摘要
本文提出了一個名為 Unified Language-driven Zero-shot Domain Adaptation(ULDA)的新任務設置,旨在使單一模型能夠適應多種目標領域,而無需明確的領域標識(domain-ID)知識。現有語言驅動的零樣本領域適應任務存在限制,例如需要領域ID和領域特定模型,這限制了模型的靈活性和可擴展性。為了解決這些問題,作者提出了一個包含三個組件的新框架:層次上下文對齊(Hierarchical Context Alignment, HCA)、領域一致表示學習(Domain Consistent Representation Learning, DCRL)和文本驅動校正器(Text-Driven Rectifier, TDR)。這些組件協同工作,分別在多個視覺層面上對齊模擬特征與目標文本、保留不同區域表示之間的語義相關性以及校正模擬特征與真實目標視覺特征之間的偏差。大量實證評估表明,該框架在兩種設置中均取得了具有競爭力的性能,甚至超越了需要領域ID的模型,展現了其優越性和泛化能力。該方法不僅有效,而且在推理時不會引入額外的計算成本,具有實用性和效率。
Introduction
擬解決的問題:
- 領域適應中的靈活性和可擴展性問題:現有方法需要領域ID來選擇領域特定的模型,這限制了模型在實際應用中的靈活性和可擴展性。例如,在“雨中駕駛”和“雪中駕駛”兩種任務領域中,需要分別訓練兩個獨立的模型來適應這些領域。
- 缺乏目標領域數據時的模型適應性問題:在實際應用中,由于隱私問題或數據稀缺性,可能無法直接訪問目標領域的圖像數據。因此,需要開發一種能夠在沒有目標領域圖像的情況下,僅通過文本描述來適應目標領域的模型。
