索引結構
概述
MySQL 的索引是在存儲引擎層實現的,不同的存儲引擎有不同的索引結構,主要包含以下幾種:
| 索引結構 | 描述 |
|---|---|
| B+Tree索引 | 最常見的索引類型,大部分引擎都支持 B+ 樹索引 |
| Hash索引 | 底層數據結構是用哈希表實現的,只有精確匹配索引列的查詢才有效,不支持范圍查詢 |
| R-tree(空間索引) | 空間索引是MyISAM引擎的一個特殊索引類型,主要用于地理空間數據類型,通常使用較少 |
| Full-text(全文引) | 是一種通過建立倒排索引,快速匹配文檔的方式。類似于Lucene,Solr,ES |
MySQL 中所支持的所有的索引結構,接下來,我們再來看看不同的存儲引擎對于索引結構的支持情況。
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
注意:我們平常所說的索引,如果沒有特別指明,都是指B+樹結構組織的索引。
具體實現
B-Tree與B+Tree
B-Tree
B-Tree,B樹是一種多叉路衡查找樹,相對于二叉樹,B樹每個節點可以有多個分支,即多叉。
以一顆最大度數(max-degree)為5(5階)的b-tree為例,那這個B樹每個節點最多存儲4個key,5個指針:

B+Tree
B+Tree是B-Tree的變種,我們以一顆最大度數(max-degree)為4(4階)的b+tree為例,來看一下其結構示意圖:
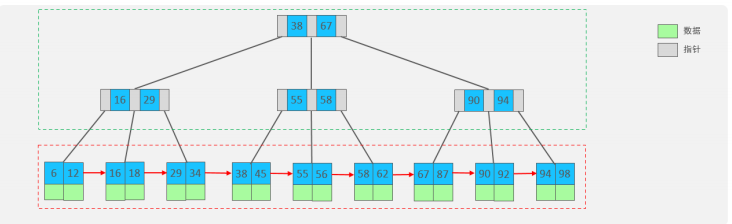
我們可以看到,兩部分:
綠色框框起來的部分,是索引部分,僅僅起到索引數據的作用,不存儲數據。
紅色框框起來的部分,是數據存儲部分,在其葉子節點中要存儲具體的數據。
B+Tree 與 B-Tree 的區別
最終我們看到,B+Tree 與 B-Tree 相比,主要有以下三點區別:
所有的數據都會出現在葉子節點。
葉子節點形成一個單向鏈表。
非葉子節點僅僅起到索引數據作用,具體的數據都是在葉子節點存放的。
上述我們所看到的結構是標準的 B+Tree 的數據結構,接下來,我們再來看看 MySQL 中優化之后的 B+Tree。
MySQL 索引數據結構對經典的 B+Tree 進行了優化。在原 B+Tree 的基礎上,增加一個指向相鄰葉子節點的鏈表指針,就形成了帶有順序指針的 B+Tree,提高區間訪問的性能,利于排序。
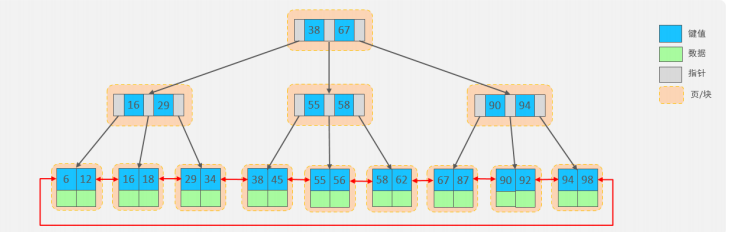
頁(Page)的概念與作用
在關系型數據庫(如 MySQL InnoDB、Oracle、SQL Server 等)中,最常用的索引結構是 B+ 樹(或其變種)。B+ 樹索引在磁盤或持久化存儲上,都是以“頁(page)”為最小 I/O 單元來管理的。
頁(Page)是什么?
頁(也稱數據頁、塊 block)是數據庫讀寫時的最小單位,典型大小為 4?KB、8?KB 或 16?KB。
每個頁在內存中對應一個緩沖區幀(buffer frame),從磁盤讀入時,整個頁一起加載;修改時,整個頁也會被標記為“臟頁”并遲緩寫回。
為什么要用頁?
