
機器學習入門核心算法:層次聚類算法(AGNES算法和 DIANA算法)
- 一、算法邏輯
- 二、算法原理與數學推導
- 1. 距離度量
- 2. 簇間距離計算(連接標準)
- 3. 算法偽代碼(凝聚式)
- 三、模型評估
- 1. 內部評估指標
- 2. 外部評估指標(已知真實標簽)
- 3. 超參數選擇
- 四、應用案例
- 1. 生物信息學
- 2. 文檔主題分層
- 3. 圖像分割
- 4. 社交網絡分析
- 五、面試題及答案
- 常見問題
- 六、相關論文
- 七、優缺點對比
- 總結
一、算法邏輯
層次聚類(Hierarchical Clustering)通過構建樹狀結構(樹狀圖/Dendrogram)揭示數據內在的層次關系,分為兩類:
- 凝聚式(Agglomerative)
- 自底向上:每個樣本初始為一個簇 → 迭代合并最近簇 → 最終形成單一簇
- 流程:
計算距離矩陣 → 合并最近簇 → 更新距離矩陣 → 重復至終止
- 分裂式(Divisive)
- 自頂向下:所有樣本初始為一個簇 → 迭代分裂最異質簇 → 直至每個樣本一簇
- 計算復雜度高,較少使用
核心特點:
- 無需預設聚類數
- 樹狀圖可視化層次關系
- 合并/分裂過程不可逆
二、算法原理與數學推導
1. 距離度量
設樣本 X = { x 1 , x 2 , . . . , x n } X = \{x_1, x_2, ..., x_n\} X={x1?,x2?,...,xn?}, x i ∈ R d x_i \in \mathbb{R}^d xi?∈Rd
常用距離:
- 歐氏距離: d ( x i , x j ) = ∑ k = 1 d ( x i k ? x j k ) 2 d(x_i, x_j) = \sqrt{\sum_{k=1}^d (x_{ik} - x_{jk})^2} d(xi?,xj?)=k=1∑d?(xik??xjk?)2?
- 曼哈頓距離: d ( x i , x j ) = ∑ k = 1 d ∣ x i k ? x j k ∣ d(x_i, x_j) = \sum_{k=1}^d |x_{ik} - x_{jk}| d(xi?,xj?)=k=1∑d?∣xik??xjk?∣
2. 簇間距離計算(連接標準)
| 類型 | 公式 | 特點 |
|---|---|---|
| 單連接 | d min ( C i , C j ) = min ? a ∈ C i , b ∈ C j d ( a , b ) d_{\text{min}}(C_i, C_j) = \min_{a \in C_i, b \in C_j} d(a,b) dmin?(Ci?,Cj?)=a∈Ci?,b∈Cj?min?d(a,b) | 易形成鏈式結構 |
| 全連接 | d max ( C i , C j ) = max ? a ∈ C i , b ∈ C j d ( a , b ) d_{\text{max}}(C_i, C_j) = \max_{a \in C_i, b \in C_j} d(a,b) dmax?(Ci?,Cj?)=a∈Ci?,b∈Cj?max?d(a,b) | 對噪聲敏感 |
| 質心法 | d cent ( C i , C j ) = d ( μ i , μ j ) d_{\text{cent}}(C_i, C_j) = d(\mu_i, \mu_j) dcent?(Ci?,Cj?)=d(μi?,μj?) | 可能導致逆反(Inversion) |
其中 μ i = 1 ∣ C i ∣ ∑ x ∈ C i x \mu_i = \frac{1}{|C_i|}\sum_{x \in C_i} x μi?=∣Ci?∣1?∑x∈Ci??x 為簇質心, Δ SSE \Delta \text{SSE} ΔSSE 為合并后的簇內平方和增量。
3. 算法偽代碼(凝聚式)
輸入: 數據集 X, 連接標準
輸出: 樹狀圖
1. 初始化 n 個簇,每個簇包含一個樣本
2. 計算所有簇對的距離矩陣 D
3. for k = n to 1:
4. 找到 D 中最小距離的簇對 (C_i, C_j)
5. 合并 C_i 和 C_j 為新簇 C_{new}
6. 更新距離矩陣 D(移除 C_i, C_j,添加 C_{new})
7. 記錄合并高度(距離)
8. 生成樹狀圖
三、模型評估
1. 內部評估指標
- 輪廓系數(Silhouette Coefficient):
s ( i ) = b ( i ) ? a ( i ) max ? { a ( i ) , b ( i ) } s(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}} s(i)=max{a(i),b(i)}b(i)?a(i)?
