影響結果出了最終的目標,還會有許多細節因素
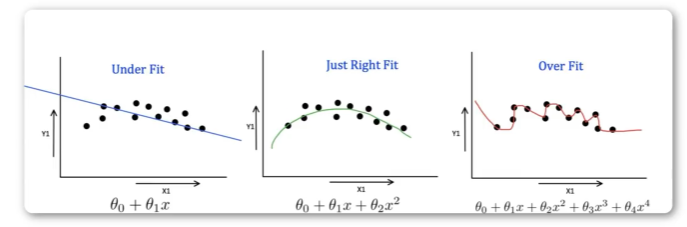
在機器學習中,往往會面臨很多過擬合和欠擬合的問題。
欠擬合是訓練不到位,過擬合是訓練過頭,會導致泛化性差
正則化是在損失函數中添加一個懲罰項,以簡化模型

對于懲罰項Penalty——L1、L2
L1正則化:
會使一些特征的權重變為0,因此可以用來做特征選擇。
λ是超參數,用于控制正則化強度,wi是第i個特征的權重
優點:減少特征數量
缺點:可能會過度懲罰某些特征,導致一些有用信息被舍棄
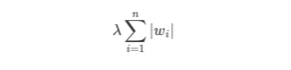
L2正則化:
使所有特征的權重都變小且不為零。
優點:降低權重,防止過擬合
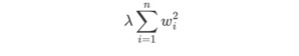
正則化有廣泛的應用
在線性回歸中:通過添加L1、L2進行正則化
在神經網絡中:通過添加正則項,控制模型復雜度
多元線性回歸+L1——Lasso回歸
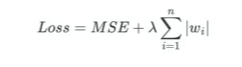
多元線性回歸+L2——Ridge嶺回歸
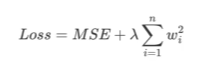
新聞分類
from sklearn.datasets import fetch_20newsgroups
from sklearn.pipline import make_pipeline
from sklearn.feature_extraction.text import Countvectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_scoretrain = fetch_20newsgroups(subset="train")
test = fetch_20newsgroups(subset="test")#數據是文本文件,須通過pipeline提取,提取后通過CountVectorizer向量化,然后采用邏輯回歸訓練
pipeline = make_pipeline(CountVectorizer(), LogisticRegression(max_iter = 3000))pipeline.fit(train.data, train.target)y_pred = pipeline.predict(test.data)print("Accuracy:%。2f" % accuracy_score(test.target, y_pred))
)





3DGS訓練)








)
YOLO12 環境配置與基本應用)

