【Cortex-M】異常中斷時的程序運行指針SP獲取,及SCB寄存器錯誤類型獲取
更新以gitee為準:
gitee
文章目錄
- 異常中斷
- 異常的程序運行指針SP獲取
- SCB寄存器錯誤類型獲取
- 硬件錯誤異常 Hard fault status register (SCB->HFSR)
- 存儲器管理錯誤異常 SCB->CFSR中MMFSR位
- 總線錯誤異常 SCB->CFSR中BFSR位
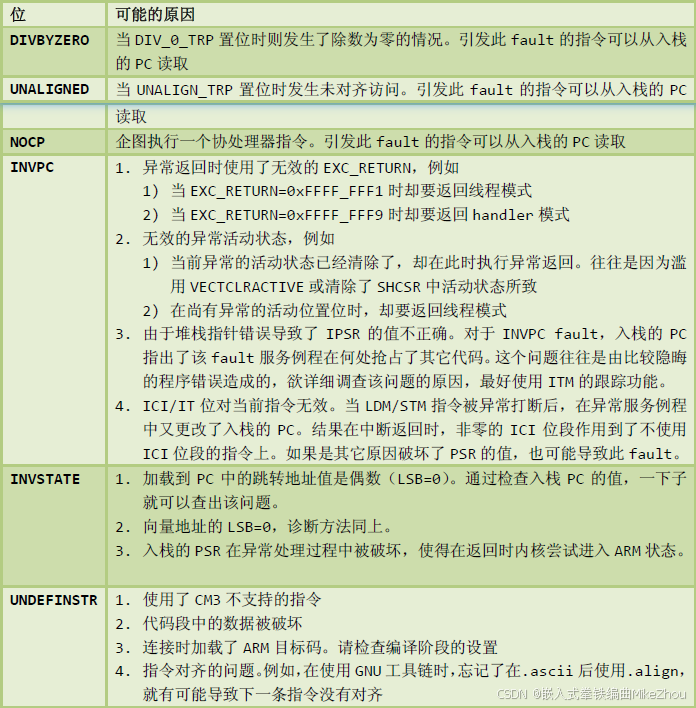
- 使用錯誤異常 SCB->CFSR中UFSR位
- 附錄:壓縮字符串、大小端格式轉換
- 壓縮字符串
- 浮點數
- 壓縮Packed-ASCII字符串
- 大小端轉換
- 什么是大端和小端
- 數據傳輸中的大小端
- 總結
- 大小端轉換函數
異常中斷
當MCU因堆棧溢出等造成異常會 會進入異常中斷
可以在startup.s中查看
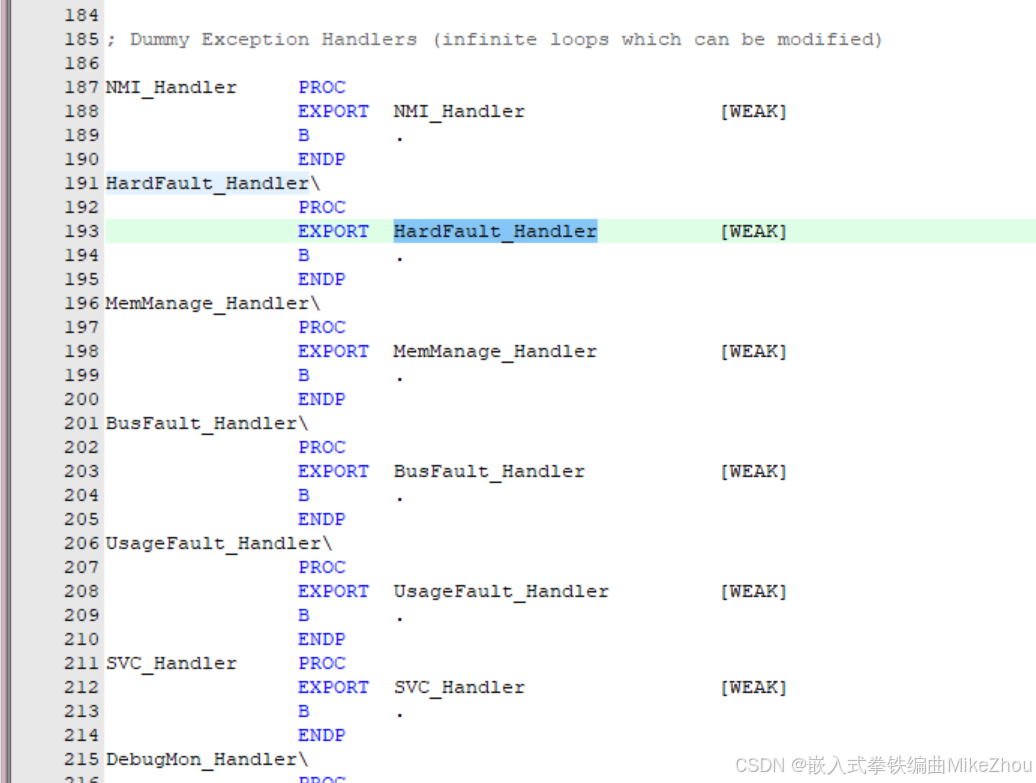
通常引起的時HardFault中斷(包括內存溢出、非法賦值、寄存器操作錯誤、堆棧溢出等)
譬如手動引起異常:
*(uint32_t *)0x45678912=1;
異常的程序運行指針SP獲取
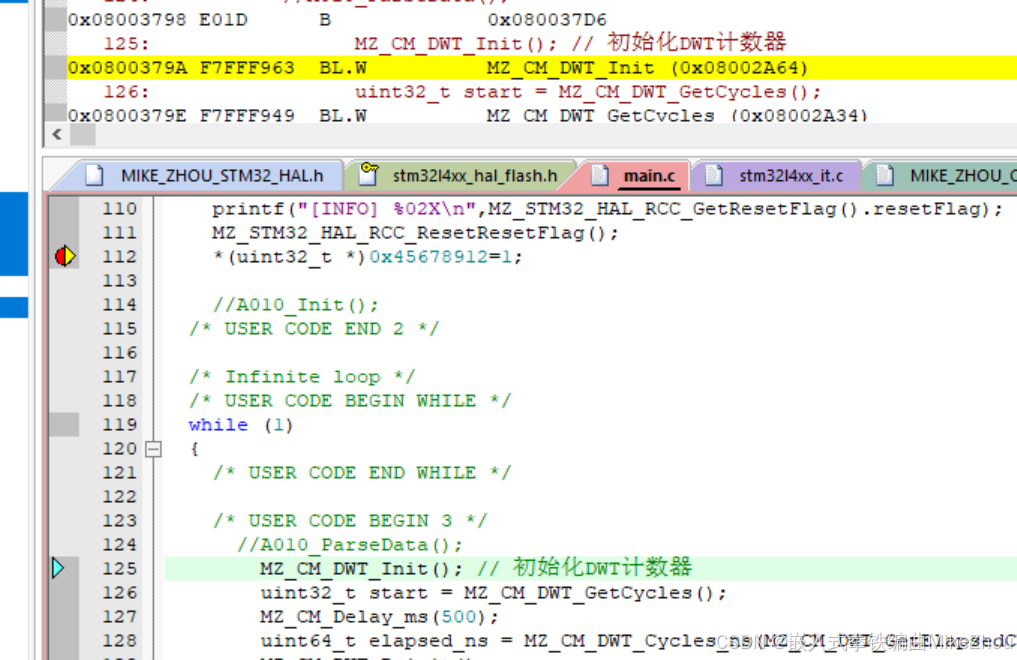
打個斷點在異常代碼處 可以看到地址為0x08003792
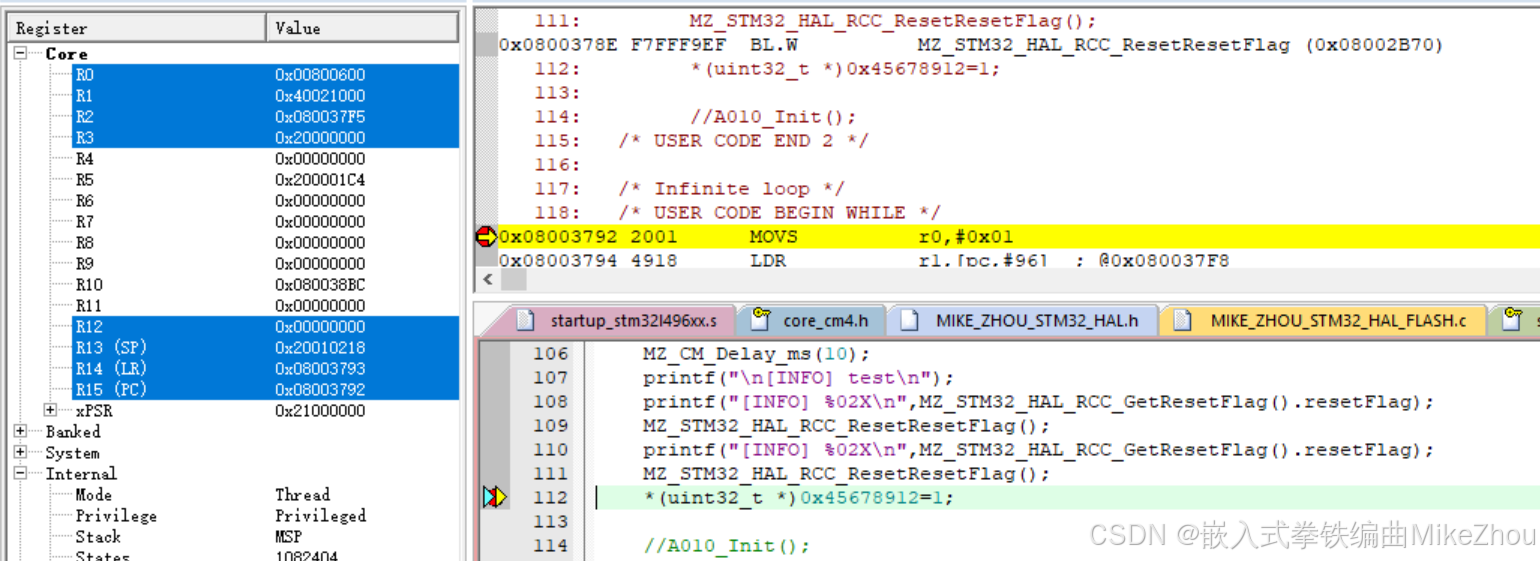
在HardFault_Handler中也打個斷點 就能在運行到其中時停止
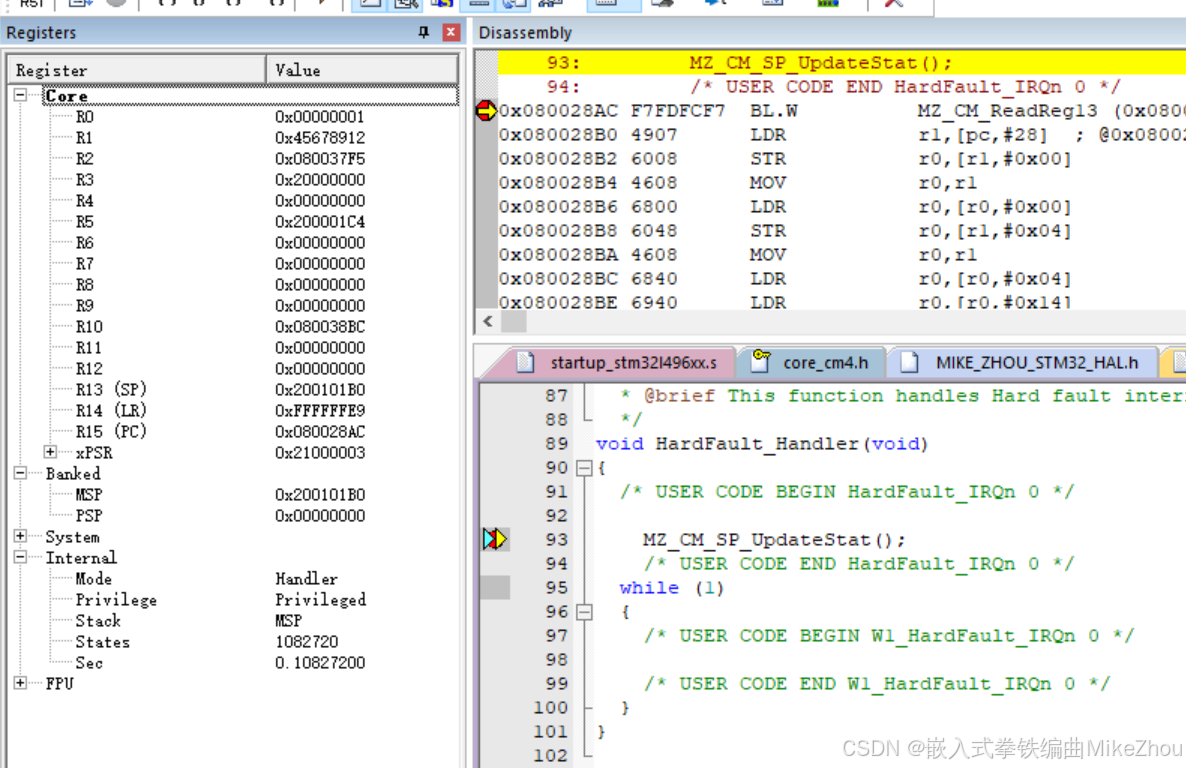