a ( i ) a(i) a(i):樣本 i i i 到同簇其他點的平均距離, b ( i ) b(i) b(i):到最近其他簇的平均距離。 s ( i ) ∈ [ ? 1 , 1 ] s(i) \in [-1,1] s(i)∈[?1,1],越大越好。 - 共表型相關(Cophenetic Correlation):
衡量樹狀圖距離與原始距離的一致性(值接近1表示層次結構保留良好)
2. 外部評估指標(已知真實標簽)
- 調整蘭德指數(Adjusted Rand Index, ARI)
- Fowlkes-Mallows Index(FMI)
3. 超參數選擇
- 切割高度選擇:通過樹狀圖的"最長無交叉垂直邊"確定聚類數
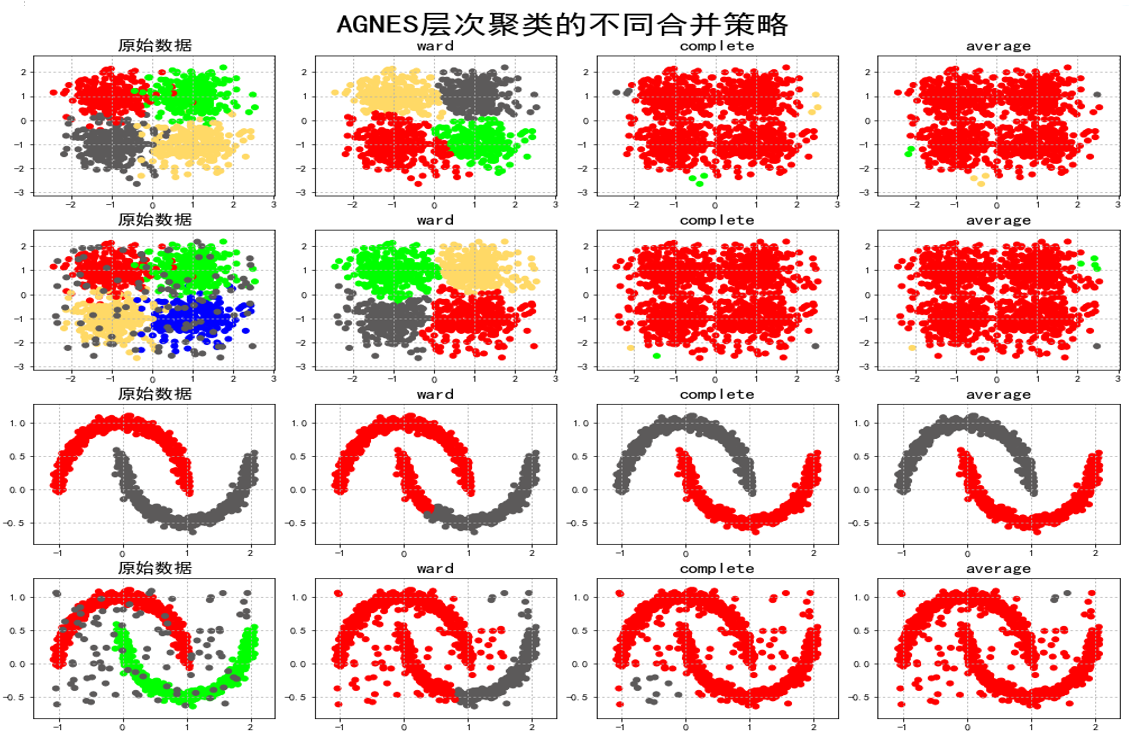
- 連接標準選擇:
- 單連接:適合非凸形狀
- Ward法:適合凸簇且噪聲少
四、應用案例
1. 生物信息學
- 基因表達聚類:對RNA-seq數據聚類,識別功能相似的基因模塊
- 工具:GenePattern、Cluster 3.0
2. 文檔主題分層
- 步驟:
- 文檔→TF-IDF向量
- 余弦距離 + 平均連接
- 切割樹狀圖得到主題層級(如:科技→AI→CV/NLP)
3. 圖像分割
- 流程:
像素→顏色+坐標特征 → Ward法聚類 → 合并相似區域 - 優勢:保留空間連續性
4. 社交網絡分析
- 用戶行為數據聚類 → 發現社區層級結構(如:核心用戶群→子興趣組)
五、面試題及答案
常見問題
-
Q: 層次聚類與K-means的本質區別?
