文章目錄
- Redis部署架構詳解:原理、場景與最佳實踐
- 單點部署架構
- 原理
- 適用場景
- 優勢
- 劣勢
- 最佳實踐
- 主從復制架構
- 原理
- 消息同步機制
- 1. 全量同步(Full Resynchronization)
- 2. 部分重同步(Partial Resynchronization)
- 3. 心跳檢測機制
- 主從復制的工作流程
- 復制的一致性保證
- 適用場景
- 優勢
- 劣勢
- 最佳實踐
- 哨兵(Sentinel)架構
- 原理
- 哨兵的工作機制
- 1. 監控機制
- 2. 哨兵集群的選主與一致性
- 3. 自動故障轉移流程
- 4. 配置提供者功能
- 哨兵的高可用保證
- 適用場景
- 優勢
- 劣勢
- 最佳實踐
- 集群(Cluster)架構
- 原理
- 集群的工作機制
- 1. 數據分片與哈希槽
- 2. Gossip協議與集群通信
- 3. 故障檢測與自動故障轉移
- 4. 集群一致性與可用性保證
- 5.節點變更
- 添加新節點
- 減少節點(下線節點)
- 適用場景
- 優勢
- 劣勢
- 最佳實踐
- Codis 集群架構
- 原理
- 集群工作機制
- 1. 數據分片與路由機制
- 2. 中心化控制體系
- 3. 請求處理流程
- 4. 節點變更機制
- 添加新節點
- 移除節點
- 適用場景
- 優勢
- 劣勢
- 最佳實踐
- Active-Active地理分布式架構
- 原理
- 沖突解決機制
- 跨地域復制
- 適用場景
- 優勢
- 劣勢
- 最佳實踐
- Kubernetes云原生部署
- 原理
- 部署模式
- 存儲考慮
- 適用場景
- 優勢
- 劣勢
- 最佳實踐
- 架構選型指南與場景比對
- 架構選型決策樹
- 典型應用場景比對
- 性能與可用性對比
- 總結與展望
- 參考資料
Redis部署架構詳解:原理、場景與最佳實踐
Redis作為一種高性能的內存數據庫,在現代應用架構中扮演著至關重要的角色。隨著業務規模的擴大和系統復雜度的提升,選擇合適的Redis部署架構變得尤為重要。本文將詳細介紹Redis的各種部署架構模式,包括單點部署、主從復制、哨兵模式、集群模式、Active-Active地理分布式以及Kubernetes云原生部署等,深入剖析其工作原理和底層機制,并提供架構選型指南和典型應用場景比對,幫助讀者根據實際需求選擇最適合的Redis部署方案。
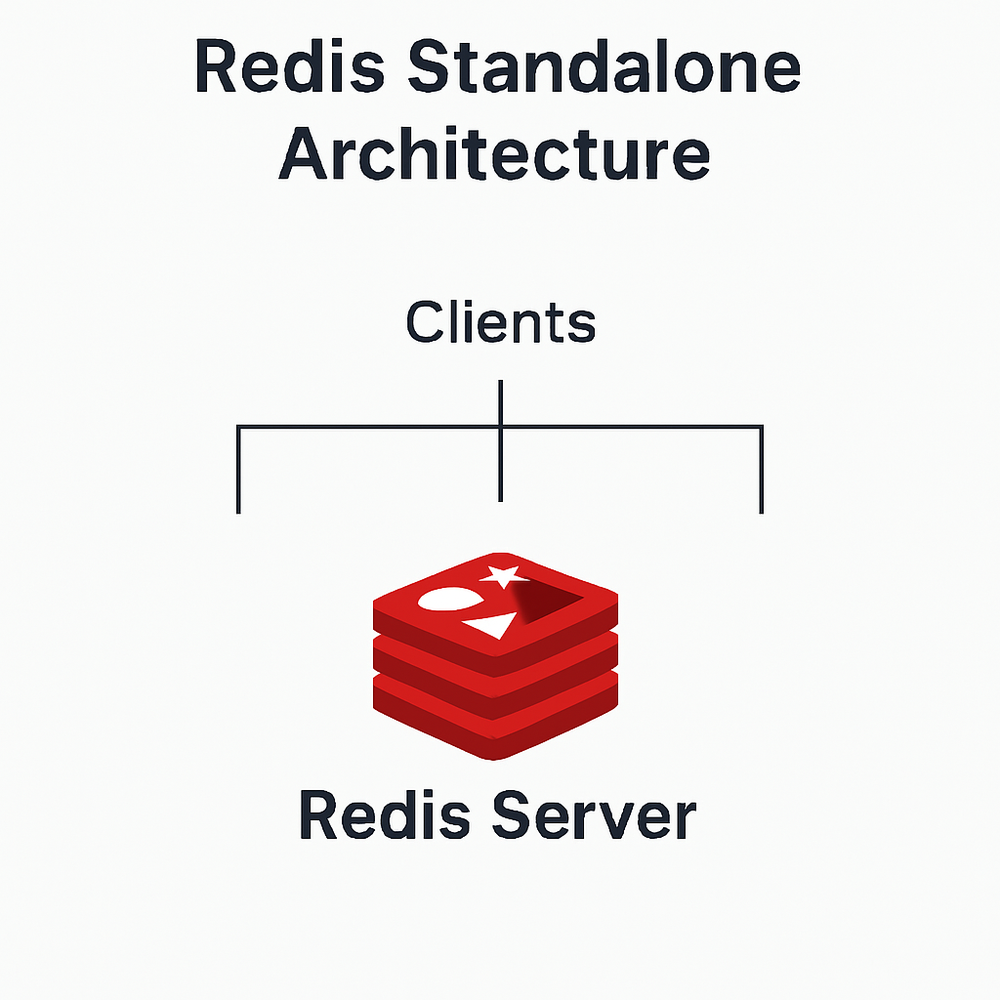
單點部署架構
原理
單點部署是最簡單的Redis架構模式,僅包含一個Redis實例,所有的讀寫操作都在這個實例上進行。
適用場景
-
開發和測試環境
-
數據量較小且對可用性要求不高的應用
-
作為本地緩存使用
-
簡單的隊列或消息中間件場景
優勢
-
部署簡單,配置方便
-
資源消耗少
-
沒有復制和同步開銷
-
延遲最低
劣勢
-
單點故障風險高
-
無法橫向擴展
-
容量受單機內存限制
-
無法提供高可用性
最佳實踐
-
啟用持久化:配置AOF或RDB持久化,防止數據丟失
-
合理設置內存上限:避免內存溢出
-
定期備份:設置定時任務備份數據
-
監控系統:部署監控系統及時發現問題
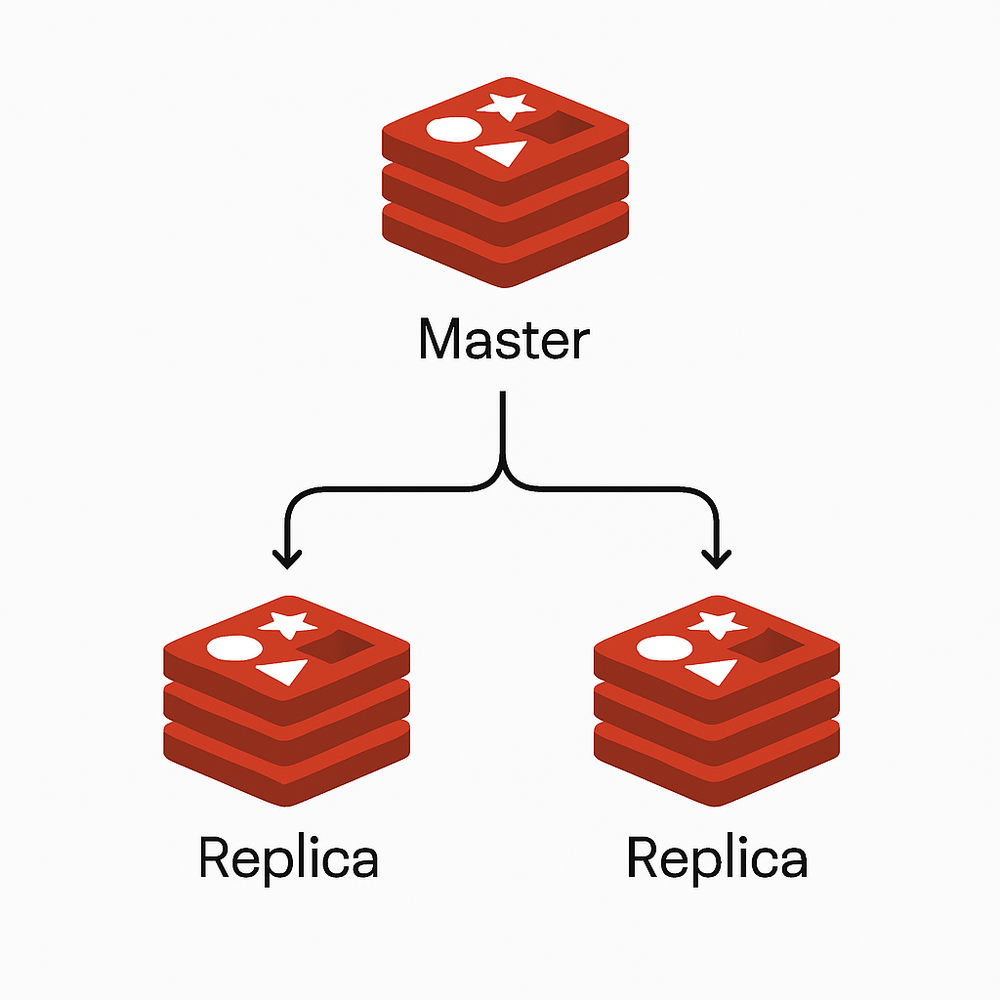
主從復制架構
原理
主從復制架構由一個主節點(master)和一個或多個從節點(replica)組成。主節點處理寫操作,從節點通過異步復制方式從主節點同步數據,并提供讀服務。
消息同步機制
Redis主從復制是通過三種主要機制實現的:
1. 全量同步(Full Resynchronization)
當從節點首次連接到主節點,或者無法進行部分重同步時,會觸發全量同步:
-
RDB文件傳輸:主節點啟動后臺進程生成RDB快照文件
-
命令緩沖:同時,主節點會緩沖所有新收到的寫命令
-
文件傳輸:RDB生成完成后,主節點將文件傳輸給從節點
-
從節點加載:從節點將文件保存到磁盤并加載到內存
-
增量命令同步:主節點發送緩沖的寫命令給從節點
全量同步對網絡帶寬和主節點性能有較大影響,特別是數據量大的情況下。
