自然語言處理初期發展歷程
早期:離散表示
? ? ? ? one-hot(只表達“有/無”,語義完全丟失)→ n-gram(局部上下文,但高維稀疏)→ TF-IDF(考慮詞頻與權重,但不能表達詞關聯),可見,缺點非常明顯,達不到要求
過渡:分布式思想萌芽
? ? ? ?LSA等降維嘗試,引入“詞語義空間”思想,但非神經網絡。
突破:神經網絡分布式表示
NNLM(深度學習自動學語義嵌入,訓練慢)
word2vec(極大提高訓練效率與質量,催生“詞嵌入”大潮流)
主流趨勢
? ? ? ?低維、稠密、有語義的詞向量成為自然語言理解基礎,后續BERT等“上下文相關詞向量”技術,是word2vec之后更高階的語義學習。
? ? ? ?理念從“詞級one-hot”→“全局加權”→“上下文分布”→“深度學習自學表示”。
小結
? ? ? ?one-hot、n-gram、TF-IDF:簡單直觀,但稀疏、高維、語義弱。
分布式表示、NNLM、word2vec:低維稠密,語義能力強,推動深度學習NLP大發展。
? ? ?從one-hot到word2vec,是NLP詞表示從“人工特征”到“自動語義學習”的質變。
發展過程中,案例展示
一,one-hot
基本的語意:

對文本的表示:

優缺點:

二、TF-IDF
基礎公式描述

公式表達:?

優缺點分析;?

三、N-gram
基礎語法表達:
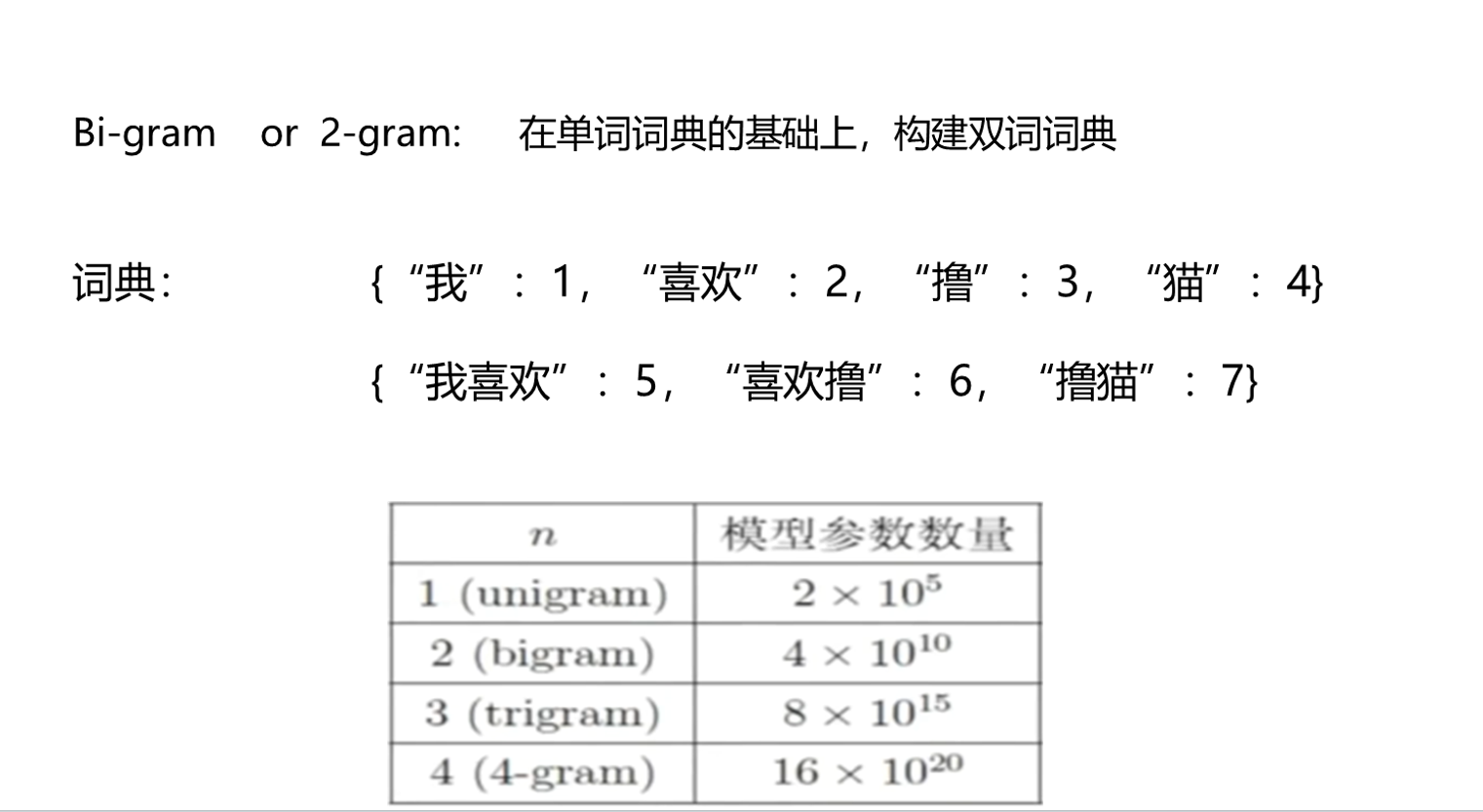
優缺點:?

