今天深入探討如何構建更強大的序列到序列模型,特別是Seq2Seq架構。序列到序列模型,顧名思義,它的核心任務就是將一個序列映射到另一個序列。這個序列可以是文本,也可以是其他符號序列。最早,人們嘗試用一個單一的RNN來搞定整個序列到序列的任務,比如直接讓RNN讀完中文句子,然后輸出英文句子。但很快發現,效果不理想。為什么呢?因為RNN在處理長序列時,就像一個記憶力有限的學者,讀到后面可能就忘了前面的內容了。梯度消失、梯度爆炸問題,以及它捕捉長距離依賴的能力不足,使得信息在處理過程中容易丟失或混淆。
編碼器-解碼器架構
為了解決這個問題,研究人員提出了序列到序列模型的基石——編碼器-解碼器架構。這個想法非常巧妙:我們不再用一個RNN來處理所有事情,而是把它分成兩個獨立的部分。
- 一部分負責編碼器,專門負責讀取輸入序列,比如中文,然后把它壓縮成一個濃縮的精華,也就是一個固定大小的向量。
- 另一部分負責解碼器,接收這個精華向量,然后像一個翻譯官一樣,根據這個向量,逐步生成輸出序列,比如英文。這樣分工合作,信息就更容易被完整地保存和傳遞了。
整個過程就像一個翻譯機,先把原文翻譯成一種通用語,再從通用語翻譯成目標語言。
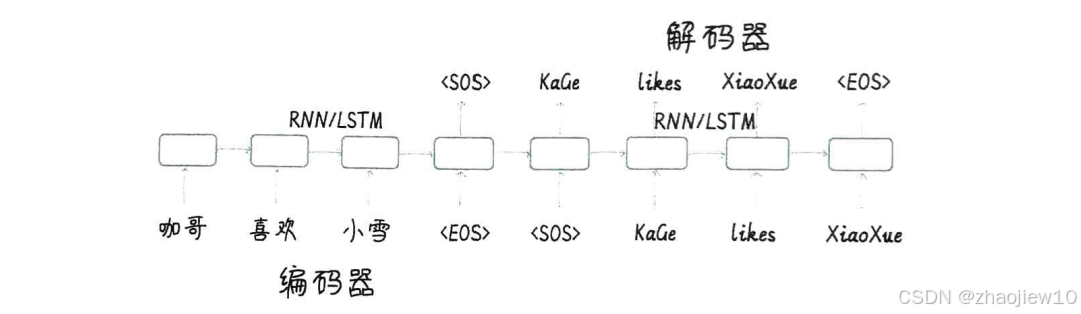
上圖更具體地展示了基于RNN或LSTM的Seq2Seq模型。左邊是輸入序列,比如咖哥喜歡小雪,后面可能加了個EOS標記表示結束。右邊是輸出序列,比如KaGe likes XiaoXue,同樣有EOS。注意**,輸入序列的開頭通常會加上一個特殊的SOS符號,表示序列開始**。解碼器在生成每個詞的時候,會依賴于之前的詞和當前的上下文狀態,所以輸出序列的開頭也用SOS標記。模型中間就是兩個RNN或LSTM單元,分別負責編碼和解碼。
我們再細看一下這兩個核心組件。
- 編碼器,它的任務是吃進去一個完整的輸入序列,比如中文句子,然后通過內部的RNN、LSTM或者GRU等機制,一步步處理,最終吐出一個濃縮的、固定大小的向量。這個向量,我們稱之為上下文向量,它包含了整個輸入序列的所有信息。
- 解碼器,接收這個上下文向量作為起點,然后也開始一步步處理,生成一個輸出序列。
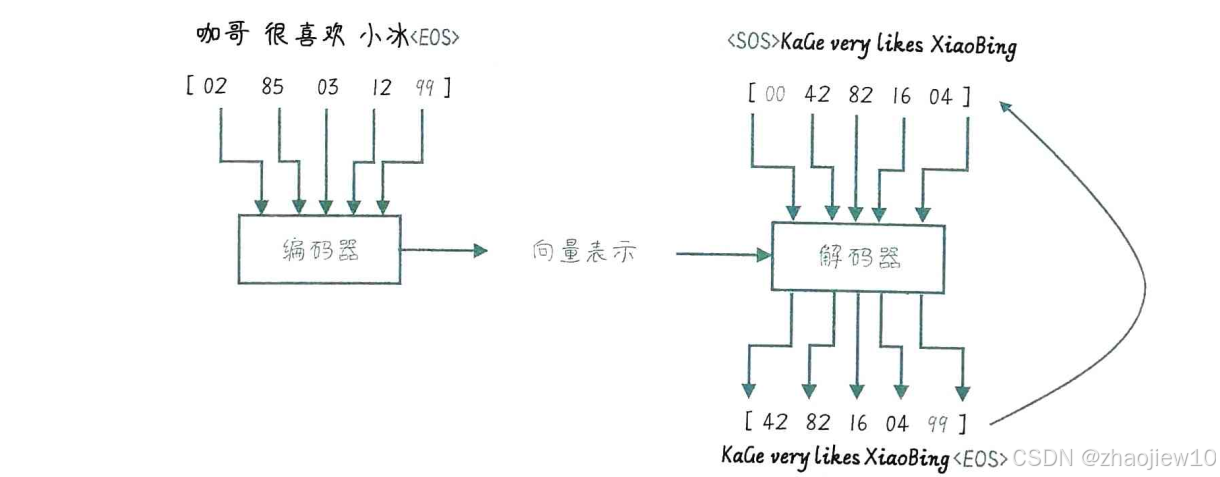
左邊是中文句子咖哥很喜歡小冰,經過編碼器處理,變成了一個向量,比如02 85 03 12 99。這個向量就是編碼器的輸出。然后,這個向量被傳遞給右邊的解碼器,解碼器根據這個向量,逐步生成英文句子KaGe very likes XiaoBing。注意,解碼器的輸出是逐個詞生成的,直到遇到EOS結束標記。整個過程就是從輸入序列到向量,再到輸出序列的完整映射。
所以,我們可以這樣總結Seq2Seq的核心思想:它本質上是一個壓縮與解壓縮的過程。輸入序列被壓縮成一個緊湊的向量,然后這個向量被解壓縮成輸出序列。這個壓縮和解壓縮的過程,通常由RNN、LSTM或GRU等序列建模方法來實現。
特別要注意的是,解碼器在生成序列時,它不是一次性生成所有詞,而是一個詞一個詞地生成,而且當前生成的詞,會作為下一個詞的輸入,這就是所謂的自回歸特性。這種特性使得模型能夠更好地處理序列的生成任務。
Seq2Seq架構有幾個非常重要的特點。
- 非常靈活,能夠處理輸入和輸出序列長度不等的情況。比如,一個中文句子可能對應一個很長的英文句子,或者一個長句子對應一個短摘要。
- 它組件可以替換。編碼器和解碼器可以選用不同的RNN變體,比如LSTM、GRU,甚至可以引入更復雜的結構,比如Transformer。
- 具有很好的擴展性。我們可以在這個基礎上,進一步添加注意力機制等組件,來提升模型在處理長序列和復雜語境時的能力。
Seq2Seq模型實踐
理論講完了,我們來動手實踐一下。我們來構建一個簡單的Seq2Seq模型,讓它能夠學習如何把中文翻譯成英文。
- 構建實驗語料庫和詞匯表
- 生成Seq2Seq訓練數據
- 定義編碼器和解碼器類
- 定義Seq2Seq架構
- 訓練Seq2Seq架構
- 測試Seq2Seq架構
數據準備
數據準備。我們需要一個包含中文和英文句子對的語料庫。
