一、NoSQL
1.1 單機mysql的美好時代
在90年代,一個網站的訪問量一般都不大,用單個數據庫完全可以輕松應付。
那個時候,更多的是靜態網頁,動態交互類型的網站不多。

上述架構上,我們來看看數據存儲的瓶頸是什么?
DAL:Data Access Layer(數據庫訪問層)
-
數據量的總大小一個機器放不下時
-
數據的索引(B+ Tree)一個機器的內存放不下時
-
訪問量(讀寫混合)一個實例不能承受
如果滿足了上面的1 or 3 個時,只能對數據庫的整體架構進行重構
1.2 mysql主從讀寫分離
讀寫集中在一個數據庫上讓數據庫不堪重負,大部分網站開始使用主從復制技術來達到讀寫分離,以提高讀寫性能和讀庫的可擴展性。
Mysql的master-slave模式成為這個時候的網站標配了。
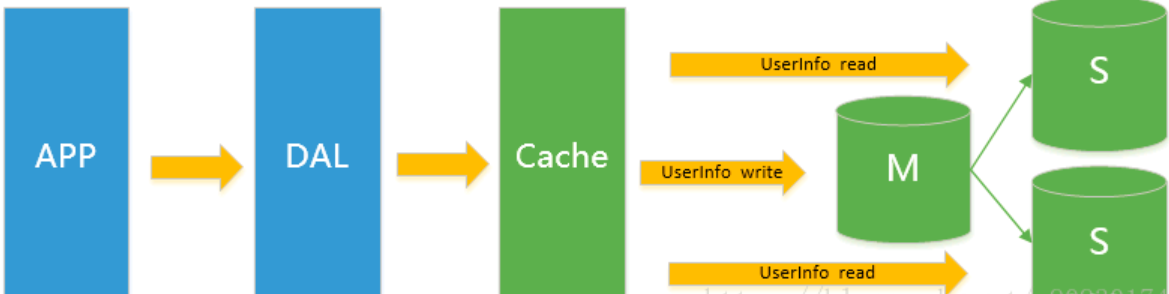
1.3 MySQL的擴展性瓶頸
MySQL數據庫也經常存儲一些大文本字段,導致數據庫表非常的大,在做數據庫恢復的時候就導致非常的慢,不容易快速恢復數據庫。
比如1000萬4KB大小的文本就接近40GB的大小,如果能把這些數據從MySQL省去,MySQL將變得非常的小。
關系數據庫很強大,但是它并不能很好的應付所有的應用場景。
MySQL的擴展性差(需要復雜的技術來實現),大數據下IO壓力大,表結構更改困難,正是當前使用MySQL的人員面臨的問題。
1.4 今天是什么樣子
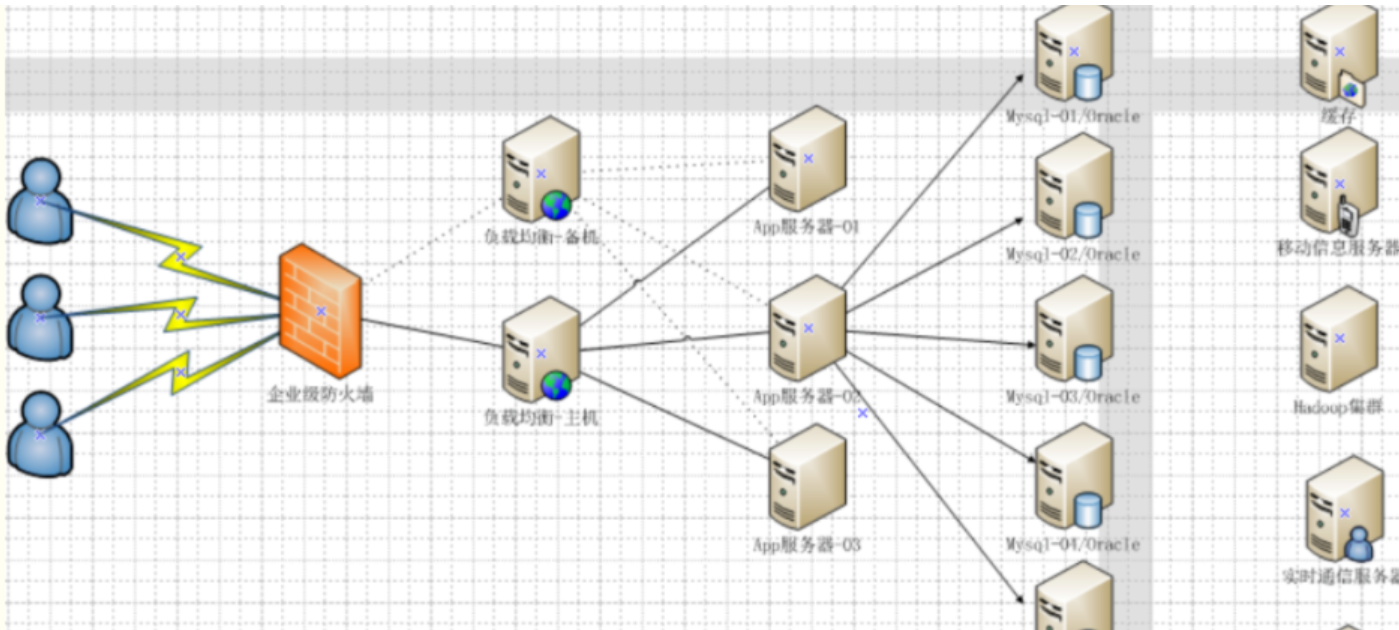
最前面的是企業級防火墻,后面通過負載均衡主機在 web 服務器集群之間進行調度,再由具體的 web 服務器(Tomcat)去訪問緩存,訪問數據庫。
1.5 為什么用nosql
今天我們可以通過第三方平臺(如:Google,Facebook等)可以很容易的訪問和抓取數據。
用戶的個人信息,社交網絡,地理位置,用戶生成的數據和用戶操作日志已經成倍的增加。
我們如果要對這些用戶數據進行挖掘,那SQL數據庫已經不適合這些應用了, NoSQL數據庫的發展也卻能很好的處理這些大的數據。
1.6 什么是nosql
NoSQL(NoSQL = Not Only SQL ),意即“不僅僅是SQL”。
泛指非關系型的數據庫。隨著互聯網web2.0網站的興起,傳統的關系數據庫在應付web2.0網站,特別是超大規模和高并發的的web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關系型的數據庫則由于其本身的特點得到了非常迅速的發展。
NoSQL數據庫的產生就是為了解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題,包括超大規模數據的存儲。
(例如谷歌或Facebook每天為他們的用戶收集萬億比特的數據)。
這些類型的數據存儲不需要固定的模式,無需多余操作就可以橫向擴展。
1.7 nosql代表
MongoDB、Redis 和 Memcached 都是非常流行的數據庫/緩存解決方案,但它們的設計目標和使用場景有所不同。
以下是這三個軟件的簡要分析及其主要區別的表格:
-
MongoDB:雖然MongoDB主要是作為一個NoSQL數據庫被廣泛認知,它提供了一個靈活的文檔存儲模型(JSON-like documents),適用于處理各種類型的數據。盡管MongoDB可以作為緩存層使用,但這并不是它的主要用途。MongoDB更適合于需要復雜查詢和數據持久化的應用場景。
-
