動漫角色識別是計算機視覺的典型應用場景,可用于周邊商品分類、動畫制作輔助等。
這個案例是一個經典的深度學習應用,用于圖像分類任務,它使用了一個自定義的VGG-16模型來對《海賊王》中的七個角色進行分類,演示如何將經典CNN模型應用于小規模自定義數據集。
1. 數據集準備
數據集包含7個類別的圖片,每個類別對應一個《海賊王》的角色:
- 路飛(lufei)
- 羅賓(luobin)
- 娜美(namei)
- 喬巴(qiaoba)
- 山治(shanzhi)
- 索隆(suolong)
- 烏索普(wusuopu)
每個角色有不同數量的圖片,總共621張圖片。
(1)導入必要的庫和設置隨機種子
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
import pathlib
import matplotlib.pyplot as plt
import os, PILnp.random.seed(1)
tf.random.set_seed(1)
#導入所需的Python庫,并設置隨機種子以確保實驗的可重復性。(2)設置數據目錄和參數
data_dir = r"D:\hzw_photos"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.png')))
print("圖片總數為:", image_count)batch_size = 32
img_height = 224
img_width = 224#作用:指定數據集路徑、統計圖片總數,并定義批量大小和圖片尺寸。
#運行結果:輸出圖片總數(621張)。(3)加載訓練集和驗證集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size
)val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size
)
#作用:從指定目錄加載圖像數據集,并將其分為訓練集和驗證集。validation_split=0.2表示20%的數據用于驗證,其余80%用于訓練。
#運行結果:打印出找到的文件數量和類別信息。(4)獲取類別名稱
class_names = train_ds.class_names
print(class_names)
#作用:獲取并打印數據集中所有類別的名稱。
#運行結果:輸出類別名稱列表:['lufei', 'luobin', 'namei', 'qiaoba', 'shanzhi', 'suolong', 'wusuopu']。(5)可視化數據
plt.figure(figsize=(10, 5))
for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")
plt.show()
#作用:從訓練集中隨機選取一批圖像進行可視化展示。
#運行結果:顯示8張隨機選擇的圖像及其對應的標簽。
2. 數據預處理
(1)配置數據集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
#作用:對數據集進行緩存、打亂和預取操作,以提高數據讀取效率。
#運行結果:無直接輸出,但優化了數據加載過程。(2)歸一化處理
normalization_layer = tf.keras.layers.Rescaling(1. / 255)
train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]
print("歸一化后數據范圍:", np.min(first_image), np.max(first_image))
#作用:將圖像像素值歸一化到[0, 1]區間內。
#運行結果:輸出歸一化后的數據范圍(0.0到0.9928046),表明歸一化操作成功。3. 模型構建
VGG-16 是一種經典的卷積神經網絡(CNN)架構,通過堆疊多個卷積層和池化層來提取圖像特征,最后通過全連接層進行分類。以其簡單的結構和深度而聞名,尤其在圖像分類任務中表現出色。
定義VGG-16模型
def VGG16(nb_classes, input_shape):# 構建VGG-16模型...return model
#作用:定義一個自定義的VGG-16模型,包括多個卷積層和全連接層。
#運行結果:無直接輸出,但生成了一個可以使用的模型結構。(1)?輸入層
input_tensor = layers.Input(shape=input_shape)
#input_shape 輸入圖像的形狀,通常為 (height, width, channels),例如 (224, 224, 3) 表示 224x224 像素的 RGB 圖像
#Input 層定義了模型的輸入張量。
(2)卷積塊 1
x = layers.Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input_tensor)
x = layers.Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
#兩個 Conv2D 層,每個層使用 64 個 3x3 的卷積核,激活函數為 ReLU,padding='same' 表示輸出特征圖的大小與輸入相同。
#MaxPooling2D 層使用 2x2 的池化窗口,步幅為 2,將特征圖的大小減半。
#輸入圖像(224×224×3)
#→ 經過64個3×3卷積核提取特征(輸出224×224×64)
#→ 再次卷積增強特征(保持尺寸)
#→ 2×2最大池化(輸出112×112×64)(3)卷積塊 2
x = layers.Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = layers.Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
