網絡結構
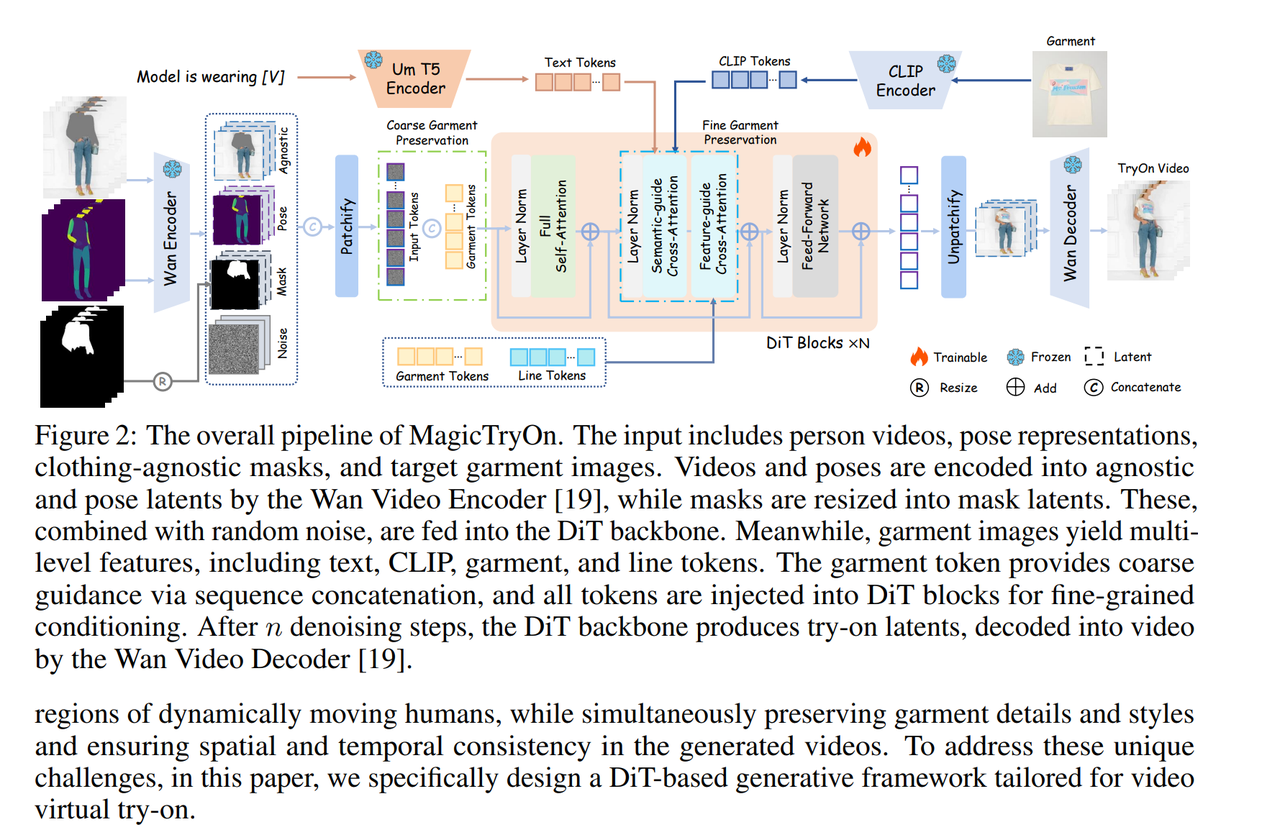
?Attention模塊詳解
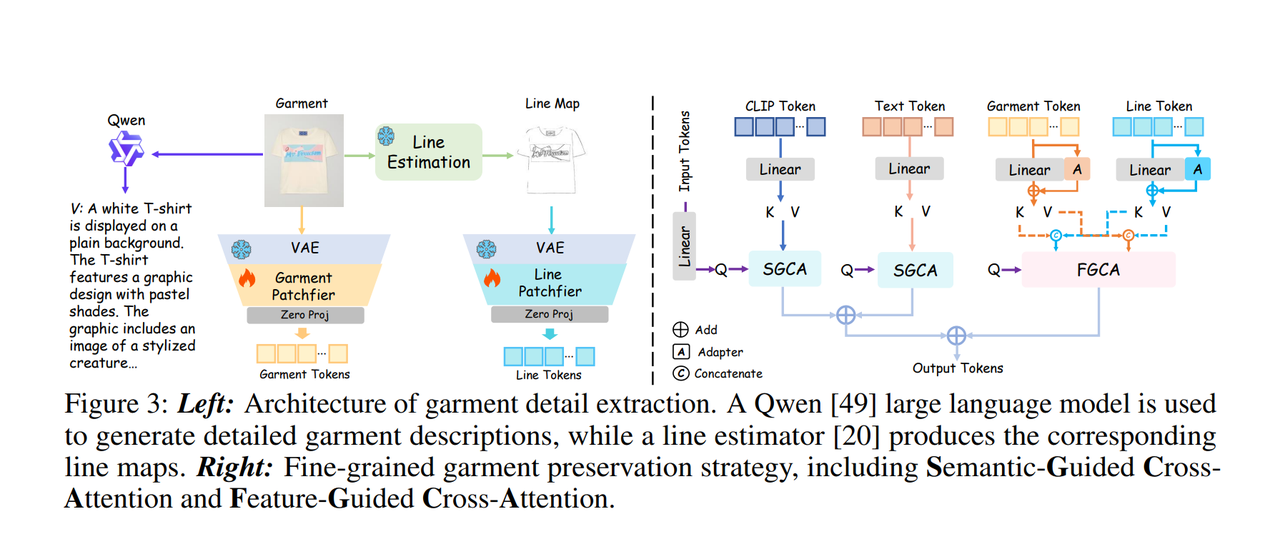 ????????左邊服裝通過qwen2.5-VL-7B來生成詳細的服裝描述;線條提取器產生相應的線條map;garment和line map通過vae轉換為潛在空間特征,然后分別經過patchfier,最后通過zero proj得到Garment Tokens和Line Tokens;右邊是dit中的attention block模塊(只包括cross attention部分),首先是Input Tokens 經過線性層和經過clip的圖像tokens做交叉注意力計算,Text Tokens (文本通過umt5 文本編碼器得到)經過線性層和經過線性層的Input Tokens 進行交叉注意力計算,后面將經過交叉注意力計算的文本特征和圖像特征相加在一起;FGCA也同樣是交叉注意力,只不過他們是將Line Tokens和Garment Tokens經過Linear得到的K,V分別堆疊在一起后再和Input Tokens進行叉注意力計算。最后將所有的經過注意力計算的特征相加在一起。需要注意的是一個輕量化Adapter模塊:自適應服裝特征分布 .
????????左邊服裝通過qwen2.5-VL-7B來生成詳細的服裝描述;線條提取器產生相應的線條map;garment和line map通過vae轉換為潛在空間特征,然后分別經過patchfier,最后通過zero proj得到Garment Tokens和Line Tokens;右邊是dit中的attention block模塊(只包括cross