sentences = [['咖哥 喜歡 小冰', '<sos> KaGe likes XiaoBing', 'KaGe likes XiaoBing <eos>'],['我 愛 學習 人工智能', '<sos> I love studying AI', 'I love studying AI <eos>'],['深度學習 改變 世界', '<sos> DL changed the world', 'DL changed the world <eos>'],['自然 語言 處理 很 強大', '<sos> NLP is so powerful', 'NLP is so powerful <eos>'],['神經網絡 非常 復雜', '<sos> Neural-Nets are complex', 'Neural-Nets are complex <eos>']]
有了語料庫,我們還需要構建詞匯表。我們需要知道每個詞對應的編號。我們分別創建一個中文詞匯表和一個英文詞匯表,把所有出現的詞都收集起來。然后,為每個詞分配一個唯一的編號,也就是索引。同時,我們還要創建一個反向索引,知道每個編號對應哪個詞。這樣,模型就能把文本轉換成數字序列,方便神經網絡處理。
中文詞匯到索引的字典: {'神經網絡': 0, '小冰': 1, '人工智能': 2, '復雜': 3, '我': 4, '處理': 5, '改變': 6, '深度學習': 7, '強大': 8, '咖哥': 9, '世界': 10, '學習': 11, '自然': 12, '語言': 13, '很': 14, '非常': 15, '愛': 16, '喜歡': 17}英文詞匯到索引的字典: {'are': 0, 'the': 1, 'NLP': 2, 'XiaoBing': 3, 'I': 4, 'so': 5, 'complex': 6, '<sos>': 7, 'studying': 8, 'KaGe': 9, 'DL': 10, 'AI': 11, 'love': 12, 'is': 13, 'world': 14, 'Neural-Nets': 15, 'changed': 16, 'powerful': 17, '<eos>': 18, 'likes': 19}
生成Seq2Seq訓練數據
我們需要把剛才的語料庫轉換成模型可以直接使用的訓練數據。具體來說,就是把每個句子的中文單詞、帶sos的英文單詞和帶eos的英文單詞都轉換成對應的索引序列。然后,把這些索引序列轉換成PyTorch的LongTensor張量格式。
原始句子: ['我 愛 學習 人工智能', '<sos> I love studying AI', 'I love studying AI <eos>']
編碼器輸入張量的形狀: torch.Size([1, 4])
解碼器輸入張量的形狀: torch.Size([1, 5])
目標張量的形狀: torch.Size([1, 5])編碼器輸入張量: tensor([[ 5, 13, 10, 4]]) # 每個詞查索引表
解碼器輸入張量: tensor([[17, 14, 12, 18, 9]])
目標張量: tensor([[14, 12, 18, 9, 16]])
這個函數每次調用,都會返回一個批次的訓練數據。這個函數的輸出結果是這樣的:encoder_input 是中文句子的索引張量,decoder_input 是帶 <sos> 的英文句子的索引張量,target 是帶 <eos> 的英文句子的索引張量。注意 decoder_input 和 target 的區別在于 <sos> 和 <eos> 的位置。decoder_input 用于訓練解碼器,而 target 用于計算損失。這個 decoder_input 里面包含了真實的目標序列,這其實是教師強制的體現。
這里提到了一個重要的概念:教師強制。簡單來說,就是在訓練解碼器的時候,我們給它喂的是真實答案。具體來說,就是把目標序列的英文單詞,除了最后一個 <eos>,都作為輸入給解碼器。這樣做是為了讓模型更快地學習到正確的翻譯路徑。但是,這也會帶來一個問題:模型在訓練時依賴了真實答案,但在實際應用中,它只能自己生成下一個詞,這就可能造成訓練和測試時的分布不一致,也就是所謂的曝光偏差。為了解決這個問題,可以使用計劃采樣,讓模型在訓練過程中逐漸適應自己生成的詞。
定義編碼器和解碼器類
我們開始構建神經網絡模型了。