語言模型:?

離散表示:

四、分布式
表示方法表示:

優缺點:

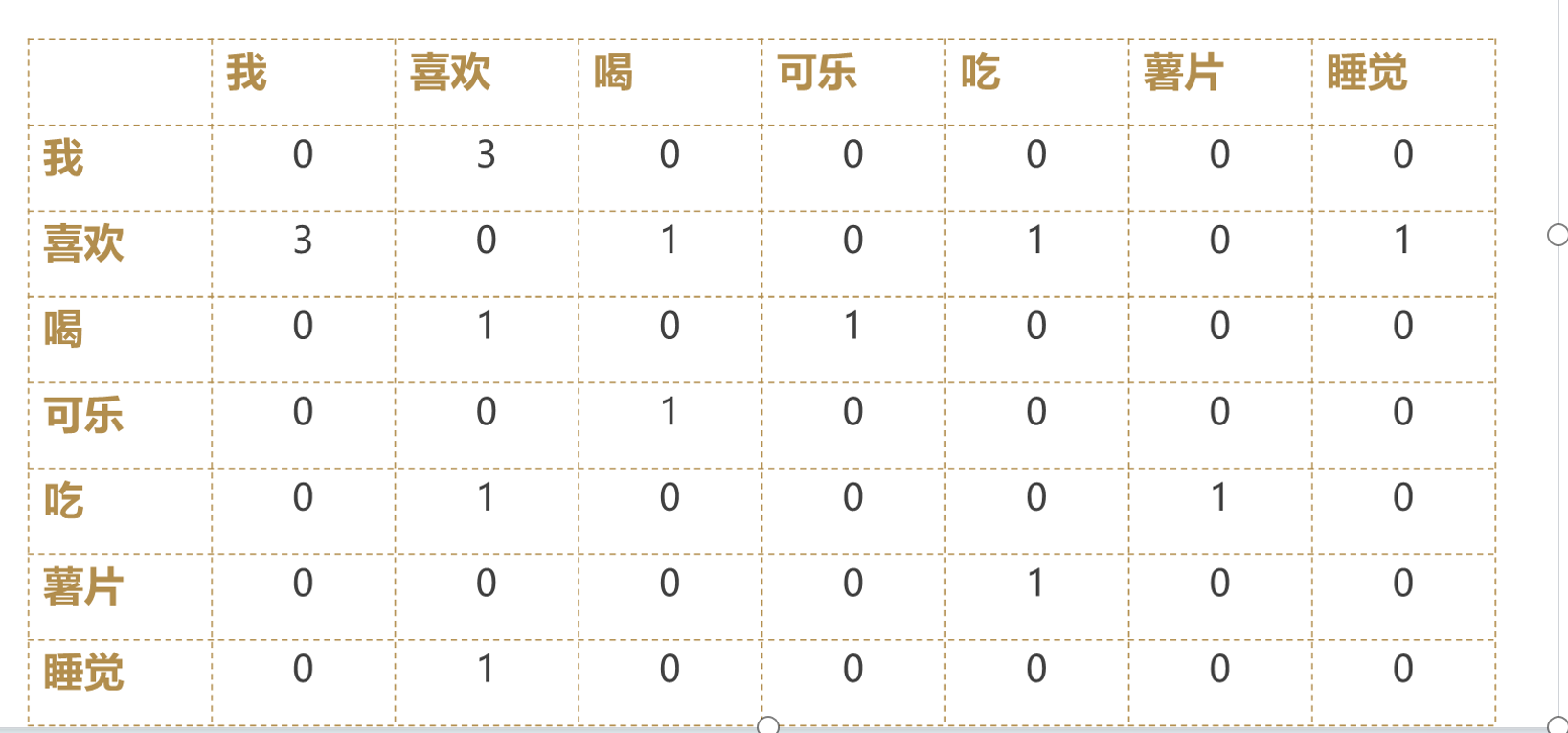
