目錄
項目介紹
內存池概念
池化技術
內存池
內存池主要解決的問題
malloc
定長內存池
申請內存
釋放內存
整體框架設計
thread cache? ? ? ??
申請內存
釋放內存
central cache
申請內存
釋放內存
?page cache
申請內存
釋放內存
大塊內存申請實現
定長內存池配合脫離使用new
性能測試
tcmalloc源碼實現基數樹優化
項目介紹
? ? ? ? 該項目實現的時一個高并發的內存池,原型是google的開源項目tcmalloc(Thread-Caching Malloc),即線程緩存的malloc,實現了高效的多線程內存管理,用于替代系統的內存分配相關函數(malloc、free)。在此僅把tcmalloc最核心的框架簡化出來模擬實現一個自己的高并發內存池。
? ? ? ? 相關知識概念:C/C++、鏈表、哈希桶、操作系統內存管理、單例模式、多線程、互斥鎖
內存池概念
? ? ? ? 我們可以通過一個現實的例子更好地理解內存池:假如有一座山,山腳處才有水流經過,而山上的居民想要打水喝,每次都需要反復地上山和下山打水,效率很低下,費時又費力。但如果在山上建一個蓄水池,通過蓄水池將山腳下的水資源轉移上來,是不是就省事很多?內存池也是一樣的。
池化技術
? ? ? ? 所謂“池化技術”,就是程序先向系統申請過量的資源,然后自己管理,以備不時之需。之所以要申請過量的資源,是因為每次申請該資源都有較大的開銷,不如提前申請好了,這樣使用時就會變得非常快捷,大大提高效率。在計算機中有很多使用“池”這種技術的地方,除了內存池,還有連接池、線程池。對象池等。以服務器上的線程池為例,它的主要思想是:先啟動若干數量的線程,讓它們處于睡眠狀態,當接受到客戶端的請求時,喚醒池中某個睡眠的線程,讓它來處理客戶端的請求,當處理完這個請求,線程又進入睡眠狀態。
內存池
? ? ? ? 內存池是指程序預先從操作系統申請一塊足夠大的內存,此后,當程序中需要申請內存的時候,不是直接向操作系統申請,而是直接從內存池中獲取;同理,當程序釋放內存的時候,并不真正地將內存返回給操作系統,而是返回內存池。當程序退出(或者特定時間內),內存池才將之前申請的內存真正釋放。
內存池主要解決的問題
? ? ? ? 通過剛才那個例子我們就能知道內存池主要解決的是效率問題。其次作為系統的內存分配器,還需要解決一下內存碎片的問題。
內存碎片主要分為外碎片和內碎片:
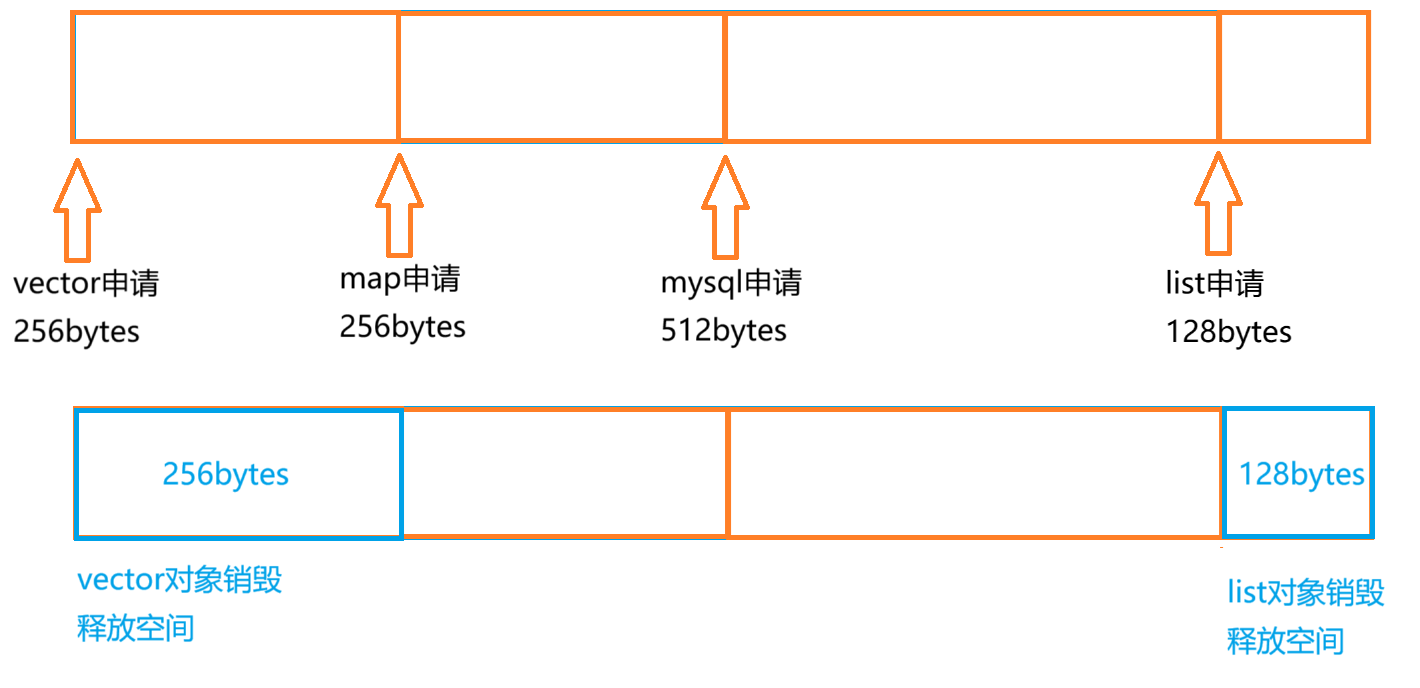
外碎片:空閑的連續內存空間太小,這些內存空間不連續,以至于合計的內存足夠,但是不能滿足一些的內存分配申請需求。如圖:
? ? ? ? vector對象和list對象銷毀后釋放空間,現有256+128=284bytes的內存空間,但是此時如果要申請大于256bytes的空間卻申請不出來,因為這兩塊空間是碎片化的,不連續。
內碎片在后續內容再作解釋。
malloc
? ? ? ? C/C++?中我們要動態申請內存都是通過malloc去申請內存,但實際上我們不是直接去堆獲取內存的。malloc就是一個內存池。malloc()相當于向操作系統“批發”了一塊較大的內存空間,然后“零售”給程序用。當全部“售完”或程序又大量的內存需求時,再根據實際需求向操作系統“進貨”。malloc的實現方式有很多種,一般不同編譯器平臺用的都是不同的。比如windows的vs系列用的微軟自己寫的一套,Linux gcc用的glibc中的ptmalloc。
但是malloc什么場景下都可以使用,這就意味著沒有針對性,什么場景下都不會有太高的性能。
介紹完相關概念,我們可以開始著手實現項目內容了。在實現之前,我們先通過一個簡單的定長內存池程序來熟悉內存申請和釋放的過程。同時,這個定長內存池也會作為項目的一個基礎組件。
定長內存池
我們首先建立一個頭文件:Common.h,這個頭文件中的內容其他文件都可能會用到。?
在windows下,是通過Virtual Alloc函數直接向堆申請頁為單位的大塊內存的:VirtualAlloc函數
而在Linux下是通過brk和mmap去向堆申請頁為單位的大塊內存的.
我們通過VirtualAlloc/brk/mmap來實現內存分配:
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// Linux下使用brk、mmap實現
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}此處使用了條件編譯,根據自己的平臺選擇不同的實現。
下面創建頭文件ObjectPool.h實現定長內存池,也就是ObjectPool類:
1.定長的概念
實現定長有兩種途徑:
(1)通過非類型模板參數實現:template <size_t N>
(2)通過類模板參數實現定長,即根據傳入的對象類型大小決定內存大小
此處采用第二種途徑。
template<class T>
class ObjectPool
{};2.定長內存池需要哪些成員變量?
