前言
在學習數據結構的時候我們學習過二叉樹,那啥是搜索二叉樹呢?我們知道單純的二叉樹沒有增刪查改的實際意義,因為沒有任何限制條件的二叉樹其實用處很局限。但是堆就不一樣了,他就是一個二叉樹加上了大小堆的限制條件,在排序方面很有作用,比如堆排序,時間復雜度是n*logN,效率挺高的。那搜索二叉數是加了上限制條件呢?搜索二叉數:本質是一顆二叉樹+左子樹的所有節點都小于根節點的值(左子樹不為空的話)+右子樹的所有結點的值都大于根節點的值(右子樹不為空)+左右子樹也分別為搜索二叉樹。
總結下:搜索二叉樹
- 若他的左子樹不為空,左子樹的所有節點的值都小于根節點的值
- 若他的右子樹不為空,右子樹的所有結點的值都大于根節點的值
- 他的左右子樹也分別為搜索二叉樹
我們管搜索二叉樹也叫二叉搜索樹,或者二叉排序樹。這里提問下,他為啥可以叫二叉搜索樹呢?
我們看一下這兩個,SBTree(搜索二叉樹),BSTree(二叉搜索樹),你覺得SB好聽呢?還是BSTree,讓你更舒服點呢?這里開玩笑,其實叫啥都行,畢竟都有b樹這種名字(聽著就像在罵人)。可見取名字的人水平不是很高呀。好了,回到正文。
正文
在實現之前我們先看一顆搜索二叉樹,如下圖:

這棵樹就是一顆二叉搜索樹,你用中序遍歷一遍會發現他是有序的,這也是他的實際用處。搜索二叉數主要運用在一些Kye搜索模型,快速判斷在不在的場景,比如小區車輛出入系統。還有就是Key/Value模型,比如大名鼎鼎的高鐵實名認證系統。
搜索二叉數的實現
基本代碼
//結點
template<class K>
struct BSTreeNode
{BSTreeNode<K>* left;BSTreeNode<K>* right;K _key;BSTreeNode(const K& key):left(nullptr), right(nullptr), _key(key){}
};//二叉搜索樹
template<class K>
class BSTree
{typedef BSTreeNode<K> Node;
public://構造BSTree():_root(nullptr){}//析構~BSTree(){Destroy(_root);}//拷貝構造BSTree(const BSTree<K>& t){_root = Copy(t._root);}//賦值重載 現代寫法BSTree<K>& operator=(BSTree<K>& t){std::swap(_root, t._root);return *this;}//中序遍歷void InOrder(){_InOrder(_root);cout << endl;}void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->left);cout << root->_key << " ";_InOrder(root->right);}private:
//拷貝
Node* Copy(Node* root)
{if (root == nullptr){return nullptr;}Node* copyRoot = new Node(root->_key);copyRoot->left = Copy(root->left);copyRoot->right = Copy(root->right);return copyRoot;
}
//后序刪除 引用置空 方便很多
void Destroy(Node*& root)
{if (root == nullptr){return;}Destroy(root->left);Destroy(root->right);delete root;root == nullptr;
}Node* _root;
};
這里實現析構,拷貝構造,都是采用套娃的思路,定義一個私有方法,使用私有方法完成代碼的邏輯,在public的方法就是調用這些方法,這樣邏輯很清晰,庫里很多代碼都是這樣實現。如果你學過一點java,會發現java里全是這樣的設計。這里的賦值重載是用的現代寫法,直接交換根節點,返回this指針,這也是推薦的寫法,傳統的一個一個賦值的寫法,太麻煩了,這里不推薦。其實這里拷貝構造這樣設計還有一個原因就是,你無法直接傳一個_root,只能傳一個樹,但是我們有需要_root,因此只能采取這種方式,上傳_root參數,實現拷貝效果。下面講的是搜索二叉數里的核心代碼,有兩個版本,都要掌握。
非遞歸版
這里介紹了,查找,插入,刪除,返回值都是bool值,表示成功與否。
//插入
bool Insert(const K& key)
{if (_root == nullptr) {_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->right;}else if (cur->_key > key){parent = cur;cur = cur->left;}else{return false;}}//記得鏈接 局部變量賦值 不會影響我們的鏈表cur = new Node(key);if (parent->_key > key){parent->left = cur;}else{parent->right = cur;}}
//查找
bool Find(const K& key)
{Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->right;}else if (cur->_key > key){cur = cur->left;}else{return true;}}return false;
}
//刪除(重點) 思路先找后刪除 刪除有兩種可能一個/沒有孩子 或者 多個孩子>=2(替換法)
bool Erase(const K& key)
{Node* parent = nullptr;Node* cur = _root;//空樹進不去while (cur){if (cur->_key < key){parent = cur;cur = cur->right;}else if (cur->_key > key){parent = cur;cur = cur->left;}//找到了 刪除else{//左為空if (cur->left == nullptr){if (cur == _root){_root = cur->right;}else{if (parent->right == cur){parent->right = cur->right;}else{parent->left = cur->right;}} }//右為空else if (cur->right == nullptr){if (cur == _root){_root = cur->left;}else{if (parent->right == cur){parent->right = cur->left;}else{parent->left = cur->left;}} }//替換法else{//cur = 8;Node* leftParent = cur;Node* leftMax = _root->left;while (leftMax->right){leftParent = leftMax;leftMax = leftMax->right;}std::swap(leftMax->_key, cur->_key);if (leftParent->left == leftMax){leftParent->left = leftMax->left;}else{leftParent->right = leftMax->left;}cur = leftMax;}delete cur;return true;}}return false;
}Find實現
我們前面講過,搜索二叉數的特點,適合排序。因此,我們在查找值的時候,可以根據左右子樹大于/小于根這一特性,實現查找,這樣查找的效率就不會是全部遍歷一遍,如果比根小,那我們就可以直接在左子樹里找,所以這里的時間復雜度就是高度次。我們這里非遞歸實現就是使用while循環cur指針,if else if分支語句,控制查找方向,在循環內找到,就進入else語句。如果循環解釋還沒找到,這時cur指針為空,那說明就沒有,直接返回false 。提問下,這里的時間復雜是,O(n)還是logN,答案是O(n),不是查找高度次嗎,二叉樹的高度不是logN嗎?這里二叉搜索樹不一定就很滿足完全二叉樹的條件,他甚至可以這樣,如下圖