I/O 單元:磁盤和 OS 的 I/O 都是按頁(或塊)做的,讀寫整頁比逐條讀寫要高效得多。
緩存管理:數據庫的 Buffer Pool 也是以頁為單位進行加載和置換。
空間管理:頁作為固定大小的容器,便于分配、回收和查找空閑空間。
B+ 樹的邏輯結構與頁的映射
┌───────────┐┌──────?│ Internal │?──────┐│ ? ? ? │ page(s) │ ? ? ? ││ ? ? ? └───────────┘ ? ? ? │┌──┴──┐ ? ? ? ? ? ? ? ? ? ┌───┴──┐│ ... │ ? ? ? ? ? ? ? ? ? │ ... │└──┬──┘ ? ? ? ? ? ? ? ? ? └───┬──┘│ ? ? ? ┌───────────┐ ? ? ? │└──────?│ Leaf page │?──────┘└───────────┘
內部節點(Internal node)對應一個或多個頁
存放 鍵值 + 子節點指針(頁號或內存指針)。
用于路由查找:從根開始,根據鍵值范圍逐層向下定位到葉子頁。
葉子節點(Leaf node) 對應一系列連續頁
真正存放 完整的索引記錄 或 聚簇索引的全行數據。
通常包含:
索引鍵(Key)
若是非聚簇索引,則附帶 主鍵 作為“行定位指針”;
若是聚簇索引(Clustered Index),葉子頁直接存放整行數據。
頁之間的鏈表
葉子頁還會雙向鏈成一個鏈表,方便范圍掃描;
內部節點頁在分裂/合并時,也可能維護兄弟指針或在父節點更新。
頁內記錄的組織
頁頭(Header)
存放頁類型(內部/葉子)、當前記錄數、Free Space 指針、鏈表指針(前驅/后繼頁號)等元信息。
記錄目錄(Slot Array)
有些數據庫(如 InnoDB)在頁尾維護一個 Slot Array,存放每條記錄在頁內的偏移。
插入/刪除只需調整 Slot Array 及相應記錄位置,避免大量移動。
記錄存儲(Record Storage)
記錄以物理或邏輯順序(根據索引鍵)存儲在頁的主體區域。
有的系統支持 前綴壓縮:只存儲鍵的增量部分,減少空間。
空閑空間管理(Free Space)
頁頭維護一個指向空閑區(free space)的指針;新記錄優先填滿空閑區,再觸發分裂。
頁分裂與合并
頁分裂(Page Split)
觸發:當插入一條記錄到已無足夠空閑空間的葉子頁或內部頁時。
過程:
分配一個“同級”新頁;
將原頁中大約一半偏后的記錄(或指針)移動到新頁;
在父節點中插入一個新的鍵和指向新頁的指針;若父頁也滿,則遞歸向上分裂。
影響:
寫放大:要寫兩個頁(原頁&新頁)及更新父頁;
碎片化:原本連續的邏輯鍵可能跨兩個頁,影響范圍掃描的 I/O 連續性;
內存/緩存抖動:新頁要加載到內存,可能驅逐其他頁面。
頁合并(Page Merge)
觸發:當刪除操作導致某頁的記錄數低于某個閾值(例如空閑空間過大),并且相鄰頁也較空時。
過程:把兩個兄弟頁的記錄合并到一頁,釋放一個頁號,并相應在父節點刪除指針;若父節點太空,也可遞歸向上合并。