Redis:Redis是一個開源的內存數據結構存儲系統,通常用作數據庫、緩存和消息中間件。它支持多種數據結構如字符串、哈希、列表、集合等,并且提供了豐富的操作命令。由于所有數據都存儲在內存中,Redis讀寫速度非常快,適合用于實時數據分析、計數器、排行榜等高性能要求的場景。
-
Memcached:Memcached是一種高性能的分布式內存對象緩存系統,主要用于加速動態Web應用程序的數據訪問速度。與Redis相比,Memcached更簡單,只支持基本的鍵值對存儲,并且不支持持久化存儲。它非常適合用來緩存簡單的對象,如HTML片段或數據庫查詢結果。
| 特性 | MongoDB | Redis | Memcached |
|---|---|---|---|
| 類型 | 文檔型NoSQL數據庫 | 內存數據結構存儲(鍵值對) | 分布式內存緩存 |
| 主要用途 | 數據庫 | 數據庫、緩存、消息中間件 | 緩存 |
| 數據結構 | JSON-like文檔 | 字符串、哈希、列表、集合等多種數據結構 | 鍵值對 |
| 持久化 | 支持 | 可選(默認情況下為內存存儲) | 不支持 |
| 擴展性 | 水平擴展(分片) | 主從復制、哨兵、集群模式 | 分布式架構 |
| 性能 | 中等(磁盤I/O影響性能) | 高(全內存操作) | 高(全內存操作) |
| 適用場景 | 復雜查詢、大數據集 | 實時分析、高速交易、隊列 | 加速頁面加載、緩存數據庫查詢結果 |
1.8 關系數據庫和nosql的區別
RDBMS
-
高度組織化的結構化數據
-
結構化查詢語言(SQL)
-
數據和關系都存儲在單獨的表中
-
數據操作語言,數據定義語言
-
嚴格的一致性
-
基礎事務
-
ACID原則(事務的特性)
-
A (Atomicity) 原子性:原子性很容易理解,也就是說事務里的所有操作要么全部做完,要么都不做,事務成功的條件是事務里的所有操作都成功,只要有一個操作失敗,整個事務就失敗,需要回滾。比如銀行轉賬,從A賬戶轉100元至B賬戶,分為兩個步驟:1)從A賬戶取100元;2)存入100元至B賬戶。這兩步要么一起完成,要么一起不完成,如果只完成第一步,第二步失敗,錢會莫名其妙少了100元。
-
C (Consistency) 一致性:一致性也比較容易理解,也就是說數據庫要一直處于一致的狀態,事務的運行不會改變數據庫原本的一致性約束。
-
I (Isolation) 獨立性:所謂的獨立性是指并發的事務之間不會互相影響,如果一個事務要訪問的數據正在被另外一個事務修改,只要另外一個事務未提交,它所訪問的數據就不受未提交事務的影響。比如現有有個交易是從A賬戶轉100元至B賬戶,在這個交易還未完成的情況下,如果此時B查詢自己的賬戶,是看不到新增加的100元的
-
D (Durability) 持久性:持久性是指一旦事務提交后,它所做的修改將會永久的保存在數據庫上,即使出現宕機也不會丟失。
-
nosql
-
沒有聲明性查詢語言
-
沒有預定義的模式
-
鍵 - 值對存儲,列存儲,文檔存儲,圖形數據庫
-
最終一致性,而非ACID屬性
-
非結構化和不可預知的數據
-
高性能,高可用性和可伸縮性
-
CAP定理(說明:C:強一致性 A:高可用性 P:分布式容忍性)
-
Consistency(一致性), 數據一致更新,所有數據變動都是同步的
-
Availability(可用性), 好的響應性能
-
Partition tolerance(分區容錯性) 可靠性
-
定理:任何分布式系統只可同時滿足二點,沒法三者兼顧。
1.9 小結
-
在性能方面,NoSQL數據庫使用一些算法將對磁盤的隨機寫轉換成順序寫,提升了寫的性能
-
在擴展性方面,NoSQL數據庫天生支持分布式,支持數據冗余和數據分片的特性
-
