Spring Boot 2.1.18 集成 Elasticsearch 6.6.2 實戰指南
- 前言:
- 一. JAVA客戶端對比
- 二. 導入數據
- 2.1 分析創建索引
- 2.2 代碼實現
- 三. ElasticSearch 查詢
- 3.1 matchAll 查詢
- 3.2 term查詢
- 3.3 match查詢
- 3.4 模糊查詢
- 3.5 范圍查詢
- 3.6 字符串查詢
- 3.7 布爾查詢
- 3.8 分頁與排序
- 3.9 聚合查詢
- 3.10 高亮查詢
- 四. 重建索引&索引別名
- 五. ElasticSearch 增刪改文檔
- 六. ElasticsearchRepository基本使用
- 七. Elasticsearch 集群搭建
- 7.1 集群及分布式介紹
- 7.2 相關概念
- 7.3 集群搭建
- 7.4 JavaAPI 操作集群
- 7.5 分片配置
- 7.6 路由原理
- 7.7 腦裂
- 八、關鍵注意事項
前言:
本文主要講述的是springboot2.1.18和java 1.8情況下集成elasticsearch,由于Spring Boot 2.1.x默認支持的是Elasticsearch 6.4.x,而我們選擇的是6.6.2版本,因此可能需要手動管理版本,確保版本兼容。
在上篇文章ElasticSearch的概念、安裝、以及與spring boot簡單整合中我是搭建HighLevel客戶端集成到Springboot項目中,本文主要講述的是用spring-data-elasticsearch的集成到SpringBoot項目中,也會重點講一下ElasticsearchTemplate的各種查詢方法以及可能出現的一些問題。
一. JAVA客戶端對比
目標:理解不同客戶端的區別,能夠在項目中選擇合適的客戶端
transportclient:通過監聽9300端口tcp進行數據傳輸,它可以觸摸到es的API和結構,此客戶端對ES的版本兼容性較差,并且它在高并發環境下會有性能問題。
restclient:restclient就是采用http協議進行交互,它相比transportclient最大的好處就是對ES版本兼容性較好。restclient也分為high-level和low-level兩種,兩者原理基本一致,區別最大的就是封裝性。low-level各種操作都要你自己封裝,并且java本身不支持json還需要引用第三方包。而high-level是針對elasticsearch的api進行高級封裝,和elasticsearch的版本關聯大一些。
spring-data-elasticsearch:spring官方提供的框架,使用起來非常方便,3.2.0 版本之前是基于transportclient封裝的,在此之后是基于HighLevelRestClient進行封裝的,因此建議使用3.2.0 及以后的版本。
spring-boot-starter-data-elasticsearch:springboot官方提供的客戶端,內部使用spring-data-elasticsearch,springboot-2.2(對應spring-data-elasticsearch-3.2.0)
| Spring Boot 版本 | Spring Data Elasticsearch 版本 | 兼容的 Elasticsearch 版本 | 最低 Java 版本 |
|---|---|---|---|
| 3.2.x | 5.2.x | 8.10.x - 8.11.x | Java 17 |
| 3.1.x | 5.1.x | 8.6.x - 8.9.x | Java 17 |
| 3.0.x | 5.0.x | 8.4.x - 8.5.x | Java 17 |
| 2.7.x(LTS) | 4.4.x | 7.17.x(LTS) | Java 11(推薦)/ Java 8 |
| 2.6.x | 4.3.x | 7.15.x - 7.16.x | Java 8 |
| 2.5.x | 4.2.x | 7.12.x - 7.14.x | Java 8 |
| 2.4.x | 4.1.x | 7.9.x - 7.11.x | Java 8 |
| 2.3.x | 4.0.x | 7.6.x - 7.8.x | Java 8 |
| 2.2.x | 3.2.x | 6.8.x | Java 8 |
| 2.1.x | 3.1.x | 6.4.x - 6.7.x | Java 8 |
| 2.0.x | 3.0.x | 5.5.x - 6.3.x | Java 8 |
?
該如何選擇客戶端?
- 若使用的是springboot項目(spring-boot-starter-data-elasticsearch啟動器),建議使用springboot-2.2以后版本
- 若只是一個普通spring項目,使用spring-data-elasticsearch-3.2.0以后版本。
- 若以上兩種都不是,建議使用HighLevelRestClient,而非transportclient
二. 導入數據
2.1 分析創建索引
目標:理解如何分析數據并創建索引庫
需求:將數據庫中Goods表的數據導入到ElasticSearch中,數據需要自己造一點
創建腳本如下:
PUT goods
{"mappings": {"_doc": {"properties": {"title": {"type": "text","analyzer": "ik_smart"},"price": {"type": "double"},"num": {"type": "integer"},"category": {"type": "keyword"},"brand": {"type": "keyword"}}}}
}
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '商品id,同時也是商品編號',`title` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品標題',`price` decimal(20, 2) NOT NULL COMMENT '商品價格,單位為:元',`num` int(10) NOT NULL COMMENT '庫存數量',`category` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品類別',`brand` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌名稱',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1369284 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '商品表' ROW_FORMAT = Dynamic;
字段說明:
- title:商品標題
- price:商品價格
- num:商品庫存
- category:商品類別
- brand:品牌名稱
添加文檔進行測試:
PUT goods/_doc/1