#與第一個卷積塊類似,但卷積核數量增加到 128。(4)?卷積塊 3
x = layers.Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = layers.Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = layers.Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
#卷積核數量增加到 256,并且有三個卷積層。(5)卷積塊 4
x = layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
#卷積核數量增加到 512,同樣有三個卷積層。(6)卷積塊 5
x = layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
#與卷積塊 4 相同,卷積核數量保持為 512。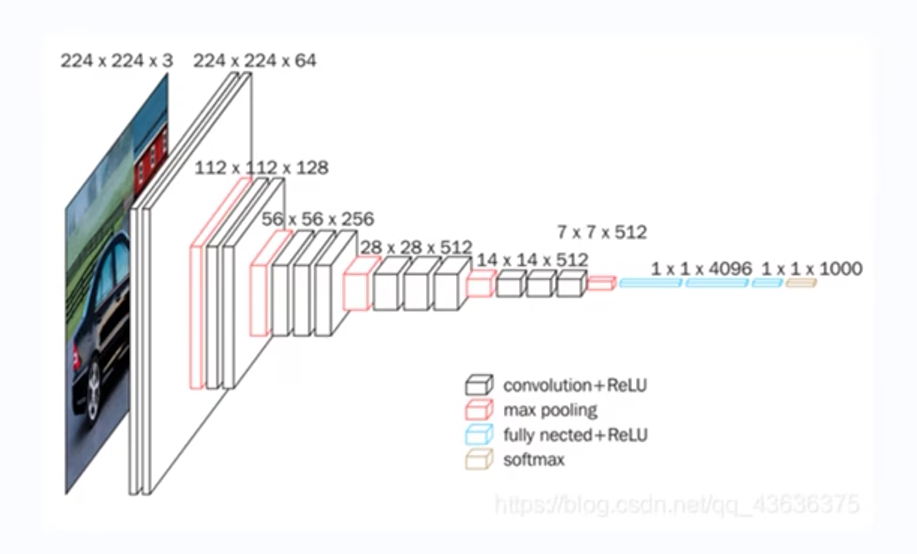
| 塊編號 | CONV層數量 | 輸出尺寸 | 通道數 | 作用 |
|---|---|---|---|---|
| 1 | 2 | 112×112 | 64 | 提取邊緣/顏色等低級特征 |
| 2 | 2 | 56×56 | 128 | 捕獲紋理/簡單形狀 |
| 3 | 3 | 28×28 | 256 | 識別復雜圖案(如草帽輪廓) |
| 4 | 3 | 14×14 | 512 | 檢測角色局部特征(娜美的頭發等) |
| 5 | 3 | 7×7 | 512 | 整合全局語義信息 |
(7)?全連接層
x = layers.Flatten()(x)
x = layers.Dense(4096, activation='relu', name='fc1')(x)
x = layers.Dense(4096, activation='relu', name='fc2')(x)
output_tensor = layers.Dense(nb_classes, activation='softmax', name='predictions')(x)
#Flatten 層將多維特征圖展平為一維向量。
#兩個 Dense 層,每個層有 4096 個神經元,激活函數為 ReLU。
#最后的 Dense 層輸出類別概率,使用 softmax 激活函數,nb_classes 是類別數量。(8)構建模型
model = models.Model(input_tensor, output_tensor)
#使用 Model 類將輸入張量和輸出張量組合成模型。(9)初始化模型
model = VGG16(nb_classes=7, input_shape=(img_width, img_height, 3))
model.summary()
#作用:初始化VGG-16模型,并打印模型結構摘要。
#運行結果:輸出模型各層的詳細信息,包括層名、輸出形狀和參數數量等。輸入圖像 → [CONV→POOL]×5 → 展平 → FC×2 → 分類輸出
? ? ? ? ? ? ? ? ? ? ? ? (特征提取)? ? ? ? ? ? ? ? ? ? ? ? ? ?(決策)
4. 模型編譯與訓練
編譯模型
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(optimizer=opt,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['accuracy']
)
#作用:配置模型的優化器、損失函數和評估指標。訓練模型
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
#作用:在訓練集上訓練模型,并在每個epoch結束后評估驗證集上的性能。
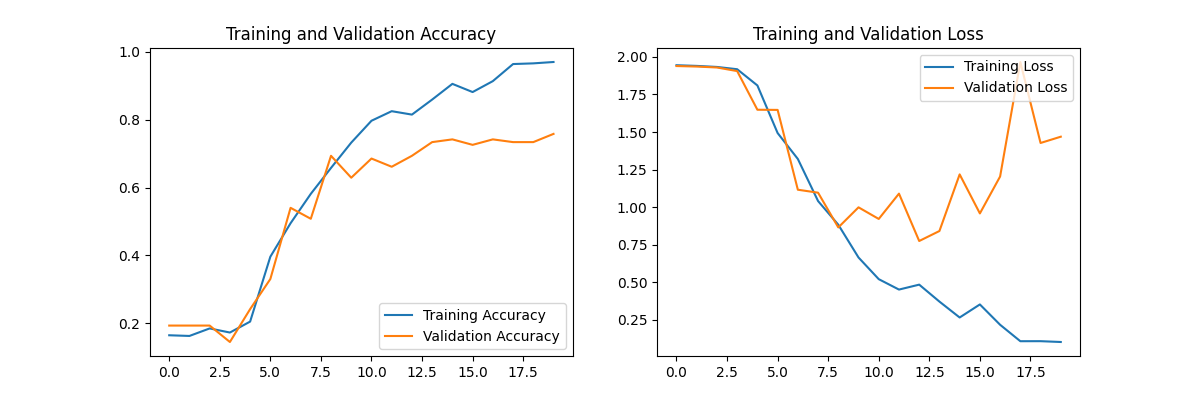
#運行結果:輸出每個epoch的訓練準確率、訓練損失、驗證準確率和驗證損失。5. 結果分析
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(epochs), acc, label='Training Accuracy')
plt.plot(range(epochs), val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(range(epochs), loss, label='Training Loss')
plt.plot(range(epochs), val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
#作用:繪制訓練和驗證過程中的準確率及損失變化曲線。
#運行結果:顯示兩個子圖,分別表示準確率和損失的變化趨勢。
?
- 訓練準確率和驗證準確率都隨著訓練輪數的增加而上升,表明模型逐漸學習到了數據的特征。
- 訓練損失和驗證損失則逐漸下降,說明模型的預測誤差在減小。
圖片總數為: 621
Found 621 files belonging to 7 classes.
Using 497 files for training.
Found 621 files belonging to 7 classes.
Using 124 files for validation.
['lufei', 'luobin', 'namei', 'qiaoba', 'shanzhi', 'suolong', 'wusuopu']
歸一化后數據范圍: 0.0 0.9928046
Model: "functional"