如下圖所示。我們提出的統一語言驅動的領域適應(ULDA)任務側重于現實世界的實際場景。在訓練階段,ULDA不允許訪問目標域的圖像,只提供源域圖像和文本描述。在測試期間,ULDA需要一個單一的模型來適應不同的目標域,而不是像以前的方法那樣使用特定于域的頭。
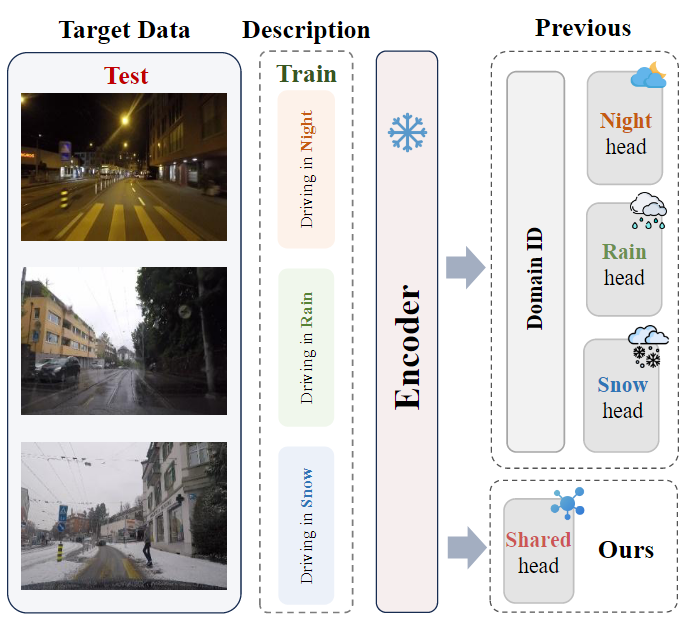
創新之處:
提出了一種新的任務設置ULDA:與現有方法不同,ULDA要求單個模型能夠適應多種目標領域,而無需在測試時提供領域ID,這更符合實際應用場景。
設計了一個包含三個關鍵組件的新框架:
- 層次上下文對齊(HCA):通過在場景級別、區域級別和像素級別對齊特征與文本嵌入,解決了全局對齊可能導致的語義損失問題。
- 領域一致表示學習(DCRL):通過保留不同類別在不同領域中的語義相關性,確保了模型在不同領域之間的結構一致性。
- 文本驅動校正器(TDR):通過利用文本嵌入來校正模擬特征,減少了模擬特征與真實目標特征之間的偏差,提高了模型的泛化能力。
在推理階段不引入額外計算成本:該方法在保持有效性的同時,確保了模型在實際應用中的實用性和效率。
Preliminary
P?DA 是一種用于計算機視覺中零樣本領域適應(Zero-shot Domain Adaptation, ZSDA)的范式。它通過僅利用目標領域的自然語言描述,而無需目標領域的圖像數據來訓練模型,從而實現從源領域到目標領域的適應。P?DA 的核心思想是利用預訓練的 CLIP 編碼器來優化源特征的轉換,并將其與目標領域的文本嵌入對齊。
P?DA 的訓練過程分為兩個階段:
第一階段:模擬目標特征(Simulating Target Features)
-
Prompt-driven Instance Normalization (PIN):P?DA 引入了 PIN 操作,通過可學習的變量 μ 和 σ,這些變量由目標領域的文本提示引導,來模擬目標領域的知識。具體公式如下:
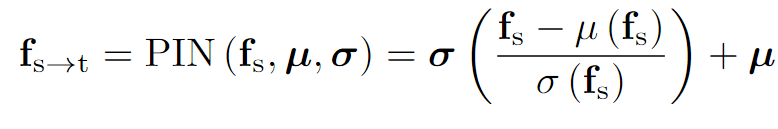
其中,fs? 是源域特征,μ(fs?) 和 σ(fs?) 分別是源特征的均值和標準差。
對齊目標文本嵌入:為了確保從源域到目標域的適當轉換,需要通過以下損失函數促進 fs→tPIN? 與 CLIP 文本嵌入 TrgEmb 之間的相似性:
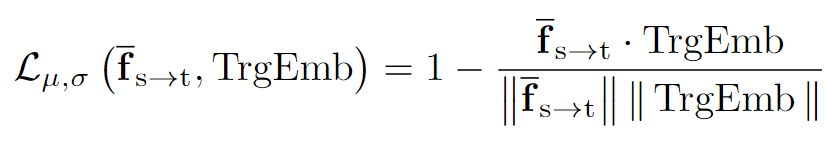
??其中,是通過 Prompt-driven Instance Normalization (PIN) 轉換后的全局特征,TrgEmb 是目標文本嵌入。
第二階段:微調分割頭(Fine-tuning the Segmentation Head)
在第一階段獲得模擬特征后,P?DA 對預訓練的分割頭進行微調,使模型能夠更好地適應目標領域的下游任務。這一階段的訓練由分割預測與真實掩碼之間的交叉熵損失監督。
方法
提出了一種名為 Unified Language-driven Zero-shot Domain Adaptation (ULDA) 的新方法,旨在使單一模型能夠適應多種目標領域,而無需明確的領域標識(domain-ID)。該方法的核心在于通過語言驅動的方式,僅利用源域數據和目標域的文本描述,來實現對目標域的有效適應。ULDA框架包含三個關鍵組件:層次上下文對齊(HCA)、領域一致表示學習(DCRL) 和 文本驅動校正器(TDR)。這些組件協同工作,分別從特征對齊、語義一致性保持和特征校正三個方面提升模型的泛化能力和適應性。
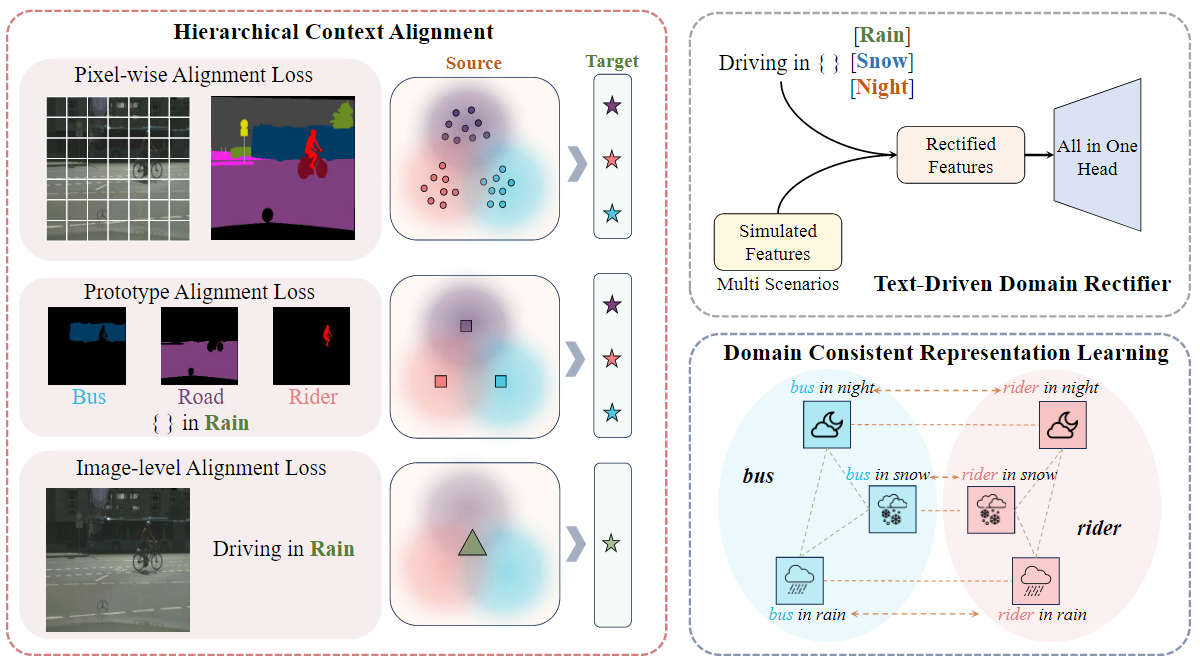
1. 層次上下文對齊(Hierarchical Context Alignment, HCA)