A:- 層次聚類生成樹狀結構,K-means生成平面劃分
- 層次聚類無需預設K,K-means需指定聚類數
- 層次聚類復雜度 O ( n 3 ) O(n^3) O(n3),K-means為 O ( n k ) O(nk) O(nk)
-
Q: Ward法的目標函數是什么?
A: 最小化合并后的簇內平方和增量:
Δ SSE = ∣ C i ∣ ∣ C j ∣ ∣ C i ∣ + ∣ C j ∣ ∥ μ i ? μ j ∥ 2 \Delta \text{SSE} = \frac{|C_i||C_j|}{|C_i|+|C_j|} \|\mu_i - \mu_j\|^2 ΔSSE=∣Ci?∣+∣Cj?∣∣Ci?∣∣Cj?∣?∥μi??μj?∥2 -
Q: 何時選擇全連接而非單連接?
A: 當需要緊湊球形簇且數據噪聲較少時;單連接易受噪聲影響形成鏈式結構。 -
Q: 如何處理大規模數據?
A:- 使用優先隊列優化到 O ( n 2 log ? n ) O(n^2 \log n) O(n2logn)
- 采樣或Mini-Batch
- 切換為BIRCH(平衡迭代規約聚類)算法
六、相關論文
-
奠基性論文:
- Ward, J. H. (1963). Hierarchical Grouping to Optimize an Objective Function
貢獻:提出Ward最小方差法 - Johnson, S. C. (1967). Hierarchical Clustering Schemes
貢獻:系統化連接標準
- Ward, J. H. (1963). Hierarchical Grouping to Optimize an Objective Function
-
高效優化:
- Murtagh, F. (1983). A Survey of Recent Advances in Hierarchical Clustering Algorithms
貢獻:提出 O ( n 2 ) O(n^2) O(n2) 單連接算法
- Murtagh, F. (1983). A Survey of Recent Advances in Hierarchical Clustering Algorithms
-
生物學應用:
- Eisen, M. B., et al. (1998). Cluster Analysis of Gene Expression Data
工具:開發TreeView軟件
- Eisen, M. B., et al. (1998). Cluster Analysis of Gene Expression Data
七、優缺點對比
| 優點 | 缺點 |
|---|---|
| 1. 可視化強(樹狀圖展示層次) | 1. 計算復雜度高(凝聚式 O ( n 3 ) O(n^3) O(n3)) |
| 2. 無需預設聚類數 | 2. 合并/分裂后不可逆 |
| 3. 靈活選擇距離/連接標準 | 3. 對噪聲和離群點敏感(尤其全連接) |
| 4. 適合層次結構數據(如生物分類學) | 4. 大樣本內存消耗大 |
總結
- 核心價值:揭示數據內在層次關系(如生物進化樹、文檔主題樹)
- 工業選擇:中小規模數據用層次聚類(<10k樣本),大規模用BIRCH或HDBSCAN
- 關鍵決策:距離度量 + 連接標準(Ward法最常用)
- 趨勢:與深度學習結合(如深度層次聚類)
)


)













Java/python/JavaScript/C/C++/GO最佳實現)
的鋰電池健康狀態(SOH)預測)
