文章目錄
- 零、寫在前面
- 1、XV6 中的鎖
- 2、XV6 進程切換
- 3、觸發調度
- 一、Uthread: switching between threads
- 1.1 說明
- 1.2 實現
- 二、Using threads
- 2.1 說明
- 2.2 實現
- 三、Barrier
- 3.1 說明
- 3.2 實現
零、寫在前面
可以讀一下xv6 book 的第六章 鎖 以及 第七章 調度:
- https://xv6.dgs.zone/tranlate_books/book-riscv-rev1/c6/s0.html
- https://xv6.dgs.zone/tranlate_books/book-riscv-rev1/c7/s0.html
本實驗將使你熟悉多線程編程。你將實現一個用戶級線程庫中的線程切換,使用多個線程加速程序運行,并實現一個屏障(Barrier)機制。
1、XV6 中的鎖
Xv6有兩種類型的鎖:自旋鎖(spinlocks)和睡眠鎖(sleep-locks)。我們將從自旋鎖(注:自旋,即循環等待)開始。Xv6將自旋鎖表示為struct spinlock (*kernel/spinlock.h*:2)。結構體中的重要字段是locked,當鎖可用時為零,當它被持有時為非零。從邏輯上講,xv6應該通過執行以下代碼來獲取鎖
void acquire(struct spinlock* lk) // does not work!
{for(;;) {if(lk->locked == 0) {lk->locked = 1;break;}}
}上述代碼嚴格意義上是不正確的,因為很可能兩個 CPU 同時抵達第5行代碼,然后都通過執行第6行持有鎖,那么就有兩個CPU 同時持有鎖,違背了互斥屬性。
我們需要一種方式,來使第5行和第6行作為**原子性(即不可分割)**步驟執行。
因為鎖被廣泛使用,多核處理器通常提供實現第5行和第6行的原子版本的指令。在RISC-V上,這條指令是amoswap r, a。amoswap讀取內存地址a處的值,將寄存器r的內容寫入該地址,并將其讀取的值放入r中。也就是說,它交換寄存器和指定內存地址的內容。它原子地執行這個指令序列,使用特殊的硬件來防止任何其他CPU在讀取和寫入之間使用內存地址。
自旋鎖
Xv6的acquire(*kernel/spinlock.c*:22)使用可移植的C庫調用歸結為amoswap的指令__sync_lock_test_and_set;返回值是lk->locked的舊(交換了的)內容。acquire函數將swap包裝在一個循環中,直到它獲得了鎖前一直重試(自旋)。每次迭代將1與lk->locked進行swap操作,并檢查lk->locked之前的值。如果之前為0,swap已經把lk->locked設置為1,那么我們就獲得了鎖;如果前一個值是1,那么另一個CPU持有鎖,我們原子地將1與lk->locked進行swap的事實并沒有改變它的值。
獲取鎖后,用于調試,acquire將記錄下來獲取鎖的CPU。lk->cpu字段受鎖保護,只能在保持鎖時更改。
函數release(*kernel/spinlock.c*:47) 與acquire相反:它清除lk->cpu字段,然后釋放鎖。從概念上講,release只需要將0分配給lk->locked。C標準允許編譯器用多個存儲指令實現賦值,因此對于并發代碼,C賦值可能是非原子的。因此release使用執行原子賦值的C庫函數__sync_lock_release。該函數也可以歸結為RISC-V的amoswap指令。