這種情況是肯定存在的,在這種情況幾乎就是O(n),所以這里二叉搜索樹,也沒有很厲害,因此我們后面還要學習紅黑樹,他的底層就是二叉搜索樹。這里我沒有套值進去,大家可以自己套一下,這種情況是包存在的。
Insert實現
插入的代碼的遍歷樹和查找是一個邏輯的,不同就是,插入是要循環外,當cur指針為空的時候再插入結點,所以這里需要new 一個結點,但是這并沒有真正改變鏈表里的指向,我們需要引入一個父節點,來鏈接這里的關系。這里在根指針為空的時候,我們直接特殊處理,new結點賦值給root,然后返回true就行。這里注意二叉搜索樹是不允許重復的值,這也符合他的特性。因此這里插入失敗就是發現了重復的值。這里在用父節點,改變鏈接關系的時候,需要保證插入后還是一個二叉搜索樹,因此,還需要判斷一下他與父節點值的大小,再決定插入在左邊還是右邊。

入上圖,這里插入-1還是2就是不同的結果,或者插入可能就會改變了這棵樹,導致這棵樹不再是二叉搜索樹。
Erase實現
這里把這個刪除放在最后講,是因為刪除是最難的一個實現,而且考的話也應該就是考這個(題目),這里刪除是要分好幾個情況
第一種情況:沒有孩子或者一個孩子-->托孤
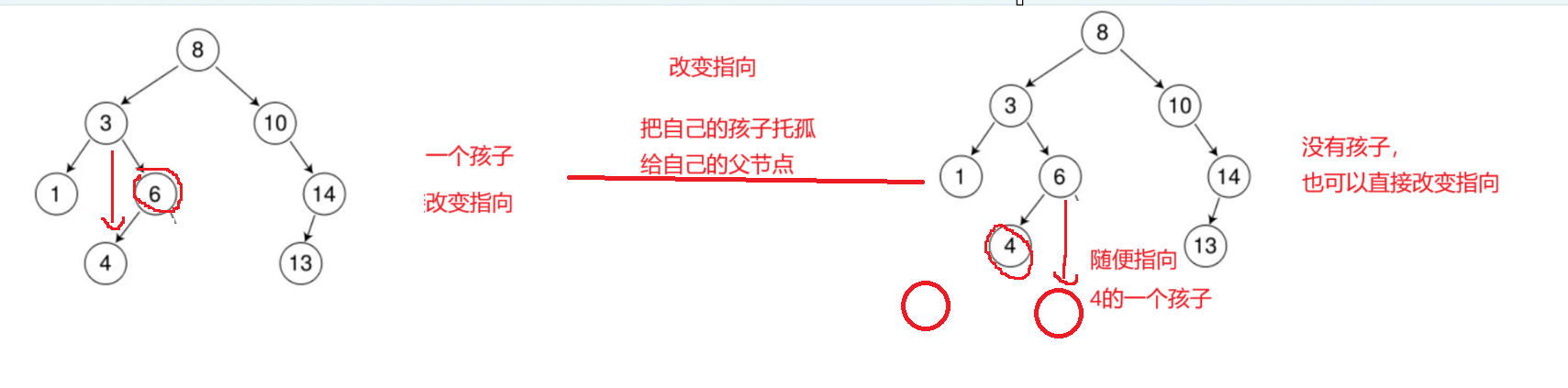
對于第一種情況,我們需要定義一個父節點,改變鏈接關系,那這里父節點是賦值給空指針呢還是賦值給cur指針呢,這里只能賦值cur指針,因為有一種情況會導致空指針引用問題,如下圖