此時 LR寄存器為特殊標記值
0xFFFFFFE9對應的是要看MSP寄存器
0xFFFFFFFD對應的是要看PSP寄存器
具體根據芯片手冊而定(cortex-M權威指南)
不過也有個更方便的方式是直接讀取SP指針
通過匯編即可實現
__asm uint32_t MZ_CM_ReadReg13(void){MOV R0, spbx lr
}
那么 就可以通過此方式獲取到0x200101B0
通過內存查看該地址:
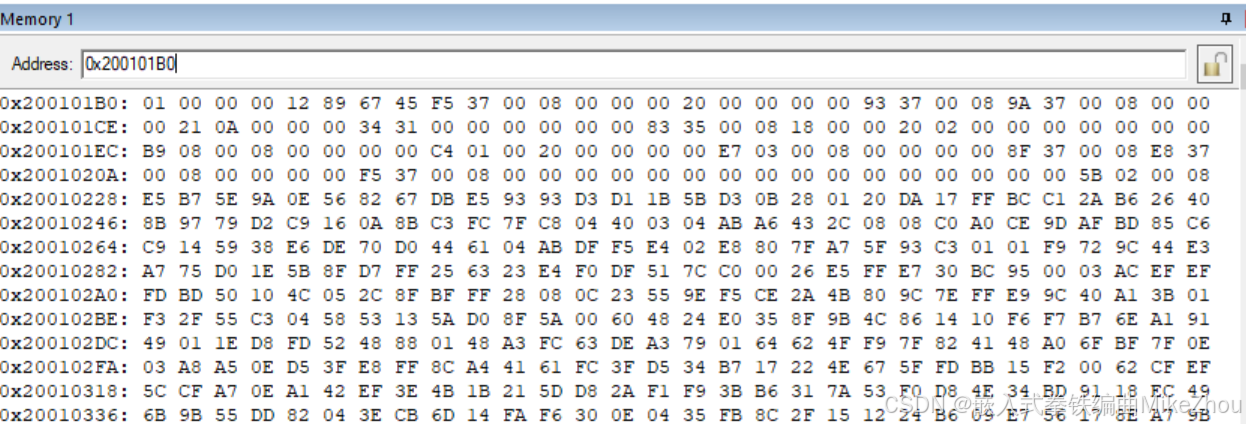
第5和6個uint32值即為上一次異常程序地址 和如果正常運行的話 下一個程序地址
注意為小端格式 所以解析出來就是0x08003793和0x0800379A

但程序地址的最后一位是標志位 用于區分是否為thumb指令或ARM指令(cortex權威指南)
由于歷史原因,最初的16位單片機用的指令是Thumb指令,為16位指令。后來,ARM推出了32位的ARM指令。16位的指令更適合空間有限的嵌入式處理器,而32位的指令則更加靈活、功能豐富。因此,有些單片機在運行時可以根據需求切換指令狀態。如下圖:
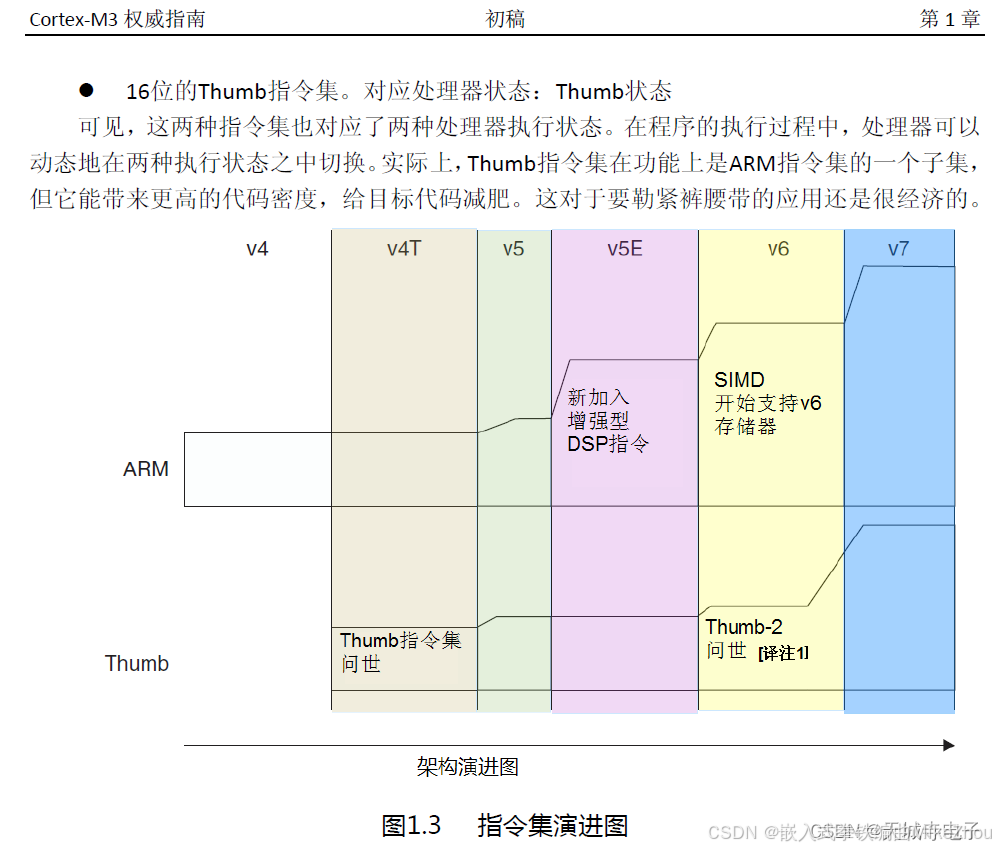
后來誕生了Thumb-2指令集,它實現了16位指令和32位指令的共存。而Cortex-M3架構則就是采用Thumb-2指令集。由于16位指令長度是2字節,32位指令長度是4字節,因此其PC指針地址是按照2字節(16位)對齊的。換言之其最低位一定是0。
另外 需要注意的是 如果在代碼層面進行獲取 不能包裝子函數(子函數會導致LR和SP被重寫) 所以直接用一個宏替代即可