共現矩陣的表達方式
表達方式:
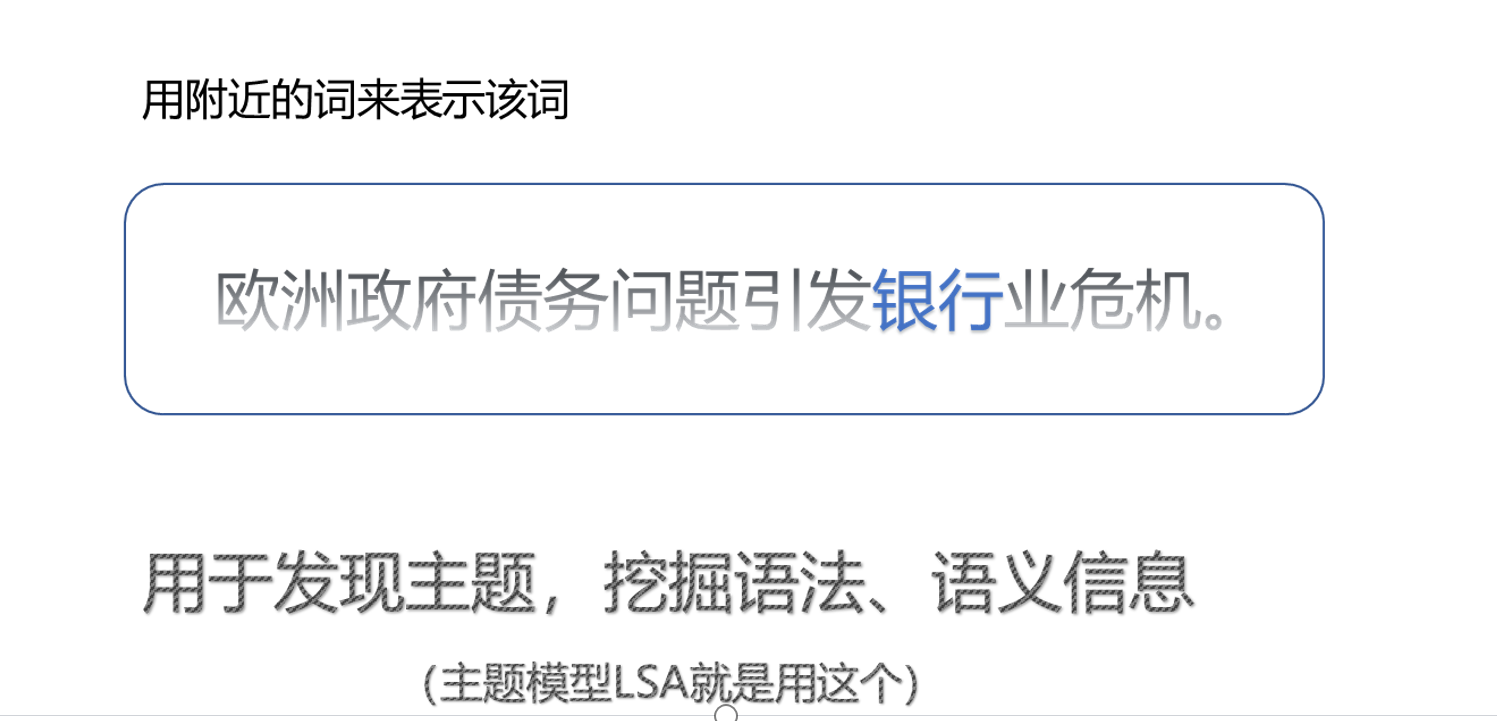
表達案例:?
優缺點:?