{"title": "小米手機","price": 1000,"num": 10000,"category": "手機","brand": "小米"
}
2.2 代碼實現
目標:使用ElasticsearchTemplate批量添加文檔到goods索引庫
1)創建maven工程
2)添加相關依賴包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/2.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/2.0.0 http://maven.apache.org/xsd/maven-2.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.18.RELEASE</version></parent><groupId>cn.explame</groupId><artifactId>springboot_es2</artifactId><version>1.0-SNAPSHOT</version><dependencies><!--test啟動器--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><!--es啟動器--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><!--mybatis啟動器--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.1.3</version></dependency><!--mysql驅動包--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>provided</scope></dependency><!-- Java工具包 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency></dependencies></project>
3)創建啟動類
package cn.explame;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class ElasticApplication {public static void main(String[] args) {SpringApplication.run(ElasticApplication.class, args);}
}
4)創建并編寫application.yml文件
spring:data:# es連接信息elasticsearch:cluster-name: elasticsearchcluster-nodes: 192.168.211.129:9300# 數據庫連接信息datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/esusername: rootpassword: 123456# mybatis配置
mybatis:# 指定xml文件位置mapper-locations:- classpath:/mappers/*.xmltype-aliases-package: cn.explame.pojo
5)編寫實體類Goods
package cn.explame.pojo;import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;/*** 商品表** @Author LK* @Date 2021/2/25*/
@Document(indexName = "goods", type = "_doc")
public class Goods {// 商品id@Id // 指定id,對應到ES中的_Idprivate Long id;// 商品標題@Field(type = FieldType.Text, analyzer = "ik_smart")private String title;// 商品價格@Field(type = FieldType.Double)private Double price;// 商品庫存@Field(type = FieldType.Integer)private Integer num;// 商品類別@Field(type = FieldType.Keyword)private String category;// 品牌名稱@Field(type = FieldType.Keyword)private String brand;public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public Double getPrice() {return price;}public void setPrice(Double price) {this.price = price;}public Integer getNum() {return num;}public void setNum(Integer num) {this.num = num;}public String getCategory() {return category;}public void setCategory(String category) {this.category = category;}public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}}
6)創建GoodsDao數據訪問層
package cn.explame.dao;import cn.explame.pojo.Goods;
import org.apache.ibatis.annotations.Mapper;import java.util.List;/*** 商品數據訪問層** @Author LK* @Date 2021/2/25*/
@Mapper
public interface GoodsDao {public List<Goods> findAll();
}
7)在resources目錄下創建mappers文件夾,創建并編寫GoodsMapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 2.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.explame.dao.GoodsDao"><select id="findAll" resultType="Goods">select * from goods</select>
</mapper>
8)編寫單元測試用例
package cn.explame.dao;import cn.explame.pojo.Goods;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.IndexQuery;
import org.springframework.test.context.junit4.SpringRunner;import java.util.ArrayList;
