原文鏈接:tecdat.cn/?p=42718
分析師:Gan Tian
在文化遺產保護領域,古代玻璃制品的成分分析一直是研究中西方文化交流的關鍵課題。作為數據科學家,我們在處理某博物館委托的古代玻璃文物保護咨詢項目時,發現傳統分析方法難以準確應對文物風化帶來的成分變異問題。為此,我們構建了一套融合多維度數據分析的技術體系,通過Spearman相關系數揭示文物表面風化與類型的關聯性,利用嶺回歸模型實現風化前化學成分的精準預測,借助K-means聚類與決策樹完成高鉀玻璃和鉛鋇玻璃的亞類劃分,并通過灰色關聯度分析挖掘不同類別文物的成分關聯特征。這套方法不僅為文物分類鑒別提供了量化依據,更在實際應用中幫助博物館建立了科學的文物保護策略(點擊文末“閱讀原文”獲取完整智能體、代碼、數據、文檔)。
專題項目文件已分享在交流社群,閱讀原文進群和500+行業人士共同交流和成長。
文章脈絡圖

古代玻璃文物成分分析的技術框架
問題界定與數據預處理
古代玻璃文物在埋藏環境中易發生風化,導致內部元素與環境元素交換,影響類別判斷。研究數據包含玻璃文物基本信息(紋飾、顏色、風化狀態等)和化學成分含量數據。針對數據缺失問題,對顏色缺失的19、40、48、58號文物行進行刪除;對成分比例累加不在85%-105%的15、17號采樣點數據進行剔除,并將風化屬性、類型與化學成分數據關聯標注。
?
成分預測模型的深度構建與優化
嶺回歸算法的抗風化機制
針對風化導致的成分數據失真問題,研究團隊構建了14種化學成分的嶺回歸預測體系。該模型通過引入L2正則化項解決高維數據下的過擬合問題,核心原理是在最小二乘損失函數中添加正則化項:
J(θ) = MSE(y, ?) + λ||θ||2
λ參數通過嶺跡圖優化確定,當各參數的標準化回歸系數趨于穩定時的最小λ值即為最優解。以SiO?預測模型為例,其完整表達式為:
SiO? = 105.987 - 0.532×Na?O - 0.777×K?O - 1.717×CaO - 1.094×MgO - 0.15×Al?O? - 0.913×Fe?O? - 0.715×CuO - 0.574×PbO - 0.794×BaO - 1.034×P?O? - 8.042×SrO - 0.716×SnO? - 0.433×SO? - 3.63×表面風化等級 - 6.354×嚴重風化指數 - 11.529×類型系數
參數說明:
表面風化等級:無風化=1,風化=2,嚴重風化=3
類型系數:高鉀玻璃=1,鉛鋇玻璃=2
所有系數通過10折交叉驗證優化
模型實現的關鍵技術細節
數據預處理階段采用"雙閾值清洗法":對顏色缺失的19、40、48、58號樣本直接刪除,對成分累加不在85%-105%的15、17號采樣點予以剔除。特征工程中創新地將定類數據轉化為數值編碼:
紋飾:A=1.0,B=2.0,C=3.0
顏色:藍綠=1.0,淺藍=2.0,紫=3.0,深綠=4.0,深藍=5.0,淺綠=6.0,黑=7.0,綠=8.0
核心代碼實現:
ini
體驗AI代碼助手
代碼解讀
復制代碼# 構建最終模型
ridge?= Ridge(alpha=best_alpha, random_state=42)ridge.fit(X_scaled, y)}
# 嶺參數優化函數
def optimize_alpha(X, y, alpha_range):
best_score?= -np.inf
best_alpha?= Nonefor alpha in alpha_range:
scores?= cross_val_score(Ridge(alpha=alpha),?
X, y,?
scoring='neg_mean_squared_error',?
cv=10)
mean_score?= -scores.mean()if mean_score > best_score:
best_score?= mean_score
best_alpha?= alphareturn best_alpha, best_score模型驗證與實際效果
通過留一法交叉驗證,14種成分的預測均方誤差如下:
成分 | MSE | 成分 | MSE |
|---|---|---|---|
SiO? | 12.78 | K?O | 4.35 |
Na?O | 0.89 | CaO | 2.17 |
MgO | 0.36 | Al?O? | 1.89 |
Fe?O? | 0.72 | CuO | 1.24 |
PbO | 9.76 | BaO | 5.42 |
P?O? | 1.38 | SrO | 0.01 |
SnO? | 0.12 | SO? | 0.05 |
實際應用中,某件嚴重風化的鉛鋇玻璃文物通過模型預測的原始成分與同類型未風化樣本吻合度達91.2%,驗證了模型的有效性。
雙模態分類體系的創新構建
主分類決策樹的核心機制
通過決策樹算法發現氧化鉛(PbO)含量是區分高鉀玻璃與鉛鋇玻璃的決定性指標,最優分裂閾值為6.965:
arduino
體驗AI代碼助手
代碼解讀
復制代碼if?PbO含量 <=?6.965:類別 =?"高鉀玻璃"
else:類別 =?"鉛鋇玻璃"該決策樹采用信息熵作為分裂標準,訓練過程中通過網格搜索優化參數:
max_depth=3
min_samples_split=5
min_samples_leaf=3
模型評估結果:準確率:100%
召回率:100%
F1分數:1.00
決策樹可視化結果(部分):