公式展現?
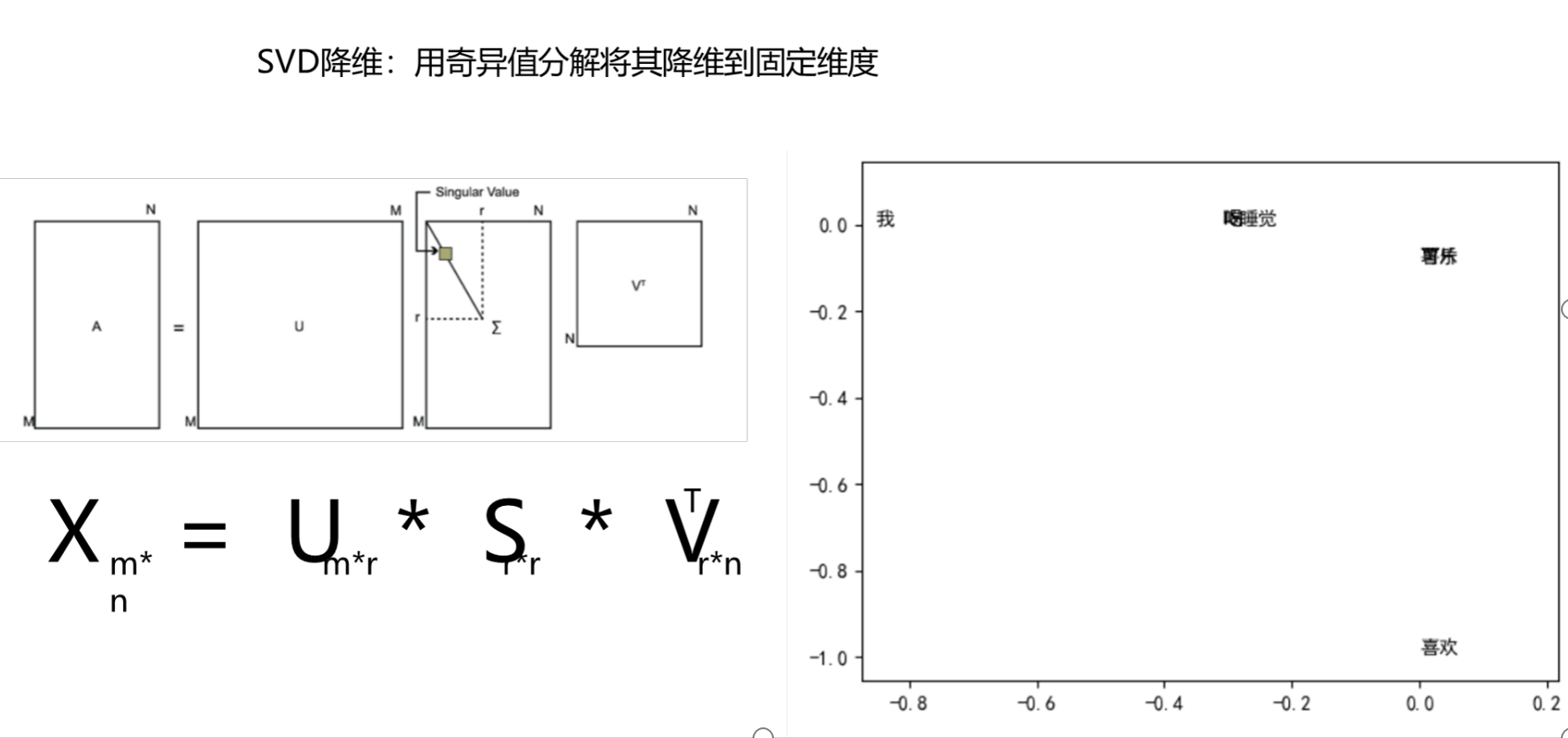
實現代碼?
