一、Python 數據分析與可視化簡介

在當今數字化時代,數據就像一座蘊藏無限價值的寶藏,等待著我們去挖掘和探索。而 Python,作為數據科學領域的明星語言,憑借其豐富的庫和強大的功能,成為了開啟這座寶藏的關鍵鑰匙,在數據分析和可視化領域占據著舉足輕重的地位。
(一)Python 在數據分析領域的重要性
Python 之所以備受青睞,主要有以下幾個原因:
- 簡單易學:Python 以其簡潔、易讀的語法聞名,它采用了人類自然語言的思維方式,使得代碼就像一段段清晰的指令,降低了編程的門檻。對于初學者而言,無論是剛踏入編程世界的新手,還是其他領域想要轉行從事數據分析的人員,都能輕松上手,快速掌握基本的編程技能。例如,使用 Python 進行簡單的數學運算,代碼直觀易懂,就像在紙上書寫數學公式一樣。
- 豐富的庫和工具:Python 擁有龐大的開源社區,這使得它積累了數量眾多、功能各異的庫,這些庫就像是一個個強大的工具包,涵蓋了數據處理、分析、建模、可視化等數據分析的各個環節。無論你是需要進行復雜的數據清洗,還是構建高級的機器學習模型,亦或是創建精美的數據可視化圖表,都能在 Python 的庫中找到合適的工具。比如,Pandas 庫提供了高效的數據處理和分析工具,NumPy 庫則為數值計算提供了堅實的基礎。
- 強大的數據處理能力:Python 具備高效的數據處理能力,能夠輕松應對大規模數據集。通過合理使用 Pandas、NumPy 等庫,我們可以實現數據的快速讀取、清洗、轉換和分析。這些庫在底層進行了高度優化,利用了先進的數據結構和算法,大大提高了數據處理的效率。例如,使用 Pandas 讀取和處理包含數百萬條記錄的 CSV 文件,速度快且占用內存少。
- 廣泛的應用領域:Python 在金融、醫療、電商、科研等眾多領域都得到了廣泛的應用。在金融領域,它被用于風險評估、投資分析和量化交易;在醫療領域,可用于疾病預測、藥物研發和醫療數據分析;在電商領域,能幫助進行用戶行為分析、銷售預測和精準營銷;在科研領域,可助力實驗數據處理、模型構建和結果可視化。Python 的通用性使其成為各個領域數據分析師和科學家的首選工具。
(二)常用的 Python 數據分析與可視化庫

在 Python 的數據分析與可視化生態系統中,有許多優秀的庫,它們各自發揮著獨特的作用,相互配合,為我們提供了強大的數據分析和可視化能力。下面為大家介紹幾個常用的庫:
- Pandas:Pandas 是 Python 數據分析的核心庫,就像是數據處理的瑞士軍刀,提供了快速、靈活、明確的數據結構,旨在簡單、直觀地處理關系型、標記型數據。它的主要數據結構是 Series(一維帶標簽數組)和 DataFrame(二維帶標簽表格),這兩種數據結構足以應對金融、統計、社會科學、工程等領域里的大多數典型數據處理任務。Pandas 不僅擅長數據的讀取、清洗、轉換和合并,還內置了基本的繪圖功能,能夠快速生成簡單的圖表,使數據分析流程更加連貫和高效。例如,使用 Pandas 可以輕松地從 CSV 文件中讀取數據,對數據進行去重、缺失值處理等操作,還能通過幾行代碼創建數據透視表,對數據進行多維度分析。
- NumPy:NumPy 是 Python 的基礎科學計算庫,為 Python 提供了快速的數組處理能力,是 Python 數據分析的基石。它支持大量的維度數組與矩陣運算,并且內置了許多數學函數庫,如三角函數、指數函數、對數函數等,能夠高效地進行各種數值計算。NumPy 的數組操作比 Python 原生的列表操作更加高效,因為它在底層使用了 C 語言實現,減少了 Python 的循環開銷。例如,在進行大規模矩陣運算時,使用 NumPy 可以顯著提高計算速度,節省計算時間。此外,NumPy 還為其他科學計算庫(如 SciPy、Pandas 等)提供了基礎支持,許多庫都依賴于 NumPy 進行數組操作。
- Matplotlib:Matplotlib 是 Python 中最常用的 2D 繪圖庫,它就像是一位多才多藝的畫師,能夠以多種硬拷貝格式和跨平臺的交互式環境生成高質量的圖形。Matplotlib 提供了廣泛的函數和方法,可以輕松繪制各種類型的圖表,如折線圖、散點圖、柱狀圖、餅圖、直方圖等,滿足不同的數據可視化需求。同時,Matplotlib 還支持對圖表的細節進行高度自定義,包括線條顏色、寬度、標記類型、圖例、標題、坐標軸標簽、刻度等,讓我們能夠根據具體的需求創建出個性化的圖表。例如,通過 Matplotlib 可以精確地控制圖表的每一個元素,調整圖表的布局和樣式,使其更加美觀和專業。
- Seaborn:Seaborn 是基于 Matplotlib 的高級繪圖庫,它在 Matplotlib 的基礎上進行了更高層次的封裝,提供了更美觀、更現代的默認樣式和更高級的繪圖函數,使得繪制的圖表更具吸引力和表現力。Seaborn 專注于統計數據可視化,提供了許多用于展示數據分布、關系和統計特性的函數,如分布圖(distplot)、關系圖(relplot)、分類圖(catplot)、熱力圖(heatmap)等。這些函數能夠幫助我們更直觀地理解數據的內在結構和規律,發現數據中的模式和趨勢。例如,使用 Seaborn 的熱力圖可以清晰地展示數據之間的相關性,通過分布圖可以快速了解數據的分布情況。而且,Seaborn 與 Pandas 數據結構無縫集成,使用起來非常方便。
- Plotly:Plotly 是一個用于創建交互式可視化的庫,它為數據可視化帶來了全新的體驗。與傳統的靜態圖表不同,Plotly 創建的圖表具有交互性,用戶可以通過鼠標懸停、縮放、點擊等操作來探索數據,獲取更多的細節信息。Plotly 支持多種圖表類型,包括常見的折線圖、柱狀圖、散點圖,以及更高級的 3D 圖表、地圖、等高線圖等,適用于各種數據展示場景。此外,Plotly 還可以將圖表導出為 HTML 格式,方便在網頁中嵌入和分享。例如,在創建數據儀表盤時,使用 Plotly 可以創建出動態、交互式的可視化界面,讓用戶能夠更加直觀地與數據進行交互,深入了解數據背后的信息。
這些庫各有所長,在實際的數據分析與可視化項目中,我們通常會根據具體的需求和場景選擇合適的庫進行組合使用。例如,使用 Pandas 和 NumPy 進行數據處理和分析,然后使用 Matplotlib 或 Seaborn 進行靜態圖表繪制,當需要創建交互式圖表時,則可以選擇 Plotly。通過合理運用這些庫,我們能夠更加高效地完成數據分析與可視化任務,從數據中挖掘出有價值的信息,并以直觀、清晰的方式展示給他人。
二、開發工具介紹
在進行 Python 數據分析與可視化的旅程中,選擇合適的開發工具至關重要。它們就像是工匠手中的精良工具,能夠極大地提升我們的工作效率和開發體驗。下面將為大家介紹兩款在 Python 數據分析領域廣泛使用的開發工具:Jupyter Notebook 和 VSCode。
2.1 Jupyter Notebook
Jupyter Notebook 是一款廣受歡迎的開源交互式計算環境,它以網頁的形式呈現,為用戶提供了一個集成的工作空間,在這個空間里,用戶可以創建和共享包含實時代碼、數學方程、可視化內容以及說明文本的文檔,這些文檔被稱為 “筆記本”,文件擴展名為.ipynb 。Jupyter Notebook 就像是一個功能強大的實驗室工作臺,讓我們能夠在一個地方完成數據分析的整個流程,從數據探索、清洗、分析到可視化展示,一應俱全。
特點和優勢
- 交互式編程:這是 Jupyter Notebook 最為突出的特點之一。它允許用戶逐行或逐塊地執行代碼,并立即查看結果,就像與代碼進行實時對話一樣。這種即時反饋的編程方式非常適合數據分析和探索性編程,我們可以快速迭代和調整代碼,直至達到期望的結果。例如,在進行數據探索時,我們可以先讀取一小部分數據,然后通過執行單行代碼對數據進行簡單的統計分析,如計算均值、最大值、最小值等,根據結果再決定下一步的操作。
- 即時查看結果:在 Jupyter Notebook 中,代碼的運行結果會直接顯示在代碼塊下方,無論是數據的統計信息、計算結果還是可視化圖表,都能一目了然。這使得我們能夠迅速驗證代碼的正確性,及時發現問題并進行調整。比如,當我們使用 Matplotlib 庫繪制折線圖時,執行代碼后,折線圖會立即呈現在代碼塊的下方,方便我們查看和分析數據的趨勢。
- 多語言支持:雖然 Jupyter 最初是為 Python 設計的,但它已擴展支持多種編程語言,如 R、Julia 等。通過安裝不同的內核(kernel),我們可以在同一個 Notebook 中使用不同的編程語言進行編程,這使得 Jupyter Notebook 成為一個功能強大的平臺,可以滿足不同編程語言用戶的需求。例如,在進行數據分析項目時,我們可能需要使用 Python 進行數據處理,使用 R 進行統計建模,Jupyter Notebook 就能夠輕松實現這一需求。
- 富文本展示:Jupyter Notebook 支持 Markdown 和 HTML 等富文本格式,我們可以在文檔中插入文本、圖片、數學公式、鏈接等,使得文檔內容更加豐富和易于理解。此外,Jupyter Notebook 還支持多種輸出格式,如圖表、視頻等,便于我們展示數據分析和模型訓練的結果。比如,在撰寫數據分析報告時,我們可以使用 Markdown 語法添加標題、段落、列表等,使報告結構清晰;同時,還可以插入數據可視化圖表,增強報告的可視化效果。
- 易于分享:Jupyter Notebook 文檔(.ipynb 文件)可以輕松地通過電子郵件、GitHub 等平臺與他人分享。這些文件包含了數據處理、模型訓練、結果分析的所有步驟,便于他人復現和驗證工作。此外,Jupyter Notebook 還支持將文檔導出為多種格式,如 HTML、PDF、Markdown 等,以適應不同的展示和分享需求。例如,我們可以將完成的數據分析項目以.ipynb 文件的形式分享給團隊成員,他們可以直接打開文件并運行其中的代碼,查看分析過程和結果;如果需要在會議上展示,我們可以將 Notebook 導出為 PDF 格式,方便演示。
- 模塊化:代碼可以分割成多個可執行的單元格,使得大型分析項目更易于管理和組織。我們可以將不同功能的代碼放在不同的單元格中,每個單元格可以獨立運行,也可以按照順序依次運行。這樣,我們可以更加清晰地組織代碼結構,便于調試和維護。比如,在進行一個復雜的機器學習項目時,我們可以將數據讀取、數據預處理、模型訓練、模型評估等步驟分別放在不同的單元格中,每個單元格專注于一個特定的功能,使代碼的邏輯更加清晰。
安裝和基本使用方法
- 安裝:安裝 Jupyter Notebook 通常有兩種方式,分別是使用 Anaconda 和 pip 命令。
-
- 使用 Anaconda 安裝:Anaconda 是一個流行的 Python 發行版,它包含了許多常用的數據科學庫和工具,并且已經自動為我們安裝了 Jupyter Notebook 及其他相關工具。我們可以從 Anaconda 官方網站(https://www.anaconda.com/products/individual)下載適合自己操作系統的安裝包,然后按照安裝向導的提示進行安裝。安裝完成后,我們可以在開始菜單(Windows 系統)或應用程序文件夾(Mac 系統)中找到 Anaconda Navigator,打開它,在其中可以直接啟動 Jupyter Notebook。
-
- 使用 pip 命令安裝:如果我們已經安裝了 Python,也可以使用 pip 命令來安裝 Jupyter Notebook。首先,打開命令行終端(Windows 系統可以通過 “開始菜單” -> “運行”,輸入 “cmd” 打開;Mac 系統可以通過 “應用程序” -> “實用工具” -> “終端” 打開),然后輸入以下命令將 pip 升級到最新版本:
pip install --upgrade pip升級完成后,再輸入以下命令安裝 Jupyter Notebook:
pip install jupyter- 基本使用方法:
-
- 啟動 Jupyter Notebook:安裝完成后,在命令行終端中輸入以下命令啟動 Jupyter Notebook:
jupyter notebook執行該命令后,系統會自動打開默認的瀏覽器,并在瀏覽器中顯示 Jupyter Notebook 的主界面。如果瀏覽器沒有自動打開,我們可以復制命令行中顯示的 URL 地址(通常是http://localhost:8888/ ),然后手動粘貼到瀏覽器的地址欄中打開。
- 創建新的 Notebook:在 Jupyter Notebook 的主界面中,點擊右上角的 “New” 按鈕,在彈出的菜單中選擇 “Python 3”(如果我們安裝了其他內核,還可以選擇其他編程語言),即可創建一個新的 Notebook。新創建的 Notebook 會自動打開,我們可以在其中進行代碼編寫和運行。
- 編寫和運行代碼:在 Notebook 中,我們可以看到一個一個的單元格,每個單元格可以輸入代碼或文本。默認情況下,單元格是代碼類型,我們可以在其中輸入 Python 代碼。例如,輸入以下代碼:
print("Hello, World!")然后按下 “Shift + Enter” 組合鍵,即可運行該單元格中的代碼,運行結果會顯示在單元格下方。“Shift + Enter” 組合鍵的作用是運行當前單元格,并自動跳轉到下一個單元格;如果我們只想運行當前單元格,不跳轉到下一個單元格,可以使用 “Ctrl + Enter” 組合鍵;如果我們想在當前單元格下方插入一個新的單元格并運行當前單元格,可以使用 “Alt + Enter” 組合鍵。
- 添加和刪除單元格:如果我們需要添加新的單元格,可以點擊菜單欄中的 “Insert” -> “Insert Cell Above”(在當前單元格上方插入)或 “Insert Cell Below”(在當前單元格下方插入);如果要刪除某個單元格,可以先選中該單元格,然后點擊菜單欄中的 “Edit” -> “Delete Cells”,或者使用快捷鍵 “D, D”(連續按兩次 D 鍵)。
- 修改單元格類型:單元格的類型可以在代碼、Markdown 和 Raw NBConvert 之間切換。如果我們想在單元格中輸入文本說明,可以將單元格類型切換為 Markdown。選中單元格后,點擊菜單欄中的 “Cell” -> “Cell Type”,在彈出的子菜單中選擇 “Markdown” 即可。在 Markdown 類型的單元格中,我們可以使用 Markdown 語法編寫文本,例如添加標題、段落、列表、鏈接、圖片等。編寫完成后,按下 “Shift + Enter” 組合鍵,即可將 Markdown 文本渲染成富文本格式顯示。
- 保存和關閉 Notebook:在編寫代碼的過程中,我們需要及時保存 Notebook,以免數據丟失。可以點擊菜單欄中的 “File” -> “Save and Checkpoint”,或者使用快捷鍵 “Ctrl + S”(Windows 和 Linux 系統)或 “Command + S”(Mac 系統)進行保存。當我們完成工作后,可以點擊菜單欄中的 “File” -> “Close and Halt”,關閉當前 Notebook 并停止內核運行;如果我們只是暫時離開,可以點擊瀏覽器的關閉按鈕,下次打開時,Notebook 會恢復到上次保存的狀態。
2.2 VSCode
VSCode(Visual Studio Code)是一款由微軟開發的輕量級、跨平臺的代碼編輯器,雖然它本身并不直接支持 Python 數據分析和可視化,但通過安裝豐富的插件,它可以成為一個功能強大的 Python 開發環境,在 Python 數據分析領域也得到了廣泛的應用。VSCode 就像是一個高度可定制的工作間,我們可以根據自己的需求安裝各種插件,打造出適合自己的開發工具。
作為 Python 開發編輯器的優勢
- 豐富的插件生態:這是 VSCode 最為顯著的優勢之一。VSCode 擁有一個龐大的插件市場,其中包含了大量與 Python 開發相關的插件,這些插件可以滿足我們在 Python 數據分析和可視化過程中的各種需求。例如,通過安裝 “Python” 插件,我們可以獲得 Python 語法高亮、智能提示、代碼自動補全、代碼調試等基本功能;安裝 “Jupyter” 插件,我們可以在 VSCode 中直接打開和編輯 Jupyter Notebook 文件,實現與 Jupyter Notebook 類似的交互式編程體驗;安裝 “Pylance” 插件,可以提供更強大的代碼分析和智能感知功能,幫助我們更快地編寫高質量的 Python 代碼。此外,還有許多其他插件,如代碼格式化插件(如 “black”、“autopep8”)、版本控制插件(如 “GitLens”)、數據庫管理插件(如 “SQLite”)等,可以進一步增強 VSCode 的功能。