第二種情況:兩個及兩個以上的孩子-->替換法

這里也是需要一個父節點,再替換后,改變鏈接關系,但是注意這里是需要做一下判斷的,不一定就是右子樹改變關系,如下圖

遞歸版
//遞歸實現bool FindR(const K& key){return _FindR(_root, key);}bool InsertR(const K& key){return _InsertR(_root, key);}bool EraseE(const K& key){return _EraseE(_root, key);}遞歸是需要上傳一個root節點,但是我們只能上傳一個個樹,所以這里采取內部上傳根節點,調用私有方法實現。
Find實現
bool _FindR(Node* root, const K& key){if (root == nullptr) return false;if (root->_key < key) {_FindR(root->right, key);}if (root->_key > key){_FindR(root->left, key);}else{return true;遞歸版就簡單多了,使用二叉搜索樹的特性判斷,和上面循環的版本是一樣的,只不過是吧循環該遞歸了而已
Insert實現
//這里引用 起到了自動鏈接的作用 bool _InsertR(Node*& root, const K& key){//為空鏈接 if (root == nullptr) {root = new Node(key);return true;}if (root->_key < key) {_InsertR(root->right, key);}if (root->_key > key){_InsertR(root->left, key);}//找不到else{return false;}}這里遞歸實現插入也很簡單,非遞歸的版本是需要用父節點來鏈接,但是遞歸的版本我們可以不用這樣子做,把參數改成引用,這樣子改變的就不再是局部變量,而是直接改變本體。
Erase實現
//遞歸實現bool _EraseE(Node*& root, const K& key){if (root == nullptr) return false;//這里是if else if 一個執行了 另一個就不能執行 否則 你出錯if (root->_key < key){_EraseE(root->right, key);}else