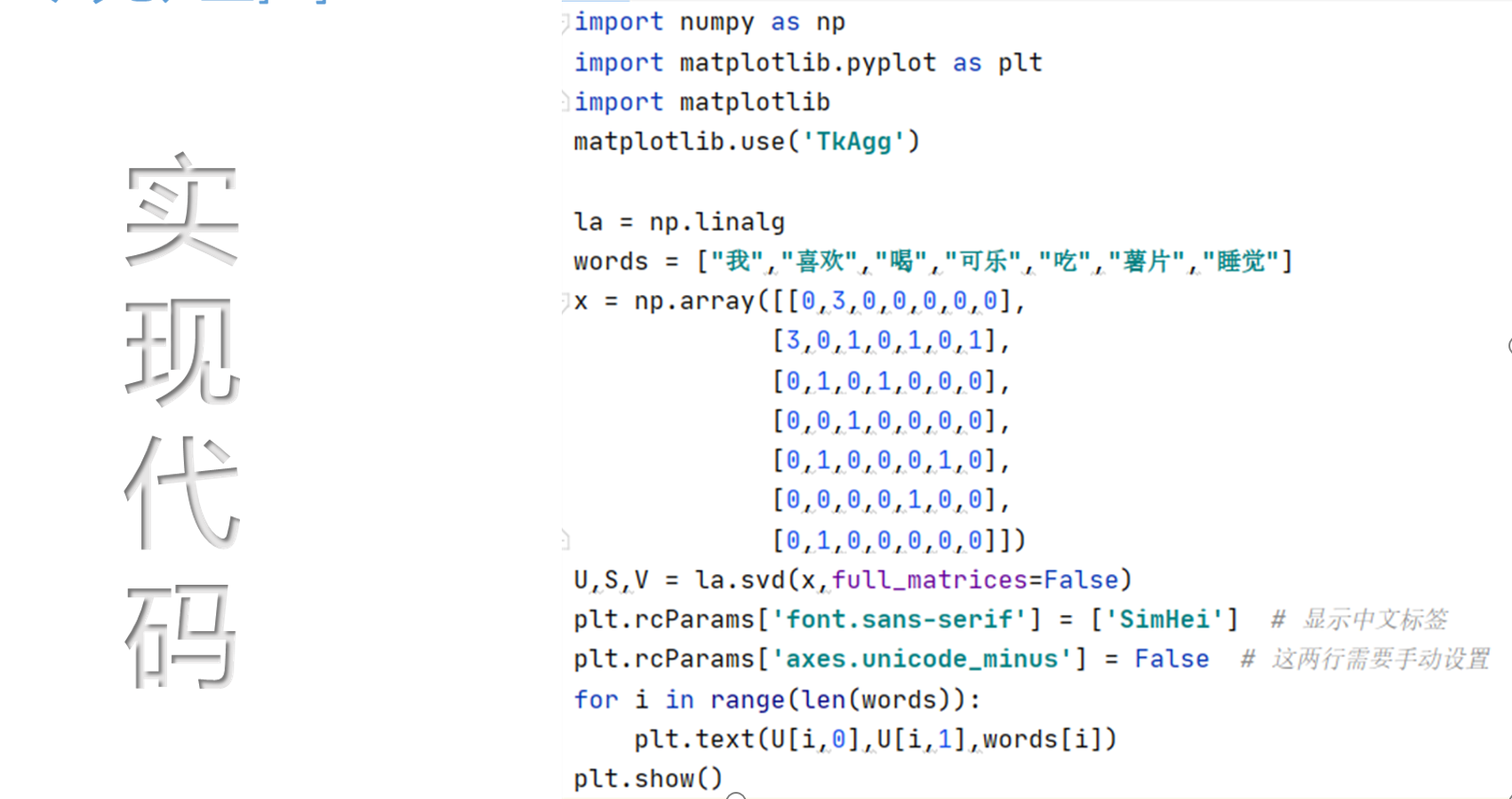
技術實現優缺點:?

