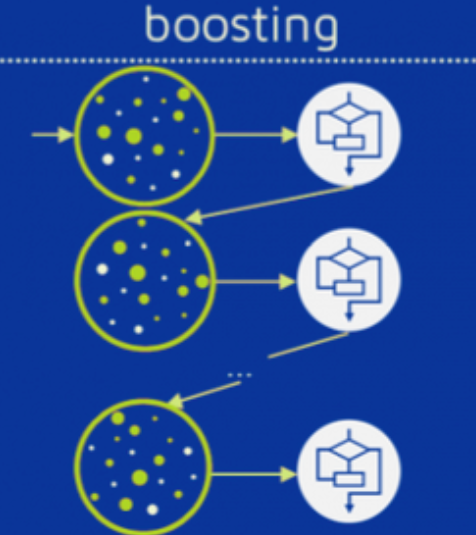
咱們結合這張圖,把 “提升” 想象成 “做錯題本 + 請老師補課” 的過程:
- 第一波數據(最上面的圓圈):“第一次作業”
假設你第一次做 100 道數學題(圖中圓圈里的綠點白點代表不同的題),做完后老師批改:
- 綠點:你做對的題;
- 白點:你做錯的題(比如 10 道)。
- 第一個模型(最上面的方框):“第一次總結規律”
你根據這 100 道題,總結出一套 “解題模板”(比如 “看到‘雞兔同籠’就用方程”),但這套模板只能做對 90 道題,10 道白點題還是錯。
- 第二波數據(中間的圓圈):“錯題本重點練”
老師把你做錯的 10 道題(白點)標紅,讓你重點練習。同時,把原來的 100 道題重新混在一起,但這次錯題的 “權重” 更高(比如每道錯題算 2 道題,普通題算 1 道)。
這樣,新的練習冊里,錯題出現的概率更大,你被迫更關注它們。
- 第二個模型(中間的方框):“針對錯題補課”
你根據新的練習冊(重點是錯題),再總結一套新的解題模板(比如 “雞兔同籠用假設法更快”)。這次,你可能把之前的 5 道錯題改對了,但還有 5 道錯題。
- 第三波數據(最下面的圓圈):“繼續補漏”
老師再次把你還沒改對的 5 道題標紅,繼續增加它們的權重,讓你重點練習…… 直到你把大部分錯題改對。
- 最終模型:“綜合所有模板”
經過幾輪 “做題→總結→補漏”,你有了好幾套解題模板。考試時,遇到一道題,你會同時用這幾套模板分析,誰在這類題上更準,就聽誰的(比如第一套模板在幾何題上準,第二套在應用題上準)。
提升(Boosting)的核心邏輯(對應圖中箭頭)
- 從第一波到第二波的箭頭:把錯誤樣本(白點)的權重提高,讓模型更關注它們;
- 每個方框(模型)的箭頭:每個模型都在前一個模型的錯誤上改進;
- 最終所有模型的輸出:按 “能力” 加權投票(比如在某類題上表現好的模型,權重更高)。
總結
“先做一套題,找出錯題重點練;再做一套題,再找錯題重點練…… 最后綜合所有經驗,誰強聽誰的。”
它和裝袋(Bagging)的區別是:裝袋是 “平行做題,投票決定”,提升是 “串行補漏,強者主導”~
提升算法的使用示例
為了讓你更直觀地理解提升算法的使用,我們以一個簡單的分類任務為例,使用 Python 的scikit-learn庫中的AdaBoostClassifier來實現。
假設我們有一個數據集,包含一些樣本的特征和對應的類別標簽,我們的目標是根據這些特征來預測樣本的類別。
# 導入必要的庫 from sklearn.ensemble import AdaBoostClassifier from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 生成一個示例數據集 X, y = make_classification(n_samples=1000, n_features=20, random_state=42) # 將數據集劃分為訓練集和測試集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 創建一個AdaBoost分類器對象 # n_estimators表示使用的弱學習器(這里是決策樹)的數量 # random_state用于保證結果的可重復性 clf = AdaBoostClassifier(n_estimators=50, random_state=42) # 訓練模型 clf.fit(X_train, y_train) # 在測試集上進行預測 y_pred = clf.predict(X_test) # 計算模型的準確率 accuracy = accuracy_score(y_test, y_pred) print(f"模型的準確率為: {accuracy}") |
在這個示例中:
- 首先,我們生成了一個用于分類的示例數據集,其中包含 1000 個樣本和 20 個特征。
- 然后,我們將數據集劃分為訓練集和測試集,訓練集用于訓練模型,測試集用于評估模型的性能。
- 接著,我們創建了一個AdaBoostClassifier對象,設置了使用 50 個弱學習器(這里默認是決策樹)。
- 然后,我們使用訓練集對模型進行訓練,模型會按照提升算法的原理,逐步構建一系列的弱學習器,并不斷調整樣本的權重,使得后續的弱學習器更關注那些被之前的弱學習器錯誤分類的樣本。
- 訓練完成后,我們使用測試集對模型進行預測,并計算模型的準確率來評估其性能。
通過這個示例,你可以看到提升算法是如何通過逐步改進模型來提高分類準確率的。在實際應用中,你可以根據具體的問題和數據特點,選擇合適的提升算法和參數,以獲得更好的性能。






)



 - 實例方法、類方法、靜態方法)

![[yotroy.cool] Git 歷史遷移筆記:將 Git 項目嵌入另一個倉庫子目錄中(保留提交記錄)](http://pic.xiahunao.cn/[yotroy.cool] Git 歷史遷移筆記:將 Git 項目嵌入另一個倉庫子目錄中(保留提交記錄))






(下))