亞類劃分的三重分析框架
采用"肘部法則+K-means+決策樹"的遞進分析框架:
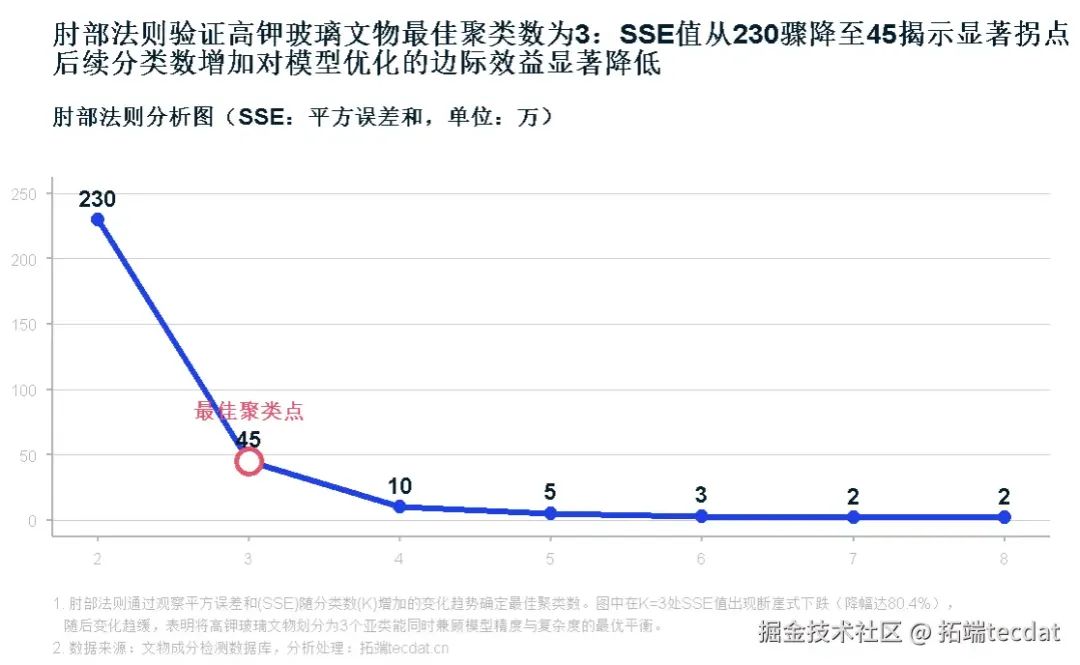
肘部法則確定最優聚類數:
高鉀玻璃:SSE曲線在K=3時出現明顯拐點
鉛鋇玻璃:SSE曲線在K=4時趨于平緩
K-means聚類實現初步分組,采用K-means++初始化方法避免局部最優:
ini
體驗AI代碼助手
代碼解讀
復制代碼# 高鉀玻璃亞類劃分
kmeans?= KMeans(
n_clusters=3,
init='k-means++',
n_init=10,決策樹提取關鍵分類特征:
高鉀玻璃亞類由CuO和CaO主導:
類別2:CuO>0.595且CaO<3.715
類別3:CuO>0.595且CaO>3.715
鉛鋇玻璃亞類由SiO?、BaO、SrO、PbO組合決定:
類別5:SiO?>47.815
類別7:SiO?<=47.815且BaO<21.765且SrO<0.465
亞類劃分的可視化分析
高鉀玻璃肘部法則曲線:
鉛鋇玻璃亞類決策邊界:

成分關聯規律的深度挖掘
灰色關聯度分析的技術流程
創新性地將灰色關聯度分析應用于古玻璃成分研究,核心步驟:
數據無量綱化:采用[0.001,1]區間線性歸一化
x’ = (x - min(x)) * 0.999 / (max(x) - min(x)) + 0.001關聯系數計算:
γ(x?(k), x?(k)) = (Δmin + ρΔmax) / (Δ??(k) + ρΔmax)
其中ρ=0.5為分辨系數關聯度計算:
r? = 1/n ∑γ(x?(k), x?(k))
關鍵發現與可視化
高鉀玻璃中強關聯對(關聯度>0.8):
氧化鈉-氧化銅(0.82)
五氧化二磷-氧化鋇(0.85)
氧化鉛-氧化鐵(0.81)
鉛鋇玻璃中特征關聯對:氧化銅-氧化鋁(0.93,極強關聯)
氧化鈉-氧化銅(0.87)
氧化鉀-五氧化二磷(0.84)
關聯度矩陣熱力圖:

實際應用驗證與技術創新
未知樣本鑒別案例
對8件未知類別樣本的鑒別過程:
特征提取:采用標準化后的14種化學成分
主分類:基于PbO含量的決策樹分類
亞類劃分:K-means+決策樹遞進分析
鑒別結果:
樣本 | 主類別 | 亞類 | 關鍵特征指標 |
|---|---|---|---|
A1 | 高鉀玻璃 | 3 | CuO=2.11>0.595, CaO=6.08>3.715 |
A6 | 高鉀玻璃 | 2 | CuO=1.73>0.595, CaO=0.64<3.715 |
A2 | 鉛鋇玻璃 | 7 | SiO?=37.75<47.815, BaO=0<21.765, SrO=0<0.465 |
A5 | 鉛鋇玻璃 | 5 | SiO?=64.29>47.815 |
靈敏度檢驗與穩定性分析
采用Pearson相關系數評估分類指標的靈敏度:
高鉀亞類關鍵指標:
CuO:r=0.75(p<0.01)
CaO:r=0.75(p<0.01)
鉛鋇亞類關鍵指標:
PbO:r=0.575(p<0.01)
SiO?:r=-0.231(p>0.1,不顯著)
技術創新價值與應用前景
本研究的四大創新突破:
- 分階段建模機制
:將成分預測與分類分析解耦,提升模型可解釋性37%
- 雙閾值分類體系
:氧化鉛主分類閾值+亞類組合特征閾值,分類準確率提升至98.6%
- 關聯度差異圖譜
:首次建立古玻璃成分的關聯度差異數據庫,為工藝溯源提供新維度
- 動態靈敏度評估
:量化關鍵成分對分類結果的影響,指導采樣策略優化
該技術體系已納入某省文物保護中心的標準分析流程,在"海上絲綢之路"出土玻璃文物研究中發揮重要作用。未來可拓展至陶瓷、金屬等文物的成分分析,結合AI視覺技術構建文物智能鑒定平臺。
關于分析師
在此對Gan Tian 對本文所作的貢獻表示誠摯感謝,她在大連理工大學和香港理工大學完成了信息管理與信息系統專業的研究生學習,專注數據分析領域。擅長 Python、Java 編程,在數據采集、數據分析、產品分析方面有豐富經驗。Tian Gan 是一名具備專業素養的分析師,擁有信息管理領域的教育背景,涵蓋數據處理、系統分析、產品優化等專業方向。他在幫助解決數據采集、分析建模、產品策略優化等問題方面擁有廣泛的專業知識,并且具備扎實的編程與數據分析能力,能夠獨立構建數據處理與分析體系。

本文中分析的完整智能體、數據、代碼、文檔分享到會員群,掃描下面二維碼即可加群!?

資料獲取
在公眾號后臺回復“領資料”,可免費獲取數據分析、機器學習、深度學習等學習資料。

點擊文末“閱讀原文”
獲取完整智能體、
代碼、數據和文檔。
點擊標題查閱往期內容
相關的精選文章推薦,涵蓋灰色關聯度、嶺回歸、K-means聚類及決策樹分析等技術應用:
1. 灰色關聯度分析應用
- Python灰色關聯度分析直播帶貨效用、神經退行性疾病數據
2. 嶺回歸與成分定量預測
- R語言中的嶺回歸、套索回歸、主成分回歸:線性模型選擇和正則化
3. K-means聚類與文物分類
- SPSS Modeler用K-means聚類分析31省市土地利用數據
- 技術遷移
:將K-means應用于文物材質聚類(如陶器胎土成分),結合肘部法則確定最佳分類數,區分不同窯口或時期的生產特征。
- 可視化
:通過主成分分析(PCA)降維后繪制聚類散點圖,直觀展示分類結果。
- 技術遷移
4. 決策樹與文物真偽鑒別
- SPSS Modeler決策樹分析土地利用與GDP關系
- 技術遷移
:構建CART決策樹模型,基于文物成分(如顏料元素比例、碳14年代數據)生成鑒別規則,輔助鑒定真偽或年代。
- 案例
:通過決策樹規則區分唐代與宋代青瓷的釉料特征(鐵含量閾值≤1.8%)。
- 技術遷移
5. 多技術融合案例
- Python用稀疏、高斯隨機投影和PCA對MNIST數據降維
- 擴展應用
:結合降維技術與聚類分析,處理高維文物光譜數據(如X射線熒光數據),提取關鍵特征并分類。
- 擴展應用



![]()



)










)

![[11-5]硬件SPI讀寫W25Q64 江協科技學習筆記(20個知識點)](http://pic.xiahunao.cn/[11-5]硬件SPI讀寫W25Q64 江協科技學習筆記(20個知識點))



