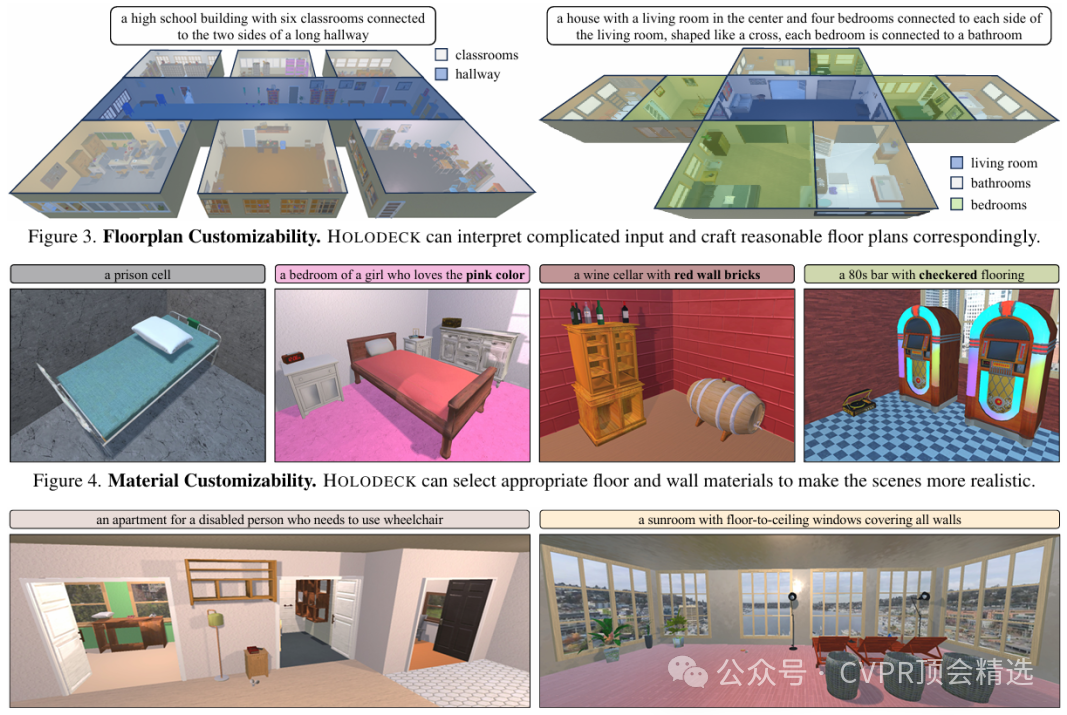
該模塊負責創建房間的平面圖、構建墻體結構,并為地板和墻壁選擇合適的材料。LLM會直接生成房間的坐標和連接信息,每個房間被定義為由四個元組坐標確定的矩形。該模塊能夠根據復雜的輸入生成精細的多房間平面圖。此外,它還能從236種材料和148種顏色中進行匹配,以實現場景的語義定制化。
物體選擇模塊:
該模塊允許LLM根據場景描述來選擇合適的物體。HOLODECK利用龐大的Objaverse資產庫,根據LLM建議的描述和尺寸來檢索最佳的3D資產。
基于約束的布局設計模塊:
HOLODECK預定義了十種空間關系約束,分為五類:全局、距離、位置、對齊和旋轉。這些約束被視為軟約束,并通過一個優化算法來解決,以找到滿足最多約束的合理布局。同時,系統還強制執行硬約束,以防止物體碰撞并確保所有物體都在房間邊界內。
圖靈學術論文輔導
5. 實驗結果分析
5.1 住宅場景的人類評估
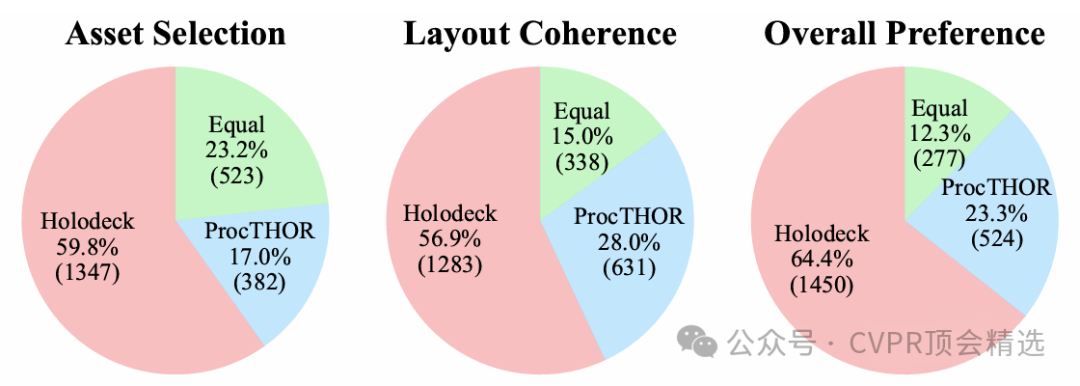
在一項與PROCTHOR的對比研究中,680名參與者對HOLODECK和PROCTHOR生成的住宅場景進行了評估。結果顯示,在資產選擇、布局一致性和整體偏好三個方面,人類評估者都明顯偏向HOLODECK。
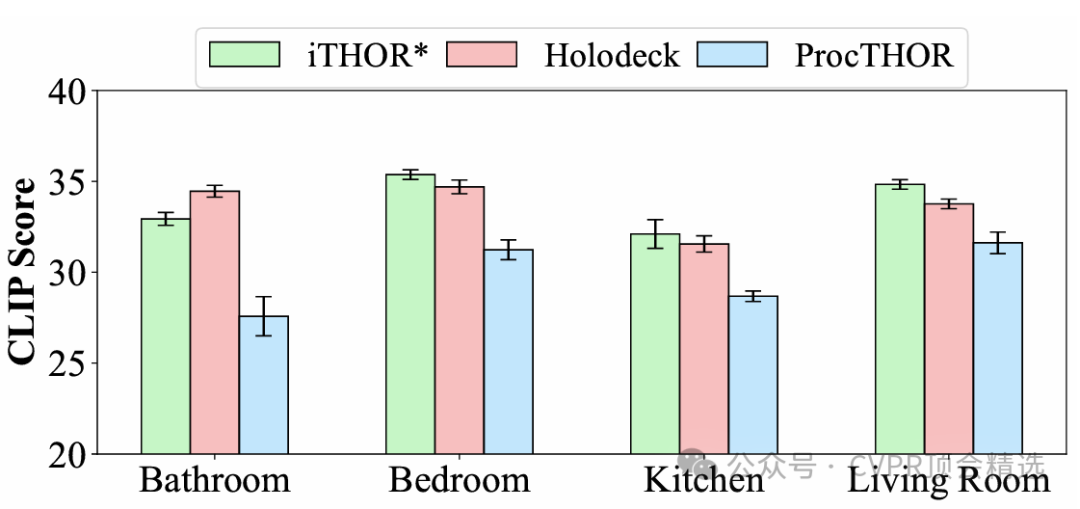
在整體偏好上,64.4%的評估者更喜歡HOLODECK,而只有23.3%的評估者更喜歡PROCTHOR。此外,使用CLIP分數進行的視覺一致性量化評估也顯示,HOLODECK的得分顯著高于PROCTHOR,且接近人類專家設計的場景,進一步證明了其生成視覺連貫場景的能力。
5.2 多樣化場景的生成能力
為了評估HOLODECK在住宅場景之外的表現,研究人員讓人類對52種不同類型的場景進行了評分。結果表明,HOLODECK在超過一半(28/52)的場景類型上獲得了比PROCTHOR更高的平均偏好分數。

