文章大綱
- 帶貨直播間推薦系統:原理、算法與實踐
-
- 一、推薦系統在帶貨直播中的重要性
- 二、數據收集與處理
-
- 1. 用戶數據
- 2. 直播間數據
- 3. 用戶行為數據
- 4. 數據處理與特征工程
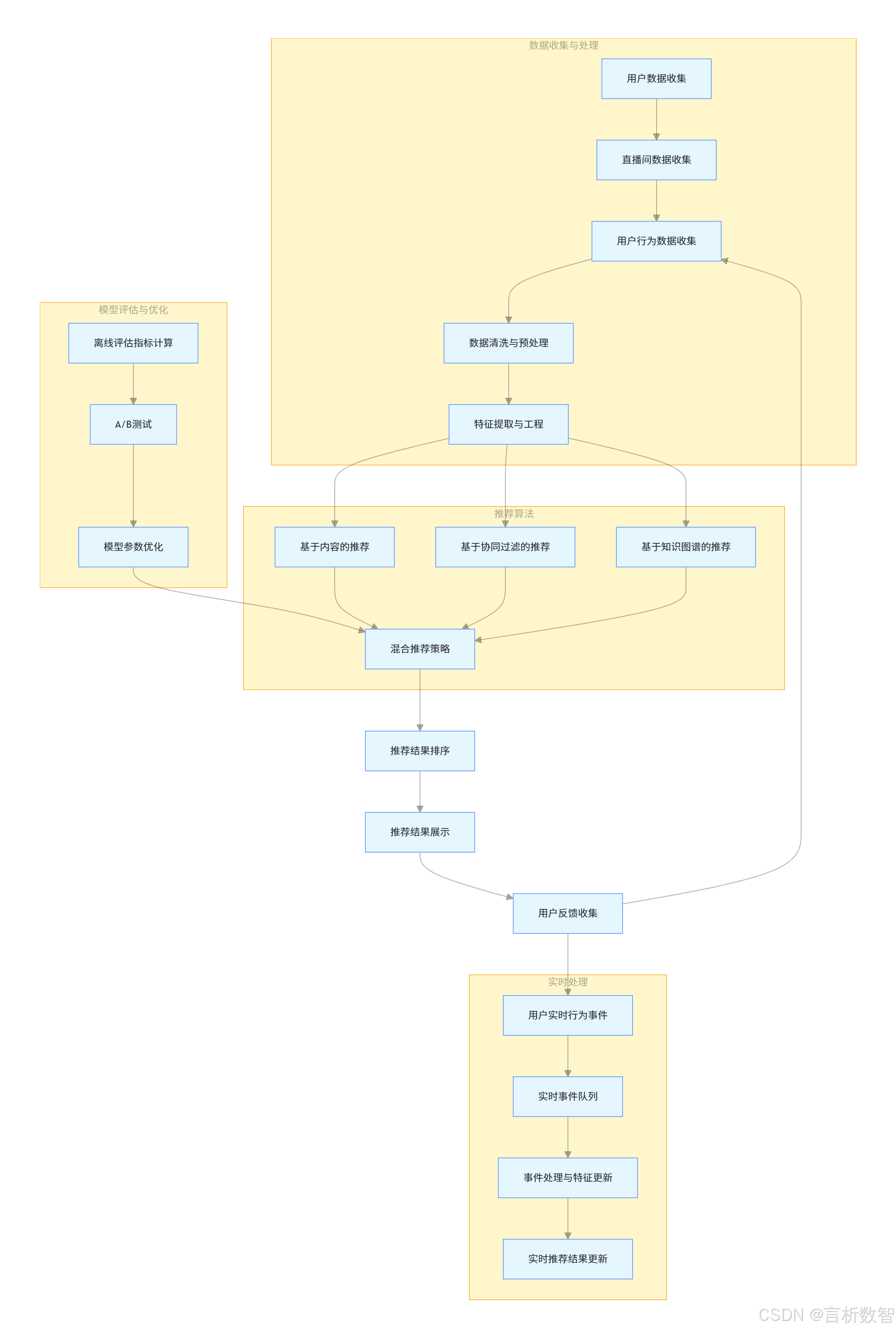
- 三、推薦算法實現
-
- 1. 基于內容的推薦
- 2. 基于協同過濾的推薦
- 3. 基于知識圖譜的推薦
- 4. 混合推薦算法
- 四、實時推薦系統架構
- 五、推薦系統評估
- 六、實際應用中的挑戰與解決方案
-
- 1. 冷啟動問題
- 2. 實時性要求
- 3. 推薦多樣性與準確性的平衡
- 4. 可擴展性問題
- 七、總結與展望
帶貨直播間推薦系統:原理、算法與實踐
在電商直播蓬勃發展的今天,如何將合適的帶貨直播間精準推送給有需求的用戶,成為提升平臺轉化率和用戶體驗的關鍵。
- 本文將深入探討帶貨直播間推薦系統的核心原理、算法實現和工程實踐,并結合具體代碼案例進行詳細解析。
一、推薦系統在帶貨直播中的重要性
- 帶貨直播作為一種新興的電商模式,具有實時性、互動性強的特點。
- 但同時也面臨信息過載的問題:平臺上的直播間數量眾多,內容和品類豐富多樣,用戶很難快速找到符合自己興趣和需求的直播間。
推薦系統通過分析用戶行為和偏好,能夠為每個用戶提供個性化的直播間推薦,幫助用戶發現感興趣的內容,提高直播觀看時長和商品購買轉化率。
一個好的帶貨直播間推薦系統可以帶來以下價值:
- 提高用戶粘性和活躍度:通過精準推薦,用戶更容易找到感興趣的直播間,從而增加在平臺上的停留時間。
- 提升商品轉化率:將用戶可能感興趣的商品直播間推薦給他們,能夠有效提高購買意愿。
- 增加主播曝光機會:優質的直播間能夠被更多潛在觀眾發現,提高主播的影響力和收益。
- 優化平臺資源分配:幫助平臺更好地管理和推薦內容,提高整體運營效率。
二、數據收集與處理
推薦系統的基礎是數據。在帶貨直播間推薦場景中,我們需要收集和處理多種類型的數據,包括用戶特征、直播間特征和用戶行為數據。
1. 用戶數據
用戶數據包括用戶的基本信息和興趣偏好,例如:
import pandas as pd
import numpy as np
from datetime import datetime# 模擬用戶數據
def generate_user_data(num_users=1000):"""生成模擬的用戶數據"""user_ids = [f"user_{i}" for i in range(1, num_users + 1)]genders = np.random.choice(['男', '女'], size=num_users)ages = np.random.randint(18, 60, size=num_users)locations = np.random.choice(['北京', '上海', '廣州', '深圳', '杭州', '成都', '其他'], size=num_users)interests = np.random.choice(['服裝', '美妝', '數碼', '家電', '食品', '母嬰', '家居', '運動'], size=num_users)user_data = pd.DataFrame({'user_id': user_ids,'gender': genders,'age': ages,'location': locations,'interest': interests})return user_data
2. 直播間數據
直播間數據描述了 每個直播間的特征,例如直播類別、主播信息、直播時間和商品價格等:
# 模擬直播間數據
def generate_live_data(num_lives=200):"""生成模擬的直播間數據"""live_ids = [f"live_{i}" for i in range(1, num_lives + 1)]categories = np.random.choice(['服裝', '美妝', '數碼', '家電', '食品', '母嬰', '家居', '運動'], size=num_lives)anchors = [f"主播_{i}" for i in range(1, num_lives + 1)]start_times = [datetime.now() + pd.Timedelta(hours=np.random.randint(0, 24), minutes=np.random.randint(0, 60)) for _ in range(num_lives)]expected_durations = np.random.randint(1, 6, size=num_lives) # 直播時長(小時)product_prices = np.random.uniform(10, 1000, size=num_lives) # 平均產品價格live_data = pd.DataFrame({'live_id': live_ids,'category': categories,'anchor': anchors,'start_time': start_times,'expected_duration': expected_durations,'product_price': product_prices})return live_data
3. 用戶行為數據
用戶行為數據記錄了 用戶與直播間的交互歷史,是推薦系統的核心數據:
- 用戶對直播間的興趣程度,結合用戶興趣和直播間類別,如果用戶興趣與直播間類別匹配,興趣分數更高。
- 價格因素,假設用戶對價格有不同偏好
- 地理位置因素
- 綜合興趣分數:
score = interest_score * 0.5 + price_score * 0.3 + location_match * 0.2
# 模擬用戶歷史行為數據
def generate_user_behavior_data(user_data, live_data, num_records=5000):"""生成模擬的用戶行為數據"""user_ids = user_data['user_id'].tolist()live_ids = live_data['live_id'].tolist()records = []for _ in range(num_records):user_id = np.random.choice(user_ids)live_id = np.random.choice(live_ids)# 用戶對直播間的興趣程度,結合用戶興趣和直播間類別user_row = user_data[user_data['user_id'] == user_id].iloc[0]live_row = live_data[live_data['live_id'] == live_id].iloc[0]# 如果用戶興趣與直播間類別匹配,興趣分數更高interest_score = 0.8 if user_row['interest'] == live_row['category'] else 0.2# 價格因素,假設用戶對價格有不同偏好price_preference = np.random.choice(['低', '中', '高'])if (price_preference == '低' and live_row['product_price'] < 100) or \(price_preference == '中' and 100 <= live_row['product_price'] < 500) or \(price_preference == '高' and live_row['product_price'] >= 500):price_score = 0.7else:price_score = 0.3# 地理位置因素location_match = 0.6 if user_row['location'] == '其他' else 0.3# 綜合興趣分數score = interest_score * 0.5 + price_score * 0.3 + location_match * 0.2# 基于分數決定用戶是否會點擊或觀看直播間clicked = np.random.choice([True, False], p=[score, 1-score])if clicked:watch_duration = np.random.uniform(0, live_row[


 視頻教程 - 微博類別信息爬取)
)


)








獲取)

)