#define MZ_CM_SP_UpdateStat() MZ_CM_SP_Stat.sp = MZ_CM_ReadReg13();MZ_CM_SP_Stat.spAddr = (uint32_t *)MZ_CM_SP_Stat.sp;MZ_CM_SP_Stat.lastFlashAddr = MZ_CM_SP_Stat.spAddr[5];MZ_CM_SP_Stat.nextFlashAddr = MZ_CM_SP_Stat.spAddr[6];調用后 如下:
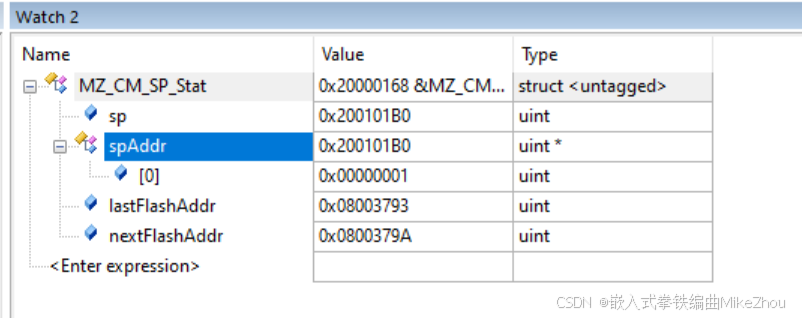
后一個地址正是如果正常運行的下一個程序語句地址
SCB寄存器錯誤類型獲取
關鍵寄存器:
SCB->CFSR(可配置故障狀態寄存器):判斷故障類型(如內存訪問錯誤、未對齊訪問、指令執行錯誤)。
SCB->HFSR(硬件故障狀態寄存器):確認是否為HardFault的直接觸發原因。
SCB->MMFAR/SCB->BFAR:記錄導致內存管理或總線故障的具體地址。
直接通過memcpy獲取即可
硬件錯誤異常 Hard fault status register (SCB->HFSR)
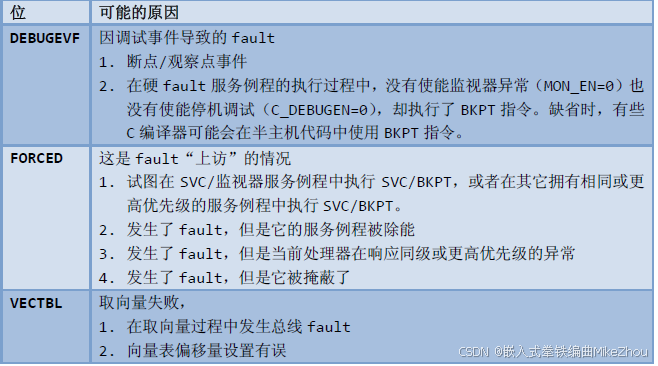
存儲器管理錯誤異常 SCB->CFSR中MMFSR位

總線錯誤異常 SCB->CFSR中BFSR位
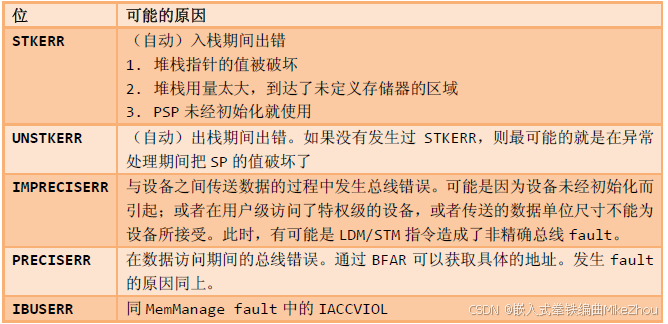
使用錯誤異常 SCB->CFSR中UFSR位
附錄:壓縮字符串、大小端格式轉換
壓縮字符串
首先HART數據格式如下:


重點就是浮點數和字符串類型
Latin-1就不說了 基本用不到
浮點數
