線性回歸是機器學習中最基礎、最核心的算法之一,它為我們理解更復雜的模型奠定了基礎。本文將帶你全面解析線性回歸的方方面面。
1. 什么是回歸?
回歸分析用于預測連續型數值。它研究自變量(特征)與因變量(目標)之間的關系。例如:
- 根據房屋面積、地段預測房價
- 根據廣告投入預測產品銷量
核心目標:找到特征與目標之間的最佳映射函數。
2. 線性回歸
核心假設:目標變量(y)與特征變量(x)之間存在線性關系。
模型表達式:
y = w0 + w1*x1 + w2*x2 + ... + wn*xn + ε
y:預測目標w0:偏置項(截距)w1..wn:特征權重(斜率)ε:隨機誤差
3. 損失函數:衡量模型誤差
均方誤差(MSE) 是最常用損失函數:
MSE = (1/m) * Σ(y_i - ?_i)^2
m:樣本數量y_i:真實值?_i:預測值
目標:找到一組權重 w,使 MSE 最小化。
數據: [[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]]
我們假設 這個最優的方程是:
y=wx+by=wx+by=wx+b
這樣的直線隨著w和b的取值不同 可以畫出無數條
在這無數條中,哪一條是比較好的呢?
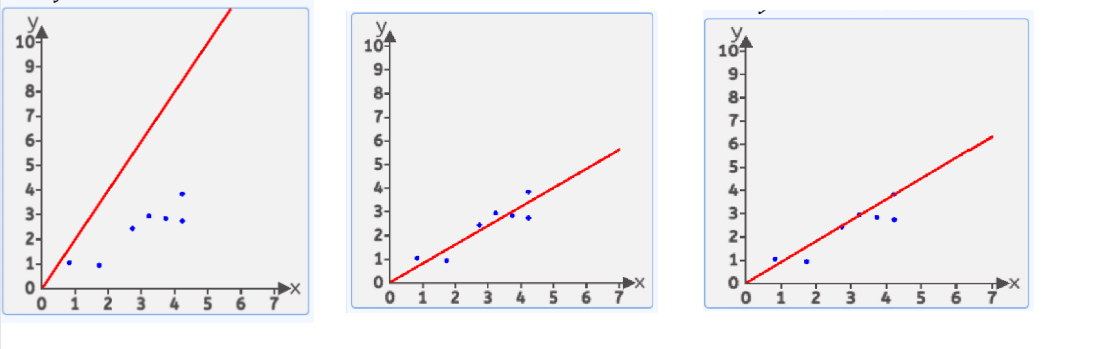
我們有很多方式認為某條直線是最優的,其中一種方式:均方差
就是每個點到線的豎直方向的距離平方 求和 在平均 最小時 這條直接就是最優直線
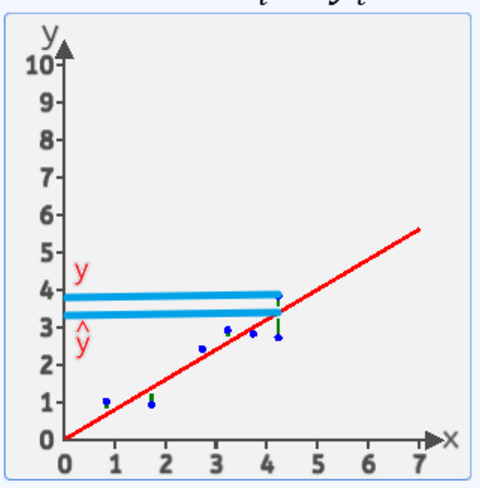
假設: y=wx+by=wx+by=wx+b
把x1,x2,x3...x_1,x_2,x_3...x1?,x2?,x3?...帶入進去 然后得出:
y1,=wx1+by_1^,=wx_1+by1,?=wx1?+b
y2,=wx2+by_2^,=wx_2+by2,?=wx2?+b
y3,=wx3+by_3^,=wx_3+by3,?=wx3?+b
…
然后計算y1?y1,{y_1-y_1^,}y1??y1,? 表示第一個點的真實值和計算值的差值 ,然后把第二個點,第三個點…最后一個點的差值全部算出來
有的點在上面有點在下面,如果直接相加有負數和正數會抵消,體現不出來總誤差,平方后就不會有這個問題了
所以最后:
總誤差(也就是傳說中的損失):
loss1=(y1?y1,)2+(y2?y2,)2+....(yn?yn,)2{(y_1-y_1^,)^2}+{(y_2-y_2^,)^2}+....{(y_n-y_n^,)^2}(y1??y1,?)2+(y2??y2,?)2+....(yn??yn,?)2
平均誤差(總誤差會受到樣本點的個數的影響,樣本點越多,該值就越大,所以我們可以對其平均化,求得平均值,這樣就能解決樣本點個數不同帶來的影響)
這樣就得到了傳說中的損失函數:
eˉ=1n∑i=1n(yi?wxi?b)2\bar e = \frac{1}{n} \textstyle\sum_{i=1}^{n}(y_{i}-w x_{i} - b)^{2}eˉ=n1?∑i=1n?(yi??wxi??b)2
總結
1.實際數據中 x和y組成的點 不一定是全部落在一條直線上
2.我們假設有這么一條直線 y=wx+by=wx+by=wx+b 是最符合描述這些點的
3.最符合的條件就是這個方程帶入所有x計算出的所有y與真實的y值做 均方差計算
