解密 Kubernetes Device Plugin:讓容器輕松駕馭特殊硬件
在容器化技術飛速發展的今天,容器憑借輕量、隔離、可移植的特性成為應用部署的主流選擇。但在實際應用中,當容器需要訪問 GPU、FPGA 等特殊硬件資源時,事情就變得不那么簡單了。Kubernetes 中的 Device Plugin(設備插件)正是為解決這一難題而生,它如同一位“橋梁工程師”,讓容器與宿主機的特殊硬件之間搭建起穩定、高效的溝通通道。
一、容器訪問硬件的“天然障礙”:為什么需要 Device Plugin?
容器的核心優勢之一是“隔離性”——它通過 Linux 命名空間(Namespaces)和控制組(cgroups)等技術,為應用打造獨立的運行環境,同時限制其對宿主機資源的無序占用。這種隔離性在處理 CPU、內存等“標準化資源”時表現出色:
- CPU:容器通過 cgroups 共享宿主機的 CPU 時間片,管理員可通過
--cpus等參數限制使用量; - 內存:同樣依托 cgroups 進行配額管理,
--memory等參數能精準控制內存占用。
然而,當面對 GPU、FPGA、高性能網卡等“特殊硬件”時,容器的隔離性反而成了“絆腳石”。以最常用的 GPU 為例:
- GPU 的設備文件(如
/dev/nvidia0)和驅動庫(如/usr/local/nvidia/lib64)默認不會暴露給容器,否則可能破壞容器的隔離性,甚至導致硬件資源被濫用; - 不同型號的 GPU 驅動依賴不同,容器若想正常調用 GPU,必須匹配宿主機的驅動環境,這與容器“一次打包、到處運行”的理念相悖;
- 集群中 GPU 數量有限,若缺乏統一的調度機制,可能出現多個容器爭搶同一 GPU 的情況,導致資源浪費或應用崩潰。
顯然,CPU、內存等標準化資源的管理方式無法直接套用到特殊硬件上。為了讓容器安全、高效地使用這些“特殊資源”,Kubernetes 引入了 Device Plugin 機制——它既是特殊硬件的“管理員”,也是容器與硬件之間的“翻譯官”。
二、Device Plugin 的核心使命:連接容器與特殊硬件
Device Plugin 的核心作用可以概括為一句話:讓 Kubernetes 集群“感知”特殊硬件的存在,并協調容器對硬件的有序使用。具體來說,它承擔著三大關鍵任務:
1. 設備發現與注冊:讓集群“看見”硬件
宿主機上的特殊硬件(如 GPU 的型號、數量,FPGA 的設備路徑)對 Kubernetes 而言是“隱形”的。Device Plugin 首先要做的,就是讓集群“感知”到這些硬件的存在:
- 自動探測:啟動后,Device Plugin 會掃描宿主機,識別出所有可用的特殊設備(例如檢測到 2 塊 NVIDIA Tesla T4 GPU,設備文件分別為
/dev/nvidia0和/dev/nvidia1); - 資源注冊:將探測到的設備以“標準化名稱”(格式為