_memory
首先我們肯定需要一個指針,即定長內存池的起始地址。

_left
其次我們在對內存池進行內存申請和釋放的操作時,需要一個變量來存儲內存池的剩余空間。
_freeList
此外,我們要對釋放的內存對象進行管理。我們將釋放的對象“鏈接”到自由鏈表上,因為我們是根據傳入的對象類型決定申請內存大小的,這必定意味著我們每一次申請的對象大小都是固定的該類型的長度。我們將釋放的對象“掛”在自由鏈表上,下次申請內存的時候就可以優先使用自由鏈表上的對象。
但是我們這里有必要真的用鏈表來實現_freeList嗎?答案是否定的,我們只需要讓釋放的對象能鏈接起來就可以了,換句話說,就是能根據當前對象找到下一個對象。所以我們可以用當前對象的前4/8個字節來存儲下一個對象的地址。

這樣我們通過讀取當前對象的前4/8個字節內容就可以找到下一個對象的地址了。
此處的4/8個字節大小指的就是32位/64位下指針的大小(存儲地址所需要的空間大小),那么問題來了,當我們尋找下一個對象時,怎么知道到底是讀取4個字節還是8個字節的內容呢?這一點也需要指針的運算來解決——指針在解引用時,讀取多少字節的內容取決于指針的類型:如果是對int*類型的指針進行解引用操作,我們讀取的就是前四個字節(即int大小)的內容。而如果我們對void**類型的指針進行解引用操作,我們讀取的就是void*大小的內容,void*的大小在32位下是4字節,在64位下是8字節,可以很好地解決這個問題。
(tips:這里只要使用二級指針進行操作都是可以的,如int**/char**)
申請內存
申請內存實際上就是返回申請的內存的起始地址,所以返回值即是T*類型的指針。
執行的操作:
①優先查看_freeList中有沒有可以直接使用的對象:
? ? ? ? 有的話直接將其中第一個對象“取”出來(頭刪)
②當_freeList中沒有對象時就需要向內存池申請新的內存空間:
? ? ? ? 檢查內存池剩余空間大小是否夠要申請的對象大小,不夠的話需要重新向操作系統申請大塊內存空間;
? ? ? ? 這里要注意由于我們在_freeList中是使用每個對象的前4/8個字節來存儲下一個對象的位置,必須要保證對象大小大于4/8字節。
③使用定位new對申請到的內存空間進行初始化
T* New()
{T* obj = nullptr;// 優先使用釋放的內存,循環利用if (_freeList){void* next = *((void**)_freeList);obj = (T*)_freeList;_freeList = next;}else{if (_left < sizeof(T)) // 大塊內存的剩余字節數不夠對象要申請的字節數{//重新申請大塊內存_left = 128 * 1024; // 128KB_memory = (char*)SystemAlloc(_left >> PAGE_SHIFT);// PAGE_SHIFT作為全局變量定義在Common.h中,一頁為8KB的情況下PAGE_SHIFT=13if (_memory == nullptr){throw std::bad_alloc(); // 申請失敗拋出異常}}obj = (T*)_memory;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objSize;_left -= objSize;}//自定義類型//定位new,顯式調用T的構造函數初始化new(obj)T;return obj;
}釋放內存
執行的操作:
將釋放的對象頭插到_freeList中
void Delete(T* obj)
{// 顯式調用析構函數obj->~T();// 將釋放的對象頭插到_freeList中*(void**)obj = _freeList;_freeList = obj;
}定長內存池的完整代碼:
#include "Common.h"template<class T>
class ObjectPool
{
public:T* New(){T* obj = nullptr;// 優先使用釋放的內存,循環利用if (_freeList){void* next = *((void**)_freeList);obj = (T*)_freeList;_freeList = next;}else{if (_left < sizeof(T)) // 大塊內存的剩余字節數不夠對象要申請的字節數{//重新申請大塊內存_left = 128 * 1024;_memory = (char*)SystemAlloc(_left >> PAGE_SHIFT); // 128KBif (_memory == nullptr){throw std::bad_alloc(); // 申請失敗拋出異常}}obj = (T*)_memory;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objSize;_left -= objSize;}//自定義類型//定位new,顯式調用T的構造函數初始化new(obj)T;return obj;}void Delete(T* obj){// 顯式調用析構函數obj->~T();// 將釋放的對象頭插到_freeList中*(void**)obj = _freeList;_freeList = obj;}
private:char* _memory = nullptr; // 指向申請的大塊內存的指針void* _freeList = nullptr; // 指向還回來的內存size_t _left = 0; // 大塊內存的剩余字節數
};整體框架設計
? ? ? ? 現代很多的開發環境都是多核多線程,在申請內存的情況下,必然存在激烈的鎖競爭問題。malloc本身已經非常優秀了,我們項目的原型tcmalloc是在多線程高并發的環境下更勝一籌。所以這次我們實現的內存池需要考慮以下幾方面的問題。
- 性能問題
- 多線程環境下,鎖競爭問題
- 內存碎片問題
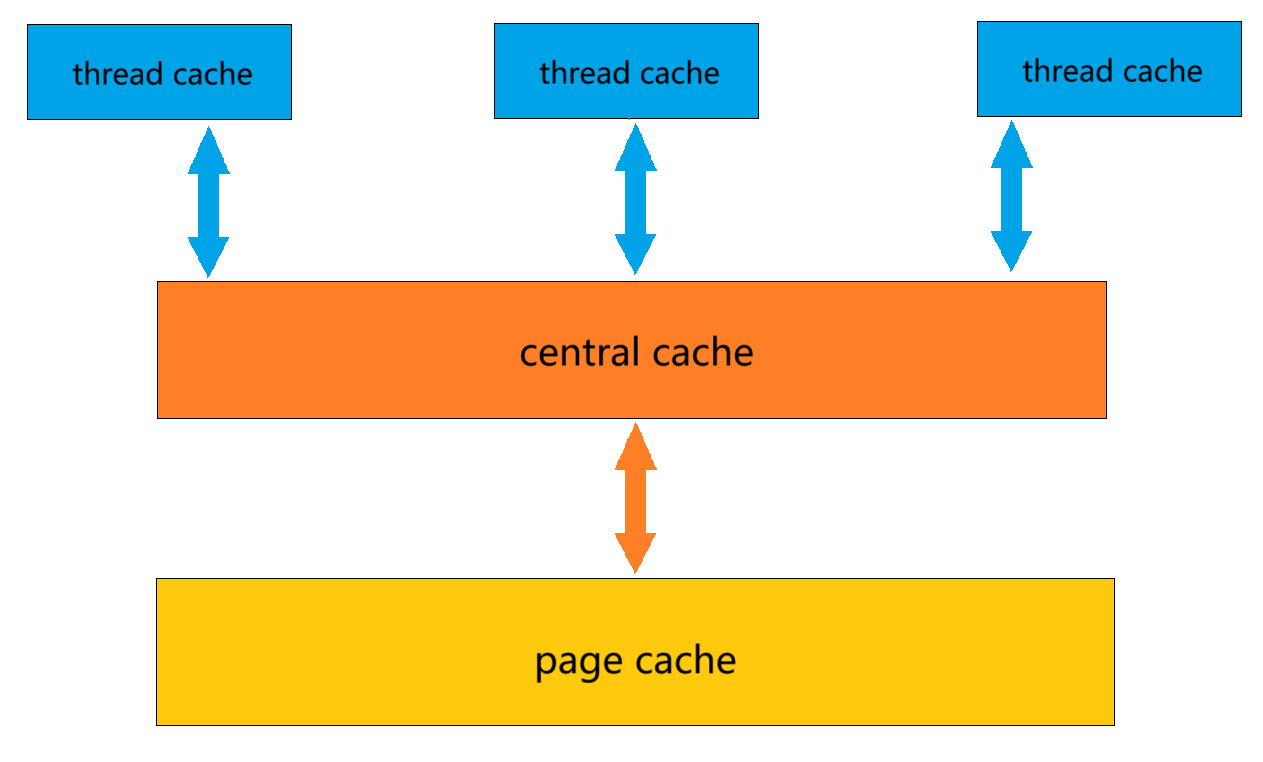
Concurrent Memory Pool主要由以下三個部分組成:
- thread cache:線程緩存是每個線程獨有的,用于小于256KB的內存的分配,線程從這里申請內存不需要加鎖,每個線程獨享一個cache,這也就是這個并發線程池高效的地方。
- central cache:中心緩存是所有線程所共享的,thread cache是按需從central cache中獲取的對象。central cache在合適的時機回收thread cache中的對象,避免一個線程占用了太多的內存,而其他線程的內存吃緊,達到內存分配在多個線程中更均衡的按需調度的目的。central cache是存在競爭的,所以從這里取對象時需要加鎖的,這里使用的是桶鎖并且只有thread cache沒有內存對象時才會找central cache,所以這里競爭不會很激烈。
- page cache:頁緩存是在central cache緩存上面的一層緩存,存儲的內存是以頁為單位存儲及分配的,central cache沒有內存對象時,從page cache分配一定數量的page,并切割成定長大小的小塊內存,分配給central cache。當一個span的幾個跨度頁的對象都回收以后,page cache會回收central cache滿足條件的span對象,并且合并相鄰的頁,組成更大的頁,緩解內存碎片的問題。
以上部分下面會詳細分層講解。?
thread cache? ? ? ??
????????thread cache是哈希桶結構,每個桶是一個按桶位置映射大小的內存塊對象的自由鏈表。每個線程都會有一個thread cache對象,這樣每個線程在這里獲取對象和釋放對象時是無鎖的。
????????在定長內存池中我們已經了解到自由鏈表中掛載的是按照對象大小切分好的小塊內存。所以在向thread cache申請內存空間時,也應該根據申請的內存大小找到映射的哈希桶,在對應的哈希桶中申請內存。
申請內存:
1.當內存申請size <= 256KB時,先獲取到線程本地存儲的thread cache對象,計算size映射的哈希桶自由鏈表下標i.