- 輕量級和快速:相比于一些大型的集成開發環境(IDE),VSCode 是一款輕量級的編輯器,它啟動速度快,占用系統資源少,這使得我們在編寫 Python 代碼時能夠獲得更加流暢的體驗。尤其是在處理大型項目或同時打開多個文件時,VSCode 的性能優勢更加明顯,不會因為資源占用過多而導致系統卡頓。
- 良好的調試支持:VSCode 提供了強大的內置調試工具,支持設置斷點、單步執行、變量觀察等多種調試功能。在進行 Python 數據分析和可視化開發時,我們經常需要調試代碼來查找錯誤和優化性能。通過 VSCode 的調試功能,我們可以方便地在代碼中設置斷點,當程序執行到斷點處時會暫停,我們可以查看變量的值、跟蹤程序的執行流程,從而快速定位和解決問題。例如,在調試一個數據處理腳本時,我們可以在關鍵代碼行設置斷點,觀察數據在不同處理步驟后的變化情況,找出可能存在的問題。
- 便捷的 Git 集成:VSCode 內置了對 Git 版本控制系統的支持,這使得我們在開發過程中能夠方便地進行代碼版本管理和團隊協作。我們可以直接在 VSCode 中進行 Git 操作,如提交代碼、拉取代碼、創建分支、合并分支等,無需頻繁切換到命令行終端。同時,VSCode 還提供了直觀的界面來顯示代碼的修改情況和版本歷史,方便我們查看和管理代碼的變更。例如,在一個多人協作的數據分析項目中,我們可以使用 VSCode 的 Git 集成功能,及時將自己的代碼提交到遠程倉庫,并與團隊成員的代碼進行合并,確保項目的順利進行。
- 跨平臺支持:VSCode 支持 Windows、macOS 和 Linux 等多種操作系統,無論我們使用哪種操作系統,都可以享受到 VSCode 帶來的便利。這使得我們在不同的開發環境中都能夠保持一致的開發體驗,無需為適應不同的編輯器而花費額外的時間和精力。例如,我們可以在 Windows 系統上進行日常的開發工作,在 Mac 系統上進行項目展示和匯報,在 Linux 服務器上進行代碼部署,而始終使用 VSCode 作為主要的開發工具。
配置 VSCode 以進行 Python 數據分析開發
要在 VSCode 中進行 Python 數據分析開發,我們需要進行以下配置:
- 安裝 VSCode:首先,從 VSCode 官方網站(Visual Studio Code - Code Editing. Redefined)下載適合自己操作系統的安裝包,然后按照安裝向導的提示進行安裝。安裝完成后,打開 VSCode。
- 安裝 Python 插件:打開 VSCode 后,點擊左側邊欄的 “擴展” 圖標(看起來像四個方塊組成的正方形),在搜索框中輸入 “Python”,然后在搜索結果中找到由 Microsoft 提供的 “Python” 插件,點擊 “安裝” 按鈕進行安裝。安裝完成后,VSCode 將具備 Python 開發的基本支持,如語法高亮、智能提示等。
- 配置 Python 解釋器:安裝完 Python 插件后,我們需要告訴 VSCode 使用哪個 Python 解釋器來運行我們的代碼。打開一個新的或現有的 Python 文件,然后點擊 VSCode 窗口底部狀態欄中的 Python 版本信息(例如 “Python 3.9.10 64-bit (venv)”),在彈出的列表中選擇我們想要使用的 Python 解釋器。如果列表中沒有我們需要的解釋器,可以點擊 “Enter interpreter path...” 手動指定解釋器的路徑。例如,如果我們使用 Anaconda 管理 Python 環境,那么可以在 Anaconda 安裝目錄下的 “envs” 文件夾中找到對應的環境目錄,在該目錄下的 “Scripts” 文件夾(Windows 系統)或 “bin” 文件夾(Mac 和 Linux 系統)中找到 “python.exe”(Windows 系統)或 “python3”(Mac 和 Linux 系統)作為解釋器路徑。
- 安裝其他插件:根據我們的具體需求,還可以安裝其他與 Python 數據分析和可視化相關的插件。例如,安裝 “Jupyter” 插件,以便在 VSCode 中使用 Jupyter Notebook;安裝 “Pylance” 插件,提升代碼智能感知能力;安裝 “Matplotlib Interactive” 插件,實現 Matplotlib 圖表的交互式顯示等。安裝插件的方法與安裝 Python 插件類似,在擴展搜索框中輸入插件名稱,然后點擊 “安裝” 按鈕即可。
- 創建 Python 項目:在 VSCode 中,我們可以通過創建項目文件夾來組織我們的 Python 代碼。點擊菜單欄中的 “文件” -> “新建文件夾”,選擇一個目錄來存放我們的 Python 項目。然后在該目錄中,右鍵點擊空白處,選擇 “新建文件”,將文件保存為以.py 為擴展名的 Python 源文件。例如,我們可以創建一個名為 “data_analysis” 的項目文件夾,在其中創建一個名為 “main.py” 的 Python 文件,用于編寫我們的數據分析代碼。
- 運行和調試 Python 代碼:在編寫完 Python 代碼后,我們可以通過以下幾種方式運行和調試代碼:
-
- 運行代碼:右鍵點擊編輯器中的代碼,選擇 “在終端中運行 Python 文件”,VSCode 會在終端中執行我們的 Python 代碼,并顯示運行結果。也可以使用快捷鍵 “Ctrl + F5”(Windows 和 Linux 系統)或 “Command + F5”(Mac 系統)來運行代碼。
-
- 調試代碼:在我們想要設置斷點的行號旁邊點擊,出現一個紅點表示斷點設置成功。然后點擊側邊欄的 “調試” 圖標(看起來像一個蟲子),在彈出的調試配置列表中選擇 “Python 文件”(如果沒有該選項,可以點擊 “創建配置” 按鈕,選擇 “Python 文件” 創建一個調試配置)。最后點擊調試工具欄中的 “啟動調試” 按鈕(綠色三角形圖標),或者使用快捷鍵 “F5” 來啟動調試會話。在調試過程中,我們可以通過調試面板管理斷點、查看變量值、單步執行代碼等。例如,在調試一個數據處理函數時,我們可以在函數內部設置斷點,然后通過單步執行觀察函數的執行過程和變量的變化情況,找出可能存在的問題。
通過以上步驟,我們就可以將 VSCode 配置為一個功能強大的 Python 數據分析開發環境,利用其豐富的插件生態和強大的功能,高效地進行 Python 數據分析和可視化工作。
三、核心庫基礎
在 Python 數據分析與可視化的領域中,Pandas、NumPy、Matplotlib 和 Seaborn 這幾個核心庫猶如璀璨的明星,各自發揮著獨特而關鍵的作用,是我們進行數據分析和可視化的得力工具。接下來,讓我們深入探索這些庫的基礎用法,領略它們的強大魅力。
3.1 Pandas
Pandas 是 Python 數據分析的核心支撐,它為我們提供了快速、靈活、明確的數據結構,使我們能夠高效地處理和分析各種類型的數據。無論是簡單的表格數據,還是復雜的時間序列數據,Pandas 都能輕松應對。
3.1.1 Series 數據結構
Series 是 Pandas 中用于表示一維帶標簽數組的數據結構,它由一組數據和與之對應的索引組成。可以將其看作是一個列數據,索引則是每一行數據的標識,就像給每個數據點都貼上了獨特的標簽,方便我們進行數據的定位和操作。
創建 Series 對象非常簡單,我們可以通過多種方式來實現。最常見的方式是從 Python 列表或 NumPy 數組創建:
import pandas as pd
import numpy as np# 從列表創建Series
data = [10, 20, 30, 40, 50]
s1 = pd.Series(data)
print(s1)上述代碼中,我們首先導入了 Pandas 庫并別名為 pd,然后定義了一個 Python 列表 data,接著使用 pd.Series () 函數將列表轉換為 Series 對象 s1。運行代碼后,我們可以看到輸出的 Series 對象,它不僅包含了數據,還自動生成了從 0 開始的整數索引。
我們還可以從字典創建 Series,此時字典的鍵將作為索引,值作為數據:
# 從字典創建Series
data_dict = {'a': 100, 'b': 200, 'c': 300, 'd': 400}
s2 = pd.Series(data_dict)
print(s2)在這段代碼中,我們定義了一個字典 data_dict,然后將其傳遞給 pd.Series () 函數創建了 Series 對象 s2。輸出結果中,索引為字典的鍵 'a'、'b'、'c'、'd',對應的數據分別為 100、200、300、400。
訪問 Series 中的數據也很直觀,我們可以通過索引來獲取單個數據或多個數據:
# 訪問單個數據
print(s2['b']) # 訪問多個數據
print(s2[['a', 'c']]) 在第一行代碼中,我們通過索引 'b' 獲取了 s2 中對應的數據 200;第二行代碼中,我們通過傳遞一個包含索引 'a' 和 'c' 的列表,獲取了這兩個索引對應的數據,輸出結果是一個包含這兩個數據的新 Series 對象。
此外,Series 還支持許多強大的操作方法,比如數學運算、數據過濾、缺失值處理等。例如,我們可以對 Series 進行簡單的數學運算:
# Series數學運算
s3 = s2 * 2
print(s3)這段代碼將 s2 中的每個數據都乘以 2,生成了一個新的 Series 對象 s3,展示了 Series 在數學運算方面的便捷性。
3.1.2 DataFrame 數據結構
DataFrame 是 Pandas 中的二維表格型數據結構,它由多個 Series 組成,可以看作是一個由列組成的表格,每一列都是一個 Series,且所有列共享同一索引。DataFrame 的出現,使得我們能夠更加方便地處理和分析結構化數據,是 Pandas 庫中最為常用的數據結構之一。
創建 DataFrame 的方式同樣豐富多樣。我們可以從字典創建,字典的鍵將成為 DataFrame 的列名,值為對應列的數據:
# 從字典創建DataFrame
data = {'姓名': ['張三', '李四', '王五', '趙六'],'年齡': [25, 30, 35, 40],'城市': ['北京', '上海', '廣州', '深圳']
}
df = pd.DataFrame(data)
print(df)在上述代碼中,我們定義了一個包含 ' 姓名 '、' 年齡 '、' 城市 ' 三個鍵的字典 data,然后使用 pd.DataFrame () 函數將其轉換為 DataFrame 對象 df。運行代碼后,我們可以看到一個規整的表格,列名分別為字典的鍵,每列的數據對應字典中鍵的值。
也可以從二維列表創建 DataFrame,并通過 columns 參數指定列名:
# 從二維列表創建DataFrame
data_list = [['張三', 25, '北京'],['李四', 30, '上海'],['王五', 35, '廣州'],['趙六', 40, '深圳']
]
df2 = pd.DataFrame(data_list, columns=['姓名', '年齡', '城市'])
print(df2)這里,我們定義了一個二維列表 data_list,然后使用 pd.DataFrame () 函數創建 DataFrame 對象 df2,并通過 columns 參數明確指定了列名。
對 DataFrame 進行索引、切片和篩選操作是數據分析中常見的任務。通過索引,我們可以獲取指定行或列的數據:
# 獲取列數據
age_column = df['年齡']
print(age_column)# 獲取行數據
row_data = df.loc[2]
print(row_data)在第一行代碼中,我們通過列名 ' 年齡 ' 獲取了 df 中的 ' 年齡 ' 列數據,返回的是一個 Series 對象;第二行代碼中,我們使用 loc 索引器通過行索引 2 獲取了第三行的數據,同樣返回的是一個 Series 對象,其索引為列名,值為對應列的數據。
切片操作可以幫助我們獲取指定范圍的數據:
# 切片操作
subset_df = df.loc[1:3, ['姓名', '城市']]
print(subset_df)這段代碼中,我們使用 loc 索引器進行切片操作,獲取了 df 中索引為 1、2、3 的行,以及 ' 姓名 ' 和' 城市 ' 兩列的數據,返回的是一個新的 DataFrame 對象。
根據條件篩選數據也是 DataFrame 的重要功能之一,例如篩選出年齡大于 30 歲的行:
# 條件篩選
filtered_df = df[df['年齡'] > 30]
print(filtered_df)在這段代碼中,我們通過布爾索引 df [' 年齡 '] > 30 篩選出了 df 中年齡大于 30 歲的行,返回的是一個新的 DataFrame 對象,只包含滿足條件的行數據。
3.1.3 數據讀取與寫入
在實際數據分析中,我們通常需要從外部文件讀取數據,進行處理后再將結果保存到文件中。Pandas 提供了豐富的函數來讀取和寫入各種常見格式的數據文件,使得數據的輸入輸出操作變得簡單高效。
讀取 CSV 文件是數據分析中極為常見的操作,Pandas 的 read_csv () 函數可以輕松完成這一任務:
# 讀取CSV文件
data = pd.read_csv('data.csv')
print(data.head()) 上述代碼中,我們使用 pd.read_csv () 函數讀取了名為 'data.csv' 的 CSV 文件,并將其存儲為一個 DataFrame 對象 data。通過調用 head () 方法,我們可以查看 DataFrame 的前 5 行數據,以快速了解數據的結構和內容。
讀取 Excel 文件也同樣便捷,借助 read_excel () 函數即可實現:
# 讀取Excel文件
data_excel = pd.read_excel('data.xlsx')
print(data_excel.head())這里,我們使用 pd.read_excel () 函數讀取了名為 'data.xlsx' 的 Excel 文件,并將其轉換為 DataFrame 對象 data_excel,同樣通過 head () 方法查看前 5 行數據。
當我們完成數據處理后,需要將結果保存到文件中。Pandas 提供了 to_csv () 和 to_excel () 函數來實現數據的保存:
# 將DataFrame保存為CSV文件
data.to_csv('new_data.csv', index=False) # 將DataFrame保存為Excel文件
data_excel.to_excel('new_data.xlsx', index=False) 在第一行代碼中,我們使用 to_csv () 函數將 data 保存為名為 'new_data.csv' 的 CSV 文件,并通過 index=False 參數指定不保存行索引;第二行代碼中,使用 to_excel () 函數將 data_excel 保存為名為 'new_data.xlsx' 的 Excel 文件,同樣不保存行索引。這樣,我們就可以方便地將處理后的數據保存下來,以便后續使用或分享。通過這些數據讀取與寫入的操作,Pandas 為我們搭建了一座連接外部數據和數據分析流程的橋梁,使得數據的獲取和保存變得輕松自如。
3.2 NumPy
NumPy 是 Python 科學計算的基礎庫,它提供了高效的多維數組對象以及豐富的數組操作函數,為 Python 在數據分析、機器學習、科學計算等領域的廣泛應用奠定了堅實的基礎。NumPy 的數組操作速度極快,這得益于其底層使用 C 語言實現,大大減少了 Python 循環帶來的開銷,使得我們能夠快速處理大規模的數值數據。
3.2.1 數組創建
在 NumPy 中,創建數組是進行后續操作的基礎。我們可以通過多種方式創建數組,以滿足不同的需求。最直接的方式是從 Python 列表或元組轉換:
import numpy as np# 從列表創建一維數組
arr1 = np.array([1, 2, 3, 4, 5])
print(arr1)# 從嵌套列表創建二維數組
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2)在上述代碼中,我們首先導入了 NumPy 庫并別名為 np。然后,使用 np.array () 函數從 Python 列表創建了一維數組 arr1,從嵌套列表創建了二維數組 arr2。運行代碼后,可以看到輸出的數組,它們的數據類型會根據輸入數據自動推斷。