在某些場景下,比如全文搜索功能,關系型數據庫并不能高效的支持,需要NoSQL數據庫的支持
二、軟件實踐
Redis 是一個開源的內存數據結構存儲系統,通常用作數據庫、緩存和消息中間件。
它支持多種數據類型,如字符串(String)、哈希(Hash)、列表(List)、集合(Set)以及有序集合(Sorted Set)。
拉取 Redis 鏡像
在終端或中運行以下命令來拉取最新的 Redis 官方鏡像:
docker pull redis運行 Redis 容器
使用命令啟動一個 Redis 容器:
docker run --name my-redis -d redis連接到 Redis 容器
可以使用 Docker 命令進入 Redis 容器內部,然后使用 Redis CLI 來與 Redis 實例進行交互:
docker exec -it my-redis redis-cli字符串(String)
字符串是最基礎的數據類型,也是 Redis 的默認數據類型。
SET:設置鍵值對。
SET key value示例:
set name jackGET:獲取鍵對應的值。
GET key示例:
get name 哈希(Hash)
哈希是用于存儲字段和字段值的映射表,適合存儲對象。
HSET:設置哈希表中的字段值。
HSET hash field value示例:
hset person name lshhset person age 18HGET:獲取哈希表中指定字段的值。
HGET hash field示例:
HGET person name列表(List)
列表是一個簡單的字符串列表,按照插入順序排序。可以從列表的兩端進行添加或移除元素。
LPUSH:在列表的左側插入一個或多個值。
LPUSH list value [value ...]示例:
LPUSH mylist "a" "b"LRANGE:獲取列表中指定范圍的元素。
LRANGE mylist 0 -1注釋:
-1 指的是最后一位集合(Set)
集合是一個無序不重復元素的集合。
SADD:向集合中添加一個或多個成員。
SADD set member [member ...]示例:
sadd names qwe asd zxcSMEMBERS:返回集合中的所有成員。
smembers namesSPOP:隨機從集合中抽一個值
spop names有序集合(Sorted Set)
有序集合類似于集合,但每個成員都關聯了一個分數,這使得成員可以根據分數來排序。
ZADD:向有序集合中添加一個或多個成員,或者更新已存在成員的分數。
ZADD zset score member [[score member] [score member] ...]示例:
zadd socres 60 wxqzadd socres 70 jyxZRANGE:返回有序集中指定區間內的成員,按分數值遞增排序。
ZRANGE zset start stop [WITHSCORES]示例:
zrange socres 0 -1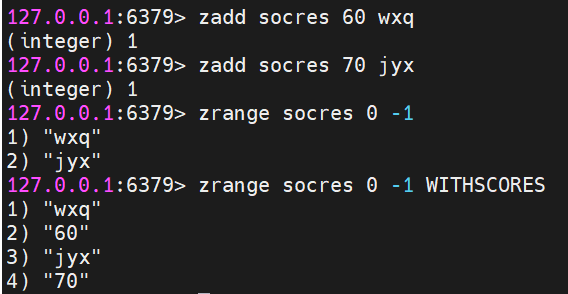
三、主從復制與哨兵模式
Redis的主從復制和哨兵模式是兩種不同的機制,旨在提高系統的可用性和數據冗余度。它們各自有不同的目標和實現方式。
主從復制(Replication)
主從復制是指Redis支持單個master節點對應多個slave節點的一種架構模式。在這種模式下:
-
數據同步:Master節點可以進行讀寫操作,而Slave節點只能進行讀操作。Master會自動將數據更新同步給所有連接的Slave節點。
-