睡眠鎖
自旋鎖也有著明顯缺點:
- 如果另一個進程想要獲取自旋鎖,那么長時間保持自旋鎖會導致獲取進程在自旋時浪費很長時間的CPU
- 一個進程在持有自旋鎖的同時不能讓出(yield)CPU,然而我們希望持有鎖的進程等待磁盤I/O的時候其他進程可以使用CPU
- 持有自旋鎖時讓步是非法的,因為如果第二個線程試圖獲取自旋鎖,就可能導致死鎖
- 因為
acquire不會讓出CPU, - 第二個線程的自旋可能會阻止第一個線程運行并釋放鎖。在持有鎖時讓步也違反了在持有自旋鎖時中斷必須關閉的要求。因此,我們想要一種鎖,它在等待獲取鎖時讓出CPU,并允許在持有鎖時讓步(以及中斷)。
Xv6以睡眠鎖(sleep-locks)的形式提供了這種鎖。acquiresleep (*kernel/sleeplock.c*:22) 在等待時讓步CPU
睡眠鎖有一個被自旋鎖保護的鎖定字段,acquiresleep對sleep的調用原子地讓出CPU并釋放自旋鎖。結果是其他線程可以在acquiresleep等待時執行。
因為睡眠鎖保持中斷使能,所以它們不能用在中斷處理程序中。因為acquiresleep可能會讓出CPU,所以睡眠鎖不能在自旋鎖臨界區域中使用(盡管自旋鎖可以在睡眠鎖臨界區域中使用)。
因為等待會浪費CPU時間,所以自旋鎖最適合短的臨界區域;睡眠鎖對于冗長的操作效果很好。
2、XV6 進程切換
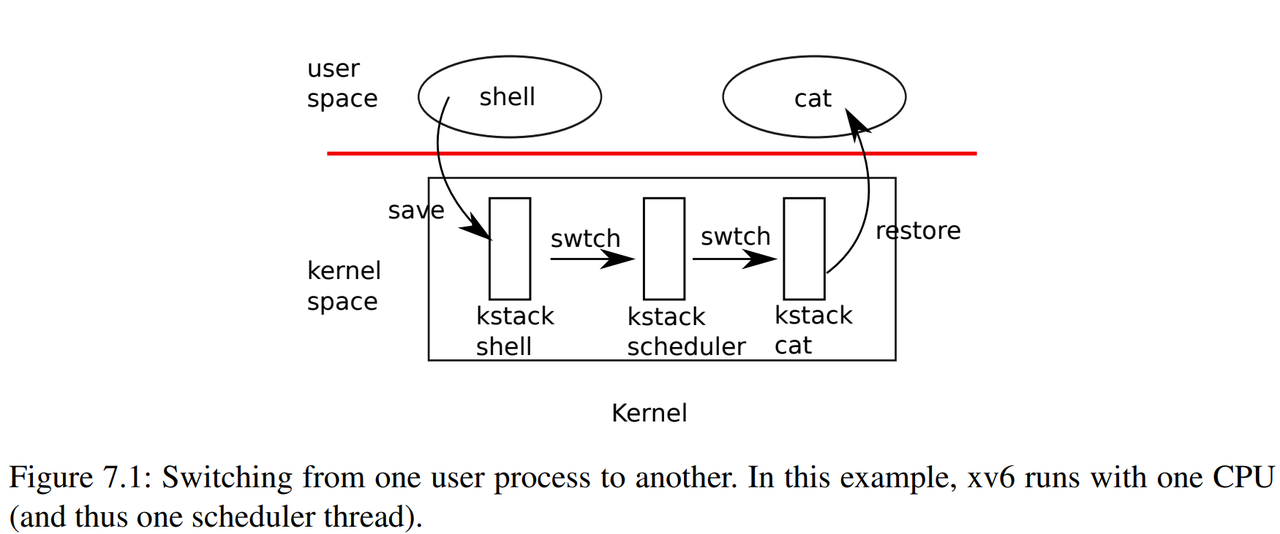
圖7.1概述了從一個用戶進程(舊進程)切換到另一個用戶進程(新進程)所涉及的步驟:
- 一個到舊進程內核線程的用戶-內核轉換(系統調用或中斷)
- 一個到當前CPU調度程序線程的上下文切換
- 一個到新進程內核線程的上下文切換
- 以及一個返回到用戶級進程的陷阱
- 從上圖可以看到,兩個不同核心上使用了兩個不同的內核棧,來保證安全執行。
? XV6 進程切換主要依賴兩個函數,swtch() 和 scheduler()
1、swtch
void swtch(struct context *old, struct context *new);
- 保存當前寄存器到 old 中
- 從 new 中加載寄存器
- 返回到new的 ra 寄存器指向的地址
.globl swtch
swtch:# 保存當前 CPU 的上下文到 old (a0 參數)sd ra, 0(a0) # 保存 ra 寄存器指向的函數返回地址 return addresssd sp, 8(a0) # 保存棧頂位置sd s0-s11... # 保存被調用者保存的寄存器# 加載新上下文 new (a1 參數)到 CPUld ra, 0(a1) # 加載新的返回地址ld sp, 8(a1) # 加載新的棧指針ld s0-s11... # 加載新的寄存器值ret # 返回到新上下文的 ra 指定的地址(ra 已經設置過了)- swtch 運行在內核態,此時,用戶進程的狀態在切換到 內核態 的時候已經保存到
trapframe里了,所以,這里的匯編程序只需要 保存/恢復 函數調用相關的寄存器即可
2、scheduler
板子上電后,每個 CPU 都會運行從 enter.S -> start.c -> main.c -> scheduler() 的流程。
// start() jumps here in supervisor mode on all CPUs.