import java.util.List;/*** TODO** @Author LK* @Date 2021/2/22*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class GoodsDaoTest {@Autowiredprivate ElasticsearchTemplate template;@Autowiredprivate GoodsDao goodsDao;@Testpublic void importData() throws Exception {// 1.查詢數據庫數據List<Goods> goodsList = goodsDao.findAll();// 如果不通過腳本操作,可以先創建索引庫// template.createIndex(Goods.class);// 如果不通過腳本操作,指定映射// template.putMapping(Goods.class);// 2.循環創建請求對象if (goodsList != null) List<IndexQuery> queries = new ArrayList<>();for (Goods goods : goodsList) {// 2.1 創建請求對象IndexQuery indexQuery = new IndexQuery();indexQuery.setObject(goods);// 2.2 添加請求對象queries.add(indexQuery);}// 2.執行操作,無返回值template.bulkIndex(queries);}}}
運行結果:
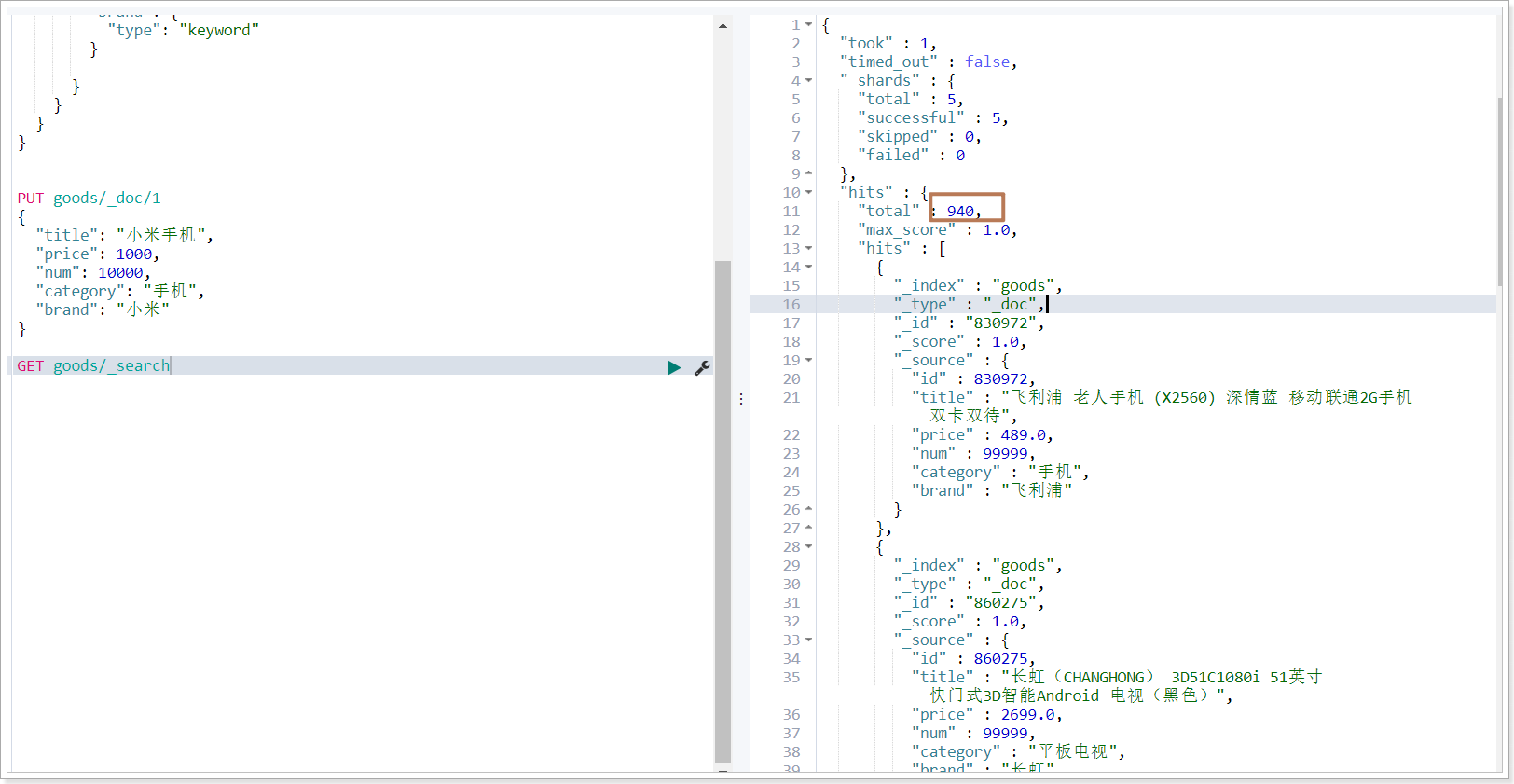
注解說明
- @Document(indexName = “goods”, type = “_doc”) // 指定對應索引庫以及類型
- @Id // 指定對應ES中_id的字段
- @Field(type = FieldType.Text, analyzer = “ik_smart”) // 指定字段的數據類型,以及分詞器
- 添加文檔前,先創建索引庫、類型、映射信息
三. ElasticSearch 查詢
3.1 matchAll 查詢
目標:掌握matchAll查詢的應用場景以及代碼實現
應用場景:當查詢列表的頁面初始化時,沒有任何查詢條件
腳本操作
# GET 索引庫名稱/_search,默認展示10條數據
GET goods/_search
{"query": {"match_all": {}}
}
代碼操作
1)改造Goods實體類,添加toString方法
package cn.explame.pojo;import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;/*** 商品表** @Author LK* @Date 2021/2/25*/
@Document(indexName = "goods", type = "_doc")
public class Goods {// 商品id@Id // 指定idprivate Long id;// 商品標題@Field(type = FieldType.Text, analyzer = "ik_smart")private String title;// 商品價格@Field(type = FieldType.Double)private Double price;// 商品庫存@Field(type = FieldType.Integer)private Integer num;// 商品類別@Field(type = FieldType.Keyword)private String category;// 品牌名稱@Field(type = FieldType.Keyword)private String brand;public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public Double getPrice() {return price;}public void setPrice(Double price) {this.price = price;}public Integer getNum() {return num;}public void setNum(Integer num) {this.num = num;}public String getCategory() {return category;}public void setCategory(String category) {this.category = category;}public String getBrand() {return brand;}public void setBrand(String brand) {this.brand = brand;}@Overridepublic String toString() {return "Goods{" +"id=" + id +", title='" + title + '\'' +", price=" + price +", num=" + num +", category='" + category + '\'' +", brand='" + brand + '\'' +'}';}
}
2)編寫測試用例
/*** 匹配全部查詢*/
@Test
public void matchAllTest(){// 構建查詢條件SearchQuery query = new NativeSearchQuery(QueryBuilders.matchAllQuery());// 執行查詢,獲取運行結果List<Goods> goodsList = template.queryForList(query, Goods.class);for (Goods goods : goodsList) {System.out.println(goods);}
}
運行結果:
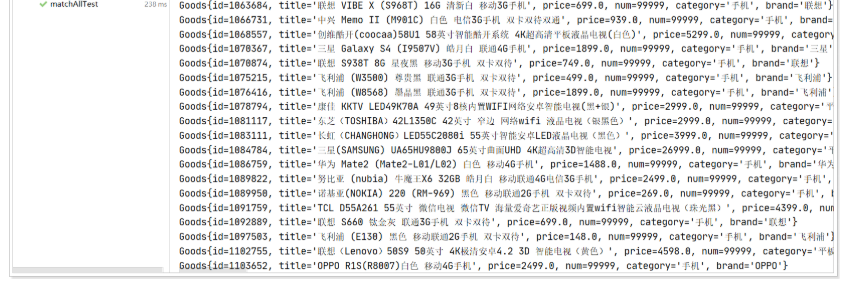
3.2 term查詢
目標:掌握term查詢的應用場景以及代碼實現
應用場景:不想對搜索關鍵字進行分詞,搜索的結果更加精確。
腳本操作
GET goods/_search
{"query": {"term": {"title": {"value": "老人手機"}}}
}
執行搜索可以發現結果為空,為何?在前一天我們其實已經學過,term搜索是將搜索關鍵字的整個內容作為詞條去倒排索引中進行詞條的等值匹配。如果倒排索引中并沒有分出"老人手機"這個詞,就搜索不到。我們可以通過ES提供的接口看看某字符串按某分詞器分出的效果:
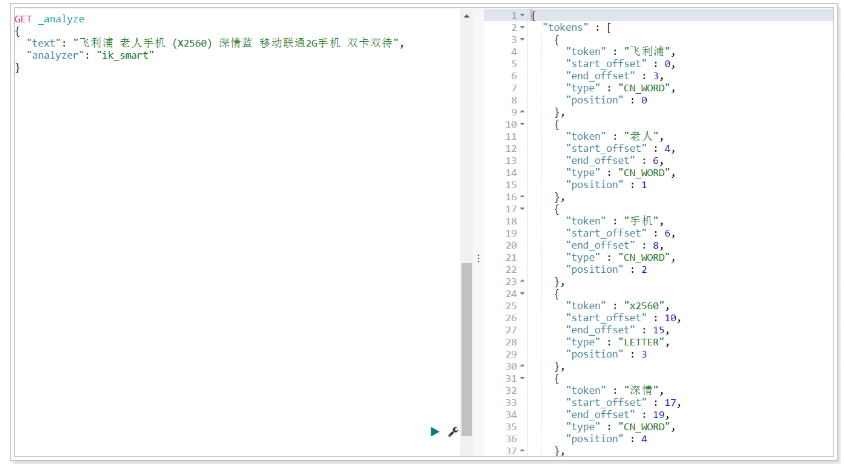
代碼操作
/*** term查詢*/
@Test
