25年4月來自具身機器人創業公司 PI 公司的論文“π0.5: a Vision-Language-Action Model with Open-World Generalization”。
為了使機器人發揮作用,它們必須在實驗室之外的現實世界中執行實際相關的任務。雖然視覺-語言-動作 (VLA) 模型在端到端機器人控制方面已展現出印象深刻的效果,但此類模型在實際應用中的泛化能力仍是一個懸而未決的問題。本文提出一個基于 π0 的演進模型 π0.5,它利用異構任務的協同訓練來實現廣泛的泛化。π0.5 使用來自多個機器人、高級語義預測、網絡數據和其他來源的數據,以實現泛化的現實世界機器人操作。該系統結合協同訓練和混合多模態示例,這些示例結合圖像觀察、語言命令、目標檢測、語義子任務預測和低級動作。實驗表明,這種知識遷移對于有效的泛化至關重要,并且一個支持端到端學習的機器人系統可以在全新的家中執行長視野和靈巧的操作技能,例如清潔廚房或臥室。注:PI 公司在網站視頻展示了在 AirBnB 搭建這種模型的機器人如何工作。
π0.5 如圖所示:

開放世界的泛化是物理智能(PI)領域最大的開放性問題之一:機械臂、類人機器人和自動駕駛汽車等具身系統只有能夠走出實驗室,應對現實世界中發生的各種情況和意外事件時,才能真正發揮作用。基于學習的系統為實現廣泛的泛化提供了一條途徑,尤其是最近的進展,使得從自然語言處理 [79, 21, 10, 78] 到計算機視覺 [34, 66, 35, 43] 等領域的可擴展學習系統成為可能。然而,機器人在現實世界中可能遇到的情境千差萬別,這不僅僅需要規模,還需要設計能夠提供廣泛知識的訓練方案,使機器人能夠在多個抽象層次上進行泛化。例如,如果一個移動機器人被要求清理一個它從未見過的廚房,如果數據中存在足夠多的場景和物體(例如,拿起刀或盤子),某些行為很容易泛化;而另一些行為可能需要調整或修改現有技能,才能以新的方式或新的順序使用它們;還有一些行為可能需要基于先驗知識理解場景的語義(例如,打開哪個抽屜,或者柜臺上哪個物體最有可能是晾衣架)。那么問題上:如何為機器人學習系統構建一個訓練方案,使其能夠實現這種靈活的泛化?
一個人可以借鑒一生的經驗,綜合出針對每個挑戰的合適解決方案。并非所有經驗都是第一手的,也并非所有經驗都來自死記硬背——例如,可能會結合他人告知或從書中讀到的信息,以及在不同情境下執行其他任務時獲得的見解,并結合在目標領域的直接經驗。類似地,可以假設,可泛化的機器人學習系統必須能夠遷移來自各種信息源的經驗和知識。其中一些來源是與當前任務直接相關的第一手經驗,一些需要從其他機器人實例、環境或域遷移,還有一些則代表完全不同的數據類型,例如口頭指令、基于網絡數據的感知任務或高級語義命令的預測。這些不同數據源的異構性構成重大障礙,但幸運的是,視覺-語言-動作 (VLA) 模型的最新進展提供一個工具包,可以實現這一點:通過將不同的模態數據引入同一序列建模框架,VLA 可以適用于機器人數據、語言數據、計算機視覺任務以及上述數據的組合進行訓練。