除了從已有數據結構創建數組,NumPy 還提供了許多函數來創建具有特定特征的數組。例如,使用 arange () 函數創建等差數列數組:
# 使用arange創建等差數列數組
arr3 = np.arange(0, 10, 2)
print(arr3)這段代碼中,np.arange (0, 10, 2) 表示創建一個從 0 開始,到 10 結束(不包含 10),步長為 2 的等差數列數組,運行結果為 [0 2 4 6 8]。
使用 zeros () 和 ones () 函數可以創建全零或全一的數組:
# 創建全零數組
arr4 = np.zeros((3, 4))
print(arr4)# 創建全一數組
arr5 = np.ones((2, 3))
print(arr5)在第一行代碼中,np.zeros ((3, 4)) 創建了一個形狀為 (3, 4) 的全零數組,即 3 行 4 列,每個元素都是 0;第二行代碼中,np.ones ((2, 3)) 創建了一個 2 行 3 列的全一數組。
另外,使用 random 模塊可以創建隨機數數組,為數據分析和模擬實驗提供了便利:
# 創建隨機數數組
arr6 = np.random.rand(2, 3)
print(arr6)這里,np.random.rand (2, 3) 創建了一個 2 行 3 列的數組,數組中的元素是在 0 到 1 之間均勻分布的隨機數。
3.2.2 數組操作
NumPy 數組支持豐富多樣的操作,這些操作是進行數據分析和科學計算的核心。基本運算如加法、減法、乘法、除法等可以直接對數組進行,而且是元素級別的運算:
# 數組基本運算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = a + b
print(c)上述代碼中,我們定義了兩個一維數組 a 和 b,然后進行加法運算 a + b,得到的結果 c 是一個新的數組,其每個元素是 a 和 b 對應元素之和。
索引和切片操作與 Python 列表類似,但在多維數組中更加靈活:
# 數組索引和切片
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr[1, 2])
print(arr[0:2, 1:3]) 在第一行代碼中,arr [1, 2] 表示獲取二維數組 arr 中第二行(索引從 0 開始)第三列的元素,結果為 6;第二行代碼中,arr [0:2, 1:3] 表示獲取 arr 中前兩行(索引 0 和 1),第二列和第三列(索引 1 和 2)的子數組,返回的是一個形狀為 (2, 2) 的二維數組。
廣播機制是 NumPy 的一大特色,它允許不同形狀的數組進行運算,在滿足一定條件下,較小的數組會自動擴展以匹配較大數組的形狀:
# 廣播機制
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([10, 20, 30])
c = a + b
print(c)這里,數組 b 的形狀為 (3,),數組 a 的形狀為 (2, 3),在進行加法運算 a + b 時,由于 b 的形狀可以通過廣播擴展為 (2, 3),因此可以順利進行運算,結果 c 是一個形狀為 (2, 3) 的數組,其元素是 a 和 b 對應元素之和。廣播機制極大地簡化了數組運算,提高了代碼的簡潔性和效率,是 NumPy 強大功能的重要體現。
3.3 Matplotlib
Matplotlib 是 Python 最常用的繪圖庫之一,它提供了一套簡潔、直觀的 API,使得我們能夠輕松創建各種類型的高質量圖表,將數據以可視化的形式呈現出來,幫助我們更好地理解數據背后的信息和趨勢。無論是簡單的折線圖、散點圖,還是復雜的多子圖組合,Matplotlib 都能勝任。
???????
3.3.1 基本繪圖
Matplotlib 的基本繪圖函數非常簡單易用,通過幾行代碼就能創建出常見的圖表類型。以繪制折線圖為例:
import matplotlib.pyplot as plt
import numpy as np# 生成數據
x = np.arange(0, 10, 0.1)
y = np.sin(x)# 繪制折線圖
plt.plot(x, y)
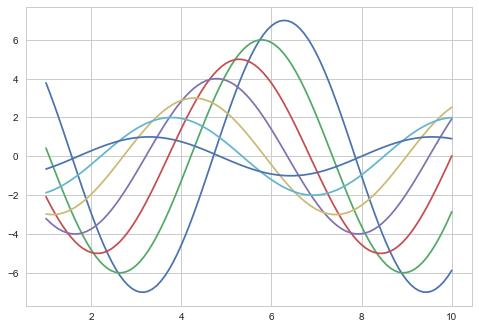
plt.show()在上述代碼中,我們首先導入了 Matplotlib 的 pyplot 模塊并別名為 plt,以及 NumPy 庫。然后,使用 np.arange () 函數生成了一組 x 數據,范圍是從 0 到 10(不包含 10),步長為 0.1,接著計算出對應的 y 數據(這里是正弦值)。最后,使用 plt.plot () 函數繪制折線圖,將 x 和 y 數據作為參數傳入,再調用 plt.show () 函數顯示圖表。運行代碼后,我們可以看到一個展示正弦函數曲線的折線圖。
繪制散點圖同樣簡單,使用 scatter () 函數即可:
# 生成數據
x = np.random.rand(50)
y = np.random.rand(50)# 繪制散點圖
plt.scatter(x, y)
plt.show()這段代碼中,我們使用 np.random.rand () 函數生成了兩組隨機數作為 x 和 y 數據,然后使用 plt.scatter () 函數繪制散點圖,展示了這些隨機點的分布情況。
柱狀圖可以使用 bar () 函數繪制,用于比較不同類別或組的數據:
# 數據
categories = ['A', 'B', 'C', 'D']
values = [25, 40, 15, 30]# 繪制柱狀圖
plt.bar(categories, values)
plt.show()在這段代碼中,我們定義了類別列表 categories 和對應的值列表 values,然后使用 plt.bar () 函數繪制柱狀圖,每個類別對應一個柱子,柱子的高度表示對應的值。運行代碼后,我們可以直觀地比較不同類別數據的大小。
Matplotlib 還支持對圖表的外觀進行設置,如顏色、標記、線型等,使圖表更加美觀和富有表現力:
# 生成數據
x = np.arange(0, 10, 0.1)
y1 = np.sin(x)
y2 = np.cos(x)# 繪制折線圖并設置顏色、標記和線型
plt.plot(x, y1, color='red', marker='o', linestyle='--', label='Sin')
plt.plot(x, y2, color='blue', marker='s', linestyle='-.', label='Cos')
plt.legend()
plt.show()在這段代碼中,我們分別繪制了正弦函數 y1 和余弦函數 y2 的折線圖,并通過參數設置了顏色(color)、標記(marker)和線型(linestyle)。同時,使用 label 參數為每條曲線添加了標簽,最后調用 plt.legend () 函數顯示圖例,以便區分不同的曲線。這樣,我們就創建了一個更加豐富和易讀的圖表。
3.3.2 圖表定制
為了使圖表更加清晰和易于理解,我們可以對圖表進行各種定制,包括添加標題、軸標簽、刻度、圖例等。添加標題可以使用 title () 函數,軸標簽可以通過 xlabel () 和 ylabel () 函數添加:
# 生成數據
x = np.arange(0, 10, 0.1)
y = np.sin(x)# 繪制折線圖
plt.plot(x, y)# 添加標題和軸標簽
plt.title('Sine Function')
plt.xlabel('X')
plt.ylabel('Sin(X)')
plt.show()
四、數據獲取
在 Python 數據分析與可視化的旅程中,數據獲取是第一步,也是至關重要的一步。就像廚師需要新鮮的食材才能烹飪出美味佳肴一樣,我們需要獲取高質量的數據,才能進行有效的分析和可視化展示。數據的來源多種多樣,下面將介紹從文件、數據庫和網絡中獲取數據的常見方法。
4.1 從文件讀取數據
在數據分析中,我們經常會遇到各種格式的文件,如 CSV、Excel、JSON 等,Pandas 庫為我們提供了便捷的函數來讀取這些文件中的數據。
CSV 文件:CSV(Comma-Separated Values)是一種常見的文本文件格式,以逗號分隔字段,常用于存儲表格數據。使用 Pandas 的 read_csv () 函數可以輕松讀取 CSV 文件,將其轉換為 DataFrame 對象,方便后續處理。
import pandas as pd# 讀取CSV文件
data_csv = pd.read_csv('data.csv')
print(data_csv.head()) # 查看前5行數據上述代碼中,我們使用 pd.read_csv () 函數讀取了名為 'data.csv' 的文件,并將其存儲為 DataFrame 對象 data_csv。通過調用 head () 方法,我們可以快速查看數據的前 5 行,了解數據的結構和內容。read_csv () 函數還有許多參數可以設置,以滿足不同的讀取需求。例如,sep 參數可以指定字段分隔符,header 參數可以指定作為列名的行,index_col 參數可以指定作為行索引的列等。如果 CSV 文件使用分號作為分隔符,我們可以這樣設置參數:
data_csv = pd.read_csv('data.csv', sep=';')Excel 文件:Excel 文件是另一種常見的數據存儲格式,它具有豐富的格式設置和數據處理功能。Pandas 的 read_excel () 函數可以讀取 Excel 文件中的數據。在使用該函數之前,需要確保安裝了 openpyxl 或 xlrd 庫,分別用于處理.xlsx 和.xls 格式的文件。
# 讀取Excel文件(.xlsx格式)
data_excel = pd.read_excel('data.xlsx', engine='openpyxl')
print(data_excel.head())# 讀取特定工作表(假設工作表名為'Sheet2')
data_sheet2 = pd.read_excel('data.xlsx', sheet_name='Sheet2', engine='openpyxl')
print(data_sheet2.head())在上述代碼中,我們首先使用 read_excel () 函數讀取了名為 'data.xlsx' 的文件,并通過 engine='openpyxl' 指定使用 openpyxl 庫來處理。然后,通過 sheet_name 參數指定讀取名為 'Sheet2' 的工作表。如果想查看所有工作表的名字,可以使用以下代碼:
with pd.ExcelFile('data.xlsx') as xls:print(xls.sheet_names)JSON 文件:JSON(JavaScript Object Notation)是一種輕量級的數據交換格式,常用于在不同的應用程序之間傳輸數據。Pandas 的 read_json () 函數可以將 JSON 數據讀取為 DataFrame 對象。
# 讀取JSON文件
data_json = pd.read_json('data.json')
print(data_json.head())上述代碼中,我們使用 read_json () 函數讀取了名為 'data.json' 的文件,并將其轉換為 DataFrame 對象 data_json。read_json () 函數支持從 JSON 文件、JSON 字符串或 JSON 網址中加載數據,并且可以通過 orient 參數指定 JSON 數據的結構方式,常見的值有'split'、'records'、'index'、'columns'、'values' 等。例如,從 JSON 字符串加載數據并指定 orient 為 'records':
import pandas as pd# JSON字符串
json_data = '''[{"Name": "Alice", "Age": 25, "City": "New York"},{"Name": "Bob", "Age": 30, "City": "Los Angeles"},{"Name": "Charlie", "Age": 35, "City": "Chicago"}
]'''# 從JSON字符串讀取數據,指定orient='records'
df = pd.read_json(json_data, orient='records')
print(df)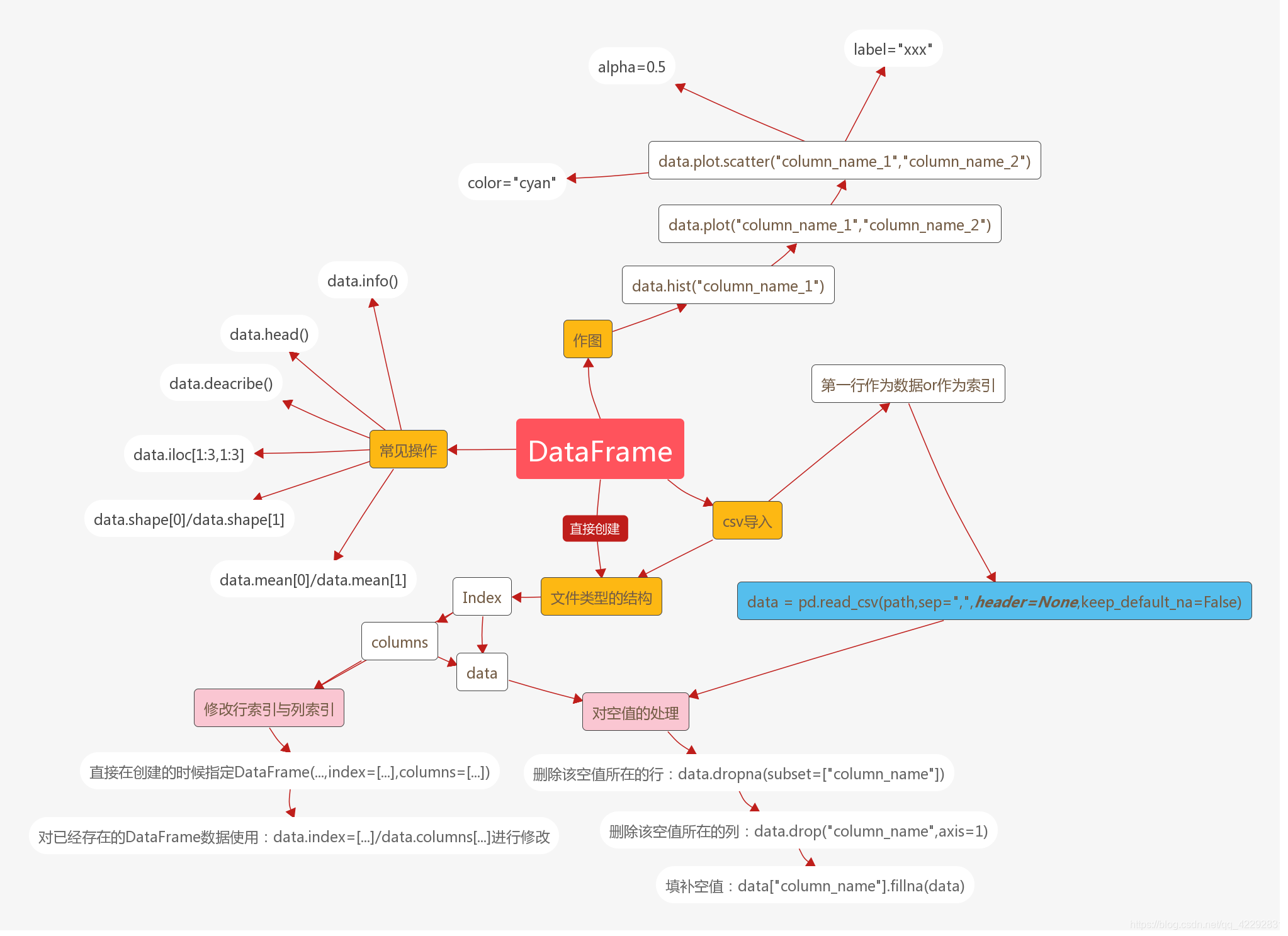
4.2 從數據庫獲取數據
數據庫是存儲和管理大量數據的重要工具,在實際應用中,我們經常需要從數據庫中獲取數據進行分析。Python 提供了多種庫來連接和操作常見的數據庫,如 MySQL、SQLite 等。
MySQL 數據庫:MySQL 是一種廣泛使用的關系型數據庫,使用 Python 連接 MySQL 數據庫并獲取數據,通常可以使用 pymysql 庫。在使用之前,需要先安裝該庫,可以使用 pip 命令進行安裝:
pip install pymysql安裝完成后,以下是一個連接 MySQL 數據庫并查詢數據的示例:
import pymysql# 建立數據庫連接
try:connection = pymysql.connect(host="localhost", # 主機地址port=3306, # 端口號user="your_username", # 用戶名password="your_password", # 密碼database="your_database", # 數據庫名稱charset="utf8" # 編碼)if connection.open:print("成功連接到MySQL數據庫")# 創建游標對象with connection.cursor() as cursor:# 執行查詢操作select_query = "SELECT * FROM your_table"cursor.execute(select_query)# 獲取所有查詢結果results = cursor.fetchall()# 打印查詢結果print("查詢結果:")for row in results:print(row)except pymysql.Error as e:print(f"連接數據庫時出錯: {e}")finally:if connection.open:connection.close()print("數據庫連接已關閉")
在上述代碼中,我們首先使用 pymysql.connect () 方法建立與 MySQL 數據庫的連接,需要提供主機地址、端口號、用戶名、密碼、數據庫名稱和編碼等信息。然后,通過 connection.cursor () 創建一個游標對象,用于執行 SQL 語句。接著,執行 SELECT 語句查詢指定表中的所有數據,并使用 fetchall () 方法獲取所有查詢結果。最后,在操作完成后,關閉數據庫連接。
SQLite 數據庫:SQLite 是一種輕量級的嵌入式數據庫,它不需要獨立的服務器進程,非常適合小型應用程序和快速開發。Python 內置了 sqlite3 模塊,用于連接和操作 SQLite 數據庫。
import sqlite3# 連接到SQLite數據庫(如果數據庫不存在,將創建一個新數據庫)
conn = sqlite3.connect('example.db')# 創建一個游標對象
cursor = conn.cursor()# 執行SQL查詢
cursor.execute("SELECT * FROM your_table")# 獲取所有記錄
rows = cursor.fetchall()# 遍歷并打印記錄
for row in rows:print(row)# 關閉游標和連接
cursor.close()
conn.close()
在上述代碼中,我們使用 sqlite3.connect () 方法連接到名為 'example.db' 的 SQLite 數據庫,如果數據庫不存在,將創建一個新的數據庫。然后,創建游標對象并執行 SQL 查詢,使用 fetchall () 方法獲取所有查詢結果,最后關閉游標和數據庫連接。
4.3 網絡數據獲取
隨著互聯網的發展,網絡成為了豐富的數據來源。我們可以通過網絡獲取各種類型的數據,如網頁內容、API 數據等。下面將介紹使用 requests 庫獲取網頁數據以及網頁爬蟲的基礎知識。
4.3.1 使用 requests 庫
requests 庫是 Python 中用于發送 HTTP 請求的常用庫,它提供了簡單易用的 API,使得我們能夠輕松地與網頁進行交互,獲取網頁數據。
發送 HTTP GET 請求是最常見的操作之一,通過 requests.get () 函數可以實現。例如,獲取百度首頁的內容:
import requests# 發送GET請求
response = requests.get('https://www.baidu.com')# 檢查響應狀態碼
if response.status_code == 200:print("請求成功")print(response.text) # 打印網頁內容
else:print(f"請求失敗,狀態碼: {response.status_code}")
在上述代碼中,我們使用 requests.get () 函數向'百度一下,你就知道' 發送 GET 請求,并將響應結果存儲在 response 變量中。通過檢查 response.status_code 屬性,可以判斷請求是否成功,如果狀態碼為 200,表示請求成功,此時可以通過 response.text 屬性獲取網頁的文本內容。
有時,我們需要在請求中傳遞參數。例如,在百度搜索框中搜索關鍵詞,可以通過 params 參數傳遞搜索關鍵詞:
import requests# 搜索關鍵詞
keyword = "Python數據分析"# 發送GET請求并傳遞參數
response = requests.get('https://www.baidu.com/s', params={'wd': keyword})# 檢查響應狀態碼
if response.status_code == 200:print("請求成功")print(response.url) # 打印請求的URL
else:print(f"請求失敗,狀態碼: {response.status_code}")
在上述代碼中,我們通過 params 參數傳遞了一個字典 {'wd': keyword},其中 'wd' 是百度搜索的參數名,keyword 是搜索關鍵詞。發送請求后,通過 response.url 可以查看實際請求的 URL,其中包含了我們傳遞的參數。
4.3.2 網頁爬蟲基礎
網頁爬蟲是一種自動獲取網頁內容的程序,它通過模擬瀏覽器行為,按照一定的規則遍歷網頁,提取所需的數據。網頁爬蟲在數據采集、搜索引擎優化、市場調研等領域有著廣泛的應用。
網頁爬蟲的基本原理是通過發送 HTTP 請求獲取網頁的 HTML 內容,然后使用解析庫(如 BeautifulSoup、lxml 等)對 HTML 進行解析,提取出我們需要的數據。下面是一個使用 requests 和 BeautifulSoup 庫編寫的簡單爬蟲示例,用于獲取豆瓣電影 Top250 的電影名稱和評分:
import requests
from bs4 import BeautifulSoup# 發送GET請求獲取網頁內容
url = 'https://movie.douban.com/top250'
response = requests.get(url)# 檢查響應狀態碼
if response.status_code == 200:# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(response.text, 'html.parser')# 找到所有電影條目movie_items = soup.find_all('div', class_='item')# 遍歷電影條目,提取電影名稱和評分for item in movie_items:title = item.find('span', class_='title').textrating = item.find('span', class_='rating_num').textprint(f"電影名稱: {title}, 評分: {rating}")else:print(f"請求失敗,狀態碼: {response.status_code}")
在上述代碼中,我們首先使用 requests.get () 函數獲取豆瓣電影 Top250 頁面的內容。然后,使用 BeautifulSoup 庫對獲取到的 HTML 內容進行解析,通過 find_all () 方法找到所有包含電影信息的 div 標簽,其 class 屬性為 'item'。接著,在每個電影條目中,使用 find () 方法找到電影名稱和評分對應的 span 標簽,并提取其文本內容。最后,打印出電影名稱和評分。
需要注意的是,在進行網頁爬蟲時,要遵守網站的使用規則和法律法規,不要對網站造成過大的負擔,避免侵犯他人的權益。同時,一些網站可能會采取反爬蟲措施,如限制訪問頻率、檢測爬蟲行為等,我們需要根據實際情況進行相應的處理,如設置合理的請求頭、添加隨機延遲等,以確保爬蟲的正常運行。
五、數據清洗與預處理
在數據分析的過程中,原始數據往往存在各種各樣的問題,如缺失值、異常值、重復值等,這些問題會嚴重影響數據分析的準確性和可靠性。因此,在進行數據分析之前,我們需要對數據進行清洗和預處理,將原始數據轉換為干凈、整齊、可用的數據。下面將詳細介紹數據清洗與預處理的常見方法和操作。
5.1 缺失值處理
缺失值是指數據集中某些數據點的數值缺失或未被記錄。缺失值的存在可能會導致數據分析結果的偏差,因此需要對其進行處理。
5.1.1 檢測缺失值
在 Pandas 中,我們可以使用 isnull () 或 isna () 方法來檢測數據集中的缺失值,這兩個方法的功能相同,只是名稱不同。它們會返回一個布爾值的 DataFrame 或 Series,表示每個元素是否為缺失值。
import pandas as pd# 創建一個包含缺失值的DataFrame
data = {'A': [1, 2, None, 4],'B': [5, None, None, 8],'C': [9, 10, 11, 12]}
df = pd.DataFrame(data)# 檢測缺失值
print(df.isnull())運行上述代碼,輸出結果如下:
A B C
0 False False False
1 False True False
2 True True False
3 False False False可以看到,對于每個元素,如果是缺失值則返回 True,否則返回 False。
為了統計每列的缺失值數量,可以使用 sum () 方法:
print(df.isnull().sum())輸出結果為:
A 1
B 2
C 0
dtype: int64這樣我們就可以清楚地知道每列中缺失值的個數。
5.1.2 刪除缺失值
當數據集中缺失值較少時,我們可以選擇直接刪除含有缺失值的行或列。在 Pandas 中,使用 dropna () 方法來實現這一操作。
# 刪除包含缺失值的行
df_drop_rows = df.dropna()
print(df_drop_rows)# 刪除包含缺失值的列
df_drop_cols = df.dropna(axis=1)
print(df_drop_cols)在上述代碼中,dropna () 方法默認刪除含有缺失值的行(axis=0),通過設置 axis=1 可以刪除含有缺失值的列。運行代碼后,我們可以看到刪除缺失值后的 DataFrame。
dropna () 方法還有其他參數可以設置,例如:
- how='any':只要有一個缺失值就刪除(默認)。
- how='all':只有當所有值都是缺失值時才刪除。
- thresh=n:至少有 n 個非缺失值才保留。
5.1.3 填充缺失值
除了刪除缺失值,我們還可以使用指定值、統計量(如均值、中位數)等方法來填充缺失值,以保留數據集中的信息。在 Pandas 中,使用 fillna () 方法進行填充。
# 用指定的值填充缺失值
df_fill_value = df.fillna(0)
print(df_fill_value)# 用均值填充缺失值
df_fill_mean = df.fillna(df.mean())
print(df_fill_mean)# 用前一個非缺失值填充(前向填充)
df_ffill = df.fillna(method='ffill')
print(df_ffill)# 用后一個非缺失值填充(后向填充)
df_bfill = df.fillna(method='bfill')
print(df_bfill)在上述代碼中,首先使用 fillna (0) 將缺失值填充為 0;然后使用 df.mean () 計算每列的均值,并將缺失值填充為均值;接著使用 method='ffill' 進行前向填充,即使用前一個非缺失值填充當前缺失值;最后使用 method='bfill' 進行后向填充,即使用后一個非缺失值填充當前缺失值。運行代碼后,可以看到不同填充方法得到的結果。
5.2 異常值處理
異常值是指數據集中與其他數據點顯著不同的數據點,它們可能是由于數據錄入錯誤、測量誤差或其他原因導致的。異常值的存在可能會對數據分析和模型訓練產生較大的影響,因此需要對其進行處理。
5.2.1 檢測異常值
檢測異常值的方法有很多種,下面介紹兩種常用的統計方法:箱線圖和 Z-Score。
- 箱線圖:箱線圖是一種基于統計的圖形化方法,通過可視化數據的分布情況來識別異常值。它展示了數據的最小值、第一四分位數(Q1)、中位數(Q2)、第三四分位數(Q3)和最大值。異常值通常定義為超出 1.5 倍 IQR(四分位距,IQR = Q3 - Q1)范圍的數據點。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np# 生成示例數據
data = np.random.normal(100, 10, 100)
data = np.append(data, [150, 160, 200]) # 添加幾個異常值
df = pd.DataFrame({'data': data})# 繪制箱線圖
plt.figure(figsize=(10, 6))
sns.boxplot(data=df['data'])
plt.title('Boxplot for Outlier Detection')
plt.show()運行上述代碼,會生成一個箱線圖,超出上下邊界的數據點即為異常值,通過觀察箱線圖,我們可以直觀地識別出異常值。
- Z-Score:Z-Score 是一種基于標準差的異常值檢測方法。它通過計算每個數據點與均值的標準差偏離程度來判斷是否為異常值。Z-Score 的計算公式為:Z = (X - μ) / σ,其中 X 是數據點,μ 是均值,σ 是標準差。通常情況下,Z-Score 的絕對值大于 3 的數據點被視為異常值。
import numpy as np
import pandas as pd# 示例數據
data = np.array([10, 12, 12, 13, 12, 13, 14, 14, 14, 15, 16, 18, 19, 20, 30])
df = pd.DataFrame({'data': data})# 計算均值和標準差
mean = df['data'].mean()
std_dev = df['data'].std()# 計算Z-Score
df['z_score'] = (df['data'] - mean) / std_dev# 識別異常值
threshold = 3
outliers = df[df['z_score'].abs() > threshold]
print(outliers)在上述代碼中,首先計算數據的均值和標準差,然后計算每個數據點的 Z-Score,最后通過設置閾值(這里為 3)來識別異常值。運行代碼后,會輸出檢測到的異常值。
5.2.2 處理異常值
對于檢測到的異常值,可以采取以下幾種處理方式:
- 修正異常值:如果異常值是由于數據錄入錯誤等原因導致的,可以根據實際情況進行修正。例如,將一個明顯錯誤的年齡值(如 200 歲)修正為合理的值。
- 刪除異常值:當異常值對分析結果影響較大且無法修正時,可以選擇刪除異常值。使用 drop () 方法可以刪除 DataFrame 中指定的行。
# 刪除異常值
df = df[df['z_score'].abs() <= threshold]
print(df)在上述代碼中,通過布爾索引刪除了 Z-Score 絕對值大于閾值的行,即刪除了異常值。
- 轉換異常值:可以對異常值進行轉換,使其對分析結果的影響減小。例如,對數據進行對數變換,將異常值的影響分散到整個數據集中。
import numpy as np
import pandas as pd# 示例數據
data = np.array([10, 12, 12, 13, 12, 13, 14, 14, 14, 15, 16, 18, 19, 20, 30])
df = pd.DataFrame({'data': data})# 對數據進行對數變換
df['log_data'] = np.log(df['data'])
print(df)在上述代碼中,使用 np.log () 函數對數據進行對數變換,得到了一個新的列 'log_data',這樣可以在一定程度上減小異常值的影響。
5.3 重復值處理
重復值是指數據集中完全相同或部分相同的記錄。重復值的存在會占用存儲空間,影響數據分析的效率和準確性,因此需要對其進行處理。
在 Pandas 中,可以使用 duplicated () 方法檢測數據集中的重復行,該方法會返回一個布爾值的 Series,表示每行是否為重復行(True 表示是重復行,False 表示不是重復行)。使用 drop_duplicates () 方法可以刪除重復行。
import pandas as pd# 創建一個包含重復值的DataFrame
data = {'A': [1, 2, 2, 4],'B': [5, 6, 6, 8],'C': [9, 10, 10, 12]}
df = pd.DataFrame(data)# 檢測重復值
print(df.duplicated())# 刪除重復值
df = df.drop_duplicates()
print(df)在上述代碼中,首先使用 duplicated () 方法檢測重復值,然后使用 drop_duplicates () 方法刪除重復值。運行代碼后,可以看到檢測結果和刪除重復值后的 DataFrame。
drop_duplicates () 方法也有一些參數可以設置,例如:
- subset:指定要檢查的列,只檢查指定列是否重復。
- keep:指定保留哪一行,'first' 表示保留第一次出現的行(默認),'last' 表示保留最后一次出現的行,False 表示刪除所有重復行。
5.4 數據轉換
數據轉換是將數據從一種格式或表示形式轉換為另一種格式或表示形式的過程,以滿足數據分析和建模的需求。常見的數據轉換操作包括數據類型轉換、數據標準化與歸一化等。
5.4.1 數據類型轉換
在數據分析中,有時需要將數據從一種類型轉換為另一種類型。例如,將字符串類型的數值轉換為數值類型,以便進行數學運算。在 Pandas 中,可以使用 astype () 方法進行數據類型轉換。
import pandas as pd# 創建一個包含字符串類型數值的DataFrame
data = {'A': ['1', '2', '3', '4'],'B': ['5', '6', '7', '8']}
df = pd.DataFrame(data)# 將列A轉換為整數類型
df['A'] = df['A'].astype(int)
print(df.dtypes)在上述代碼中,使用 astype (int) 將列 'A' 的數據類型從字符串轉換為整數。運行代碼后,可以看到列 'A' 的數據類型已經變為 int64。
除了基本的數據類型轉換,還可以進行日期時間類型的轉換。例如,將字符串類型的日期轉換為 Pandas 的日期時間類型,以便進行日期時間相關的操作。
import pandas as pd# 創建一個包含字符串類型日期的DataFrame
data = {'日期': ['2023-01-01', '2023-01-02', '2023-01-03']}
df = pd.DataFrame(data)# 將列'日期'轉換為日期時間類型
df['日期'] = pd.to_datetime(df['日期'])
print(df.dtypes)在上述代碼中,使用 pd.to_datetime () 將列 ' 日期 ' 的字符串類型轉換為日期時間類型。運行代碼后,可以看到列 ' 日期 ' 的數據類型已經變為 datetime64 [ns]。
5.4.2 數據標準化與歸一化
數據標準化和歸一化是將數據轉換為統一尺度的過程,有助于提高數據分析和機器學習模型的性能。
- 數據標準化(Z-Score 標準化):標準化是依照特征矩陣的列處理數據,通過特征的平均值和標準差,將特征縮放成一個標準的正態分布,縮放后均值為 0,方差為 1。標準化的公式為:\(x' = \frac{x - \mu}{\sigma}\),其中\(x\)是原始數據值,\(x'\)是標準化后的數據值,\(\mu\)是均值,\(\sigma\)是標準差。
