今天帶來EMO2(全稱End-Effector Guided Audio-Driven Avatar Video Generation)是阿里巴巴智能計算研究院研發的創新型音頻驅動視頻生成技術。該技術通過結合音頻輸入和靜態人像照片,生成高度逼真且富有表現力的動態視頻內容,值得一提的是目前阿里并沒有開源這個項目,所以今天內容僅供學習(阿里的EMO一代到目前都還沒有開源,所以等項目開源那是遙遙無期)歡迎大家再評論區討論
- 項目官網: https://humanaigc.github.io/emote-portrait-alive-2/carxiv
- 技術論文: https://arxiv.org/pdf/2501.10687
1. 動機與問題
1.1 問題1:如何實現富有表現力的音畫同步人體視頻生成
- 研究背景:音頻驅動人體視頻生成技術旨在創建音畫同步的面部表情與肢體動作,盡管在音頻驅動面部表情生成和以人物為中心的視頻合成方面已取得顯著成果,但在實現富有表現力的音畫同步人體視頻生成,尤其是伴隨語音的視頻生成方面仍存在挑戰
- 現狀與挑戰:現有方法主要聚焦于面部區域,忽略了上半身尤其是手部動作的建模,現有方法難以生成 富有表現力,語義一致的全身動作
1.2 問題2:存在肢體動作豐富度不足或泛化能力有限等缺陷
- 分析原因:
- 人體是一個具有高自由度的復雜多關節系統,其運動具有高度的時間依賴性與多樣性。
- 在像素空間或顯式坐標空間中從音頻直接預測全身動作,而音頻與不同身體關節之間的相關性存在顯著差異,所以容易出現動作僵硬、同步性不足等問題
解決方案: - 借鑒機器人控制系統的“末端執行器”和機器人逆向運動學降低自由度,改進逆向運動學,提出“像素先于逆運動學”,這種方法能夠重建完整人物角色,實現音頻與嘴唇運動的同步,同時保持人體結構的合理性,從而生成連貫、自然的共語視頻。
- 不再直接從音頻預測全身動作,專注于將音頻映射到手部姿態,充分利用音頻與手部動作的強相關性。
2. 創新點
- 受到機械臂和人形機器人等控制系統常通過仿生設計來模擬人類行為的啟發,將手部動作看作日常生活的"末端執行器"簡化人體自由度
- 提出音頻特征與全身動作之間的對應關系比較弱是當前方法的關鍵限制,驗證了音頻信號與手部動作的強相關性(所以這篇文章是由音頻輸入先生成手部姿態,再將手部姿態看作“末端執行器”來生成全身動作)
- 提出一種簡化的兩段音頻驅動手勢生成框架
- 引入基于擴散模型的生成方法,能夠從生成的手部姿態合成逼真的面部表情與身體動作
3. 方法
EMO2 提出了一個創新的音頻驅動視頻生成框架,結合末端執行器引導機制,在音畫同步的基礎上,顯著提升了生成動作的自然性、協調性和表現力。該方法的整體架構由音頻解碼器、末端執行器預測網絡、視頻合成模塊、運動控制模塊四個主要模塊組成
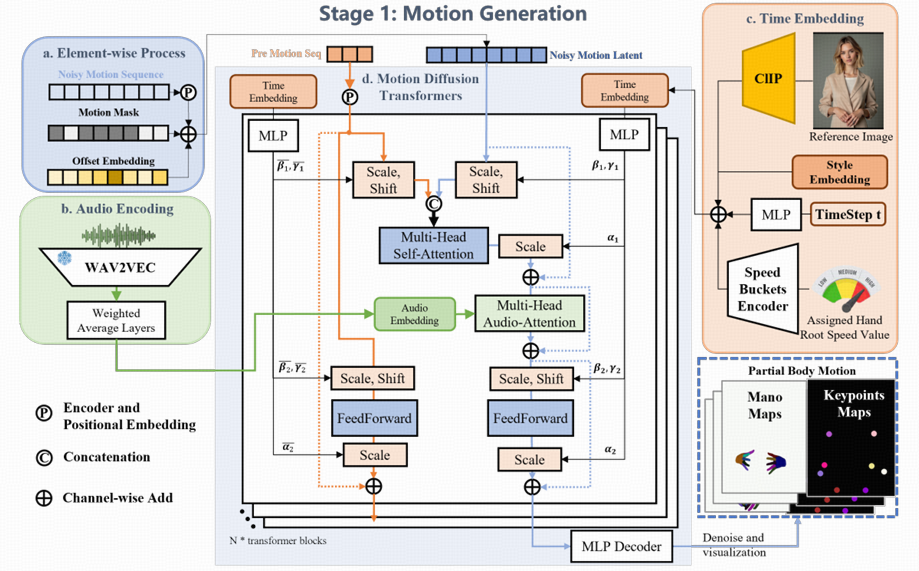
3.1 音頻編碼器
音頻編碼器接收時序音頻信號作為輸入,提取其局部語義信息和全局情緒特征。EMO2利用 wav2vec2.0 預訓練模型來提取高維語音表示,捕捉音頻中的語音節奏、語調、強度等潛在驅動因素。
輸出包括:
- 逐幀語音特征(Frame-level audio embedding)
- 韻律與情感信息(Global prosody vector)
3.2 末端執行器預測網絡(手部動作生成)
EMO2 的核心創新點在于引入末端執行器引導機制,該機制首次應用于音頻驅動的人體生成任務中。將手部動作作為末端執行器,利用上半身的預定義關鍵點,作為視頻生成的弱監督信號,采用的是 Diffusion Transformer(DiT ) 作為主干網絡,利用交叉注意力機制聯結音頻特征和噪聲運動潛變量,并嵌入時間步。
基于音頻特征,通過注意力機制,生成與語音節奏一致的MANO手部系數, 從而獲得符合語音語調和節奏的手勢。為了保證連續片段之間的平滑過渡,前一片段的運動序列的最后幾幀被拼接到當前運動序列中,確保動作的流暢性和連貫性。
3.3 視頻生成模塊(Video Renderer / Image Synthesizer )
視頻生成模塊基于EMO,骨干網絡接收多幀噪聲潛在輸入,并在每個時間步中嘗試去噪,生成連續的視頻幀。該框架可以分為四個部分:
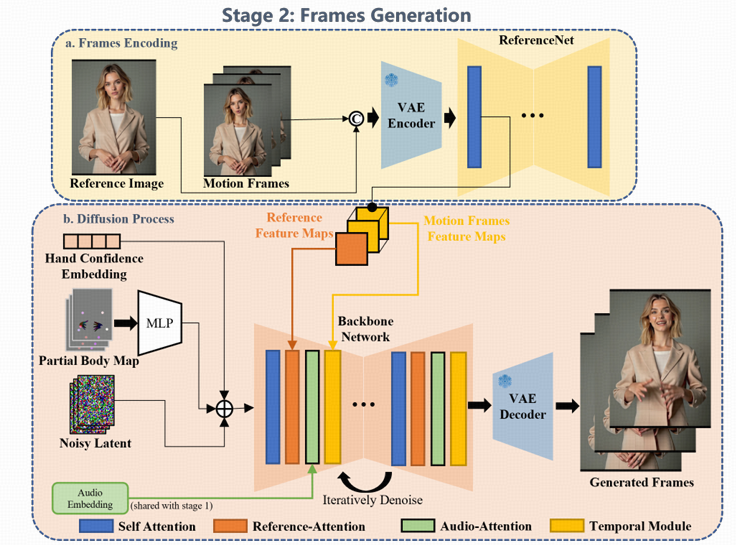
