一、企業災備體系
1.1 災備體系
災備切換的困境:

容災領域的標準化方法和流程、算法體系是確保業務連續性和數據可靠性的核心,以下從標準框架、流程規范、算法體系三個維度進行系統分析:
1.1.1、標準化方法體系?
?1. 容災等級標準?
- ?國際標準SHARE78?:
將容災能力劃分為7級(Tier 0~6),核心指標包括RTO(恢復時間目標)和RPO(恢復點目標)。- ?Tier 0?:無異地備份(RPO≥24小時)
- ?Tier 3?:電子傳輸+定時備份(RPO≤24小時)
- ?Tier 6?:零數據丟失+自動切換(RPO=0,RTO≤2分鐘)
- ?中國金融行業標準?:
采用6級分類(1級最高),例如:- ?1級?:RTO≤2小時,RPO≤15分鐘(銀行核心系統)
- ?4級?:RTO≤12小時,RPO≤4小時(支付機構)
?2. 技術架構標準?
- ?容災架構類型?:
?架構? ?適用場景? ?技術要點? 同城容災 低延遲強一致性 同步復制(如EMC VPLEX)、RDMA網絡 異地容災 成本敏感型業務 異步復制(如Canal/Otter)+增量壓縮 兩地三中心 金融/政府高可用 同城雙活+異地異步(如TiDB DR Auto-Sync) 異地多活 互聯網高并發業務 分片同步+一致性哈希(如Redis Cluster) - ?合規框架?:
- ?ISO 22301?:業務連續性管理體系,覆蓋容災規劃全流程
- ?NIST SP 800-34?:美國聯邦容災指南,強調風險評估與恢復策略
?3. 行業專用標準?
- ?金融行業?:遵循《JR/T 0168-2020》,要求容災中心獨立部署、定期演練
- ?云計算?:CSA STAR認證,評估云服務商容災能力(如阿里云多AZ架構)
1.1.2、標準化流程體系?
?1. 全生命周期管理流程?
graph LR
A[風險評估] --> B[業務影響分析] --> C[容災策略制定] --> D[方案設計與部署] --> E[預案文檔化] --> F[演練與迭代]- ?風險評估?:識別單點故障(如網絡分區、存儲損壞),量化潛在損失
- ?業務影響分析?:確定關鍵業務優先級(如支付系統RTO需≤30分鐘)
?2. 容災預案制定與演練流程?
- ?預案核心要素?:
- 數據備份策略(增量/全量)
- 切換觸發條件(如心跳檢測超時)
- 人員職責分工(應急指揮組、技術恢復組)
- ?演練標準化流程?:
- ?計劃制定?:模擬災難場景(如機房斷電、網絡攻擊)
- ?技術準備?:搭建沙箱環境,注入故障(ChaosMesh)
- ?實施與評估?:記錄切換時間、數據一致性偏差
- ?復盤優化?:更新預案文檔,調整資源分配
?3. 資源分配流程?
- ?靜態分配?:預先預留資源(如冷備服務器),成本高但切換快
- ?動態分配?:
- ?虛擬機熱遷移?:vMotion實時遷移(RTO秒級)
- ?容器化彈性調度?:K8s聯邦集群跨云調度Pod
1.1.3、算法體系?
?1. 數據同步算法?
- ?同步復制?:基于Paxos/Raft共識算法,確保強一致性(金融交易系統)
- ?異步復制?:
- ?增量日志追補?:數據庫Redo Log解析(如MySQL GTID)
- ?向量時鐘(Vector Clock)??:解決分布式寫入沖突(Cassandra)
- ?壓縮優化?:LZ4算法壓縮增量數據(帶寬節省≥50%)
?2. 故障檢測與切換算法?
- ?BFD(雙向轉發檢測)??:毫秒級鏈路探測(間隔≤50ms)
- ?智能仲裁?:
- ZooKeeper ZAB協議防腦裂
- 基于PSO(粒子群優化)動態選擇最優路徑
?3. 資源調度算法?
| ?算法? | ?原理? | ?應用場景? |
|---|---|---|
| 一致性哈希 | 動態增刪節點僅遷移1/N數據 | 分布式緩存(Redis) |
| 加權ECMP | 按鏈路負載動態分配流量 | SDN網絡容災 |
| 動態優先級調度 | 關鍵業務優先搶占資源 | 虛擬機高可用集群 |
?4. 數據一致性算法?