2.如果自由鏈表_freeLists[i]中有對象,則直接Pop一個內存對象返回。
3.如果_freeLists[i]中沒有對象,則批量從central cache中獲取一定數量的對象,插入到自由鏈表,并且返回一個對象。
????????但是我們不可能為所有的內存大小都設置一個哈希桶(自由鏈表),這樣的話我們就需要256*1024= 262144個自由鏈表,數量太多了。為了減少哈希桶的數量,我們會在空間利用上做出一定的犧牲,這就是所謂的內存對齊。比如:如果全部按照8bytes進行內存對齊,當申請9bytes的內存空間時,我們為其分配16bytes的內存空間,這就導致有7bytes的空間浪費。這就是內碎片——由于對齊的需求導致分配出去的空間中一些內存無法被利用。
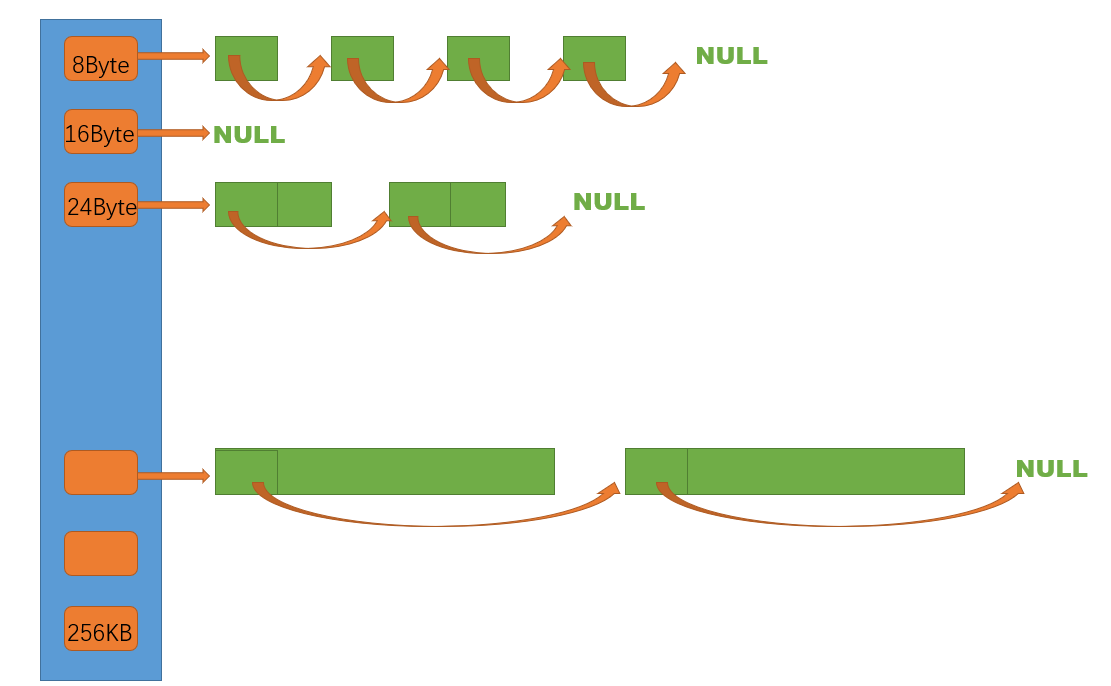
? ? ? ? 按照如圖所示8bytes的大小進行內存對齊,我們仍然需要256KB/8=32768個哈希桶(自由鏈表)。于是我們向進一步減少哈希桶的數量,就需要指定一個合適的內存對齊規則,實現空間利用和哈希桶數量的平衡。這里我們整體控制在10%左右的內碎片浪費:
內存浪費率=(對齊后的內存大小 - 申請的內存大小)/對齊后的內存大小
| 內存大小 | 對齊大小 | 哈希桶 |
| [1,128] | 8bytes | _freeLists[0,16) |
| [128+1,1024] | 16bytes | _freeLists[16,72) |
| [1024+1,8*1024] | 128bytes | _freeLists[72,128) |
| [8*1024+1,64*1024] | 1024bytes | _freeLists[128,184) |
| [64*1024+1,256*1024] | 8*1024bytes | _freeLists[184,208) |
[129,1024]區間內存浪費率最大的為129bytes:15/144 ≈ 10.42%
[1025,8*1024]區間內存浪費率最大的為1025bytes:127/(1024+128) ≈ 11.02%
[8*1024+1,64*1024]區間內存浪費率最大的為8*1024+1bytes:1023/(8*1024+1024) ≈ 11.1%
[64*1024+1,256*1024]區間內存浪費率最大的為64*1024+1bytes:(8*1024-1)/(64*1024+8*1024) ≈ 11.11%
內存對齊方面的代碼我們寫在Common.h的SizeClass類中:
1.RoundUp,計算對齊后的內存大小
由于不同大小區間是按照不同的對齊數對齊的,我們在RoundUp中根據申請的內存大小將其所在區間的對齊數傳給子函數_RoundUp,在_RoundUp中計算對齊后的內存大小。
(我們提到過Thread Cache僅僅支持小于等于256KB大小的內存申請,目前還不支持大于256KB的大小申請,所以這里先不考慮這種情況,直接assert(false))
class SizeClass
{
public:static inline size_t RoundUp(size_t size){if(size <= 128)return _RoundUp(size, 8);else if(size <= 1024)return _RoundUp(size, 16);else if(size <= 8 * 1024)return _RoundUp(size, 128);else if(size <= 64 * 1024)return _RoundUp(size, 1024);else if(size <= 256 * 1024)return _RoundUp(size, 8 * 1024);else{assert(false);return -1;}}
}我們初步設置的_RoundUp計算對齊后的內存如下:
size_t _RoundUp(size_t bytes, size_t alignNum)
{size_t alignSize = 0;if(bytes % alignNum == 0){alignSize = bytes;}else{alignSize = (bytes/alignNum + 1) * alignNum;}return alignSize;
}?但是這個函數一定會被頻繁調用,采用位運算效率能夠更高一些:
先讓申請的內存大小bytes加上(對齊數的大小alignNum - 1),這樣每個區間的最小內存加上該數后剛好等于該區間的最小對齊內存,如:
1 + (8? - 1) = 8,8是[1,128]中內存對齊后的最小數;
129 + (16 - 1) =144,144是[129, 1024]中內存對齊后的最小數
而每個區間的最大數加上對齊數減一后的大小又不超過下一個區間的最小對齊數,如:
128 + (8 - 1) = 135 < 144
1024 + (16 - 1) = 1039 < 1152
然后我們再將計算結果與上(對齊數減一的相反數)就能得到對齊后的內存大小了
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{return ((bytes + alignNum - 1) & ~(alignNum - 1));
}Thread Cache在申請內存時是根據申請的內存大小到對應映射的哈希桶中去申請的,所以我們還需要寫一個函數來完成申請的內存大小到第幾個哈希桶之間的映射:
MAX_BYTES定義如下,作為全局變量:
static const size_t MAX_BYTES = 256 * 1024;class SizeClass
{
public:static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1; // 下標從0開始}static inline size_t Index(size_t bytes){assert(bytes < MAX_BYTES);// 每個區間有多少個桶static int group_array[4] = { 16,56,56,56 };if (bytes <= 128){return _Index(bytes, 3);}else if (bytes <= 1024){return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024){return _Index(bytes - 1024, 7) + group_array[0] + group_array[1];}else if (bytes <= 64 * 1024){return _Index(bytes - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];}else if (bytes <= 256 * 1024){return _Index(bytes - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];}else{assert(false);return -1;}}
};?還有一項準備工作,我們需要將自由鏈表結構定義出來,自由鏈表中存放的是切分好的小對象,ThreadCache申請內存時可能會去自由鏈表中取出一個對象,釋放內存時會將釋放的對象掛到對應的自由鏈表中,因此我們需要Pop()和Push()函數。
之前已經講解了自由鏈表實際上是使用每個對象的前4/8個字節內容去存儲下一個對象地址的,所以這里我們在Common.h中定義一個計算下個對象地址的函數:
static void*& NextObj(void* obj)
{return *((void**)obj);
};class FreeList
{
public:void Push(void* obj){assert(obj);NextObj(obj) = _freeList;_freeList = obj;}void* Pop(){assert(_freeList);void* obj = _freeList;_freeList = NextObj(obj);return obj;}bool Empty(){return _freeList == nullptr;}
private:void* _freeList;
};ThreadCache.h:
NFREELIST即是哈希桶的總數量,也就是自由鏈表的數量,共208個(根據內存對齊規則計算):
128/8 + (1024-128)/16 + (8*1024-1024)/128 + (64*1024-8*1024)/1024 + (256*1024-64*1024)/(8*1024) = 208
static const size_t NFREELIST = 208;#include "Common.h"class ThreadCache
{
public:void* Allocate(size_t size); //申請內存對象void Deallocate(void* ptr, size_t size);//ThreadCache中內存不夠向上一層CentralCache申請void* FetchFromCentralCache(size_i index, size_t size);//當一個自由鏈表桶的長度過長,回收內存給CentralCache//實現內存的均衡調度void ListTooLong(Free& list, size_t size);
private:FreeList _freeLists[NFREELIST];
};//通過TLS每個線程無鎖地獲取自己專屬的ThreadCache對象
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;申請內存
ThreadCache.cpp:
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);if(!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}釋放內存
1.當釋放內存小于256KB時將內存釋放回thread cache,計算size映射自由鏈表桶位置i,將對象Push到_freeLists[i]。
2.當鏈表的長度過長,則回收一部分內存對象到central cache(內存的均衡調度)。
此處我們想要實現判斷一個自由鏈表桶的長度是否需要過長,需要回收內存給central cache,就需要給FreeList新增一個成員變量size來儲存自由鏈表中的對象個數。
那到底怎樣才算是鏈表長度過長,需要回收內存給central cache呢?