- 去噪:骨干網絡是一個去噪的2D-UNet,并集成了來自AnimateDiff 間模塊。這個網絡負責在每個時間步中逐步去除噪聲,并生成連續的視頻幀。
- 幀參考:為了保持角色的身份,我們將ReferenceNet與骨干網絡并行部署,輸入參考圖像和運動幀,以獲取2D圖像特征。這些特征通過跨注意力機制分別注入骨干網絡的空間和時間維度。
- 音頻驅動:為了通過音頻驅動角色,第一階段共享的音頻特征通過跨注意力機制與骨干網絡的潛在特征相結合,從而實現音頻與角色動作的同步。
- 運動引導:第一階段生成的MANO映射和關鍵點映射被按通道拼接,并與潛在特征一起集成,以調節身體運動,從而實現更加自然且精準的動作生成。
3.4 運動控制模塊
- 運動控制模塊利用末端執行器預測網絡生成的MANO映射引導角色的運動。這些映射明確描述了生成幀中的手部運動,涵蓋形狀、大小和姿勢等方面。 并使用MANO手部檢測的置信度分數。這些分數在遇到顯著遮擋或運動模糊的情況下可能會降低,作為條件輸入來增強生成的手部質量。
- 初步實現使用了僅手部控制信號,使得其他身體部位可以與音頻信號和手部運動同步。然而,MANO手部信號的大幅度運動通常與靜止的軀干不兼容,導致視頻中的表現顯得不自然(所以說文章提出的改進逆向運動學其實效果也不怎么好?)。為了解決這一問題,EMO2引入了關節關鍵點來補充運動驅動方法,這些關鍵點映射表示了手臂和腿部關節的二維位置。
4. 實驗
4.1 數據集
MOSEI 簡介:
數據類型:
- 視頻(包含人臉、語音和文本信息)
- 對象為網絡中真實人物的訪談、演講等短視頻片段
標注:
- 情感極性評分([-3, 3],例如:-3為非常負面,3為非常正面)
- 情緒標簽(7類:快樂、憤怒、驚訝、厭惡、悲傷、恐懼、中性)
AVSpeech 簡介:
數據類型:
- 來自 YouTube 的講話者視頻(“in-the-wild”)
- 每個片段包含:清晰人臉視頻 + 對應的干凈語音
數據特點:
- 僅包含一個人說話的片段,背景干擾較少
- 沒有轉錄文本,僅提供音頻和視頻模態
EMTD簡介:
- 用于音頻驅動的人體上半身表達生成任務的多模態數據集。它的目標是推動真實感強、表達豐富的音頻驅動人體動畫技術的發展,特別關注于面部表情、手勢動作與語音內容的自然匹配與同步。
數據類型: 視頻、音頻、3D人體關鍵點、文本轉錄、情感標簽和動作標簽
標注:面部動作、手部動作、上半身姿勢動作都有具體標注
4.2 評價指標
手部動作生成評價指標
- DIV(Diversity,多樣性):
計算多個生成樣本之間的歐式距離或分布距離,較高的 DIV 表示模型具有更強的表達能力,能生成更多樣、 生動且不重復的動作;較低的 DIV 可能說明模型模式崩潰或生成內容單一。 - BA(Beat Alignment,節拍對齊):
計算節拍位置與“運動峰值”的對齊度,較高的 BA 表示生成的手勢、身體動作等能更好地跟隨語音節奏,增強自然性和表現力。 - PCK(Percentage of Correct Keypoints):
較高的 PCK 說明生成動作在空間上更接近真實數據,通常用于檢測動作是否合理、逼真。 - FGD(Fréchet Gesture Distance):
較低的 FGD 表明生成動作的風格、動態特征更接近真實分布,是衡量“自然性”的重要指標。
視頻生成評價指標
- FID
FID度量生成圖像與真實圖像之間的距離 , 基于Fréchet距離,衡量生成樣本的特征分布與真實樣本的特征分布的差異。數值越低,表示生成圖像的質量越接近真實圖像。 - 結構相似性指數(SSIM)
SSIM度量圖像的結構相似性,考慮了亮度、對比度和結構信息的影響。其計算方式是將圖像分成小塊,分別計算每個塊的SSIM值,然后綜合得出圖像的整體SSIM值,值越高說明生成的圖像與參考圖像在結構上越相似。 - 峰值信噪比(PSNR)
PSNR用于評估圖像重建的誤差,它通過計算圖像的最大像素值與均方誤差(MSE)之間的關系來衡量質量。PSNR的值越高,表示圖像的質量越好。 - Fréchet Video Distance(FVD)
FVD是通過計算生成視頻和真實視頻的Fréchet距離來度量它們之間的差異,值越高說明生成視頻與真實視頻之間的差異越大,即生成視頻的質量越差。
4.3 實驗結論
手部動作生成對比實驗結果

