目錄
3D視覺感知任務
單目3D感知
單目3D物體檢測 – 直接預測3D信息
單目3D物體檢測 – 總結
單目深度估計
雙目3D感知
多目3D感知
3D視覺感知任務
? 輸入:單攝像頭或多攝像頭生成的圖像數據
? 單張圖像
? 圖像序列
? 輸出
? 稀疏:物體在3D坐標系中的位置,大小,朝向,速度等
? 稠密:像素點的類別標簽和深度信息
? 算法
? 按輸入來分:單目,雙目,多目
? 按輸出來分:3D物體檢測,場景深度估計

主要難點
? 圖像是真實世界在透視視圖下的投影
? 透視投影導致距離/深度信息丟失
? 圖像上物體的大小隨著距離而變化
? 很難估計物體的實際距離和大小
? 解決方案
? 借助其它傳感器,比如激光雷達
? 借助幾何假設和約束來輔助求解病態問題
? 借助深度學習自動地從圖像中提取 3D 信息
? 借助多個攝像頭和立體視覺算法

單目3D感知
? 單目3D物體檢測
? 反變換
? 關鍵點和3D模型
? 2D/3D幾何約束
? 直接預測 3D 信息
? 單目深度估計
? 監督學習算法

單目 3D 物體檢測 – 反變換
? 基本思路
? 2D圖像反變換到3D世界坐標,再進行物體檢測
? 病態問題:通過一些額外信息來輔助解決
? 幾何假設:目標位于地面(Oy已知 )
? 深度估計:目標深度已知(Oz已知)
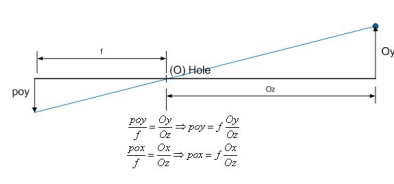
病態問題:已知[ pox,poy ]和 𝑓 ,求解[o x,oy,oz ]
輔助信息1:目標位于地面
? BEV-IPM:2D圖像變換到BEV視圖
? 假設路面和車輛坐標系都與世界坐標系平行 => 路面高度已知
? 在像素高度值已知的情況下,將圖像轉換到BEV視圖
? 采用YOLO網絡在BEV視圖下檢測目標的下邊框(與路面接觸部分)

助信息2:目標深度已知
? Pseudo-LiDAR
? 依據深度圖將輸入圖像轉換為3D點云數據
? 深度估計不依賴于特定的方法
? 可以采用單目,雙目,甚至低線束激光雷達(Pseudo-LiDAR++)
? 采用點云和圖像融合的算法來檢測3D物體
? 深度估計的精度非常關鍵

Wang et al., Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving, CVPR 2019
輔助信息2:目標深度已知
? 問題:可不可以直接采用類似RGB-D的數據表示呢?
? 遠處物體面積非常小,導致檢測不準確
? 相鄰像素深度差別可能很大( 比如物體邊緣),不適合卷積操作

基本思路
? 待檢測的目標(比如車輛)其大小和形狀相對比較固定
? 將3D模型與2D圖像上檢測的關鍵點進行匹配
單目 3D 物體檢測 – 關鍵點和 3D 模型
DeepMANTA(3D車輛檢測)
? 2D圖像上的檢測輸出
? 2D邊框 𝑩𝑩
? 2D關鍵點集合 𝑺𝑺 和可見度 𝑽𝑽
? 與3D模型的相似度 𝑻𝑻
? 根據 𝑻𝑻 選擇相似度最高的3D模型(相當于選擇一個車型)
? 匹配3D模型和2D輸出的關鍵點,得到3D關鍵點 𝑺𝑺 𝟑𝟑𝟑𝟑 和邊框 𝑩𝑩 𝟑𝟑𝟑𝟑
? 每一對( 𝑺𝑺 𝟑𝟑𝟑𝟑 , 𝑺𝑺 𝟐𝟐𝟐𝟐 )可以得到一個匹配度
基本思路
? 2D物體框的表示
? 4維變量:2D的中心點和大小
? 3D物體框的表示
? 9維變量:3D的中心點,大小和朝向
? 無法直接通過2D物體框求解
? 大小和朝向與視覺特征相關性強
? 中心點3D位置很難通過視覺特征預測
? 兩步流程
? 采用2D物體框內的圖像特征來估計物體大小和朝向
? 通過2D/3D的幾何約束來求解物體3D中心點的位置
Deep3DBox
? 約束條件:2D物體框的每條邊上都至少能找到一個3D物體框的角點。
? 超約束問題:約束數量(4個)大于未知參數(3個)數量。
? 這個超約束問題的求解過程也可以建模成一個網絡層,進行端到端訓練
單目3D物體檢測 – 直接預測3D信息
基本思路
? 兩階段檢測,Anchor-based
? 根據先驗知識生成稠密的3D物體候選
? 通過2D圖像上的特征對所有的候選框進行評分
? 評分高的候選框作為最終的輸出
? 單階段檢測,Anchor-free
? 直接從圖像回歸3D信息
? 根據先驗知識設定物體3D參數的初始值
? 神經網絡只需要回歸與實際值的偏差即可
兩階段檢測
? Mono3D
? 基于目標先驗位置(z坐標位于地面)和大小來生成稠密的3D候選框;
? 3D候選框投影到圖像坐標后,通過2D圖像上特征進行評分;
? 特征來自語義分割、實例分割、上下文、形狀以及位置先驗信息;
? 分數較高的候選再通過CNN進行分類和邊框回歸,以得到最終的3D物體框
兩階段檢測,Anchor-based
? TLNet
? 稠密的Anchor帶來巨大的計算量;
? 采用2D圖像上的檢測結果來降低Anchor數量;
? 2D檢測結果形成的3D視錐可以過濾掉大量背
景上的Anchor。
單階段檢測,Anchor-free
? FCOS3D
? 整體網絡結構與2D物體檢測非常相似,只是增加了3D回歸目標
單階段檢測,Anchor-free
? FCOS3D
? 3D回歸目標
? 2.5D中心(ΔX, ΔY,Depth): 3D物體框的中心投影到2D圖像;
? 3D大小(L,W,H)和朝向
單階段檢測,Anchor-free
? FCOS3D
? Centerness的定義
?
以 3D 中心點的 2D 投影為原點的高斯分布

