一、數據倉庫的由來
數據倉庫(Data Warehouse, DW)概念的誕生源于企業對數據價值的深度挖掘需求。在1980年代,隨著OLTP(聯機事務處理)系統在企業中的普及,傳統關系型數據庫在處理海量數據分析時顯露出明顯瓶頸:事務處理與分析查詢的沖突、數據孤島現象嚴重、歷史數據利用率低下等問題日益突出。
1991年,Bill Inmon在《Building the Data Warehouse》中首次明確定義了數據倉庫:"面向主題的、集成的、非易失的且隨時間變化的數據集合,用于支持管理決策"。這標志著數據倉庫從理論走向實踐。隨后Ralph Kimball提出維度建模理論,與Inmon的企業級數據倉庫架構形成兩大主流方法論,奠定了現代數據倉庫體系的基礎。
二、數據倉庫的核心應用場景
- 決策支持系統(DSS)
- 通過整合多源異構數據(ERP/CRM/日志系統等)
- 構建統一分析視圖支撐戰略決策
- 典型案例:沃爾瑪"啤酒與尿布"的關聯分析
- 商業智能(BI)平臺
- Tableau/Power BI等工具的數據底座
- 支持靈活的多維分析(OLAP)
- 某銀行通過客戶360°視圖提升交叉銷售率23%
- 客戶行為分析
- 構建用戶畫像標簽體系
- 支撐精準營銷與個性化推薦
- 電商平臺基于購買歷史實現實時商品推薦
- 實時運營監控
- 物聯網數據流處理(如智能制造)
- 金融交易反欺詐實時預警
- 某運營商實現網絡故障分鐘級定位
三、主流技術實現方案
架構演進
| 架構類型 | 代表方案 | 核心特征 |
| 傳統離線數倉 | Teradata/Oracle Exadata | 集中式架構,MPP并行處理 |
| 大數據數倉 | Hadoop+Hive/Spark | 分布式計算,高擴展性 |
| 云原生數倉 | Snowflake/Redshift | 存算分離,彈性伸縮 |
| 實時數倉 | Apache Flink+Doris | 流批一體,亞秒級響應 |
一個典型的傳統離線數據倉庫架構如下
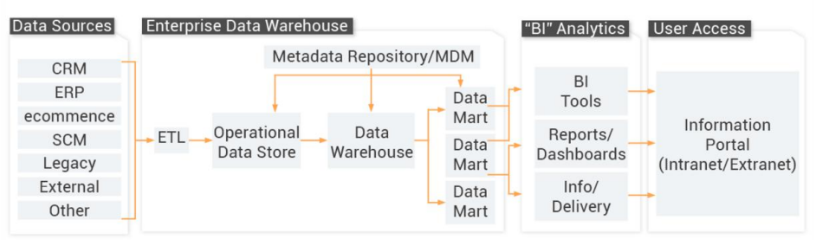
缺點:
- ETL過程所占成本過高
- 數據處理鏈路過長
- 只能T+1模式,無法支持實時/近實時數據分析
Lambda 架構
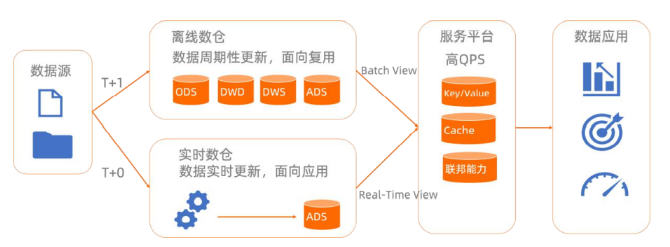
缺點:
- 一種邏輯兩套代碼,開發運維難
- 服務器存儲開銷大
- 實時和批量結果不一致引起的沖突
關鍵技術組件
- ETL/ELT工具鏈:Apache Nifi/Airflow構建數據管道
- 存儲引擎:列式存儲(Parquet/ORC)提升壓縮比
- 計算引擎:Spark SQL/Presto實現交互式查詢
- 元數據管理:Apache Atlas構建數據血緣
- 質量管控:Great Expectations自動化校驗
典型行業方案
- 金融領域:Lambda架構實現T+0監管報送
- 新零售:Delta Lake構建實時庫存預警系統
- 工業互聯網:TimescaleDB處理時序數據分析
四、未來發展趨勢
- 實時化能力升級
- 流批融合架構成為標配(如Apache Pulsar+Iceberg)
- 復雜事件處理(CEP)技術深化應用
- 某證券公司的交易風控延遲從分鐘級降至毫秒級
- 智能化數據管理
- AI驅動自動優化(自動索引/分區策略)
- 增強分析(Augmented Analytics)技術
- Google BigQuery ML實現模型訓練直連數倉
- 湖倉一體化(Lakehouse)
- Databricks Delta Engine統一數據湖與數倉
- 支持ACID事務與版本控制
- 微軟Fabric平臺實現多模態數據統一治理
- 云原生深度演進
- Serverless架構降低運維復雜度
- 多云協同架構保障數據主權
- Snowflake跨云數據共享打破信息孤島
- 增強型數據治理
- 自動化數據編目(AutoML數據發現)
- 隱私計算與數據脫敏深度集成
- 螞蟻集團Morse隱私SQL保護敏感數據
)





)







)

)
樣式配置、漸變色生成)