import numpy as np
from sklearn.preprocessing import StandardScaler# 示例數據
data = np.array([[10, 10, 15, 10],[5, 1, 21, 5],[1, 2, 15, 12]])# 創建StandardScaler對象
scaler = StandardScaler()# 對數據進行標準化
scaled_data = scaler.fit_transform(data)
print(scaled_data)在上述代碼中,使用 scikit-learn 庫中的 StandardScaler 對數據進行標準化。首先創建 StandardScaler 對象,然后使用 fit_transform () 方法對數據進行擬合和轉換。運行代碼后,可以看到標準化后的數據。
- 數據歸一化(Min-Max 歸一化):歸一化是利用特征的最大值和最小值,將特征縮放到 [0, 1] 區間。歸一化的公式為:\(x' = \frac{x - min}{max - min}\),其中\(x\)是原始數據值,\(x'\)是歸一化后的數據值,\(min\)是最小值,\(max\)是最大值。
import numpy as np
from sklearn.preprocessing import MinMaxScaler# 示例數據
data = np.array([[10, 10, 15, 10],[5, 1, 21, 5],[1, 2, 15, 12]])# 創建MinMaxScaler對象
scaler = MinMaxScaler()# 對數據進行歸一化
normalized_data = scaler.fit_transform(data)
print(normalized_data)在上述代碼中,使用 scikit-learn 庫中的 MinMaxScaler 對數據進行歸一化。首先創建 MinMaxScaler 對象,然后使用 fit_transform () 方法對數據進行擬合和轉換。運行代碼后,可以看到歸一化后的數據。
標準化和歸一化的選擇取決于具體的應用場景。一般來說,當數據存在異常值或數據分布未知時,標準化更為合適,因為它對異常值不敏感;當數據的最大值和最小值已知,且需要將數據縮放到特定范圍時,歸一化更為適用。

六、數據分析與建模
6.1 描述性統計分析
描述性統計分析是數據分析的基礎環節,它通過計算數據的一些基本統計量,幫助我們快速了解數據的整體特征和分布情況。在 Python 中,Pandas 庫為我們提供了豐富的函數和方法來進行描述性統計分析。
計算均值是描述性統計中常用的操作之一,它可以反映數據的集中趨勢。使用 Pandas 的mean()方法可以輕松計算 DataFrame 或 Series 的均值。假設我們有一個包含學生成績的 DataFrame:
import pandas as pd# 創建示例數據
data = {'學生姓名': ['張三', '李四', '王五', '趙六'],'數學成績': [85, 90, 78, 95],'語文成績': [76, 88, 82, 90]
}
df = pd.DataFrame(data)# 計算數學成績的均值
math_mean = df['數學成績'].mean()
print(f'數學成績的均值為: {math_mean}')# 計算所有成績的均值
all_mean = df[['數學成績', '語文成績']].mean()
print(f'所有成績的均值為:\n{all_mean}')上述代碼中,首先通過df['數學成績'].mean()計算了 ' 數學成績 ' 列的均值,然后通過df[['數學成績', '語文成績']].mean()計算了 ' 數學成績 ' 和' 語文成績 ' 兩列的均值,并將結果打印輸出。
中位數是將數據從小到大排序后,位于中間位置的數值(如果數據個數為奇數)或中間兩個數的平均值(如果數據個數為偶數)。中位數可以避免極端值對數據集中趨勢的影響。使用median()方法可以計算中位數:
# 計算數學成績的中位數
math_median = df['數學成績'].median()
print(f'數學成績的中位數為: {math_median}')運行上述代碼,即可得到 ' 數學成績 ' 列的中位數。
標準差用于衡量數據的離散程度,標準差越大,說明數據的離散程度越大,數據越分散;標準差越小,說明數據越集中。使用std()方法計算標準差:
# 計算數學成績的標準差
math_std = df['數學成績'].std()
print(f'數學成績的標準差為: {math_std}')通過上述代碼,我們可以得到 ' 數學成績 ' 列的標準差,從而了解該列數據的離散情況。
分位數是描述性統計中的重要概念,它可以幫助我們了解數據在不同位置的分布情況。常見的分位數有四分位數(25%、50%、75% 分位數)、百分位數等。使用quantile()方法可以計算分位數:
# 計算數學成績的25%分位數
math_25_quantile = df['數學成績'].quantile(0.25)
print(f'數學成績的25%分位數為: {math_25_quantile}')# 計算數學成績的75%分位數
math_75_quantile = df['數學成績'].quantile(0.75)
print(f'數學成績的75%分位數為: {math_75_quantile}')上述代碼分別計算了 ' 數學成績 ' 列的 25% 分位數和 75% 分位數,通過這些分位數,我們可以更全面地了解數學成績的分布情況。
除了上述單個統計量的計算,Pandas 還提供了describe()方法,該方法可以一次性計算出 DataFrame 中所有數值列的多個描述性統計量,包括計數、均值、標準差、最小值、25% 分位數、50% 分位數(中位數)、75% 分位數和最大值,非常方便快捷:
# 計算所有數值列的描述性統計量
desc_stats = df[['數學成績', '語文成績']].describe()
print(f'所有數值列的描述性統計量為:\n{desc_stats}')運行上述代碼,將會輸出一個包含所有數值列描述性統計量的 DataFrame,我們可以直觀地看到數據的各種特征。通過這些描述性統計分析,我們能夠對數據有一個初步的了解,為后續更深入的數據分析和建模提供基礎。
6.2 相關性分析
在數據分析中,了解數據特征之間的相關性是非常重要的,它可以幫助我們發現數據之間的潛在關系,為進一步的分析和決策提供依據。Python 中的 Pandas 和 Seaborn 庫提供了強大的工具來計算和可視化數據特征之間的相關性。
使用 Pandas 計算相關性非常簡單,通過corr()方法可以計算 DataFrame 中數值列之間的皮爾遜相關系數。皮爾遜相關系數是一種常用的度量兩個變量之間線性相關程度的指標,其取值范圍在 - 1 到 1 之間,值越接近 1 表示正相關性越強,值越接近 -1 表示負相關性越強,值接近 0 表示相關性較弱。
import pandas as pd# 創建示例數據
data = {'數學成績': [85, 90, 78, 95, 88],'語文成績': [76, 88, 82, 90, 85],'英語成績': [80, 85, 70, 92, 86]
}
df = pd.DataFrame(data)# 計算相關性矩陣
corr_matrix = df.corr()
print(corr_matrix)上述代碼中,首先創建了一個包含 ' 數學成績 '、' 語文成績 ' 和' 英語成績 ' 的 DataFrame,然后使用df.corr()計算了各成績之間的相關性矩陣。輸出的相關性矩陣中,對角線上的值都為 1,因為每個變量與自身的相關性是完全相關的;其他位置的值表示對應兩個變量之間的相關系數。
為了更直觀地展示相關性,我們可以使用 Seaborn 庫繪制相關性熱圖。熱圖通過顏色的深淺來表示相關性的強弱,使我們能夠一目了然地看出各個變量之間的關系。
import seaborn as sns
import matplotlib.pyplot as plt# 繪制相關性熱圖
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.title('成績相關性熱圖')
plt.show()在上述代碼中,首先導入了 Seaborn 庫和 Matplotlib 庫的pyplot模塊。然后使用plt.figure()設置圖形大小,接著使用sns.heatmap()繪制相關性熱圖,其中annot=True表示在熱圖上顯示相關系數的值,cmap='coolwarm'指定了顏色映射方案,使相關性強的區域顏色更深,相關性弱的區域顏色更淺。最后,使用plt.title()添加標題,并通過plt.show()顯示圖形。運行代碼后,我們可以看到一個直觀的相關性熱圖,通過顏色和數值可以清晰地了解各成績之間的相關性強弱。例如,如果數學成績和英語成績的相關系數較高且顏色較深,說明這兩門成績之間存在較強的正相關關系;如果相關系數接近 0 且顏色較淺,說明它們之間的相關性較弱。通過這種方式,我們能夠快速發現數據特征之間的潛在關系,為數據分析和決策提供有力支持。
6.3 數據分組與聚合
數據分組與聚合是數據分析中常用的操作,它可以幫助我們按照不同的維度對數據進行匯總分析,從而發現數據在不同分組下的特征和規律。在 Python 中,Pandas 庫提供了強大的groupby功能來實現數據分組與聚合操作。
使用groupby方法可以根據一個或多個列對 DataFrame 進行分組,然后對每個組應用聚合函數。假設我們有一個包含銷售數據的 DataFrame,其中包含 ' 地區 '、' 產品 ' 和' 銷售額 ' 等列,我們想要按 ' 地區 ' 分組,計算每個地區的總銷售額。
import pandas as pd# 創建示例數據
data = {'地區': ['華北', '華東', '華北', '華東', '華南'],'產品': ['A', 'B', 'A', 'C', 'B'],'銷售額': [100, 150, 120, 90, 180]
}
df = pd.DataFrame(data)# 按地區分組,計算每個地區的總銷售額
grouped_sales = df.groupby('地區')['銷售額'].sum()
print(grouped_sales)上述代碼中,首先使用df.groupby('地區')按 ' 地區 ' 列對 DataFrame 進行分組,然后通過['銷售額'].sum()對每個分組中的 ' 銷售額 ' 列應用sum聚合函數,計算每個地區的總銷售額。輸出結果是一個以 ' 地區 ' 為索引,總銷售額為值的 Series 對象,我們可以清晰地看到每個地區的銷售總額情況。
我們還可以按多個列進行分組,例如,按 ' 地區 ' 和' 產品 ' 分組,計算每個地區每種產品的平均銷售額。
# 按地區和產品分組,計算每個地區每種產品的平均銷售額
grouped_avg_sales = df.groupby(['地區', '產品'])['銷售額'].mean()
print(grouped_avg_sales)在這段代碼中,df.groupby(['地區', '產品'])按 ' 地區 ' 和' 產品 ' 兩列進行分組,然后對每個分組中的 ' 銷售額 ' 列應用mean聚合函數,計算平均銷售額。輸出結果是一個具有層次化索引的 Series 對象,第一級索引為 ' 地區 ',第二級索引為 ' 產品 ',對應的值為每個地區每種產品的平均銷售額。這樣,我們可以更細致地了解不同地區不同產品的銷售情況。
除了常用的聚合函數如sum、mean外,Pandas 還支持其他聚合函數,如count(計數)、max(最大值)、min(最小值)等。我們可以同時應用多個聚合函數進行分析。
# 按地區分組,同時計算每個地區銷售額的總和、平均值、最大值和最小值
grouped_multi_stats = df.groupby('地區')['銷售額'].agg(['sum', 'mean','max','min'])
print(grouped_multi_stats)上述代碼中,df.groupby('地區')['銷售額'].agg(['sum', 'mean','max','min'])按 ' 地區 ' 分組后,對 ' 銷售額 ' 列同時應用了sum、mean、max和min四個聚合函數。agg方法接受一個函數列表,用于對每個分組的數據進行多個聚合操作。輸出結果是一個 DataFrame 對象,列名為聚合函數名,行索引為 ' 地區 ',展示了每個地區銷售額的多種統計信息,為我們提供了更全面的數據分析視角。通過數據分組與聚合操作,我們能夠從不同維度深入分析數據,挖掘數據背后的信息和規律,為業務決策提供有力的數據支持。
6.4 機器學習基礎與建模
6.4.1 機器學習簡介
機器學習是一門多領域交叉學科,它涉及概率論、統計學、逼近論、凸分析、算法復雜度理論等多門學科,旨在讓計算機通過數據學習模式和規律,并利用這些模式和規律進行預測和決策。機器學習在當今數字化時代發揮著至關重要的作用,廣泛應用于各個領域,如金融領域的風險評估與預測、醫療領域的疾病診斷與預測、電商領域的推薦系統、圖像識別領域的人臉識別和物體檢測等。
機器學習主要分為以下幾類:
- 監督學習:監督學習是最常見的機器學習類型之一,它使用標記數據進行訓練,即每個樣本都有對應的標簽或目標值。模型通過學習輸入特征與標簽之間的關系,來對新的未知數據進行預測。例如,在一個預測房價的任務中,我們可以使用房屋的面積、房間數量、地理位置等特征作為輸入,房屋的實際價格作為標簽,通過監督學習算法訓練模型,使其能夠根據新的房屋特征預測房價。常見的監督學習算法包括線性回歸、邏輯回歸、決策樹、支持向量機、隨機森林等。
- 無監督學習:無監督學習使用未標記的數據進行訓練,數據中沒有預先定義的標簽。其目標是發現數據中的內在結構、模式或關系,例如聚類、降維、異常檢測等。聚類算法可以將數據點劃分為不同的組,使得同一組內的數據點具有較高的相似性,而不同組之間的數據點具有較大的差異性。降維算法則可以將高維數據轉換為低維數據,在保留數據主要特征的同時,減少數據的維度,降低計算復雜度。例如,在客戶細分中,我們可以使用無監督學習算法對客戶的購買行為、偏好等數據進行分析,將客戶劃分為不同的群體,以便企業能夠針對不同群體制定個性化的營銷策略。常見的無監督學習算法有 K-Means 聚類、層次聚類、主成分分析(PCA)等。
- 半監督學習:半監督學習結合了監督學習和無監督學習的特點,使用少量的標記數據和大量的未標記數據進行訓練。這種學習方式在標記數據獲取成本較高時非常有用,通過利用未標記數據中的信息,可以提高模型的性能和泛化能力。例如,在圖像分類任務中,可能只有少量的圖像被人工標注了類別標簽,而大量的圖像沒有標簽,半監督學習算法可以利用這些未標記圖像中的特征信息,結合少量的標記圖像,訓練出一個性能較好的圖像分類模型。
- 強化學習:強化學習是一種基于環境反饋的學習方法,智能體(agent)在環境中采取行動,并根據環境返回的獎勵或懲罰信號來學習最優的行為策略。智能體通過不斷地嘗試和探索,逐漸找到在不同狀態下能夠獲得最大獎勵的行動。強化學習在機器人控制、游戲、自動駕駛等領域有廣泛的應用。例如,在訓練一個自動駕駛汽車的模型時,汽車作為智能體,在行駛過程中根據路況、交通規則等環境信息采取加速、減速、轉彎等行動,通過獲得的獎勵(如安全到達目的地、遵守交通規則等)和懲罰(如碰撞、違規等)來不斷優化自己的駕駛策略,最終學會在各種復雜環境下安全、高效地行駛。
6.4.2 模型訓練與評估
為了更直觀地展示機器學習模型的訓練與評估過程,我們以一個簡單的線性回歸問題為例,使用 Scikit-learn 庫進行實現。線性回歸是一種用于預測連續數值的監督學習算法,它試圖找到一個線性關系,將輸入特征映射到輸出目標值。
首先,我們需要導入必要的庫,包括用于數據處理的 Pandas 和 NumPy,用于數據分割的train_test_split函數,用于線性回歸模型的LinearRegression類,以及用于評估模型性能的mean_squared_error函數。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error接著,我們創建一個簡單的數據集,這里假設我們有房屋面積和房價的數據。
# 創建示例數據
data = {'房屋面積': [100, 120, 80, 150, 90],'房價': [200, 250, 160, 300, 180]