浮點數里面 如 0x40 80 00 00表示4.0f
在HART協議里面 浮點數是按大端格式發送的 就是高位先發送 低位后發送
發送出來的數組為:40,80,00,00
但在C語言對浮點數的存儲中 是按小端格式來存儲的 也就是40在高位 00在低位
浮點數:4.0f
地址0x1000對應00
地址0x1001對應00
地址0x1002對應80
地址0x1003對應40
若直接使用memcpy函數 則需要進行大小端轉換 否則會存儲為:
地址0x1000對應40
地址0x1001對應80
地址0x1002對應00
地址0x1003對應00
大小端轉換:
void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}壓縮Packed-ASCII字符串
本質上是將原本的ASCII的最高2位去掉 然后拼接起來 比如空格(0x20)
四個空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六進制:82 08 20
對了一下表 0x20之前的識別不了
也就是只能識別0x20-0x5F的ASCII表

壓縮/解壓函數后面再寫:
//傳入的字符串和數字必須提前聲明 且字符串大小至少為str_len 數組大小至少為str_len%4*3 str_len必須為4的倍數
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(buf,0,str_len/4*3); for(i=0;i<str_len;i++){if(str[i]==0x00){str[i]=0x20;}}for(i=0;i<str_len/4;i++){buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);}return 1;
