寫在前面
高質量數據的準備是微調大模型的重中之重,一些高質量的數據集可能遠比模型性能更佳重要。
我是根據自己的數據照著B站up code花園LLaMA Factory 微調教程:如何構建高質量數據集?_嗶哩嗶哩_bilibili做的。
數據集格式
在LLaMA Factory中,支持Alpaca 格式和 ShareGPT 兩種格式,詳細可以自行去查查,下面是兩個格式的示例。

Alpaca 數據格式

? ShareGPT?數據格式
采用Easy Dataset制作數據集
Easy Dataset是一個專門創建大型語言模型數據集的程序。它能將行業領域的語料庫轉換為結構化的數據集。

安裝
安裝教程見官方文檔https://docs.easy-dataset.com/
Easy Dataset工具使用
打開程序,然后創建項目

進入模型配置,這里我旋轉qwen模型(主要是阿里大氣,學生認證免費送300代金卷),注意需要配置對應平臺的api key。


任務配置可以更具需求設置

提示詞配置可以不做,如果生成的有問題在調整提示詞。

文獻處理,這里先選擇模型,再選擇需要處理的文獻,然后就可以開始處理文獻了,

可以查看右方的GA對,GA對可以參考https://zhuanlan.zhihu.com/p/1916488453228561713。主要意思就是針對不同群里設置的不同深度語氣格式的數據集。


查看分割和領域分析數據是否生成合理,如果不合理需要人工干預

一切就緒之后開始提取問題
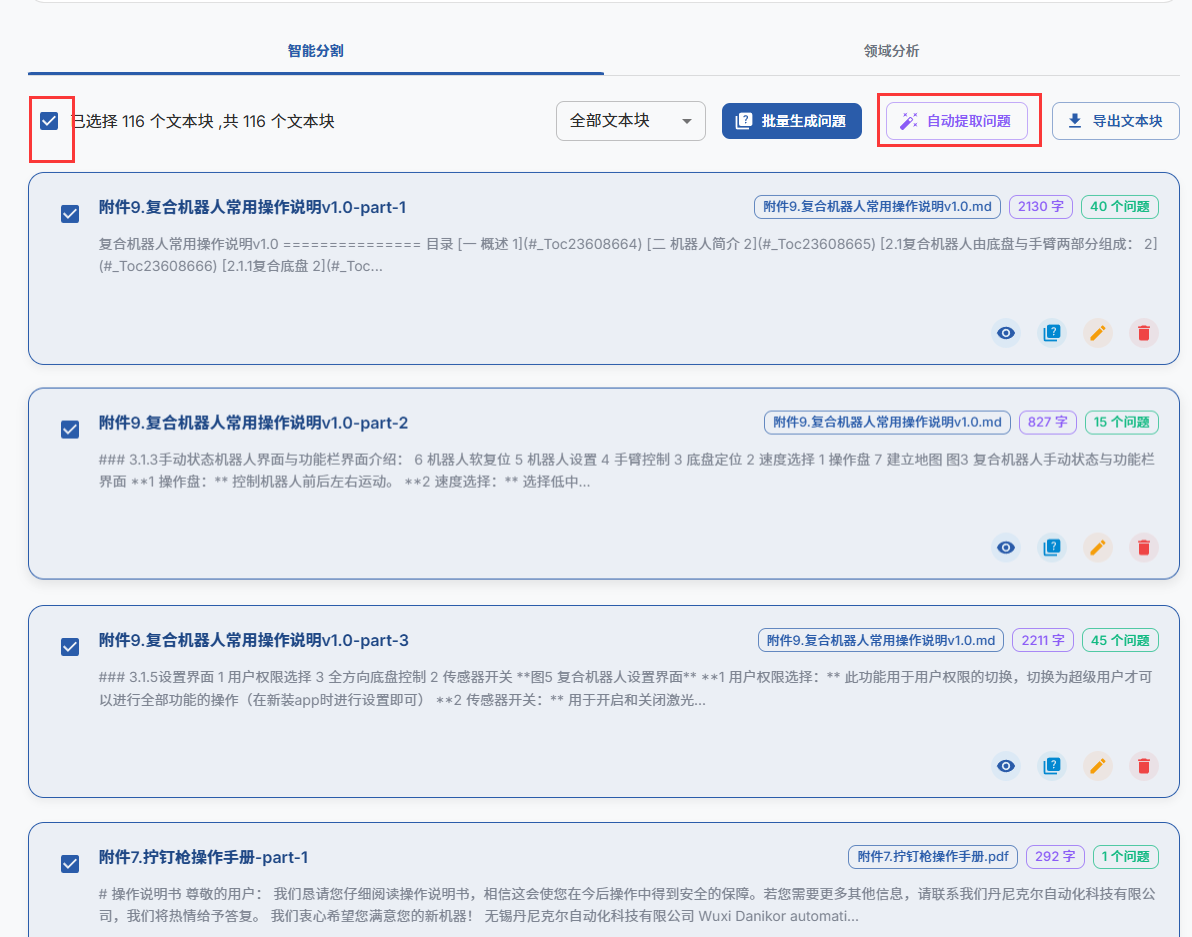
右上方有任務進行進度,整個過程都是并發運行,可以切換到其他界面操作。一些就緒之后進入問題管理界面查看問題,然后切換模型到推理效果好的deepseek-R1模型,就可以生成答案了.

然后等待生成。幸好deepseek便宜,一個小時才花5塊錢,而且硅基流動也有學生認證,認證送50代金卷。

還能用數據蒸餾增加數據集,這個步驟等待時間較長,生成的數據集也多。

等數據生成結束之后,進入數據集管理界面,導出數據,這里可以導出在LLaMA Factory中使用,會得到一個配置文件。


進入這個文件路徑,打開dataset_info文件發現就是LLaMA Factory要求的格式。


在LLaMA Factory直接將數據路徑粘貼到數據集路徑那里

最后配置好LLaMA Factory的參數就可以開始訓練了。









)


linux)