}
df = pd.DataFrame(data)然后,我們將數據集劃分為特征矩陣X和目標變量y,并使用train_test_split函數將數據分割為訓練集和測試集,其中測試集占比 20%。
# 劃分特征矩陣和目標變量
X = df[['房屋面積']]
y = df['房價']# 分割訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)接下來,我們創建線性回歸模型對象,并使用訓練集數據對模型進行訓練。
# 創建線性回歸模型
model = LinearRegression()# 訓練模型
model.fit(X_train, y_train)模型訓練完成后,我們使用測試集數據進行預測,并計算預測結果與真實值之間的均方誤差(MSE)來評估模型的性能。均方誤差是一種常用的回歸模型評估指標,它衡量了預測值與真實值之間的平均誤差平方,值越小表示模型的預測效果越好。
# 進行預測
y_pred = model.predict(X_test)# 計算均方誤差
mse = mean_squared_error(y_test, y_pred)
print(f'均方誤差: {mse}')通過上述步驟,我們完成了一個簡單的線性回歸模型的訓練與評估過程。在實際應用中,我們還可以對模型進行調優,如選擇不同的算法、調整模型參數、進行特征工程等,以提高模型的性能和泛化能力。同時,還可以使用其他評估指標,如決定系數(R2)、平均絕對誤差(MAE)等,從不同角度評估模型的表現。例如,決定系數可以衡量模型對數據的擬合優度,其值越接近 1 表示模型對數據的擬合效果越好;平均絕對誤差則衡量了預測值與真實值之間的平均絕對誤差,它對異常值的敏感度相對較低。通過綜合使用多種評估指標,可以更全面、準確地評估模型的性能,為模型的選擇和優化提供依據。

七、數據可視化進階
7.1 Plotly 交互式可視化
在數據可視化的領域中,Plotly 庫以其獨特的交互式特性脫穎而出,為我們呈現了一種全新的數據展示方式。Plotly 支持多種圖表類型,并且能夠創建高度交互的可視化效果,讓用戶能夠通過縮放、平移、懸停等操作,深入探索數據背后的細節信息。
Plotly Express 是 Plotly 的高級 API,它提供了一種簡潔、直觀的方式來創建各種交互式圖表。下面,我們通過幾個示例來展示如何使用 Plotly Express 創建常見的交互式圖表。
首先,我們來創建一個交互式散點圖,以展示兩個變量之間的關系。假設我們有一組關于房屋面積和房價的數據,想要觀察它們之間的分布情況:
import plotly.express as px
import pandas as pd# 創建示例數據
data = {'房屋面積': [100, 120, 80, 150, 90],'房價': [200, 250, 160, 300, 180]
}
df = pd.DataFrame(data)# 使用Plotly Express創建散點圖
fig = px.scatter(df, x='房屋面積', y='房價', title='房屋面積與房價的關系')
fig.show()運行上述代碼后,會彈出一個交互式的散點圖窗口。在這個窗口中,當我們將鼠標懸停在某個數據點上時,會顯示該數據點對應的房屋面積和房價的具體數值;我們還可以通過鼠標滾輪進行縮放操作,以便更清晰地觀察數據點的分布情況;拖動鼠標可以平移圖表,查看不同區域的數據。
接下來,創建一個交互式折線圖,展示時間序列數據的變化趨勢。假設我們有某公司過去一年每個月的銷售額數據:
import plotly.express as px
import pandas as pd# 創建示例數據
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
sales = [100, 120, 150, 130, 180, 200, 220, 250, 230, 280, 300, 350]
data = {'月份': months, '銷售額': sales}
df = pd.DataFrame(data)# 使用Plotly Express創建折線圖
fig = px.line(df, x='月份', y='銷售額', title='某公司過去一年銷售額變化趨勢')
fig.show()在生成的折線圖中,我們不僅可以看到每個月銷售額的變化趨勢,還能通過交互操作,在鼠標懸停時獲取每個月具體的銷售額數值,并且可以縮放和平移圖表,聚焦于我們感興趣的時間段。
再來看一個交互式柱狀圖的例子,用于比較不同類別的數據。假設我們有不同城市的人口數據:
import plotly.express as px
import pandas as pd# 創建示例數據
cities = ['北京', '上海', '廣州', '深圳']
populations = [2154, 2428, 1531, 1343]
data = {'城市': cities, '人口(萬)': populations}
df = pd.DataFrame(data)# 使用Plotly Express創建柱狀圖
fig = px.bar(df, x='城市', y='人口(萬)', title='不同城市人口對比')
fig.show()在這個交互式柱狀圖中,當鼠標懸停在某個柱子上時,會顯示該城市的具體人口數量。我們可以通過縮放操作,更清晰地比較不同城市人口之間的差異,也可以平移圖表,查看整個數據的分布情況。通過這些簡單的示例,我們可以看到 Plotly Express 創建的交互式圖表,極大地增強了數據的可視化效果和用戶與數據的交互性,使我們能夠更深入、全面地理解數據。
7.2 高級圖表定制
在使用 Plotly 進行數據可視化時,除了創建基本的交互式圖表外,我們還可以對圖表進行更高級的定制,以滿足不同的展示需求和審美要求。這包括添加注釋、調整布局、設置交互行為等方面,使圖表更加豐富、專業和易于理解。
首先,我們來看如何添加注釋。注釋可以幫助我們在圖表中標記重要的數據點、區域或添加額外的說明信息,從而更好地傳達數據的含義。例如,在之前的房屋面積與房價散點圖中,我們想要標記出某個具有代表性的房屋數據點:
import plotly.express as px
import pandas as pd# 創建示例數據
data = {'房屋面積': [100, 120, 80, 150, 90],'房價': [200, 250, 160, 300, 180]
}
df = pd.DataFrame(data)# 使用Plotly Express創建散點圖
fig = px.scatter(df, x='房屋面積', y='房價', title='房屋面積與房價的關系')# 添加注釋
fig.add_annotation(x=120, # 注釋的x坐標y=250, # 注釋的y坐標text='這是一個典型的房屋數據點', # 注釋文本showarrow=True, # 顯示箭頭arrowhead=1 # 箭頭形狀
)
fig.show()運行上述代碼后,在散點圖中,我們會看到一個帶有箭頭的注釋指向坐標為 (120, 250) 的數據點,并顯示注釋文本 “這是一個典型的房屋數據點”。通過這種方式,我們可以突出重要的數據信息,幫助觀眾更好地理解圖表。
布局調整是圖表定制的另一個重要方面,它可以影響圖表的整體外觀和可讀性。我們可以調整圖表的標題、軸標簽、圖例位置、背景顏色等。例如,對之前的銷售額變化趨勢折線圖進行布局調整:
import plotly.express as px
import pandas as pd# 創建示例數據
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
sales = [100, 120, 150, 130, 180, 200, 220, 250, 230, 280, 300, 350]
data = {'月份': months, '銷售額': sales}
df = pd.DataFrame(data)# 使用Plotly Express創建折線圖
fig = px.line(df, x='月份', y='銷售額', title='某公司過去一年銷售額變化趨勢')# 調整布局
fig.update_layout(title_font_size=20, # 標題字體大小xaxis_title='月份', # x軸標簽yaxis_title='銷售額', # y軸標簽legend_title='圖例', # 圖例標題legend=dict(orientation='h', # 圖例水平顯示yanchor='bottom',y=1.02,xanchor='right',x=1), # 圖例位置plot_bgcolor='white', # 繪圖區域背景顏色paper_bgcolor='lightgray' # 圖表背景顏色
)
fig.show()在這段代碼中,我們通過update_layout方法對圖表的布局進行了一系列調整。增大了標題字體大小,使其更加醒目;明確了 x 軸和 y 軸的標簽,使坐標軸含義清晰;將圖例設置為水平顯示,并調整了其位置;同時,分別設置了繪圖區域和圖表的背景顏色,使圖表整體看起來更加美觀和專業。
設置交互行為可以進一步增強用戶與圖表的互動體驗。例如,我們可以設置點擊數據點時的操作,如顯示更多詳細信息、跳轉到相關頁面等。下面以散點圖為例,設置點擊數據點時顯示彈窗信息:
import plotly.express as px
import pandas as pd# 創建示例數據
data = {'房屋面積': [100, 120, 80, 150, 90],'房價': [200, 250, 160, 300, 180],'房屋詳情': ['兩居室,精裝修', '三居室,毛坯房', '一居室,簡裝修', '四居室,豪華裝修', '兩居室,普通裝修']
}
df = pd.DataFrame(data)# 使用Plotly Express創建散點圖
fig = px.scatter(df, x='房屋面積', y='房價', hover_name='房屋詳情', title='房屋面積與房價的關系')# 設置點擊數據點的交互行為
fig.update_traces(hovertemplate='房屋面積: %{x}<br>房價: %{y}<br>房屋詳情: %{customdata[0]}',customdata=df[['房屋詳情']]
)
fig.show()在上述代碼中,我們首先在創建散點圖時,通過hover_name參數設置鼠標懸停時顯示的信息為房屋詳情。然后,使用update_traces方法設置點擊數據點時的交互行為,hovertemplate定義了彈窗中顯示的內容格式,customdata指定了要顯示的額外數據。這樣,當我們點擊散點圖中的數據點時,會彈出一個包含房屋面積、房價和房屋詳情的彈窗,為用戶提供更詳細的數據信息。通過這些高級圖表定制操作,我們可以創建出更加個性化、功能豐富的可視化圖表,更好地展示數據的內涵和價值。
7.3 動態圖表制作
在數據可視化中,動態圖表能夠展示數據隨時間或其他變量的變化過程,為我們提供更加直觀和豐富的信息。Python 提供了多種方法來制作動態圖表,下面我們將介紹使用 Matplotlib 的動畫模塊(如 FuncAnimation)以及其他動態圖表庫來創建動態圖表。
Matplotlib 是 Python 中常用的繪圖庫,其動畫模塊FuncAnimation可以幫助我們創建動態圖表。以一個簡單的動態折線圖為例,展示隨著時間變化,正弦函數的曲線動態變化:
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import numpy as np# 創建圖形和子圖
fig, ax = plt.subplots()
x = np.linspace(0, 2 * np.pi, 100)
line, = ax.plot(x, np.sin(x))# 更新函數,用于每一幀的更新
def update(frame):line.set_ydata(np.sin(x + frame / 10.0)) # 更新y數據return line,# 創建動畫
ani = FuncAnimation(fig, update, frames=100, interval=50, blit=True)# 顯示圖表
plt.show()在上述代碼中,首先創建了一個圖形和子圖,并繪制了初始的正弦函數曲線。update函數是動畫的核心,它接受一個frame參數,表示當前的幀數。在每一幀中,通過修改曲線的 y 數據來實現動態效果。FuncAnimation函數用于創建動畫,其中frames參數指定幀數,interval參數指定每幀之間的時間間隔(單位為毫秒),blit=True表示只更新變化的部分,以提高動畫的繪制效率。運行代碼后,我們可以看到正弦函數曲線隨著時間動態變化,呈現出一個生動的動畫效果。
除了 Matplotlib,還有其他一些動態圖表庫可以使用,例如pandas - alive,它完美結合了 Pandas 數據格式和 Matplotlib 的強大功能,使得制作動圖變得更加容易。以下是使用pandas - alive創建動態條形圖的示例:
import pandas as pd
import pandas_alive# 創建示例數據
data = {'年份': [2010, 2011, 2012, 2013, 2014],'蘋果銷量': [100, 120, 150, 130, 180],'香蕉銷量': [80, 90, 110, 100, 140]
}
df = pd.DataFrame(data)
df.set_index('年份', inplace=True)# 使用pandas_alive創建動態條形圖
df.plot_animated(filename='sales_animation.gif', kind='bar', period_label={'x': 0.1, 'y': 0.9})在這段代碼中,我們首先創建了一個包含不同年份蘋果和香蕉銷量的 DataFrame,并將年份設置為索引。然后,使用plot_animated方法創建動態條形圖,filename參數指定生成的動畫文件名,kind='bar'表示創建條形圖,period_label參數用于設置時間標簽的位置。運行代碼后,會生成一個名為sales_animation.gif的動態條形圖,展示了不同年份蘋果和香蕉銷量的變化情況。通過這些方法,我們可以根據具體需求選擇合適的工具來制作動態圖表,為數據可視化增添更多的魅力和表現力,讓數據以更加生動的方式展現出來。

八、自動化與批量處理
8.1 使用循環批量處理數據
在數據分析過程中,經常會遇到需要對多個數據文件進行相同分析操作的情況。手動逐個處理不僅效率低下,還容易出錯。Python 的循環機制為我們提供了一種高效的解決方案,通過循環可以自動對多個文件進行操作,并將結果整合起來。
假設我們有一個文件夾,里面包含多個 CSV 格式的銷售數據文件,每個文件記錄了不同月份的銷售情況。我們的目標是讀取每個文件,計算每個文件中的銷售總額,并將所有文件的銷售總額匯總。
首先,我們需要導入必要的庫,這里用到os庫來操作文件和目錄,pandas庫來處理數據:
import os
import pandas as pd# 定義數據文件夾路徑
data_folder ='sales_data'
total_sales = 0# 獲取文件夾中所有CSV文件的文件名
file_names = [file for file in os.listdir(data_folder) if file.endswith('.csv')]# 循環處理每個文件
for file_name in file_names:file_path = os.path.join(data_folder, file_name)df = pd.read_csv(file_path)# 假設銷售金額列名為'sales_amount'monthly_sales = df['sales_amount'].sum()print(f'{file_name}的銷售總額為: {monthly_sales}')total_sales += monthly_salesprint(f'所有文件的銷售總額為: {total_sales}')在上述代碼中,我們首先使用os.listdir獲取指定文件夾中的所有文件和目錄名,通過列表推導式篩選出以.csv結尾的文件,得到包含所有 CSV 文件名的列表file_names。然后,使用for循環遍歷這個列表,對于每個文件名,使用os.path.join函數拼接出完整的文件路徑file_path,再使用pd.read_csv讀取文件內容到 DataFrame 對象df中。接著,計算當前文件中銷售金額列sales_amount的總和monthly_sales,并打印出來。最后,將每個文件的銷售總額累加到total_sales中,循環結束后,打印出所有文件的銷售總額。