2. 部分重同步(Partial Resynchronization)
為了避免連接斷開后的全量重同步開銷,Redis 2.8引入了部分重同步機制:
-
復制偏移量:主從節點各自維護一個復制偏移量,記錄復制的字節數
-
復制積壓緩沖區:主節點維護一個固定長度的環形緩沖區,默認1MB,記錄最近執行的寫命令
-
復制ID:每個主節點有一個唯一的復制ID,標識數據集的"版本"
當從節點連接斷開后重新連接,會發送PSYNC命令,包含之前的復制ID和偏移量。主節點檢查:
-
如果復制ID匹配且請求的偏移量在復制積壓緩沖區內,則只發送缺失的部分命令
-
否則,執行全量同步
配置較大的復制積壓緩沖區可以提高部分重同步的成功率:
repl-backlog-size 100mb
3. 心跳檢測機制
主從節點間通過心跳機制維持連接和檢測狀態:
-
PING-PONG交互:主節點每隔10秒向從節點發送PING
-
復制偏移量交換:從節點每秒向主節點報告自己的復制偏移量
-
空閑連接檢測:即使沒有復制流量,心跳也能保持連接活躍
心跳參數可通過以下配置調整:
repl-ping-replica-period 10
repl-timeout 60
主從復制的工作流程
-
連接建立:從節點通過
slaveof或replicaof命令連接到主節點 -
握手協商:從節點發送
PING,主節點回復PONG -
同步協商:從節點發送
PSYNC命令,帶上復制ID和偏移量 -
數據同步:根據情況進行全量或部分同步
-
命令傳播:主節點持續將寫命令發送給從節點
-
定期確認:從節點定期向主節點確認已處理的數據量
復制的一致性保證
Redis復制是異步的,這意味著:
-
主節點不等待從節點確認就返回客戶端成功
-
可能存在主從數據不一致的窗口期
-
故障轉移時可能丟失已確認的寫入
對于需要更強一致性保證的場景,可以使用WAIT命令實現半同步復制:
WAIT <num-replicas> <timeout>
這會使主節點等待至少N個從節點應用寫入后再返回,但仍不是嚴格的強一致性。
適用場景
-
讀多寫少的業務場景
-
需要讀寫分離的應用
-
對數據安全性有一定要求的場景
-
需要提高讀性能的應用
優勢
-
提高讀性能和吞吐量
-
實現讀寫分離
-
提供數據備份
-
降低主節點負載
劣勢
-
不提供自動故障轉移
-
主節點故障時需要手動干預
-
寫性能受單個主節點限制
-
存在數據一致性延遲
最佳實踐
-
配置從節點只讀:防止誤操作
-
合理設置復制緩沖區:避免全量同步
-
監控復制狀態:定期檢查復制延遲
-
網絡優化:主從節點最好在同一數據中心,減少網絡延遲
-
數據安全性考慮:
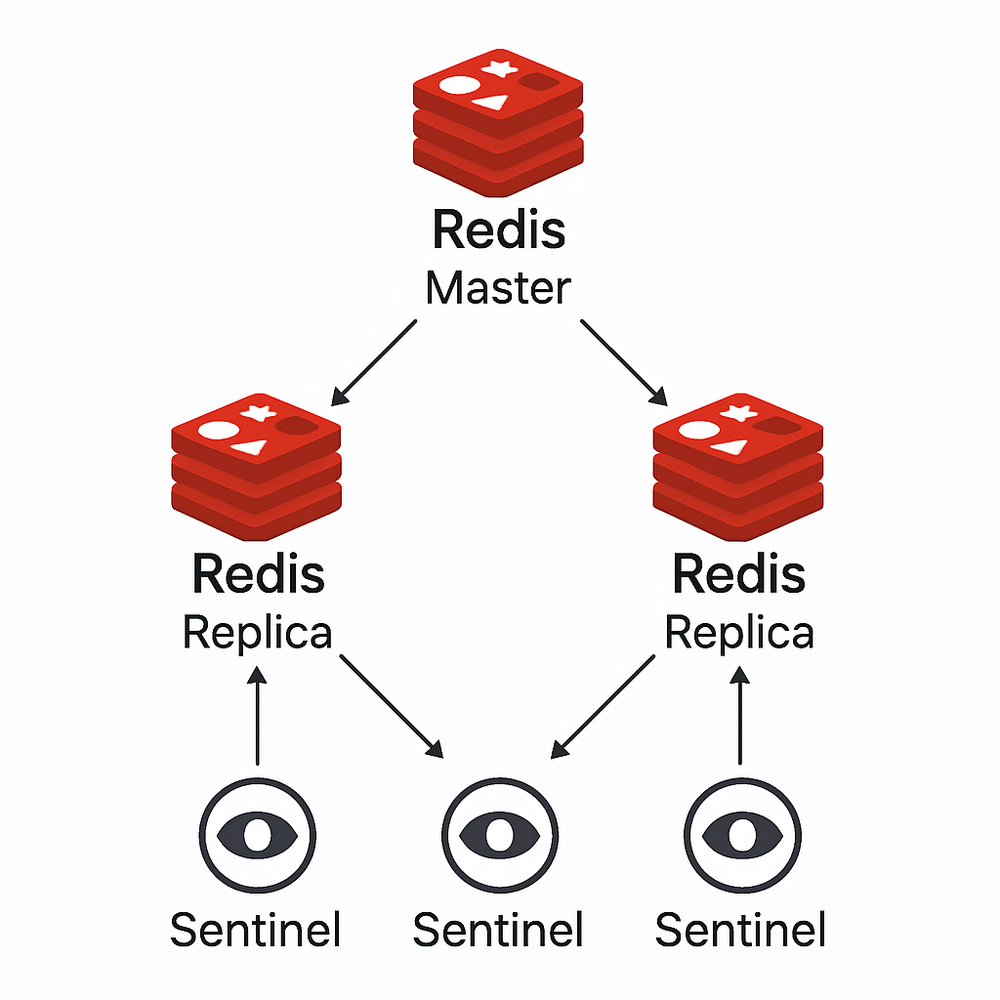
哨兵(Sentinel)架構
原理
哨兵架構是在主從復制基礎上,添加了哨兵系統來監控和管理Redis實例,實現自動故障檢測和故障轉移。哨兵系統由多個哨兵節點組成,它們通過共識算法協作工作。
哨兵的工作機制
Redis哨兵是一個分布式系統,提供高可用性保障,其核心機制包括:
1. 監控機制
哨兵通過三種方式監控Redis實例:
- 主觀下線檢測:
- 每個哨兵每秒向所有主從節點發送PING命令
- 如果在
down-after-milliseconds時間內未收到有效回復,標記為主觀下線(SDOWN) - 主觀下線只是單個哨兵的判斷,不會觸發故障轉移
- 客觀下線檢測:
- 當一個哨兵發現主節點主觀下線,會詢問其他哨兵是否同意
- 如果達到配置的
quorum數量,則標記為客觀下線(ODOWN) - 只有主節點的客觀下線才會觸發故障轉移
- 頻道消息監控:
- 哨兵通過Redis的發布/訂閱功能相互發現
- 訂閱主節點的
__sentinel__:hello頻道獲取其他哨兵信息 - 定期(每2秒)在此頻道發布自己的信息和主節點狀態
2. 哨兵集群的選主與一致性
當主節點被標記為客觀下線后,哨兵集群需要選出一個領導者來執行故障轉移:
- 領導者選舉:
- 基于Raft算法的簡化實現
- 每個發現主節點客觀下線的哨兵都可能成為候選人
- 候選人向其他哨兵發送