- ?分布式事務?:
- ?二階段提交(2PC)??:數據庫跨中心事務(如Oracle DataGuard)
- ?Quorum機制?:讀寫多數節點確認(如Cassandra LOCAL_QUORUM)
- ?時鐘同步?:PTP協議(IEEE 1588)實現微秒級對齊(證券交易系統)
1.1.4總結與趨勢?
- ?標準融合?:國際標準(ISO 22301)與行業標準(如金融JR/T 0168)逐步整合,推動跨行業兼容
- ?算法智能化?:
- AI預測故障:LSTM模型分析硬件故障率(準確率≥95%)
- 強化學習動態調優:根據網絡狀態自適應調整復制策略
- ?云原生重構?:
- 容器化+Serverless實現分鐘級容災成本降60%
- 跨云多活架構(如AWS Global Accelerator)成新趨勢
?實施建議?:
- ?強一致性場景?:采用Tier 6架構(同步復制+Paxos算法)
- ?成本敏感場景?:選擇異步復制+增量壓縮(LZ4),帶寬占用降50%
- ?合規要求?:金融系統需滿足年演練≥1次,并提交審計報告
通過標準化方法約束風險邊界、流程保障落地可行性、算法優化性能瓶頸,三者協同構建高可用容災體系。
專業名詞解釋
| 名稱 | 說明 |
|---|---|
| 機房類型 | 機房類型分為中心機房和容災機房。機房類型僅用于標識區別兩個機房,且不隨機房服務狀態改變而改變。在HotDB Server產品使用過程中,以添加計算節點集群組管理為入口可以區分中心機房和容災機房。 |
| 機房狀態 | 機房狀態分為當前主機房和當前備機房,根據機房內的主計算節點是否提供服務(默認3323服務端口)判斷機房類型。當前主計算節點提供服務的機房即為當前主機房;與當前主機房配套提供機房級別高可用服務切換的備用機房為當前備機房。 |
| - | - |
| 容災模式 | 在兩個機房內協調部署了具有容災關系的完整計算節點集群運行所需組件,稱這個集群為開啟容災模式的集群。 |
| 單機房模式 | 未開啟容災模式的計算節點集群即為單機房模式的集群。 |
| 容災數據復制關系 | 中心機房主存儲節點、配置庫與容災機房主存儲節點、配置庫之間的復制關系,簡稱:容災關系。 |
| 容災數據復制狀態 | 中心機房主存儲節點、配置庫與容災機房主存儲節點、配置庫之間的復制狀態,簡稱:容災狀態。 |