通過這樣的循環批量處理,我們可以快速、準確地對多個數據文件進行相同的分析操作,大大提高了工作效率。而且,這種方式具有很好的擴展性,如果后續有新的數據文件添加到文件夾中,只需要將新文件放入指定文件夾,代碼無需修改即可自動處理。
8.2 使用函數封裝重復性步驟
當我們在數據分析中存在一些重復性的步驟時,將這些步驟封裝為函數是一個非常好的實踐。通過函數封裝,可以使代碼更加簡潔、易讀,同時也提高了代碼的可維護性和可復用性,方便在不同的數據集上重復使用。
繼續以上述銷售數據處理為例,假設我們除了計算銷售總額,還需要計算每個文件中的平均銷售金額、最大銷售金額和最小銷售金額,并且這些操作在多個數據分析任務中都會用到。我們可以將這些操作封裝成一個函數:
import pandas as pddef analyze_sales_data(file_path):df = pd.read_csv(file_path)# 假設銷售金額列名為'sales_amount'total_sales = df['sales_amount'].sum()average_sales = df['sales_amount'].mean()max_sales = df['sales_amount'].max()min_sales = df['sales_amount'].min()return total_sales, average_sales, max_sales, min_sales# 定義數據文件夾路徑
data_folder ='sales_data'# 獲取文件夾中所有CSV文件的文件名
file_names = [file for file in os.listdir(data_folder) if file.endswith('.csv')]# 循環處理每個文件
for file_name in file_names:file_path = os.path.join(data_folder, file_name)total, average, max_val, min_val = analyze_sales_data(file_path)print(f'{file_name}的銷售總額為: {total}')print(f'{file_name}的平均銷售金額為: {average}')print(f'{file_name}的最大銷售金額為: {max_val}')print(f'{file_name}的最小銷售金額為: {min_val}')print('-' * 30)
在這段代碼中,我們定義了一個名為analyze_sales_data的函數,它接受一個文件路徑file_path作為參數。在函數內部,首先讀取指定路徑的 CSV 文件到 DataFrame 對象df,然后計算銷售總額、平均銷售金額、最大銷售金額和最小銷售金額,最后將這些結果作為元組返回。在主程序中,通過循環遍歷數據文件夾中的所有 CSV 文件,對于每個文件,調用analyze_sales_data函數進行分析,并打印出分析結果。
通過函數封裝,我們將重復性的數據分析步驟整合到一個函數中,使得代碼結構更加清晰。如果后續需要修改分析邏輯,只需要在函數內部進行修改,而不需要在每個使用到這些分析步驟的地方都進行修改,大大提高了代碼的維護性。同時,這個函數可以在其他數據分析任務中被重復調用,提高了代碼的復用性。
8.3 使用 Dask 或 Apache Spark 實現分布式計算
在處理大規模數據集時,單機的計算資源往往是有限的,傳統的數據分析工具可能會面臨內存不足或計算速度過慢的問題。這時,分布式計算框架就派上了用場。Dask 和 Apache Spark 是兩個在 Python 中廣泛使用的分布式計算框架,它們能夠利用集群中多個節點的計算資源,高效地處理大規模數據集。
Dask
Dask 是一個靈活的并行計算庫,它提供了與 NumPy 和 Pandas 類似的 API,使得從傳統的單機數據分析過渡到分布式計算變得相對容易。Dask 可以處理比內存中可容納的數據集更大的數據,通過將數據分割成多個小塊(chunks),并在多個核心或計算機上并行處理這些小塊,實現高效的計算。
首先,我們需要安裝 Dask 庫,可以使用pip install dask進行安裝。如果需要使用 Dask 的分布式功能,還需要安裝dask[distributed]。
假設我們有一個非常大的 CSV 文件,無法一次性加載到內存中,使用 Dask 進行處理的示例如下:
import dask.dataframe as dd# 讀取超大CSV文件
df = dd.read_csv('large_sales_data.csv')# 假設銷售金額列名為'sales_amount',計算銷售總額
total_sales = df['sales_amount'].sum().compute()
print(f'銷售總額為: {total_sales}')
在上述代碼中,我們使用dask.dataframe中的read_csv函數讀取超大的 CSV 文件,這個函數會返回一個 Dask DataFrame 對象,它并不會立即將整個文件加載到內存中,而是將數據分成多個小塊進行管理。然后,我們像使用 Pandas DataFrame 一樣,對 Dask DataFrame 進行操作,計算銷售總額。需要注意的是,Dask 使用延遲執行策略,即操作不會立即執行,直到調用compute方法時,才會觸發計算,并將結果返回。
Dask 還支持更復雜的數據操作,如分組、聚合、連接等,并且可以輕松地與現有的 Python 數據分析代碼集成。例如,計算每個產品類別的銷售總額:
import dask.dataframe as dd# 讀取超大CSV文件
df = dd.read_csv('large_sales_data.csv')# 假設銷售金額列名為'sales_amount',產品類別列名為'product_category'
category_total_sales = df.groupby('product_category')['sales_amount'].sum().compute()
print(category_total_sales)
在這段代碼中,我們使用groupby方法對 Dask DataFrame 按product_category列進行分組,然后計算每個分組中sales_amount列的總和,最后調用compute方法得到結果。
Apache Spark
Apache Spark 是一個快速、通用的大數據處理引擎,它提供了豐富的功能和工具,用于大規模數據的處理、分析和機器學習。Spark 使用彈性分布式數據集(Resilient Distributed Dataset,RDD)作為核心抽象,能夠在集群中進行分布式計算。
在 Python 中使用 Spark,需要安裝pyspark庫。安裝完成后,我們可以通過以下示例了解如何使用 Spark 處理大規模數據。假設我們有一個包含用戶行為數據的文本文件,每行數據包含用戶 ID、行為類型和時間戳,我們想要統計每種行為類型的出現次數。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count# 創建SparkSession
spark = SparkSession.builder.appName('UserBehaviorAnalysis').getOrCreate()# 讀取文本文件,假設文件路徑為'user_behavior_data.txt'
df = spark.read.text('user_behavior_data.txt')# 將每行數據按空格分割成列
df = df.selectExpr('split(value, " ") as cols')
df = df.select(col('cols')[0].alias('user_id'), col('cols')[1].alias('behavior_type'), col('cols')[2].alias('timestamp'))# 統計每種行為類型的出現次數
behavior_count = df.groupBy('behavior_type').agg(count('*').alias('count')).show()
在上述代碼中,首先通過SparkSession.builder.appName('UserBehaviorAnalysis').getOrCreate()創建一個 SparkSession 對象,它是與 Spark 交互的入口點。然后使用spark.read.text讀取文本文件,并將其轉換為 DataFrame。接著,通過selectExpr和select方法對數據進行處理,將每行數據按空格分割成三列,并分別命名為user_id、behavior_type和timestamp。最后,使用groupBy和agg方法統計每種行為類型的出現次數,并使用show方法顯示結果。
Apache Spark 還支持多種數據源和數據格式,如 Hive、Parquet、JSON 等,并且提供了強大的機器學習庫(MLlib)和流處理功能(Spark Streaming),能夠滿足各種大規模數據處理和分析的需求。通過使用 Dask 或 Apache Spark 這樣的分布式計算框架,我們能夠突破單機計算資源的限制,高效地處理大規模數據集,為數據分析和建模提供更強大的支持。

九、案例實戰
9.1 案例背景與數據獲取
在當今競爭激烈的商業環境中,銷售數據分析對于企業的決策和發展至關重要。通過深入分析銷售數據,企業能夠了解市場趨勢、客戶需求以及產品的銷售表現,從而制定更加精準的營銷策略,優化產品組合,提高銷售業績。接下來,我們將以某電商公司的銷售數據為例,進行一次完整的數據分析與可視化實踐。
本次案例的數據來源于該電商公司過去一年的銷售記錄,數據存儲在一個 CSV 文件中,文件名為sales_data.csv。該文件包含了豐富的銷售信息,具體字段如下:
- order_id:訂單 ID,唯一標識每一筆訂單。
- product_name:產品名稱。
- category:產品所屬類別。
- quantity:銷售數量。
- price:產品單價。
- order_date:訂單日期。
- customer_id:客戶 ID,用于標識不同的客戶。
- city:客戶所在城市。
首先,我們需要使用 Pandas 庫讀取 CSV 文件中的數據,并將其轉換為 DataFrame 對象,以便后續進行處理和分析。
import pandas as pd# 讀取銷售數據
sales_data = pd.read_csv('sales_data.csv')
# 查看數據的前5行
sales_data.head()運行上述代碼后,我們可以看到 DataFrame 的前 5 行數據,初步了解數據的結構和內容。通過head()方法,我們能夠快速檢查數據是否正確讀取,以及各列的數據類型是否符合預期。
9.2 數據清洗與預處理
原始數據往往存在各種問題,如缺失值、異常值、重復值等,這些問題會影響數據分析的準確性和可靠性。因此,在進行數據分析之前,我們需要對數據進行清洗和預處理。
9.2.1 檢測與處理缺失值
使用isnull()方法檢測數據集中的缺失值,并使用sum()方法統計每列的缺失值數量。
# 檢測缺失值
missing_values = sales_data.isnull()
# 統計缺失值數量
missing_values_count = missing_values.sum()
print(missing_values_count)假設輸出結果顯示category列有 50 個缺失值,price列有 10 個缺失值。對于category列的缺失值,我們可以采用填充眾數的方法進行處理,因為category是分類數據,眾數能夠代表該列數據的集中趨勢。對于price列的缺失值,由于價格是數值型數據,我們可以使用均值填充,以保持數據的統計特征。
# 填充category列的缺失值為眾數
mode_category = sales_data['category'].mode()[0]
sales_data['category'] = sales_data['category'].fillna(mode_category)# 填充price列的缺失值為均值
mean_price = sales_data['price'].mean()
sales_data['price'] = sales_data['price'].fillna(mean_price)再次檢查缺失值,確保所有缺失值都已處理。
missing_values_count = sales_data.isnull().sum()
print(missing_values_count)9.2.2 檢測與處理異常值
使用箱線圖檢測quantity和price列的異常值。
import matplotlib.pyplot as plt
import seaborn as sns# 繪制quantity列的箱線圖
plt.figure(figsize=(10, 6))
sns.boxplot(data=sales_data['quantity'])
plt.title('Boxplot of Quantity')
plt.show()# 繪制price列的箱線圖
plt.figure(figsize=(10, 6))
sns.boxplot(data=sales_data['price'])
plt.title('Boxplot of Price')
plt.show()從箱線圖中可以觀察到,quantity列存在一些明顯的異常值(超出上下邊界的數據點)。對于這些異常值,我們可以先進行調查,判斷其是否是由于數據錄入錯誤或其他原因導致的。如果是錯誤數據,可以進行修正;如果無法確定原因,且異常值對分析結果影響較大,可以選擇刪除這些異常值。假設經過調查,我們發現quantity列的異常值是由于數據錄入錯誤導致的,我們將其修正為合理的值。
# 修正quantity列的異常值(假設異常值為負數,修正為1)
sales_data['quantity'] = sales_data['quantity'].apply(lambda x: 1 if x <= 0 else x)再次繪制箱線圖,檢查異常值是否已處理。
plt.figure(figsize=(10, 6))
sns.boxplot(data=sales_data['quantity'])
plt.title('Boxplot of Quantity after handling outliers')
plt.show()9.2.3 檢測與處理重復值
使用duplicated()方法檢測數據集中的重復行,并使用drop_duplicates()方法刪除重復行。
# 檢測重復值
duplicate_rows = sales_data.duplicated()
print(duplicate_rows.sum())# 刪除重復值
sales_data = sales_data.drop_duplicates()再次檢查重復值,確保所有重復行都已刪除。
duplicate_rows = sales_data.duplicated()
print(duplicate_rows.sum())9.2.4 數據類型轉換
檢查數據類型,確保order_date列的數據類型為日期時間類型,以便進行日期時間相關的分析。
# 檢查數據類型
print(sales_data.dtypes)如果order_date列的數據類型不是日期時間類型,使用pd.to_datetime()方法進行轉換。
# 將order_date列轉換為日期時間類型
sales_data['order_date'] = pd.to_datetime(sales_data['order_date'])再次檢查數據類型,確認order_date列已成功轉換。
print(sales_data.dtypes)經過以上數據清洗與預處理步驟,我們得到了一個干凈、整齊的數據集,為后續的數據分析和可視化奠定了堅實的基礎。
9.3 數據分析與可視化
對預處理后的數據進行深入分析,提出一些有針對性的問題,并通過可視化的方式展示分析結果,以便更直觀地理解數據背后的信息。
9.3.1 銷售趨勢分析
問題:過去一年中,每月的銷售總額是如何變化的?
