一、演員評論家算法核心思想和原理
演員(actor)代表策略,評論家代表價值函數。演員評論家算法是基于價值和策略的綜合性方法。具體來說該算法使用了策略梯度和時序差分方法,是二者的一種有機結合。
1. 主要思想
策略梯度算法以軌跡為單位更新,樣本方差大,學習效率低。
時序差分中,價值函數以時間步為單位更新,思想可以借鑒。
2. 模型結構
基于期望的優勢函數既能實現時序差分迭代,又讓訓練更加穩定。
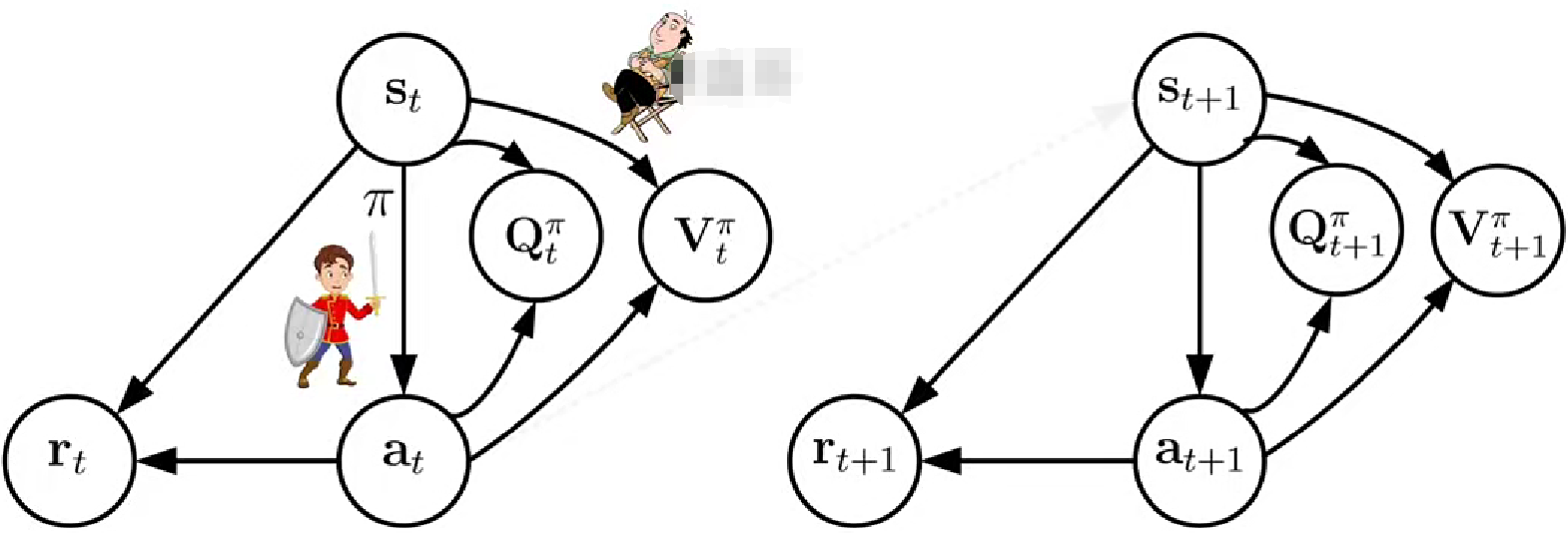
2.1 深度演員評論家算法
策略網絡:π網絡
價值網絡:Q網絡+V網絡
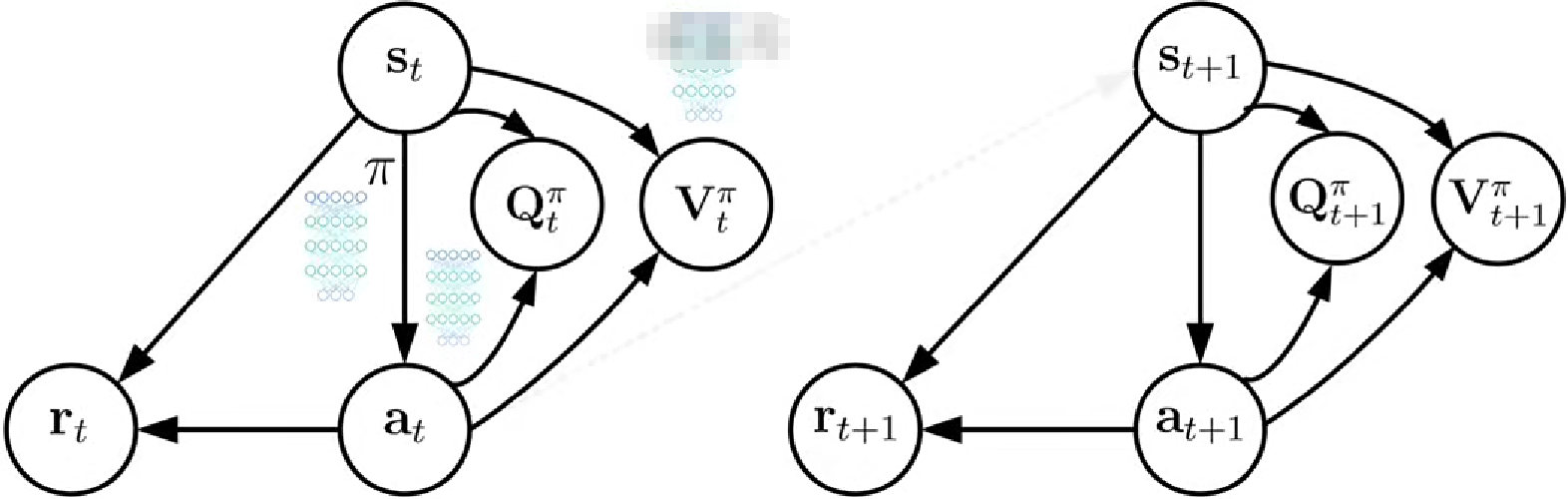
3. 演員評論家算法適用條件
連續狀態空間:高維圖像處理或機器人控制
離散動作空間:每個時間步,從固定動作集中選擇動作
梯度可以計算:通過梯度更新策略網絡的參數
獎勵信號可用:可以由環境提供,也可以由設計者定義
數據效率要求低:通常需要更多訓練樣本