if(root->_key > key){_EraseE(root->left, key);}//找到了else{Node* del = root;if (root->left == nullptr){root = root -> right;}else if (root->right == nullptr){root = root->left;}else{Node* leftMax = root->left;while (leftMax->left){leftMax = leftMax->right;}std::swap(root->_key, leftMax->_key);//這里不能傳leftMax 指向改變會亂return _EraseE(root->left, key);}delete del;}return true;}這里遞歸實現刪除相比于非遞歸的版本就簡單多了,刪除里面尋找代碼的邏輯和查找是一樣的,沒啥好講,主要是找到了之后我們該如何處理。上面插入的時候我們使用了引用直接改變了本體,不用再使用父節點改變鏈接關系,這里也是可以用引用,不用在搞一個父節點。刪除的思路和非遞歸是一致的,也是分兩種情況,不過這里有點復雜,因為你遞歸傳的是一個節點的左子樹或右子樹的指針的引用,因此你是可以直接改變這個本體,所以在判斷的時候,直接就用這個引用本身判斷他的左子樹還是右子樹為空,然后在選擇賦值給這個引用,就改變鏈接關系。然后替換也是找到節點交換節點的值,不過這里我們就可以再次遞歸,而不是直接刪除,因為這里你沒有父節點,也無法直接刪除,否則鏈接關系也沒法改變,我們干脆把遞歸思想貫徹到底,上傳root->left去刪除節點就行。注意這里不可以傳leftMax,指向會直接改變,這里引用比較復雜,大家畫圖理解建議,這里剛開始看這里的代碼,我也是沒想通,但花了圖,就想明白了。
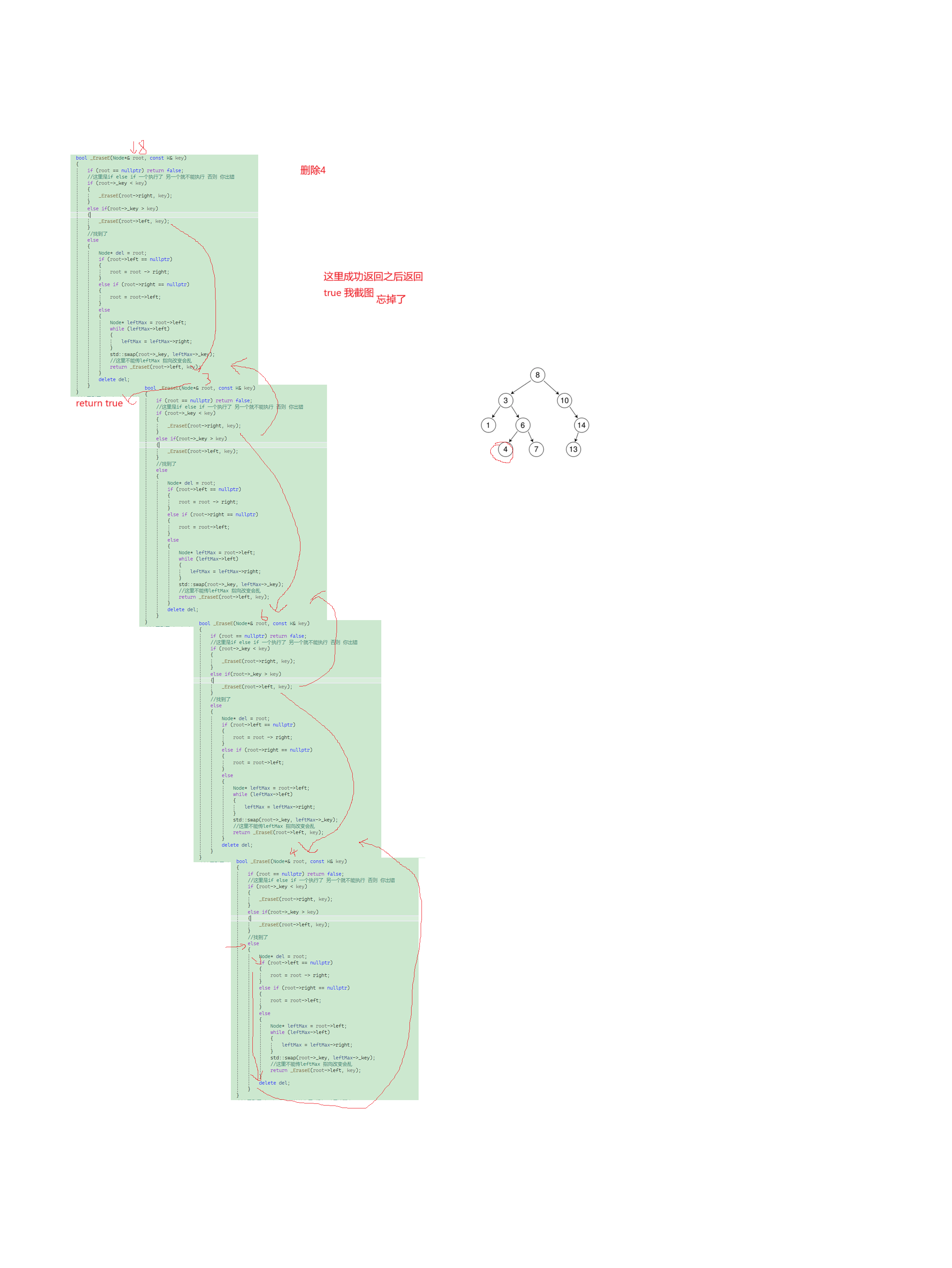
這里遞歸不理解,其實很好理解,畫遞歸展開圖,就可以解決大部分問題。
總結
搜索二叉樹其實整體上講還是比較簡單的,主要是為后面的紅黑樹打基礎,在學習C語言的時候我們發現有些數據結構很難寫,但是學到c++之后,會發現這些數據結構直接放在STL容器里,而且他們的實現也好寫多了,像這個二叉搜索樹更適用于c++寫,其實二叉樹的學習,以及到后面的紅黑樹,都是更適用于c++。








)
)






)