為了回答這個問題,我們需要先計算每月的銷售總額,然后使用折線圖展示銷售趨勢。
# 計算每月的銷售總額
sales_data['month'] = sales_data['order_date'].dt.to_period('M')
monthly_sales = sales_data.groupby('month')['quantity', 'price'].agg({'quantity':'sum', 'price':'sum'})
monthly_sales['total_sales'] = monthly_sales['quantity'] * monthly_sales['price']# 繪制銷售趨勢折線圖
plt.figure(figsize=(12, 6))
plt.plot(monthly_sales.index.astype(str), monthly_sales['total_sales'])
plt.xlabel('Month')
plt.ylabel('Total Sales')
plt.title('Monthly Sales Trend')
plt.xticks(rotation=45)
plt.show()從折線圖中可以清晰地看出,銷售總額在過去一年中呈現出一定的季節性波動。其中,在某些月份(如 11 月和 12 月)銷售總額明顯較高,可能是由于節假日促銷活動等原因導致的。而在其他月份,銷售總額相對穩定,但也存在一些小幅度的波動。通過對銷售趨勢的分析,企業可以更好地了解市場需求的季節性變化,合理安排生產和庫存,以及制定相應的營銷策略。
9.3.2 產品銷售分布分析
問題:不同產品類別的銷售占比是怎樣的?
計算各產品類別的銷售數量和銷售總額,然后使用餅圖展示銷售占比。
# 計算各產品類別的銷售數量和銷售總額
category_sales = sales_data.groupby('category')['quantity', 'price'].agg({'quantity':'sum', 'price':'sum'})
category_sales['total_sales'] = category_sales['quantity'] * category_sales['price']# 繪制產品類別銷售占比餅圖
plt.figure(figsize=(10, 10))
plt.pie(category_sales['total_sales'], labels=category_sales.index, autopct='%1.1f%%')
plt.title('Sales Distribution by Product Category')
plt.show()從餅圖中可以直觀地看出,不同產品類別的銷售占比存在較大差異。其中,某些產品類別(如電子產品)的銷售占比較高,可能是該電商公司的核心產品;而其他產品類別(如家居用品)的銷售占比相對較低。通過對產品銷售分布的分析,企業可以了解市場對不同產品類別的需求程度,優化產品組合,加大對暢銷產品的推廣力度,同時對銷售不佳的產品進行調整或淘汰。
9.3.3 客戶購買行為分析
問題:不同城市的客戶購買數量和購買金額有何差異?
計算各城市客戶的購買數量和購買金額,然后使用柱狀圖進行對比展示。
# 計算各城市客戶的購買數量和購買金額
city_sales = sales_data.groupby('city')['quantity', 'price'].agg({'quantity':'sum', 'price':'sum'})
city_sales['total_amount'] = city_sales['quantity'] * city_sales['price']# 繪制各城市客戶購買數量和購買金額柱狀圖
plt.figure(figsize=(15, 8))
bar_width = 0.35ax1 = plt.subplot(1, 2, 1)
ax1.bar(city_sales.index, city_sales['quantity'], width=bar_width, label='Quantity')
ax1.set_xlabel('City')
ax1.set_ylabel('Total Quantity')
ax1.set_title('Quantity Purchased by City')
ax1.set_xticks(np.arange(len(city_sales.index)))
ax1.set_xticklabels(city_sales.index, rotation=45)
ax1.legend()ax2 = plt.subplot(1, 2, 2)
ax2.bar(city_sales.index, city_sales['total_amount'], width=bar_width, label='Total Amount')
ax2.set_xlabel('City')
ax2.set_ylabel('Total Amount')
ax2.set_title('Total Amount Purchased by City')
ax2.set_xticks(np.arange(len(city_sales.index)))
ax2.set_xticklabels(city_sales.index, rotation=45)
ax2.legend()plt.tight_layout()
plt.show()從柱狀圖中可以明顯看出,不同城市的客戶購買數量和購買金額存在顯著差異。一些大城市(如北京、上海、廣州)的客戶購買數量和購買金額明顯高于其他城市,這可能與這些城市的人口密度、經濟發展水平以及消費能力等因素有關。通過對客戶購買行為的分析,企業可以根據不同城市的市場特點,制定差異化的市場營銷策略,提高市場占有率和銷售業績。
通過以上數據分析與可視化,我們從不同角度深入了解了銷售數據的特征和規律,為企業提供了有價值的決策依據。企業可以根據這些分析結果,優化產品策略、營銷策略和市場布局,以適應市場變化,提高競爭力,實現可持續發展。
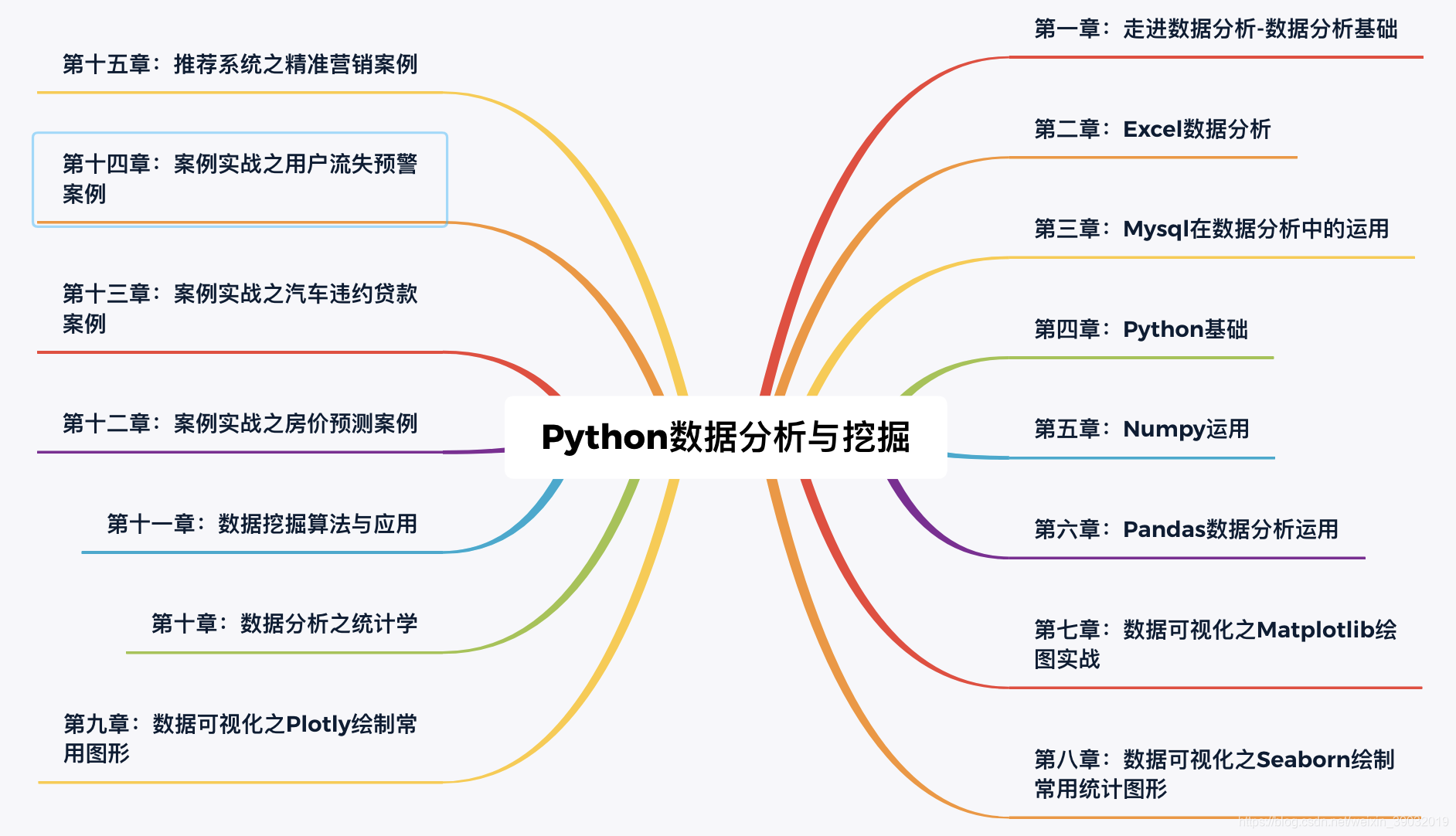
十、總結與展望
通過本次對 Python 數據分析與可視化全流程的探索,我們從基礎的庫介紹,到數據的獲取、清洗、分析以及可視化展示,再到自動化與批量處理,最后通過實際案例進行了全面的實踐。在這個過程中,我們深刻體會到了 Python 在數據分析與可視化領域的強大功能和廣泛應用。
回顧整個流程,數據獲取是基礎,我們從文件、數據庫、網絡等多種渠道獲取數據,為后續分析提供原材料。數據清洗與預處理是關鍵步驟,它能夠去除數據中的雜質和異常,使數據更加準確和可用,為分析結果的可靠性奠定基礎。數據分析與建模環節,我們運用描述性統計分析、相關性分析、數據分組與聚合等方法,深入挖掘數據背后的信息和規律,還通過機器學習進行預測和建模,為決策提供有力支持。數據可視化則是將數據分析結果以直觀、形象的方式呈現出來,幫助我們更好地理解數據,其中 Plotly 的交互式可視化和高級圖表定制為我們提供了豐富的展示方式,動態圖表制作更是為數據展示增添了生動性。自動化與批量處理提高了工作效率,讓我們能夠更高效地處理大量數據。
在實際操作中,需要注意數據的質量和準確性,確保數據清洗和預處理的徹底性。在選擇分析方法和模型時,要根據數據特點和分析目標進行合理選擇,避免盲目套用。可視化圖表的設計要注重簡潔明了,突出重點,以達到良好的展示效果。
展望未來,隨著數據量的不斷增長和數據類型的日益豐富,Python 數據分析與可視化領域有望迎來更多的發展機遇和挑戰。在技術方面,機器學習和深度學習將與數據分析更加緊密地結合,實現更智能的數據分析和預測。自動化可視化技術將不斷發展,能夠根據數據特征和用戶需求自動生成合適的可視化圖表,大大提高工作效率。在應用領域,數據分析與可視化將在更多行業得到深入應用,如醫療、金融、教育、交通等,為各行業的決策和發展提供有力支持。同時,隨著人們對數據隱私和安全的關注度不斷提高,如何在數據分析過程中保障數據的安全和隱私將成為重要的研究方向。總之,Python 數據分析與可視化領域前景廣闊,我們需要不斷學習和探索,以適應技術的發展和應用的需求。
?
相關文章推薦:
1、Python詳細安裝教程(大媽看了都會)
2、02-pycharm詳細安裝教程(大媽看了都會)
3、如何系統地自學Python?
4、Alibaba Cloud Linux 3.2104 LTS 64位 怎么安裝python3.10.12和pip3.10
5、職場新技能:Python數據分析,你掌握了嗎?
6、Python爬蟲圖片:從入門到精通
串聯文章:
1、Python小白的蛻變之旅:從環境搭建到代碼規范(1/10)?
2、Python面向對象編程實戰:從類定義到高級特性的進階之旅(2/10)
3、Python 異常處理與文件 IO 操作:構建健壯的數據處理體系(3/10)
4、從0到1:用Lask/Django框架搭建個人博客系統(4/10)
)







)
中CFG參數指的是什么?該怎么用!)