在對比實驗中,EMO2基于 MANO 模型,相較于其他基于 SMPL 的方法,在多個指標上展現了顯著優勢:
- DIV(多樣性):文章的MANO 方法在 DIV 指標上遙遙領先,顯示了更高的手部動作生動性和表現力。其他基于 SMPL 的方法往往生成單調、重復的動作,即使起始手勢不同,手部動作也傾向于維持在胸前或停留在初始位置,缺乏多樣性。
- BA(節拍對齊):在 BA 指標上,文章的 MANO 方法同樣表現優越,能夠更好地與音頻節奏同步。這兩個指標(DIV 和 BA)在生成生動且富有表現力的共語驅動信號方面至關重要,有助于提升下一階段視頻生成的質量。
- PCK 和 FGD:盡管在 PCK(接近真實動作的比例)和 FGD(生成動作分布與真實動作分布之間的距離)上,文章的方法得分較低可以預見(文章沒有給出這兩個指標結果)。其他基于 SMPL 的方法通過正向運動學計算手部動作,容易生成與真實動作更為接近的結果,而我們的 MANO 方法則具有更大的自由度,可以生成與真實動作有所不同的手部運動,導致這些指標的得分較低。
視頻生成對比試驗結果

- 圖像質量:從 FID、SSIM 和 PSNR 指標的提升可以看出,此文章的方法在生成單幀圖像質量方面優于其他方法。特別是在使用原始姿態作為驅動(“w/o motion gen”)的實驗設置中,由于與真實標簽更加一致,進一步提升了生成圖像和視頻的質量。
- 動作多樣性:盡管“w/o motion gen”設定下圖像質量提升明顯,但相對較低的 HKV 值表明動作缺乏變化。相比之下,文章的完整方法具備更高的 HKV 值,顯示出在保持合理性的前提下能夠生成更豐富、更具表現力的動作序列。
- 身份一致性與面部表現力:文章的方法能夠更好地保持人物身份一致性,這從更高的 CSIM 值中得到驗證。同時,更低的 EFID 值也證明了EMO2能生成更生動、自然的面部表情。
![[Redis] Redis:高性能內存數據庫與分布式架構設計](http://pic.xiahunao.cn/[Redis] Redis:高性能內存數據庫與分布式架構設計)






 Naflex模型的動態分辨率原理)






)



)