| - | - |
| 容災數據復制時延 | 中心機房主存儲節點、配置庫與容災機房主存儲節點、配置庫之間的復制的延時情況,簡稱:容災時延。 |
| 計算節點 | 即分布式事務數據庫服務HotDB Server |
| - | - |
| 存儲節點 | 即存儲數據的MySQL數據庫服務,一個MySQL物理庫可作為一個存儲節點;一個或多個有MySQL復制關系的存儲節點組成數據節點。 |
| 配置庫 | 存放計算節點配置數據的MySQL數據庫。 |
| - | - |
| RPO | Recovery Point Objectives,故障恢復點目標。 |
| RTO | Recovery Time Objectives,故障恢復時間目標。 |
| - | - |
1.2 規劃企業安全保障體系考慮的因素
(1)需要防范的災難類型:
企業信息系統可能遇到的災難類型及其發生的比例如下:
對于“人為錯誤”、“軟件損壞和程序錯誤”加上“病毒”等這些都稱為邏輯錯誤,占總故障的 56%,這些錯誤只能通過備份系統才能防范;
對于“硬件和系統故障”以及“自然災難”等故障可以通過在容災系統(或者異地備份)來防范,占總故障率的44%。
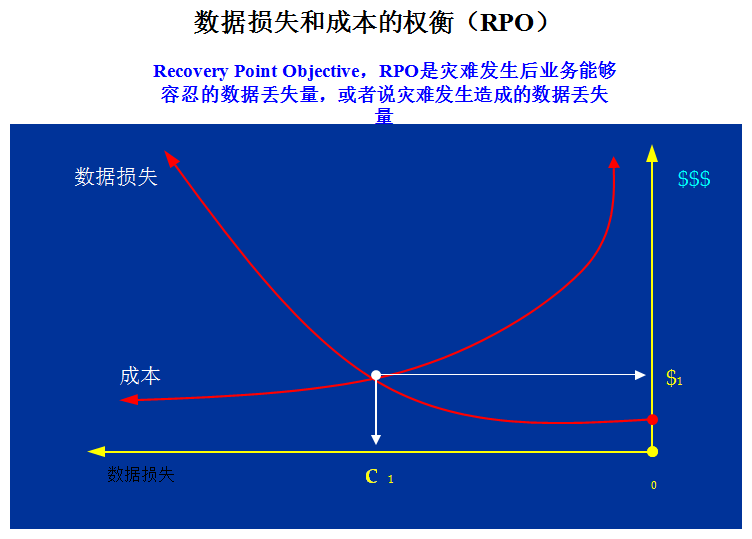
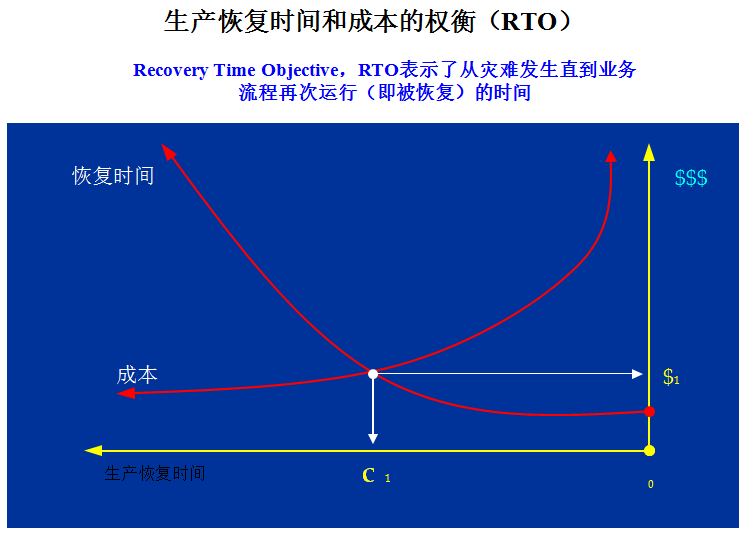
(2)允許的RTO和RPO指標
從技術上看,衡量容災系統有兩個主要指標:RPO(Recovery Point Object)和RTO(Recovery Time Object),其中RPO代表了當災難發生時允許丟失的數據量;而RTO則代表了系統恢復的時間。
(3)系統投資
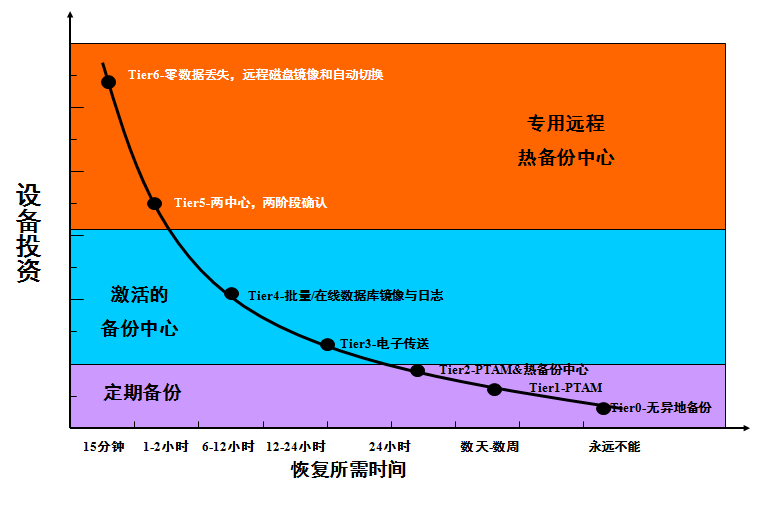
總的說來,建設備份系統的投資遠比建設標準意義的容災系統的投資小得多:
備份系統的投資規模一般在幾百萬;
而最節省的一套容災系統投資都將上千萬;
災難恢復與投資關系:
1.3 信息安全容災標準
信息系統容災恢復規范是保障業務連續性和數據安全的核心框架,主要依據國家標準《GB/T 20988-2007 信息系統災恢復規范》。
1.3.1 、核心規范框架與指標?