void
main()
{if(cpuid() == 0){... // 一系列的初始化工作__sync_synchronize();started = 1;} else {while(started == 0) // 其他 CPU 等待 0 號位完成初始化再執行;__sync_synchronize();kvminithart(); // turn on paging 開啟分頁trapinithart(); // install kernel trap vector 注冊 trap ...}scheduler(); // 進入自己的調度器
}- 對于 0 號 CPU,負責初始化 內存、進程、文件管理 以及 啟動第一個用戶程序 等工作,全局初始化 執行完以后,進入 scheduler()。
- 對于其他 CPU,在等待 0 號位完成 全局初始化 后,再進行開啟自己的 分頁(每個 CPU 的寄存器都是獨立的)、注冊中斷 等工作,最終也進入 scheduler()。
在 xv6 中,結構體 cpu 保存了當前 CPU 的上下文 context,以及當前 CPU 正在運行的進程 proc。
// Per-CPU state.
struct cpu {struct proc *proc; // The process running on this cpu, or null.struct context context; // swtch() here to enter scheduler().
};- 調度器(scheduler)以每個CPU上一個特殊線程的形式存在,每個線程都運行
scheduler函數。此函數負責選擇下一個要運行的進程 - scheduler函數邏輯:
- 遍歷進程表,尋找一個處于
runnable狀態的進程,然后調用swtch()切換到該進程。- 當前CPU 的狀態會被保存到 c->context 中,
- ra 寄存器保存的是 swtch() 的下一條指令地址(對應代碼中的 c->proc = 0)
- 進程p 返回時,ra 會被恢復為 swtch 時的值,即 c->proc = 0
- p->context 會被加載到 CPU,然后返回到 ra 指向的地址繼續執行
- p->context ra 保存的是上一次執行的位置,如果是新進程,則ra 會指向 forkret()函數(forkret() 負責新進程創建后的收尾工作)
- 當前CPU 的狀態會被保存到 c->context 中,
- 如果沒有需要執行的進程,執行
wfi指令,讓 CPU 進入 低功耗 等待狀態,直到有 中斷 發生。
- 遍歷進程表,尋找一個處于
void scheduler(void)
{struct proc *p;struct cpu *c = mycpu();c->proc = 0;for(;;){// 允許中斷,這樣 I/O 中斷才能喚醒等待的進程intr_on();// 遍歷進程表,選取一個處于 runnable 狀態的進程for(p = proc; p < &proc[NPROC]; p++){// 確保每一個進程只有一個 CPU 在修改狀態acquire(&p->lock);// 找到了if(p->state == RUNNABLE){p->state = RUNNING;c->proc = p;// 保存當前調度器(cpu->context)的狀態,恢復 p->context(保存了進程 p 上次離開時的內核上下文)swtch(&c->context, &p->context);// 當進程 p 再次切回到 CPU 后,繼續執行此處,即 ra 寄存器返回的地址c->proc = 0;}release(&p->lock);}if(nproc <= 2) { // only init and sh existintr_on();asm volatile("wfi");}}
}XV6 創建新進程的時候,會為該進程創建新的上下文 context,這一步用來保證:如果一個新創建的進程首次被調度器選中,p->context 不會為空。
static struct proc* allocproc(void)
{...// Set up new context to start executing at forkret,// which returns to user space.memset(&p->context, 0, sizeof(p->context));p->context.ra = (uint64)forkret;p->context.sp = p->kstack + PGSIZE;...