attention部分),首先是Input Tokens 經過線性層和經過clip的圖像tokens做交叉注意力計算,Text Tokens (文本通過umt5 文本編碼器得到)經過線性層和經過線性層的Input Tokens 進行交叉注意力計算,后面將經過交叉注意力計算的文本特征和圖像特征相加在一起;FGCA也同樣是交叉注意力,只不過他們是將Line Tokens和Garment Tokens經過Linear得到的K,V分別堆疊在一起后再和Input Tokens進行叉注意力計算。最后將所有的經過注意力計算的特征相加在一起。需要注意的是一個輕量化Adapter模塊:自適應服裝特征分布 .
訓練目標函數
?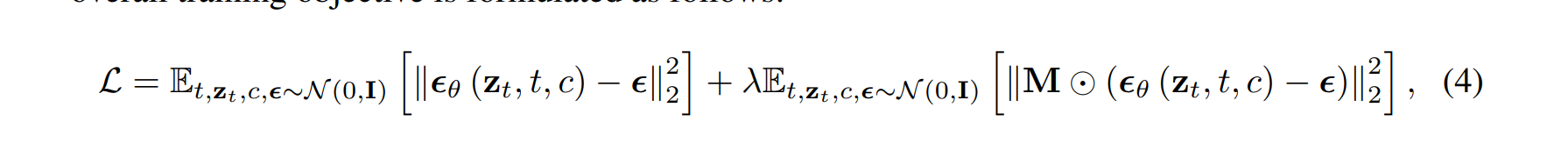
?引入了一個mask區域loss計算,加強需要生成的衣服區域的生成保真度。
?數據和評估指標
?數據
VITON-HD
DressCode
ViViD
?評估指標
?SSIM, LPIPS, FID, and KID;前兩個主要專注于兩個圖像像素的相似度,后兩個主要專注于兩個圖像像素分布的相似度
?實現細節
預訓練模型Wan2.1-Fun-14B-Control
第一階段使用分辨率256-512的分辨率訓練,第二階段繼續訓練,在512-1024分辨率上
訓練視頻49幀,batch_size為2。第一階段15k步數,第二階段10K步數。
優化器 AdamW,學習率1e-5
機器配置8 NVIDIA H20 (96GB) GPUs
?
參考論文
https://arxiv.org/pdf/2505.21325
目前代碼未開源
?

)
技術應用解析:從原理到落地場景)

- 進制轉換)





)

:C++中的內存分配)



)
)