順序 vs. 隨機主鍵對頁分裂的影響
順序主鍵(自增、時間戳)
新記錄總插入到葉子頁的最右端,
只會在最右頁“尾部”分裂;
降低對中間頁的頻繁分裂,保證大部分頁都被順序填滿。
隨機/無序主鍵(UUID、散列)
每次插入可以分散到任何葉子頁,
導致各頁隨機“爆滿”并分裂,
頻繁觸發分裂,帶來更高的寫放大和碎片率。
索引分類
索引分類
在MySQL數據庫,將索引的具體類型主要分為以下幾類:主鍵索引、唯一索引、常規索引、全文索引。
| 分類 | 含義 | 特點 | 關鍵字 |
|---|---|---|---|
| 主鍵索引 | 針對表中主鍵創建的索引 | 默認自動創建,只能有一個 | PRIMARY |
| 唯一索引 | 避免同一個表中某數據列中的值重復 | 可以有多個 | UNIQUE |
| 常規索引 | 快速定位特定數據 | 可以有多個 | |
| 全文索引 | 全文索引查找的是文本中的關鍵詞,而不是比較索引中的值 | 可以有多個 | FULLTEXT |
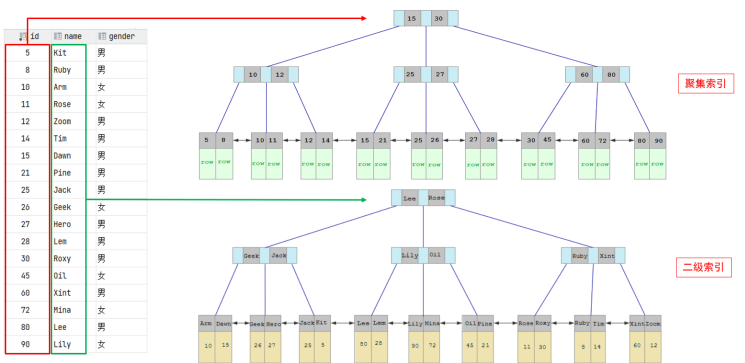
聚集索引 & 二級索引
而在 InnoDB 存儲引擎中,根據索引的存儲形式,又可以分為以下兩種:
| 分類 | 含義 | 特點 |
|---|---|---|
| 聚集索引 (Clustered Index) | 將數據存儲與索引放到了一塊,索引結構的葉子節點保存了行數據 | 必須有,而且只有一個 |
| 二級索引 (Secondary Index) | 將數據與索引分開存儲,索引結構的葉子節點關聯的是對應的主鍵 | 可以存在多個 |
聚集索引選取規則:
如果存在主鍵,主鍵索引就是聚集索引。
如果不存在主鍵,將使用第一個唯一 (UNIQUE) 索引作為聚集索引。
如果表沒有主鍵,或沒有合適的唯一索引,則 InnoDB 會自動生成一個 rowid 作為隱藏的聚集索引。
查找過程-回表查詢
接下來,我們來分析一下,當我們執行如下的SQL語句時,具體的查找過程是什么樣子的
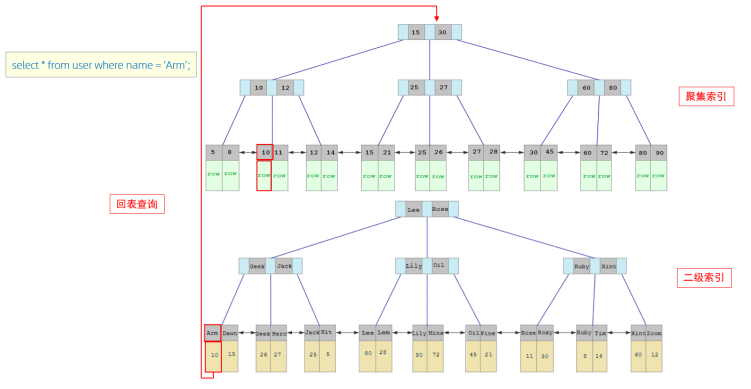
具體過程如下:
①. 由于是根據name字段進行查詢,所以先根據name='Arm'到name字段的二級索引中進行匹配查找。但是在二級索引中只能查找到Arm對應的主鍵值10。
②. 由于查詢返回的數據是*,所以此時,還需要根據主鍵值10,到聚集索引中查找10對應的記錄,最終找到10對應的行row。
③. 最終拿到這一行的數據,直接返回即可。
這個過程也稱為回表查詢
回表查詢: 這種先到二級索引中查找數據,找到主鍵值,然后再到聚集索引中根據主鍵值,獲取
數據的方式,就稱之為回表查詢。
HTML零基礎教學)
)


 ? | DoubleClickHeart(雙擊愛心))













![[逆向工程]160個CrackMe入門實戰之Afkayas.1.Exe解析(二)](http://pic.xiahunao.cn/[逆向工程]160個CrackMe入門實戰之Afkayas.1.Exe解析(二))