public void termTest(){// 構建查詢條件SearchQuery query = new NativeSearchQuery(QueryBuilders.termQuery("title", "老人手機"));// 執行查詢,獲取運行結果List<Goods> goodsList = template.queryForList(query, Goods.class);for (Goods goods : goodsList) {System.out.println(goods);}
}
3.3 match查詢
目標:掌握match查詢的應用場景以及代碼實現
應用場景:想對搜索關鍵字進行分詞,搜索的結果更全面
特點
-
會對查詢條件進行分詞
-
然后將分詞后的查詢條件和詞條進行等值匹配
-
默認取并集(OR)
腳本操作
GET goods/_search
{"query": {"match": {"title": "老人手機"}}
}
運行結果:
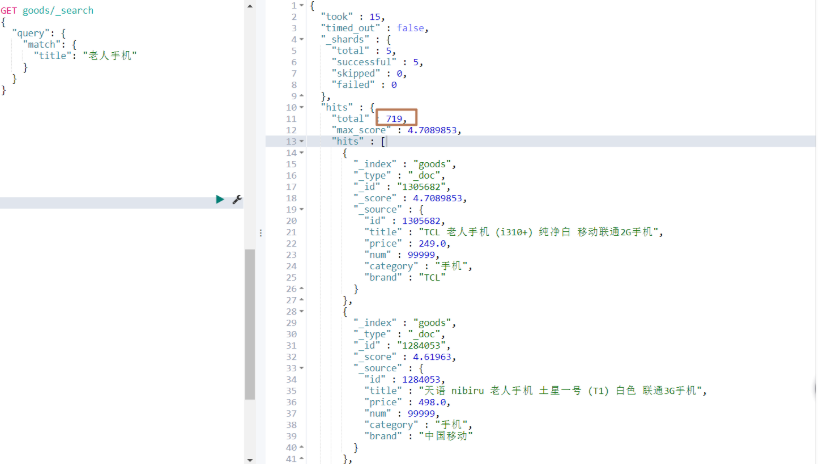
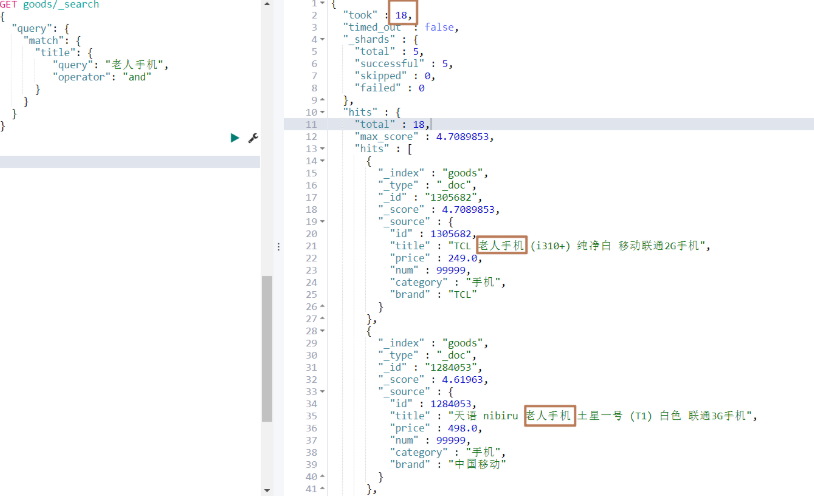
若想要結果取交集(既包含手機,又包含老人),可以如下進行操作
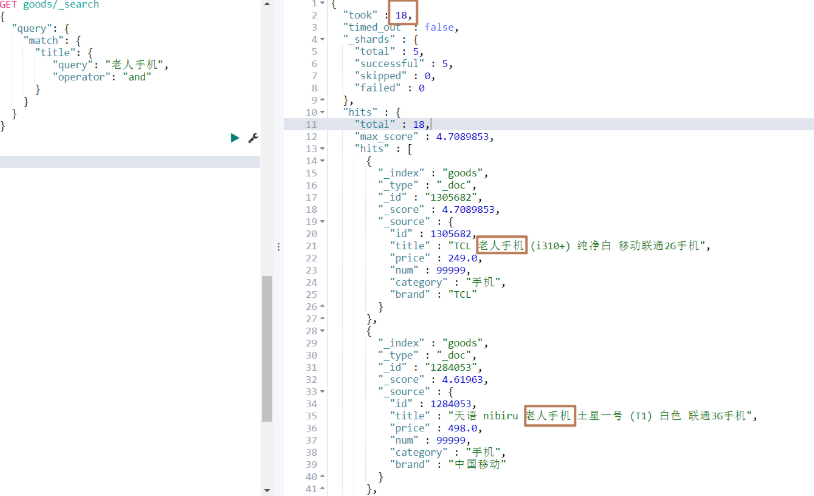
代碼操作
/*** match查詢*/
@Test
public void matchTest(){// 構建查詢條件SearchQuery query = new NativeSearchQuery(QueryBuilders.matchQuery("title", "老人手機").operator(Operator.AND));// 執行查詢,獲取運行結果
List<Goods> goodsList = template.queryForList(query, Goods.class);for (Goods goods : goodsList) {System.out.println(goods);}
}
3.4 模糊查詢
目標:掌握模糊查詢的應用場景以及代碼實現
應用場景:當使用match搜索仍然查詢不到數據,可以嘗試使用模糊查詢,范圍更廣
樣例:
GET goods/_search
{"query": {"match": {"title": "華"}}
}
運行結果:
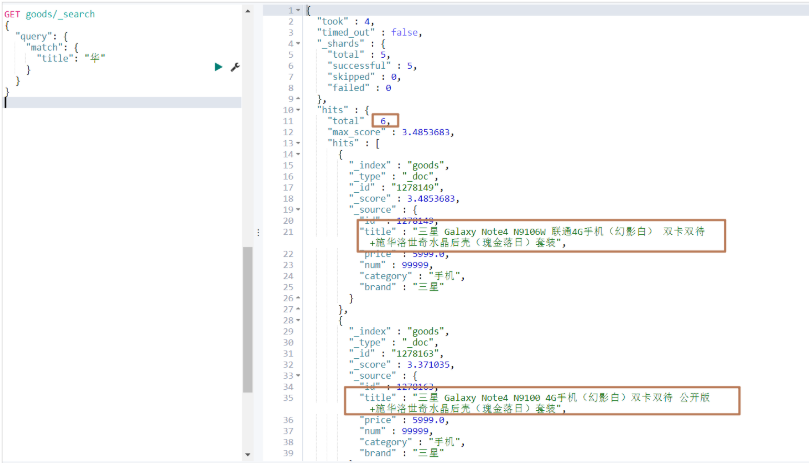
可以發現查詢的結果中,那些title包含"華為"的數據查不出來,因為那些數據,沒有分出"華"這一個字,而分出的就是"華為",這個時候我們若想把包含"華為"的數據都查出來,就可以使用模糊查詢。
wildcard查詢特點
-
會對查詢條件進行分詞
-
分出的詞和索引庫的詞條進行模糊匹配,可以使用通配符 ?(任意單個字符) 和 * (0個或多個字符)
-
默認取結果并集
腳本操作
# 模糊匹配索引庫中以華開頭的詞條,注意不要在華前面使用通配符,否則就和mysql數據庫一樣,索引失效了
GET goods/_search
{"query": {"wildcard": {"title": {"value": "華*"}}}
}
運行結果:
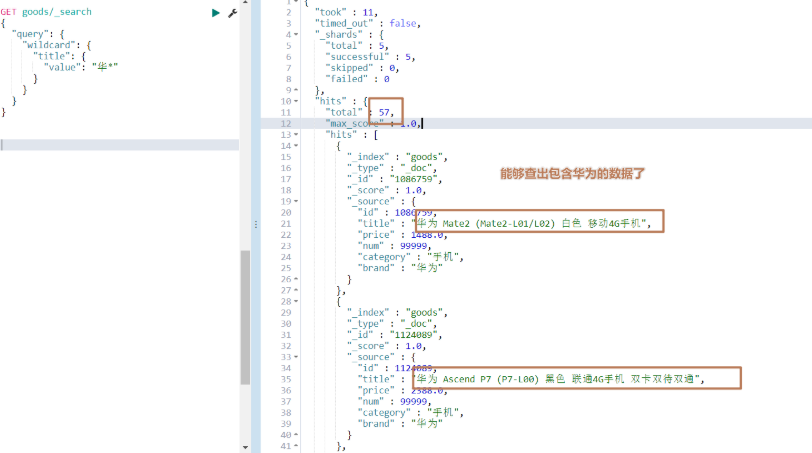
代碼操作
/*** wildcard查詢*/
@Test
public void wildcardTest(){// 構建查詢條件SearchQuery query = new NativeSearchQuery(QueryBuilders.wildcardQuery("title", "華*"));// 執行查詢,獲取查詢結果List<Goods> goodsList = template.queryForList(query, Goods.class);for (Goods goods : goodsList) {System.out.println(goods);}
}
3.5 范圍查詢
目標:掌握范圍查詢的應用場景以及代碼實現
應用場景:當想對數值類型的字段做區間的搜索,例如商品價格。
腳本操作
# 價格大于等于2000,小于等于3000
# gte: >= lte:<= gt:> lt:<
GET goods/_search
{"query": {"range": {"price": {"gte": 2000,"lte": 3000}}}
}
代碼操作
/*** ranage查詢*/
@Test
public void rangeTest(){// 構建查詢條件SearchQuery query = new NativeSearchQuery(QueryBuilders.rangeQuery("price").gte(2000).lte(3000));// 執行查詢,返回結果List<Goods> goodsList = template.queryForList(query, Goods.class);for (Goods goods : goodsList) {System.out.println(goods);}
}
3.6 字符串查詢
目標:掌握字符串查詢的應用場景以及代碼實現
應用場景:當不知道搜索的內容存儲在哪個字段時,可以使用字符串搜索
特點
- 會對查詢條件進行分詞
- 將分詞后的查詢條件和詞條進行等值匹配
- 默認取并集(OR)
- 可以指定多個查詢字段
腳本操作
1)不指定字段
GET goods/_search
{"query": {"query_string": {"query": "華為手機"}}
}
2)指定字段
GET goods/_search
{"query": {"query_string": {"fields": ["title", "brand"],"query": "華為手機"}}
}
運行結果:
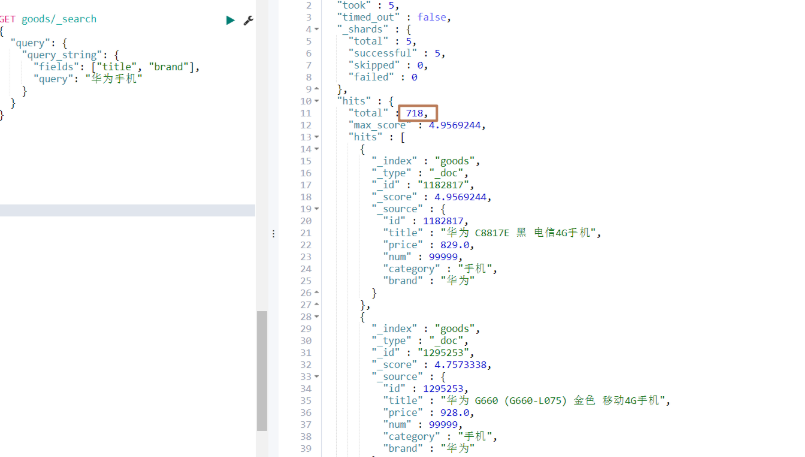
代碼操作
/*** 字符串查詢*/
@Test
public void stringTest(){// 構建查詢條件SearchQuery query = new NativeSearchQuery(QueryBuilders.queryStringQuery("華為手機").field("title").field("brand"));// 執行查詢,獲取查詢結果List<Goods> goodsList = template.queryForList(query, Goods.class);for (Goods goods : goodsList) {System.out.println(goods);}
}
3.7 布爾查詢
目標:掌握布爾查詢的應用場景以及代碼實現
應用場景:當存在多個查詢條件時
語法
must(and):條件必須成立
must_not(not):條件必須不成立,必須和must或filter連接起來使用
should(or):條件可以成立
filter:條件必須成立,性能比must高(不會計算得分)
腳本操作
# 查詢品牌為華為,并且title包含手機的數據
GET goods/_search
{"query": {"bool": {"must": [ # must可以改為filter{"term": {"brand": {"value": "華為"}}},{"match": {"title": "手機"}}]}}