}那么開機首次從 內核 scheduler() 切換到 用戶進程的過程可以有如下描述:
首次切換:
scheduler() 運行↓
swtch(&c->context, &p->context)↓ 保存 scheduler() 的上下文到 c->context↓ 加載進程的上下文(從 p->context 中獲取)↓ usertrapret() -> trampoline.S:1. 切換到用戶頁表2. 從 trapframe 恢復所有用戶寄存器3. 返回用戶態繼續執行XV6 如何從 用戶進程切換回 scheduler() ?
3、觸發調度
在 XV6 中,有 三個 主要入口會調用 swtch() 切換回 scheduler():
- yield():主動讓出 CPU
```c
void yield(void) {struct proc *p = myproc();acquire(&p->lock);p->state = RUNNABLE;sched(); // 調用 swtch 切換到 schedulerrelease(&p->lock);
}```
-
exit():進程退出
void exit(int status) {// ... 清理進程資源 ...p->state = ZOMBIE;release(&original_parent->lock);sched(); // 切換到 scheduler,永不返回panic("zombie exit"); } -
sleep():進程休眠
void sleep(void *chan, struct spinlock *lk) {// ... 設置休眠條件 ...p->chan = chan;p->state = SLEEPING;sched(); // 切換到 scheduler// ... 喚醒后的清理工作 ... }我們下面只看 用戶進程時間片用完,觸發定時器中斷的場景:
void usertrap(void) {// ... if(which_dev == 2) { // 時鐘中斷yield();} }void kerneltrap(void) {// ...if(which_dev == 2 && myproc() != 0 && myproc()->state == RUNNING) {yield();} }-
如果 which_dev == 2,說明是 時鐘中斷,觸發了
yield()。 -
定時器的時長是在 CPU0 執行初始化工作的時候設置的:
kernel/start.c // 為每個 CPU 的時鐘中斷間隔為 1000,000 個 CPU 周期 timerinit() {... int interval = 1000000; // cycles; about 1/10th second in qemu.*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;... } -
每個進程允許執行 1000,000 個 CPU 周期,到期觸發 時鐘中斷,然后調用
yield(),yield()又調用了sched()函數讓出 CPU。void sched(void) {...struct proc *p = myproc();swtch(&p->context, &mycpu()->context);... } -
sched() 函數很簡單,轉頭調用 swtch() 執行切換,入參 old = p->context,new = mycpu->context
- 把當前 CPU 狀態保存到正在運行進程的 context 。
- 取出上次 mycpu->context 保存的上下文,恢復到 CPU
- switch 匯編執行最后一行 ret 的那一刻,切換回 scheduler() 繼續運行(c->proc = 0)。
-
void scheduler(void) {...for(;;){...for(p = proc; p < &proc[NPROC]; p++){...swtch(&c->context, &p->context);c->proc = 0; }} } -
切回 調度器 后,
scheduler()繼續查找 下一個 需要調度的進程,進程的時間片用完了,觸發 定時器中斷,調用yield()切換回 內核調度器scheduler(),……
-
記得切換到分支 thread
一、Uthread: switching between threads
1.1 說明
在本練習中,你將設計并實現一個用戶級線程系統的上下文切換機制。為幫助你開始,xv6 提供了兩個文件:user/uthread.c 和 user/uthread_switch.S,以及一個在 Makefile 中構建 uthread 程序的規則。uthread.c 包含了大部分用戶級線程庫的代碼以及三個簡單測試線程的代碼,但線程的創建和線程間切換的部分尚未完成。、
你的任務是設計一個方案來創建線程,并實現寄存器的保存和恢復,從而在多個線程間切換,并將該方案實現出來。
你需要完成以下幾個函數中的代碼:
thread_create()和thread_schedule()(位于user/uthread.c)thread_switch()(位于user/uthread_switch.S)
你的目標之一是:當 thread_schedule() 首次運行某個線程時,該線程應在它自己的棧上執行傳給 thread_create() 的函數。
另一個目標是:thread_switch() 需要保存當前線程的寄存器狀態(從這個線程切換出去),恢復目標線程的寄存器狀態(切換到它),并跳回該線程上次執行到的位置繼續運行。
你需要決定把寄存器保存在哪里。一個好的方法是修改 struct thread 來保存寄存器。你還需要在 thread_schedule() 中調用 thread_switch(),你可以按需傳遞參數,但目的是從當前線程 t 切換到 next_thread。
官網的一些提示:
thread_switch只需要保存和恢復**被調用者保存(callee-save)**的寄存器。- 因為調用者的寄存器已經保存在了 thread_schedule 的棧上了
- 你可以查看
user/uthread.asm文件中的匯編代碼,這在調試時可能很有用。 - 為了測試你的代碼,可以使用
riscv64-linux-gnu-gdb單步調試thread_switch。你可以這樣開始:
(gdb) file user/_uthread
Reading symbols from user/_uthread...
