MYSQL:
查詢函數:
執行查詢語句:
1.mysql_query("SQL語法");
凡是執行操作希望拿到數據庫返回的數據進行展示的(結果返回: 數據結果);
2.執行結果的處理:成功為結果集,失敗為false;
成功返回結果:SQL指令沒有錯誤,但是查詢結果本身為空也返回true(結果集是一種資源:轉換成bool永遠為TRUE)
失敗為false:SQL指令有問題
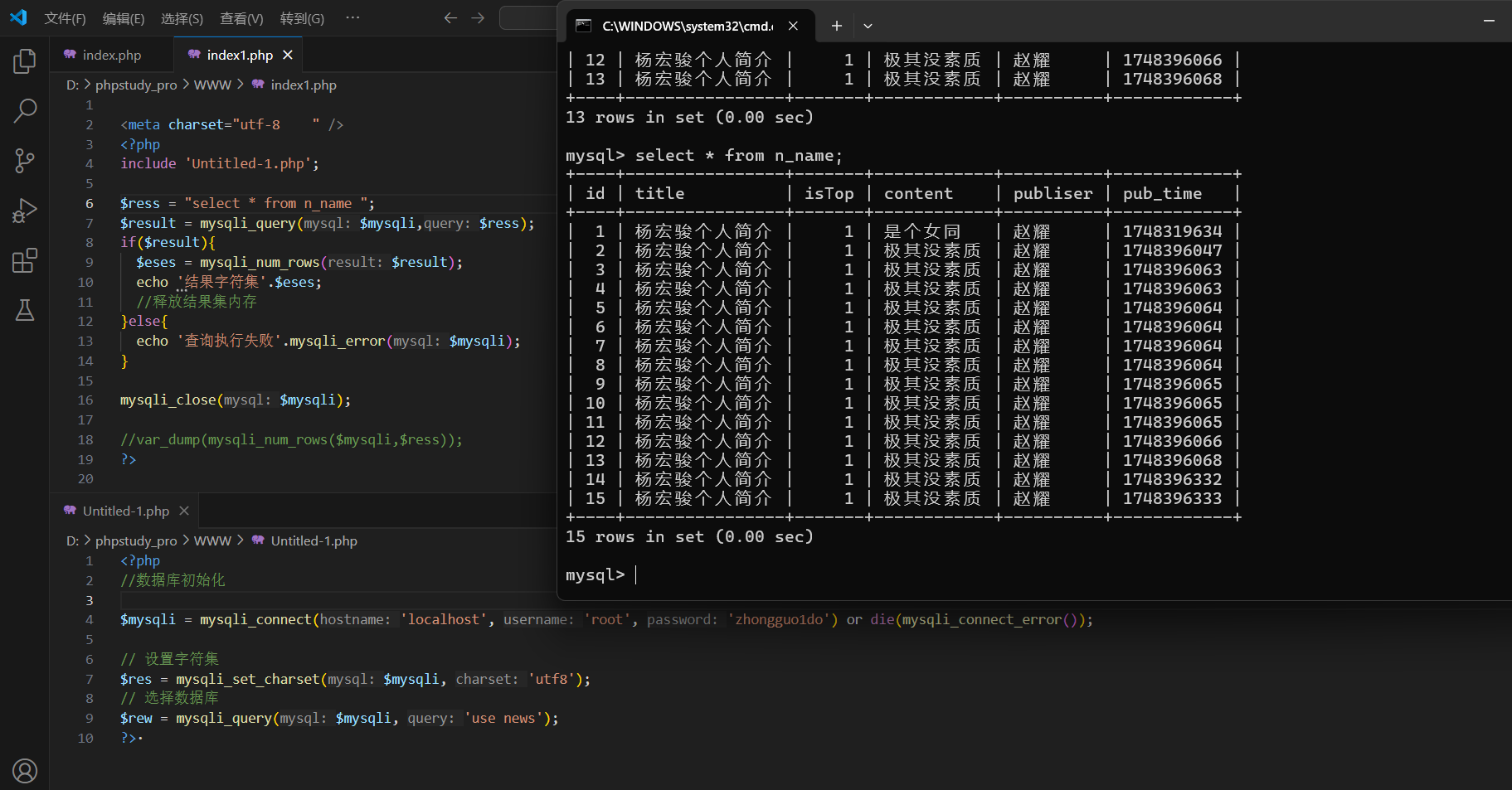
獲取結果集行數:
mysqli_num_rows(SQL指令變量);
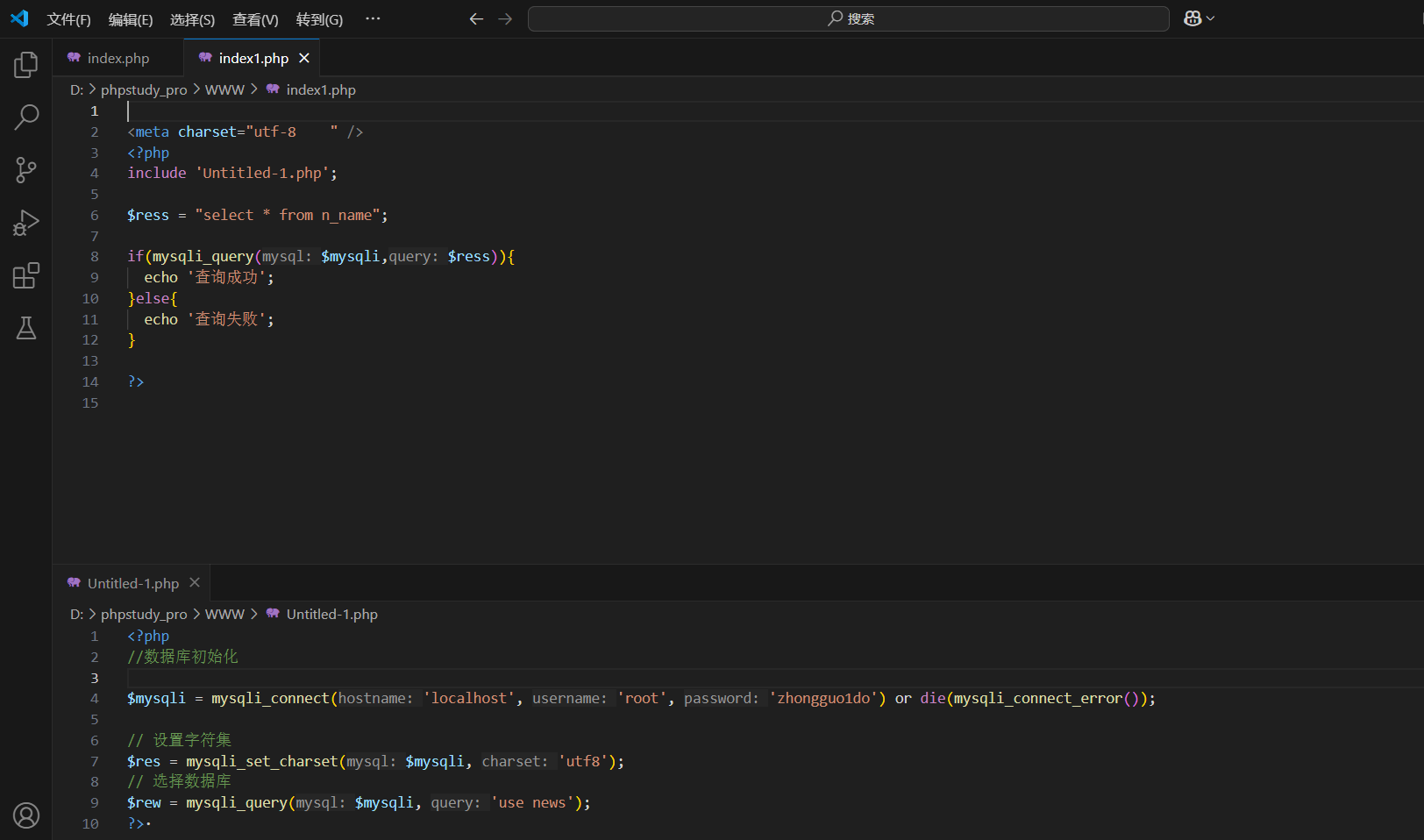
<meta charset="utf-8 " />
<?php
include 'Untitled-1.php';$ress = "select * from n_name ";
$result = mysqli_query($mysqli,$ress);
if($result){$eses = mysqli_num_rows($result);echo '結果字符集'.$eses;//釋放結果集內存
}else{echo '查詢執行失敗'.mysqli_error($mysqli);
}mysqli_close($mysqli); //var_dump(mysqli_num_rows($mysqli,$ress));
?>
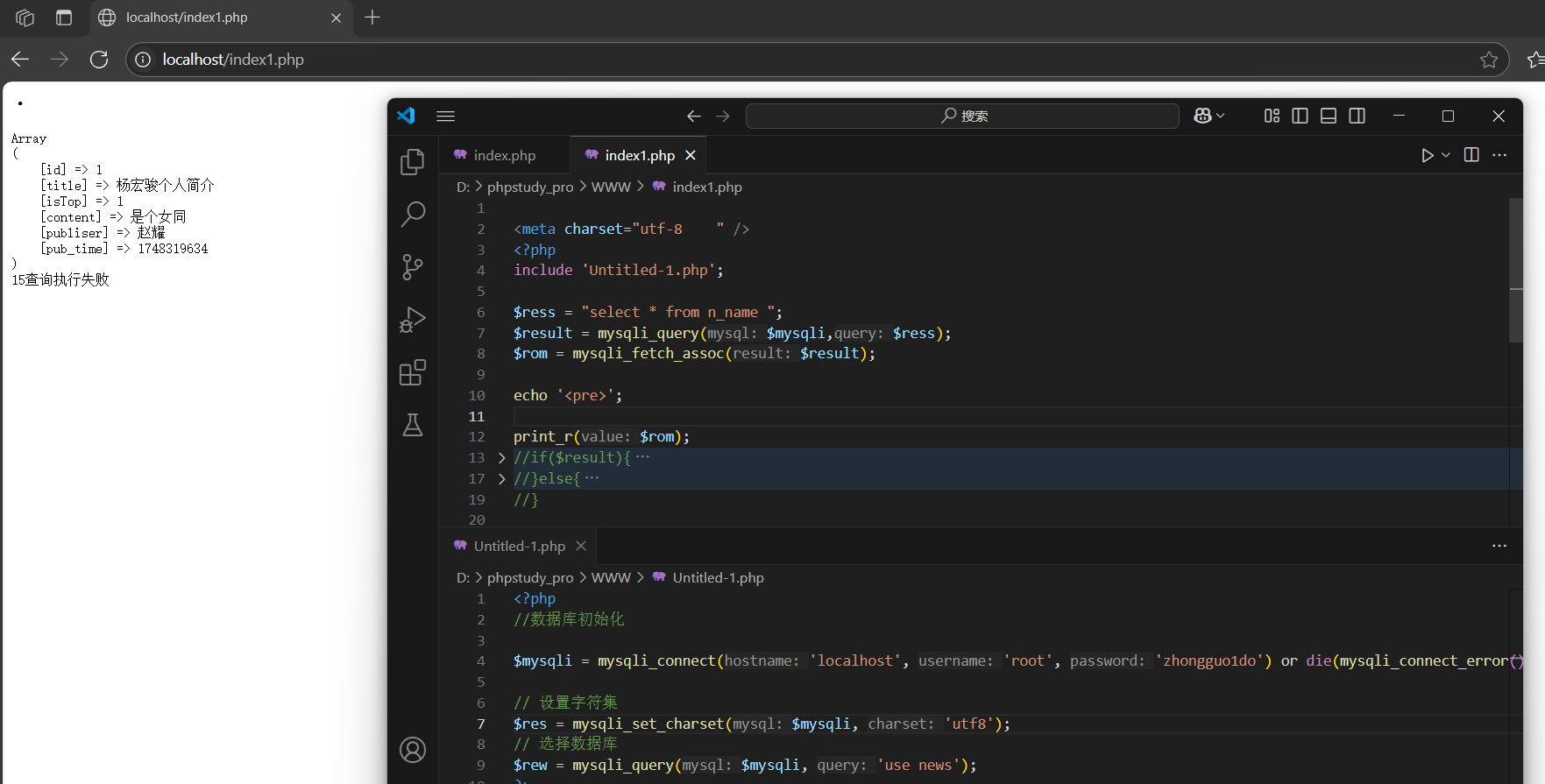
解析結果集:
將一種結果集資源(PHP不能直接使用),轉換成一種PHP能夠解析的數據格式,通過從結果集中(結果集指針,類似數組指針),按照結果集指針所在位置取出對應的一條記錄(一行),返回一個數組,同時指針下移……直到指針移出結果集.
myqsli_fetch_assoc(變量);
獲取關聯數組,表的表單名字作為數組下標,元素值作為數組元素值。
mysqli_fetch_row(變量):
獲取索引數組,只獲取數據的值,然后數組的下標從0開始自動索引。
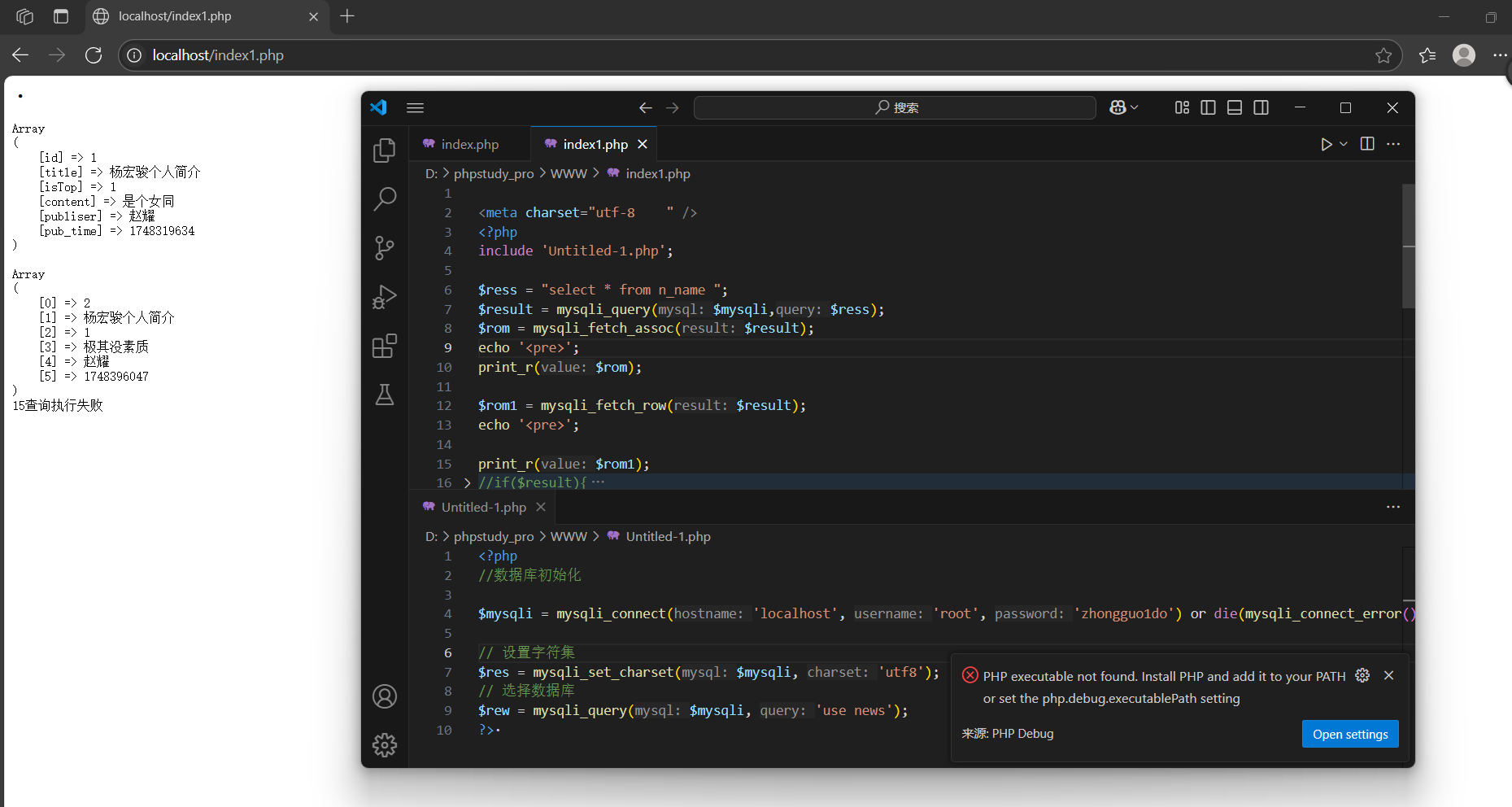
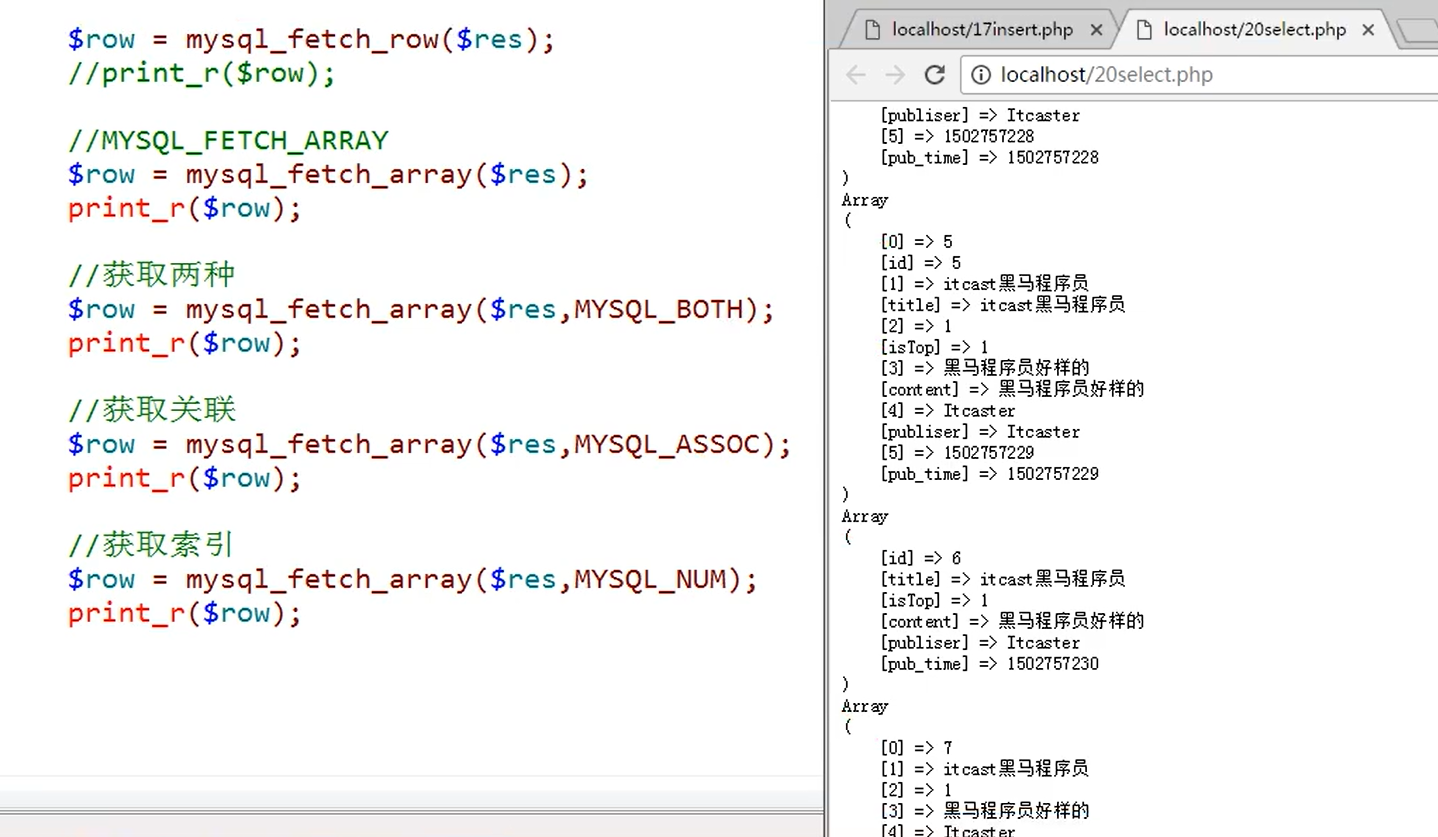
mysqli_fetch_array:
獲取關聯后者索引數組,但是默認是同時存在的:一個記錄取兩次,形成一組是關聯數組,一組是索引數組;但是可以通過第二個參數來決定獲取的方式
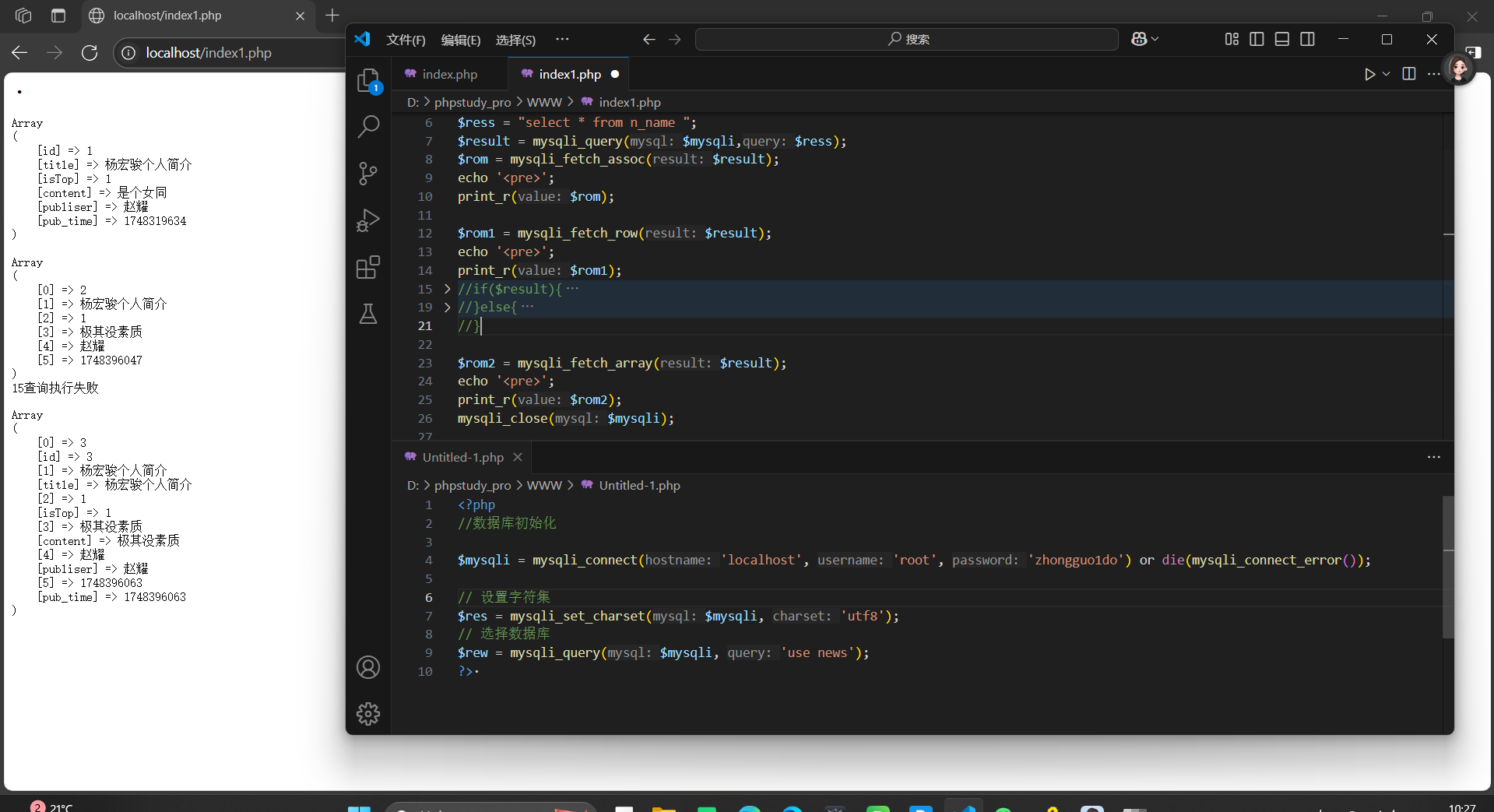
補:MYSQL_ASSOC 只獲取關聯數組,MYSQL_NUM只獲取數組,MYSQL_BOTH獲取全部兩種:
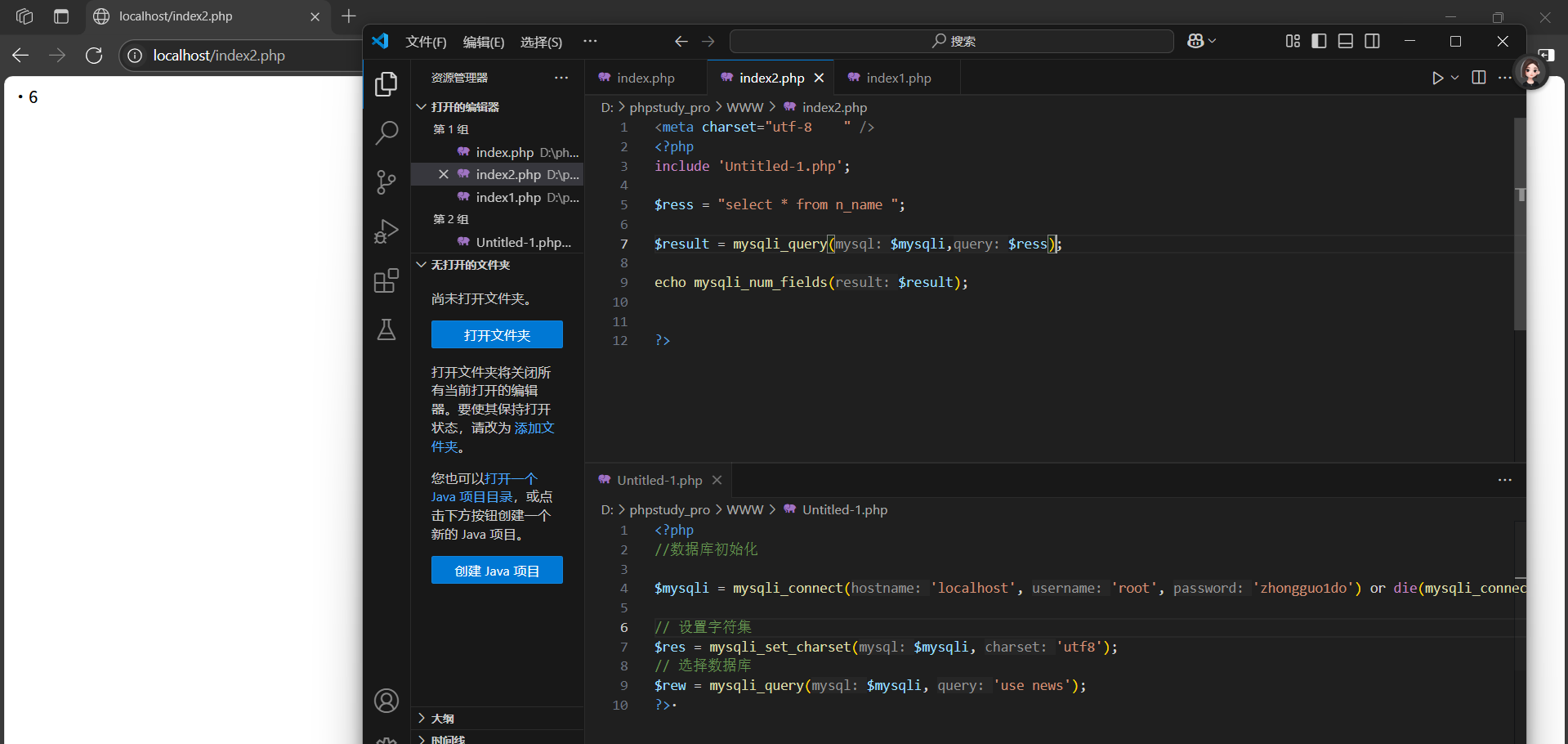
常用相關函數:
mysqli_num_fields(變量):
獲取一個指定結果種所有的字段數
mysqli_fetch_field_direct():
函數返回的是一個 stdclass對象(代表字段元數據 )
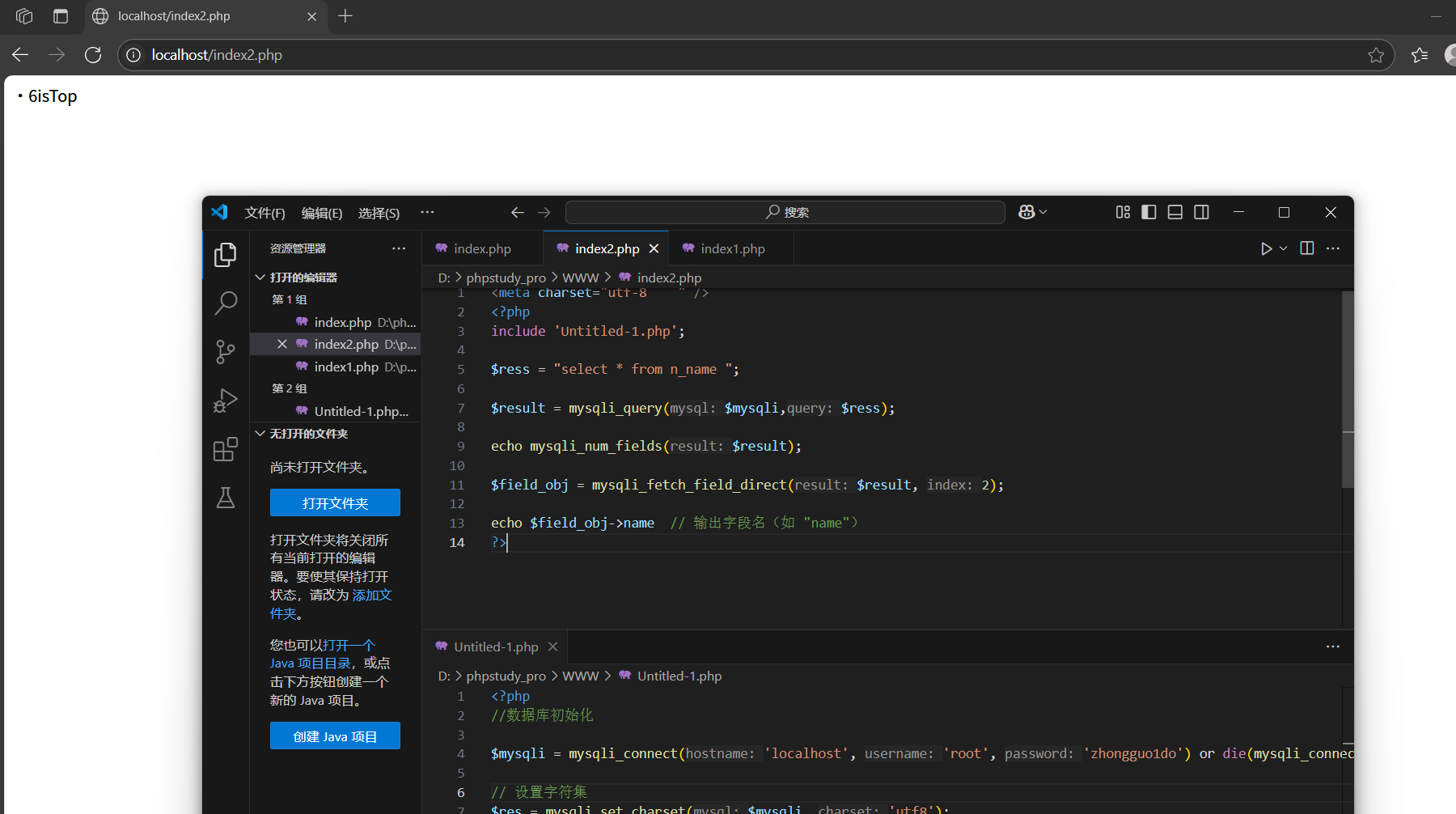
有關出錯信息:
mysqli_error(變量):
獲取出錯對應的提示信息
mysqli_errno(變量):
獲取出錯對應的錯誤提示代號
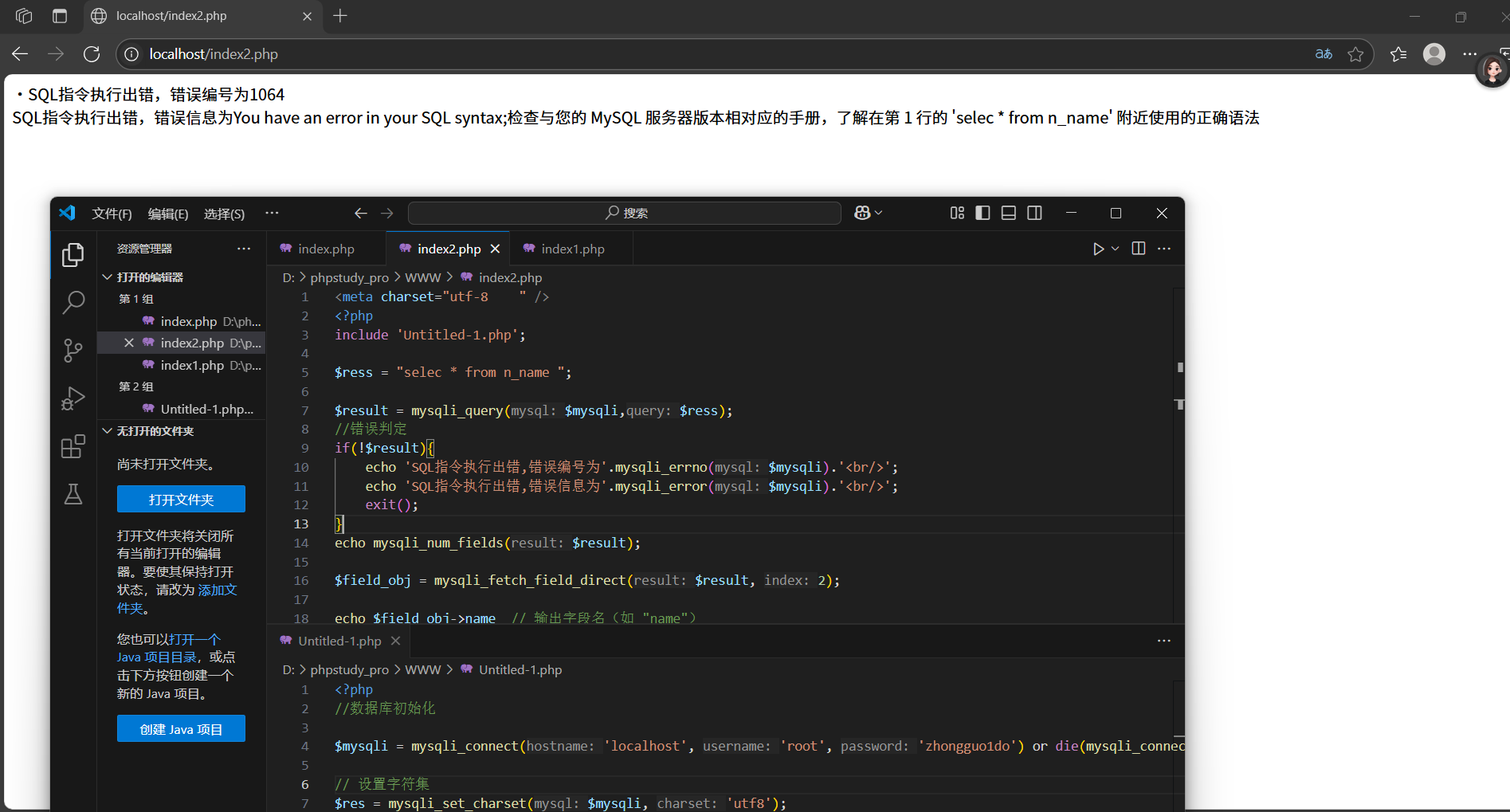
錯誤的判斷:基于Mysql_query這個函數執行的結果,結果返回false就代表執行錯誤
其他函數:
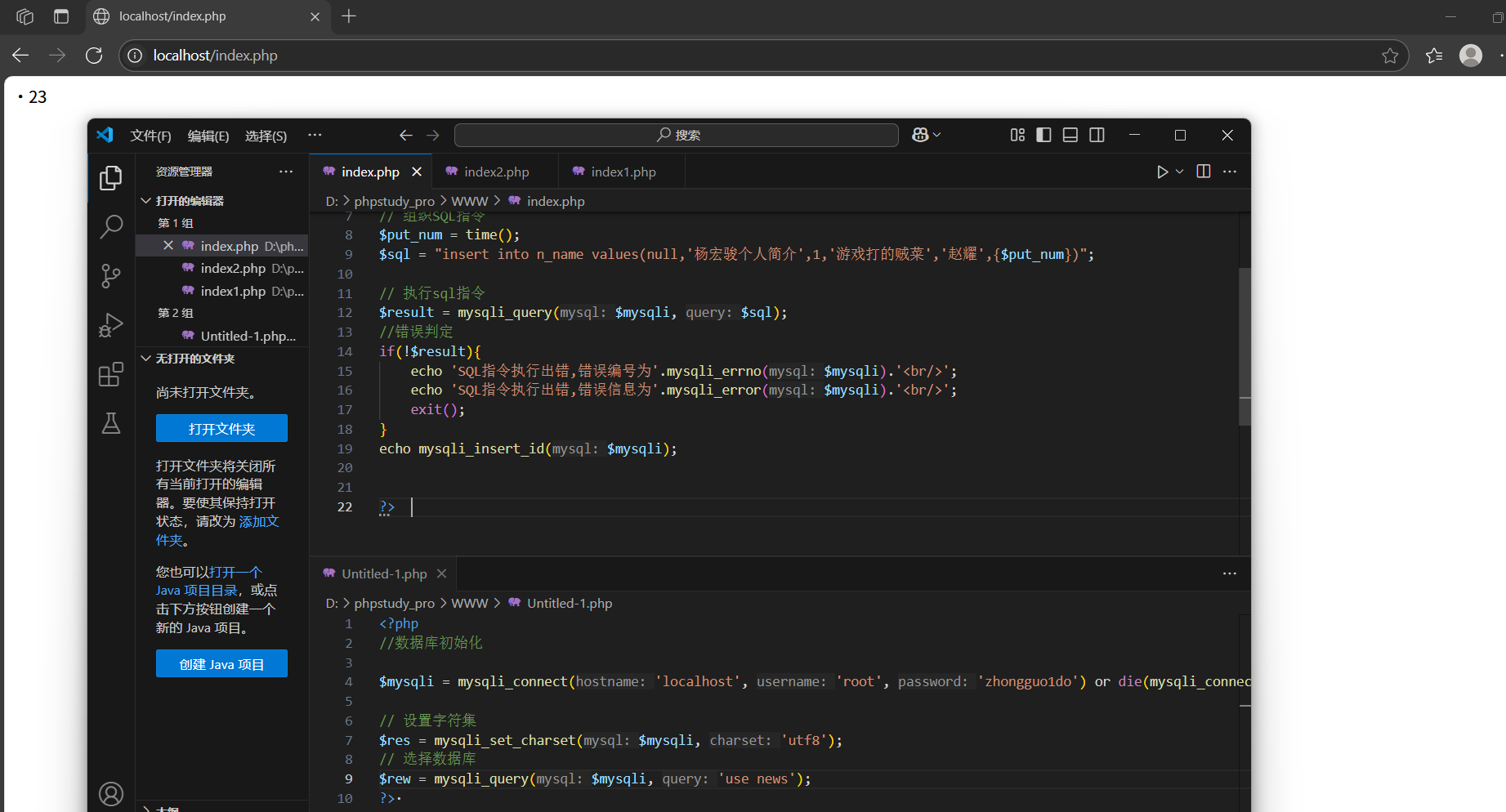
mysqli_insert_id():
獲取上次插入操作所產生的自增長ID,如果沒有自增長ID就返回0
HTTP協議:
HTTP協議概念:
HTTP協議,即超文本傳輸協議。是一種詳細規定了服務器和萬維網服務器之間相互通信的規則,通過因特網傳送萬維網文檔的數據傳送協議。
HTTP協議是用來從www服務器傳輸超文本到本地瀏覽器的傳送協議。它可以使服務器更加高效,使網絡傳輸更少.它不僅保證計算機正確快速的傳輸超文本文檔,還確定了傳輸文檔的哪一部分,已經哪一部分內容首先顯示(如文本先于圖形)等.
HTTP協議特點:
1.客戶/服務器模式:客戶端(瀏覽器)服務端
2.簡單快速:客戶向服務器請求服務時,只需傳送請求方法和路徑。由于HTTP協議簡單,
