在當今數字化時代,用戶評論和反饋成為企業了解產品滿意度的重要渠道。本項目將通過神經網絡構建一個情感分析模型,自動識別用戶評論中的情感傾向。我們將使用真實的產品評論數據,從數據預處理到模型部署,完整展示神經網絡在NLP領域的應用。
1. 數據讀取與初步查看
之前我們已經準備好了產品評論數據集,現在讓我們加載并查看數據基本情況:
import pandas as pd
df = pd.read_excel('../機器學習/產品評價.xlsx')
df.head()

原理解釋:
首先,我們使用pandas庫讀取本地的產品評價數據。read_excel函數可以直接讀取Excel文件,head()方法可以預覽前幾行數據,幫助我們了解數據結構。
從輸出結果可以看到,數據集包含客戶編號、評論內容和評價三個字段,其中評價字段是我們要預測的目標變量(1表示正面評價)。
2. 中文分詞處理
import jieba
word = jieba.cut(df.iloc[0]['評論'])
result = ' '.join(word)
print(result)

原理解釋:
因為中文文本沒有天然的分隔符,所以需要用jieba庫對評論內容進行分詞。這樣可以將一句話拆分為有意義的詞語,便于后續特征提取。
3. 批量分詞
words = []
for i, row in df.iterrows():words.append(' '.join(jieba.cut(row['評論'])))

原理解釋:
通過遍歷每一條評論,將所有評論都進行分詞處理,并用空格連接,最終得到一個分詞后的評論列表,為后續向量化做準備。
4. 文本向量化(詞袋模型)
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
X = vect.fit_transform(words)
X = X.toarray()

原理解釋:
因為機器學習模型無法直接處理文本,所以我們用CountVectorizer將分詞后的文本轉化為數字向量(詞袋模型)。每一列代表一個詞,每一行代表一條評論,數值表示該詞出現的次數。
5. 查看詞袋內容
words_bag = vect.vocabulary_
print(words_bag)

原理解釋:
通過查看vocabulary_屬性,可以了解詞袋模型中包含了哪些詞及其對應的索引,有助于理解特征空間。
6. 構建特征和標簽
y = df['評價']
我們將評論的情感標簽(如好評/差評)作為模型的目標變量(y),用于監督學習。
7. 劃分訓練集和測試集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)
原理解釋:
通過train_test_split函數,將數據集分為訓練集和測試集。這樣可以用訓練集訓練模型,用測試集評估模型效果,防止過擬合。
8. 構建并訓練神經網絡模型
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(X_train, y_train)
原理解釋:
我們選擇MLPClassifier(多層感知機)作為神經網絡模型。通過fit方法用訓練集數據訓練模型,讓模型學習評論與情感標簽之間的關系。
9. 模型預測
y_pred = mlp.predict(X_test)
y_pred

原理解釋:
通過predict方法,模型對測試集的評論進行情感預測,輸出預測結果。
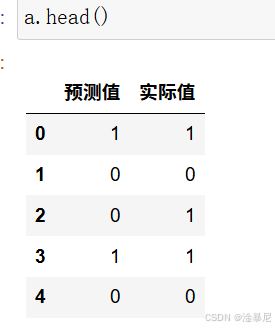
10. 結果對比
a = pd.DataFrame()
a['預測值'] = list(y_pred)
a['實際值'] = list(y_test)
a.head()
原理解釋:
將預測結果與實際標簽進行對比,可以直觀地看到模型的預測準確性。
11. 模型準確率評估
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
score
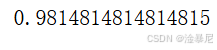
原理解釋:
通過accuracy_score計算模型在測試集上的準確率,衡量模型的整體表現。
12. 實時評論情感預測
comment = input('請輸入您對本商品的評價:')
comment = [' '.join(jieba.cut(comment))]
X_try = vect.transform(comment)
y_pred = mlp.predict(X_try.toarray())
print(y_pred)

原理解釋:
最后,我們可以輸入一條新的評論,經過分詞和向量化后,利用訓練好的神經網絡模型進行情感預測,實現用戶交互。結果為0,代表差評與我們期望一致
13. 對比樸素貝葉斯模型
from sklearn.naive_bayes import GaussianNB
nb_clf = GaussianNB()
nb_clf.fit(X_train, y_train)
y_pred = nb_clf.predict(X_test)
score = accuracy_score(y_pred, y_test)
print(score)

原理解釋:
為了對比神經網絡與其他模型的效果,我們還用樸素貝葉斯(GaussianNB)進行訓練和預測,并計算準確率。這樣可以評估不同模型在情感分析任務上的表現。從結果可見樸素貝葉斯的效果略遜于MLP神經網絡模型
通過以上步驟,我們完成了一個基于神經網絡的用戶評論情感分析模型的實戰案例。你可以根據自己的數據和需求,進一步優化和擴展模型。
參考文獻
[1] Python大數據分析與機器學習商業案例實戰/王宇韜,錢妍竹著[M]. 機械工業出版社, 2020.5





 219. 存在重復元素 II (哈希表))



)







分布式事務)