我們還需要在FreeList中定義一個成員變量_maxSize,代表鏈表的最大長度,即當鏈表長度大于等于_maxSize時就需要回收內存了。但是有關_maxSize值的相關操作我們放在central cache中進行講解,此處先不做解釋?
class FreeList
{
public:// ...void Push(void* obj){// ...++_size; // 自由鏈表長度加一};void* Pop(){// ...--_size; // 自由鏈表長度減一return obj; }size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}
private:void* _freeList;size_t size = 0; //自由鏈表的長度size_t _maxSize = 1;
};void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);if(_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);}
}ListTooLong()函數進行的操作就是將自由鏈表_freeLists[index]中的內存對象回收給central cache。所以我們還需要寫一個函數PopRange去處理對應的自由鏈表,將其中的所有對象pop出來回收給central cache:
ThreadCache.cpp:
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());// 將內存回收給central cache// CentralCache::GetInstance()->ReleaseListToSpan(start, size); // 后面詳解
}Common.h:
class FreeList
{// ...void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);start = _freeList;end = start;// end指向最后一個對象的起始地址for(size_t i = 0; i < n - 1; i++){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr; // 因為我們需要將pop出來的這一段自由鏈表還給central cache// 所以此處要將NextObj(end)置空_size -= n;}
};central cache
????????central cache也是一個哈希桶結構,它的哈希桶的映射關系跟thread cache是一樣的。不同的是它的每個哈希桶位置掛的時SpanList鏈表結構,不過每個映射桶下面的span中的大內存塊被按映射關系切成了一個個小內存塊對象掛在span的自由鏈表中。
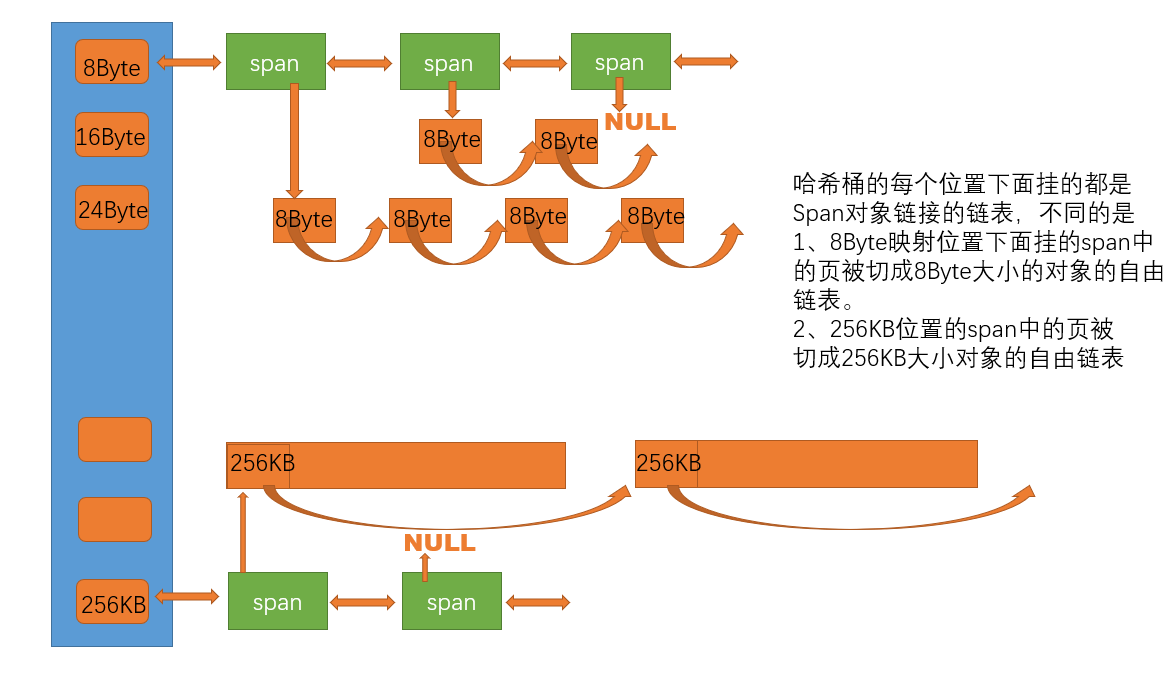
由于Span在合適的時機也會回收給page cache,所以涉及到將某一個span從一個哈希桶中取出來的操作,如下圖:
將指向的span從central cache中取出回收給page cache
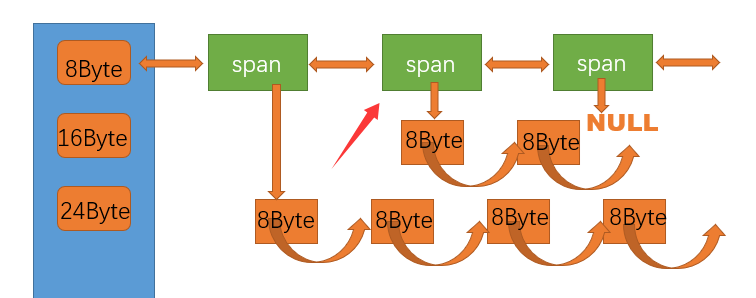
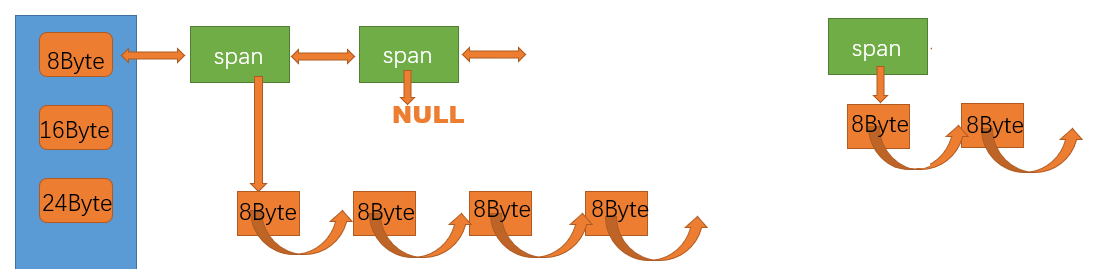
很明顯這里spanlist采用雙向帶頭結構操作更加方便。?
Common.h:?
Span管理一個跨度的大塊內存,以頁為單位,PAGE_ID代表頁號,在32位和64位平臺下不同,采用條件編譯:
#ifdef _WIN64typedef unsigned long long PAGE_ID;
#elif _WIN32typedef size_t PAGE_ID;
#else//linux
#endifstruct Span
{void* _freeList = nullptr; // 掛載的自由鏈表size_t _objSize = 0; // 切分的小塊內存對象大小PAGE_ID _pageId = 0; // 起始頁號size_t _n = 0; // 頁數size_t _useCount = 0; // 分配出去的對象的數量Span* _prev = nullptr;Span* _next = nullptr;
};class SpanList
{
public:SpanList(){_head = new Span;_head->_prev = nullptr;_head->_next = nullptr;}void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = pos;newSpan->_next = pos;pos->_prev = newSpan;}void Erase(Span* pos){assert(pos);assert(pos != _head);Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = pos;// 不刪除pos// pos是回收給page cache的}bool Empty(){return _head->_next == _head;}Span* Begin(){return _head->_next;}Span* End(){return _head;}void PushFront(Span* span){Insert(Begin(), span);}Span* PopFront(){Span* front = _head->_next;Erase(front);return front;}
private:Span* _head;
public:std::mutex _mtx; // 桶鎖
};CentralCache.h:
central cache和thread cache不同,thread cache可能有多個,但central cache一定只存在一個,所以我們采用單例模式來設計。
并且由于central cache的哈希桶映射規則與thread cache相同,所以同樣擁有208個哈希桶即SpanList。
#include "Common.h"class CentralCache
{
public:static CentralCache* GetInstance(){return &_sInst;}// 獲取一個非空的SpanSpan* GetOneSpan(SpanList& list, size_t size);// thread cache自由鏈表過長回收內存給central cachevoid ReleaseListToSpan(void* start, size_t size);// 分配內存給thread cachevoid* FetchRangeObj(void*& start, void*& end, size_t size);private:CentralCache(){};CentralCache(const CentralCache&) = delete;static CentralCache _sInst; // 唯一實例SpanList _spanLists[NFREELIST];
};thread cache向central cache申請內存:
申請內存
1.當thread cache中沒有內存時,就會批量向central cache申請一些內存對象,這里的批量獲取對象的數量使用了類似網絡tcp協議擁塞控制的慢開始算法;central cache也有一個哈希映射的spanlist,spanlist中掛著span,從span中取出對象給thread cache,這個過程是需要加鎖的(不同線程之間會產生競爭),不過這里使用的是一個桶鎖(申請不同區間內存大小會去不同的哈希桶中取內存,不同的哈希桶互不影響),盡可能提高效率。
2.central cache映射的spanlist中所有span都沒有內存以后,則需要向page cache申請一個新的span對象,拿到span以后將span管理的內存按大小切好作為自由鏈表鏈接到一起。然后從span中取對象給thread cache。
3.central cache中掛的span中use_count記錄分配了多少個對象出去,分配一個對象給thread cache,就++use_count
當thread cache沒有內存而向central cache申請內存時,central cache不可能一次只分配一個對象給thread cache,而應該多分配一些給thread cache,批量地獲取對象,提高效率。我們在Common.h中定義一個函數來初步計算分配給thread cache的對象個數:
class SizeClass
{
public:static size_t NumMoveSize(size_t size){assert(size > 0);sizt_t num = size / MAX_BYTES;if(num < 2)num = 2;if(num >= 512)num = 512;return num;}
};但是我們并不是就按這個計算分配對象的個數,而是采用慢開始反饋調節算法。在FreeList中定義成員變量_maxSize,初始值設為1.MaxSize()函數返回該值。
分配對象的個數batchNum從_maxSize開始,逐漸增長,直到NumMoveSize(size)。
thread cache向central cache申請內存時,二者哈希桶和內存大小的映射規則相同,是到映射的哈希桶即SpanList中找到一個非空的Span,由這個非空的Span為其分配內存,所以我們需要一個獲取Span的函數GetOneSpan。但是獲取到的Span中的內存不一定夠batchNum個。所以實際分配的對象個數還要考慮這一點。
我們定義函數FetchRangeObj從central cache中獲取內存:其中需要兩個輸出型接口start和end來標記獲取的內存的起始和結束地址,同時返回實際能夠獲取到的內存對象個數
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while(it != list.End()){if(it->_freeList != nullptr){return it;}else{it = it->_next;}}// 走到這里說明central cache沒有內存,要向page cache申請// ...}size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t size)
{size_t index = SizeClass::Index(size);_spanList[index]._mtx.lock(); //上桶鎖Span* span = CentralCache::GetInstance()->GetOneSpan(_spanLists[index], size);assert(span);assert(span->_freeList);start = span->_freeList;end = start;size_t batchNum = SizeClass::NumMoveSize(size);size_t actualNum = 1;size_t i = 0;while(i < batchNum - 1 && NextObj(end) != nullptr){end = NextObj(end);++actualNum;++i;}span->_freeList = NextObj(end);NextObj(end) = nullptr;span->_useCount += actualNum;_spanLists[index]._mtx.unlock();return actualNum;
}現在我們就可以完善thread cache向central cache申請內存的函數了:?