使得HTTP服務器的程序規模小,因而通信速度很快。
3.靈活:HTTP允許傳輸任意類型的數據對象
4.無連接:無連接的含義是限制每次連接只處理一個請求。服務器處理完客戶的請求,并
收到客戶的應答后,即斷開連接。采用這種方式可以節省傳輸時間。
5.無狀態:HTTP協議是無狀態協議。無狀態是指協議對于事務處理沒有記憶能力。缺少狀
態意味著如果后續處理需要前面的信息,則它必須重傳,這樣可能導致每次連接傳送的數據
量增大。另一方面,在服務器不需要先前信息時它的應答就較快。·
HTTP協議分類:
HTTP請求協議:瀏覽器向服務器發起請求的時候需要遵循的協議
HTTP響應協議:服務器向瀏覽器發起響應的時候需要遵循的協議
HTTP請求:
請求行:
形式:請求方式 資源路徑 協議版本號
GET/index.php HTTP1.1
請求行獨占一行(第一行 )
請求頭:
請求頭就是各種協議內容,具體的協議內容不會每次都使用全部
1.Host:請求的主機地址( 必須 );
2.Accept:當前請求能夠接收服務器返回的類型(MIME類型);
3.Accept-Language:接收的語言;
4.User-Agent:客戶服務器所在點的一些信息
注:請求頭不固定數量,每個請求協議也是獨占一行,最后會有一行空行(用來區分)
請求體:
請求數據:POST請求會有請求體.GET請求所有的數據都是跟在URL之后的,會在請求行中的資源路徑上體現.
基本格式:資源名字=資源值&&資源名字=資源值……
HTTP響應:
響應行:
1.形式:協議版本號 狀態碼 狀態信息(獨占一行)
HTTP/1.1 200 ok;
2. 200 ok:成功;
3. 403 Forbidden: 沒權限訪問;
- 404 Not Found:未找到頁面;
5. 500 Server Internal Error: 服務器內部錯誤;
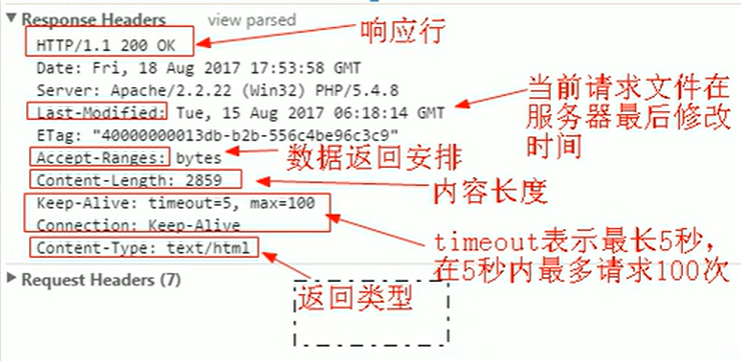
響應頭:
具體協議內容:
- 時間:web,16 Sep 2017 11:43:33 GMT
- 服務器: Server: Apache/2.2.22 (win32) PHP/5.3.13
- 內容長度:Content-Length:1571,數據具體的字節數(響應體);
- 內容類型:Content-Type:text/html:告訴瀏覽器對應的數據格式
列舉了幾個常見的響應頭,并不是:響應頭一個占一行
響應體:
實際服務器響應給瀏覽器的內容
常用HTTP狀態碼:
狀態碼 200 :成功
狀態碼 403 :forbidden,拒接訪問(沒有權限)
狀態碼 404 : NOT FOUND , 找不到(客戶端出錯了)
狀態碼 500 :服務器問題
1XX:
服務器正在處理中:

2XX:
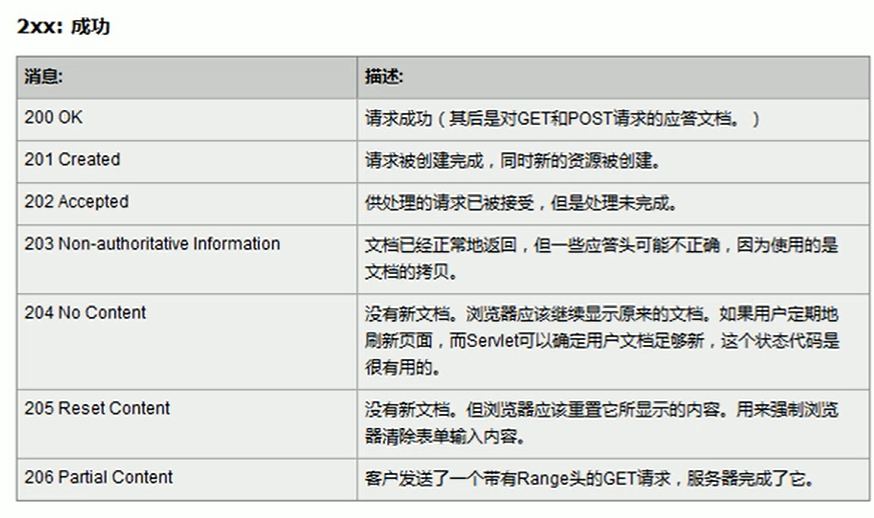
3XX:
請求的目標已經轉移或者需要更新:
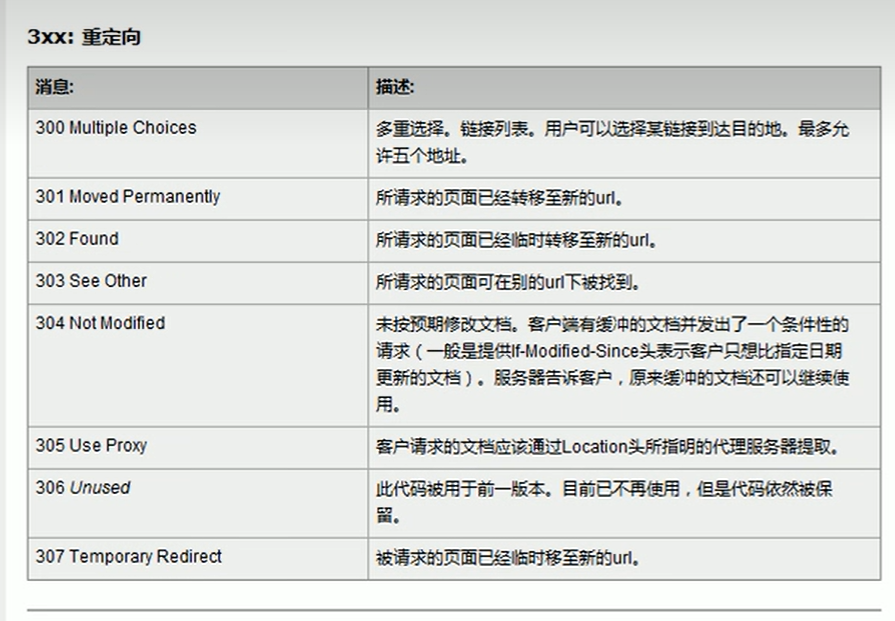
4XX:
客戶端(服務器)出錯了

5XX:
服務器錯誤
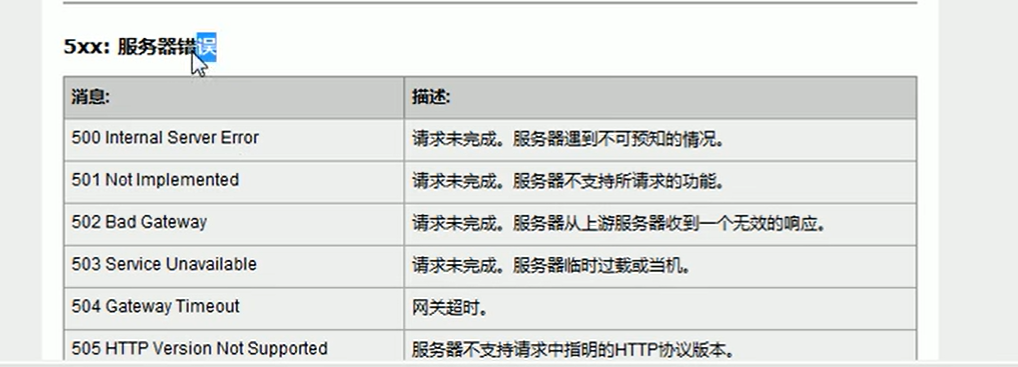
常見HTTP響應設置及使用:
PHP中針對HTTP協議(響應)進行了底層設計,可以通過函數header來實現修改HTTP響應(響應頭)
注意事項:
1、Header可以設計HTTP響應,因為HTTP協議特點是:響應行,響應頭(空行結尾),響
應體。認為通過header設計響應頭的時候,不應該有任何內容輸出,所以一旦產生內容輸
出(哪怕一個空格),系統都會認為響應頭已經結束而響應體開始了,所有如果先輸出內容
后設置響應頭(header使用),理論設置無效;
2、在PHP5以后,增加程序緩存內容:允許服務器腳本在輸出內容的時候,不直接返回劉
覽器而是先在服務器端使用程序緩存保留(php.ini中使用output buffering),有了該內容之
后,在程序緩存內會自動調整響應頭和響應體(允許響應頭在已經輸出的內容之后再設置),
但是此時會報錯(警告)。
總結:header設置響應體之前不要有任何輸出
location:重定向,立即跳轉(響應體不用解析)
瀏覽器在解析服務器響應的時候:先判定響應行,繼續響應頭,最后響應體:location是在響應頭中,所有瀏覽器一旦見到該協議項,不再往下解析.