Vanilla scene-text 對齊會導致語義丟失。P?DA 通過等式直接將池化特征 fs→t 與文本嵌入 TrgEmb 對齊,在場景級別實現了視覺語言對齊。然而,模型僅通過調整全局上下文以適應目標域來實現與目標域的良好對齊具有挑戰性,因為在將場景中不同對象的特征對齊到單個共享目標域嵌入時這可能會導致潛在的語義損失,從而導致偏離它們各自的真實語義分布。為了緩解這個問題,我們提出了一種分層上下文對齊 (HCA) 策略,該策略可以在多個級別上對特征進行復雜的對齊,包括 1) 整個場景,2) 場景中的區域,以及 3) 場景中的像素。
1.1 場景級別對齊

HCA 的第一個層次是場景級別對齊,目標是將全局特征與目標文本嵌入對齊。具體來說,通過以下公式實現:
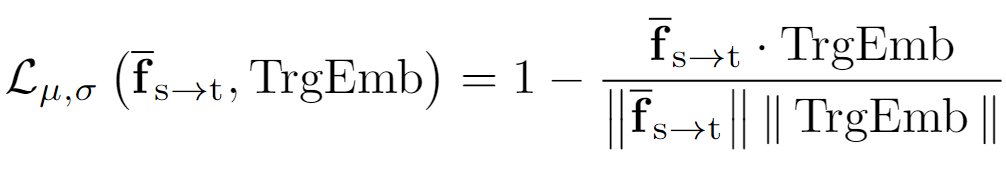
?其中,是通過 Prompt-driven Instance Normalization (PIN) 轉換后的全局特征,TrgEmb 是目標文本嵌入。該損失函數通過最大化全局特征與文本嵌入的相似性,使模型能夠適應目標域的整體語義。
1.2 區域級別對齊

區域級別對齊的目標是保留不同類別在場景中的獨特語義特征。具體步驟如下:
1.利用類別名稱和目標域描述生成細粒度的文本嵌入,其中 n 是類別數量,d 是嵌入維度。
2.將圖像特征圖與類別標簽
轉換為二值掩碼
。
3.通過掩碼平均池化(Masked Average Pooling, MAP)計算每個類別的區域原型:
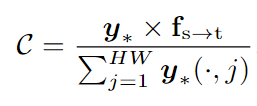
4.計算區域原型 C 與文本嵌入 T 之間的相似性矩陣:
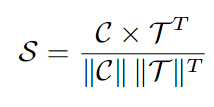
5.通過以下公式優化區域對齊損失:
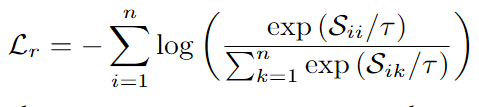
?1.3 像素級別對齊