}
運行結果:
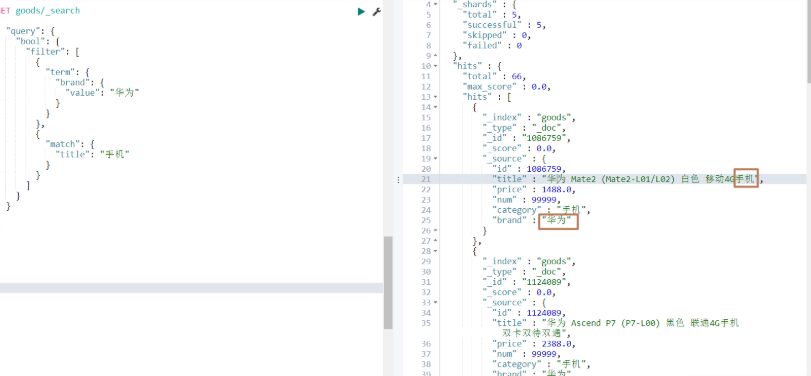
如果想詞條查詢品牌為華為,或title包含手機的數據,即如下所示:
GET goods/_search
{"query": {"bool": {"should": [{"term": {"brand": {"value": "華為"}}},{"match": {"title": "手機"}}]}}}
代碼操作
/*** bool查詢:詞條查詢品牌為華為,并且title包含手機的數據*/
@Test
public void boolTest(){// 構建查詢條件BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.termQuery("brand", "華為"));boolQueryBuilder.must(QueryBuilders.matchQuery("title", "手機"));SearchQuery query = new NativeSearchQuery(boolQueryBuilder).setPageable(PageRequest.of(0, 20));// 執行查詢,獲取查詢結果List<Goods> goodsList = template.queryForList(query, Goods.class);for (Goods goods : goodsList) {System.out.println(goods);}
}
3.8 分頁與排序
目標:掌握分頁與排序的API
腳本操作
# GET 索引庫名稱/_search,默認展示10條數據
GET goods/_doc/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "desc" # 根據價格降序排序}}],"from": 0, # 從哪一條開始"size": 20 # 顯示多少條
}
代碼操作
/*** 分頁與排序*/
@Test
public void pageAndSort(){// pageRequest.of,參數1-當前頁(從0開始,0代表第一頁),參數2-每頁顯示數量SearchQuery query = new NativeSearchQuery(QueryBuilders.matchAllQuery()).setPageable(PageRequest.of(0, 20));// 設置排序參數,根據價格降序排序query.addSort(new Sort(Sort.Direction.DESC, "price"));// 執行查詢,返回結果AggregatedPage<Goods> page = template.queryForPage(query, Goods.class);List<Goods> goodsList = page.getContent(); // 獲取文檔數據System.out.println("總頁數 = " + page.getTotalPages());System.out.println("當前頁 = " + (page.getNumber() + 1));System.out.println("總條數 = " + page.getTotalElements());System.out.println("每頁顯示條數 = " + page.getNumberOfElements());for (Goods goods : goodsList) {System.out.println(goods);}
}
3.9 聚合查詢
目標:掌握聚合查詢的應用場景以及代碼實現
- 指標聚合:相當于MySQL的聚合函數。max、min、avg、sum等
- 桶聚合:相當于MySQL的 group by 操作。(不要對text類型的數據進行分組,會失敗)
腳本操作
1)指標聚合
# 查詢價格最貴的華為
GET goods/_search
{"query": {"match": {"title": "華為"}},"aggs": {"max_price": { # max_price可以自定義名稱"max": {"field": "price"}}}
}
運行結果:
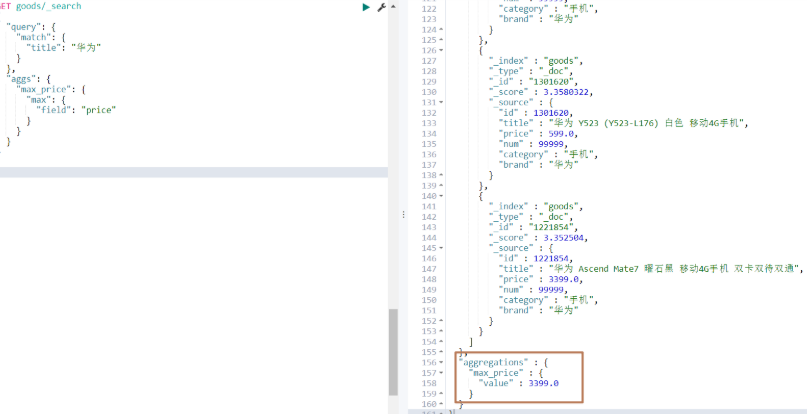
2)桶聚合
# 查詢title包含手機的品牌
GET goods/_search
{"query": {"match": {"title": "手機"}},"aggs": {"NAME": {"terms": {"field": "brand","size": 200}}}
}
運行結果:
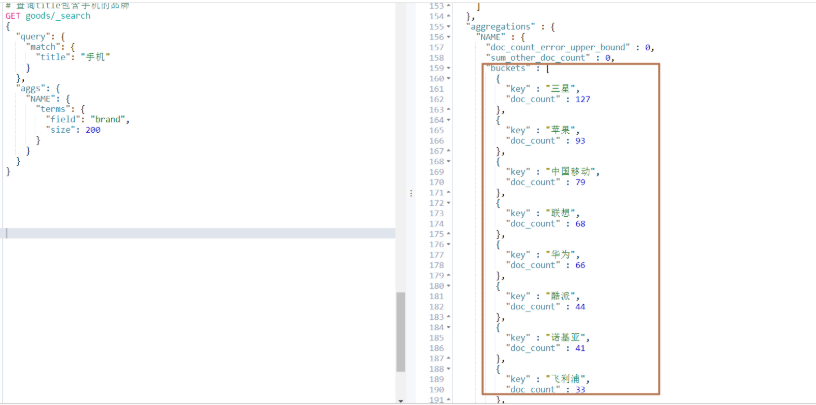
代碼操作
1)指標聚合
/*** 聚合查詢*/
@Test
public void aggregateTest(){// 構造查詢條件NativeSearchQueryBuilder query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "手機"));// 添加聚合條件query.addAggregation(AggregationBuilders.max("max_price").field("price"));// 執行查詢,獲取查詢結果AggregatedPage<Goods> page = template.queryForPage(query.build(), Goods.class);// 獲取聚合函數結果Max maxPrice = (Max)page.getAggregation("max_price");System.out.println(max.getValue());}
運行結果:

2)桶聚合
/*** 聚合查詢*/
@Test
public void aggregateTest2(){// 構造查詢條件NativeSearchQueryBuilder query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "手機"));// 添加聚合條件query.addAggregation(AggregationBuilders.terms("goods_brand").field("brand"));// 執行查詢,獲取查詢結果AggregatedPage<Goods> page = template.queryForPage(query.build(), Goods.class);// 獲取聚合函數結果Terms terms = (Terms) page.getAggregation("goods_brand");List<? extends Terms.Bucket> buckets = terms.getBuckets();for (Terms.Bucket bucket : buckets) {System.out.println(bucket.getKey() + "," + bucket.getDocCount());}
}
運行結果:

3.10 高亮查詢
目標:掌握高亮查詢的代碼實現
分析:高亮顯示如何實現?