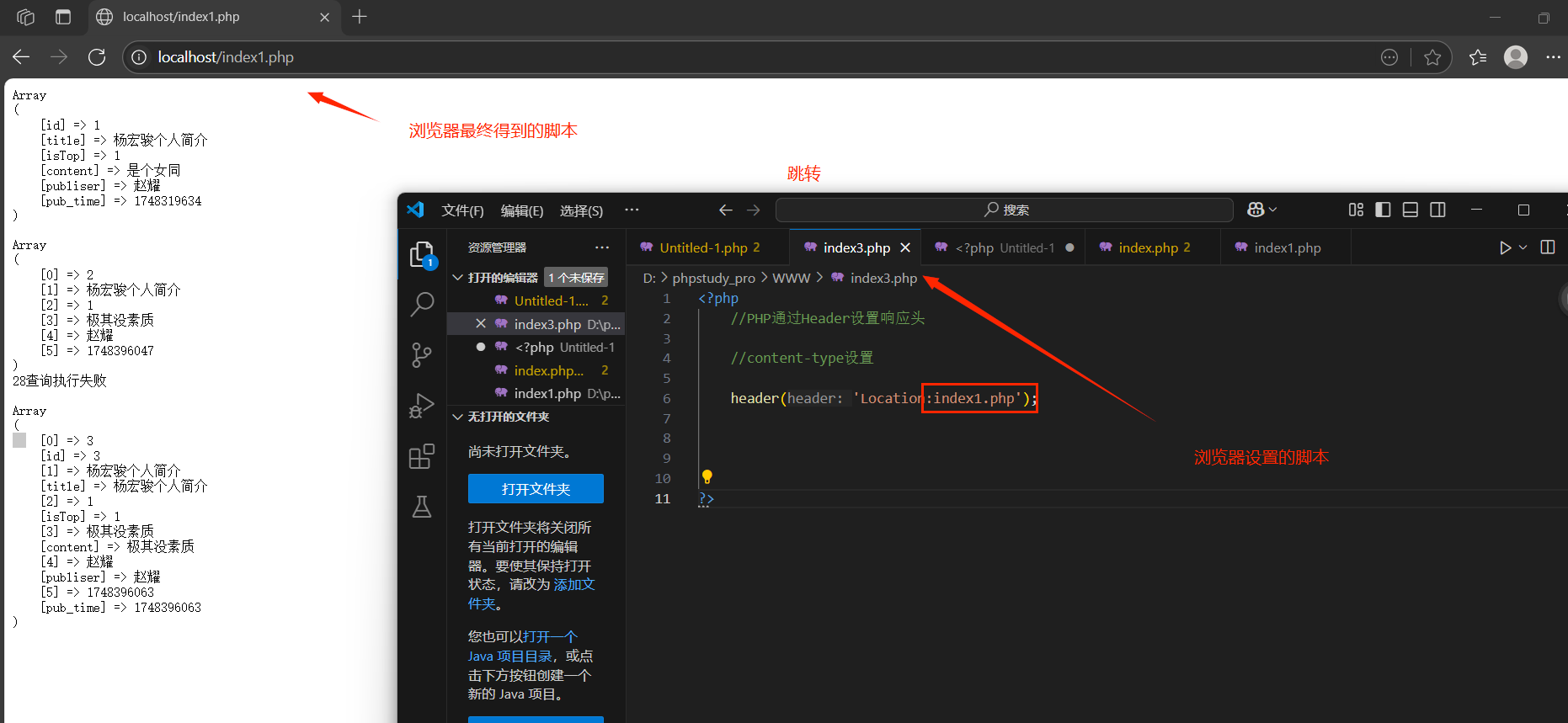
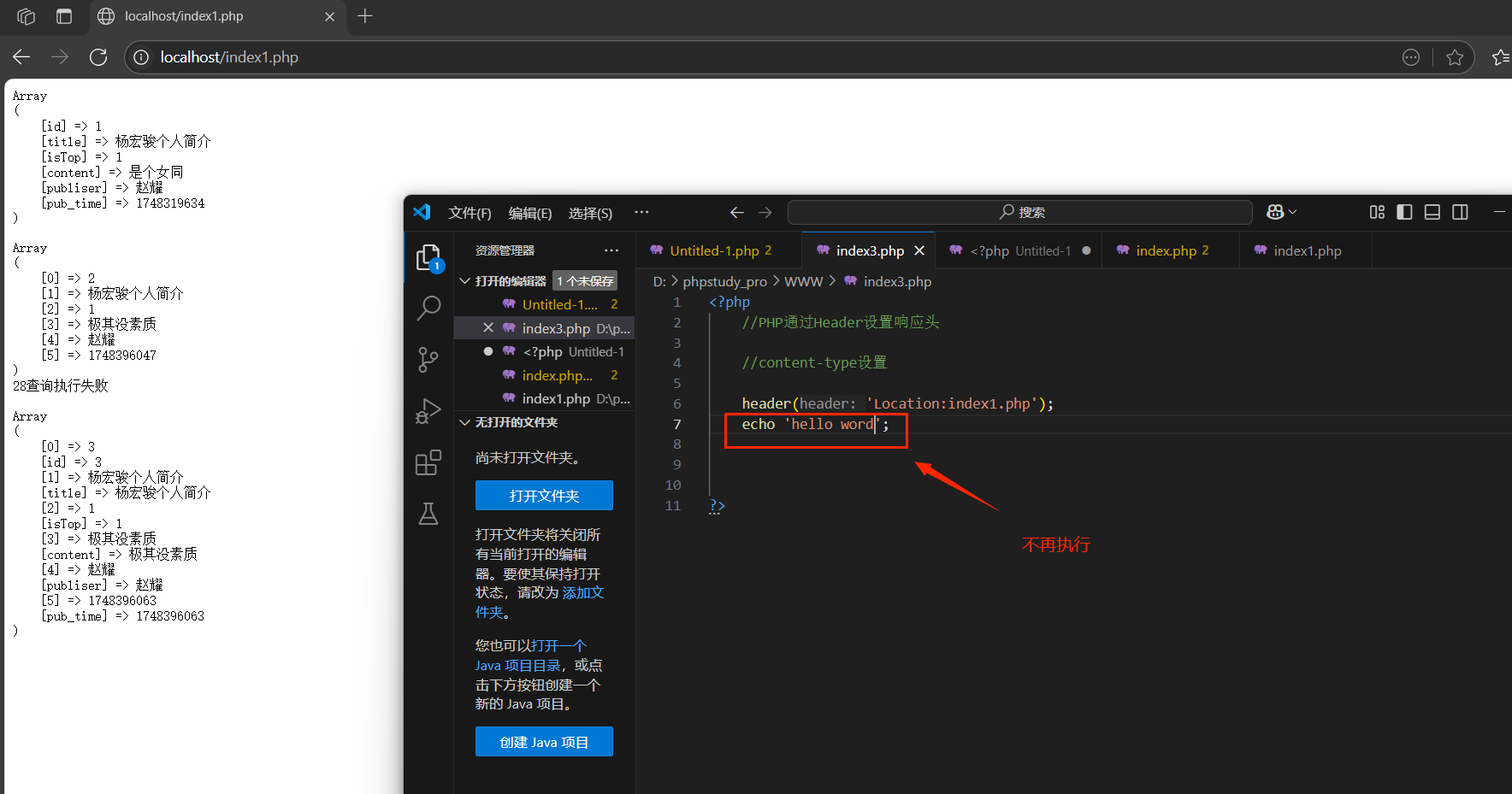
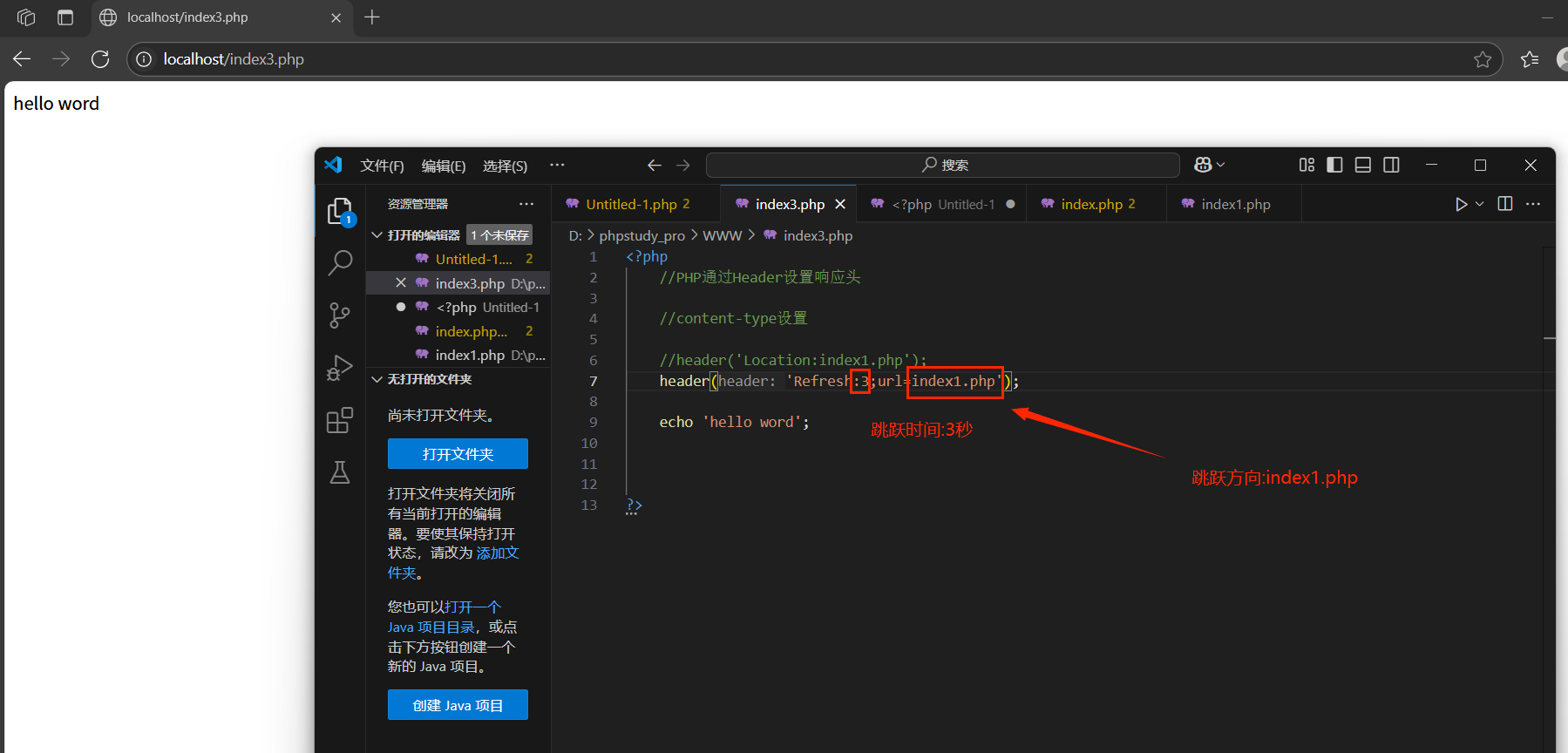
Refresh:重定向,定時跳轉(響應體會解析)
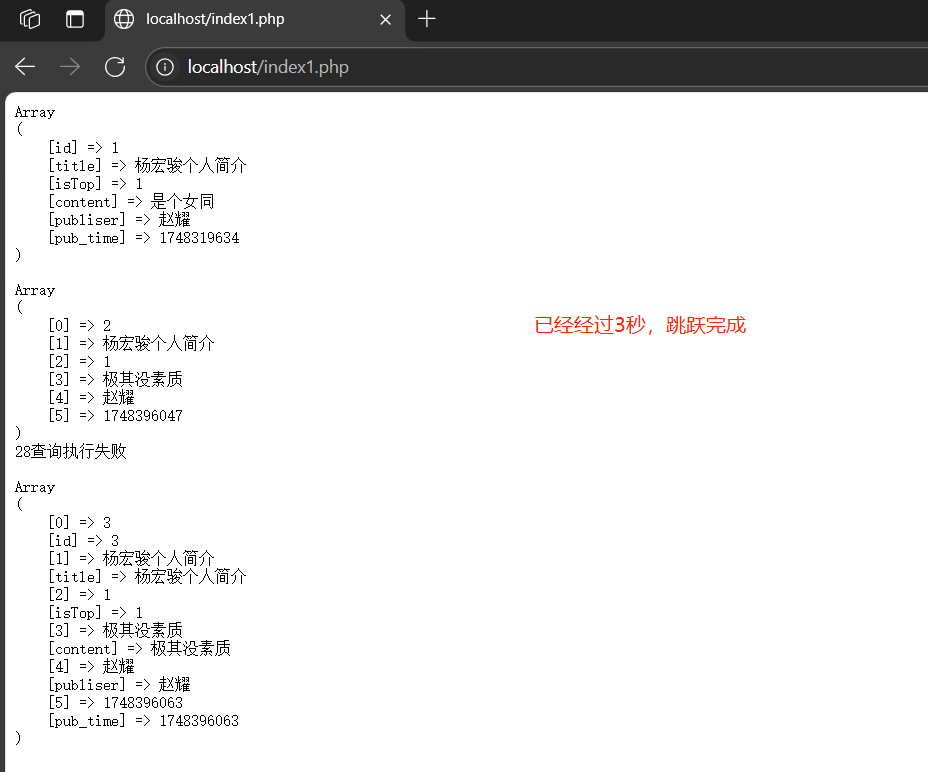
延時重定向,瀏覽器會根據具體時間延遲后在訪問指定跳轉鏈接:瀏覽器在準備跳轉訪問之前,會繼續解析HTTP協議(響應頭和響應體)
Content-type:內容類型,MIME類型
通過內容告知(MIME類型),瀏覽器正確解析內容
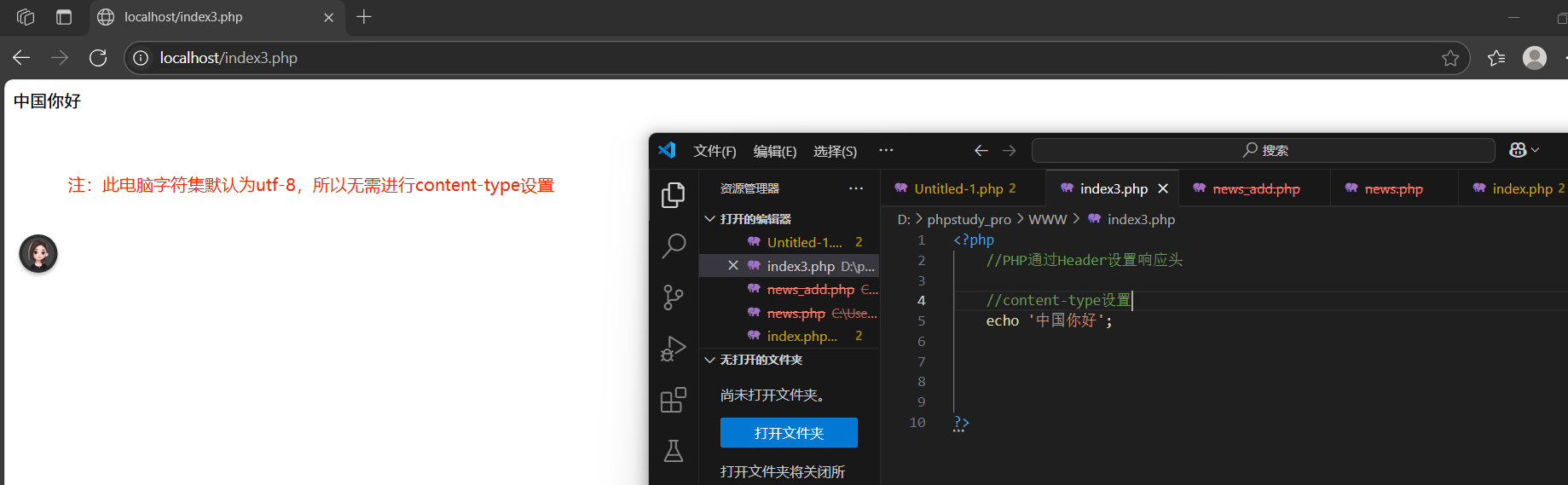
轉換后:
content-disposition: 內容類型,MIME類型擴展,激活瀏覽器文件下載對話框
瀏覽器在解析內容的時候,默認是直接解析,那么有時候需要瀏覽器不解析,當做一個內容下載成文件

點擊后立馬下載成功:
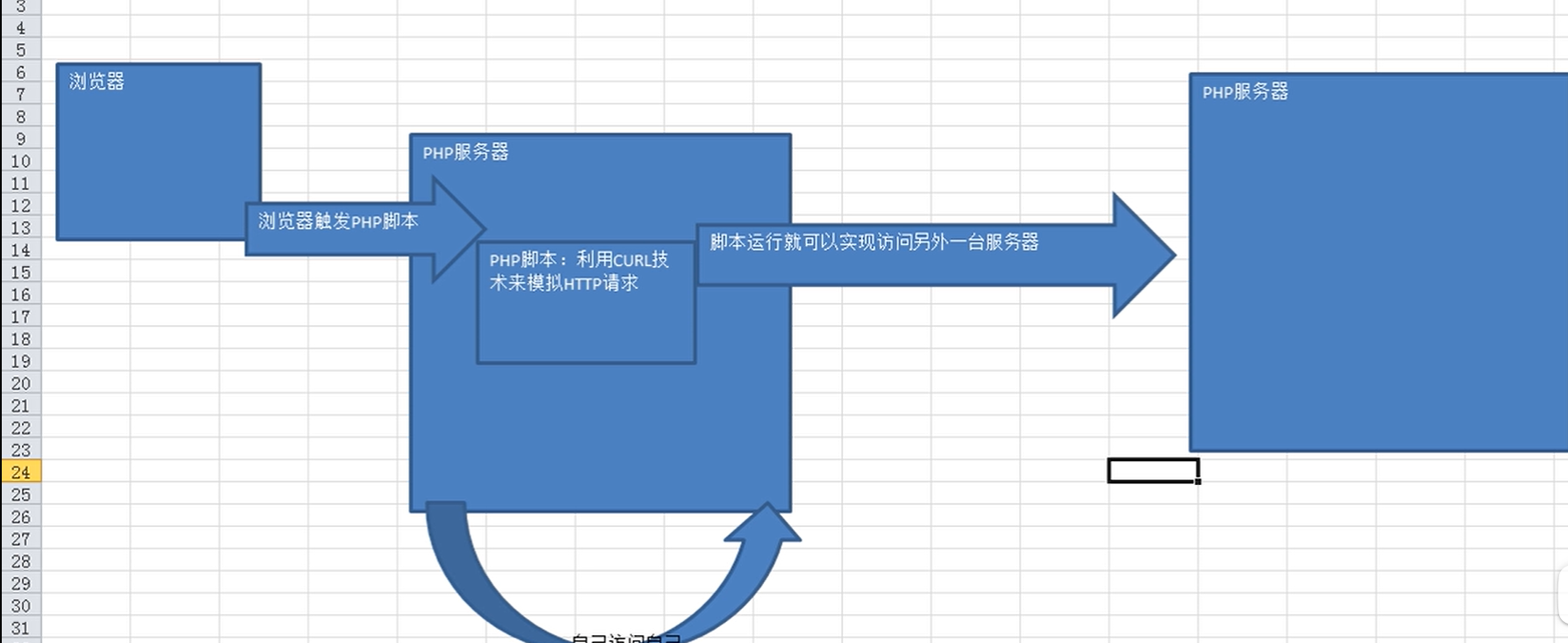
PHP模擬HTTP請求:
原理:
PHP可以通過模擬HTTP協議發起HTTP請求
CURL是一個非常強大的開源庫,支持很多協議,包括HTTP、FTP、TELNET等,我們使用它
來發送HTTP請求。它給我們帶來的好處是可以通過靈活的選項設置不同的HTTP協議參數,
并且支持HTTPS。CURL可以根據URL前綴是“HTTP”還是“HTTPS”自動選擇是否加密發
送內容。
前提條件:HTTP協議的客戶端/服務端模式,HTTP協議不局限于一定要刻覽器訪問
curl擴展庫使用:
1.建立連接:curl_init():激活一個curl連接功能
2.設置請求選項:
基本語法:Curl_setopt(變量,操作,文件地址):設定(連接)選項
//文件地址也可以寫成布爾類型,意為文件流形式返回數據(不直接顯示)
操作:
curlopt_url:連接對象
curlopt_returntransfer:將服務器執行的結果(響應)以文件流的形式返回請求界面(php腳本)

curlopt_post:是否才有post方式發起請求(默認請求時GET)
curlopt_postfields:用來傳遞post提交的數據,分為兩種方式:字符串(name=abc&password=123),
以及數組形式(array('name'=>'abc',……))
curlopt_header:是否得到響應的header信息(響應頭),默認不獲取。
3.執行請求:curl_exec():執行選項(與服務器發起請求),得到服務器返回的內容
4.關閉請求:curl_close():關閉資源
文件編程:
文件編程的必要性:
文件編程指利用PHP代碼針對文件(文件夾)進行增刪改查操作.