二、改進型演員評論家算法
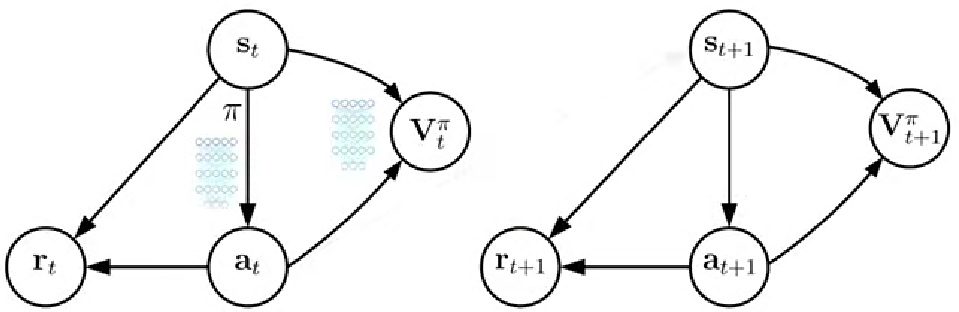
1. 優勢演員評論家算法(A2C)
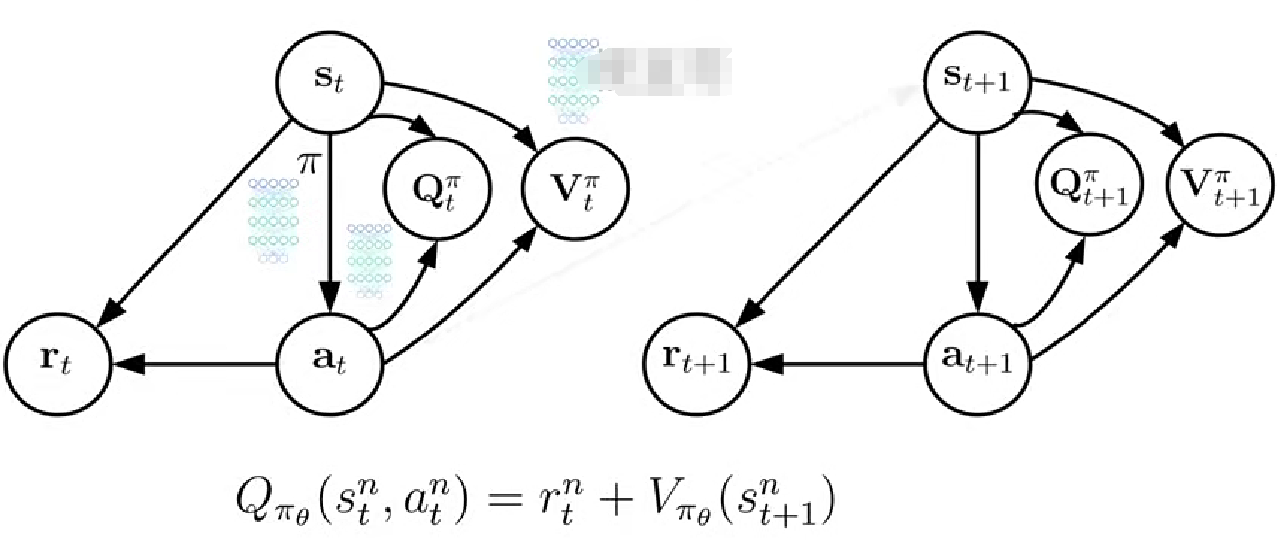
優勢函數衡量給定狀態下選擇某個動作相對平均預期回報的優勢價值,相對于值函數的整體估計,提供了更精細的價值估計,能夠量化特定的動作相對于平均水平的價值優勢,能更好地用于動作選擇和策略改進。省去了Q結點
 2. 異步優勢演員評論家算法(A3C)
2. 異步優勢演員評論家算法(A3C)
通過并行運算來提高訓練的速度,因為多數的強化學習訓練過程都比較慢。A3C是在A2C的基礎上進一步改進。
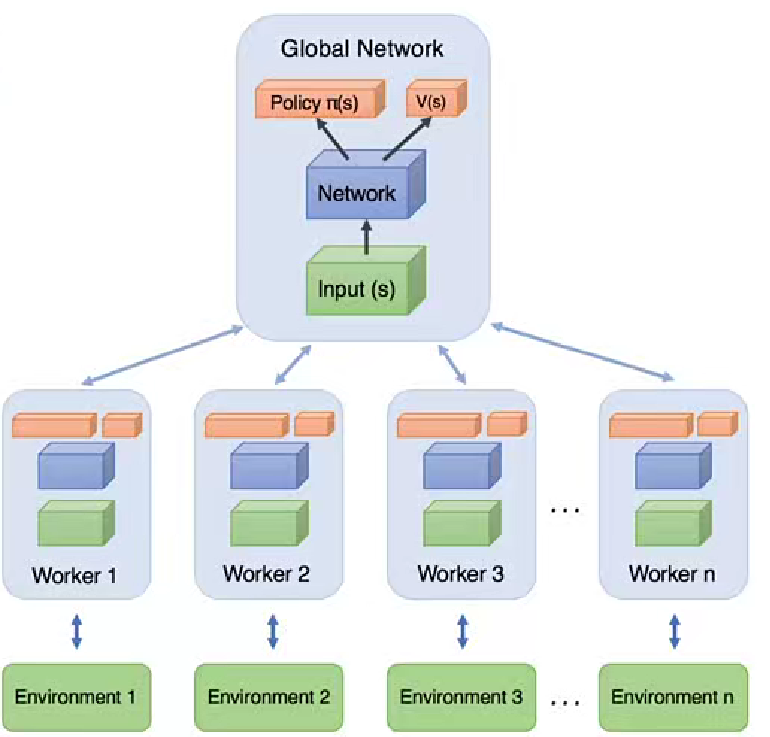
2.1 網絡結構圖
第一部分:Global Network是整個算法的核心,目標是學習策略和價值函數的參數。