通才機器人操控策略。近期研究表明,將機器人操控策略的訓練數據分布從狹窄的單任務數據集拓展到涵蓋眾多場景和任務的多樣化數據集 [17, 25, 80, 63, 41, 6, 30, 67, 1],不僅可以使生成的策略開箱即用地解決更廣泛的任務,還能提升其泛化到新場景和任務的能力 [9, 63, 62, 22]。訓練此類通才策略需要新的建模方法,以應對通常涵蓋數百個不同任務和場景的數據集的規模和多樣性。視覺-語言-動作模型 (VLA) [23, 92, 42, 8, 83, 90, 55, 45, 3, 75, 64, 76, 84, 7, 37] 提供了一個頗具吸引力的解決方案:通過對用于機器人控制的預訓練視覺-語言模型進行微調,VLA 可以利用從網絡規模預訓練中獲得的語??義知識,并將其應用于機器人問題。當與高表達力的動作解碼機制(例如流匹配 [8]、擴散 [55, 84, 52] 或高級動作token化方案 [64])結合使用時,VLA 可以在現實世界中執行各種復雜的操作任務。然而,盡管 VLA 擁有印象深刻的語言跟隨能力,但其評估環境通常仍與其訓練數據高度匹配。雖然一些研究表明,只需在更廣泛的環境中收集機器人數據,就能將拾取物體或打開抽屜等簡單技能泛化到實際場景中 [14, 67, 28, 49, 64],但將相同方法應用于更復雜、更長期的任務(如清理廚房)卻極具挑戰性,因為通過強力擴展機器人數據收集來廣泛覆蓋所有可能場景是不可行的。
非機器人數據協同訓練。許多先前的研究都試圖利用多樣化的非機器人數據來提升機器人策略的泛化能力。先前的方法包括從計算機視覺數據集初始化視覺編碼器 [85, 58, 57, 18],或利用現成的任務規劃器 [38, 48, 73, 81]。VLA 策略通常由預訓練的視覺-語言模型初始化,該模型已接觸過大量的互聯網視覺和語言數據 [23, 92, 42]。值得注意的是,VLA 架構非常靈活,允許在多模態視覺、語言和動作 token 的輸入和輸出序列之間進行映射。因此,VLA 不僅支持在機器人動作模仿數據上,還支持在任何包含上述一種或多種模態的數據集上協同訓練單一統一的架構,從而拓寬可能的遷移方法設計空間,使其超越簡單的權重初始化。先前的研究已經證明,使用用于 VLM 訓練的混合數據 [23, 92, 86] 協同訓練 VLA 可以提升其泛化能力,例如在與新物體或未見過的場景背景交互時。
機器人運用語言進行推理和規劃。許多先前的研究表明,通過高級推理增強端到端策略可以顯著提升長周期任務的性能 [2, 36, 44, 74, 71, 4, 16, 11, 53, 88, 51, 59, 13, 70, 91, 65, 72, 47, 76, 89],尤其是當高級子任務推理能夠受益于大型預訓練的 LLM 和 VLM 時。
具有開放世界泛化的機器人學習系統。雖然大多數機器人學習系統在與訓練數據高度匹配的環境中進行評估,但之前已有不少研究探索了更廣泛的開放世界泛化能力。當機器人的任務僅限于一組較為狹窄的基本基元(例如拾取物體)時,允許特定任務假設的方法(例如,抓取預測或結合基于模型的規劃和控制)已被證明能夠實現廣泛的泛化,甚至擴展到全新的家庭環境 [40, 20, 60, 56, 29]。然而,此類方法并不容易泛化到多面手機器人可能需要執行的所有任務。最近,來自多個領域的大規模數據集 [41, 68, 63, 67, 14, 49] 已被證明能夠將簡單但端到端學習的任務泛化到新環境 [33, 31, 67, 69, 26, 49, 28, 64]。然而,這些演示中的任務仍然相對簡單,通常時長不到一分鐘,而且成功率通常相對較低。