在實際開發項目中,會有很多內容(文件上傳,配置文件等)具有很多不確定性,不能在一開始就手動的創建,需要根據實際需求和數據本身進行管理,這個時候就可以使用PHP文件編程來實現代碼批量控制和其他操作
文件編程的分類:
1.目錄操作:文件夾,用來存放文件的特殊文件
2.文件操作:用來存放內容
路徑操作(增刪改查):
目錄操作:
文件操作創建目錄結構:
1.mkdir(路徑名字):創建成功返回true,創建失敗返回false
//一般來說創建失敗的原因有2
1.路徑錯誤
2.已有該文件
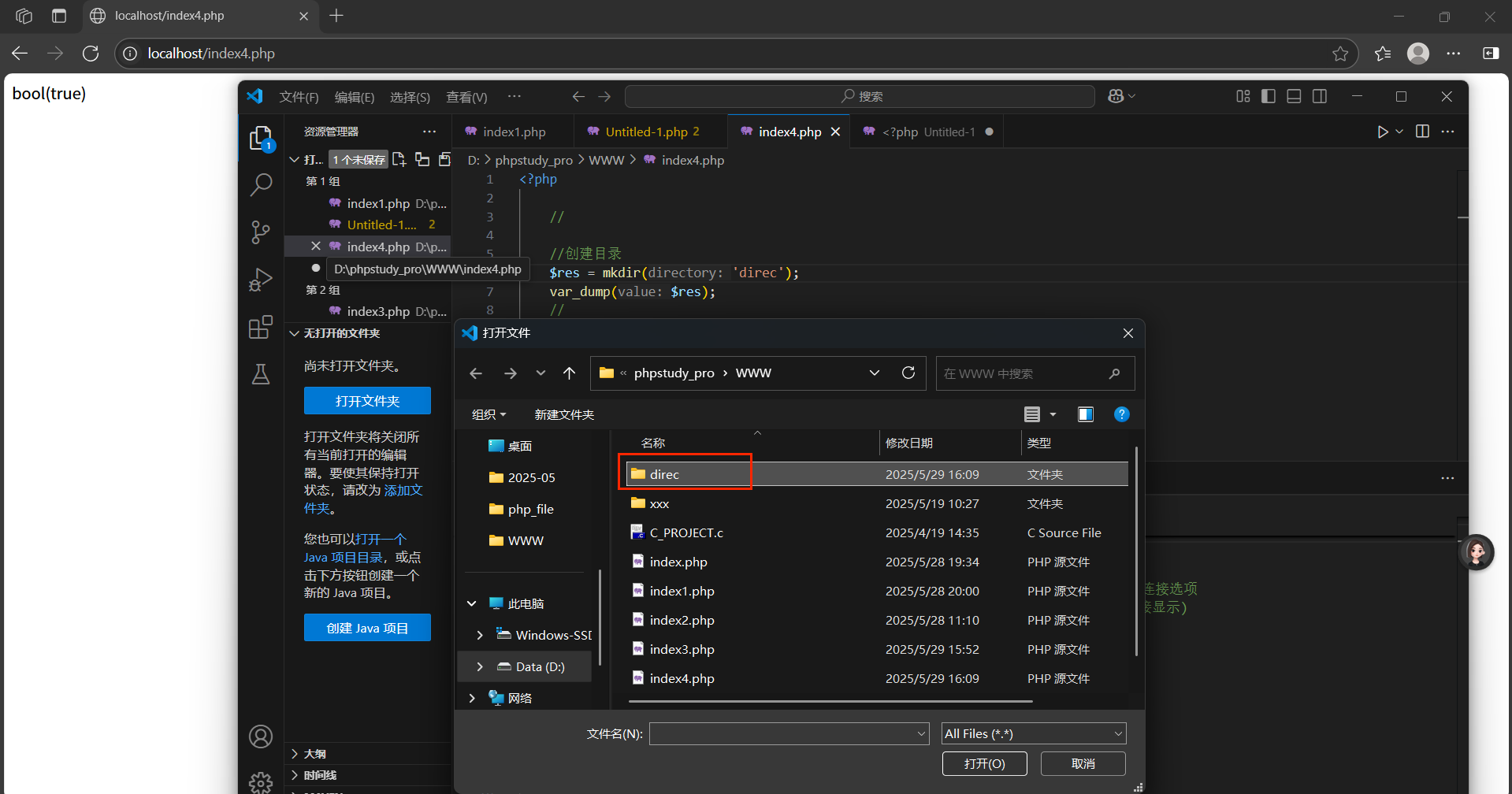
錯誤:
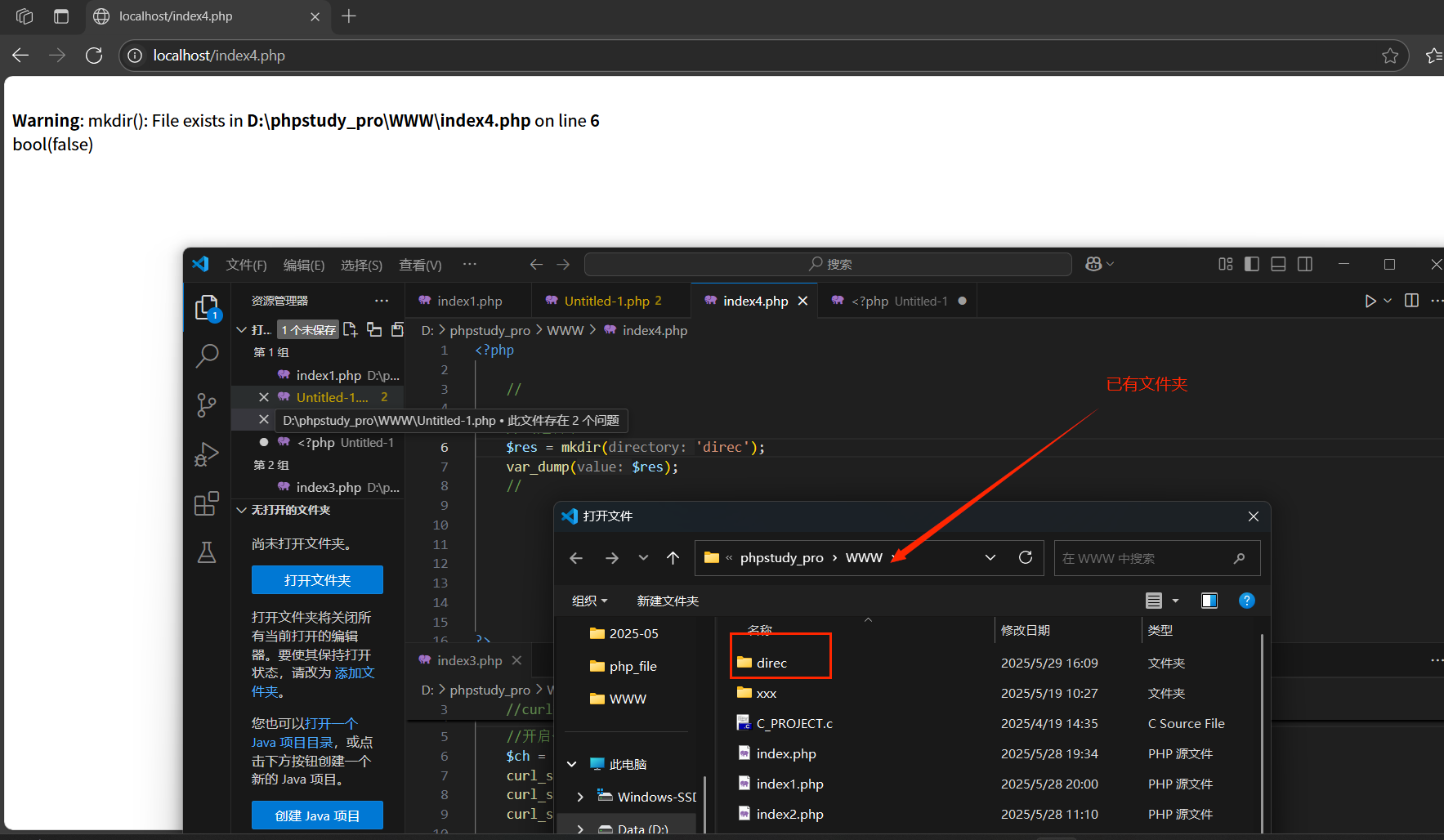
應該加上錯誤抑制符:@
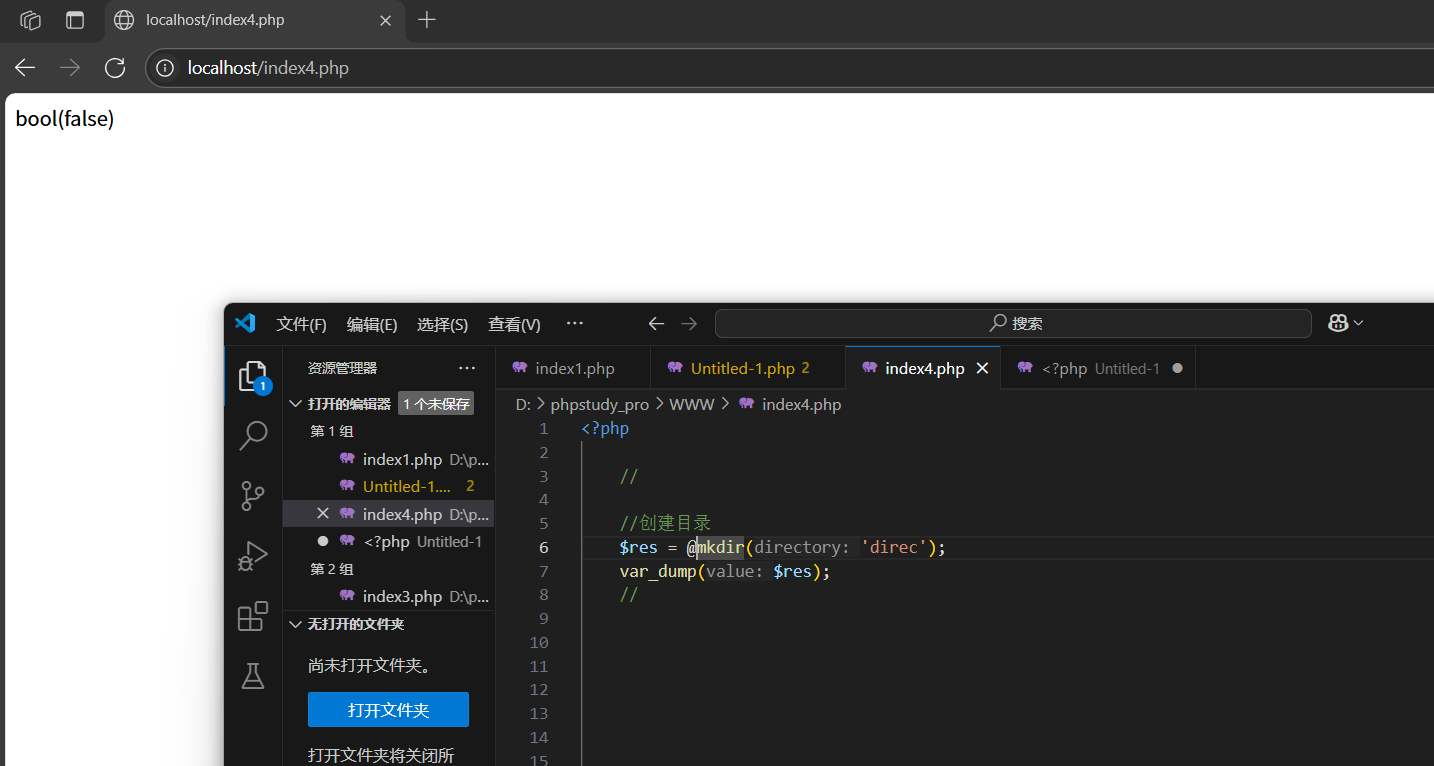
刪除操目錄:
rmdir(指定文件夾目錄):移出文件夾
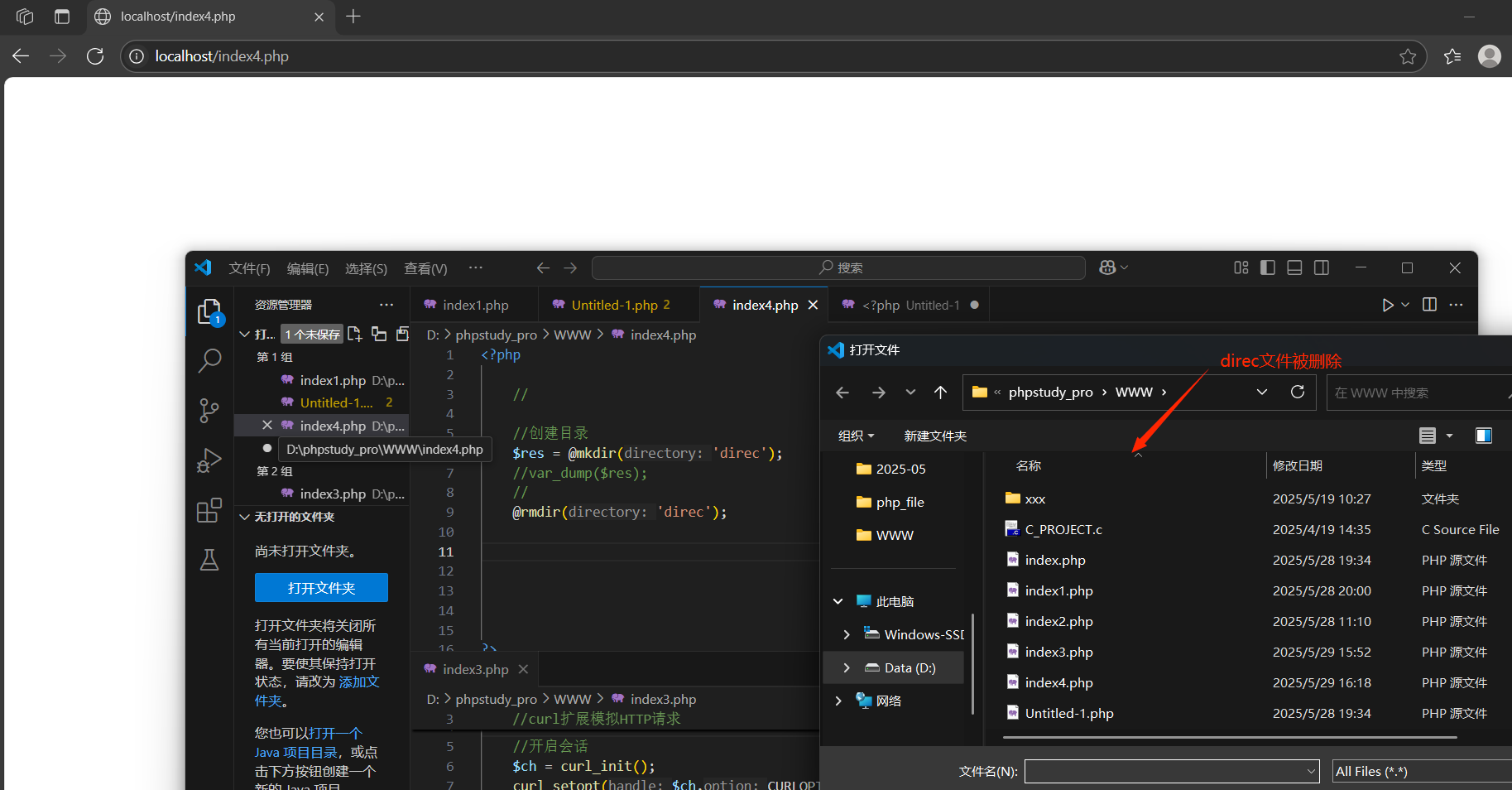
讀取目錄:
讀取方式:將文件夾(路徑)按照資源方式打開
1.opendir():打開資源,返回一個路徑資源,包含指定目錄下的所有文件(文件夾);
2.readdir():從資源中讀取指針所在位置的文件名字,然后指針下移,直到指針移出資源
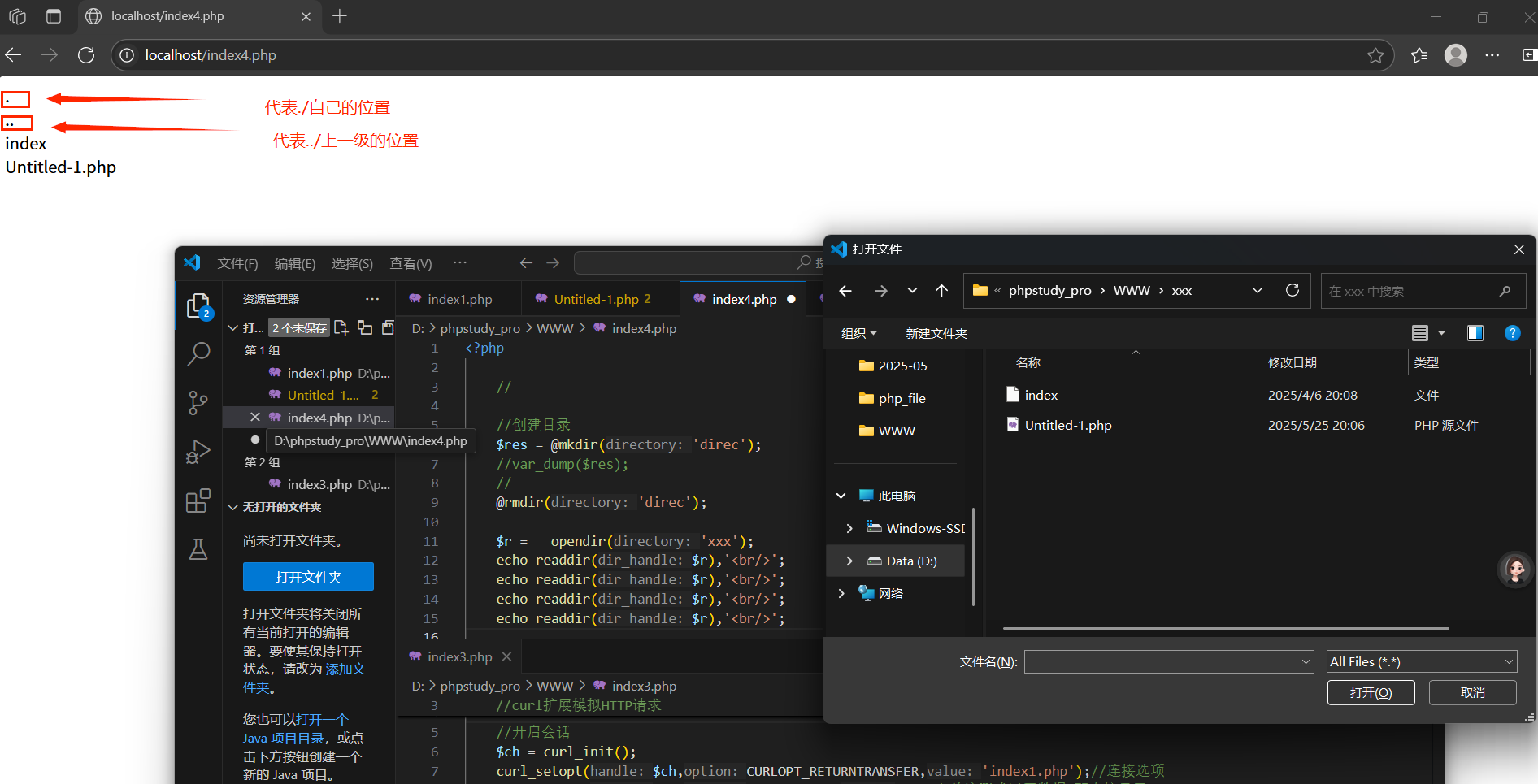
又或者循環遍歷:
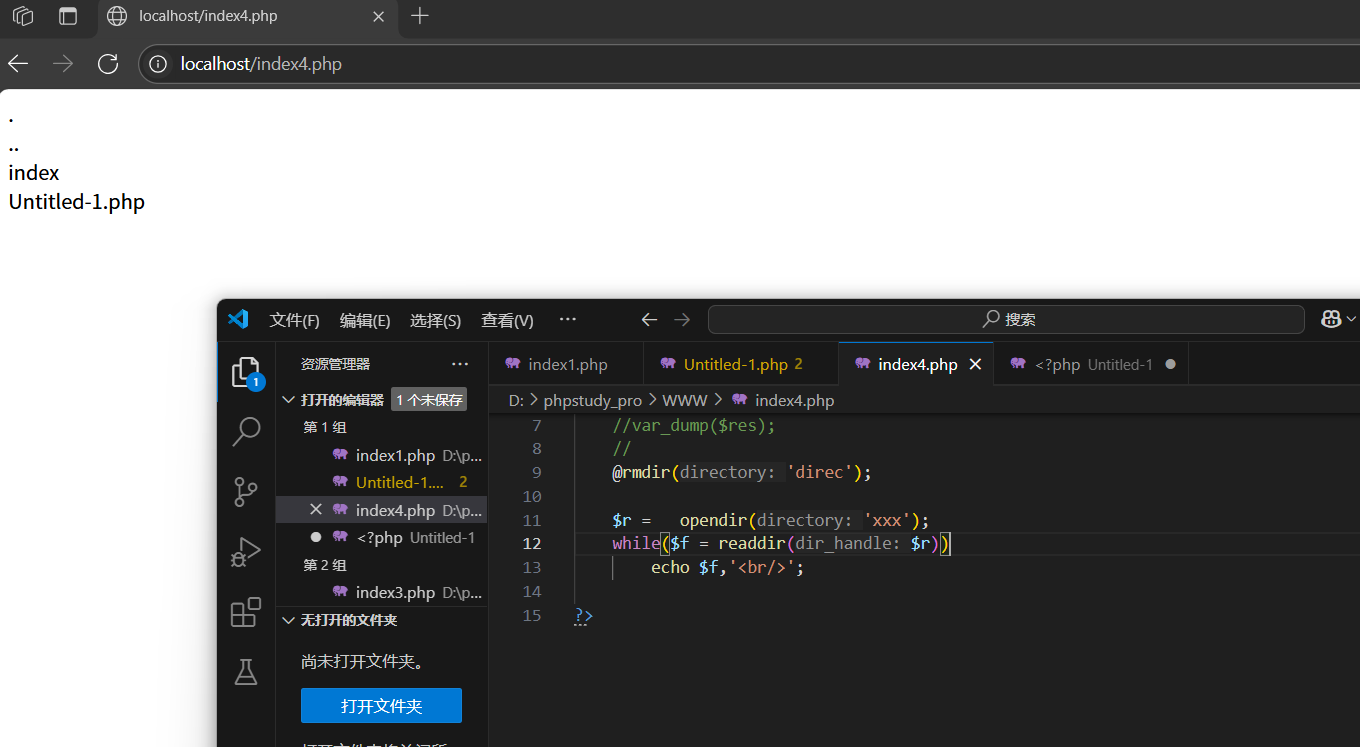
如果已經沒有資源了,再往下就不會在運行了:
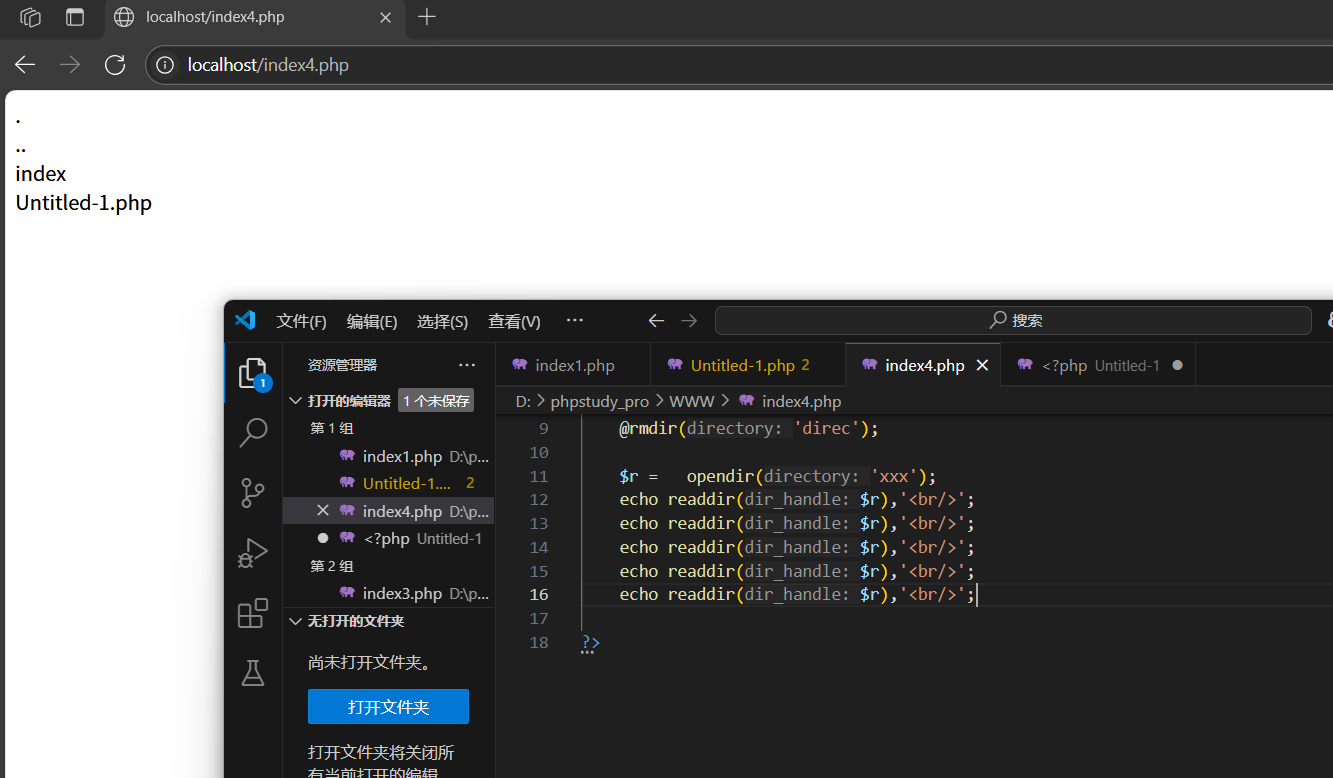
關閉目錄:
closedir():關閉資源
其他目錄操作:
1.dirname(一個路徑):得到的是路徑的上一層路徑