?1. 關鍵術語定義?
- ?災難?:導致信息系統癱瘓的突發性事件(如自然災害、人為事故)。
- ?災難恢復?:將系統從災難狀態恢復到正常運行的活動流程。
- ?RTO(恢復時間目標)??:業務中斷到恢復的最長時間(如金融系統通常要求≤30秒)。
- ?RPO(恢復點目標)??:災難發生時允許丟失的數據量(如實時交易系統要求RPO=0)。
?2. 災難恢復能力等級劃分?
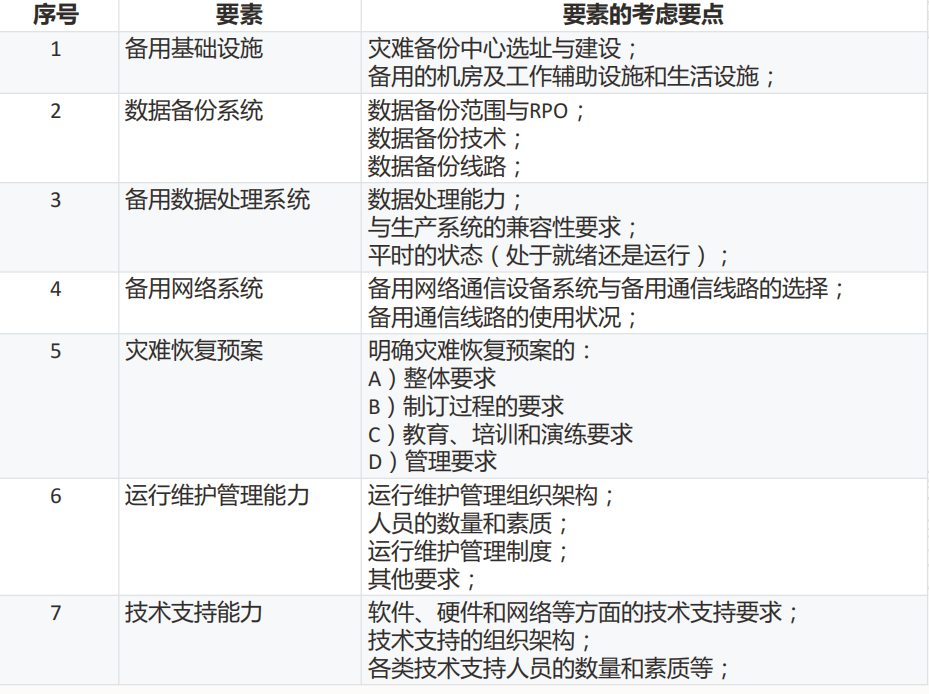
國家標準將災難恢復能力分為6個等級,每個等級需滿足7項要素要求:
| ?等級? | ?名稱? | ?核心要求? | ?典型RTO/RPO? |
|---|---|---|---|
| 第1級 | 基本支持 | 每周完全備份+介質異地存放,年演練1次 | RTO=天級,RPO≥24小時 |
| 第2級 | 備用場地支持 | 增加備份網絡和備用基礎設施(如電力、空調) | RTO≤24小時 |
| 第3級 | 電子傳輸部分設備支持 | 實時數據備份+備用主機就緒,支持部分業務切換 | RTO≤12小時 |
| ?第4級? | 電子傳輸完整設備支持 | ?同城雙活架構,數據實時同步,業務恢復自動化 | RTO≤4小時,RPO≈0 |
| ?第5級? | 實時數據傳輸完整支持 | ?異地雙活,零數據丟失(如兩階段提交事務) | RTO≤30分鐘,RPO=0 |
| 第6級 | 遠程集群支持 | 多中心并行負載均衡,自動故障切換(如分布式數據庫Paxos協議) | RTO≤秒級,RPO=0 |
?注?:第4~6級需滿足數據備份、備用處理系統、網絡、基礎設施、技術支援、運維管理、預案7要素全部要求。
1.3.2、災備技術方案關鍵點?