4.找到均方差最小的那個w
5.這樣就求出了最優解的函數(前提條件是假設b=0)
4. 多參數回歸
當特征數量 > 1 時,使用矩陣運算更高效:
? = X · w
X:m×(n+1) 維特征矩陣(含偏置列)w:(n+1)×1 維權重向量
上面案例中,實際情況下,影響這種植物高度的不僅僅有溫度,還有海拔,濕度,光照等等因素:
實際情況下,往往影響結果y的因素不止1個,這時x就從一個變成了n個,x1,x2,x3...xnx_1,x_2,x_3...x_nx1?,x2?,x3?...xn? 上面的思路是對的,但是求解的公式就不再適用了
案例: 假設一個人健康程度怎么樣,由很多因素組成
| 被愛 | 學習指數 | 抗壓指數 | 運動指數 | 飲食情況 | 金錢 | 心態 | 壓力 | 健康程度 |
|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 8 | 0 | 5 | -2 | 9 | -3 | 339 |
| -4 | 10 | 6 | 4 | -14 | -2 | -14 | 8 | -114 |
| -1 | -6 | 5 | -12 | 3 | -3 | 2 | -2 | 30 |
| 5 | -2 | 3 | 10 | 5 | 11 | 4 | -8 | 126 |
| -15 | -15 | -8 | -15 | 7 | -4 | -12 | 2 | -395 |
| 11 | -10 | -2 | 4 | 3 | -9 | -6 | 7 | -87 |
| -14 | 0 | 4 | -3 | 5 | 10 | 13 | 7 | 422 |
| -3 | -7 | -2 | -8 | 0 | -6 | -5 | -9 | -309 |
| 11 | 14 | 8 | 10 | 5 | 10 | 8 | 1 | ? |
求如果karen的各項指標是:
被愛:11 學習指數:14 抗壓指數:8 運動指數:10 飲食水平:5 金錢:10 心態:8 壓力:1
那么karen的健康程度是多少?
直接能想到的就是八元一次方程求解:
14w2+8w3+5w5+?2w6+9w7+?3w8=39914w_2+8w_3+5w_5+-2w_6+9w_7+-3w_8=39914w2?+8w3?+5w5?+?2w6?+9w7?+?3w8?=399
?4w1+10w2+6w3+4w4+?14w5+?2w6+?14w7+8w8=?144-4w_1+10w_2+6w_3+4w_4+-14w_5+-2w_6+-14w_7+8w_8=-144?4w1?+10w2?+6w3?+4w4?+?14w5?+?2w6?+?14w7?+8w8?=?144
?1w1+?6w2+5w3+?12w4+3w3+?3w6+2w7+?2w8=30-1w_1+-6w_2+5w_3+-12w_4+3w_3+-3w_6+2w_7+-2w_8=30?1w1?+?6w2?+5w3?+?12w4?+3w3?+?3w6?+2w7?+?2w8?=30
5w1+?2w2+3w3+10w4+5w5+11w6+4w7+?8w8=1265w_1+-2w_2+3w_3+10w_4+5w_5+11w_6+4w_7+-8w_8=1265w1?+?2w2?+3w3?+10w4?+5w5?+11w6?+4w7?+?8w8?=126