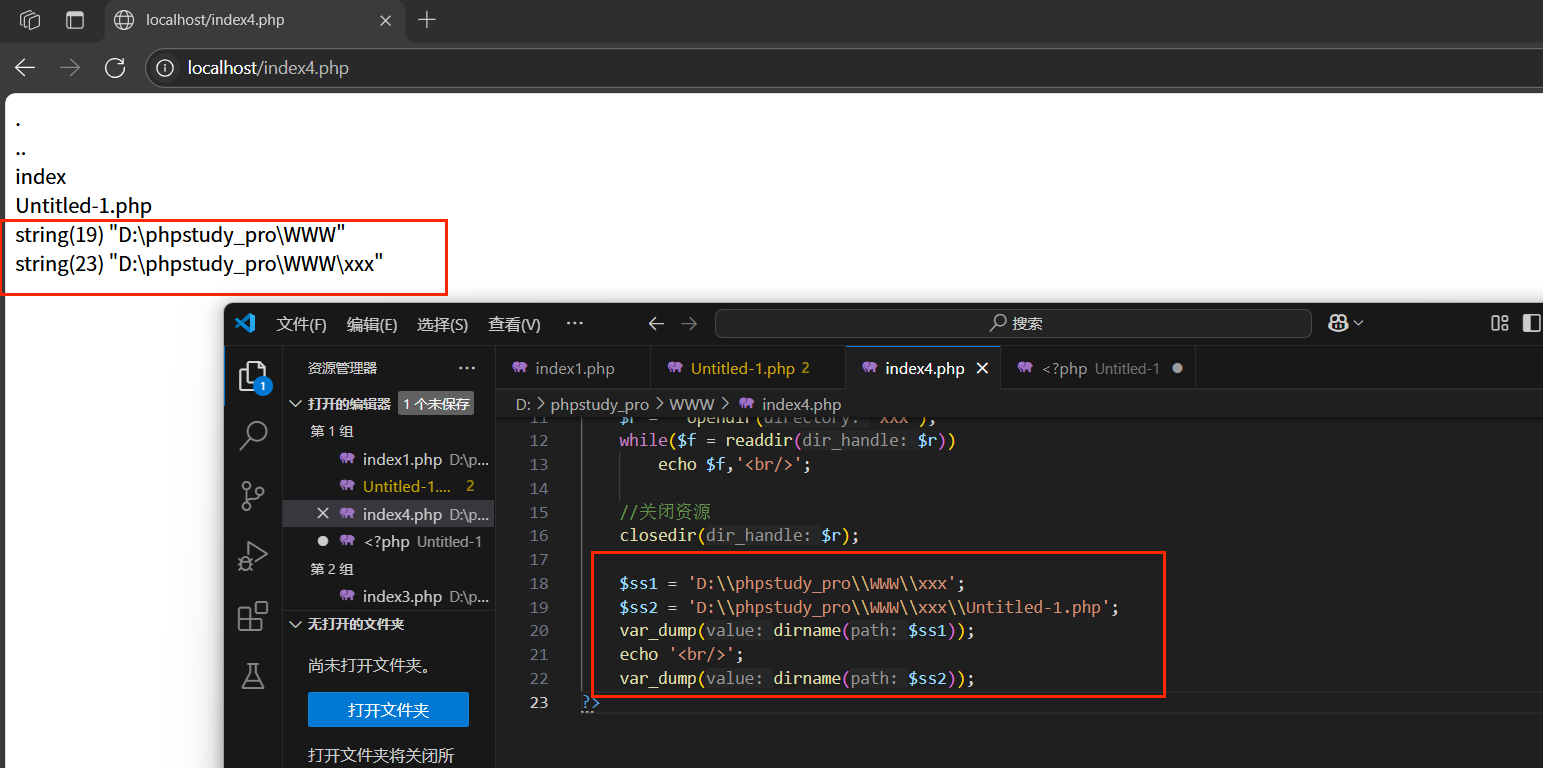
2.realpath(一個路徑/文件):得到真實的路徑信息(目錄路徑)
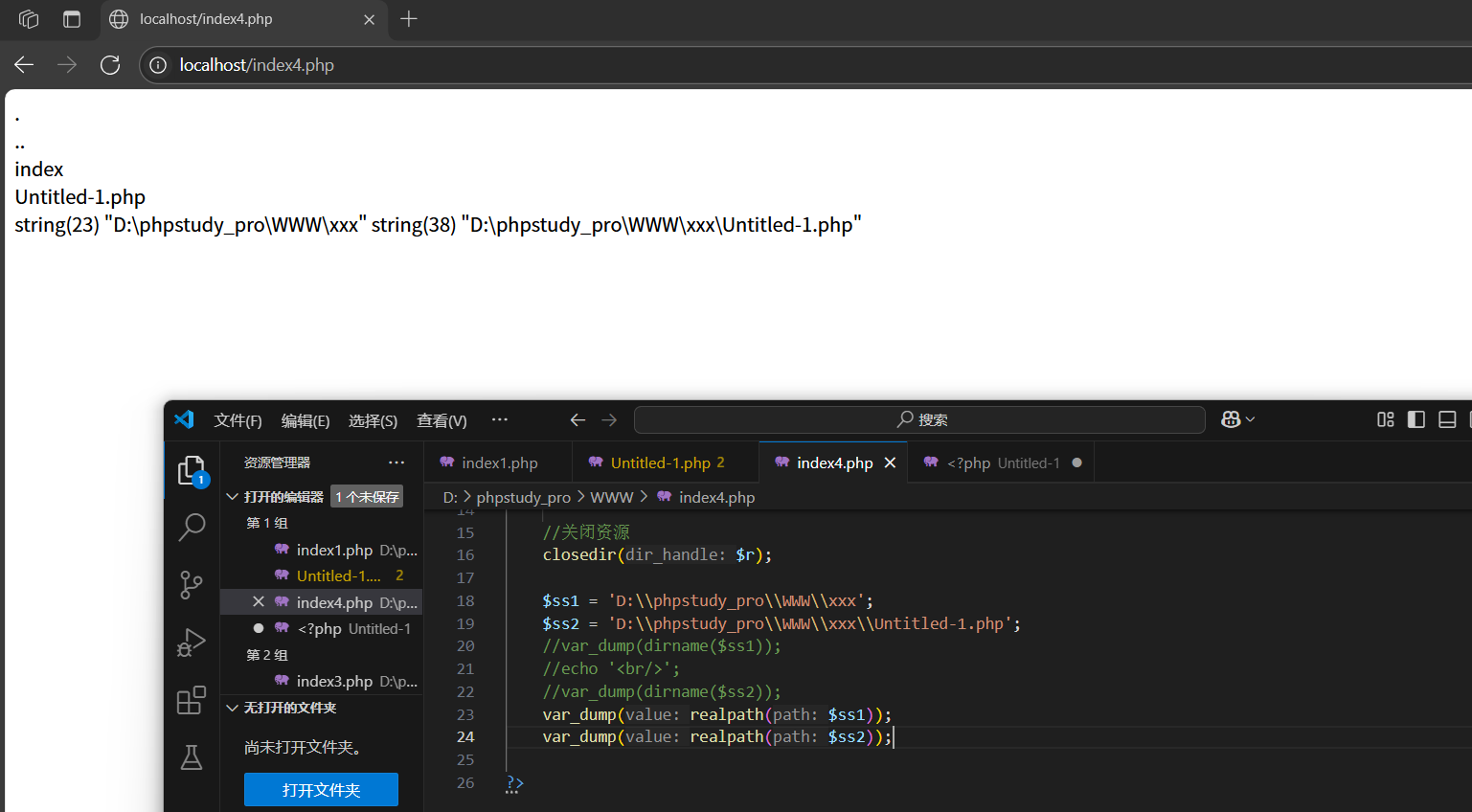
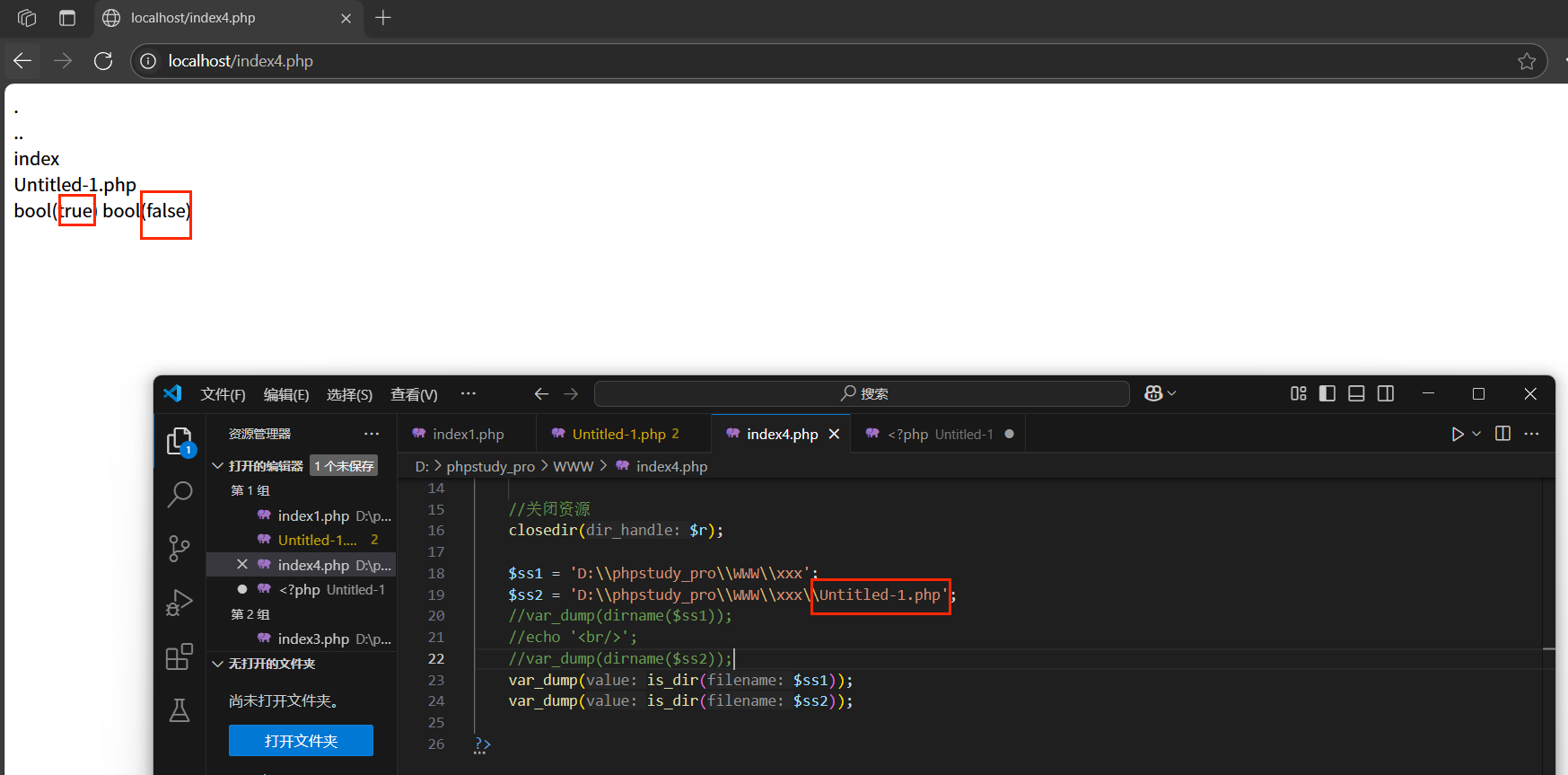
3.is_dir(一個路徑):判斷指定路徑是否是一個目錄
同理,如果是文件,結果也是false
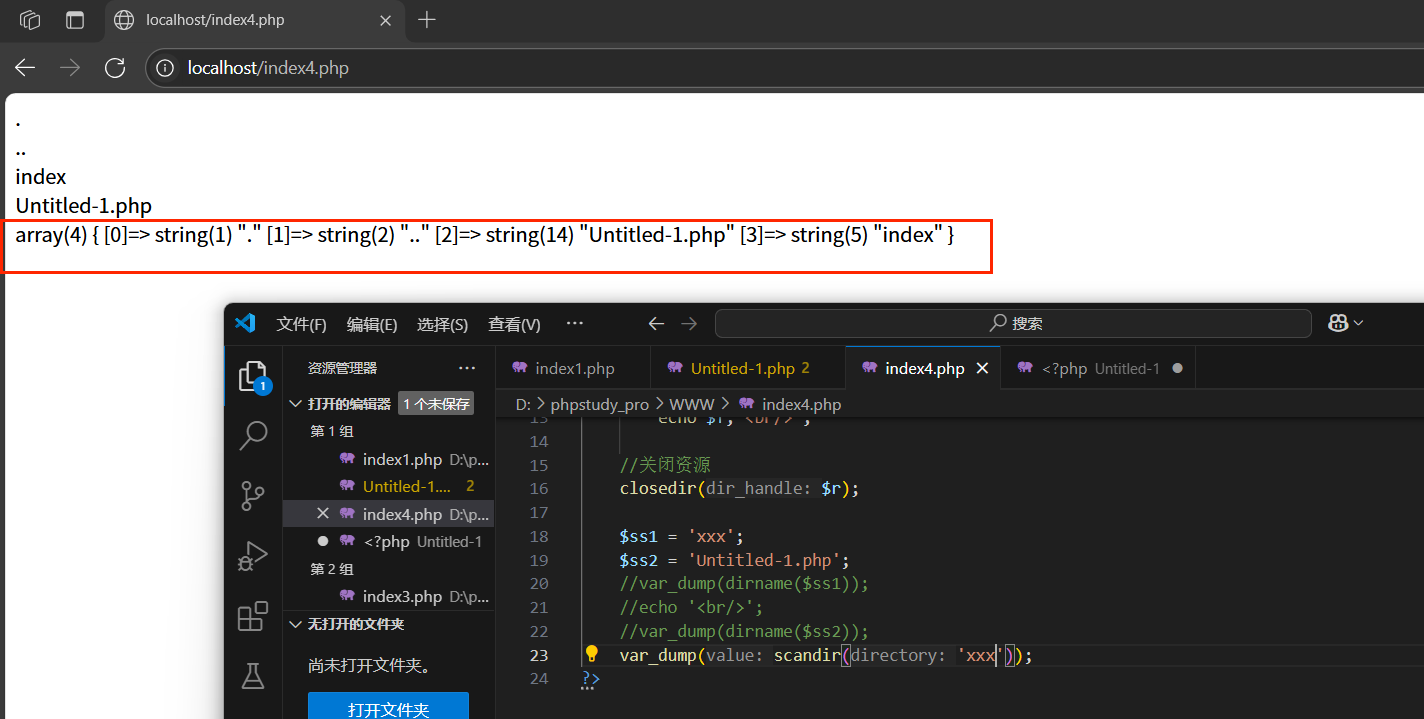
4.scandir():
封裝版的opendir/readdir/closedir,獲取一個指定路徑下的所有文件信息(第一層),以數組的形式返回
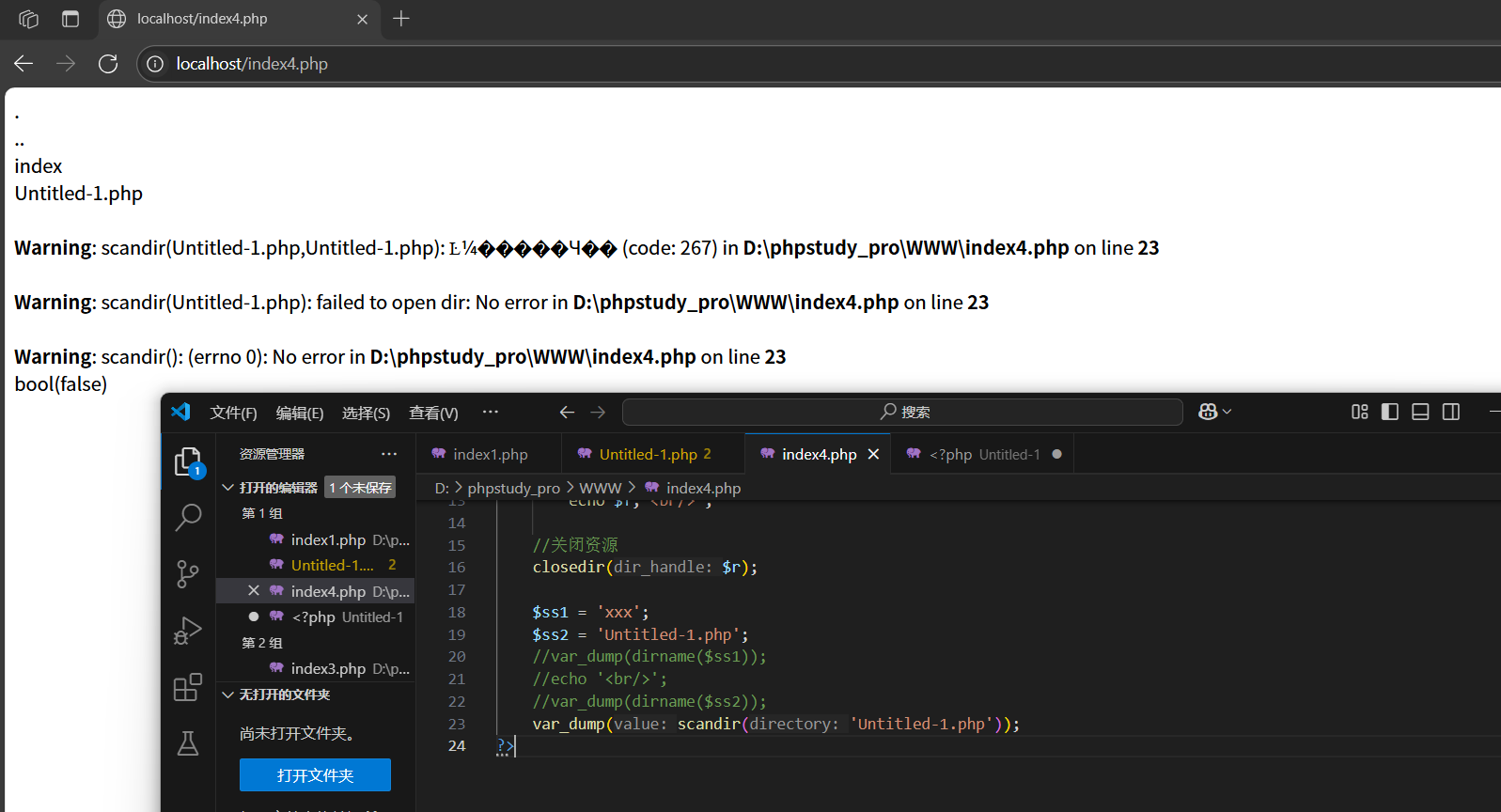
文件的形式就會報錯:
遞歸遍歷目錄:
遞歸遍歷目錄:指定一個目錄的情況下,將其下所有的目錄和文件,及其目錄內容的所有內容都輸出出來。
遞歸遍歷目錄:指定一個目錄的情況下,將其下的所有文件和目錄,及其目錄內部的所有內容都輸出出來。
遞歸算法:將大問題切成相似的小問題(最小單位),然后可以調用解決大問題的方法來解決小問題。
遞歸函數:函數如果自己內部調用自己,該函數稱之為遞歸函數。
遞歸遍歷目錄的思維邏輯:
1.設計一個能夠遍歷一層文件的函數:
a.創建函數
b.安全判定:是路徑才訪問
c.讀取全部內容,遍歷輸出
2.找到遞歸,點:遍歷得到的文件是目錄,應該調用當前函數(調用自己):
a.需要構造路徑(遍歷得到的結果只是文件的名字)
b.需要注意除 “ . ” 和“ .. ”;
3、找到遞歸出口:遍歷完這個文件夾之后,發現沒有任何子文件夾(函數不再調用自己)
foreach自帶遞歸出口
結果:
4、如問顯示層級關系?