┌─────────────────────────────────┬────────────────────────┬───────────────┐
│ Layer (type) ? ? ? ? ? ? ? ? ? ?│ Output Shape ? ? ? ? ? │ ? ? ? Param # │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ input_layer (InputLayer) ? ? ? ?│ (None, 224, 224, 3) ? ?│ ? ? ? ? ? ? 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block1_conv1 (Conv2D) ? ? ? ? ? │ (None, 224, 224, 64) ? │ ? ? ? ? 1,792 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block1_conv2 (Conv2D) ? ? ? ? ? │ (None, 224, 224, 64) ? │ ? ? ? ?36,928 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block1_pool (MaxPooling2D) ? ? ?│ (None, 112, 112, 64) ? │ ? ? ? ? ? ? 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block2_conv1 (Conv2D) ? ? ? ? ? │ (None, 112, 112, 128) ?│ ? ? ? ?73,856 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block2_conv2 (Conv2D) ? ? ? ? ? │ (None, 112, 112, 128) ?│ ? ? ? 147,584 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block2_pool (MaxPooling2D) ? ? ?│ (None, 56, 56, 128) ? ?│ ? ? ? ? ? ? 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block3_conv1 (Conv2D) ? ? ? ? ? │ (None, 56, 56, 256) ? ?│ ? ? ? 295,168 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block3_conv2 (Conv2D) ? ? ? ? ? │ (None, 56, 56, 256) ? ?│ ? ? ? 590,080 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block3_conv3 (Conv2D) ? ? ? ? ? │ (None, 56, 56, 256) ? ?│ ? ? ? 590,080 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block3_pool (MaxPooling2D) ? ? ?│ (None, 28, 28, 256) ? ?│ ? ? ? ? ? ? 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block4_conv1 (Conv2D) ? ? ? ? ? │ (None, 28, 28, 512) ? ?│ ? ? 1,180,160 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block4_conv2 (Conv2D) ? ? ? ? ? │ (None, 28, 28, 512) ? ?│ ? ? 2,359,808 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block4_conv3 (Conv2D) ? ? ? ? ? │ (None, 28, 28, 512) ? ?│ ? ? 2,359,808 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block4_pool (MaxPooling2D) ? ? ?│ (None, 14, 14, 512) ? ?│ ? ? ? ? ? ? 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block5_conv1 (Conv2D) ? ? ? ? ? │ (None, 14, 14, 512) ? ?│ ? ? 2,359,808 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block5_conv2 (Conv2D) ? ? ? ? ? │ (None, 14, 14, 512) ? ?│ ? ? 2,359,808 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block5_conv3 (Conv2D) ? ? ? ? ? │ (None, 14, 14, 512) ? ?│ ? ? 2,359,808 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ block5_pool (MaxPooling2D) ? ? ?│ (None, 7, 7, 512) ? ? ?│ ? ? ? ? ? ? 