?15w1+?15w2+?8w3+?15w4+7w5+?4w6+?12w7+2w8=126-15w_1+-15w_2+-8w_3+-15w_4+7w_5+-4w_6+-12w_7+2w_8=126?15w1?+?15w2?+?8w3?+?15w4?+7w5?+?4w6?+?12w7?+2w8?=126
11w1+?10w2+?2w3+4w4+3w5+?9w6+?6w7+7w8=?8711w_1+-10w_2+-2w_3+4w_4+3w_5+-9w_6+-6w_7+7w_8=-8711w1?+?10w2?+?2w3?+4w4?+3w5?+?9w6?+?6w7?+7w8?=?87
?14w1+4w3+?3w4+5w5+10w6+13w7+7w8=422-14w_1+4w_3+-3w_4+5w_5+10w_6+13w_7+7w_8=422?14w1?+4w3?+?3w4?+5w5?+10w6?+13w7?+7w8?=422
?3w1+?7w2+?2w3+?8w4+?6w6+?5w7+?9w8=?309-3w_1+-7w_2+-2w_3+-8w_4+-6w_6+-5w_7+-9w_8=-309?3w1?+?7w2?+?2w3?+?8w4?+?6w6?+?5w7?+?9w8?=?309
解出 權重 w(w1,w2...w8)w(w_1,w_2...w_8)w(w1?,w2?...w8?) 然后帶入即可求出karen的健康程度
權重即重要程度,某一項的權重越大說明它影響最終健康的程度越大
但是這有一個前提:這個八元一次方程組得有解才行
因此我們還是按照損失最小的思路來求權重 w(w1,w2...w8)w(w_1,w_2...w_8)w(w1?,w2?...w8?)
多元線性回歸:
y,=w1x1+w2x2+....wnxn+by^,=w_1x_1+w_2x_2+....w_nx_n+by,=w1?x1?+w2?x2?+....wn?xn?+b
b是截距,我們也可以使用w0w_0w0?來表示只要是個常量就行
y,=w1x1+w2x2+....wnxn+w0y^,=w_1x_1+w_2x_2+....w_nx_n+w_0y,=w1?x1?+w2?x2?+....wn?xn?+w0?
y,=w1x1+w2x2+....wnxn+w0?1y^,=w_1x_1+w_2x_2+....w_nx_n+w_0*1y,=w1?x1?+w2?x2?+....wn?xn?+w0??1
那么損失函數就是
loss=[(y1?y1,)2+(y2?y2,)2+....(yn?yn,)2]/nloss=[(y_1-y_1^,)^2+(y_2-y_2^,)^2+....(y_n-y_n^,)^2]/nloss=[(y1??y1,?)2+(y2??y2,?)2+....(yn??yn,?)2]/n
如何求得對應的W(w1,w2..w0)W{(w_1,w_2..w_0)}W(w1?,w2?..w0?) 使得loss最小呢?
數學家高斯給出了答案,就是最小二乘法。
5. 最小二乘法(OLS)
h(x)=w1x1+w2x2+w3x3+w4x4+w5x5+w6x6+w7x7+w8x8+w0x0h(x)=w_1x_1+w_2x_2+w_3x_3+w_4x_4+w_5x_5+w_6x_6+w_7x_7+w_8x_8+w_0x_0h(x)=w1?x1?+w2?x2?+w3?x3?+w4?x4?+w5?x5?+w6?x6?+w7?x7?+w8?x8?+w0?x0?