函數第一次運行遍歷的結果是最外層目錄,內部調用一次說明進入一個子目錄,子目錄再調用一次函數進行孫子目錄如果能夠在第一次調用的時候給個標記,然后在進入的時候,通過標記的變化來識別層級關系,就可以達到目的:該標記還能代表層次關系:縮進。
a.在函數參數中增加一個標記:默認值為0
b.遞歸調用的時候也需要使用該參數:但是是屬于當前層級的子級,所以+1
c.根據層級縮進:str_repeat()
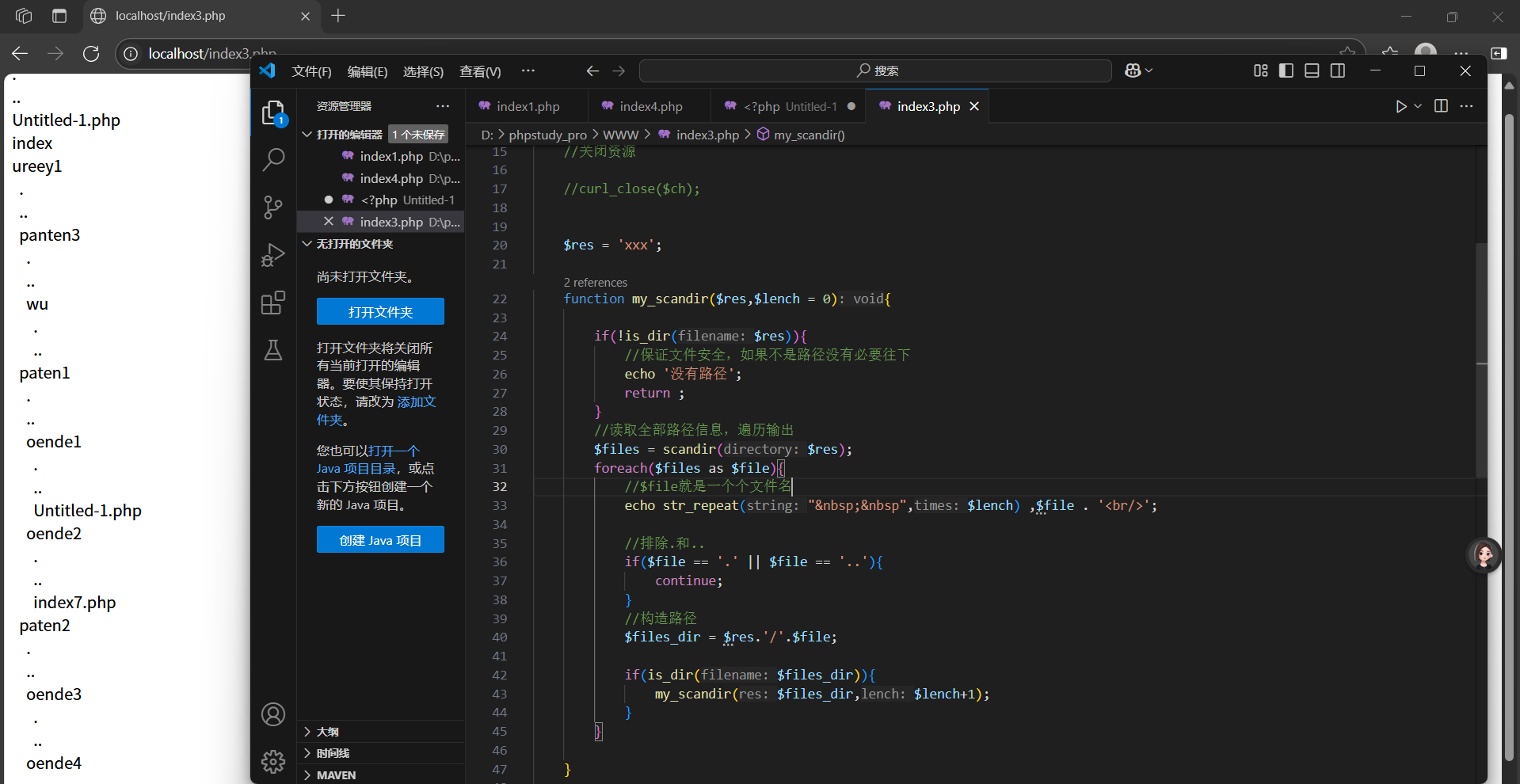
<?phpheader('Content_type:text/html;charset=utf-8');$res = 'xxx';function my_scandir($res,$lench = 0){if(!is_dir($res)){//保證文件安全,如果不是路徑沒有必要往下echo '沒有路徑';return ;}//讀取全部路徑信息,遍歷輸出$files = scandir($res);foreach($files as $file){//$file就是一個個文件名echo str_repeat("  ",$lench) ,$file . '<br/>';//排除.和..if($file == '.' || $file == '..'){continue;}//構造路徑$files_dir = $res.'/'.$file;if(is_dir($files_dir)){my_scandir($files_dir,$lench+1);}}}//測試my_scandir($res);
?>
設計知識點:
str_repeat 函數
str_repeat 是 PHP 的內置函數,作用是將指定字 符串 重復指定次數。它有兩個參數,第一個參數是要重復的字符串,第二個參數是重復的次數。在這句代碼中,str_repeat(" ",$lench) 就是將 " " 這個字符串重復 $lench 次 。
的含義
是 HTML 中的一種實體字符,代表一個空格 。在 HTML 文檔中,普通的空格在多個連續出現時,瀏覽器會自動將其合并為一個空格來顯示。而使用 可以確保每個實體字符都顯示為一個獨立的空格。這里 " " 表示兩個空格,通過 str_repeat 函數重復若干次,就能產生一定數量的空格效果。
文件操作:
常用文件操作函數:
file_get_contents(文件路徑):獲取指定文件的所有內容
如果路徑不存在,最好做安全處理
file_put_contents(文件路徑,內容):將指定內容寫入指定文件內
如果當前路徑不存在指定的文件,函數會自動創建(如果路徑不存在,不會創建路徑)
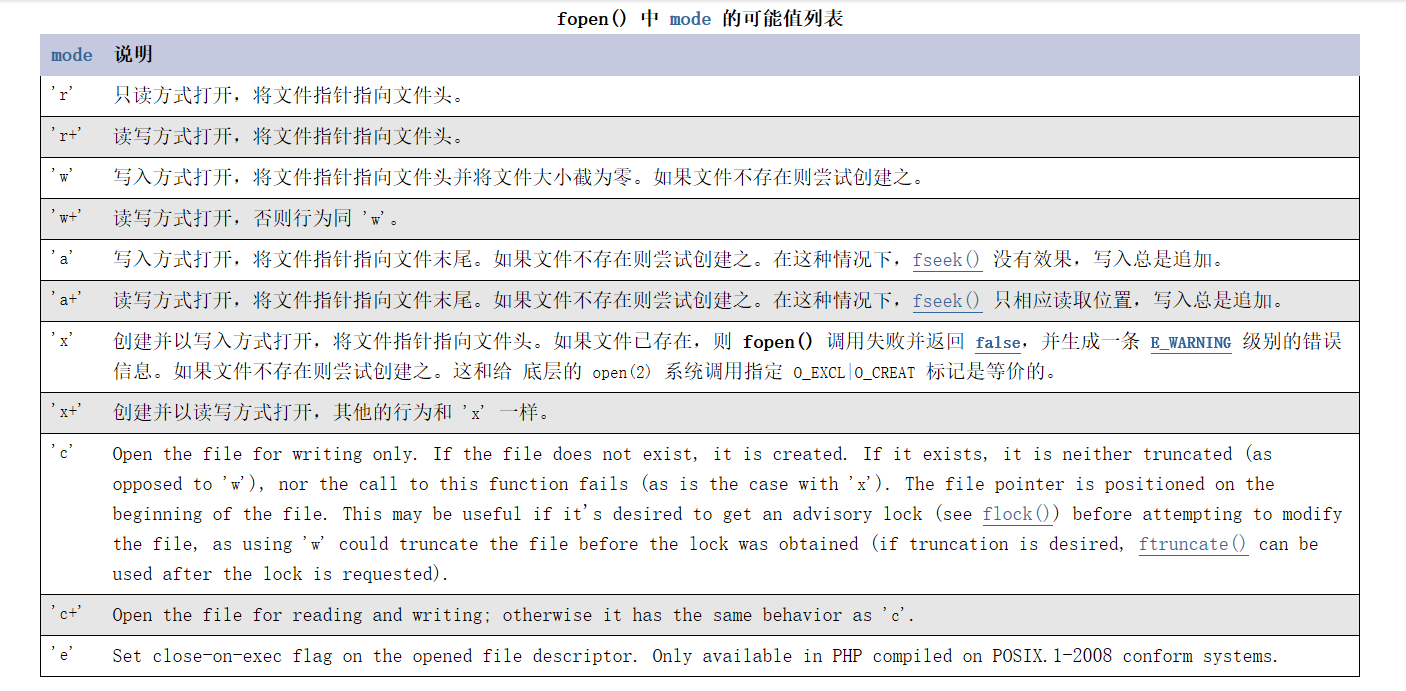
fopen(文件路徑,打開模式):打開一個文件資源,限定打開模式
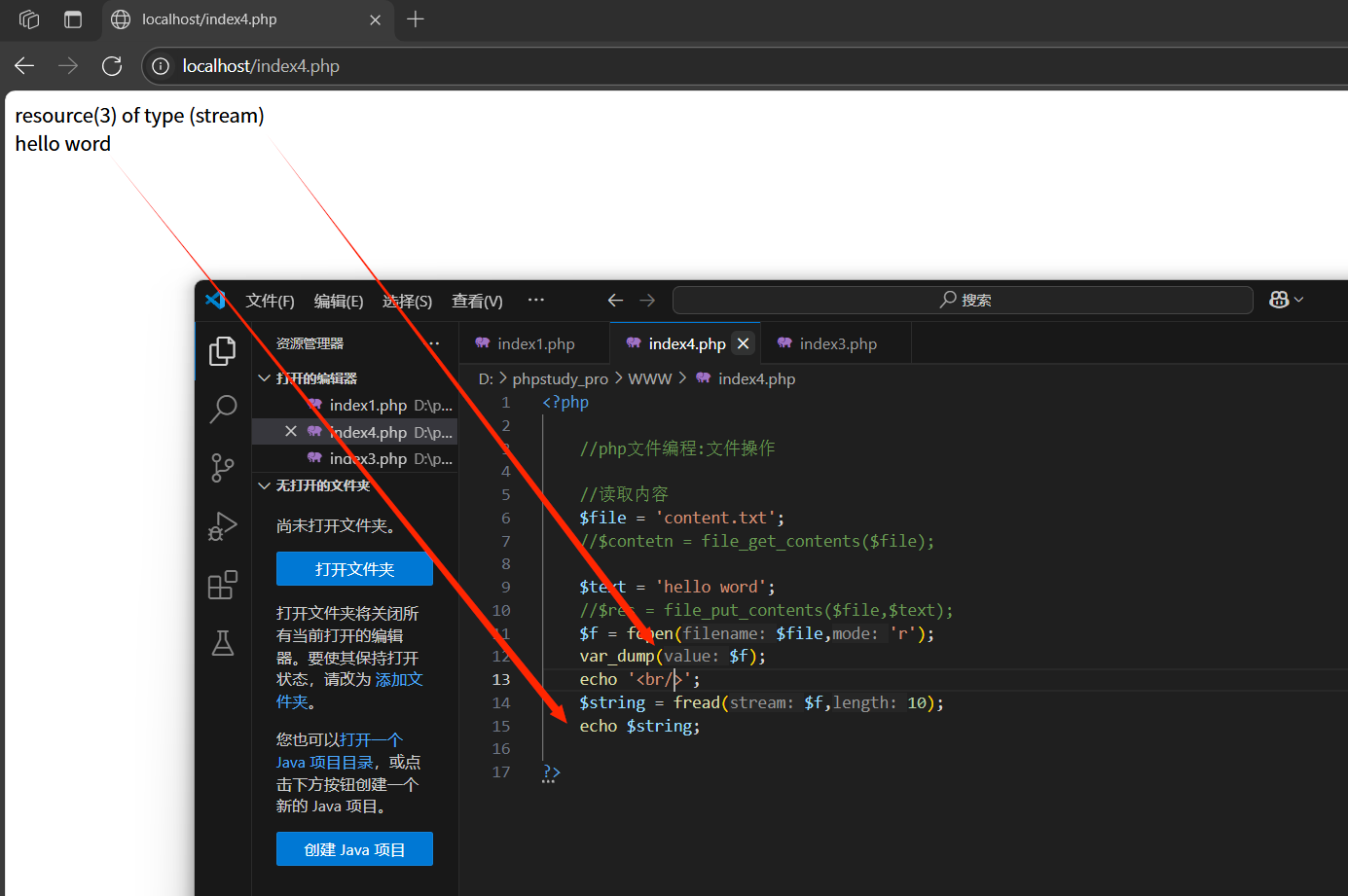
fread(資源,長度):從打開的資源中讀取指定長度的內容(字節)
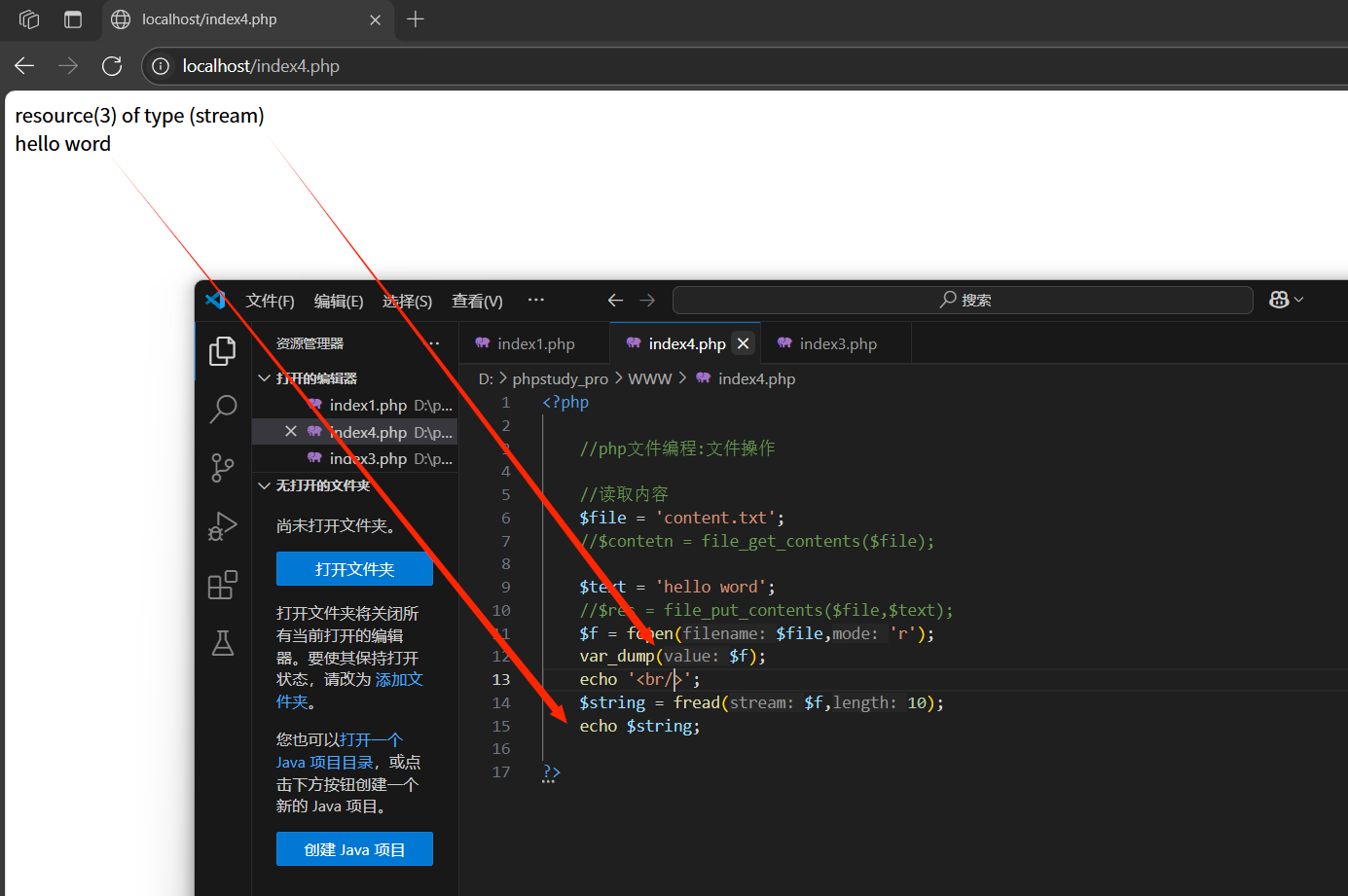
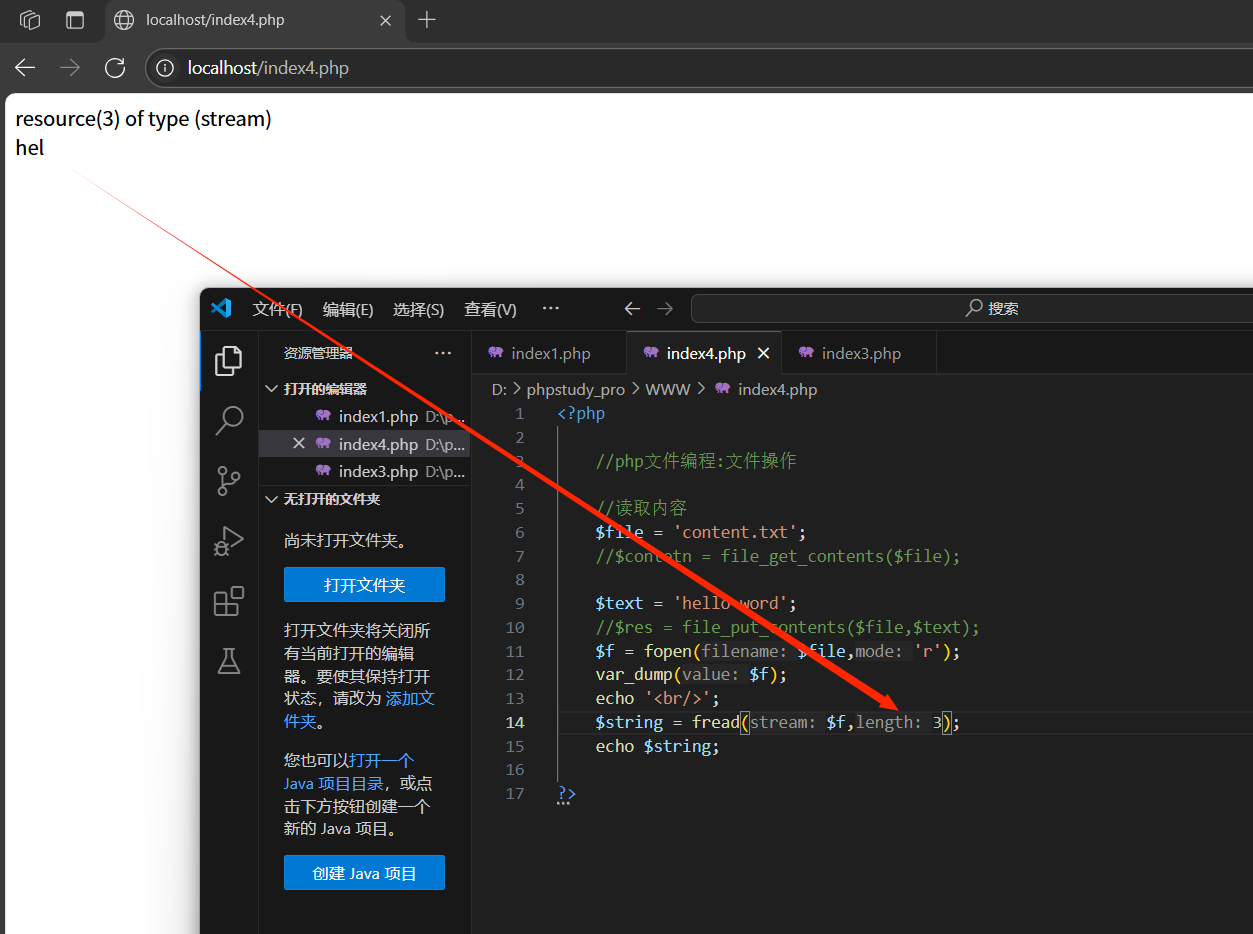
fwrite(資源,內容):向打開的資源中寫入指定的內容
fclose(資源):關閉資源
相關函數:
is_file():判斷文件是否正確(不識別路徑);
filesize():獲取文件大小
file_exists():判斷文件是否存在(識別路徑);
?
unlink():取消文件名字與磁盤地址的連接(刪除文件);
filemtime():獲取文件最后一次修改的時間
fseek():設定fopen打開的文件的指針位置
fgetc:一次獲取一個字符
fgets():一次獲取一個字符串(默認行)
file():讀取整個文件,類似file_get_contents,區別是按行讀取,返回一個數組
文件下載:
文件下載:從服務器將文件通過HTTP協議傳輸到瀏覽器,瀏覽器不解析保存成相應的文件。
提供下載方式可以使用HTML中的a標簽:<a href="互聯網絕對文件路徑”>點擊下載</a>
1、缺點1:a標簽能夠讓瀏覽器自動下載的內容有限:瀏覽器是發現如果解析不了才會啟用下載,如果能解析便不會下載
2、缺點2:a標簽下載的文件存儲路徑會需要通過hf屬性寫出來,這樣會暴露服務器存儲數據的位置(不安全);
PHP下載:
讀取文件內容,以文件流的形式傳遞給瀏覽器,在響應頭中告知瀏覽器不要解析,激活下載框實現下載
1.指定瀏覽器解析字符集
2.設定響應頭
a.設定文件返回類型:image/jpg || application/octem-stream
b. 設定返回文件計算方式:Accept-ranges:bytes
c. 設定下載提示:'content-disposition:attachment;fileename=' . 文件名字
d.設定文件大小:'Accept-length:' . 文件大小(字節)
//普遍使用filesize(文件名)來表示文件大小
//如果文件的名字是從文件夾里面讀取出來,而且存在中文,那么如果直接使用名字作為下載名字會出現亂碼,出現這種情況需要進行字符集轉碼,從GBK專成UTF-8:iconv(GBK,UTF-8,文件名字);
3.讀取文件
4.輸出文件
方案1:如果文件較小,可以直接使用文件函數操作:file_get_contents(文件名);
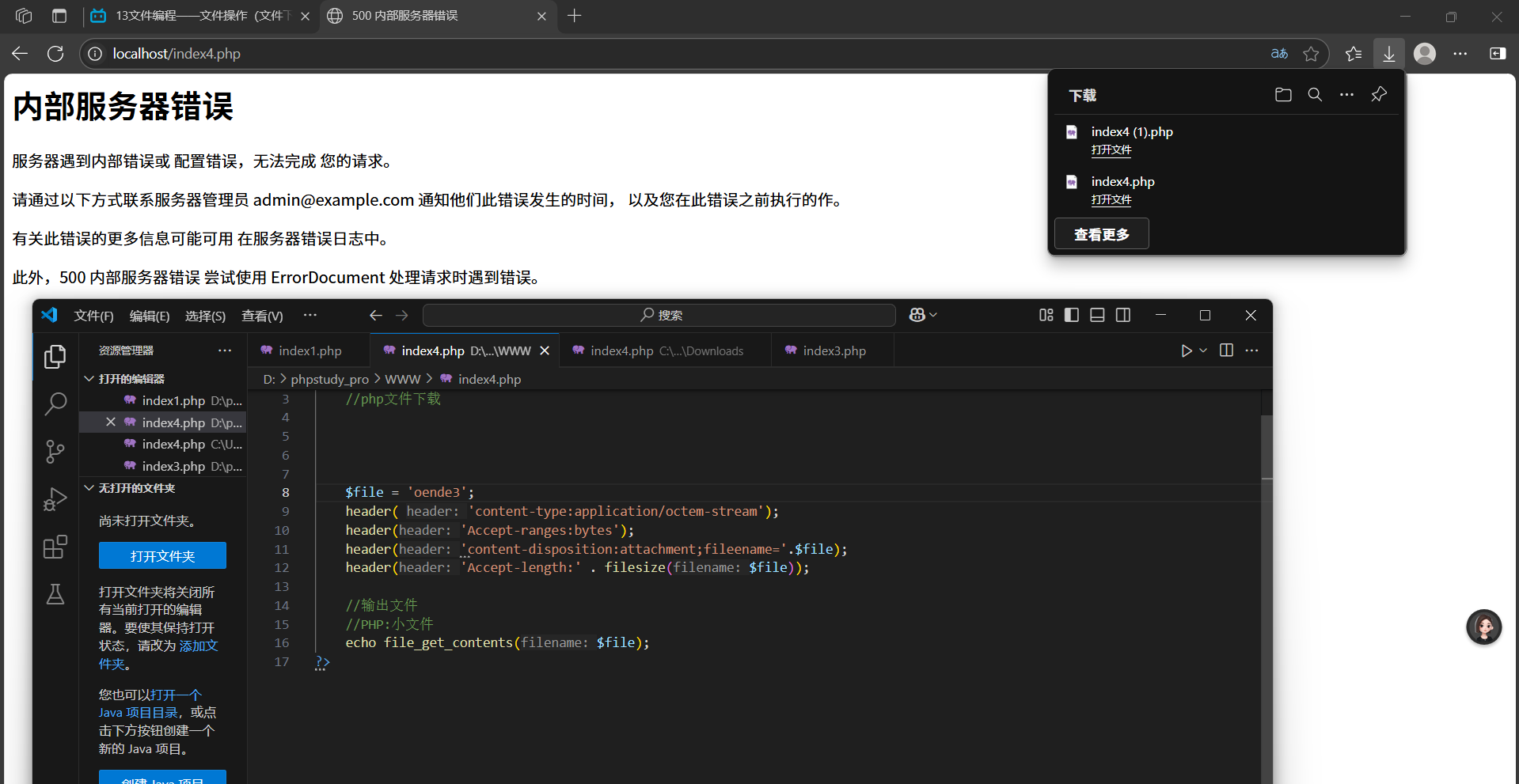
方案2:文件比較大,網絡不是很好:使用文件操作方式:一次讀一點
<?php//php文件下載$file = 'oende3';header( 'content-type:application/octem-stream');header('Accept-ranges:bytes');header('content-disposition:attachment;fileename='.$file);header('Accept-length:' . filesize($file));//輸出文件//PHP:小文件//echo file_get_contents($file);//PHP:大文件$f = @fopen($file,'r') or die();while ($rew = fread($f,1024)){echo $rew;}?>或者:
<?php//php文件下載$file = 'oende3';header( 'content-type:application/octem-stream');header('Accept-ranges:bytes');header('content-disposition:attachment;fileename='.$file);header('Accept-length:' . filesize($file));//輸出文件//PHP:小文件//echo file_get_contents($file);//PHP:大文件$f = @fopen($file,'r') or die();while (!feof($f)){echo fread($f,1024);}//關閉資源fclose($f);
?>補充:
結果(已經成功,只是頁面沒有改變而已):
會話技術:
初步認識:
web會話可簡單理解為:用戶開一個瀏覽器,訪問某一個web站點,在這個站點點擊多個超鏈接,訪問服務器多個web資源,然后關閉瀏覽器,整個過程稱之為一個會話。
HTTP協議的特點是無狀態無連接,當一個瀏覽器連續多次請求同一個web服務器時,服務器是無法區分多個操作是否來自于同一個瀏覽器(用戶)。會話技術就是通過HTTP協議想辦法讓服務器能夠識別來自同一個瀏覽器的多次請求,從而方便瀏覽器(用戶)在訪問同一個網站的多次操作中,能夠持續進行而不需要進行額外的身份驗證。
會話技術分類:
cookie技術
cookie是在HTTP協議下,服務器或腳本可以維護客戶工作站上信息的一種方式.
cookie是由web服務器保存在用戶瀏覽器(客戶端)上的小文本文件(HTTP協議響應頭),它可以包含有關用戶的信息。無論何時用戶鏈接到服務器(HTTP請求攜帶數據),web站點都可以訪問cookie信息.
session技術
Session直接翻譯成中文比按困難,一般都譯成時域。
在計算機專業術語中,Session是指一個終端用戶與交互系統進行通信的時間間隔,通常指從注冊進入系統到注銷退出系統之間所經過的時間。以及如果需要的話,可能還有一定的操作空間。
Session技術是將數據保存到服務器端,無論何時用戶鏈接到服務器,Web站點都可以訪問Session信息.