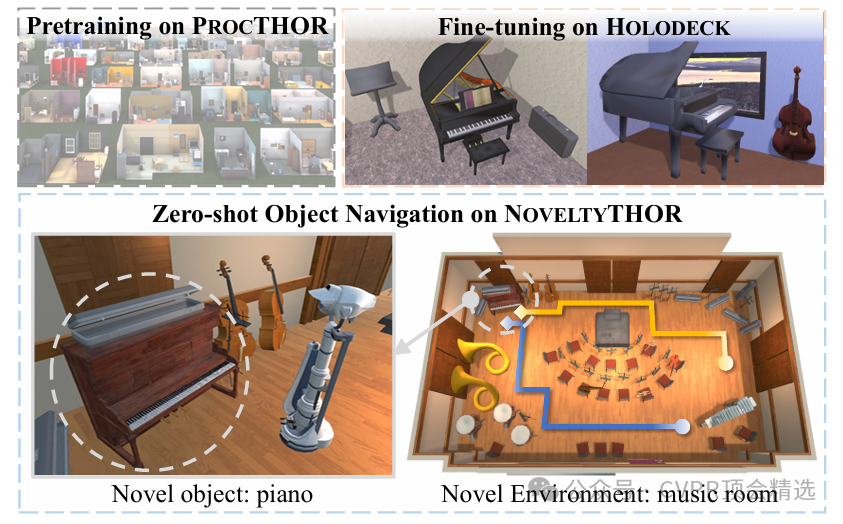
5.3 在具身智能中的應用
論文展示了HOLODECK在具身智能中的一個激動人心的應用:零樣本物體導航。研究人員在一個名為NOVELTYTHOR的新穎基準上進行了實驗。結果顯示,使用HOLODECK生成的新場景進行微調的智能體,其零樣本導航成功率和路徑長度加權成功率都顯著高于基線模型。這表明HOLODECK生成的訓練環境能夠幫助智能體更好地泛化到以前未見過的場景和物體類型。論文指出,HOLODECK在物體放置上的能力,是其優于基線的主要原因之一 。
6.論文總結展望
6.1 論文總結
該論文成功地提出了HOLODECK系統,一個由大型語言模型驅動的、能夠從文本描述中生成多樣化和可交互的3D具身智能環境的系統。
HOLODECK通過將生成過程分解為多個模塊,并利用LLM的常識知識和一種新穎的基于空間關系約束的布局優化方法,克服了傳統方法在多樣性、可定制性和物理合理性方面的局限。
大規模的人類評估結果一致表明,HOLODECK生成的場景質量優于現有基線,且能夠很好地泛化到各種場景類型。此外,通過零樣本物體導航實驗,研究還驗證了HOLODECK生成的場景在訓練具身智能體方面的實用性。

6.2 論文展望
盡管HOLODECK取得了顯著成就,但論文也指出了一些局限性。目前,該系統在處理需要非常復雜布局或需要其資產庫中不存在的獨特物體(如牙科診所的X光機)的場景時仍然面臨挑戰。未來工作的方向可以包括擴大資產庫,并引入更復雜的布局算法來解決這些問題。此外,該系統為進一步探索文本驅動的3D交互式場景生成開辟了新的途徑。
本文選自gongzhonghao【CVPR頂會精選】





![[Linux]學習筆記系列 -- [mm][memblock]](http://pic.xiahunao.cn/[Linux]學習筆記系列 -- [mm][memblock])
)








)