loss=[(h1(x)?y1)2+(h2(x)?y2)2+...(hn(x)?yn)2]/n=1n∑i=1n(h(xi)?yi)2=1n∣∣(XW?y)∣∣2=12∣∣(XW?y)∣∣2這就是傳說中的最小二乘法公式∣∣A∣∣2是歐幾里得范數的平方?也就是每個元素的平方相加loss=[(h_1(x)-y_1)^2+(h_2(x)-y_2)^2+...(h_n(x)-y_n)^2]/n\\=\frac{1}{n} \textstyle\sum_{i=1}^{n}(h(x_{i})-y_{i})^{2}\\=\frac{1}{n}||(XW-y)||^2\\=\frac{1}{2}||(XW-y)||^2 這就是傳說中的最小二乘法公式 \\ ||A||^2 是歐幾里得范數的平方\,也就是每個元素的平方相加loss=[(h1?(x)?y1?)2+(h2?(x)?y2?)2+...(hn?(x)?yn?)2]/n=n1?∑i=1n?(h(xi?)?yi?)2=n1?∣∣(XW?y)∣∣2=21?∣∣(XW?y)∣∣2這就是傳說中的最小二乘法公式∣∣A∣∣2是歐幾里得范數的平方也就是每個元素的平方相加
但求得最合適的w還需對其求導,這里使用鏈式求導,(推薦,因為后期深度學習全是這種):
內部函數是f(W)=XW?yf(W) = XW - yf(W)=XW?y,外部函數是 g(u)=12u2g(u) = \frac{1}{2} u^2g(u)=21?u2,其中 u=f(W)u = f(W)u=f(W)。
外部函數的導數:?g?u=u=XW?y\frac{\partial g}{\partial u} = u = XW - y?u?g?=u=XW?y
內部函數的導數:?f?W=XT\frac{\partial f}{\partial W} = X^T?W?f?=XT
應用鏈式法則,我們得到最終的梯度:?L?W=(?g?u)(?f?W)=(XW?y)XT\frac{\partial L}{\partial W} = \left( \frac{\partial g}{\partial u} \right) \left( \frac{\partial f}{\partial W} \right) = (XW - y) X^T?W?L?=(?u?g?)(?W?f?)=(XW?y)XT
有了W,回到最初的問題:
求如果karen的各項指標是:
被愛:11 學習指數:14 抗壓指數:8 運動指數:10 飲食水平:5 金錢:10 權利:8 壓力:1
那么karen的健康程度是多少?
分別用W各項乘以新的X 就可以得到y健康程度
5.1 矩陣公式關鍵
- 權重解:W=(XTX)?1XTyW=(X^TX)^{-1}X^TyW=(XTX)?1XTy
- 需確保 XTXX^T XXTX 可逆(否則需正則化)