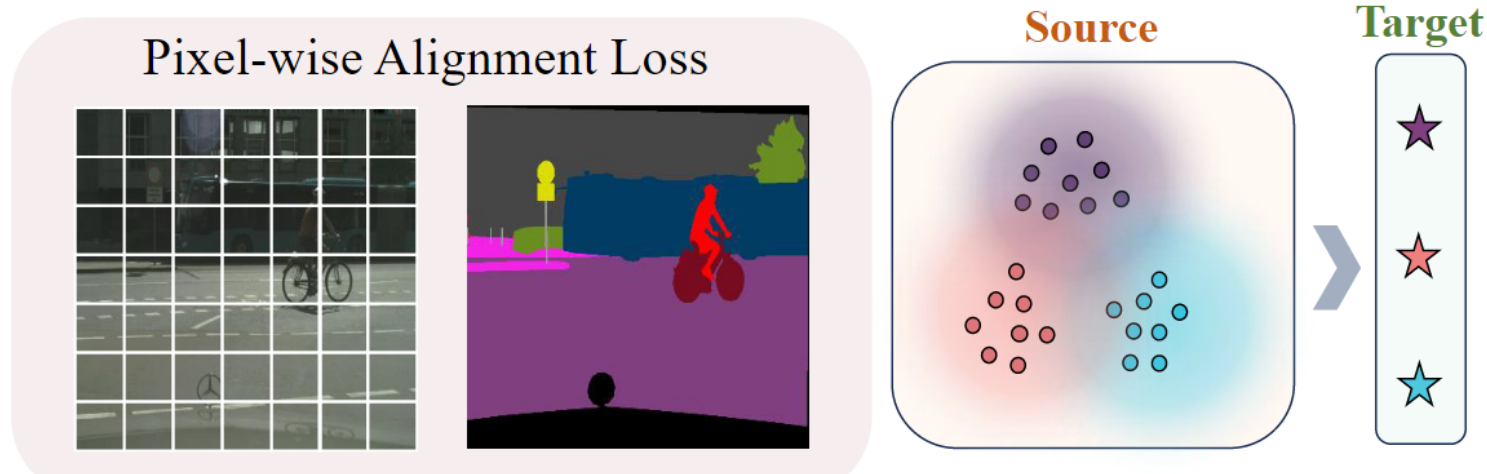
像素級別對齊進一步細化特征與文本嵌入之間的對齊,目標是使每個像素的特征更接近目標域的語義。具體步驟如下:
1.計算每個像素的類別概率:
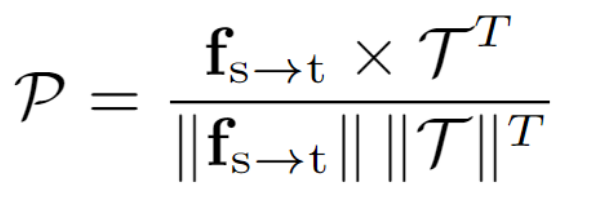
2.使用像素級標簽計算交叉熵損失:
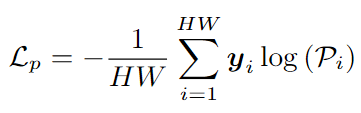
1.4 總體損失
HCA 的總體損失函數為:
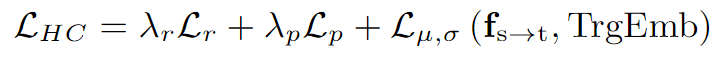
?2. 領域一致表示學習(Domain Consistent Representation Learning, DCRL)
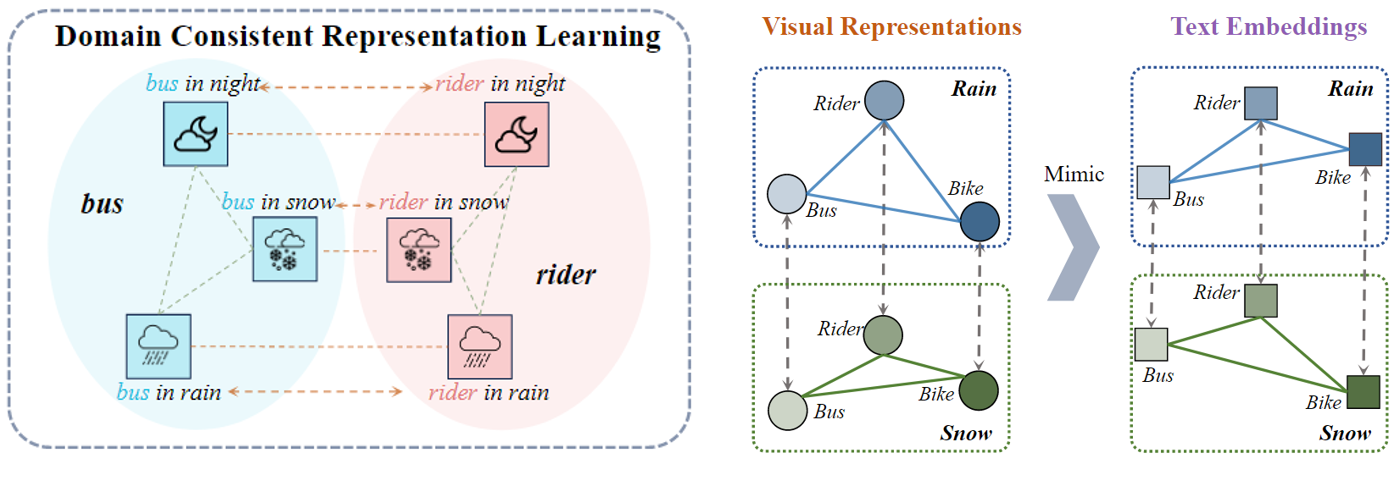
DCRL 的目標是確保不同領域之間的語義相關性保持一致。例如,“雪中的公共汽車”、“雨中的公共汽車”和“夜間的公共汽車”的文本嵌入可能與“雪”、“雨”和“夜”背景下的視覺對應物相比可能具有不同的相關性。具體來說,對于 m 個目標領域中的 n 個類別,分別計算每個領域的類別原型和文本嵌入
,并將它們組合成擴展的原型矩陣
和
。然后,通過以下公式優化領域一致性損失:
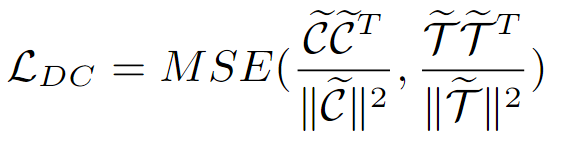
?該損失函數通過最小化不同領域中類別原型與文本嵌入之間的相關性差異,確保模型在不同領域之間保持一致的語義表示。
3. 文本驅動校正器(Text-Driven Rectifier, TDR)
在第二階段微調時,模型利用模擬的目標域特征來微調分割頭,使模型能夠有效地適應目標域。然而,模擬特征與實際目標域特征之間可能存在差異。考慮這些差異至關重要,因為直接使用模擬特征可能會導致分割頭與真實目標分布的偏差,從而在調整后產生更差的分割性能。