}//傳入的字符串和數字必須提前聲明 且字符串大小至少為str_len 數組大小至少為str_len%4*3 str_len必須為4的倍數
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(str,0,str_len);for(i=0;i<str_len/4;i++){str[4*i]=(buf[3*i]>>2)&0x3F;str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);str[4*i+3]=buf[3*i+2]&0x3F;}return 1;
}大小端轉換
在串口等數據解析中 難免遇到大小端格式問題
什么是大端和小端
所謂的大端模式,就是高位字節排放在內存的低地址端,低位字節排放在內存的高地址端。
所謂的小端模式,就是低位字節排放在內存的低地址端,高位字節排放在內存的高地址端。
簡單來說:大端——高尾端,小端——低尾端
舉個例子,比如數字 0x12 34 56 78在內存中的表示形式為:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可見,大端模式和字符串的存儲模式類似。
數據傳輸中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
則發送的buf應為{0x52,0x0A}
而數據位一般是小端格式(單字節無大小端之分)
如:
一個16位的數據發送出來為{0x52,0x0A}
則對應的uint16_t類型數為: 0x0A52
而對于浮點數4.0f 轉為32位應是:
40 80 00 00
以大端存儲來說 發送出來的buf就是依次發送 40 80 00 00
以小端存儲來說 則發送 00 00 80 40
由于memcpy等函數 是按字節地址進行復制 其復制的格式為小端格式 所以當數據為小端存儲時 不用進行大小端轉換
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};memcpy(&dat,buf,4);float f=0.0f;f=*((float*)&dat); //地址強轉printf("%f",f);
或更優解:
uint8_t buf[]={0x00,0x00,0x80,0x40}; float f=0.0f;memcpy(&f,buf,4);
而對于大端存儲的數據(如HART協議數據 全為大端格式) 其復制的格式仍然為小端格式 所以當數據為小端存儲時 要進行大小端轉換
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&dat); //大小端轉換f=*((float*)&dat); //地址強轉printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&f); //大小端轉換printf("%f",f);
或更優解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};float f=0.0f;dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)f=*((float*)&dat);