//Common.h
class FreeList
{
public:// ...// 將一段內存頭插到自由鏈表中void PushRange(void* start, void* end, size_t n){NextObj(end) = _freeList;_freeList = start;_size += n;}
}//ThreadCache.cpp
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// 采用慢開始反饋調節算法size_t batchNum = min(SizeClass::NumMoveSize(size), _freeLists[index].MaxSize());if(batchNum == _freeLists[index].MaxSize()){_freeLists[index].MaxSize() += 1;}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, size);assert(actualNum > 0);if(actualNum == 1){assert(start == end);return start;}else{// 申請到的內存取出一個對象使用// 剩下的內存放進thread cache對應的自由鏈表中,方便下次取用_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);return start;}
}釋放內存
當thread cache過長或者線程銷毀,則會將內存釋放回central cache中,釋放回來時span要--_useCount。當_useCount減到0時則表示所有對象都回到了span,則將span釋放回page cache,page cache中會對前后相鄰的頁進行合并。
在釋放內存時,我們先根據對象大小找到對應的哈希桶_spanLists[index],該哈希桶下掛的是span的鏈表。申請時我們是從該哈希桶下的某個span申請的,所以還回內存是也應該還給這個span。我們定義一個MapObjectToSpan函數來找到對應的span。這個函數在page cache部分再做詳解。?
// ThreadCache.cpp
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());// 將內存回收給central cacheCentralCache::GetInstance()->ReleaseListToSpan(start, size);
}// CentralCache.cpp
void CentralCache::ReleaseListToSpan(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();while(start){void* next = NextObj(start);// 找到對應的span// ...NextObj(start) = span->_freeList;span->_freeList = start;--span->_useCount;if(span->_useCount == 0){// 說明span分配出去的所有對象都還回來了// 此時把span回收給page cache// ...}start = next;}_spanLists[index]._mtx.unlock();
}?page cache
page cache也是哈希桶結構,但不同的是它采用了直接定址法。存儲的內存是以頁為單位存儲及分配的。central cache沒有內存對象向page cache申請時,page cache分配一定數量的page并切割成定長大小的小塊內存分配給central cache。
當分配出去的span的所有對象都回收后(_useCount減到0),page cache會回收該span。并將其與相鄰頁進行合并組成更大的頁,緩解內存碎片問題。
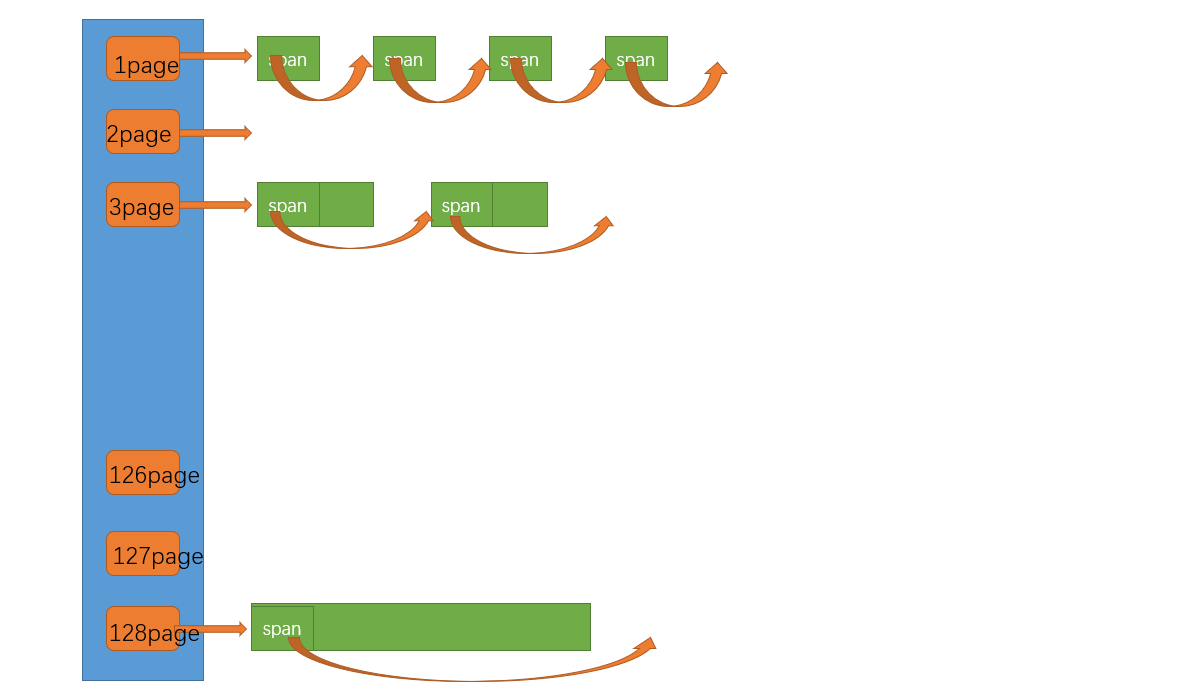
// Common.h
static const size_t NPAGES = 129; // page cache一共有1-128頁的哈希桶
static const size_t PAGE_SHIFT = 13; //一頁8KB
page cache跟central cache相同,只存在一個,同樣設計成單例模式。
#include "Common.h"class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}Span* NewSpan(size_t k);Span* MapObjectToSpan(void* obj);void ReleaseSpanToPageCache(Span* span);std::mutex _pageMtx;
private:SpanList _spanLists[NPAGES];PageCache(){};PageCache(const PageCache&) = delete;static PageCache _sInst;
}申請內存
1.當central cache向page cache申請內存時,page cache先檢查對應位置有沒有span,如果沒有則向更大頁尋找一個span,如果找到則分裂成兩個。比如:申請的是4頁page,4頁page后面沒有掛span,則向后面尋找更大的span,假設在10頁page位置找到一個span,則將10頁page span分裂成一個4頁page span和一個6頁page span。
2.如果找到_spanLists[NPAGES - 1]都沒有合適的span,則向系統使用mmap、brk、或者是VirtuallAlloc申請128頁page span掛載自由鏈表中,再重復1的過程。
3.需要注意的是central cache和page cache的核心結構都是spanlist的哈希桶,但是它們有本質區別,central cache中哈希桶,是按照thread cache一樣的大小對齊關系映射的,它的spanlist中掛的span中的內存都被按映射關系切好鏈接成小塊內存的自由鏈表。而page cache中的spanlist則是按下標桶號映射的,也就是說第i號桶掛的span都是i頁內存。
我們知道central cache在沒有內存時會向page cache申請,page cache 又是以頁為存儲單位的,分配給central cache幾頁呢,我們在Common.h中定義函數NumMovePage。
根據申請的內存對象大小,我們有NumMoveSize計算分配幾個對象。所以在page cache中我們就根據NumMoveSize計算出來的值來計算需要分配多少頁的內存。
class SizeClass
{size_t NumMovePage(size_t size){size_t num = NumMoveSize(size);size_t nPage = num * size;nPage >>= PAGE_SHIFT; // 一共需要多少頁if(nPage == 0)nPage == 1;return nPage;}
}central cache內存不夠向page cache申請span:
page cache是直接定址法,直接根據申請的頁數去對應的哈希桶中獲取span;
如果該哈希桶沒有span,則向后遍歷有沒有更大頁的內存,如果有將其切分。?
之前我們提到在釋放內存時,thread cache將內存回收給central cache應該還給當初申請內存時分配給它內存的span。而我們僅僅能根據要回收內存的起始地址算出該內存的頁號,如果要找到對應的span,就需要我們在分配span時建立每個頁號和span*的映射關系。因此,我們在page cache新建一個成員變量,用unordered_map結構存儲PAGE_ID和Span*的映射關系。(要注意包頭文件哦)
// PageCache.h
class PageCache
{
// ...
private:std::unordered_map<PAGE_ID, Span*> _idSpanMap;
// ...