高可用性:通過增加Slave節點數量來提升讀取性能,并提供一定的數據冗余。如果Master節點發生故障,雖然可以通過手動切換到某個Slave節點作為新的Master節點繼續服務,但這個過程需要人工干預,不能自動完成故障轉移。
-
配置簡單:只需要在配置文件中指定slaveof參數即可讓一個Redis實例成為另一個實例的Slave。
哨兵模式(Sentinel)
哨兵模式是在主從復制的基礎上增加了自動故障檢測和自動故障轉移的功能,確保系統具有更高的可用性:
-
監控:哨兵系統可以監控多個Master-Slave集群,持續檢查Master和Slave實例的健康狀態。
-
通知:當發現Master節點不可用時,哨兵系統能夠自動執行故障轉移策略,即將其中一個Slave提升為新的Master,并更新其他Slave的配置指向新的Master。
-
自動化故障轉移:無需人工干預即可完成故障恢復,減少了停機時間。
-
配置管理:哨兵系統還負責客戶端請求的重定向,確保客戶端能夠正確地連接到當前的Master節點。
| 特性 | 主從復制 | 哨兵模式 |
|---|---|---|
| 數據同步 | Master向Slave同步數據 | 在Master失效后,由Sentinel選擇一個Slave晉升為Master并同步數據 |
| 故障處理 | 需要手動干預進行故障轉移 | 自動檢測故障并自動進行故障轉移 |
| 監控能力 | 不具備監控和自動恢復功能 | 提供了對Redis實例的監控及自動恢復服務 |
| 高可用性 | 提供了一定程度的數據冗余,但不保證服務不間斷 | 通過自動故障轉移提高了系統的高可用性 |
| 使用場景 | 適合于讀寫分離、數據備份等需求 | 適用于需要高度自動化運維、減少人為干預的場景 |
創建自定義網絡
docker network create redis-net啟動 Redis Master
docker run -d \--name redis-master \--network redis-net \-p 6379:6379 \redis啟動 Redis Slave
docker run -d \--name redis-slave1 \--network redis-net \redis \redis-server --slaveof redis-master 6379docker run -d \--name redis-slave2 \--network redis-net \redis \redis-server --slaveof redis-master 6379查看是否主從復制連接成功
docker logs redis-slave1
查看當前的主從狀態
可以通過以下命令進入任意一個 Redis 實例來查看其角色(Master 或 Slave)。
檢查 Redis Master 狀態
-- 進入redis-master客戶端
docker exec -it redis-master redis-cliINFO replication會看到類似于以下內容,表明它是某個 Master 的 Slave:

配置并啟動 Sentinel(哨兵)
配置 sentinel.conf 文件,內容如下:
port 26379
dir /tmp
sentinel monitor mymaster redis-master 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 10000
sentinel parallel-syncs mymaster 1注釋:
sentinel 哨兵
monitor 監控器
mymaster 集群名(可以隨便寫)
redis-master 主服務器名字