五、NNLAM
樣本案例:

公式:?
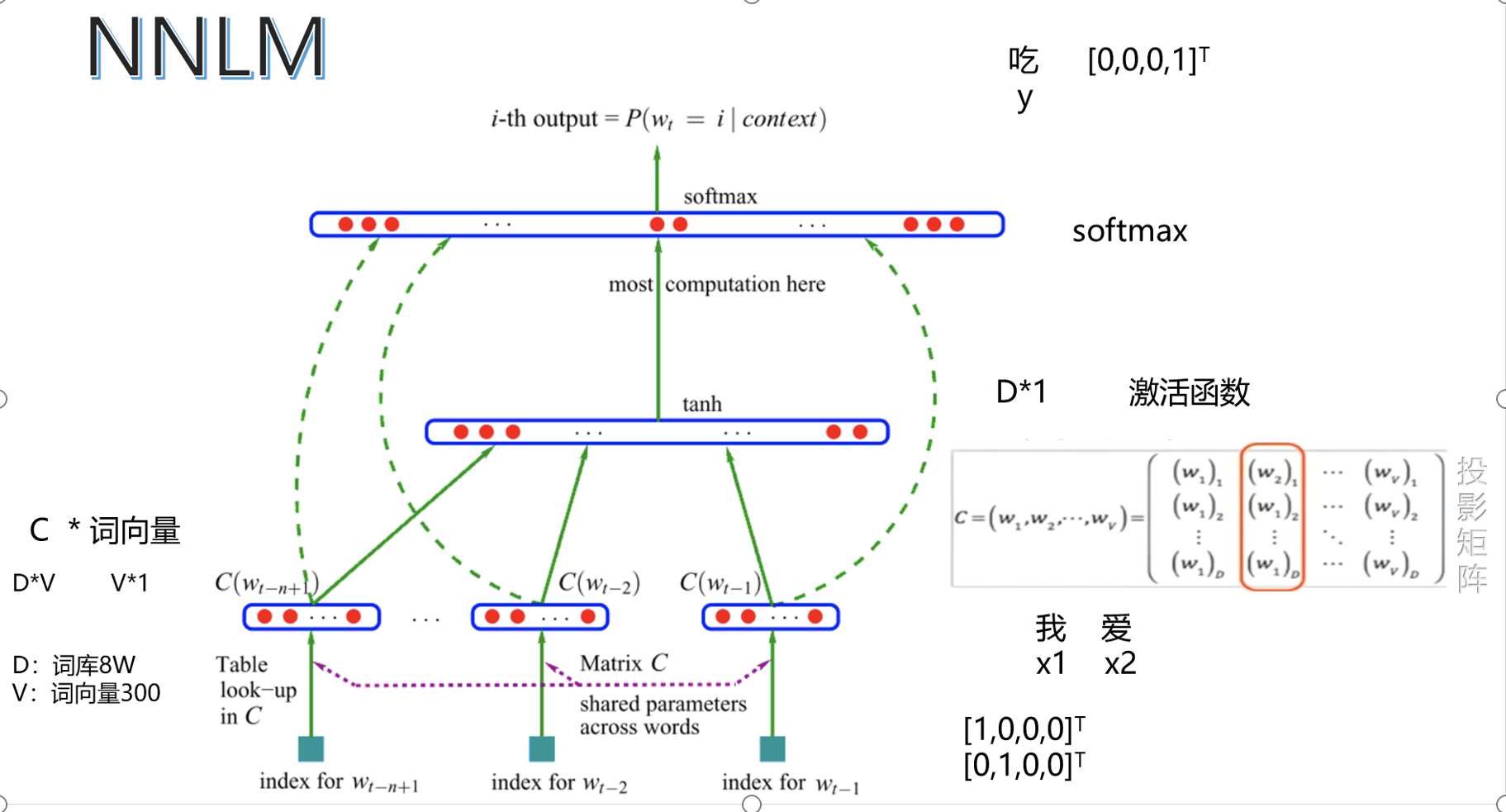
優缺點:?