5.3 Scikit-Learn 實現
from sklearn.linear_model import LinearRegressionmodel = LinearRegression()
model.fit(X_train, y_train) # 訓練模型
y_pred = model.predict(X_test) # 預測
5.4 示例代碼(含可視化)
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression# 生成數據
X = np.array([[1], [2], [3]])
y = np.array([2, 4, 5])# 訓練模型
model = LinearRegression()
model.fit(X, y)# 可視化
plt.scatter(X, y, color='blue')
plt.plot(X, model.predict(X), color='red')
plt.title('Linear Regression Fit')
plt.show()
6. 梯度下降(GD):迭代優化法
當特征維度高、數據量大時,最小二乘法計算成本過高,梯度下降成為更優選擇。
6.1 核心概念
通過迭代調整權重,逐步逼近損失函數最小值。
形象比喻:在山頂蒙眼下山,每步沿最陡峭方向前進。
6.2 梯度下降步驟
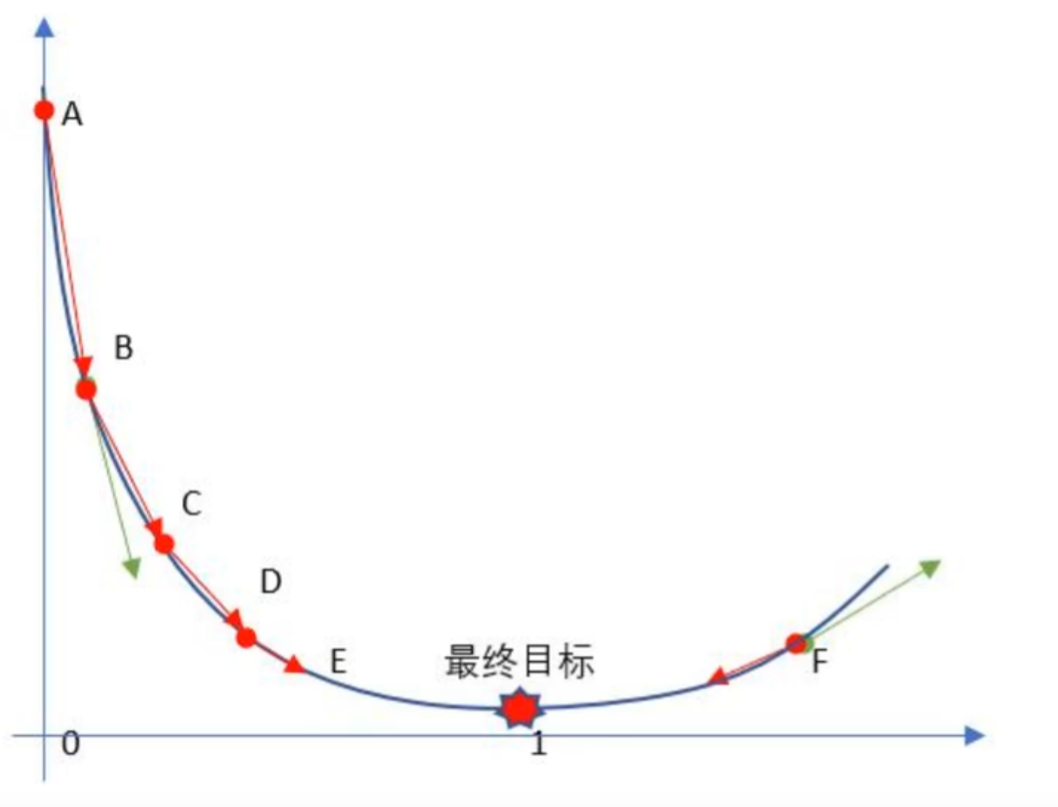
梯度下降流程就是“猜"正確答案的過程:
1、Random隨機數生成初始W,隨機生成一組成正太分布的數值w0,w1,w2....wnw_0,w_1,w_2....w_nw0?,w1?,w2?....wn?,這個隨機是成正太分布的(高斯說的)
2、求梯度g,梯度代表曲線某點上的切線的斜率,沿著切線往下就相當于沿著坡度最陡峭的方向下降.
3、if g < 0,w變大,if g >0,w變小(目標左邊是斜率為負右邊為正 )
4、判斷是否收斂,如果收斂跳出迭代,如果沒有達到收斂,回第2步再次執行2~4步收斂的判斷標準是:隨著迭代進行查看損失函數Loss的值,變化非常微小甚至不再改變,即認為達到收斂
5.上面第4步也可以固定迭代次數
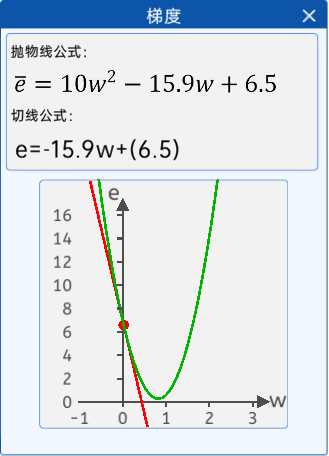
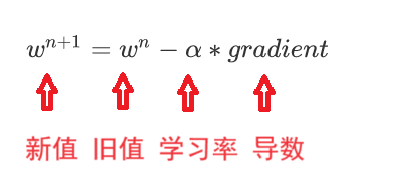
隨機給一個w初始值,然后就不停的修改它,直到達到拋物線最下面附近,比如
w=0.2
w=w-0.01*w為0.2時的梯度(導數) 假設算出來是 0.24
w=w-0.01*w為0.24時的梯度(導數) 假設算出來是 0.33
w=w-0.01*w為0.33時的梯度(導數) 假設算出來是 0.51