單目3D物體檢測 – 總結

單目深度估計
為什么要做深度估計
? 3D物體檢測中經常需要深度估計的輔助
? 3D場景語義分割需要估計稠密的深度圖
? 基本思路
? 輸入:單張圖像
? 輸出:單張圖像(一般與輸入相同大小),每個像素值
對應輸入圖像的場景深度
? 常用的方法
? 傳統方法:利用幾何信息,運動信息等線索,通過手工設計
的特征來預測像素深度
? 深度學習:通過訓練數據學習到比手工設計更加優越的特征
全局和局部線索融合
? 全局分支:將圖像進行多層卷積和下采樣,得到整個場景的描述特征。
? 局部分支:在相對較高的分辨率上提取局部特征,并與全局特征融合。
? 也可以擴展為多個分支,對應不同的分辨率
DORN:回歸問題轉換為分類問題
? 多個分支提取不同尺度的特征:全局+局部
? 將連續的深度值劃分為離散的區間,每個區間作為一個類別
? 非均勻的深度區間劃分(80m范圍劃分大約 40到120個區間)
雙目3D感知
優勢
? 單目3D感知依賴于先驗知識和幾何約束;
? 深度學習的算法非常依賴于數據集的規模、質量以及多樣性;
? 雙目系統解決了透視變換帶來的歧義性;
? 雙目感知不依賴于物體檢測的結果,對任意障礙物均有效。
? 劣勢
? 硬件:攝像頭需要精確配準,車輛運行過程中也要始終保持配準的正確性;
? 軟件:算法需要同時處理來自兩個攝像頭的數據,計算復雜度較高
雙目深度估計
基本原理
? 概念和公式
? B: 基線長度(兩個相機之間的距離)
? f: 相機的焦距
? d: 視差(左右兩張圖像上同一個3D點之間的距離)
? f和B是固定的,要求解深度z,只需要估計視差d (xl-xr)


基本原理
? 視差估計:對于左圖中的每個像素點,需要找到右圖中與其匹配的點。
? 對于每一個可能的視差(范圍有限),計算匹配誤差,因此得到的三維的誤差數據稱為Cost Volume。
? 計算匹配誤差時考慮像素點附近的局部區域,比如對局部區域內所有對應像素值的差進行求和。
? 通過Cost Volume可以得到每個像素處的視差(對應最小匹配誤差的 𝑑𝑑 ),從而得到深度值
PSMNet
? 左右圖像上采用共享的卷積網絡進行特征提取
? 包含下采樣,金字塔結構和空洞卷積來提取多分辨率的信息并且擴大感受野
? 左右特征圖構建Cost Volume
? 3D卷積提取左右特征圖以及不同視差級別之間的信息
? 上采樣到原始分辨率,找到匹配誤差最小的視差值
多目3D感知
Mobileye和ZF的三目系統
? 通過不同焦距的攝像頭來覆蓋不同范圍的場景
? 包含一個150°的廣角攝像頭,一個52°的中距攝像頭和一個28°的遠距攝像頭
? 保證中近距的探測視野和精度,用于檢測車輛周邊的環境
? 最遠探測距離可以達到300米
Foresight的四目感知系統
? 增加不同波段的傳感器,獲取更多的環境信息
? 可見光雙目攝像頭 + 長波紅外(LWIR)雙目攝像頭
? 增強了在夜間環境以及在雨霧天氣下的適應能力
? 雙目紅外攝像頭安裝在擋風玻璃的左右兩側,以增加基線長度
Tesla的多目全景感知系統 FSD(Full Self Driving)
? 不同位置,不同探測范圍的攝像頭,覆蓋360度視場
? 集成了深度學習領域的最新研究成果,在多攝像頭融合方面也很有特點
? “向量空間”的概念
? 環境中的各種目標在世界坐標系中的表示空間;
? 對于物體檢測任務,目標在3D空間中的位置、大小、朝向、速度等描述特性組成了一個向量;
? 對于語義分割任務,車道線或者道路邊緣的參數化描述組成了一個向量;
? 所有描述向量組成的空間就是向量空間。
? 視覺感知系統的任務:將圖像空間轉化為向量空間
? 決策層融合(后融合)
? 在圖像空間中完成所有的感知任務,將結果映射到向量空間,最后融合多攝像頭的感知結果。
? 特征層融合(前融合)
? 將圖像特征轉換到世界坐標系,融合來自多個攝像頭的特征,最后得到向量空間中的感知結果
)


:2022年12月2023年12月)






)




)
)