SENTINEL is-master-down-by-addr命令請求投票 - 每個哨兵在每輪選舉中只能投一票
- 第一個獲得多數票(N/2+1)的候選人成為領導者
- 選舉時間窗口:
- 選舉有時間窗口限制,默認為主節點故障確認時間+10秒
- 如果在時間窗口內無法選出領導者,將重新開始選舉
- 配置紀元(configuration epoch):
- 每次選舉都會增加配置紀元
- 用于防止腦裂和確保配置一致性
- 高紀元的配置會覆蓋低紀元的配置
3. 自動故障轉移流程
領導者哨兵執行故障轉移的具體步驟:
- 從節點篩選:
- 排除斷線、主觀下線、最近5秒未回復INFO命令的從節點
- 排除與主節點斷開連接超過
down-after-milliseconds*10的從節點
- 從節點排序:
- 按照復制偏移量排序(數據越新越優先)
- 如果偏移量相同,按照運行ID字典序排序
- 從節點晉升:
- 向選中的從節點發送
SLAVEOF NO ONE命令使其成為主節點 - 等待從節點轉變為主節點(最多等待
failover-timeout時間)
- 重新配置其他從節點:
- 向其他從節點發送
SLAVEOF命令,指向新主節點 - 更新哨兵的監控配置,將新主節點記錄下來
- 配置傳播:
- 領導者哨兵將新配置通過發布/訂閱傳播給其他哨兵
- 所有哨兵更新自己的配置狀態
4. 配置提供者功能
哨兵作為服務發現的權威來源:
- 客戶端服務發現:
- 客戶端連接到哨兵集群獲取當前主節點信息
- 使用
SENTINEL get-master-addr-by-name <master-name>命令 - 支持訂閱主節點地址變更通知
- 配置持久化:
- 哨兵會將配置持久化到本地配置文件
- 包括主從關系、運行ID、復制偏移量等信息
- 重啟后可以恢復之前的監控狀態
- 動態配置更新:
- 哨兵會自動發現主節點的從節點并更新配置
- 當拓撲結構變化時(如添加新的從節點),配置會自動更新
哨兵的高可用保證
哨兵自身的高可用性設計:
- 最少三個哨兵:
- 推薦至少部署3個哨兵實例
- 分布在不同的物理機或可用區
- 多數派原則:
- 故障轉移需要多數哨兵(N/2+1)參與決策
- 確保在網絡分區時只有一側能執行故障轉移
- 腦裂防護:
- 主節點可配置
min-replicas-to-write和min-replicas-max-lag - 當可見的從節點數量不足時,主節點拒絕寫入
- 防止網絡分區導致的雙主情況
適用場景
-
需要高可用性的生產環境
-
對系統自動恢復要求較高的場景
-
中小規模的Redis應用
-
讀多寫少且需要自動故障轉移的場景
優勢
-
提供自動故障檢測和轉移
-
無需人工干預即可恢復服務
-
支持水平擴展的讀能力
-
客戶端服務發現
劣勢
-
架構相對復雜
-
寫性能仍受單主節點限制
-
故障轉移期間可能有短暫不可用
-
腦裂情況下可能丟失數據
最佳實踐
-
部署至少3個哨兵節點:確保高可用性和決策準確性
-
合理設置判斷主節點下線的時間閾值:
-
配置客戶端連接:使用哨兵地址池而非直接連接Redis實例
-
防止腦裂:配置主節點最小寫入副本數
-
哨兵節點分布:部署在不同的物理機或可用區
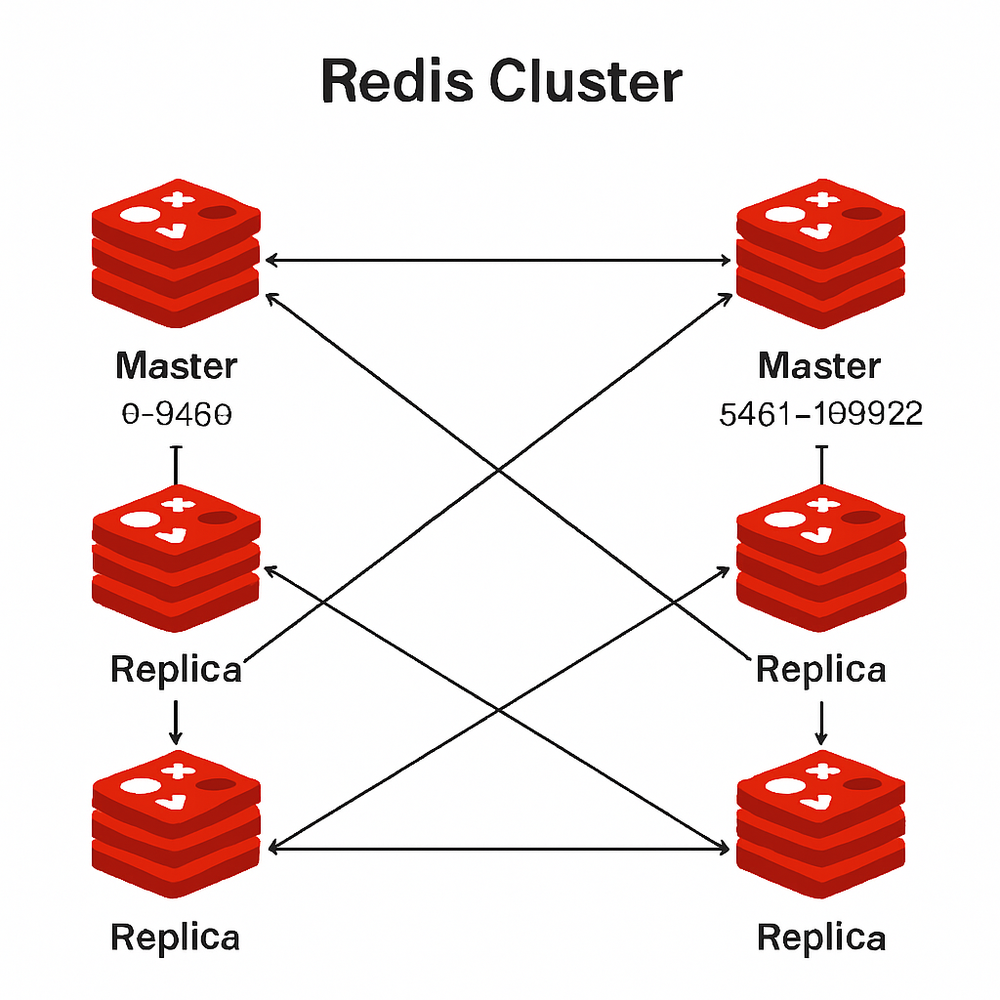
集群(Cluster)架構
原理
Redis集群通過分片(Sharding)的方式,將數據分散存儲在多個節點上,每個節點存儲一部分數據。Redis使用哈希槽(Hash Slot)機制,將16384個哈希槽分配給不同的節點,根據鍵的CRC16值對16384取模來確定數據存儲位置。
集群的工作機制
Redis集群通過分片實現數據的水平擴展,其核心機制包括:
1. 數據分片與哈希槽
Redis集群使用哈希槽(Hash Slot)而非一致性哈希來分配數據:
- 16384個哈希槽:
- 集群總共有16384個哈希槽
- 每個主節點負責一部分哈希槽
- 鍵到槽的映射:
- 使用CRC16算法計算鍵的哈希值,然后對16384取模
HASH_SLOT = CRC16(key) mod 16384
- 哈希標簽:
- 通過
{tag}語法強制多個鍵分配到同一個槽 - 例如:
user:{123}:profile和user:{123}:account會被分配到同一個槽 - 允許對這些鍵執行多鍵操作(如MGET、事務等)
- 槽遷移:
- 添加或刪除節點時,只需遷移相應的哈希槽
- 遷移過程是在線的,不影響集群服務
- 遷移期間對相關鍵的訪問會被重定向
2. Gossip協議與集群通信
Redis集群節點間通過Gossip協議進行通信和狀態同步:
- 集群總線:
- 每個節點有兩個TCP端口:客戶端端口和集群總線端口
- 集群總線端口默認是客戶端端口+10000
- 節點間通過二進制協議在集群總線上通信
- Gossip消息類型:
PING:定期發送,包含發送者已知的部分集群狀態PONG:響應PING或主動廣播狀態更新MEET:請求節點加入集群FAIL:廣播節點已失效的信息PUBLISH:用于發布/訂閱功能的集群范圍消息
- 心跳機制:
- 每個節點每秒隨機選擇一些節點發送PING
- 優先選擇長時間未收到PONG的節點
- 每100毫秒檢查是否有節點超過
cluster-node-timeout未響應
- 信息傳播:
- 每個節點的PING/PONG消息包含自己的信息和部分其他節點的信息
- 通過這種方式,信息最終會傳播到所有節點
- 關鍵事件(如節點失效)會加速傳播,所有節點主動廣播
3. 故障檢測與自動故障轉移
Redis集群的故障檢測和自動故障轉移機制:
- 節點失效檢測:
- 主觀下線(PFAIL):當節點A超過
cluster-node-timeout時間未響應節點B的PING,B將A標記為PFAIL - 客觀下線(FAIL):當超過半數主節點都認為某節點PFAIL時,該節點被標記為FAIL
- FAIL狀態會通過Gossip快速傳播到整個集群
- 自動故障轉移:
- 當主節點被標記為FAIL,其從節點會發起選舉
- 第一個發起選舉的從節點向所有主節點請求投票
- 每個主節點只能在一個配置紀元內投一票
- 獲得多數票的從節點晉升為新主節點
- 新主節點更新集群配置,接管原主節點的哈希槽
- 選舉限制:
- 從節點必須與主節點完成過復制(復制偏移量大于0)
- 每個配置紀元內,每個主節點只能投一票
- 如果兩秒內沒有從節點獲得足夠票數,將增加配置紀元重新選舉
4. 集群一致性與可用性保證
Redis集群在一致性和可用性方面的特性:
- 分區容忍度:
- 集群能夠在部分節點失效或網絡分區的情況下繼續運行
- 只要大多數主節點可以互相通信,集群就保持可用
- 多數派原則:
- 當少于一半的主節點不可達時,集群繼續提供服務
- 當多于一半的主節點不可達時,集群停止接受寫入
- 一致性保證:
- Redis集群默認提供最終一致性
- 使用異步復制,可能在故障轉移時丟失已確認的寫入
- 通過
WAIT命令可以實現更強的一致性保證,但不是嚴格的強一致性
- 集群配置參數:
cluster-node-timeout:節點失效超時時間,默認15000毫秒cluster-replica-validity-factor:從節點有效性因子,默認10cluster-migration-barrier:遷移屏障,主節點至少要有N個從節點才允許其中一個從節點遷移,默認1cluster-require-full-coverage:是否要求所有槽都被覆蓋才提供服務,默認yes
5.節點變更
添加新節點
-
加入集群
使用 CLUSTER MEET 命令讓新節點加入集群。新節點開始通過Gossip協議與其他節點通信,但此時它不持有任何槽位。 -
分配槽位
新節點默認是空的。需要手動或通過工具(如redis-cli --cluster reshard)將現有主節點的一部分槽位重新分配給新節點。這是核心步驟。 -
遷移槽數據
- 遷移命令(如CLUSTER SETSLOT IMPORTING 在目標節點 / CLUSTER SETSLOT MIGRATING 在源節點)標記槽位狀態。
- MIGRATE 命令用于原子地將單個鍵或一批鍵從源節點移動到目標節點。遷移在后臺進行。
- 遷移過程中,源節點和目標節點會協作處理請求:
- 源節點處理仍在它那里的鍵。