第二部分:works是工作器,A3C算法采用異步并行方式進行訓練,其中每個工作器都有一個本地的神經網絡副本。獨立和環境交互收集經驗數據,并用于更新全局網絡。每個工作器都有自己的經驗池,來存儲其收集的經驗數據。
第三部分:策略網絡Policy Network,屬于演員的角色,負責選擇動作接收s作為輸入。并輸出動作的概率分布。
最后一部分是價值函數網絡,value function network屬于critic部分,用于估計狀態的價值。狀態作為輸入并作為狀態值的估計。再之后是優勢函數計算模塊,根據值函數和策略網絡的輸出,使用優勢函數來計算每個動作的優勢,用于計算策略梯度和作為目標值進行值函數的訓練。
整體而言,A3C算法是一種分布式的體系結構,通過異步更新和參數共享的方式實現高效的并行訓練。
三、深度確定性策略梯度DDPG
Deep Deterministic Policy Gradient
演員評論家方法,為解決馬爾科夫決策過程提供了一種綜合而
全面的框架。其用神經網絡同時逼近了策略函數和價值函數,不過無論是A2C還是A3C,他們在離散動作空間這樣的任務當中應用比較多。DDPG著重解決了連續動作空間的問題,和可以進行離散的異策略優化。
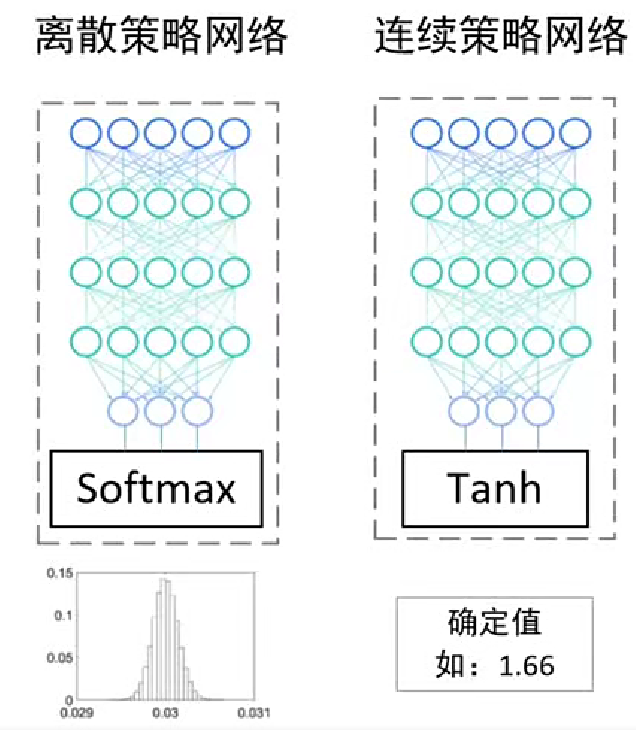
1. 離散動作和連續動作
離散動作空間中動作有限且離散,通常用隨機性描述動作![]()
連續動作空間中動作是連續的,直接輸出確定值來控制行為![]()
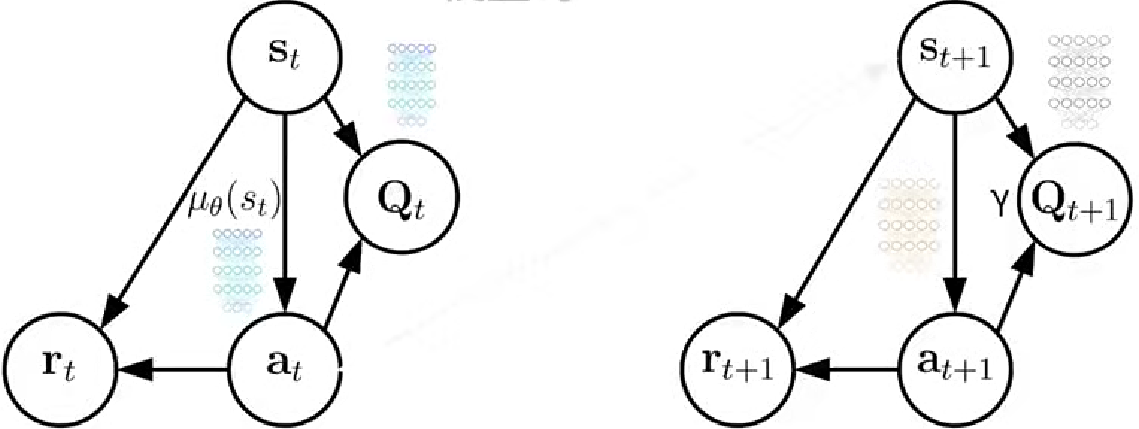
2. 模型結構
相對于A2C價值結點從V變成了Q,采用了動作價值函數Q(s,a),用深度神經網絡逼近策略分布。使用了四個網絡:策略網絡及下一時刻的目標網絡,價值網絡及下一時刻的目標網絡。?
 ?3. DDPG適用條件
?3. DDPG適用條件
連續動作空間:在處理連續控制問題中有優勢
模型無關性:適用于實際應用中缺乏準確環境模型的情況
高維狀態空間:能夠處理復雜的狀態表示? ?



)





)
相關函數)
)