SESSION技術的實現是依賴COOKIE技術的。
區別:
1.安全性方面:
- session存儲服務器端,安全性高
- cookie存儲瀏覽器端,安全性低
2.數據大小方面:
- cookie的數量和大小都有限制(20個/4k)
- session數據存儲不限
3.可用數據類型:
- cookie只能存儲簡單數據,數值/字符串
- session可以存儲復雜數據(自動序列化)
4.保存位置方面
- cookie保存在瀏覽器上
- session保存在服務器上
COOKIE:
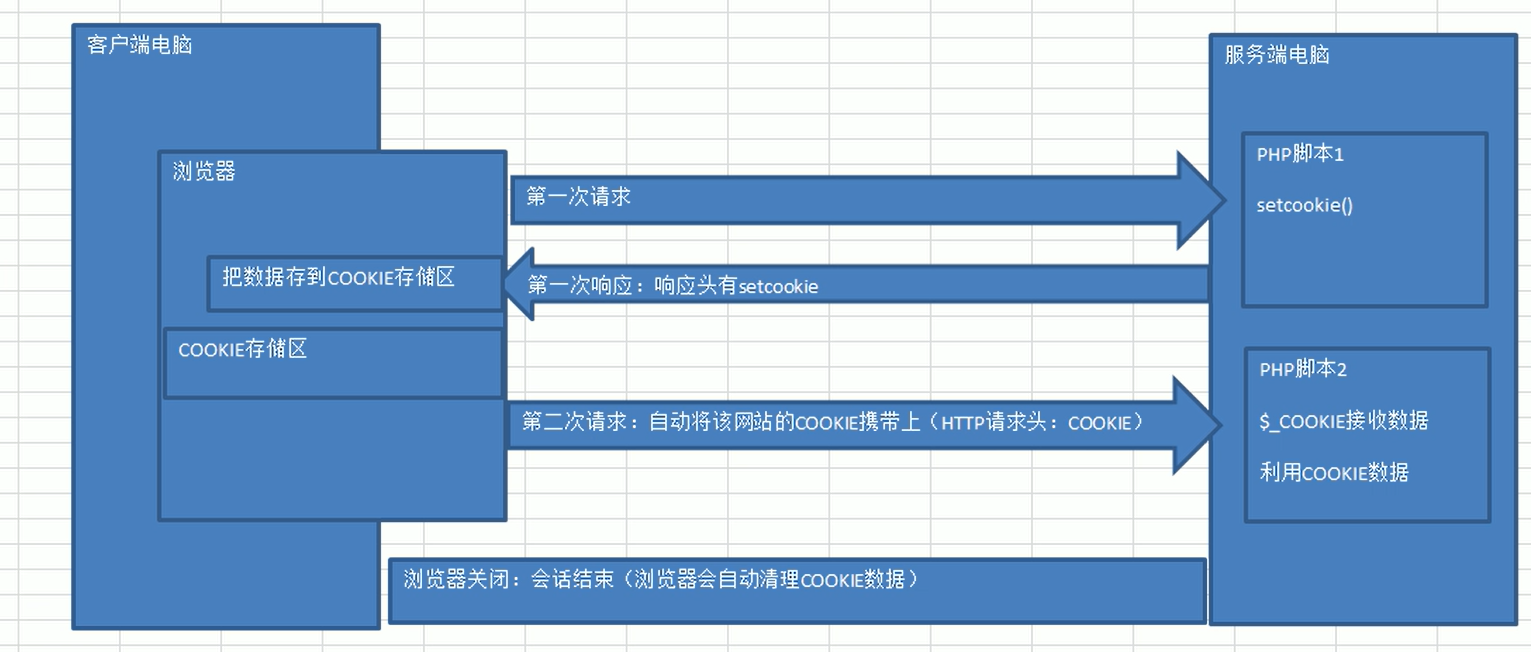
工作原理:
服務器將數據通過HTTP響應存儲到瀏覽器上,瀏覽器可以在以后攜帶對應的cookie數據訪問服務器;
1.第一次請求時,PHP會通過setcookie函數將數據通過http協議響應頭傳輸給瀏覽器;
2.瀏覽器在第一次響應時將cookie數據保存到瀏覽器;
3.瀏覽器后續請求同一個網站的時候,會自動檢測是否存在cookie數據,如果存在將在請求頭中將數據攜帶到服務器;
4.PHP執行的時候會自動判斷瀏覽器請求中是否攜帶cookie,如果寫到,自動保存到$_cookie中;
5.利用$_cookie訪問cookie數據。
交互過程:
COOKIE的基本使用:
設置cookie信息息
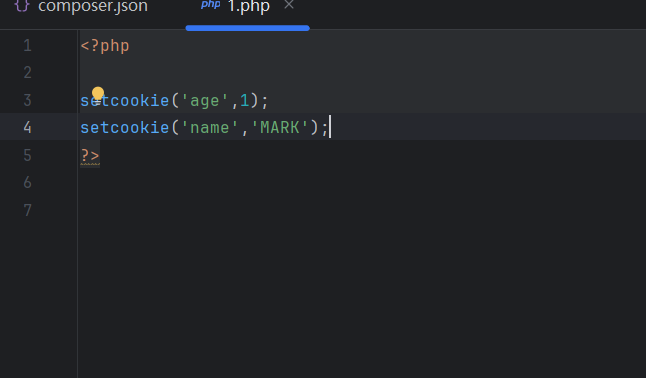
setcookie函數用來設置cookie信息
setcookie(名字,值);
- cookie名的設置:字符串,第一個參數
- cookie值的設置:第二個參數
- cookie值的類型要求:必須是簡單類型中的整數或者字符串
查看:F12 => application(應用程序) => cooies
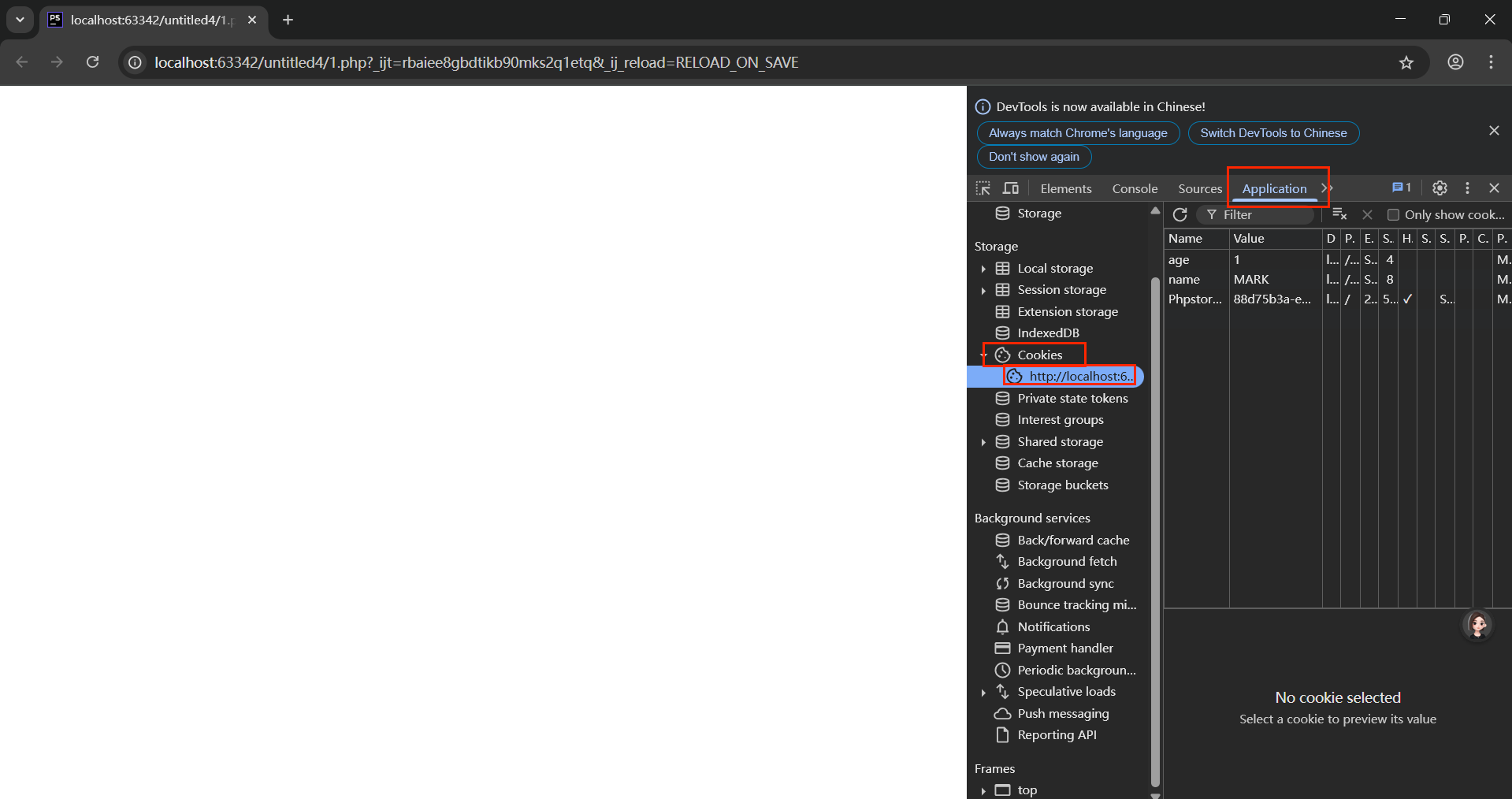
讀取cookie信息:
1.$_COOKIE數組的使用
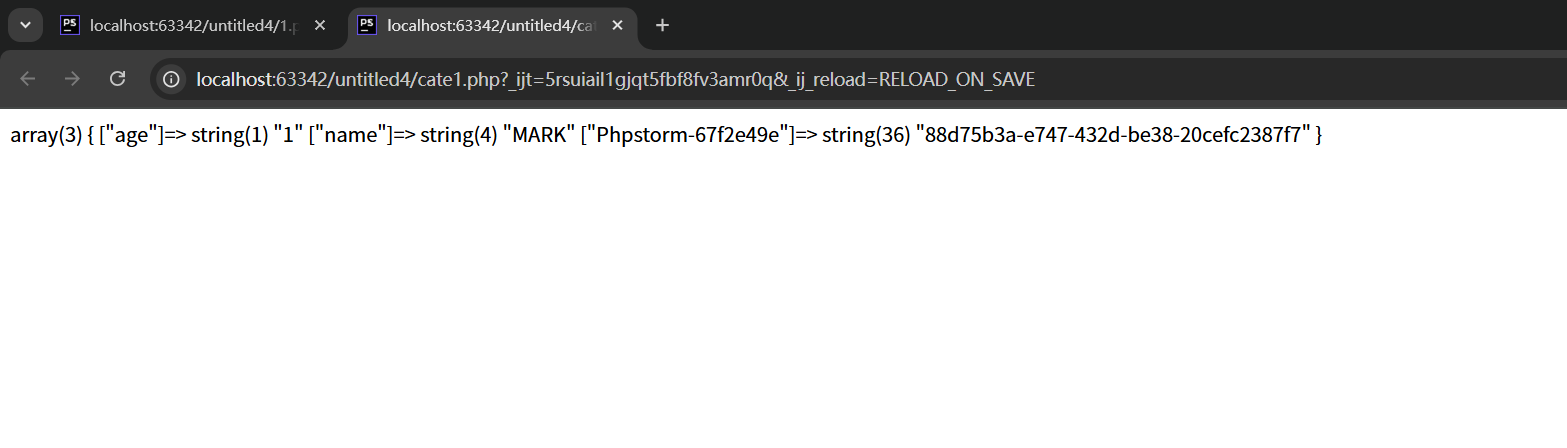
同時:
COOKIE高級:
cookle生命周期:
cookie在瀏覽器生存時間(瀏覽器在下次訪問服務器的時候是否攜帶對應的cookie)
- 默認(不設定)是的生命周期:不設定周期默認是關閉瀏覽器(會話結束)
- 設定一個常規日期戳的周期:通過setcookie第三個參數可以限定生命周期,是用時間戳來管理,從格林威治時間開始
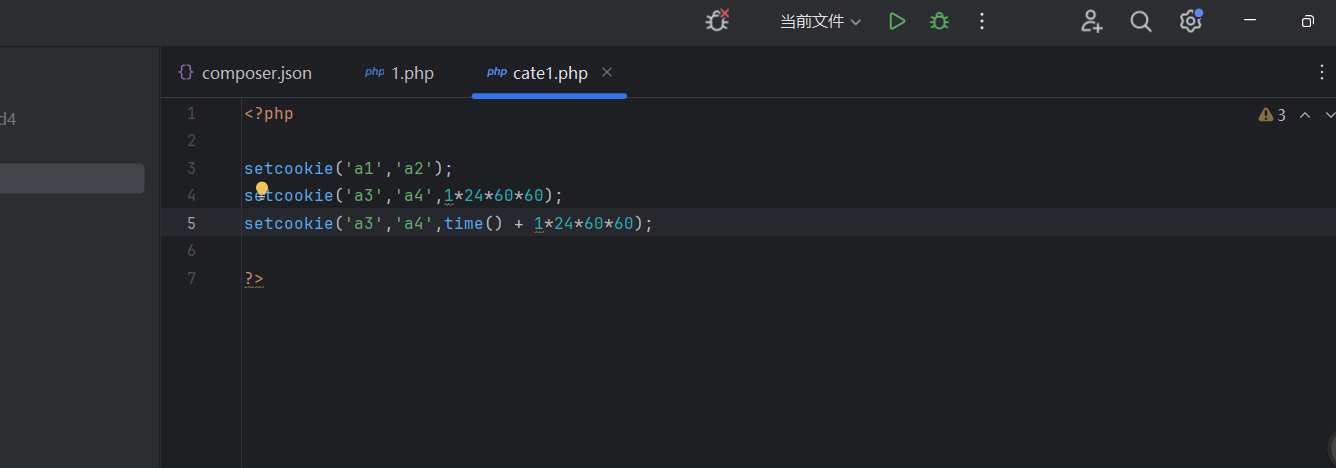
在經過重啟后,a1和a2都消失了
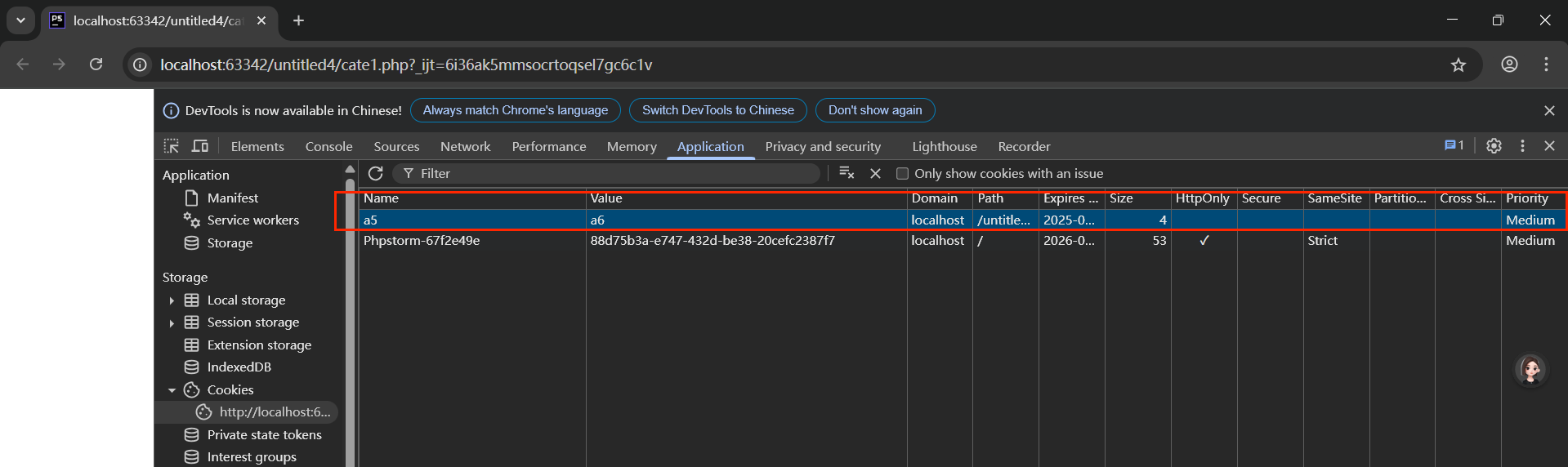
- 設定一個" 0 "的周期:在第三個參數設置為0代替時間戳的時候,表示的就是普通設置,相當于沒有,會話結束過期
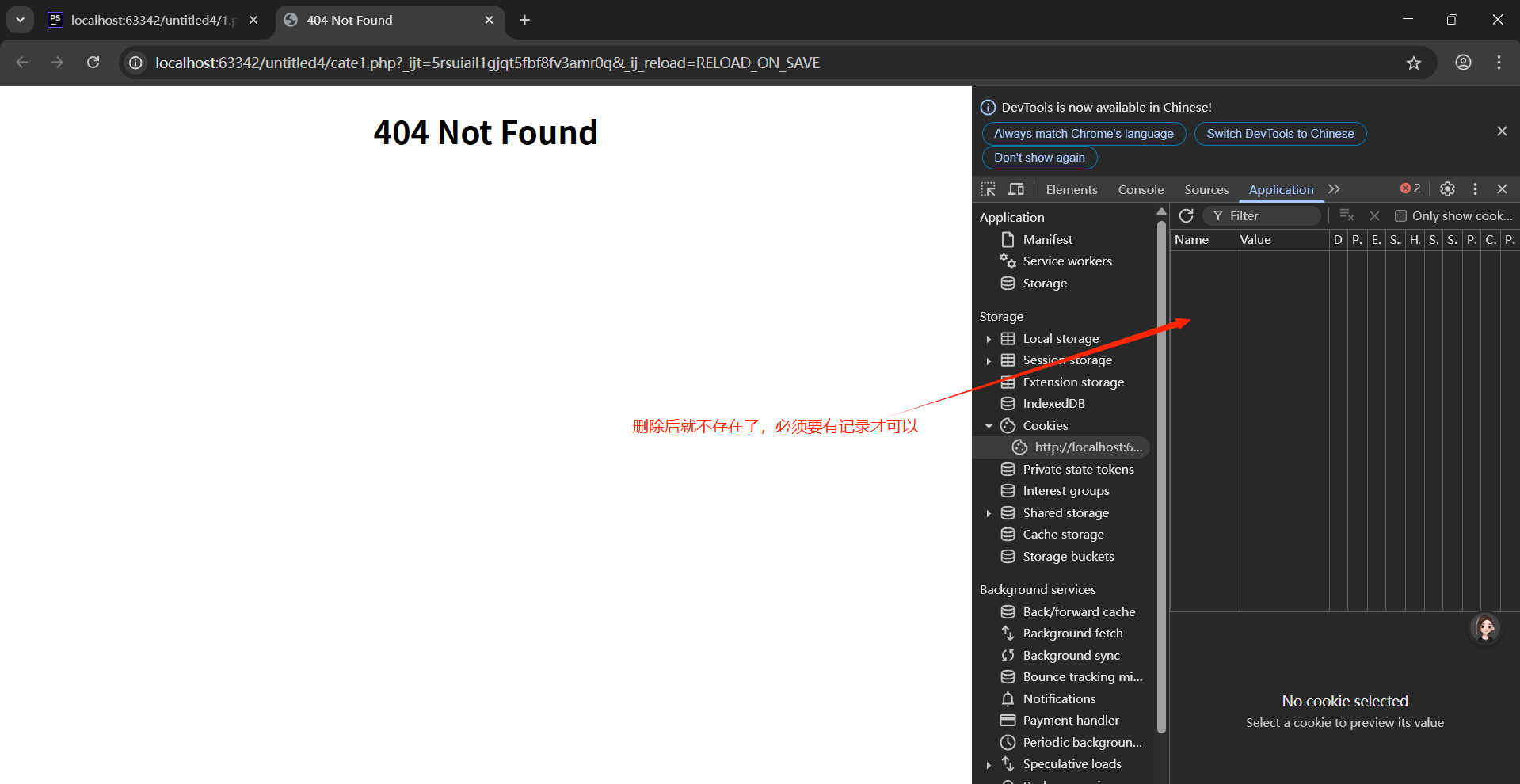
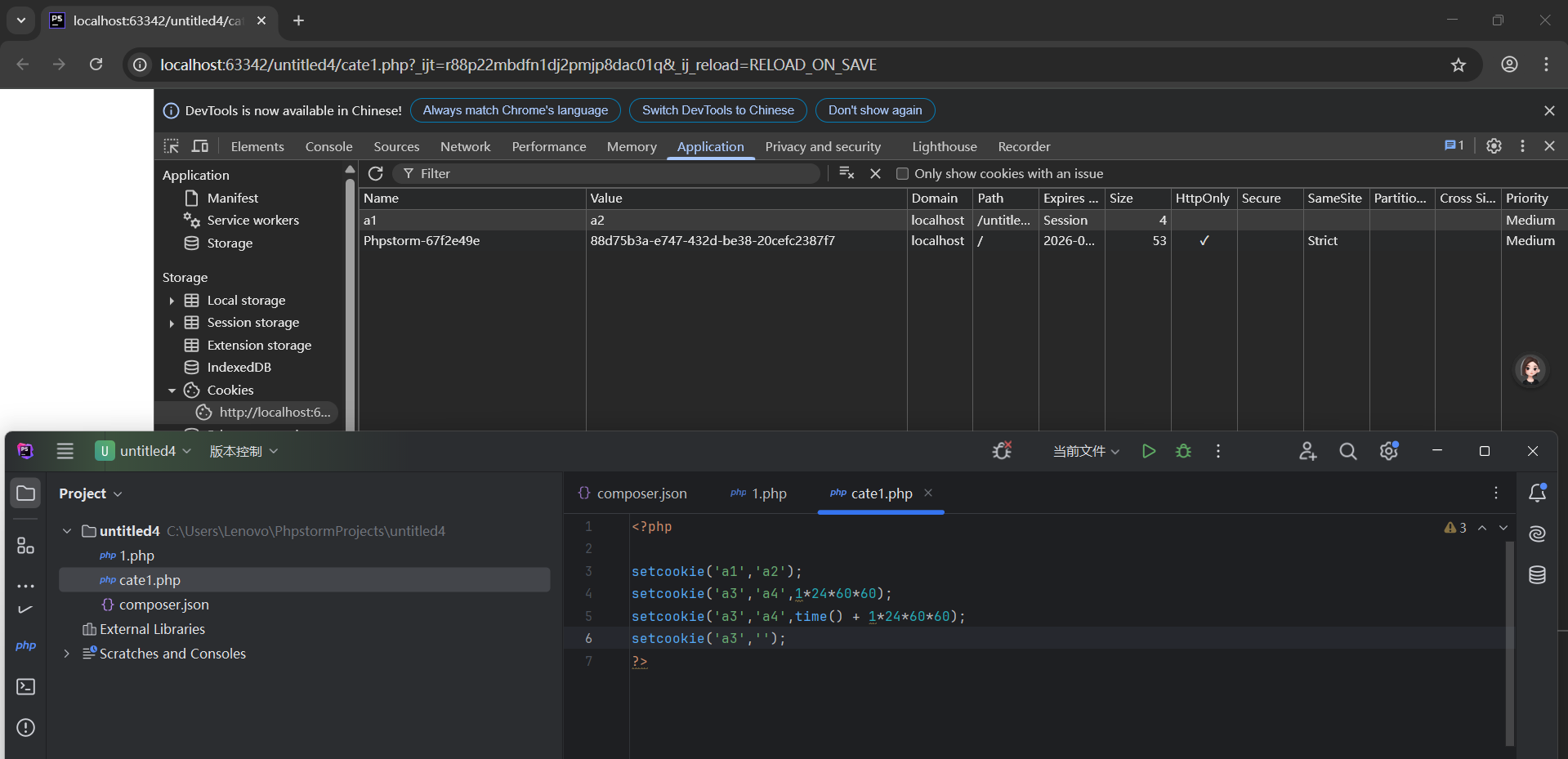