- 源節點對已遷移走的鍵或不在它那的鍵返回 MOVED。
- 源節點對正在遷移但尚未遷移走的鍵返回 ASK 重定向到目標節點。
- 當槽位中的所有鍵都遷移完成后,使用 CLUSTER SETSLOT NODE 在所有節點(或由主節點傳播)更新槽位歸屬到新節點。
- 添加為從節點(可選): 如果新節點要作為某個主節點的從節點,使用 CLUSTER REPLICATE 命令配置。
-
影響
- 性能開銷: 數據遷移會消耗源節點、目標節點和網絡的資源,可能影響集群性能。
- 客戶端重定向: 遷移期間和遷移完成后,客戶端可能會收到 MOVED 或 ASK 重定向,需要客戶端庫正確處理(更新緩存、重試)。
- 短暫不一致: 遷移過程中,同一個槽的數據部分在源節點,部分在目標節點。通過 ASKING 機制保證正確性。
- 槽位重新平衡: 集群整體負載更均衡(如果槽分配合理)。
減少節點(下線節點)
-
遷移槽數據(主節點): 不能直接下線持有槽位的主節點。必須先將其負責的所有槽位遷移到其他主節點。過程與添加節點時的遷移完全一致。redis-cli --cluster reshard 是常用工具。
-
處理從節點: 如果下線的是從節點,通常相對簡單:
-
直接執行 CLUSTER FORGET 命令(需要先在該從節點上執行 CLUSTER RESET 或直接停止進程)。
-
其主節點會感知到從節點丟失(通過Gossip超時)。
-
下線主節點
- 第一步:遷移所有槽位。 這是必須完成的步驟。
- 第二步: 確認該主節點不再持有任何槽位后,它本質上變成了一個“空”主節點。
- 第三步: 在集群的其他節點上執行 CLUSTER FORGET 命令,通知集群移除該節點。或者直接停止該節點進程,集群最終會通過Gossip協議將其標記為失敗并從節點列表中移除(需要時間)。
-
影響
- 性能開銷: 數據遷移同樣消耗資源。
- 客戶端重定向: 遷移期間有 MOVED/ASK。
- 容量減少: 集群整體存儲容量和處理能力下降。
-
高可用性影響
如果下線的是主節點且它之前有從節點,這些從節點會跟隨新的槽位持有者(遷移后槽位的新主節點)或者需要重新配置。如果下線的是最后一個從節點,其主節點失去冗余,故障時無法自動恢復。 -
槽位重新平衡
剩余節點承載了更多槽位。
適用場景
-
大規模數據存儲需求
-
需要橫向擴展的高吞吐量場景
-
需要高可用性和自動分片的生產環境
-
數據量超過單機內存容量的應用
優勢
-
支持水平擴展,理論上無容量限制
-
提供自動故障轉移和重新分片
-
高可用性,部分節點故障不影響整體服務
-
高吞吐量,可支持大規模并發訪問
劣勢
-
架構復雜度高,運維難度大
-
事務和多鍵操作受限(僅支持同一哈希槽的多鍵操作)
-
數據一致性保證較弱(異步復制)
-
網絡開銷較大
最佳實踐
-
合理規劃節點數量:根據數據量和性能需求確定
-
使用哈希標簽:確保相關鍵存儲在同一哈希槽
-
合理配置超時時間:避免頻繁故障轉移
-
監控集群狀態:定期檢查集群健康狀況
-
規劃容量和擴展:預留足夠的擴展空間,避免頻繁重新分片
Codis 集群架構
原理
Codis 采用中心化代理架構實現 Redis 分片集群,通過代理層(Proxy)屏蔽后端拓撲變化,對客戶端透明。核心組件包括:
- Codis-Proxy:無狀態代理,處理客戶端請求
- Codis-Dashboard:集群控制中心,管理元數據
- Codis-Group:Redis 實例組(1主N從)
- 外部存儲:ZooKeeper/etcd,存儲集群元數據
- Codis-FE:Web 管理界面(可選)

集群工作機制
1. 數據分片與路由機制
-
1024 預分片槽:
- 固定劃分 1024 個邏輯槽(Slot)
- 槽位分配由 Dashboard 集中管理
-
鍵路由算法:
slot = crc32(key) % 1024 # 默認分片算法 group = slot_map[slot] # 查詢槽位映射表 -
路由表管理:
- 槽位映射表存儲在外部存儲(ZK/etcd)
- Proxy 實時同步路由表
- 遷移時槽位標記為過渡狀態
2. 中心化控制體系
-