(gdb) b uthread.c:60
這會在 uthread.c 的第 60 行設置一個斷點。這個斷點可能在你運行 uthread 之前就被觸發。
當你的 xv6 shell 運行起來后,輸入 uthread,gdb 就會在第 60 行處中斷。此時你可以使用如下命令查看 uthread 的狀態:
(gdb) p/x *next_thread
使用 x 命令可以檢查內存內容,例如:
(gdb) x/x next_thread->stack
你可以直接跳到 thread_switch 的開始:
(gdb) b thread_switch
(gdb) c
使用如下命令逐條執行匯編指令:
(gdb) si
1.2 實現
- 先在uthread.c 添加 上下文結構體context
- 然后在 thread_schedule 的相應位置(即找到的要執行的線程和當前不一樣)調用 thread_switch
- 然后在 thread_create 中完成對于新線程上下文的初始化,并將傳入的func 放入 ra,sp 初始化
struct context{uint64 ra;uint64 sp;uint64 s0;uint64 s1;uint64 s2;uint64 s3;uint64 s4;uint64 s5;uint64 s6;uint64 s7;uint64 s8;uint64 s9;uint64 s10;uint64 s11;
};struct thread {char stack[STACK_SIZE]; /* the thread's stack */int state; /* FREE, RUNNING, RUNNABLE */struct context context; /* thread context */
};void thread_schedule(void)
{struct thread *t, *next_thread;// ...if (current_thread != next_thread) { /* switch threads? */next_thread->state = RUNNING;t = current_thread;current_thread = next_thread;/* YOUR CODE HERE* Invoke thread_switch to switch from t to next_thread:* thread_switch(??, ??);*/thread_switch((uint64)&t->context, (uint64)&next_thread->context);} elsenext_thread = 0;
}void thread_create(void (*func)())
{struct thread *t;for (t = all_thread; t < all_thread + MAX_THREAD; t++) {if (t->state == FREE) break;}t->state = RUNNABLE;// YOUR CODE HEREmemset(&t->context, 0, sizeof t->context);t->context.ra = (uint64)func;t->context.sp = (uint64)t->stack + STACK_SIZE;
}
還有一個是 完善一下 uthread_switch.S:
- 挺沒技術含量的,就把舊線程的寄存器存一下,新線程的恢復一下就好了
/* YOUR CODE HERE */
# a0 old context
# a1 new context# store cur context
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)# restore context of new t
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret /* return to ra */
make qemu 運行 uthread測試:
二、Using threads
2.1 說明
在本次實驗中,你將通過使用哈希表來探索使用線程和鎖進行并行編程。你應當在一臺真實的 Linux 或 macOS 計算機上完成該實驗(不是 xv6,也不是 qemu),并且該計算機應具有多個核心。