本文利用這一觀察結果為 VLA 設計一個協同訓練框架,該框架可以利用異構和多樣化的知識源實現廣泛的泛化。在 π0 VLA 的基礎上,納入一系列不同的數據源來創建 π0.5 模型(發音“pi oh five”),該模型可以控制移動機械手執行各種家務,即使在訓練期間從未見過的家庭中也可以執行。如圖所示:π0.5用于清掃一個新廚房

視覺-語言-動作模型 (VLA) 通常通過在不同機器人演示數據集 D 上進行模仿學習來訓練,通過給定觀察 o_t 和自然語言任務指令 l 來最大化動作 a_t(或更一般地,動作塊 a_t:t+H)對數似然。
觀察通常包含一個或多個圖像 I1_t,…,I^n_t 和本體感受狀態 q_t,用于捕捉機器人關節的位置。VLA 架構遵循現代語言和視覺語言模型的設計,具有特定于模態的token化器,將輸入和輸出映射到離散(“硬”)或連續(“軟”)token 表征,以及一個大型自回歸 transformer 主干,經過訓練可從輸入映射到輸出 token。
這些模型的權重由預訓練的視覺語言模型初始化。通過將策略輸入和輸出編碼為 token 化的表征,上述模仿學習問題可以轉化為一個簡單的下一個 token 預測問題,針對一系列觀察、指令和動作 token,可以利用現代機器學習的可擴展工具來優化它。在實踐中,圖像和文本輸入的 token 化器的選擇,遵循現代視覺語言模型的 token 化器。對于動作,先前的研究已經開發出有效的、基于壓縮的 token 化方法 [64],在本文的預訓練階段使用這些方法。
許多近期的 VLA 模型也提出通過擴散 [55, 84, 52] 或流匹配 [8] 來表示動作分布,從而為連續-值動作塊提供更具表現力的表征。在模型的后訓練階段,將以 π0 模型 [8] 的設計為基礎,該模型通過流匹配來表示動作分布。在此設計中,與動作對應的 token 接收來自上一步流匹配的部分去噪動作作為輸入,并輸出流匹配向量場。這些 token還使用一組不同的模型權重,稱為“動作專家”,類似于混合專家架構。該動作專家可以專注于基于流匹配的動作生成,并且比 LLM 主干的其余部分小得多。
以下介紹π0.5 模型及其訓練方案。
如圖概述 π0.5 模型及其訓練方案。模型權重由基于網絡數據訓練的標準 VLM 初始化,訓練分為兩個階段:預訓練階段,旨在使模型適應各種機器人任務;后訓練階段,旨在使模型專門用于移動操作,并為其配備高效的測試-時推理機制。在預訓練階段,所有任務(包括包含機器人動作的任務)都用離散的 token 表示,從而實現簡單、可擴展且高效的訓練 [64]。在后訓練階段,調整模型使其也包含一個動作專家,就像 π0 模型一樣,以便以更細的粒度表示動作,并實現更高效的實時控制推理計算。在推理階段,模型首先為機器人生成一個高級子任務,然后基于該子任務,通過動作專家預測低級動作。