}// PageCache.cpp
Span* PageCache::NewSpan(size_t k)
{assert(k < NPAGES);if(!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();return kSpan;}for(size_t i = k + 1; i < NPAGES; ++i){if(!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;// 分配出去的內存回收時需要根據地址算出對應的頁號// 再根據所在頁號找到對應的span// 因此分配出去的每一頁都需要建立和Span*的映射關系for(PAGE_ID i = 0; i < kSpan->_n; ++i){_idSpanMap[kSpan->_pageId + i] = kSpan;}nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);// 切分剩下的nSpan沒有分配內存出去,所以不需要每個頁號都建立和span的映射關系// 因為有合并相鄰頁的需求,我們只需要建立起始和結束頁號和Span*的映射關系即可_idSpanMap[nSpan->_pageId] = nSpan;_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;return kSpan;}}// 走到這里說明page cache中也沒有內存了,此時只能向堆申請128頁的大內存Span* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);// 遞歸回去走剛才的邏輯return NewSpan(k);
}函數MapObjectToSpan計算地址的頁號并通過頁號和Span的映射關系返回頁號對應的Span,這里需要注意加鎖,因為unorder_map的底層結構是紅黑樹,當其他地方對_idSpanMap進行寫操作時紅黑樹的結構會發生改變,此時不應該進行讀操作:
// PageCache.cpp
Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);std::unique_lock<std::mutex> lock(_pageMtx);auto ret = _idSpanMap.find(id);if(ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}
}釋放內存
如果central cache釋放回一個span,則依次尋找span的前后page id的沒有在使用的空閑span,看是否可以合并,如果可以合并就繼續向前尋找,直到不能合并為止。這樣就可以將切小的內存合并收縮成大的span,減少內存碎片。
?那么我們就需要給span新增一個成員變量,來表示該span是否正在被使用(是否空閑),默認情況下span都是空閑的,只有當span分配內存出去時我們才修改_isUse為true。
struct Span
{// ...bool _isUse = false; // Span是否被使用
};現在我們先完善一下GetOneSpan的邏輯:
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while(it != list.End()){if(it->_freeList != nullptr){return it;}else{it = it->_next;}}// 走到這里說明central cache沒有內存,要向page cache申請list._mtx.unlock(); // 可以先釋放桶鎖,方便釋放內存PageCache::GetInstance()->_pageMtx.lock();Span* newSpan = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));newSpan->_isUse = true;newSpan->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();// 申請到span后要將其按對象大小切分小塊內存char* start = (char*)(newSpan->_pageId << PAGE_SHIFT);size_t bytes = newSapn->_n << PAGE_SHIFT;char* end = start + bytes;newSapn->_freeList = start;start += size;void* tail = newSpan->_freeList;while(start < end){NextObj(tail) = start;tail = NextObj(tail);start += size;}NextObj(tail) = nullptr;list._mtx.lock();list.PushFront(newSpan);return newSpan;
}釋放內存
void PageCache::ReleaseSpanToPageCache(Span* span)
{// 向前合并while(1){PAGE_ID prevId = span->_pageId - 1;Span* prevSpan = _idSpanMap[prevId]; // ?// 前面的頁不存在,不合并if(prevSpan == nullptr){break;}// 前面的頁正在被使用,不合并if(prevSpan->_isUse == True){break;}// 前面的頁和現在的合并后超過128頁,不合并if(prevSpan->_n + span->_n > NPAGES - 1){break;}// 合并span->_pageId = prevSpan->_pageId;span->_n = prevSpan->_n + span->_n;_spanLists[prevSpan->_n].Erase(prevSpan);delete prevSpan;}// 向后合并是同樣的邏輯while(1){PAGE_ID nextId = span->_pageId + span->_n;Span* nextSpan = _idSpanMap[nextId];if(nextSpan == nullptr){break;}if(nextSpan->_isUse == true){break;}if(nextSpan->_n + span->_n > NPAGES - 1){break;}span->_n += nextSpan->_n;_spanLists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}_spanLists[span->_n].PushFront(span);_span->_isUse = false;_idSpanMap[span->_pageId] = span;_idSpanMap[span->_pageId + span->_n - 1] = span;
}完善central cache的ReleaseListToSpan:
void CentralCache::ReleaseListToSpan(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();while(start){void* next = NextObj(start);// 找到對應的span// ...NextObj(start) = span->_freeList;span->_freeList = start;--span->_useCount;if(span->_useCount == 0){// 說明span分配出去的所有對象都還回來了// 此時把span回收給page cache_spanLists[index].Erase(span);span->_freeLists = nullptr;span->_prev = nullptr;span->_next = nullptr;// 將span回收給page cache的過程中可以先把桶鎖解除// 以免其他線程向central cache釋放內存阻塞_spanLists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}start = next;}_spanLists[index]._mtx.unlock();
}大塊內存申請實現
線程申請內存的代碼:
ConcurrentAlloc.h:
static void* ConcurrentAlloc(size_t size)
{if(pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}return pTLSThreadCache->Allocate(size);
}釋放內存:
static void ConcurrentFree(void* ptr)
{// 首先需要知道釋放對象的內存大小// 在span結構中有一個成員變量_objSize,代表該span被切分成的小對象的大小// 所以我們只需要知道現在釋放的對象屬于哪個span,即可知道它的大小Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t size = span->_objSize;assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}但是正如最開始所說的,thread cache只能申請<=256KB的內存。所以以上代碼也只實現了<=256KB內存的申請。現在我們需要完善大塊內存的申請/釋放邏輯。
申請內存的第一步是進行內存對齊,我們最開始在RoundUp函數中直接忽略了>=256KB的內存,可以返回去看看,當時我們直接對大塊內存的申請情況中assert(false)了。所以現在需要修改,thread cache只能申請<=256KB的內存,?但是page cache中最高卻有128頁的內存可以申請。所以對于大塊內存,我們直接向page cache進行申請,所以在內存對齊這一步我們需要按頁對齊:
class SizeClass
{
public:static inline size_t RoundUp(size_t size){if(size <= 128)return _RoundUp(size, 8);else if(size <= 1024)return _RoundUp(size, 16);else if(size <= 8 * 1024)return _RoundUp(size, 128);else if(size <= 64 * 1024)return _RoundUp(size, 1024);else if(size <= 256 * 1024)return _RoundUp(size, 8 * 1024);else{// assert(false);// return -1;return _RoundUp(size, 1 << PAGE_SHIFT);}}
}ConcurrentAlloc和ConcurrentFree也做出相應的修改:
static void* ConcurrentAllloc(size_t size)
{if(size > MAX_BYTES){size_t alignSize = SizeCalss::RoundUp(size);size_t kPage = alignSize >> PAGE_SHIFT;PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kPage);span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_pageId << PAGE_SHIFT);return ptr;}else{if(pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}return pTLSThreadCache->Allocate(size);}
}static void ConcurrentFree(void* ptr)
{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t size = span->_objSize;if(size > MAX_BYTES){PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}?但是page cache中也只有<=128頁的內存,如果我們申請大于128頁的內存就沒辦法問page cache要了,只能找堆:
Sapn* PageCache::NewSpan(size_t k)
{assert(k > 0);if(k > NPAGES - 1){void* ptr = SystemAlloc(k);Span* span = new Span;span->_pageId = ptr >> PAGE_SHIFT;span->_n = k;_idSpanMap[span->_pageId] = span;return span;}// ...
}釋放時內存如果大于128頁我們應該還給堆,而不是給page cache,我們直接向堆申請內存時調用的是VirtualAlloc,與之對應的釋放內存的是VirtualFree:
// Common.h
void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#else// ...
#endif
}void PageCache::ReleaseSpanToPageCache(Span* span)
{if(span->_n > NPAGES - 1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);delete span;return;}// ...
}定長內存池配合脫離使用new
? ? ? ? 既然我們這個項目是為了在高并發情況下實現比malloc更高效地處理內存的申請釋放,那我們在實現中再用到malloc就不合適了。現在我們用定長內存池來進行替換。
項目中涉及到new和delete的操作主要是pagecache中對span進行的操作,我們在page cache中新增一個定長內存池的成員變量:
class PageCache
{
public:// ...
private:ObjectPool<Span> _spanPool;// ...