6379 端口號
1 投票數量(只要投票有1票通過就可以勝任新的主服務器)
down-after-milliseconds 下線時間(主服務器如果5s沒有響應,就將其下線)| 配置項 | 含義 | 示例值 |
|---|---|---|
port | Sentinel 監聽的端口 | 26379 |
dir | Sentinel 工作目錄 | /tmp |
sentinel monitor | 監控的主節點信息 | mymaster redis-master 6379 1 |
sentinel down-after-milliseconds | 多久沒響應視為下線 | 5000 ms |
sentinel failover-timeout | 故障轉移最大等待時間 | 10000 ms |
sentinel parallel-syncs | 同步新 Master 的 Slave 并發數 | 1 |
然后運行 Sentinel 容器:
docker run -d \--name redis-sentinel \--network redis-net \-p 26379:26379 \-v $(pwd)/sentinel.conf:/usr/local/etc/redis/sentinel.conf \redis \redis-sentinel /usr/local/etc/redis/sentinel.conf檢查哨兵是否運行成功:

查看哨兵日志
docker logs redis-sentinel
查看主服務器ip
docker inspect redis-master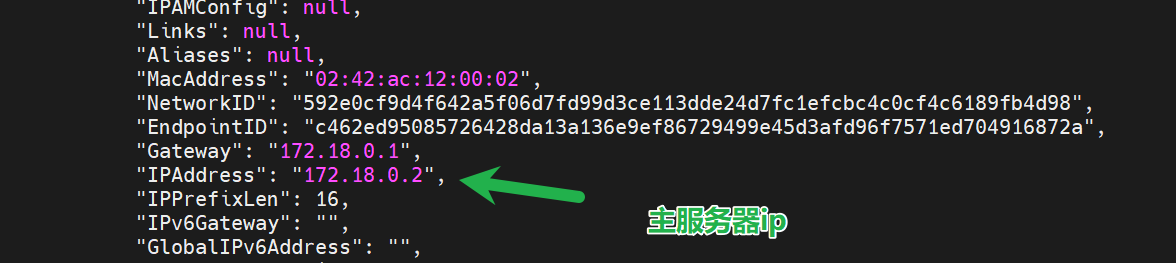
修改哨兵配置文件
vim sentinel.conf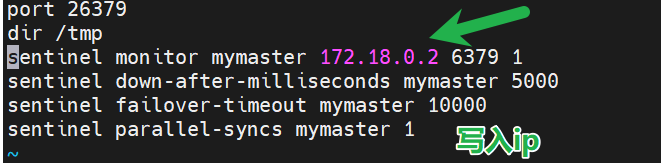
然后重新啟動哨兵
docker restart redis-sentinel
如果怕ip會變,可將ip固定
docker run -d \--name redis-master \--network redis-net \--ip 【查詢詳情里的ip寫入即可】-p 6379:6379 \redis注意:其他服務器也可以固定手動觸發故障轉移
現在讓我們模擬 Master 故障的情況。停止 Redis Master 容器:
docker stop redis-master查看哨兵日志
docker logs redis-sentinel
第一句話意思是:檢測到主服務器掛了
第二句話意思是:已經選擇為172.18.0.4的從服務器為新的主服務器
等待幾秒鐘后,檢查 Sentinel 是否已經將其中一個 Slave 提升為新的 Master。可以通過連接到 Sentinel 來查詢當前的 Master:
docker exec -it redis-sentinel redis-cli -p 26379SENTINEL get-master-addr-by-name mymaster如果一切正常,應該得到新 Master 的 IP 地址和端口。
驗證故障轉移后的狀態
再次使用 INFO replication 命令分別檢查原 Slave(現在應該是新的 Master)和其他 Slave 的狀態,確保它們都正確地進行了角色轉換。
對于新的 Master:
docker exec -it redis-slave1 redis-cliINFO replication會發現它的角色變為 role:master。





)
 創建一個 Sring Boot 項目)







Gradle的優勢、項目結構介紹)
)
)