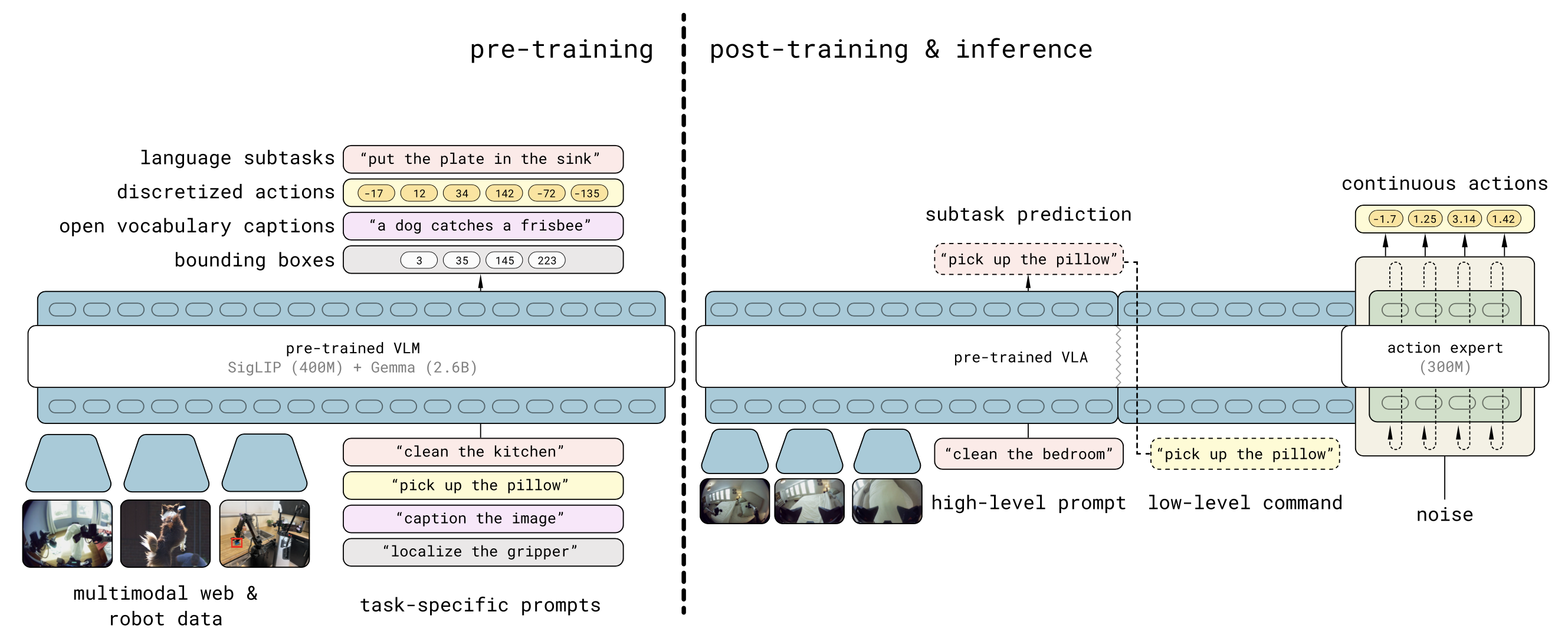
π0.5 架構
π0.5 架構可以靈活地表示動作塊分布和 token 化文本輸出,后者既可用于協同訓練任務(例如問答),也可用于在分層推理過程中輸出高級子任務預測。該模型捕獲的分布可以寫成π_θ(a_t:t+H,l|o_t,?l),其中 o_t = [I0_t, …, In_t, q_t],由所有攝像機的圖像和機器人的配置(關節角度、夾持器姿勢、軀干升降姿勢和基本速度)組成,l 是整體任務提示(例如,“收起盤子”),?l 表示模型的(token 化)文本輸出,可以是預測的高級子任務(例如,“拿起盤子”)或對網絡數據中視覺語言提示的答案,a_t:t+H是預測的動作塊。
該分布可以分解為高級和低級推理兩部分,其中動作分布取決于?l 而不是 l,高級推理捕獲π_θ(l|o_t, ?l),低級推理捕獲π_θ(a_t:t+H|o_t, ?l),這兩個分布都由同一個模型表征。
該模型對應于一個 transformer,它接受 N 個多模態輸入tokens x_1:N(寬泛地使用術語 token,指的是離散輸入和連續輸入)并產生一系列多模態輸出 y_1:N,可以將其寫成 y_1:N = f(x_1:N, A(x_1:N), ρ(x_1:N))。每個 x_i 可以是文本 token(xw_w)、一個圖像補丁(xI_I)或流匹配中機器人動作的中間去噪值(xa_i)。觀測值 o_t 和 l 構成 x_1:N 的前綴部分。根據 token 類型(如 ρ(x_i) 所示),每個 token 不僅可以由不同的編碼器處理,還可以由transformer 內的不同專家權重處理。例如,圖像補丁通過視覺編碼器輸入,文本 token 嵌入到嵌入矩陣中。按照 π0 [8],將動作 token x^a_i 線性投影到 Transformer 嵌入空間,并在 Transformer 中使用單獨的專家權重來處理動作 token。注意矩陣 A(x_1:N) ∈[0, 1] 表示一個 token 是否可以關注另一個 token。與 LLM 中的標準因果注意相比,圖像補丁、文本提示和連續動作 token 使用雙向注意。
由于希望模型同時輸出文本(回答關于場景的問題或輸出接下來要完成的任務)和動作(在世界中采取行動),因此 f 的輸出被拆分為文本 token logits 和動作輸出 token,分別為 yl_1:M 和 y^a_1:H。第一個 M 對應于可用于對 l? 進行采樣的文本 token logits,后面的 H 個 tokens 由單獨的動作專家生成,就像在 π0 中一樣,并通過線性映射投影到用于獲得 a_t:t+H 的連續輸出。請注意,M + H ≤ N,即并非所有輸出都與損失相關。機器人本體感受狀態被離散化,并作為文本 token 輸入到模型中。
離散與連續動作表示的結合
