摘要:由于語言的形態豐富,阿拉伯語文本的變音符號仍然是自然語言處理中一個持續的挑戰。 在本文中,我們介紹了一種基于微調解碼器語言模型的新方法Sadeed,該方法改編自Kuwain 1.5B Hennara等人[2025]的模型,該模型最初是在不同的阿拉伯語語料庫上訓練的緊湊模型。 Sadeed 經過精心策劃的高質量變音數據集的微調,這些數據集是通過嚴格的數據清理和規范化管道構建的。 盡管使用了適度的計算資源,但與專有的大型語言模型相比,Sadeed取得了具有競爭力的結果,并且優于在類似領域訓練的傳統模型。 此外,我們強調了當前阿拉伯語變音基準測試實踐中的主要局限性。 為了解決這些問題,我們引入了SadeedDiac-25,這是一個新的基準,旨在在不同的文本類型和復雜程度之間進行更公平、更全面的評估。 Sadeed和SadeedDiac-25共同為推進阿拉伯語NLP應用提供了堅實的基礎,包括機器翻譯、文本到語音和語言學習工具。Huggingface鏈接:Paper page,論文鏈接:2504.21635
研究背景和目的
研究背景
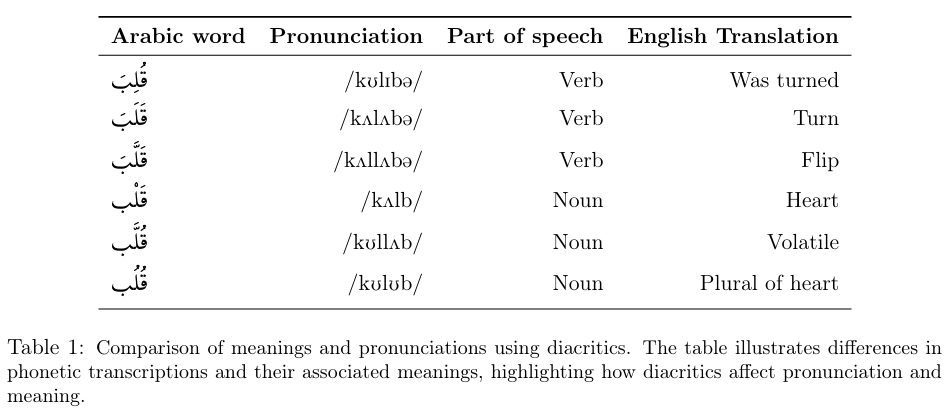
阿拉伯語作為一種形態豐富的語言,其文本變音符號(Diacritization)在自然語言處理(NLP)領域一直是一個持續的挑戰。變音符號在阿拉伯語中起著至關重要的作用,它們不僅用于區分具有相同輔音結構但意義和發音不同的單詞,還是文本消歧、提高機器翻譯、文本到語音(TTS)合成、詞性標注等NLP任務準確性的關鍵。然而,由于現代阿拉伯語書寫中經常省略變音符號以節省時間和空間,導致帶變音符號的標注數據稀缺,這增加了阿拉伯語變音符號自動標注的難度。
此外,阿拉伯語文本存在古典阿拉伯語(CA)和現代標準阿拉伯語(MSA)兩種主要書寫風格,大多數現有的變音符號數據集集中在古典阿拉伯語上,而基于這些數據訓練的模型在現代標準阿拉伯語上的表現往往不佳。同時,準確的變音符號標注往往需要理解整個句子的上下文,這也是現有模型中經常被忽視的因素。
研究目的
本研究的主要目的是通過引入一種基于小型語言模型(SLM)的新方法Sadeed,來推進阿拉伯語變音符號的自動標注。Sadeed模型基于Kuwain 1.5B Hennara等人[2025]的預訓練模型,經過微調以適應阿拉伯語變音符號標注任務。此外,本研究還旨在解決當前阿拉伯語變音符號基準測試中的局限性,通過提出一個新的基準SadeedDiac-25,以實現更公平、更全面的評估。
研究方法
數據集構建
為了訓練Sadeed模型,研究者們利用了Tashkeela語料庫和阿拉伯樹庫(ATB-3)等公開數據集。然而,這些數據集存在質量問題,如文本質量差、變音符號不一致等。因此,研究者們實施了一個嚴格的數據預處理管道,包括文本清理、標準化和文本分塊等步驟,以確保數據的一致性和可靠性。
- 文本清理:通過應用與Kuwain模型預訓練相同的嚴格清理函數,并添加額外的標準化步驟來確保變音符號的一致性。
- 文本分塊:將語料庫分割成50-60個單詞的連貫塊,同時盡量保持句法依賴關系。
- 數據集過濾:排除包含兩個以上未標注變音符號單詞的示例,確保訓練樣本的變音符號完整性。
最終得到的數據集包含約104萬個示例,總計約5300萬個單詞,并被公開發布以支持模型訓練和評估。
模型訓練
Sadeed模型是基于Kuwain 1.5B Hennara等人[2025]的預訓練模型進行微調的。微調過程被仔細設計以優化模型在阿拉伯語變音符號標注任務上的性能。具體來說,研究者們將變音符號標注任務重新表述為一個問答(QA)任務,利用模型的生成能力進行更聚焦和高效的訓練。在整個訓練數據集上應用了一致的模板轉換,以適應專門的變音符號標注任務。