六、word2vec
案例和算法圖
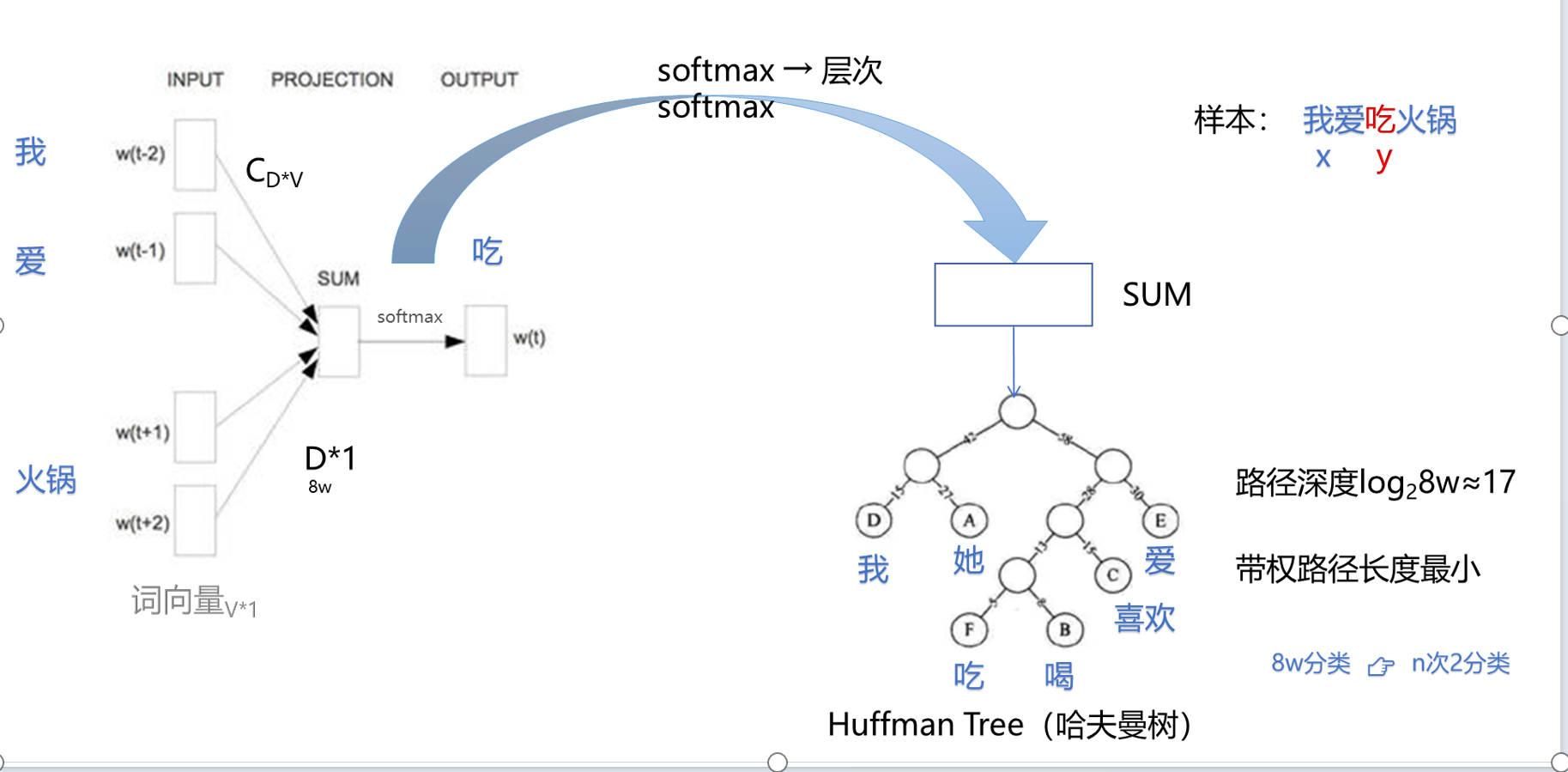
二次方的概率:?
 ?
?
PCA實現二維可視化?