Dashboard 核心作用:
- 槽位分配與再平衡
- 節點狀態監控
- 自動故障轉移控制
- 在線數據遷移管理
-
元數據存儲:
元數據類型 存儲位置 示例 Slot-Group 映射 ZK/etcd {slot:1023, group_id:5} Proxy 列表 ZK/etcd [proxy1:19000, …] Group 拓撲 ZK/etcd {group5: {master:redisA, slaves:[redisB]}} -
心跳檢測:
- Dashboard 主動探測 Group 狀態
- 故障檢測超時時間可配置(默認10s)
- 從節點晉升需人工確認(可選自動)
3. 請求處理流程
4. 節點變更機制
添加新節點
-
Group 注冊:
# 在 Dashboard 操作 codis-admin --dashboard-add-group --group-id=5 codis-admin --dashboard-add-server --group-id=5 --redis=192.168.1.10:6379 -
槽位遷移:
- Dashboard 選擇源 Group 的槽位
- 觸發同步遷移命令:
codis-admin --slot-action --create --sid=568 \--to-group=5 --from-group=3 - 遷移過程:
- 源 Group 鎖定槽位
- 批量遷移鍵值(原子操作)
- 更新槽位映射表
-
客戶端影響:
- Proxy 自動更新路由表
- 零客戶端重定向(核心優勢)
- 遷移期間請求自動路由到正確節點
移除節點
-
槽位清空:
- 必須遷移待移除 Group 的所有槽位
- Dashboard 拒絕移除非空 Group
-
Group 刪除:
codis-admin --dashboard-remove-group --group-id=3 -
從節點處理:
- 直接刪除從節點無需遷移
- 主節點需先降級為從節點
適用場景
- 企業級大規模 Redis 集群(100+節點)
- 需要客戶端零改造的遷移場景
- 對運維可視化要求高的環境
- 需精細控制數據遷移進度的場景
- 多語言客戶端支持需求
優勢
-
客戶端透明:
- 兼容所有 Redis 客戶端
- 無需處理 MOVED/ASK 重定向
-
運維友好:
- Web 控制臺實時監控
- 細粒度遷移控制
- 在線擴縮容無感知
-
高可用設計:
- Proxy 無狀態可水平擴展
- Dashboard HA 方案(主備+存儲)
- Group 級自動故障切換
-
企業級特性:
- 數據平衡權重配置
- 讀寫分離支持
- 命名空間隔離
劣勢
-
架構復雜度:
- 5個核心組件需維護
- 強依賴外部存儲(ZK/etcd)
-
性能損耗:
- Proxy 轉發增加 1-2ms 延遲
- 大 value 傳輸存在內存拷貝
-
功能限制:
- 跨 slot 事務不支持
- Pub/Sub 功能受限
- 部分 Redis 命令不兼容(如 BLPOP)
最佳實踐
-
部署規劃:
- Proxy數量 = 預期QPS / 單Proxy承載能力(通常8-10w QPS) - Group數量 = 總內存 / 單Group內存限制(建議≤64GB) -
遷移優化:
- 避開業務高峰執行遷移
- 批量遷移設置合適并行度:
codis-admin --slot-action --max-bulk=500 # 每批遷移鍵數
-
高可用配置:
# Dashboard HA配置示例 dashboard:leader: "192.168.1.10:18080"follower: "192.168.1.11:18080"store: "zookeeper://zk1:2181,zk2:2181/codis" -
監控關鍵指標:
指標類別 關鍵指標 告警閾值 Proxy QPS、延遲、錯誤率 >80%資源利用率 Group 主從延遲、內存使用 內存>90% 遷移任務 遷移速度、剩余時間 持續1小時無進展 存儲 ZK節點數、請求延遲 節點異常
注:生產環境建議使用 Codis 3.2+ 版本,較早期版本有顯著穩定性提升