};然后再將我們代碼中的new和delete全部改為調用定長內存池中的New和Delete函數:
// Span* span = new Span;
Span* span = _spanPool.New();//delete span;
_spanPool.Delete(span); ?同時,ConcurrentAlloc中的new ThreadCache也需要替換:
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES){// ...}else{if (pTLSThreadCache == nullptr){ObjectPool<ThreadCache> tcPool;pTLSThreadCache = tcPool.New();//pTLSThreadCache = new ThreadCache;}return pTLSThreadCache->Allocate(size);}
}這里為了防止線程從定長內存池中申請內存產生競爭,我們以空間換時間,每個線程都有一個定長內存池tcPool。
性能測試
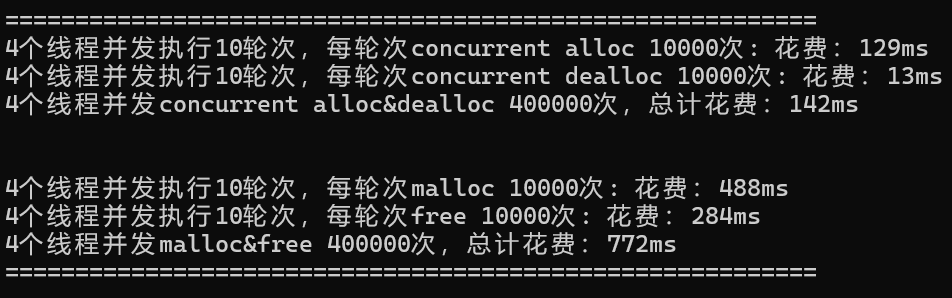
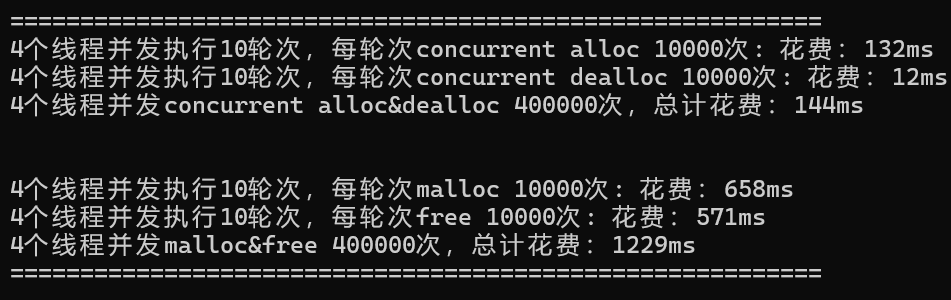
以下是一個簡單的對比malloc和高并發內存池效率的代碼:
nworks -- 線程個數
rounds -- 輪次
ntimes -- 每輪次申請和釋放內存的個數
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(malloc(16));v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u個線程并發執行%u輪次,每輪次malloc %u次: 花費:",nworks, rounds, ntimes);cout << malloc_costtime << "ms" << endl;printf("%u個線程并發執行%u輪次,每輪次free %u次: 花費:",nworks, rounds, ntimes);cout << free_costtime << "ms" << endl;printf("%u個線程并發malloc&free %u次,總計花費:",nworks, nworks * rounds * ntimes);cout << malloc_costtime + free_costtime << "ms" << endl;
}// 單輪次申請釋放次數 線程數 輪次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(ConcurrentAlloc(16));v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u個線程并發執行%u輪次,每輪次concurrent alloc %u次: 花費:",nworks, rounds, ntimes);cout << malloc_costtime << "ms" << endl;printf("%u個線程并發執行%u輪次,每輪次concurrent dealloc %u次: 花費:",nworks, rounds, ntimes);cout << free_costtime << "ms" << endl;printf("%u個線程并發concurrent alloc&dealloc %u次,總計花費:",nworks, nworks * rounds * ntimes);cout << malloc_costtime + free_costtime << "ms" << endl;
}int main()
{size_t n = 10000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << "==========================================================" << endl;return 0;
}然而運行后我們發現很多時候我們的程序性能上還是比不過malloc。這個時候我們可以利用性能分析工具來查看性能瓶頸。
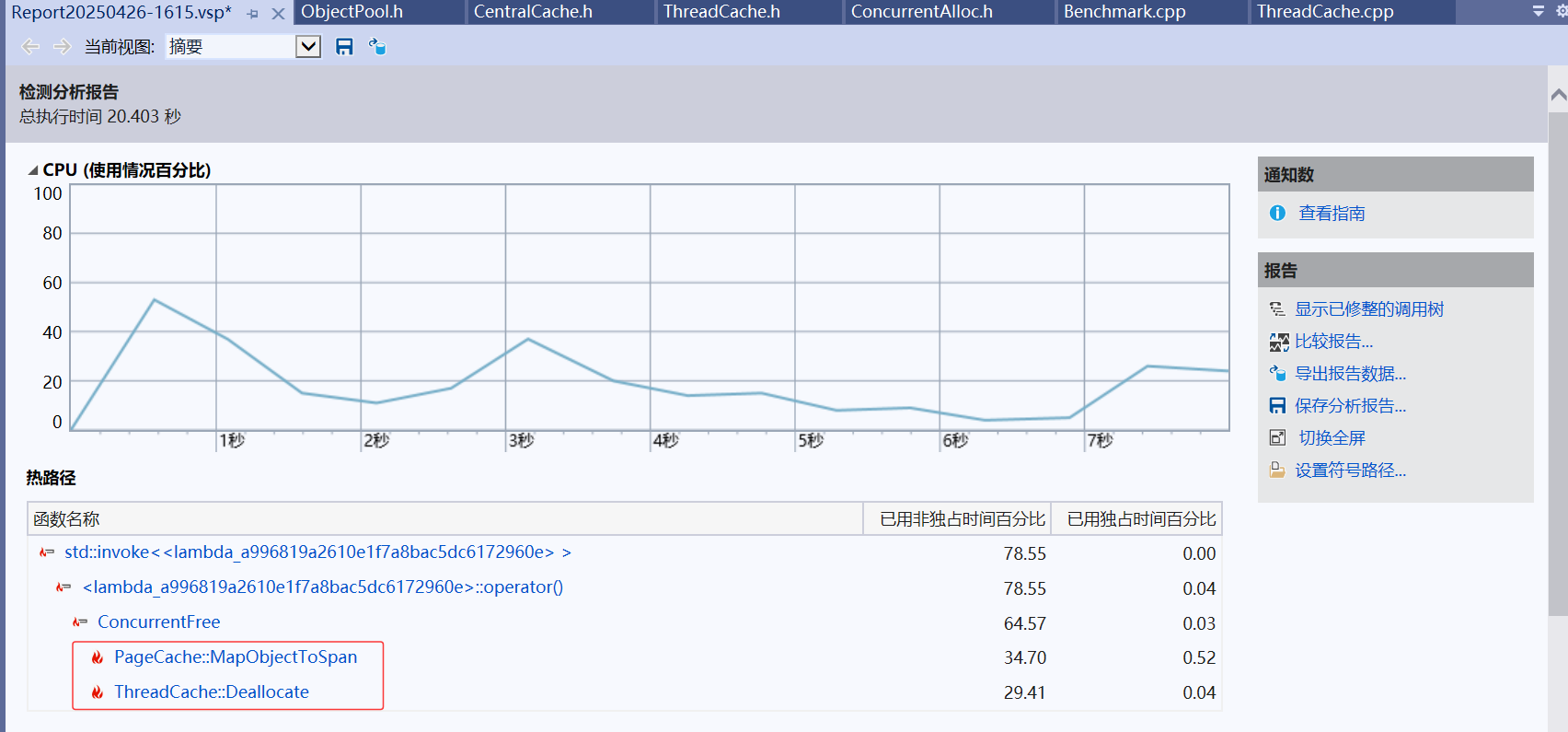 ?可以看到page cache中的MapObjectToSpan函數和thread cache中的Deallocate函數對性能影響比較大,我們可以點進去查看具體情況:
?可以看到page cache中的MapObjectToSpan函數和thread cache中的Deallocate函數對性能影響比較大,我們可以點進去查看具體情況:
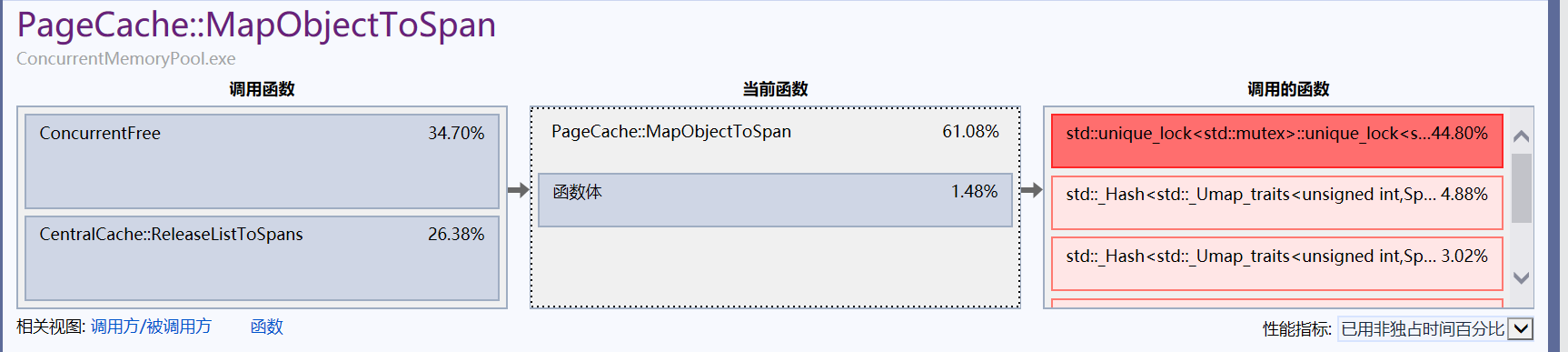
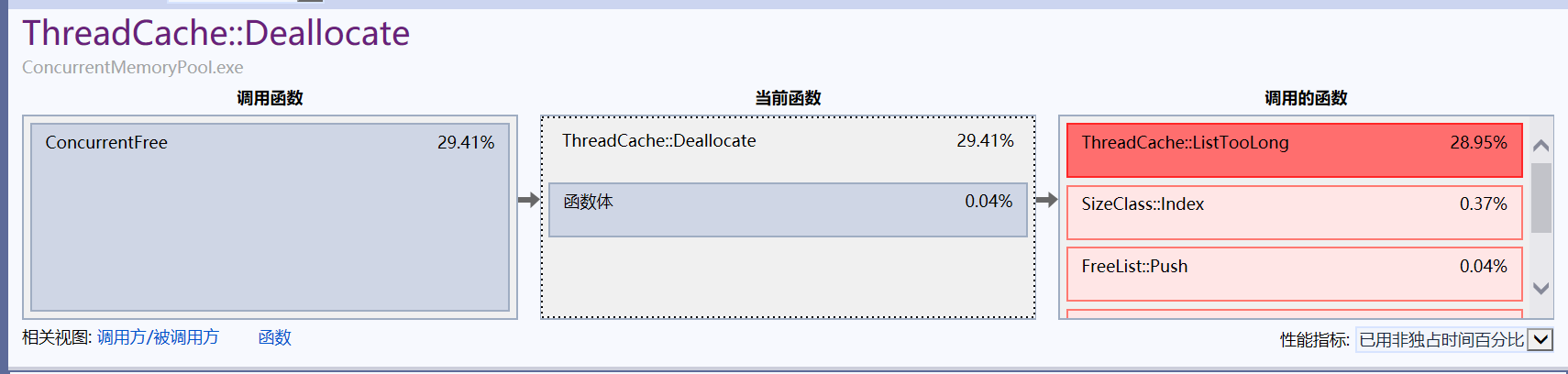
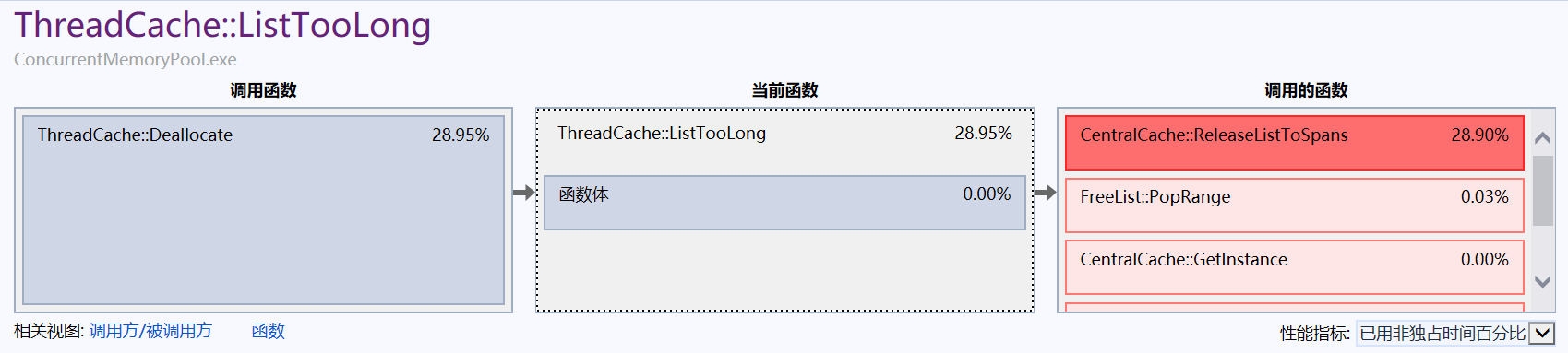
很明顯問題出在了加鎖上。?
tcmalloc源碼實現基數樹優化
? ? ? ? 我們已經知道問題在于MapObjectToSpan加鎖導致效率較低。在上文中我們提到了MapObjectToSpan需要注意加鎖是因為unordered_map底層結構是紅黑樹,當其他地方對_idSpanMap進行寫操作時紅黑樹的結構會發生改變,此時不應該進行讀操作。而tcmalloc中_idSpanMap的結構也并沒有采用紅黑樹:
TCMalloc_PageMap1是采用直接定址法存儲PAGE_ID和Span*映射關系的相當于一維數組的結構。里面對應頁號的下標位置中存儲的都是其映射的void*(Span*)。而該結構非常穩定,一開始開辟好空間后結構不會發生變化,與紅黑樹不同。因此在其他線程寫的時候也不妨礙另一個線程讀,這樣MapObjectToSpan內部就不用加鎖:
? ? ? ? 其中的set函數就是建立頁號與Span*的映射關系;而get函數則是通過頁號找到對應的Span。
????????BITS是存儲頁號需要的位數,比如一頁為8KB的情況下在32位下總共會有2^32/2^13=2^19頁,也就是說這是存儲頁號需要19位。
而TCMalloc_PageMap2也是基本相同的邏輯,只是采用了兩層映射,先通過頁號的前五位映射到第一層基數樹,再通過剩下的幾位映射到第二層基數樹。這樣我們不至于一下就把sizeof(void*)<<BITS對齊后的空間全部開辟出來,而是可以先把第一層空間開好,等到用到對應的第二層后再開辟相應的空間,一定程度上減少了內存的消耗。
然而TCMalloc_PageMap1和TCMalloc_PageMap2都只適用于32位,在32位下BITS=32-13=19,它們最終需要開辟的內存空間都是4*2^19=2MB。內存消耗不算很大。但是在64位下BITS=64-13=51。需要8*2^51=2^24GB,內存消耗太大。這時就用TCMalloc_PageMap3實現,采用三層映射,節省內存的原理與TCMalloc_PageMap2相同。
// Single-level array
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;
public:typedef uintptr_t Number;explicit TCMalloc_PageMap1(void* (allocator)(size_t)) {*array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*)<< BITS));memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.//// Sets the value 'v' for key 'k'.void set(Number k, void* v) {array_[k] = v;}
};
// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodesvoid* (*allocator_)(size_t); // Memory allocator