?1.3.2.1 數據同步技術?
容災系統中的數據同步技術是保障數據一致性、業務連續性的核心,其底層依賴復雜的算法體系及數學物理原理。
數據同步技術分類及實現?
?1. 基于存儲復制的同步?
-
?原理?:由存儲硬件(如SAN)實現數據塊級復制,通過鏡像技術保持主備數據一致。
-
?同步模式?:
-
?同步復制?:每個I/O操作需等待災備端確認(RPO=0),但延遲 敏感(同城RTT<2ms)。同城場景(距離≤100km),RPO=0,延遲敏感(如華為HyperMetro)。
-
?異步復制?:I/O操作本地確認后異步復制到遠端(RPO>0),帶寬要求低,容忍網絡延遲。
-
?半同步復制?:折中方案,多數節點確認即返回(MySQL Group Replication)。
-
-
?代表技術?:
EMC SRDF(同步)、IBM PPRC(異步)、HDS TrueCopy。
?2. 基于邏輯卷管理的同步?
-
?原理?:卷管理軟件(如Veritas VVR)截獲文件系統I/O,實時復制到災備卷。
-
?優勢?:
與存儲硬件解耦,支持異構存儲;可配置一對多、多對一復制。 -
?數據流?:
生產卷 → 日志記錄 → 網絡傳輸 → 災備卷重放。
?3. 基于數據庫日志的同步?
-
?原理?:捕獲數據庫事務日志(如Redo Log),傳輸到災備端按順序重放,實現事務級一致性。
-
?關鍵技術?:
-
?日志解析?:實時解析事務操作(增刪改);
-
?沖突解決?:時間戳或版本號排序(如MVCC)。
-
-
?代表技術?:
Oracle DataGuard(物理級)、MySQL主從復制(邏輯級)。
?4. 基于應用的增量同步?
-
?原理?:應用層捕獲數據變更(如消息隊列),通過發布-訂閱模型異步分發。
-
?場景?:
微服務架構下,Kafka/Pulsar傳輸變更事件,災備端消費并更新緩存/數據庫。 -
?一致性保障?:
最終一致性(Eventual Consistency)。
核心算法體系?
?1. 分布式一致性算法?
| ?算法? | ?原理? | ?應用場景? |
|---|---|---|
| ?Paxos? | 多數派投票達成共識,容忍節點故障(如網絡分區) | 金融核心系統強一致性 |
| ?Raft? | 選舉Leader管理日志復制,簡化Paxos流程 | etcd、Consul等分布式存儲 |
| ?Quorum? | 讀寫操作需超過半節點確認(NWR模型) | 分布式數據庫(Cassandra) |
?2. 數據沖突解決算法?
-
?向量時鐘(Vector Clock)??:
記錄事件因果順序(例:[A:2, B:1]>[A:1, B:1]),解決分布式系統并發寫沖突。 -
?操作轉換(OT)??:
實時協同編輯場景,合并并發操作(如Google Docs)。
?3. 高效同步優化算法?
-
?一致性哈希(Consistent Hashing)??:
動態增減節點時僅遷移少量數據(如Redis Cluster)。 -
?數據分片(Sharding)??:
按Key范圍(Range)或哈希值(Hash)分割數據,并行同步提升效率。
數學與物理原理?
?1. 數學原理?
-
?信息論(熵編碼)??:
數據壓縮(LZ77、Huffman編碼)減少傳輸量,節省帶寬。 -
?排隊論?:
優化I/O隊列調度(如FIFO、優先級隊列),降低同步延遲。 -
?概率模型?:
-
預測網絡丟包率,動態調整TCP窗口(AIMD算法);
-
LSTM預測同步延遲,提前調度資源。
-
?2. 物理原理?