與 π0 類似,使用流匹配[50]來預測最終模型中的連續動作。給定a^τ,ω_ t:t+H = τa_t:t+H + (1?τ)ω, ω~N(0,I),其中 τ ∈ [0,1] 是流匹配時間索引,訓練模型預測流向量場 ω ? a_t。然而,如[64]所示,當動作用離散 token 表示時,VLA 訓練速度會更快,尤其是在使用一個能夠有效壓縮動作塊的 token 化方案(例如FAST)時。遺憾的是,這種離散表示不太適合實時推理,因為它們需要昂貴的自回歸解碼才能進行推理[64]。因此,理想的模型設計應該在離散動作上進行訓練,但仍允許使用流匹配在推理時生成連續動作。
因此,模型通過對 token 進行自回歸采樣(使用 FAST token 化器)和對流場進行迭代積分來訓練以預測動作,從而結合兩者的優點。用注意矩陣來確保不同的動作表征不會互相關注。模型經過優化以最小化綜合損失:一個是文本 tokens 和預測 logits(包括 FAST 編碼的動作 token)之間的交叉熵損失,另一個是流匹配誤差的損失。其中ya_1:H = f^a_θ (a_t:t+H^τ, ω, o_t, l) 是來自(較小)動作專家的輸出,α 是一個權衡參數。這種方案能夠首先通過將動作映射到文本 token(α = 0)將模型預訓練為標準 VLM Transformer 模型,然后添加額外的動作專家權重,以非自回歸方式預測連續動作 tokens,以便在訓練后階段進行快速推理。遵循此流程可使 VLA 模型獲得穩定的預訓練效果和出色的語言跟蹤能力。在推理時,對文本 token l? 使用標準自回歸解碼,然后以文本 token 為條件進行 10 個去噪步驟,最終生成動作 a_t:t+H。
預訓練
在第一個訓練階段,π0.5 使用廣泛的機器人和非機器人數據進行訓練,其總結在下圖說明。它被訓練為一個標準的自回歸 transformer,用于對文本、物體位置和 FAST 編碼的動作 token 進行下一個 token 預測。

多樣化的移動機械手數據 (MM)。用大約 400 小時的移動機械手數據,這些機械手在大約 100 個不同的家庭環境中執行家務,其中一些環境如下圖所示,使用 PI 公司設計的機器人。這部分訓練集與評估任務最直接相關,該評估任務包括在新的、未見過的家庭環境中執行類似的清潔和整理任務。
多樣化的多環境非移動機器人數據 (ME)。還收集各種家庭環境中的非移動機器人數據,包括單臂或雙臂機器人。這些手臂固定在表面或安裝平臺上,由于它們重量明顯更輕且更易于運輸,能夠利用它們在更廣泛的家庭中收集更加多樣化的數據集。但是,這些 ME 數據來自與移動機器人不同的具身。
跨具身實驗室數據 (CE)。在實驗室中收集各種任務的數據(例如,收拾桌子、折疊襯衫),使用更簡單的桌面環境和各種類型的機器人。其中一些任務與評估高度相關(例如,將碗碟放入垃圾桶),而其他任務則不相關(例如,研磨咖啡豆)。這些數據包括單臂和雙臂機械手,以及靜態和移動基座。還包括開源 OXE 數據集 [15]。該數據集是 π0[8] 使用的數據集擴展版。