vendor-domain/resourcetype,如nvidia.com/gpu)注冊到節點的 kubelet 中。此后,Kubernetes 集群就能通過節點狀態感知到這些資源(例如“該節點有 2 塊nvidia.com/gpu”)。
2. 設備分配與調度:讓容器“按需取用”
當用戶的 Pod 聲明需要特殊硬件(例如在 resources.limits 中指定 nvidia.com/gpu: 1)時,Device Plugin 會配合 Kubernetes 調度器完成資源分配:
- 可用性檢查:檢查節點上的特殊設備是否空閑,避免重復分配(例如確保同一塊 GPU 不會被兩個 Pod 同時占用);
- 精準分配:確定可用設備后,告知 kubelet 具體的設備 ID(如
GPU-abc123),確保 Pod 能“一對一”綁定到硬件。
3. 容器資源注入:讓硬件“為容器所用”
即使設備已分配,容器若無法訪問硬件的驅動和配置,仍無法正常工作。Device Plugin 會通過 Allocate 等方法,將硬件相關的資源“注入”容器:
- 環境變量:例如注入
NVIDIA_VISIBLE_DEVICES=GPU-abc123,告訴容器“使用這塊 GPU”; - 設備文件映射:將宿主機的
/dev/nvidia0等設備文件映射到容器內,讓容器直接與硬件交互; - 驅動掛載:將宿主機的 GPU 驅動庫(如
/usr/local/nvidia/lib64)掛載到容器,解決容器內驅動缺失問題。
通過這三步操作,原本“隔絕”的容器與特殊硬件被緊密連接起來,應用無需修改代碼就能像使用本地硬件一樣調用宿主機的 GPU 等資源。
三、Device Plugin 的工作原理:從注冊到調用的全流程
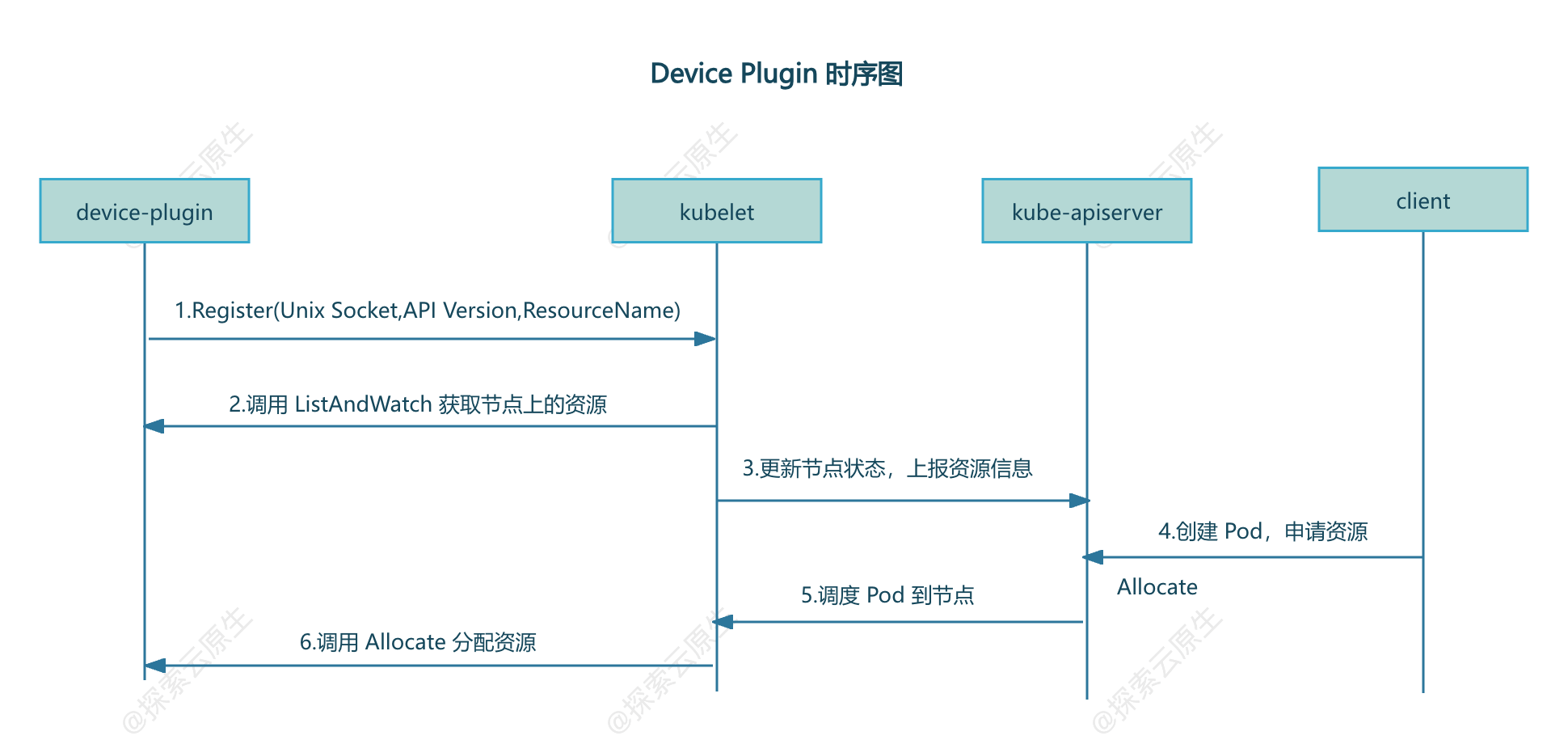
Device Plugin 的工作流程并不復雜,核心是“插件注冊”與“kubelet 調用”的協作,具體可分為以下步驟:
1. 準備階段:kubelet 啟動注冊服務
Kubernetes 節點上的 kubelet 會啟動一個 Registration gRPC 服務(通過宿主機的 kubelet.sock 套接字實現),專門用于接收 Device Plugin 的注冊請求。
2. 注冊階段:插件“自我介紹”
Device Plugin 通常以 DaemonSet 形式部署(確保每個節點都運行一份),啟動后會做一件關鍵事:向 kubelet“報到”。它通過掛載到容器內的 kubelet.sock,調用注冊接口并提供三個核心信息:
- 自身的 unix socket 名稱(方便 kubelet 后續調用);
- 插件的 API 版本(用于版本兼容);
- 管理的資源名稱(如
nvidia.com/gpu,讓 kubelet 知道它能處理哪種資源請求)。