-
?光傳輸時延約束?:
同步復制要求同城距離≤100km(光速30萬km/s,RTT≤1ms)。 -
?時鐘同步機制?:
-
?鎖相環(PLL)??:調整本地時鐘相位匹配參考時鐘(光纖通信);
-
?NTP/PTP協議?:NTP精度毫秒級,PTP(IEEE 1588)精度微秒級(金融交易)。
-
-
?量子隧穿效應?:
高密度存儲芯片(如3D NAND)依賴量子隧穿寫入數據,需精準電壓控制保障一致性。
技術對比與選型?
| ?技術類型? | RPO | 適用場景 | 算法依賴 |
|---|---|---|---|
| 存儲同步復制 | 0秒 | 同城雙活 | 無(硬件實現) |
| 數據庫日志復制 | 秒級 | 跨城容災 | MVCC、WAL |
| 應用層消息隊列 | 分鐘級 | 微服務架構 | 最終一致性、向量時鐘 |
| 邏輯卷管理 | 秒~分鐘級 | 異構存儲整合 | 環形緩沖區、QoS |
應用趨勢?
- ?云原生融合?:
Kubernetes CSI插件實現存儲卷跨云同步(如Velero)。 - ?智能優化?:
- 強化學習動態調整同步策略(如帶寬分配);
- 區塊鏈存證保障同步過程不可篡改(金融合規)。
- ?存算一體?:
iRAID技術實現硬盤KB級分塊恢復,TB級數據重構<15分鐘(比傳統RAID快40倍)。
?選型建議?:
- ?強一致性場景?:存儲同步復制+Paxos算法(同城RPO=0);
- ?跨域容災?:數據庫日志復制+Quorum仲裁(容忍網絡分區);
- ?成本敏感場景?:應用層異步隊列+最終一致性(帶寬節省>40%)。
容災同步本質是數學(一致性模型)、物理(傳輸時延)與工程(分布式算法)的深度結合,需根據業務需求在RPO/RTO、成本之間權衡。
1.3.2.2. 網絡與高可用架構?
- ?全局負載均衡(GSLB)??:基于地理位置分流流量(DNS+Anycast)。
- ?單元化部署?:按用戶/地域拆分業務單元,避免跨單元依賴(阿里UID分片)。
- ?分布式事務?:金融場景采用TCC模式(Seata框架)保障跨機房原子性。
1.3.3、實施路徑與流程?
?1. 災備規劃四階段?
- ?需求分析?
- 業務影響分析(BIA):識別關鍵業務功能(如支付交易)及容忍中斷時間。
- 風險評估:分析自然災害、網絡攻擊等潛在威脅。
- ?策略制定?
- 按業務等級選擇容災方案(如核心系統用5級,日志系統用2級)。
- ?系統建設?
- 數據備份:混合使用完全備份(每日)+增量備份(每小時)。
- 基礎設施:同城雙活中心(專線保障RTT<2ms)+異地災備中心。
- ?預案管理?
- 文檔化操作流程,明確故障切換、數據恢復、人員職責。
?2. 資源與成本優化?
- ?虛擬化+云服務?:減少物理設備投入(如Kubernetes聯邦集群跨機房調度)。
- ?分層存儲?:熱數據SSD存儲,冷數據轉對象存儲(成本降50%)。
1.3.4、行業實踐與合規要求?
?1. 金融行業?
- ?要求?:同城RTO≤30秒+異地RPO<5分鐘,符合《JR/T 0044-2008》。
- ?方案?:Oracle RAC同城同步復制 + GoldenGate異地異步備份,數據加密+區塊鏈存證日志。
?2. 政務與檔案系統?
- ?數據主權?:專網傳輸+數據脫敏(FPE加密),異地中心距主中心≥45公里。
- ?檔案備份?:電子目錄+數字化全文的完全備份(介質異地存放,年有效性驗證)。
?3. 云服務架構?
- ?多云容災?:AWS/AliCloud的DRaaS服務,支持按虛擬機粒度計費。
- ?可用區設計?:同城可用區(抗單機房故障) + 異地可用區(抗區域災害)。
1.3.5、容災演練與持續改進?