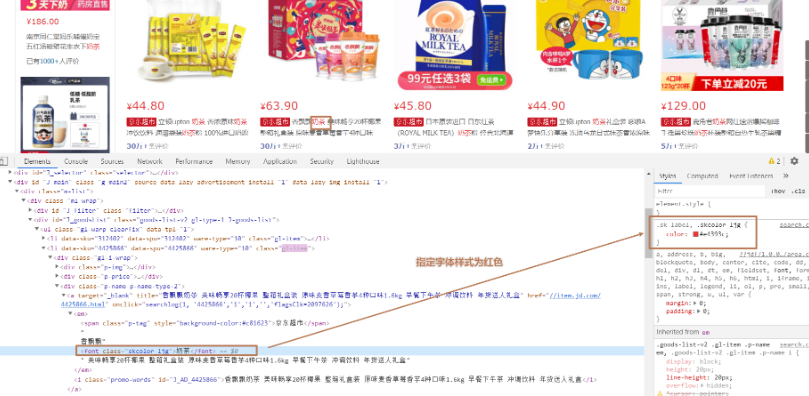
高亮三要素:
- 高亮字段
- 前綴
- 后綴
腳本操作
GET goods/_search
{"query": {"match": {"title": "華為"}},"highlight": {"fields": {"title": {"pre_tags": "<font color='red'>","post_tags": "</font>"}}}
}
運行結果:
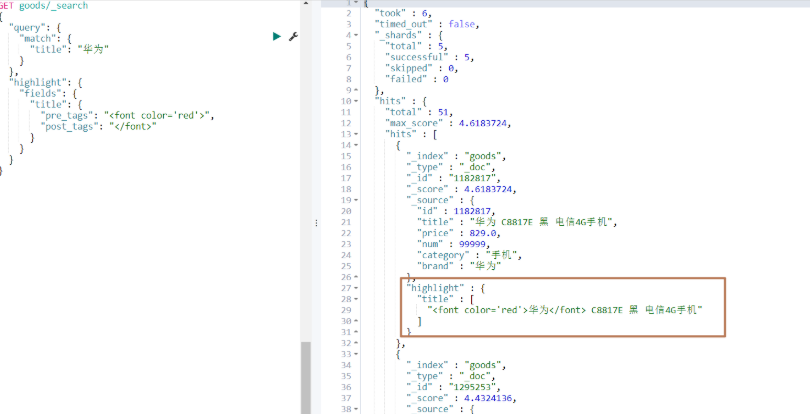
代碼操作
/*** 高亮查詢*/
@Test
public void highLightTest() {// 構造查詢條件NativeSearchQueryBuilder query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("title", "華為")).withPageable(PageRequest.of(0, 10));// 設置高亮前綴后綴String preTag = "<font color='red'>";String postTag = "</font>";// 設置高亮對象query.withHighlightFields(new HighlightBuilder.Field("title").preTags(preTag).postTags(postTag));// 執行查詢,獲取查詢結果AggregatedPage<Goods> page = template.queryForPage(query.build(), Goods.class, new SearchResultMapper() {@Overridepublic <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> aClass, Pageable pageable) {List<Goods> goodsList = new ArrayList<>();// 通過響應對象獲取返回數據SearchHits hits = searchResponse.getHits();try {// 遍歷文檔數據for (SearchHit hit : hits) {String sourceJsonString = hit.getSourceAsString();// 將文檔json轉為對象Goods goods = new ObjectMapper().readValue(sourceJsonString, Goods.class);// 獲取title高亮顯示封裝后的數據Map<String, HighlightField> highlightFields = hit.getHighlightFields();if (highlightFields != null) {HighlightField title = highlightFields.get("title");if (title != null) {String titleAfterHighlight = title.getFragments()[0].toString();// 重新設置title為高亮顯示封裝后的數據goods.setTitle(titleAfterHighlight);}}goodsList.add(goods);}if (goodsList.size() > 0) {return (AggregatedPage<T>) new AggregatedPageImpl<Goods>(goodsList, pageable, hits.getTotalHits());}} catch (Exception e) {}return null;}});// 總頁數System.out.println("總頁數 = " + page.getTotalPages());// 當前頁System.out.println("當前頁 = " + (page.getNumber() + 1));// 每頁顯示數System.out.println("每頁顯示數 = " + page.getNumberOfElements());// 總條數System.out.println("總條數 = " + page.getTotalElements());// 文檔數據List<Goods> goodsList = page.getContent();for (Goods goods : goodsList) {System.out.println(goods);}
}
運行結果:
四. 重建索引&索引別名
目標:掌握重建索引&索引別名的應用場景以及腳本操作
應用場景:隨著業務需求的變更,結構可能發生改變。ES的索引一旦創建,只允許添加字段,不允許改變字段(因為改變字段,需要重建倒排索引,影響內部緩存結構,性能太低),那么此時,就需要重建一個新的索引,并將原有索引的數據導入到新索引中。
操作步驟
1)創建一個索引庫student_index_v1,并指定映射信息
# 創建一個索引庫student_index_v1
PUT student_index_v1
{"mappings": {"_doc":{"properties":{"birthday":{"type": "date"}}}}
}
2)往student_index_v1索引庫添加數據
# 往student_index_v1索引庫添加數據
PUT student_index_v1/_doc/1
{"birthday": "1990-01-01"
}
3)此時,由于業務需求變更,需要往birthday字段添加一個1990年01月01日的數據
PUT student_index_v1/_doc/1
{"birthday": "1990年01月01日"
}
毫無疑問添加失敗,因為birthday的類型是date,不支持這種數據格式,那我們就需要修改birthday字段的數據類型為text或keyword,但是前面也提過,ES是不準我們修改字段的,因此就需要用到重建索引
4)再創建一個索引庫student_index_v2,并指定映射信息
# 創建student_index_v2索引庫
PUT student_index_v2
{"mappings": {"_doc":{"properties":{"birthday":{"type": "text"}}}}
}
5)將student_index_v1中的數據導入到student_index_v2中
# 重建索引,將student_index_v1中的數據導入到student_index_v2中
POST _reindex
{"source": {"index": "student_index_v1"},"dest": {"index": "student_index_v2"}
}
6)查看student_index_v2可以發現數據已經導過來了,而且此時也可以添加新數據比如1990年01月01日,操作如下:
# 查看student_index_v2數據
GET student_index_v2/_search# 插入1990年01月01日到student_index_v2
PUT student_index_v2/_doc/2
{"birthday": "1990年01月01日"
}# 再查看student_index_v2數據
GET student_index_v2/_search
7)現在仍然存在一個問題,比方說我們之前的java代碼中已經寫死了索引庫名稱,如果重建了索引,新數據還往舊的索引庫里插入肯定是不行的,這個時候就需要用到另一個操作:索引別名
# 先刪除舊的索引庫
DELETE student_index_v1 # 給student_index_v2起個別名student_index_v1
POST student_index_v2/_alias/student_index_v1
這個時候,操作student_index_v2索引庫,可以用student_index_v2,也可以用student_index_v1