w=w-0.01*w為0.51時的梯度(導數) 假設算出來是 0.56
w=w-0.01*w為0.56時的梯度(導數) 假設算出來是 0.58
w=w-0.01*w為0.58時的梯度(導數) 假設算出來是 0.62
就這樣一直更新下去,會在真實值附近,我們可以控制更新的次數
關于隨機的w在左邊和右邊問題:
因為導數有正負
如果在左邊 導數是負數 減去負數就是加 往右移動
如果在右邊 導數是正數 減去正數就是減 往左移動
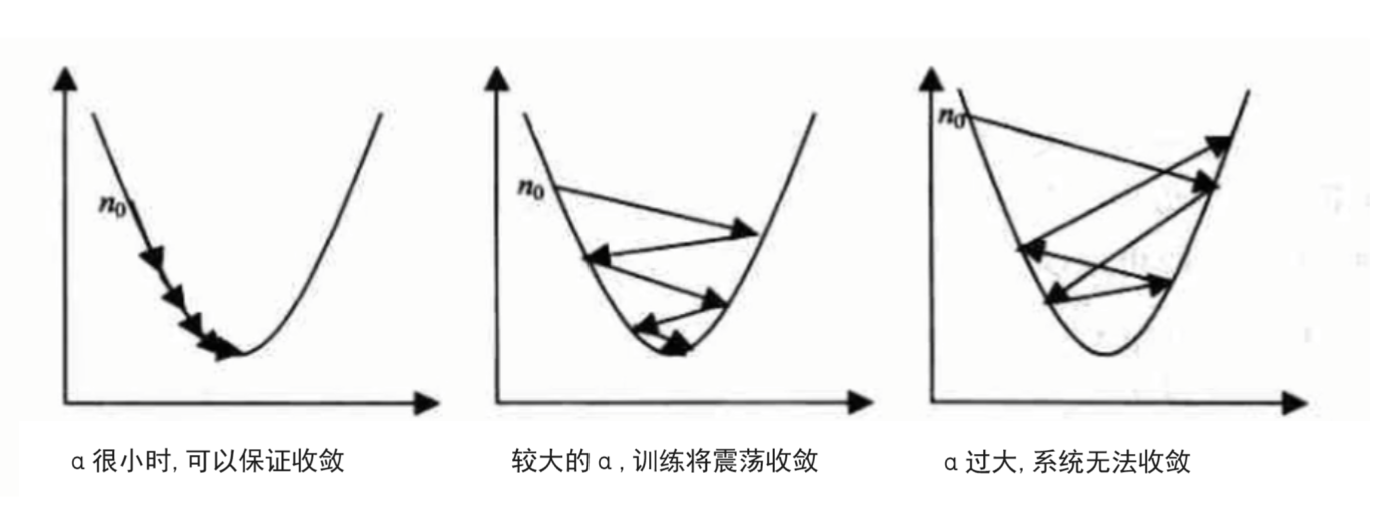
6.3 學習率(α)的重要性
- α 過大:跳過最優解,無法收斂
- α 過小:收斂速度極慢
- 實踐建議:嘗試 0.001、0.01、0.1 等值
6.4 手寫梯度下降實現
我們自己用代碼親自實現一遍梯度下降,之后使用API時就明白它底層的核心實現過程了.
1.假設損失函數是只有一個w1w_1w1?特征的拋物線:
loss(w1)=(w1?3.5)2?4.5w1+10loss(w_1)=(w_1-3.5)^2-4.5w_1+10loss(w1?)=(w1??3.5)2?4.5w1?+10
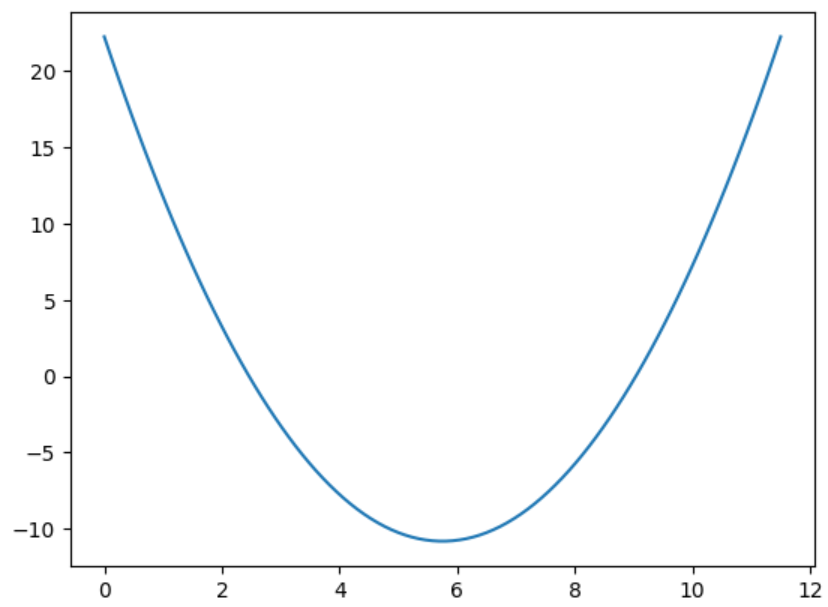
我們要求解這個拋物線最小值時的橫坐標w1w_1w1?的值
#1.列損失函數 畫出函數圖像
loss=lambda w_1:(w_1-3.5)**2-4.5*w_1+10
w_1=np.linspace(0,11.5,100)
plt.plot(w_1,loss(w_1))
#2.求這個損失函數的最小值:梯度下降
def cb():g=lambda w_1:2*(w_1-3.5)-4.5#導函數t0,t1=1,100 alpha=t0/t1#學習率,設置大和過大會導致震蕩或者無法收斂w_1=np.random.randint(0,10,size=1)[0]#隨機初始值#控制更新次數for i in range(1000):alpha=t0/(i+t1)#控制學習率 逐步變小w_1=w_1-alpha*g(w_1)#梯度下降公式print("更新后的w_1:",w_1)
cb()
6.5 Scikit-Learn 實現
官方的梯度下降API常用有三種:
批量梯度下降BGD(Batch Gradient Descent)
小批量梯度下降MBGD(Mini-BatchGradient Descent)
隨機梯度下降SGD(Stochastic Gradient Descent)。
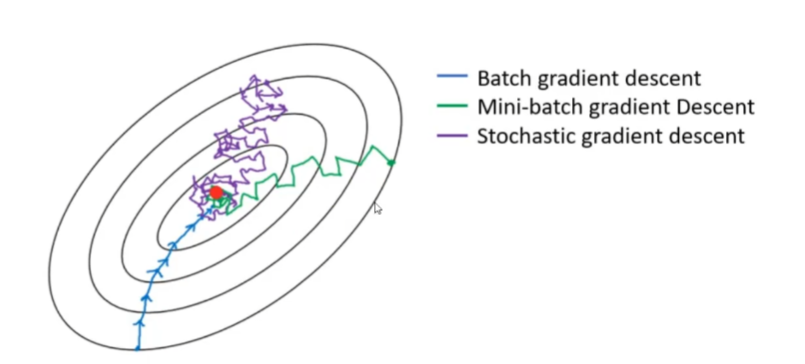
三種梯度下降有什么不同呢?
- Batch Gradient Descent (BGD): 在這種情況下,每一次迭代都會使用全部的訓練樣本計算梯度來更新權重。這意味著每一步梯度更新都是基于整個數據集的平均梯度。這種方法的優點是每次更新的方向是最準確的,但缺點是計算量大且速度慢,尤其是在大數據集上。