?1. 演練類型與周期?
| ?類型? | ?適用場景? | ?周期? |
|---|---|---|
| 桌面演練 | 預案流程驗證(無實際操作) | 每季度1次 |
| 模擬演練 | 部分系統切換測試 | 每半年1次 |
| 全面中斷測試 | 全業務切換至災備中心(真實環境) | 每年1次 |
?2. 演練關鍵步驟?
- ?目標設定?:明確測試RTO/RPO(如支付系統RTO≤1分鐘)。
- ?故障注入?:模擬機房斷電、網絡分區(ChaosMesh工具)。
- ?問題診斷?:記錄數據一致性偏差、切換延遲等缺陷。
- ?預案迭代?:修復問題并更新文檔(版本控制管理)。
?3. 演練成效評估?
- ?成功率指標?:某銀行演練達標率99.8%。
- ?成本效益?:災備投入占IT總成本≥5%,但可降低災難損失90%+。
總結:規范落地核心邏輯?
- ?分級防御?:按業務重要性匹配容災等級(如1~6級),避免過度投入。
- ?技術融合?:同步復制+單元化架構保障核心業務零感知切換;異步復制+云服務優化邊緣業務成本。
- ?合規驅動?:金融需滿足國標5級+行業審計,政務需數據主權保障。
- ?持續運維?:年演練覆蓋率100% + 預案季度迭代,形成“分析-建設-驗證”閉環。
?實施建議?:參考《GB/T 20988-2007》附錄的預案框架。
二、常用的災備組合方式
2.1 災備系統建設模式
業界在災備系統的建設上一般按照以下幾種方式:
? 建設機房內的本地備份系統
? 建設異地的備份系統
該方式可以備份系統的價格滿足備份和異地容災功能,能夠避免主生產中心由于地震、火災或其他災害造成的數據丟失。
? 備份系統+異地容災系統
這是一個較為理想化的容災系統一體化解決方案,能夠在很大程度上避免各種可能的錯誤。
2.1.1 容災恢復等級

以下是關于容災國際標準Share78的全面解析,涵蓋定義、7個等級的方法原理、底層設計思路及系統實現,結合國際標準與行業實踐:
Share78標準定義?
?Share78由國際組織SHARE于1992年制定,是全球公認的容災方案分級框架。其核心通過8個維度評估容災能力:
備份/恢復范圍
災備計劃狀態
主備中心距離
主備中心連接方式
數據傳輸機制
允許數據丟失量(RPO)
數據更新一致性保障
災備中心就緒能力
最終將容災能力劃分為 ?0~6級,從本地備份到零數據丟失的全自動災備。
7個等級詳解:方法、原理與系統實現?
?1. Tier 0:無異地備份?
-
?方法?:僅本地磁帶備份,無異地數據副本。
-
?原理?:低成本基礎備份,依賴物理介質恢復。
-
?RPO/RTO?:數據丟失量=最后一次備份至災難發生時的新數據;恢復時間數天至數周。
-
?底層設計?:
-
系統:磁帶機+備份軟件(如Veritas NetBackup)。
-
缺陷:本地災難導致數據全丟失,無業務連續性保障。
-
?2. Tier 1:異地備份(PTAM卡車運送)??
-
?方法?:備份磁帶運送至異地保存,但無備用系統。
-
?原理?:通過地理隔離降低數據全損風險,恢復需重建硬件環境。
-
?RPO/RTO?:數據丟失量=備份周期內數據(通常1-7天);RTO≥24小時。
-
?底層設計?:
-
系統:自動化磁帶庫(如IBM TS4500)+物流管理。
-
典型場景:中小企業非關鍵業務。
-
?3. Tier 2:熱備份站點?
-
?方法?:異地設熱備中心,備份數據定期恢復到備用主機。
-
?原理?:縮短硬件就緒時間,但數據仍通過運輸同步。
-
?RPO/RTO?:數據丟失量=備份周期(天/周級);RTO≥24小時。
-
?底層設計?:

:SSTable 磁盤存儲)











【題解】合集)