3. 資源發現:kubelet 獲知硬件狀態
注冊成功后,kubelet 會通過 Device Plugin 提供的 socket 調用 ListAndWatch 接口:
List:獲取當前節點上所有可用的特殊設備(如“2 塊 GPU,ID 分別為 GPU-abc123、GPU-def456”);Watch:持續監控設備狀態(如設備故障時及時上報)。
隨后,kubelet 會將這些資源信息更新到節點的狀態中,管理員通過 kubectl get node -o yaml 就能在節點的 Capacity 字段看到 nvidia.com/gpu: 2 這樣的記錄。
4. 資源分配:響應 Pod 的硬件請求
當用戶創建一個申請特殊硬件的 Pod(例如 resources.limits: {nvidia.com/gpu: 1})時:
- Kubernetes 調度器(kube-scheduler)會根據節點上的資源狀態,將 Pod 調度到有可用資源的節點;
- 目標節點的 kubelet 會調用該節點上 Device Plugin 的
Allocate接口,請求分配 1 塊 GPU; - Device Plugin 檢查并鎖定一塊空閑 GPU(如 GPU-abc123),返回設備文件、環境變量等配置信息;
- kubelet 根據返回的配置,在啟動容器時注入設備映射和驅動掛載,確保容器能正常使用 GPU。
四、總結:Device Plugin 是容器擁抱特殊硬件的“關鍵鑰匙”
在云計算和 AI 時代,GPU 等特殊硬件已成為許多應用的“剛需”。Device Plugin 通過標準化的接口和流程,解決了容器訪問特殊硬件時的隔離性、兼容性和調度難題,讓 Kubernetes 集群能夠像管理 CPU、內存一樣管理 GPU、FPGA 等資源。
無論是 AI 訓練任務調用 GPU,還是邊緣計算場景使用 FPGA 加速,Device Plugin 都在默默扮演“橋梁”的角色——它讓容器技術突破了“只能用標準化資源”的局限,為更廣泛的硬件加速場景打開了大門。
五、參考文章
- https://www.lixueduan.com/posts/kubernetes/21-device-plugin/#1-%E8%83%8C%E6%99%AF
- https://kubernetes.io/zh-cn/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/
- https://www.myway5.com/index.php/2020/03/24/kubernetes-device-plugin/





![[創業之路-527]:什么是產品技術成熟度曲線?](http://pic.xiahunao.cn/[創業之路-527]:什么是產品技術成熟度曲線?)











)