import torch.nn as nn # 導入 torch.nn 庫
# 定義編碼器類,繼承自 nn.Module
class Encoder(nn.Module):def __init__(self, input_size, hidden_size):super(Encoder, self).__init__() self.hidden_size = hidden_size # 設置隱藏層大小 self.embedding = nn.Embedding(input_size, hidden_size) # 創建詞嵌入層 self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True) # 創建 RNN 層 def forward(self, inputs, hidden): # 前向傳播函數embedded = self.embedding(inputs) # 將輸入轉換為嵌入向量 output, hidden = self.rnn(embedded, hidden) # 將嵌入向量輸入 RNN 層并獲取輸出return output, hidden# 定義解碼器類,繼承自 nn.Module
class Decoder(nn.Module):def __init__(self, hidden_size, output_size):super(Decoder, self).__init__() self.hidden_size = hidden_size # 設置隱藏層大小 self.embedding = nn.Embedding(output_size, hidden_size) # 創建詞嵌入層self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True) # 創建 RNN 層 self.out = nn.Linear(hidden_size, output_size) # 創建線性輸出層 def forward(self, inputs, hidden): # 前向傳播函數 # inputs = tensor([[ 7, 2, 13, 5, 17]])embedded = self.embedding(inputs) # 將輸入轉換為嵌入向量 output, hidden = self.rnn(embedded, hidden) # 將嵌入向量輸入 RNN 層并獲取輸出 output = self.out(output) # 使用線性層生成最終輸出return output, hiddenn_hidden = 128 # 設置隱藏層數量
# 創建編碼器和解碼器
encoder = Encoder(voc_size_cn, n_hidden)
decoder = Decoder(n_hidden, voc_size_en)編碼器結構: Encoder((embedding): Embedding(18, 128)(rnn): RNN(128, 128, batch_first=True)
)解碼器結構: Decoder((embedding): Embedding(20, 128)(rnn): RNN(128, 128, batch_first=True)(out): Linear(in_features=128, out_features=20, bias=True)
)
我們需要定義兩個類:Encoder和Decoder。這兩個類都繼承自PyTorch的nn.Module。它們的核心組件包括:
- 嵌入層,用來把輸入的單詞索引轉換成低維的向量表示;
- RNN層,用來處理序列信息;
- 對于解碼器,還需要一個線性輸出層,用來把RNN的輸出轉換成最終的詞匯表概率分布。
這就是我們定義的編碼器和解碼器的代碼。可以看到
- Encoder類主要負責處理輸入序列,它包含一個嵌入層和一個RNN層
- Decoder類除了嵌入層和RNN層,還多了一個輸出層,用于生成最終的預測結果。
- forward函數定義了數據如何在網絡中流動。
這里解釋一下RNN輸出的兩個值:output 和 hidden。
- output 是每個時間步的輸出,可以理解為對當前輸入的編碼。