Active-Active地理分布式架構
原理
Active-Active架構(也稱為多活架構)允許在多個地理位置部署Redis實例,每個位置的實例都可以進行讀寫操作,并通過沖突解決機制保持數據一致性。Redis Enterprise提供的CRDTs(Conflict-free Replicated Data Types)技術是實現這種架構的關鍵。
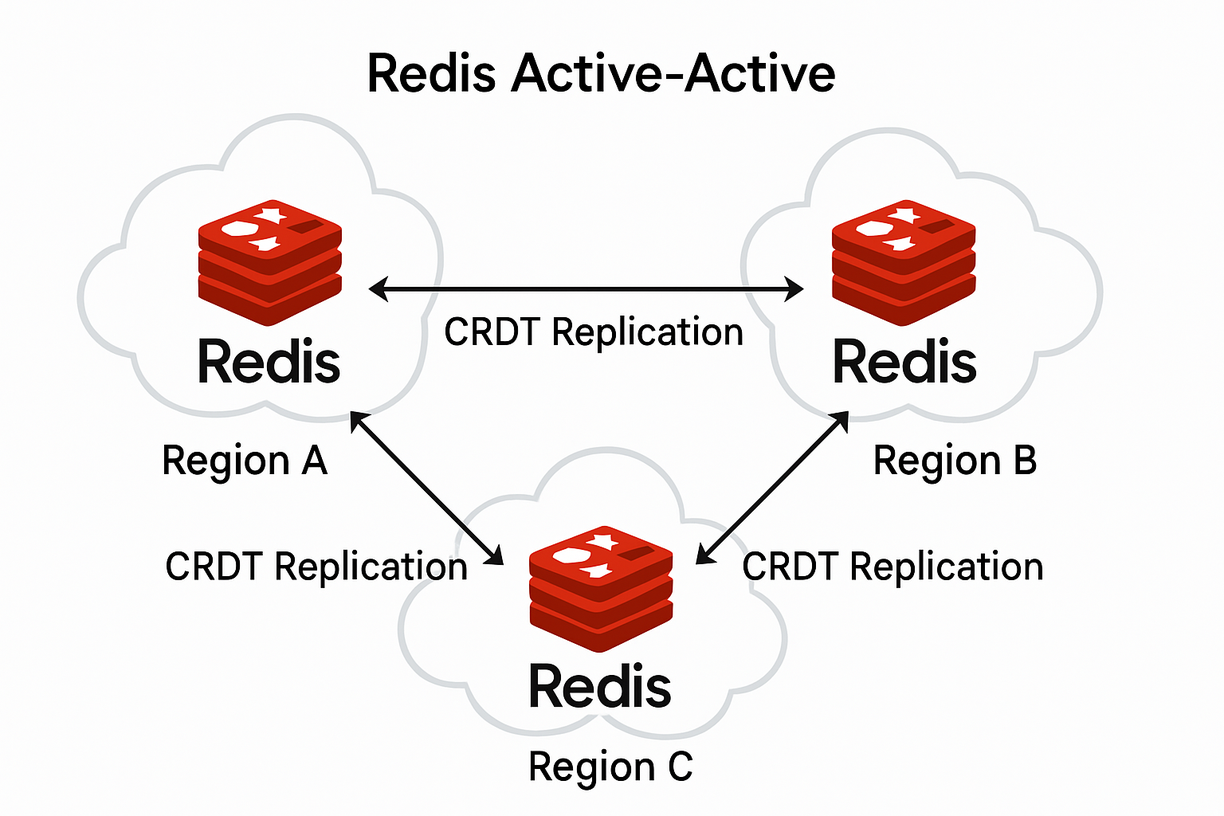
沖突解決機制
Active-Active架構使用無沖突復制數據類型(CRDTs)解決并發寫入沖突:
- 最終一致性:
- 所有實例最終會收斂到相同的數據狀態
- 不同實例可能暫時看到不同的數據視圖
- 沖突解決策略:
- 后寫入勝出:對于簡單值,最后的寫入會覆蓋之前的寫入
- 集合合并:對于集合類型,合并所有實例的元素
- 計數器累加:對于計數器,合并所有實例的增量
- 因果一致性:
- 使用向量時鐘跟蹤操作之間的因果關系
- 確保相關操作按正確順序應用
跨地域復制
Active-Active架構的跨地域復制機制:
- 異步復制:
- 實例間通過異步方式復制更新
- 本地寫入立即確認,然后后臺傳播到其他實例
- 沖突檢測與解決:
- 每個實例獨立應用本地寫入
- 接收到遠程更新時,應用沖突解決規則
- 解決后的結果再次傳播,確保最終一致性
- 網絡優化:
- 壓縮復制流量
- 批量傳輸更新
- 智能路由選擇最佳復制路徑
適用場景
-
全球化業務需要低延遲訪問
-
需要跨區域容災的關鍵業務
-
多區域寫入需求的應用
-
需要99.999%以上可用性的場景
優勢
-
提供跨地域的低延遲訪問
-
支持多區域同時寫入
-
極高的可用性(99.999%+)
-
自動沖突解決
劣勢
-
實現復雜度高
-
需要專業的商業版本支持(如Redis Enterprise)
-
成本較高
-
對網絡質量要求高
最佳實踐
-
合理規劃地理位置:選擇靠近用戶的區域部署
-
配置沖突解決策略:根據業務需求選擇合適的沖突解決方式
-
監控跨區域同步延遲:確保數據一致性在可接受范圍
-
網絡優化:使用專線或優質網絡連接各區域
-
容災演練:定期進行區域故障模擬和恢復測試
Kubernetes云原生部署
原理
在Kubernetes環境中部署Redis,利用Kubernetes的容器編排能力實現Redis的自動化部署、擴展和管理。可以通過Operator模式(如Redis Operator)或Helm Chart等方式部署各種Redis架構。
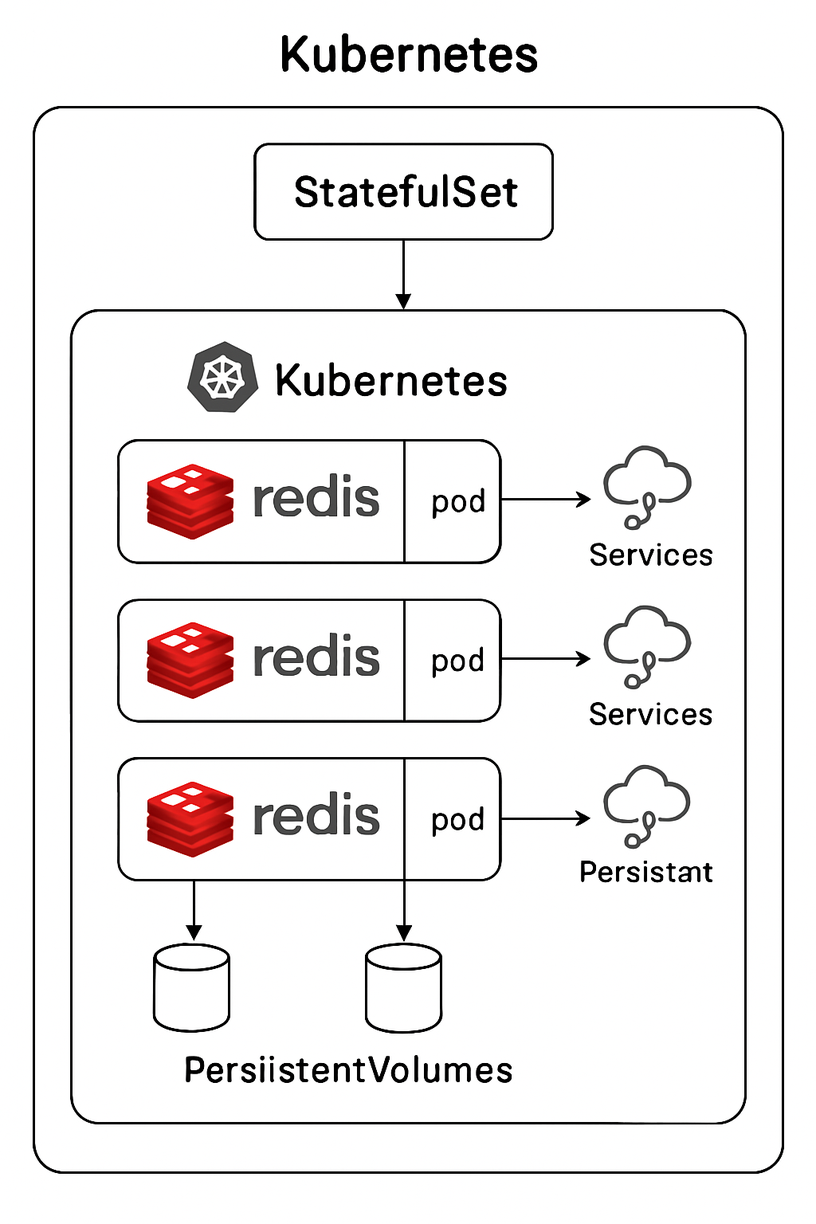
部署模式
Kubernetes中Redis的幾種部署模式:
- StatefulSet:
- 為Redis提供穩定的網絡標識和存儲
- 支持有序部署和擴縮容
- 適用于主從復制和哨兵架構
- Operator模式:
- 使用Redis Operator自動化部署和管理
- 支持自動故障轉移和配置管理
- 簡化復雜架構的運維
- Helm Chart:
- 使用Helm包管理器部署預配置的Redis
- 支持自定義配置和擴展
- 適用于快速部署標準架構
存儲考慮
Kubernetes中Redis的存儲選項:
- 持久卷(PV)和持久卷聲明(PVC):
- 為Redis數據提供持久化存儲
- 支持不同的存儲類(StorageClass)
- 確保Pod重啟后數據不丟失
- 本地存儲與網絡存儲:
- 本地存儲提供更好的性能
- 網絡存儲提供更好的可用性
- 權衡性能與可靠性
適用場景
-
云原生應用架構
-
DevOps和自動化運維環境
-
需要彈性伸縮的場景
-
混合云或多云部署
優勢
-
自動化部署和運維
-
彈性伸縮能力
-
與云原生生態系統集成
-
統一的管理平面
劣勢
-
增加了系統復雜度
-
性能可能受容器和網絡影響
-
需要Kubernetes專業知識
-
狀態管理和持久化存儲挑戰
最佳實踐
-
使用StatefulSet部署:確保穩定的網絡標識和存儲
-
配置持久化存儲:使用PersistentVolumeClaim
-
資源限制:設置合理的CPU和內存限制
-