- Mini-Batch Gradient Descent (MBGD): 這種方法介于批量梯度下降和隨機梯度下降之間。它不是用全部樣本也不是只用一個樣本,而是每次迭代從數據集中隨機抽取一小部分樣本(例如,從500個樣本中選取32個),然后基于這一小批樣本的平均梯度來更新權重。這種方法在準確性和計算效率之間取得了一個平衡。
- Stochastic Gradient Descent (SGD): 在隨機梯度下降中,每次迭代僅使用隨機單個樣本(或有時稱為“例子”)來計算梯度并更新權重。這種方法能夠更快地收斂,但由于每次更新都基于單個樣本,所以會導致權重更新路徑不穩定。
from sklearn.linear_model import SGDRegressormodel = SGDRegressor(learning_rate='constant', eta0=0.01)
model.fit(X_train, y_train)
梯度下降變體對比
| 類型 | 批量大小 | 速度 | 穩定性 | 適用場景 |
|---|---|---|---|---|
| BGD | 全批量(m) | 慢 | 高 | 小數據集 |
| SGD | 單樣本(1) | 快 | 低(震蕩) | 大規模在線學習 |
| MBGD | 小批量(b) | 中 | 中 | 最常用(b=32/64) |
6.9 梯度下降優化技巧
-
動量(Momentum):
v = β*v + (1-β)*gradient
w = w - α*v
加速收斂,減少震蕩 -
自適應學習率:
- AdaGrad:為每個參數調整 α
- RMSProp:解決 AdaGrad 學習率衰減問題
- Adam(最常用):結合 Momentum 和 RMSProp
-
標準化:前期數據的預處理
正則化:防止過擬合
關鍵總結
- 回歸預測連續值,線性回歸假設線性關系
- MSE是常用損失函數,通過最小化MSE求解模型
- 最小二乘法求解析解,梯度下降求數值解
- 學習率是梯度下降的核心超參數
- MBGD在實踐中最常用,Adam是最流行的優化器
理解線性回歸不僅能解決實際問題,更是學習深度學習、支持向量機等復雜模型的基石。掌握其數學本質和實現細節,才能在機器學習道路上走得更遠。

?? 的開源庫詳解)






檢測頭結構創新,實現有效漲點)


AXI協議總線學習)


![[特殊字符]? 整個鍵盤控制無人機系統框架](http://pic.xiahunao.cn/[特殊字符]? 整個鍵盤控制無人機系統框架)
LogisticRegression)


)
:CountDownLatch 與 Semaphore 的協作應用)