- hidden 是隱藏狀態,它包含了從序列開始到現在所有信息的累積,是RNN的核心記憶。
在編碼器中,hidden 狀態會傳遞給解碼器作為初始狀態。而編碼器的 output,雖然在這個簡單的模型里沒直接用,但在后續的注意力機制中會發揮重要作用。解碼器的 output 則是我們最終需要的預測概率分布。
定義Seq2Seq架構
我們需要把編碼器和解碼器這兩個組件組裝起來,形成一個完整的Seq2Seq模型。
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder):super(Seq2Seq, self).__init__()# 初始化編碼器和解碼器self.encoder = encoderself.decoder = decoderdef forward(self, enc_input, hidden, dec_input): # 定義前向傳播函數# 使輸入序列通過編碼器并獲取輸出和隱藏狀態encoder_output, encoder_hidden = self.encoder(enc_input, hidden)# 將編碼器的隱藏狀態傳遞給解碼器作為初始隱藏狀態decoder_hidden = encoder_hidden# 使解碼器輸入(目標序列)通過解碼器并獲取輸出decoder_output, _ = self.decoder(dec_input, decoder_hidden)return decoder_output
# 創建 Seq2Seq 架構
model = Seq2Seq(encoder, decoder)S2S 模型結構: Seq2Seq((encoder): Encoder((embedding): Embedding(18, 128)(rnn): RNN(128, 128, batch_first=True))(decoder): Decoder((embedding): Embedding(20, 128)(rnn): RNN(128, 128, batch_first=True)(out): Linear(in_features=128, out_features=20, bias=True))
)
我們定義一個名為Seq2Seq的類,它也繼承自nn.Module。在這個類里,我們會初始化一個編碼器和一個解碼器對象。然后,定義一個forward函數,描述數據如何從輸入序列經過編碼器,得到隱藏狀態,再傳遞給解碼器,最終生成輸出序列的過程。這就是我們定義的Seq2Seq模型類代碼。
我們再來看一下這個forward函數的細節。它接收三個參數:
- enc_input,編碼器的輸入
- hidden,初始隱藏狀態
- dec_input,解碼器的輸入序列
注意這個 dec_input,它包含了我們之前提到的帶 <sos> 的真實目標序列。這再次體現了教師強制的策略。函數返回的是 decoder_output,它是一個張量,每個時間步對應一個詞匯表的預測概率分布。
訓練模型
我們定義一個訓練函數,然后調用它來訓練我們的Seq2Seq模型。
def train_seq2seq(model, criterion, optimizer, epochs):for epoch in range(epochs):encoder_input, decoder_input, target = make_data(sentences) # 訓練數據的創建# encoder_input = tensor([[ 9, 17, 1]]) # decoder_input = tensor([[ 7, 9, 19, 3]]) # target = tensor([[ 9, 19, 3, 18]])hidden = torch.zeros(1, encoder_input.size(0), n_hidden) # 初始化隱藏狀態 optimizer.zero_grad()# 梯度清零 output = model(encoder_input, hidden, decoder_input) # 獲取模型輸出 loss = criterion(output.view(-1, voc_size_en), target.view(-1)) # 計算損失 if (epoch + 1) % 40 == 0: # 打印損失print(f"Epoch: {epoch + 1:04d} cost = {loss:.6f}") loss.backward()# 反向傳播 optimizer.step()# 更新參數