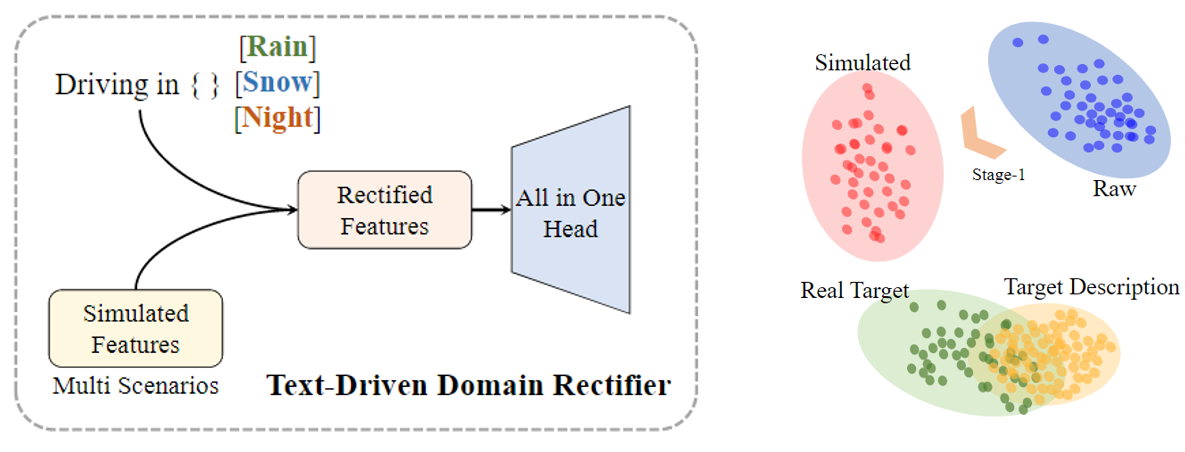
因此,我們建議通過利用 CLIP 獲得的文本嵌入來解決這個問題,這些嵌入實際上類似于真實目標域中的分布。通過采用這些文本嵌入作為先驗,我們可以糾正模擬過程,從而鼓勵模擬特征與目標特征更緊密地對齊。糾正有利于適應。具體來說,TDR 的目標是校正模擬特征與真實目標特征之間的偏差。具體來說,在模型的第二階段(微調階段),通過以下公式對模擬特征進行校正:
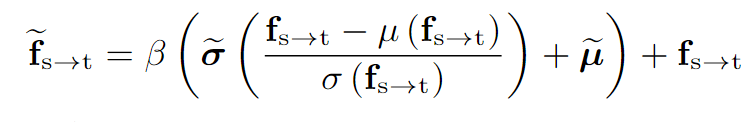
其中, 和
是通過文本嵌入經過線性層得到的目標特征的均值和標準差,β 是一個可學習的校正因子,用于控制校正的程度。通過這種方式,TDR 使模擬特征更接近真實目標特征,從而提高模型的泛化能力。?
4.總結
訓練過程:
- Stage-1:通過 PIN 生成模擬特征,并使用 HCA 和 DCRL 進行對齊。
- Stage-2:通過 TDR 校正模擬特征,并微調分割頭以優化分割任務的性能。
推理過程: 對目標域圖像進行特征提取、模擬特征生成、文本驅動校正和分割預測。
結論
-
ULDA框架的有效性:通過在多種目標領域上的實驗驗證,ULDA框架在零樣本領域適應任務中取得了具有競爭力的性能,甚至在某些情況下超越了需要領域ID的方法,證明了其在實際應用中的可行性和優越性。
-
方法的實用性:ULDA方法在推理階段不引入額外的計算成本,保持了模型的實用性和效率,使其更適合于實際的領域適應任務。
-
對領域適應任務的推動:ULDA的提出為領域適應任務提供了一種新的思路,即通過文本描述來適應目標領域,而無需直接訪問目標領域的圖像數據,這為解決實際應用中的數據稀缺問題提供了一種有效的解決方案。


的代碼與演示)
