使用Redis Operator:簡化復雜架構的部署和管理
-
網絡策略:配置適當的網絡策略保護Redis服務
架構選型指南與場景比對
選擇合適的Redis架構需要考慮多種因素,包括性能需求、可用性要求、數據規模、預算等。以下是一個架構選型指南和典型場景比對:
架構選型決策樹
- 單點部署:
- 開發/測試環境
- 數據量小(<5GB)
- 可用性要求低
- 預算有限
- 主從復制:
- 讀多寫少
- 需要讀寫分離
- 數據量中等(<10GB)
- 可接受手動故障恢復
- 哨兵架構:
- 需要高可用性
- 數據量中等(<10GB)
- 寫操作集中在單點可接受
- 需要自動故障恢復
- 集群架構:
- 大數據量(>10GB)
- 需要橫向擴展
- 高吞吐量要求
- 可接受一定的架構復雜性
- Active-Active架構:
- 全球化業務
- 極高可用性要求(99.999%+)
- 多區域寫入需求
- 預算充足
- Kubernetes部署:
- 已采用云原生架構
- 需要自動化運維
- 需要與其他云原生應用集成
- 具備Kubernetes專業知識
典型應用場景比對
| 場景 | 推薦架構 | 理由 |
|---|---|---|
| 電商網站商品緩存 | 集群架構 | 數據量大,讀寫頻繁,需要橫向擴展 |
| 社交媒體消息隊列 | 哨兵架構 | 需要高可用性,寫入集中,讀取分散 |
| 游戲排行榜 | 主從復制 | 讀多寫少,數據量適中 |
| 全球化應用會話存儲 | Active-Active架構 | 需要全球低延遲訪問,多區域寫入 |
| 微服務架構中的緩存 | Kubernetes部署 | 與其他微服務一致的部署和管理方式 |
| 日志收集和分析 | 單點或主從 | 臨時性數據,可用性要求不高 |
| 金融交易系統 | 集群+哨兵 | 高可用性和一致性要求,數據安全性高 |
| IoT數據處理 | 集群架構 | 大量并發寫入,需要橫向擴展 |
性能與可用性對比
| 架構模式 | 讀性能 | 寫性能 | 可用性 | 一致性 | 復雜度 | 成本 |
|---|---|---|---|---|---|---|
| 單點部署 | 中 | 高 | 低 | 高 | 低 | 低 |
| 主從復制 | 高 | 中 | 中 | 中 | 中 | 中 |
| 哨兵架構 | 高 | 中 | 高 | 中 | 中 | 中 |
| 集群架構 | 極高 | 高 | 高 | 中 | 高 | 高 |
| Active-Active | 極高 | 高 | 極高 | 最終一致性 | 極高 | 極高 |
| Kubernetes | 取決于底層架構 | 取決于底層架構 | 高 | 取決于底層架構 | 高 | 高 |
總結與展望
Redis提供了多種部署架構選擇,從簡單的單點部署到復雜的Active-Active地理分布式架構,可以滿足不同規模和需求的應用場景。選擇合適的架構需要綜合考慮性能、可用性、一致性、復雜度和成本等因素。
隨著云原生技術的發展,Redis在Kubernetes等環境中的部署變得越來越普遍。同時,Redis模塊生態系統的擴展(如RedisJSON、RediSearch、RedisGraph等)也為Redis提供了更多的應用可能性,這些都需要在架構設計時考慮。
未來,隨著邊緣計算和5G技術的普及,Redis可能會出現更多適合邊緣-云協同的部署架構模式。同時,隨著AI和機器學習的發展,Redis在向量數據庫方面的應用也將帶來新的架構需求和挑戰。
選擇Redis架構時,應始終遵循"適合業務需求"的原則,避免過度設計或選擇不足的架構。定期評估和調整架構,以適應業務的發展和變化,是保持Redis高效運行的關鍵。
參考資料
-
Redis官方文檔 - 復制
-
Redis官方文檔 - 哨兵
-
Redis官方文檔 - 集群
-
Redis官方文檔 - Active-Active地理分布式
-
Redis官方文檔 - Kubernetes部署



--Rasa成型可用 rasa服務化部署及識別意圖后的決策及行為)
)

)
技術應用解析:從原理到落地場景)

- 進制轉換)





)

:C++中的內存分配)