# 訓練模型
epochs = 400 # 訓練輪次
criterion = nn.CrossEntropyLoss() # 損失函數
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 優化器
train_seq2seq(model, criterion, optimizer, epochs) # 調用函數訓練模型
可以看到,它是一個循環,每次迭代一個epoch。在每次迭代中,我們首先生成數據,初始化隱藏狀態,然后執行前向傳播、計算損失、反向傳播、更新參數這幾個步驟。我們還打印了每隔一定輪次的損失值,用來監控訓練進度。
這里解釋一下代碼中的一些細節。我們使用了nn.CrossEntropyLoss作為損失函數,因為它適合處理多分類問題,比如預測下一個詞。view函數用于改變張量的形狀,比如把輸出張量展平成二維,把目標標簽展平成一維,以便損失函數計算。我們使用了Adam優化器,這是一個非常流行的優化算法。整個訓練過程就是標準的深度學習流程。
測試模型
測試模型。我們定義一個測試函數,用來評估模型在新數據上的表現。
# 定義測試函數
def test_seq2seq(model, source_sentence):# 將輸入的句子轉換為索引encoder_input = np.array([[word2idx_cn[n] for n in source_sentence.split()]])# [[12 13 5 14 8]]# 構建輸出的句子的索引,以 '<sos>' 開始,后面跟 '<eos>',長度與輸入句子相同decoder_input = np.array([word2idx_en['<sos>']] + [word2idx_en['<eos>']]*(len(encoder_input[0])-1))# [ 7 18 18 18 18]# 轉換為 LongTensor 類型encoder_input = torch.LongTensor(encoder_input)decoder_input = torch.LongTensor(decoder_input).unsqueeze(0) # 增加一維 hidden = torch.zeros(1, encoder_input.size(0), n_hidden) # 初始化隱藏狀態 predict = model(encoder_input, hidden, decoder_input) # 獲取模型輸出 predict = predict.data.max(2, keepdim=True)[1] # 獲取概率最大的索引# 打印輸入的句子和預測的句子print(source_sentence, '->', [idx2word_en[n.item()] for n in predict.squeeze()])
# 測試模型
test_seq2seq(model, '自然 語言 處理 很 強大')
測試時,我們不再提供真實的英文句子作為解碼器的輸入,而是只提供一個sos作為起始信號。
然后,我們讓模型自己一步步生成英文單詞,直到遇到eos。我們把模型預測的索引轉換回英文單詞,看看翻譯結果如何。這就是測試函數的代碼。它首先將輸入的中文句子轉換為索引。然后,它只構建了一個包含sos的解碼器輸入序列,后面填充了eos(這個代碼為了簡化,沒有實現真正的逐個token生成,而是直接輸出了與輸入序列等長的輸出)。
接著,我們初始化隱藏狀態,讓模型通過前向傳播,得到預測結果。我們取每個時間步概率最大的那個詞作為輸出,最后將這些索引轉換回英文單詞。可以看到,模型基本學到了翻譯任務。不過,這里需要指出的是,這個代碼為了簡化,沒有實現真正的逐個token生成,而是直接輸出了與輸入序列等長的輸出。
對于更復雜的任務,我們需要實現更精細的生成過程,比如GPT模型那樣,一個詞一個詞地生成。



)
)
)







)
中CFG參數指的是什么?該怎么用!)