訓練過程中使用了標準的下一標記預測方法,并監控驗證損失以防止過擬合。最佳檢查點根據訓練過程中獲得的最低驗證損失進行選擇。
基準測試
為了評估Sadeed模型的性能,研究者們在多個基準測試集上進行了實驗,包括Fadel基準測試集、WikiNews基準測試集以及新提出的SadeedDiac-25基準測試集。SadeedDiac-25基準測試集旨在提供一個更公平、更全面的評估框架,它結合了古典阿拉伯語和現代標準阿拉伯語文本,并經過專家仔細審查以確保準確性和可靠性。
研究結果
在Fadel基準測試集上的表現
在Fadel基準測試集上,Sadeed模型在詞錯誤率(WER)和變音符號錯誤率(DER)方面取得了具有競爭力的結果。特別是在排除未標注變音符號字符的情況下,Sadeed在WER方面達到了最先進的性能。這表明Sadeed模型在處理阿拉伯語變音符號標注任務時具有很高的準確性和魯棒性。
在WikiNews基準測試集上的表現
在WikiNews基準測試集上,Sadeed模型也取得了具有競爭力的性能,盡管沒有超過某些專門針對現代標準阿拉伯語訓練的模型。這表明Sadeed模型在處理現代標準阿拉伯語文本時仍有一定的提升空間。
在SadeedDiac-25基準測試集上的表現
在SadeedDiac-25基準測試集上,Sadeed模型與領先的專有大型語言模型(如Claude3.7Sonnet、GPT-4等)以及開源阿拉伯語模型進行了比較。結果顯示,Claude3.7Sonnet在所有評估指標上均表現最佳,而Sadeed模型在開源模型中表現最強,甚至與某些專有模型相比也具有競爭力。然而,Sadeed模型的主要局限性在于其幻覺率較高,這可能是由于模型規模相對較小所致。
研究局限
模型幻覺
Sadeed模型在生成變音符號標注文本時存在一定的幻覺問題,即生成與輸入文本不完全匹配的輸出。這可能是由于模型規模較小或訓練數據有限所致。為了解決這個問題,研究者們使用了Needleman-Wunsch對齊算法來自動糾正結構差異,同時保留模型生成的變音符號。
現代標準阿拉伯語數據不足
盡管Sadeed模型在古典阿拉伯語變音符號標注任務上表現出色,但在現代標準阿拉伯語上的表現仍有待提高。這主要是由于現代標準阿拉伯語標注數據的稀缺性所致。為了解決這個問題,研究者們計劃擴展數據集,增加經過仔細標注的現代標準阿拉伯語文本。
基準測試局限性
當前阿拉伯語變音符號基準測試中存在一些局限性,如數據集之間的重疊、標注錯誤以及領域多樣性不足等。這些問題可能導致模型性能評估的不準確和誤導性結論。為了解決這些問題,研究者們提出了SadeedDiac-25基準測試集,旨在提供一個更公平、更全面的評估框架。
未來研究方向
擴大模型規模
為了減少模型幻覺并提高性能,未來可以考慮擴大Sadeed模型的規模。通過增加模型參數和訓練數據量,可以期望模型在生成變音符號標注文本時更加準確和可靠。然而,這也將帶來計算資源和效率方面的挑戰。
增加現代標準阿拉伯語數據
為了解決現代標準阿拉伯語數據不足的問題,未來可以致力于收集和標注更多的現代標準阿拉伯語文本。這可以通過與語言學家和領域專家合作來實現,以確保標注數據的準確性和可靠性。
改進基準測試
為了進一步提高阿拉伯語變音符號標注模型的評估準確性,未來可以致力于改進基準測試方法。這包括開發新的基準測試集、采用更嚴格的評估指標以及實施更全面的數據集審查流程。通過這些措施,可以期望為阿拉伯語變音符號標注模型的研究和開發提供更堅實的基礎。
探索新的模型架構和技術
除了擴大模型規模和增加訓練數據外,未來還可以探索新的模型架構和技術來提高阿拉伯語變音符號標注的性能。例如,可以嘗試將注意力機制、自監督學習或遷移學習等技術應用于阿拉伯語變音符號標注任務中,以期望獲得更好的性能表現。

)














)