五. ElasticSearch 增刪改文檔
目標:掌握template增刪改文檔的應用場景及代碼實現
應用場景:當數據庫的數據發生了增刪改,需要同步數據至索引庫。
代碼實現
1)新增文檔/修改文檔
/*** 添加/修改文檔*/
@Test
public void addOrUpdateDocTest(){// 創建文檔數據Goods goods = new Goods();// 如果已經存在該id,即修改文檔goods.setId(99999l);goods.setTitle("娃娃私人訂制111");goods.setBrand("日本牌111");goods.setCategory("玩具類111");goods.setPrice(100d);goods.setNum(9999);IndexQuery query = new IndexQuery();query.setObject(goods);String id = template.index(query);System.out.println(id);
}
# 通過腳本操作是否添加數據
GET goods/_search
{"query": {"match": {"title": "娃娃"}}
}
2)刪除文檔
/*** 刪除文檔*/
@Test
public void deleteDoc(){// 根據id刪除String id = template.delete(Goods.class, "99999");// 根據條件刪除//DeleteQuery query = new DeleteQuery();//query.setQuery(QueryBuilders.matchAllQuery());//template.delete(query, Goods.class);
}
六. ElasticsearchRepository基本使用
目標:掌握ElasticsearchRepository基本使用
ElasticsearchRepository 是spring-data框架提供的一個接口,封裝了ES的一些增刪查改的基本API,使用起來比較方便。
使用步驟
1)創建GoodsRepository接口,讓其繼承ElasticsearchRepository
/*** TODO** @Author LK* @Date 2021/3/2*/
public interface GoodsRepository extends ElasticsearchRepository<Goods, Long> {}
2)在調用GoodsRepository時,可以發現里面多了一些CRUD的方法
// 添加、修改文檔
<S extends T> S save(S var1);// 添加、修改文檔
<S extends T> S index(S entity);// 根據條件查詢,返回集合
Iterable<T> search(QueryBuilder query);// 根據條件查詢,返回分頁對象
Page<T> search(QueryBuilder query, Pageable pageable);// 根據條件查詢,返回分頁對象
Page<T> search(SearchQuery searchQuery);// 根據id刪除
void deleteById(ID var1);// 根據條件刪除
void delete(T var1);// 批量刪除指定文檔
void deleteAll(Iterable<? extends T> var1);// 刪除所有
void deleteAll();
七. Elasticsearch 集群搭建
7.1 集群及分布式介紹
目標:理解什么是集群、分布式
- 集群:多個人做一樣的事。
- 分布式:多個人做不一樣的事。
說明:在一個系統中,往往分布式和集群是并存的。
7.2 相關概念
目標:理解ES集群中的一些相關概念

- 節點(node) :集群中的一個 Elasticearch 服務實例。在Elasticsearch中,節點的類型主要分為如下幾種:
- master eligible節點:有資格參加選舉成為Master的節點,默認為true(可以通過node.master: false設置)。
- data節點:保存數據的節點,默認為true(可以通過node.data: false設置)。
- Coordinating 節點:客戶端節點。負責接收客戶端請求,將請求發送到合適的節點,最終把結果匯集到一起返回,默認為true。
- 集群(cluster):一組擁有相同集群名稱的節點,集群名稱默認是elasticsearch。
- 索引(index) :es存儲數據的地方,相當于關系數據庫中的database。
- 分片(shard):索引庫可以被拆分為不同的部分進行存儲,稱為分片。在集群環境下,一個索引庫的不同分片可以拆分到放到不同的節點中,分片的好處有如下兩點。
- 提高查詢性能(多個節點并行查詢)
- 提高數據安全性(雞蛋不要放在一個籃子里)
- 主分片(Primary shard):相對于副本分片的定義。
- 副本分片(Replica shard):即對主分片數據的備份,每個主分片可以有一個或者多個副本,數據和主分片一樣,副本的好處有如下兩點:
- 數據備份,防止數據丟失
- 一定程度提高查詢的并發能力(同一份完整的索引庫的數據,分成了兩份,都可以查詢)
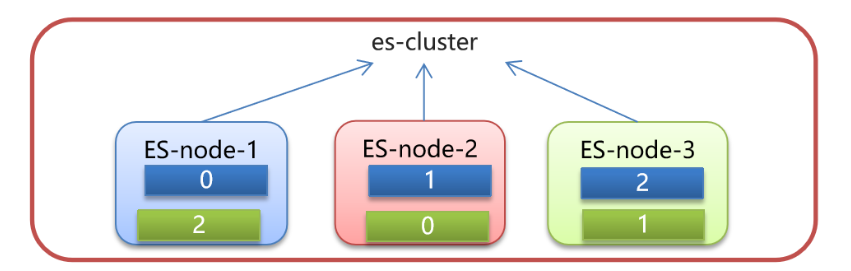
說明:主分片和副本分片永遠不會分配在同一個節點上
7.3 集群搭建
目標:能夠參考文檔搭建ES集群
請參考資料\ElasticSearch集群搭建.md
7.4 JavaAPI 操作集群
目標:掌握如何使用javaApi操作集群
1)spring-boot-data-elasticsearch,修改yml配置即可
spring:data:# es連接信息elasticsearch:cluster-name: explame-es # 修改集群名稱cluster-nodes: 192.168.211.129:9301,192.168.211.129:9302,192.168.211.129:9303 # 指定多個節點的地址
2)HighLevelRestApi
@Bean
public RestHighLevelClient restHighLevelClient() {RestHighLevelClient restHighLevelClient = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.211.129",9201,"http"),new HttpHost("192.168.211.129",9202,"http"),new HttpHost("192.168.211.129",9203,"http")));return restHighLevelClient;
}
7.5 分片配置
目標:掌握如何使用腳本設置索引分片數,以及常用分片及節點設置
-
在創建索引時,如果不指定分片配置,ES6默認主分片5,副本分片1,而ES7默認主分片1,副本分片1。
-
在創建索引時,可以通過settings設置分片
"settings": {"number_of_shards": 3, # 分片數"number_of_replicas": 1 # 副本數 } -
分片與自平衡:當節點掛掉后,掛掉的節點分片會自平衡到其他節點中
-
在Elasticsearch 中,每個查詢在每個分片的單個線程中執行,但是可以并行處理多個分片。
-
分片數量一旦確定好,不能修改。
查看分片分布情況步驟如下:
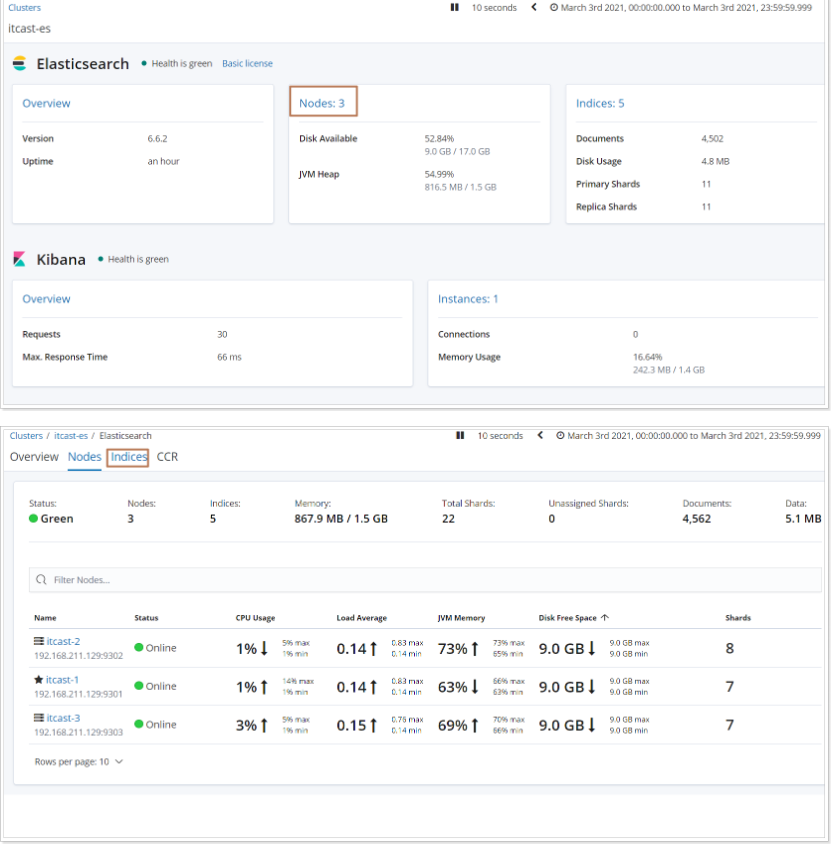
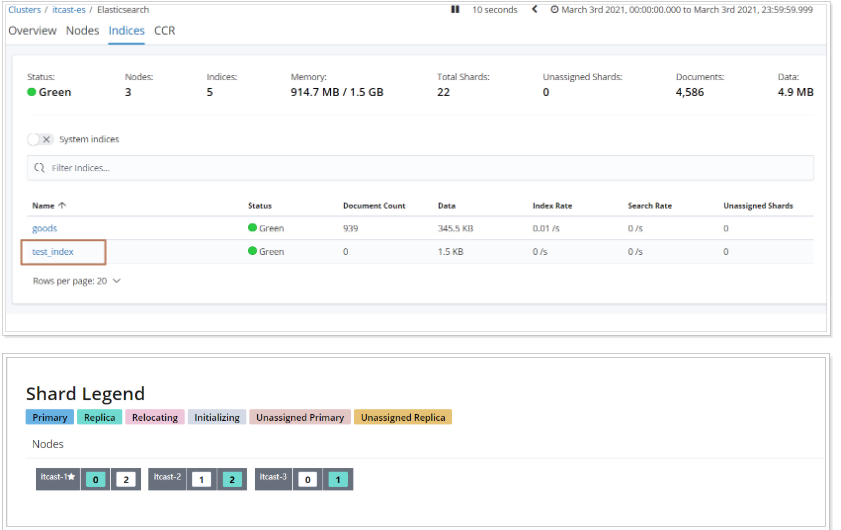
常用配置:
1、每個分片推薦大小10-30GB
2、分片數量推薦 = 節點數量 * 1~3倍
思考:比如有1000GB數據,應該有多少個分片?多少個節點?