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten (Flatten) ? ? ? ? ? ? ? │ (None, 25088) ? ? ? ? ?│ ? ? ? ? ? ? 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ fc1 (Dense) ? ? ? ? ? ? ? ? ? ? │ (None, 4096) ? ? ? ? ? │ ? 102,764,544 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ fc2 (Dense) ? ? ? ? ? ? ? ? ? ? │ (None, 4096) ? ? ? ? ? │ ? ?16,781,312 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ predictions (Dense) ? ? ? ? ? ? │ (None, 7) ? ? ? ? ? ? ?│ ? ? ? ?28,679 │
└─────────────────────────────────┴────────────────────────┴───────────────┘Total params: 134,289,223 (512.27 MB)Trainable params: 134,289,223 (512.27 MB)Non-trainable params: 0 (0.00 B)
Epoch 1/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 207s 13s/step - accuracy: 0.1736 - loss: 1.9444 - val_accuracy: 0.1935 - val_loss: 1.9390
Epoch 2/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 216s 14s/step - accuracy: 0.1594 - loss: 1.9357 - val_accuracy: 0.1935 - val_loss: 1.9355
Epoch 3/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 195s 12s/step - accuracy: 0.1656 - loss: 1.9362 - val_accuracy: 0.1935 - val_loss: 1.9293
Epoch 4/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 208s 13s/step - accuracy: 0.1749 - loss: 1.9240 - val_accuracy: 0.1452 - val_loss: 1.9054
Epoch 5/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 214s 13s/step - accuracy: 0.1787 - loss: 1.8650 - val_accuracy: 0.2419 - val_loss: 1.6483
Epoch 6/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 202s 13s/step - accuracy: 0.3046 - loss: 1.5703 - val_accuracy: 0.3306 - val_loss: 1.6471
Epoch 7/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 198s 13s/step - accuracy: 0.4451 - loss: 1.4282 - val_accuracy: 0.5403 - val_loss: 1.1161
Epoch 8/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 179s 11s/step - accuracy: 0.6045 - loss: 1.0102 - val_accuracy: 0.5081 - val_loss: 1.0964
Epoch 9/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 166s 11s/step - accuracy: 0.6386 - loss: 0.9255 - val_accuracy: 0.6935 - val_loss: 0.8652
Epoch 10/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 162s 10s/step - accuracy: 0.7404 - loss: 0.6550 - val_accuracy: 0.6290 - val_loss: 0.9989
Epoch 11/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 185s 11s/step - accuracy: 0.8052 - loss: 0.5281 - val_accuracy: 0.6855 - val_loss: 0.9217
Epoch 12/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 185s 12s/step - accuracy: 0.8136 - loss: 0.4523 - val_accuracy: 0.6613 - val_loss: 1.0901