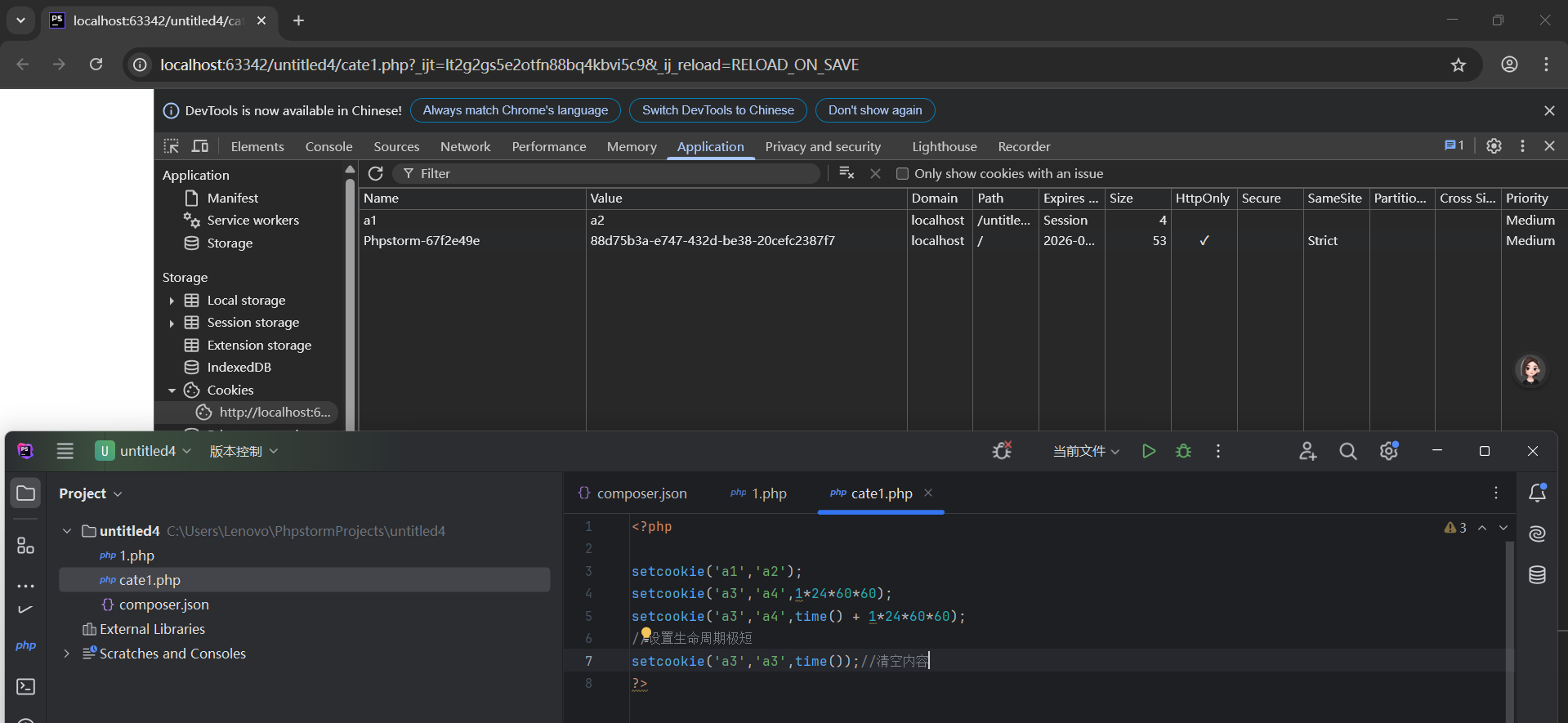
- 刪除一個cookie的做法
服務器沒有權限去操作瀏覽器上的內容(不可能刪除),可以 通過設定生命周期來讓瀏覽器自動判定cookie是否有效,無效 就清除
a. 清空cookie數據內容
b. 設定時間戳過期
COOKIE適用范圍:
作用范圍:不同的文件層級中,設定的C00KIE默認是在不同的文件夾下有訪問限制。上層文件夾中設定的C00KIE可以在下層(子文件夾)中訪問,而子文件夾中設定的C00KIE不能在上層文件夾中訪問。(就是子能看到父,而父看不到子)
- 默認(不設定)的范圍,就是使用cookie默認的作用范圍
- 設定為"/"的含義:告知瀏覽器當前cooie的作用范圍是網站根目錄(就是設定全局都可以訪問,父也可以訪問子問);
語法:setcookie(名字,值,生命周期,'/')
COOKIE跨子域:
跨子域:在同一級別域名下,myitcast.com(一級域名),可以有多個子域名(www.myitcast.com 和 gz.myitcast..com) , 他們之間是搭建在不同的服務器上(不同文件夾:E:/server/apache/htdocs和E:web) , 但是可以通過COOKIE設置實現對應的COOKIE共享訪問,但是默認是不允許跨域名訪問的。
- 設定cookie的有效域名,不同的域名(包含主機)之間不能共享cookie,可以通過setcookie的第五個參數進行控制
基本語法:setcookie(名字,值,生命周期,作用范圍,有效域名)
//意為,凡是以有效域名為結尾的網站都可以共享
不設定時的默認有效域名
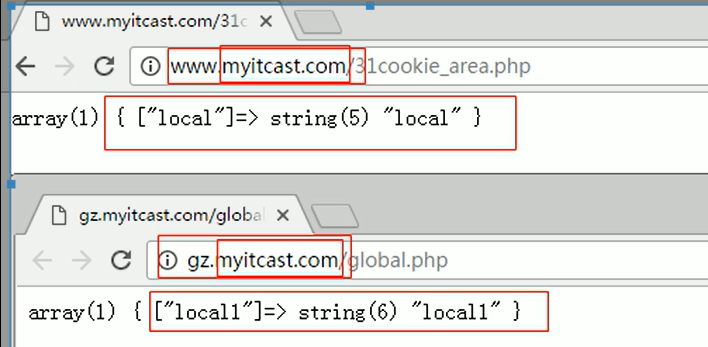
- 3)跨子域的設定方法:在設定域名訪問的時候用設定上級域名即可:myitcast..com,這個是有所有以myitcast.com結尾的網站都可以共享COOKIE
COOKIE數組使用:
C00KIE本身只支持簡單數據(數字或者字符串),能的夠保留的數據本身有限,也不成體系。
如果需要使用C00KE來保留一組數據的化,想辦法湊成數組。(C00KIE不支持數組)
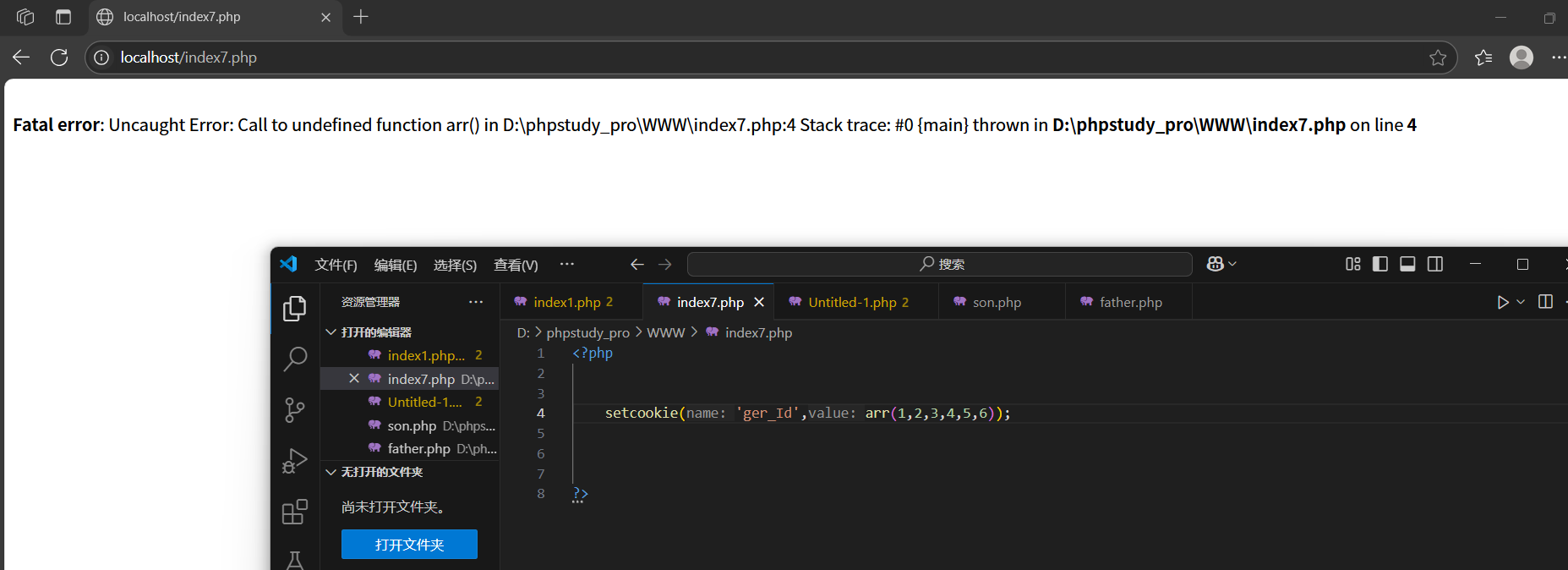
- 設置形式:setcookie('cl[k1]',值)
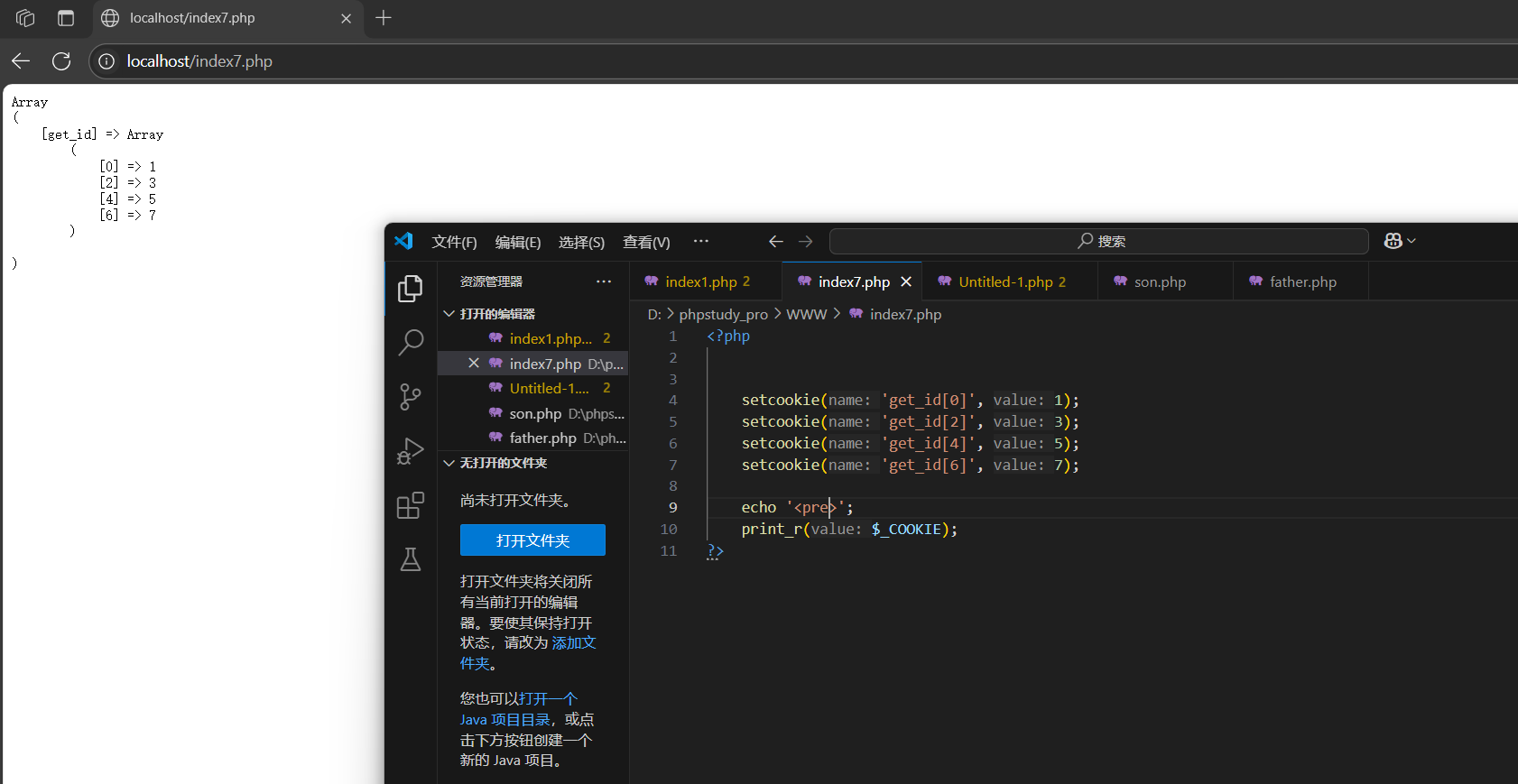
- 讀取形式:$_COOKIE['c1']['k1']
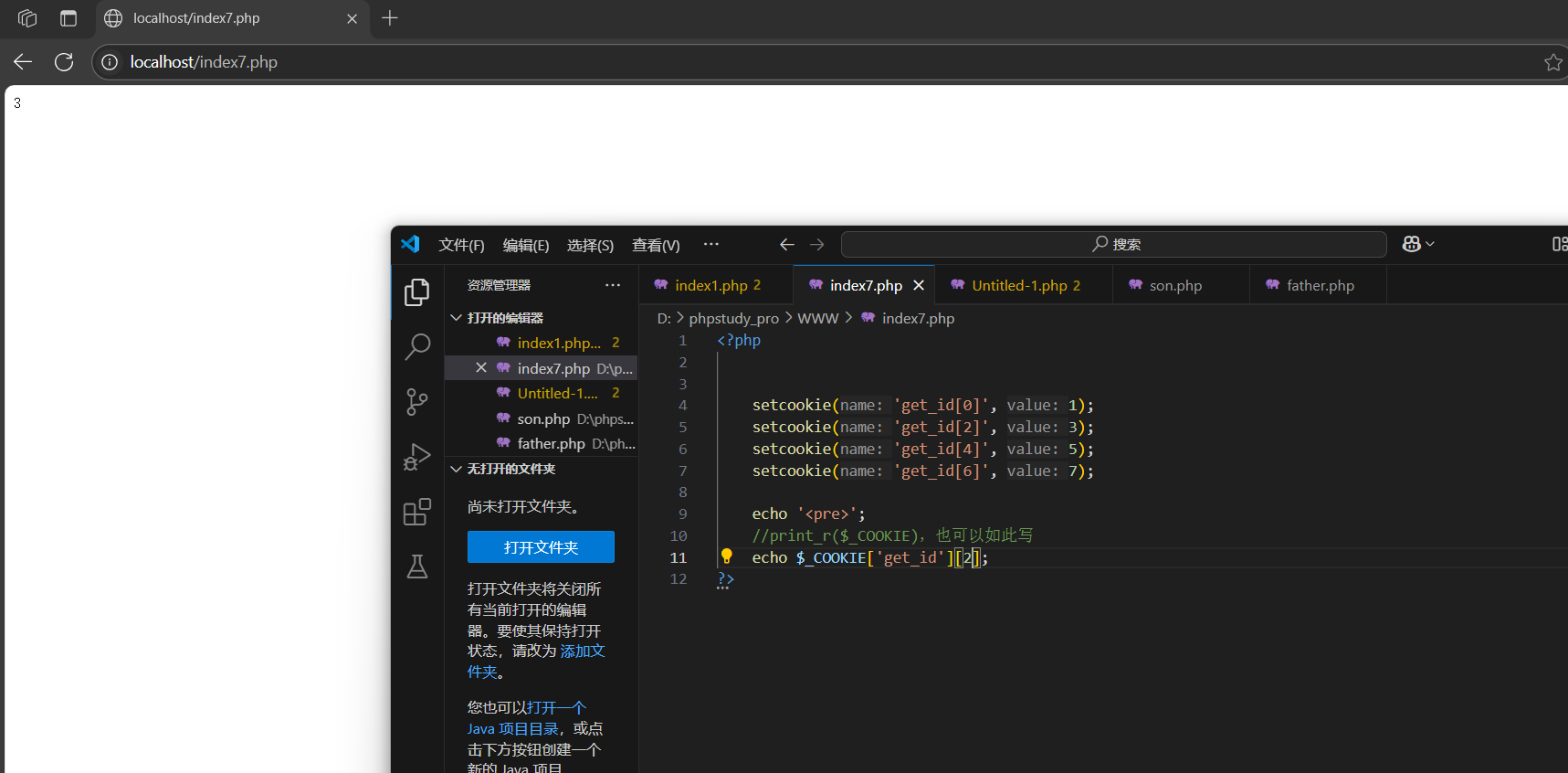
注:
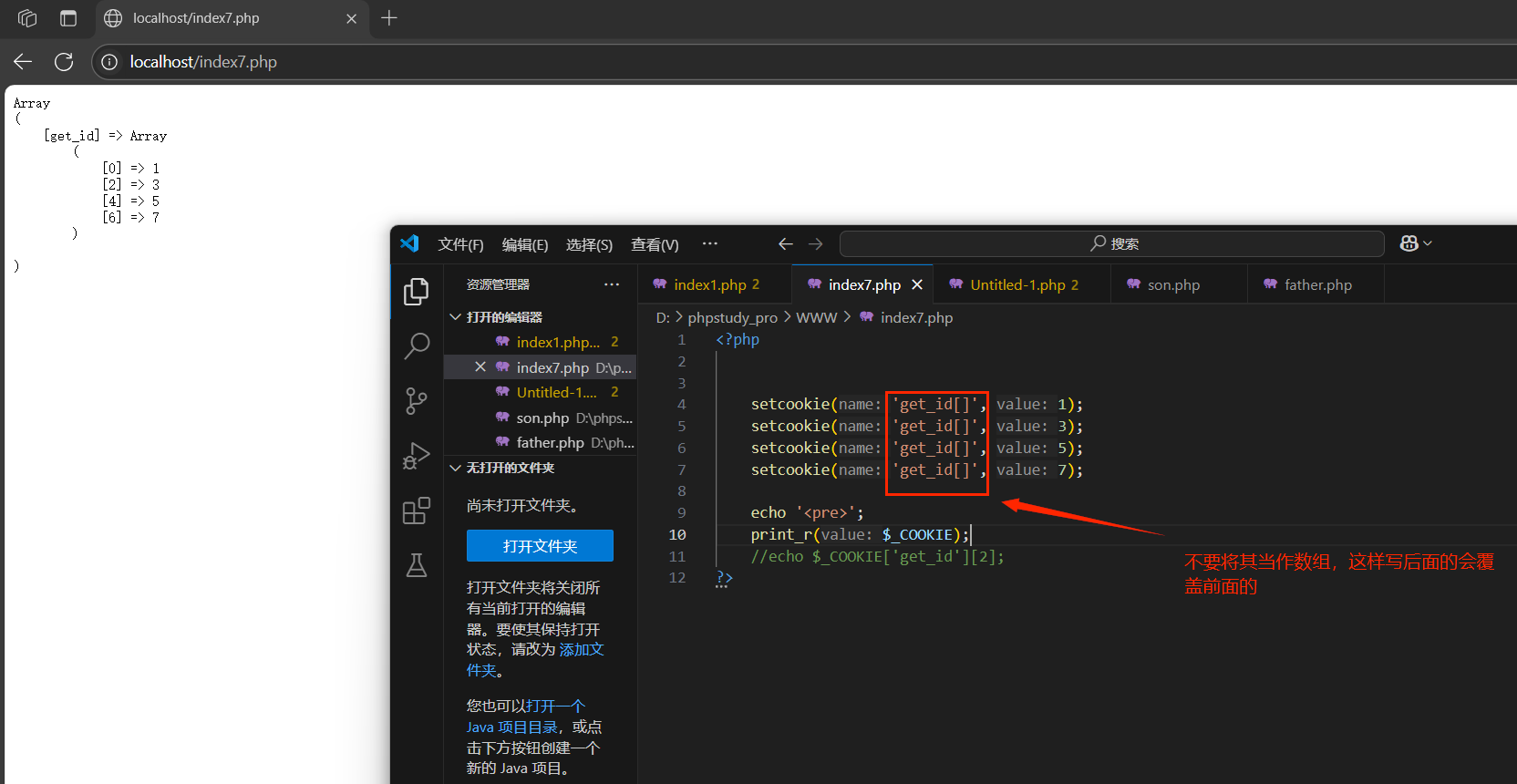
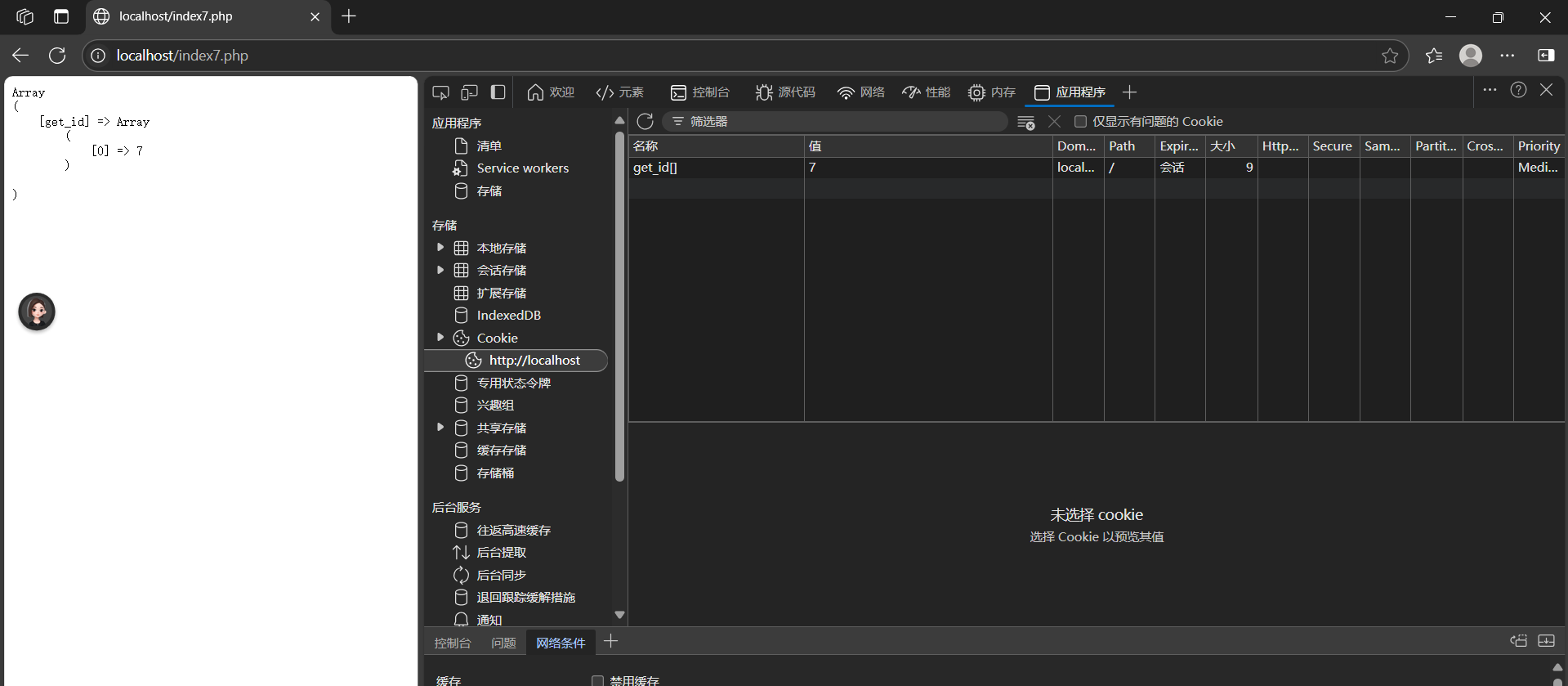
和收斂)

)






)

![[Python] Python中的多重繼承](http://pic.xiahunao.cn/[Python] Python中的多重繼承)



的縱深遍歷與生成樹實戰指南?)