總結
固 若數據為小端格式 則可以直接用memcpy函數進行轉換 否則通過移位的方式再進行地址強轉
對于多位數據 比如同時傳兩個浮點數 則可以定義結構體之后進行memcpy復制(數據為小端格式)
對于小端數據 直接用memcpy寫入即可 若是浮點數 也不用再進行強轉
對于大端數據 如果不嫌麻煩 或想使代碼更加簡潔(但執行效率會降低) 也可以先用memcpy寫入結構體之后再調用大小端轉換函數 但這里需要注意的是 結構體必須全為無符號整型 浮點型只能在大小端轉換寫入之后再次強轉 若結構體內采用浮點型 則需要強轉兩次
所以對于大端數據 推薦通過移位的方式來進行賦值 然后再進行個別數的強轉 再往通用結構體進行寫入
多個不同變量大小的結構體 要主要字節對齊的問題
可以用#pragma pack(1) 使其對齊為1
但會影響效率
大小端轉換函數
直接通過對地址的操作來實現 傳入的變量為32位的變量
中間變量ptr是傳入變量的地址
void swap16(void * p)
{uint16_t *ptr=p;uint16_t x = *ptr;x = (x << 8) | (x >> 8);*ptr=x;
}void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}void swap64(void * p)
{uint64_t *ptr=p;uint64_t x = *ptr;x = (x << 32) | (x >> 32);x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);*ptr=x;
}





--流密碼)





)






:,及解決)