Epoch 13/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 193s 12s/step - accuracy: 0.8089 - loss: 0.4674 - val_accuracy: 0.6935 - val_loss: 0.7750
Epoch 14/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 192s 12s/step - accuracy: 0.8577 - loss: 0.3848 - val_accuracy: 0.7339 - val_loss: 0.8414
Epoch 15/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 185s 12s/step - accuracy: 0.9164 - loss: 0.2603 - val_accuracy: 0.7419 - val_loss: 1.2181
Epoch 16/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 223s 14s/step - accuracy: 0.8789 - loss: 0.4077 - val_accuracy: 0.7258 - val_loss: 0.9584
Epoch 17/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 236s 15s/step - accuracy: 0.9123 - loss: 0.2405 - val_accuracy: 0.7419 - val_loss: 1.2041
Epoch 18/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 236s 15s/step - accuracy: 0.9637 - loss: 0.1224 - val_accuracy: 0.7339 - val_loss: 1.9659
Epoch 19/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 226s 14s/step - accuracy: 0.9677 - loss: 0.0793 - val_accuracy: 0.7339 - val_loss: 1.4271
Epoch 20/20
16/16 ━━━━━━━━━━━━━━━━━━━━ 224s 14s/step - accuracy: 0.9548 - loss: 0.1205 - val_accuracy: 0.7581 - val_loss: 1.4689
#指標 訓練集變化 驗證集變化 結論
#準確率 17.4% → 95.5% (↑78.1%) 19.4% → 75.8% (↑56.4%) 模型學習有效,但存在明顯過擬合
#損失值 1.94 → 0.12 (↓93.8%) 1.94 → 1.47 (↓24.2%) 訓練損失下降過快,驗證損失震蕩進程已結束,退出代碼為 0
6.從深度學習展開分析
(1)特征學習的革命性突破
傳統方法 vs 深度學習
-
傳統CV方案:
草帽、發型等特征難以用數學公式描述? ?不同姿勢/角度下特征穩定性差
需要手工設計特征(如HOG描述子、顏色直方圖),但對于動漫人物: -
深度學習方案:
VGG-16通過卷積層自動學習層次化特征:
底層特征(前幾層):邊緣/顏色 → 識別路飛的草帽紅色邊緣
中層特征:紋理/部件 → 組合出索隆的三把刀輪廓
高層特征:全局語義 → 理解"娜美的橘色頭發+身體比例"這種復合特征
(2)處理圖像數據的先天優勢
-
空間不變性:
-
通過卷積核共享機制,無論路飛出現在圖像左上角還是右下角都能被識別
-
池化層使模型對小幅位移/旋轉具有魯棒性(適合動漫截圖角度多變的特點)
-
-
通道維度理解:
-
RGB三通道自動提取色彩特征(如喬巴的粉色帽子、山治的金發)
-
相比灰度圖,保留關鍵顏色線索
-
-
感受野遞進:
-
從3×3小窗口逐步擴大到全圖感知(最終7×7的特征圖對應原圖約200×200像素區域)
-
這種機制天然適配"從局部到整體"的認知邏輯
-
(3)端到端訓練的便捷性
傳統流程:
圖像預處理 → 特征工程 → 分類器設計 → 結果優化(需分步調試)
深度學習流程:
原始圖片輸入 → VGG網絡 → 分類結果
所有優化自動完成
(4)針對動漫數據的特殊適配能力
-
風格化特征處理:
-
動漫人物線條鮮明、用色大膽,與真實照片差異大
-
CNN通過多層非線性變換,能更好捕捉這種藝術化表達
-
-
跨角色泛化:
-
即使訓練集沒有"戴草帽的羅賓"這類異常組合,模型也能通過:
-
低層學到的"草帽特征"
-
高層學到的"羅賓面部特征"
-
-
組合推理出未知變體(比傳統方法更具泛化潛力)
-
(5)延伸應用場景
這套技術方案稍加調整即可用于:
-
動漫產業:自動標注動畫分鏡中的人物出場
-
游戲開發:玩家上傳截圖自動識別角色陣容
-
周邊電商:拍照搜索手辦/服飾對應的
七、總結
在本案例中,深度學習的作用本質是:
通過多層非線性變換,自動從像素中學習到海賊王角色的抽象特征表達,并建立這些特征與人物類別的映射關系。其價值不在于替代人類認知,而是將人類難以顯式描述的視覺模式(比如"如何定義喬巴的可愛感")編碼成可優化的數學表示。未來結合注意力機制等新技術,還可進一步接近人類的分辨能力。
![[創業之路-377]:企業戰略管理案例分析-戰略制定/設計-市場洞察“五看”:看宏觀之社會發展趨勢:數字化、智能化、個性化的趨勢對初創公司的戰略機會](http://pic.xiahunao.cn/[創業之路-377]:企業戰略管理案例分析-戰略制定/設計-市場洞察“五看”:看宏觀之社會發展趨勢:數字化、智能化、個性化的趨勢對初創公司的戰略機會)








)
)


)



)