官網說了balabala一堆,其實就是讓我們給哈希表加鎖來保證并發訪問安全性。
2.2 實現
們打開./notxv6/下的 ph.c:
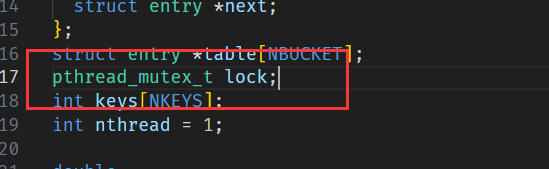
添加一個鎖:
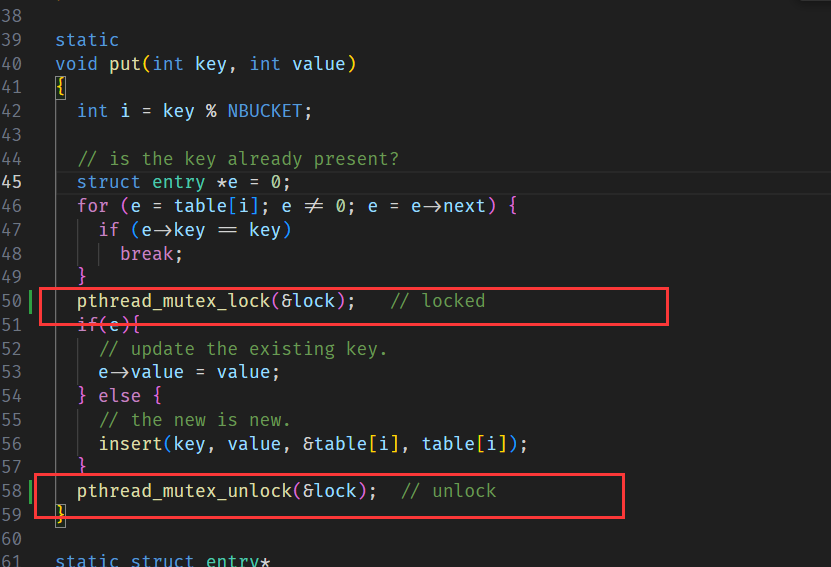
put 時上鎖:
記得初始化:

我們單獨make grade 測試,發現關于ph_safe 和 ph_fast 的部分都能通過:

三、Barrier
3.1 說明
在本次實驗中,你將實現一個 屏障(barrier):這是一個程序中的同步點,所有參與的線程必須在此等待,直到所有其他線程也到達該點后才能繼續執行。
你將使用 pthread 條件變量 來實現屏障機制,條件變量是一種線程間的同步機制,類似于 xv6 中的 sleep 和 wakeup。
notxv6/barrier.c 文件中包含一個未正確實現的屏障:
$ make barrier
$ ./barrier 2
barrier: notxv6/barrier.c:42: thread: Assertion `i == t' failed.其中 2 表示參與屏障同步的線程數(即 barrier.c 中的 nthread 變量)。每個線程執行一個循環,在每次迭代中調用 barrier(),然后隨機睡眠一段微秒級時間。
這個 assert 失敗的原因是:某個線程在其他線程還沒到達屏障前就提前通過了屏障。
目標行為是:每個線程都在 barrier() 中阻塞,直到所有 nthread 個線程都調用了 barrier() 之后,才能一起繼續。
你的任務是:實現正確的屏障行為。除了你在前一個 ph 實驗中用到的 pthread_mutex 鎖,這里你還需要用到兩個新的 pthread 原語。
pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond
pthread_cond_wait 在調用時會釋放傳入的 mutex,并在被喚醒時重新獲得這個 mutex 鎖。
我們已經為你提供了 barrier_init() 的實現。你的任務是實現 barrier(),讓程序不再 panic。
結構體 struct barrier 的各個字段是為你實現功能而準備的。
你在實現時需要處理兩個問題:
- 多輪屏障調用的區分:即同一個線程會多次調用
barrier(),每一次調用構成一個新的“輪次(round)”。變量bstate.round記錄當前是哪一輪。當所有線程都到達當前輪次的屏障時,你應將bstate.round加一。 - 線程間的競態問題:某個線程可能在離開當前輪次的屏障后太快,結果在其他線程還沒離開時就已經進入下一輪了。如果此時它修改了
bstate.nthread等共享變量,會造成錯誤。你需要確保:離開屏障的線程不會影響正在等待的前一輪的線程。
3.2 實現
打開notxv6 下的barrier.c,我們只需實現里面的barrier 函數即可
- 獲取鎖,增加 nthread
- 如果夠了就修改輪次,然后重置 nthread
- 然后喚醒其它線程
- 否則,讓步等待
static void
barrier()
{// YOUR CODE HERE//// Block until all threads have called barrier() and// then increment bstate.round.//pthread_mutex_lock(&bstate.barrier_mutex);++bstate.nthread;if (bstate.nthread >= nthread) {++ bstate.round;bstate.nthread = 0;// wake up all the threadspthread_cond_broadcast(&bstate.barrier_cond);} else {// wait for other threadspthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);}pthread_mutex_unlock(&bstate.barrier_mutex);
}
make grade 的 barrier 部分:













論文詳解(包括解題思路和寫作要點))


第2期)