分片數:1000 / 20 = 50
節點數:50 / 2 = 25
7.6 路由原理
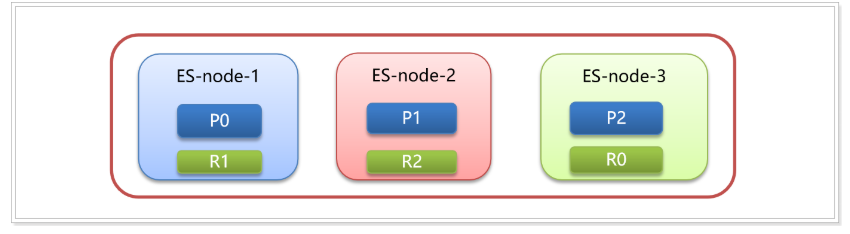
目標:理解ES中路由的原理
- 文檔存入對應的分片,ES計算分片編號的過程,稱為路由。
- Elasticsearch 是怎么知道一個文檔應該存放到哪個分片中呢?
- 查詢時,根據文檔id查詢文檔, Elasticsearch 又該去哪個分片中查詢數據呢?
- 路由算法 :shard_index(分片編號) = hash(文檔id) % number_of_primary_shards(主分片個數)
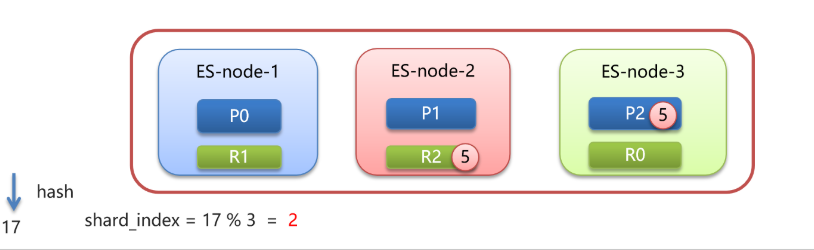
假設有三個節點,三個主分片,三個副本分片
現在有個 id=5 文檔要進行存儲,會先會id進行hash運算得到一個數字17,17對3(分片數量)取模運算:17 % 3 = 2
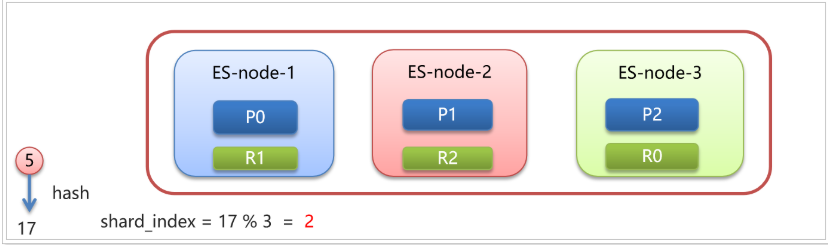
最終決定存儲在編號為2的分片上,即放到ES-node-3上,并且在ES-node-2節點上的副本分片上進行數據備份。
當要查詢 id = 5 的文檔,同樣也要先進行hash計算,計算分片位置,路由到對應的分片進行數據查詢。
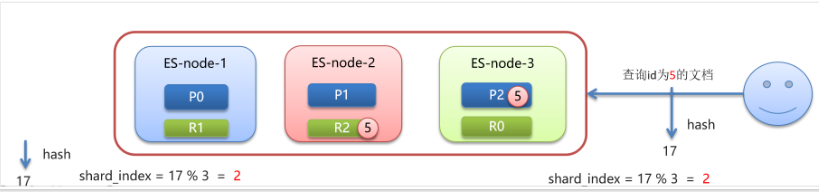
說明:任何一個節點收到查詢請求后,如果是一些詞條搜索,也會根據倒排索引找到對應的id集合,再分別計算每個id的hash值,所存儲的分片位置,再轉發請求到分片所在的節點,最終匯總查詢結果。
7.7 腦裂
目標:理解何為腦裂以及如何防止腦裂
何為腦裂?
- 一個正常es集群中只有一個主節點(Master),主節點負責管理整個集群。如創建或刪除索引,并決定哪些分片分配給哪些節點。此外還跟蹤哪些節點是集群的一部分。
- 腦裂就是一個集群出現多個主節點從而使集群分裂,使得集群處于異常狀態。簡單來說就是一個集群里只能有一個老大來指揮工作,如果有多個老大,就亂套了。
腦裂原因
-
網絡原因:網絡延遲
一般es集群會在內網部署,也可能在外網部署,比如阿里云。
內網一般不會出現此問題,外網的網絡出現問題的可能性大些。 -
節點負載
主節點的角色既為master又為data。數據訪問量較大時,可能會導致Master節點停止響應(假死狀態)。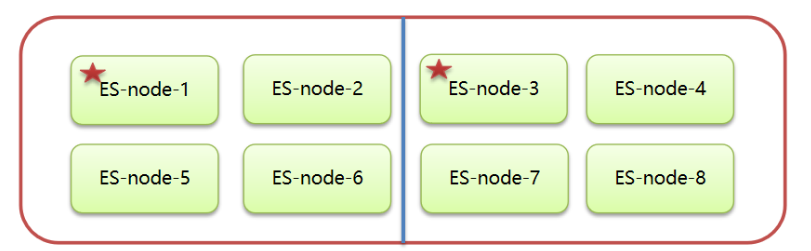
-
JVM內存回收
當Master節點設置的JVM內存較小時,引發JVM的大規模內存回收,造成ES進程失去響應
避免腦裂
腦裂產生的原因:
- 網絡原因:網絡延遲較高
- 節點負載:主節點的角色既為master又為data
- JVM內存回收:JVM內存設置太小
避免腦裂:
-
網絡原因:discovery.zen.ping.timeout 超時時間配置大一點。默認是3S
-
節點負載:角色分離策略
-
主節點配置:
node.master: true # 是否有資格參加選舉成為master node.data: false # 是否存儲數據 -
數據節點配置:
node.master: false # 是否有資格參加選舉成為master node.data: true # 是否存儲數據
-
-
JVM內存回收:修改 config/jvm.options 文件的 -Xms 和 -Xmx 為服務器的內存一半。
-
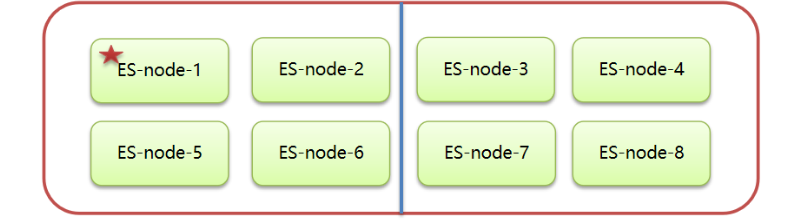
還可以在選舉層面解決腦裂問題(即不讓第二個老大產生):
# 聲明獲得大于幾票,主節點才有效,請設置為(master eligble nodes / 2) + 1 discovery.zen.minimum_master_nodes: 2比如上面存在8個節點(假如都是master eligble節點),那需要設置discovery.zen.minimum_master_nodes: 5,代表至少5票投某個節點,才有效。如果某個時刻兩個機房網絡中斷了,右邊的機房里四個節點揭竿而起從新選舉,也不夠票數。
八、關鍵注意事項
-
端口區別:
REST API端口:9200(HTTP協議)傳輸層端口:9300(TCP協議,TransportClient使用) -
版本一致性:
確保所有ES相關依賴版本為6.6.2檢查Maven依賴樹:mvn dependency:tree | grep elasticsearch

















![[echart] Vue3中使用Echart時圖表不渲染](http://pic.xiahunao.cn/[echart] Vue3中使用Echart時圖表不渲染)