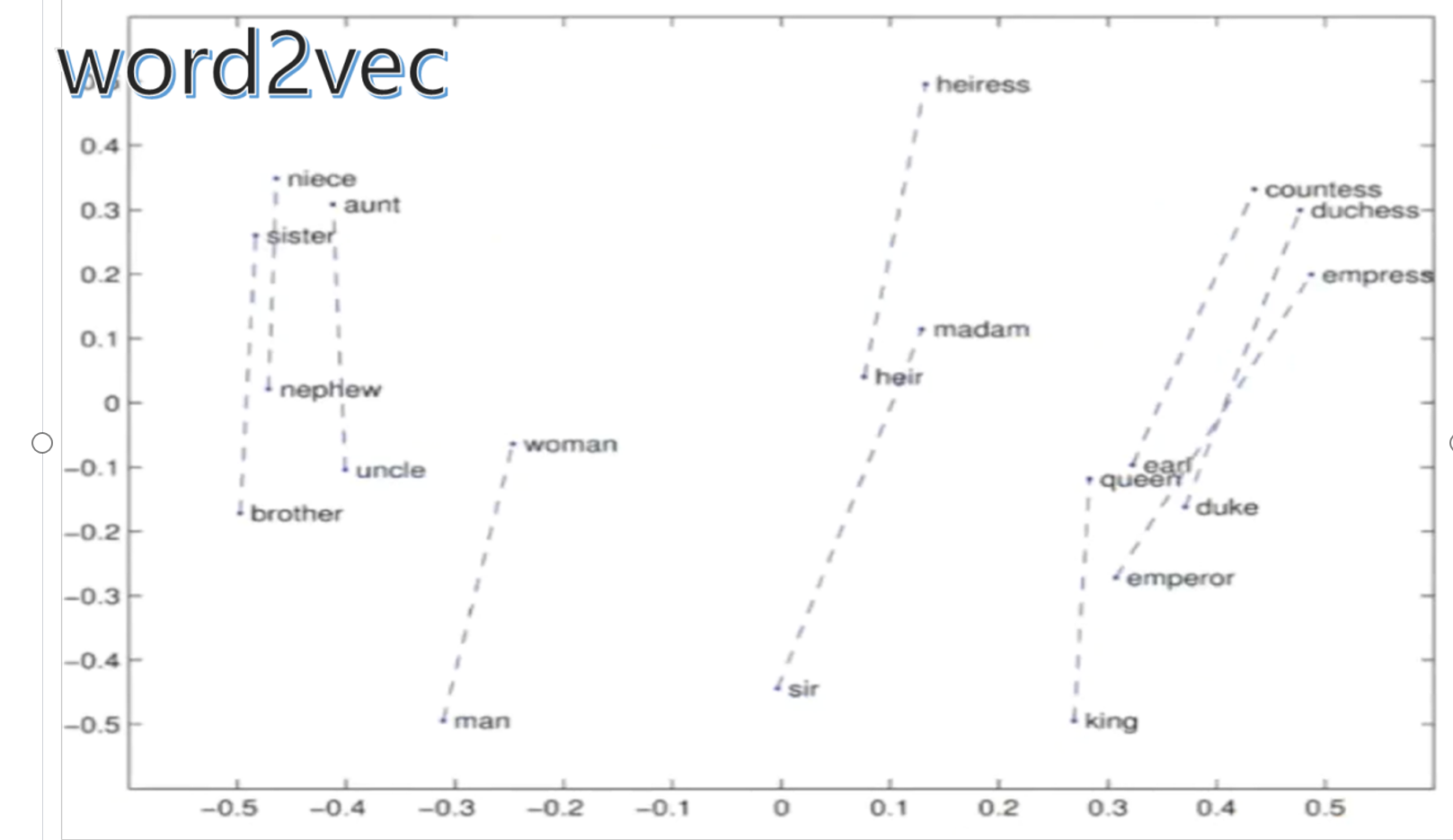
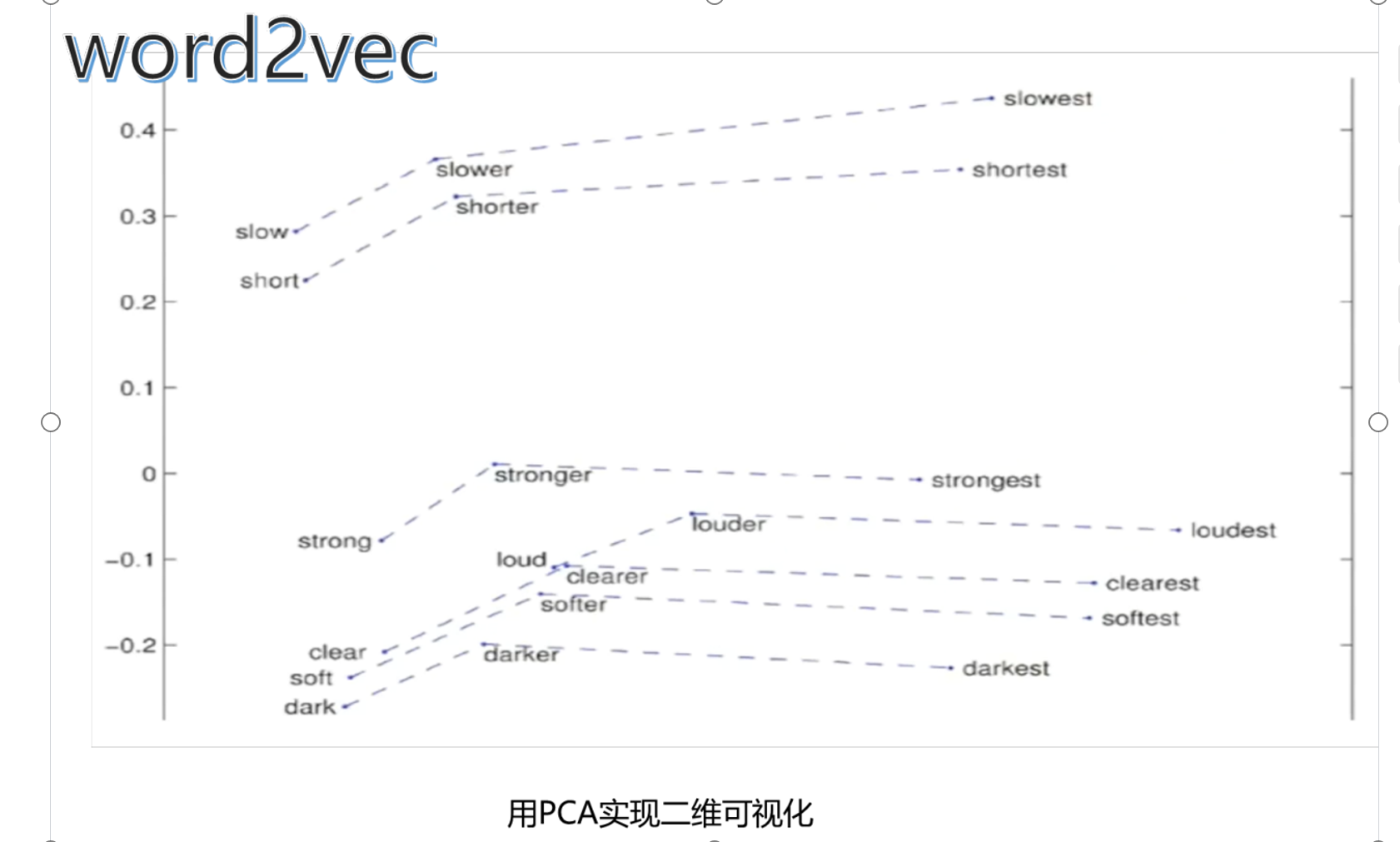 ?
?
優缺點?



)
)






)