public:typedef uintptr_t Number;explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {allocator_ = allocator;memset(root_, 0, sizeof(root_));}void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL) {return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);ASSERT(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> LEAF_BITS;// Check for overflowif (i1 >= ROOT_LENGTH)return false;// Make 2nd level node if necessaryif (root_[i1] == NULL) {Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));if (leaf == NULL) return false;memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}// Advance key past whatever is covered by this leafnodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {// Allocate enough to keep track of all possible pagesEnsure(0, 1 << BITS);}
};
// Three-level radix tree
template <int BITS>
class TCMalloc_PageMap3 {
private:// How many bits should we consume at each interior levelstatic const int INTERIOR_BITS = (BITS + 2) / 3; // Round-upstatic const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;// How many bits should we consume at leaf levelstatic const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Interior nodestruct Node {Node* ptrs[INTERIOR_LENGTH];};// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Node* root_; // Root of radix treevoid* (*allocator_)(size_t); // Memory allocatorNode* NewNode() {Node* result = reinterpret_cast<Node*>((*allocator_)(sizeof(Node)));if (result != NULL) {memset(result, 0, sizeof(*result));}return result;}
public:typedef uintptr_t Number;explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {allocator_ = allocator;root_ = NewNode();}void* get(Number k) const {const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 ||root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2]== NULL) {return NULL;}return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2]) -
> values[i3];}void set(Number k, void* v) {ASSERT(k >> BITS == 0);const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3]= v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (key >> LEAF_BITS) &(INTERIOR_LENGTH - 1);// Check for overflowif (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)return false;// Make 2nd level node if necessaryif (root_->ptrs[i1] == NULL) {Node* n = NewNode();if (n == NULL) return false;root_->ptrs[i1] = n;}// Make leaf node if necessaryif (root_->ptrs[i1]->ptrs[i2] == NULL) {Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));if (leaf == NULL) return false;memset(leaf, 0, sizeof(leaf));*root_->ptrs[i1]->ptrs[i2] =reinterpret_cast<Node*>(leaf);}// Advance key past whatever is covered by this leafnodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {}
};我們利用tcmalloc的源碼加以修改運用到項目上:
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;
public:typedef uintptr_t Number;explicit TCMalloc_PageMap1() {size_t size = sizeof(void*) << BITS;size_t alignSize = _RoundUp(size, 1 << PAGE_SHIFT);array = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}void set(Number k, void* v) {array_[k] = v;}
};// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodes
public:typedef uintptr_t Number;explicit TCMalloc_PageMap2() {memset(root_, 0, sizeof(root_));PreallocateMoreMemory();}void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL) {return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);assert(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> LEAF_BITS;// Check for overflowif (i1 >= ROOT_LENGTH)return false;// Make 2nd level node if necessaryif (root_[i1] == NULL) {static ObjectPool<Leaf> leafPool;Leaf* leaf = (Leaf*)leafPool.New();if (leaf == NULL) return false;memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}// Advance key past whatever is covered by this leafnodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {// Allocate enough to keep track of all possible pagesEnsure(0, 1 << BITS);}
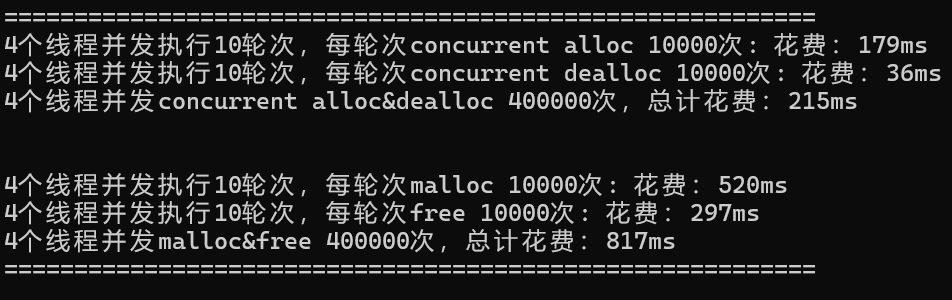
};運行程序,效率提升很大:?
?項目源碼:ConcurrentMemoryPool · 亮亮兒/Project - 碼云 - 開源中國 (gitee.com)











Element Plus項目綜合案例)





)