高級子任務預測 (HL)。將諸如“打掃臥室”之類的高級任務命令分解為諸如“調整毯子”和“拿起枕頭”之類的較短的子任務,類似于語言模型的思維鏈提示,可以幫助訓練的策略推理當前場景并更好地確定下一步操作。對于MM、ME和CE中的機器人數據,如果任務涉及多個子任務,會手動使用子任務的語義描述對所有數據進行注釋,并訓練π0.5,使其基于當前觀察結果和高級命令,聯合預測子任務標簽(以文本形式)和操作(以子任務標簽為條件)。這自然會形成一個既可以充當高級策略(輸出子任務),又可以充當執行這些子任務操作低級策略的模型。還標記當前觀察結果中顯示的相關邊框,并在預測子任務之前訓練 π0.5 對其進行預測。
多模態網絡數據 (WD)。最后,在預訓練中引入一組多樣化的網絡數據,涉及圖像字幕制作(CapsFusion [87]、COCO [12])、問答(Cambrian-7M [77]、PixMo [19]、VQAv2 [32])和目標定位。對于目標定位,進一步擴展標準數據集,添加帶有邊框注釋的室內場景和家用目標的網絡數據。
對于所有動作數據,訓練模型預測目標關節和末端執行器的姿勢。為了區分這兩者,在文本提示中添加“<控制模式>關節/末端執行器<控制模式>”。使用單個數據集每個動作維度的 1% 和 99% 分位數,所有動作數據都歸一化到 [-1, 1]。將動作 a 的維數設置為固定數,以適應所有數據集中最大的動作空間。對于具有低維配置和動作空間的機器人,對動作向量進行零填充。
后訓練
在使用離散 token 對模型進行 28 萬個梯度步長的預訓練后,進行第二階段的訓練,稱之為后訓練。此階段的目的是使模型針對用例(家庭中的移動設備操作)進行專業化,并添加一個能夠通過流匹配生成連續動作塊的動作專家。此階段與下一個 token 預測聯合訓練,以保留文本預測能力,并為動作專家進行流匹配(在后訓練開始時使用隨機權重初始化)。優化前面組合損失的目標函數,使 α = 10.0,并額外訓練 8 萬個梯度步長。后訓練動作數據集包含 MM 和 ME 機器人數據,并篩選出長度低于固定閾值的成功事件。加入網絡數據 (WD) 以保留模型的語義和視覺能力,以及與多環境數據集對應的 HL 數據切片。此外,為了提升模型預測合適高級子任務的能力,收集口頭指令演示 (VI)。這些演示由專家用戶構建,提供“語言演示”,選擇合適的子任務命令,逐步指揮機器人執行移動操作任務。這些示例是通過實時“遙操作”機器人,使用語言執行已學習的低級策略來收集的,本質上是為已訓練策略提供良好的高級子任務輸出演示。
機器人系統細節
如圖展示在移動操控實驗中使用的機器人系統。所有實驗均采用兩種類型的移動操控器。兩個平臺均配備兩個 6 自由度(DOF)機械臂,機械臂配備平行鉗口夾持器和腕式單目RGB攝像頭、一個輪式完整基座以及一個軀干升降機構。基座的狀態和動作空間分別對應線性(二維)和角(一維)速度,軀干升降機構則為一維(上下)或二維(上下和前后)。除了兩個腕式攝像頭外,機器人還在機械臂之間安裝前后攝像頭。用所有四個攝像頭進行高級推理,腕式攝像頭和前向攝像頭進行低級推理。狀態和動作空間的總維數為18或19,具體取決于平臺。
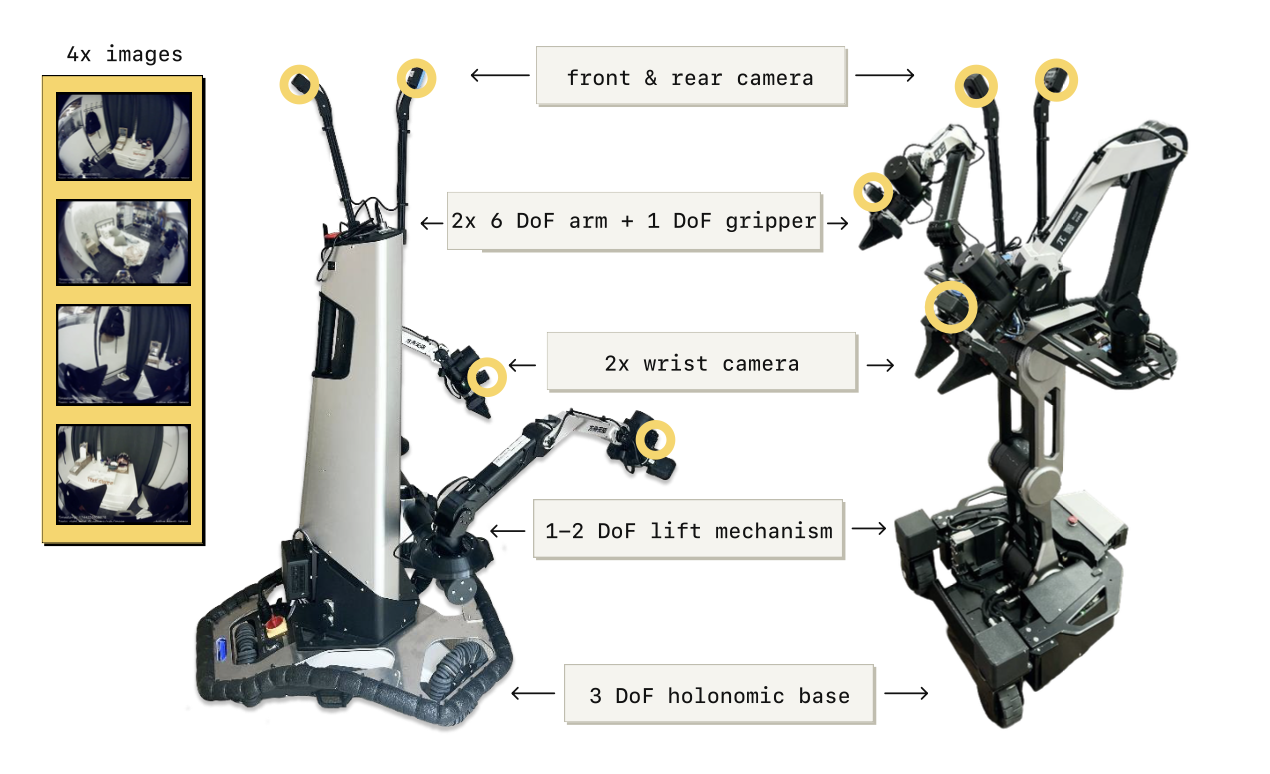
控制系統非常簡單:π0.5 模型直接控制手臂、夾持器和軀干升降的目標姿態,以及 50 Hz(帶動作分塊)的目標基準速度。這些目標通過簡單的 PD 控制器進行跟蹤,無需任何額外的軌跡規劃或碰撞檢測。所有操作和導航控制均為端到端。
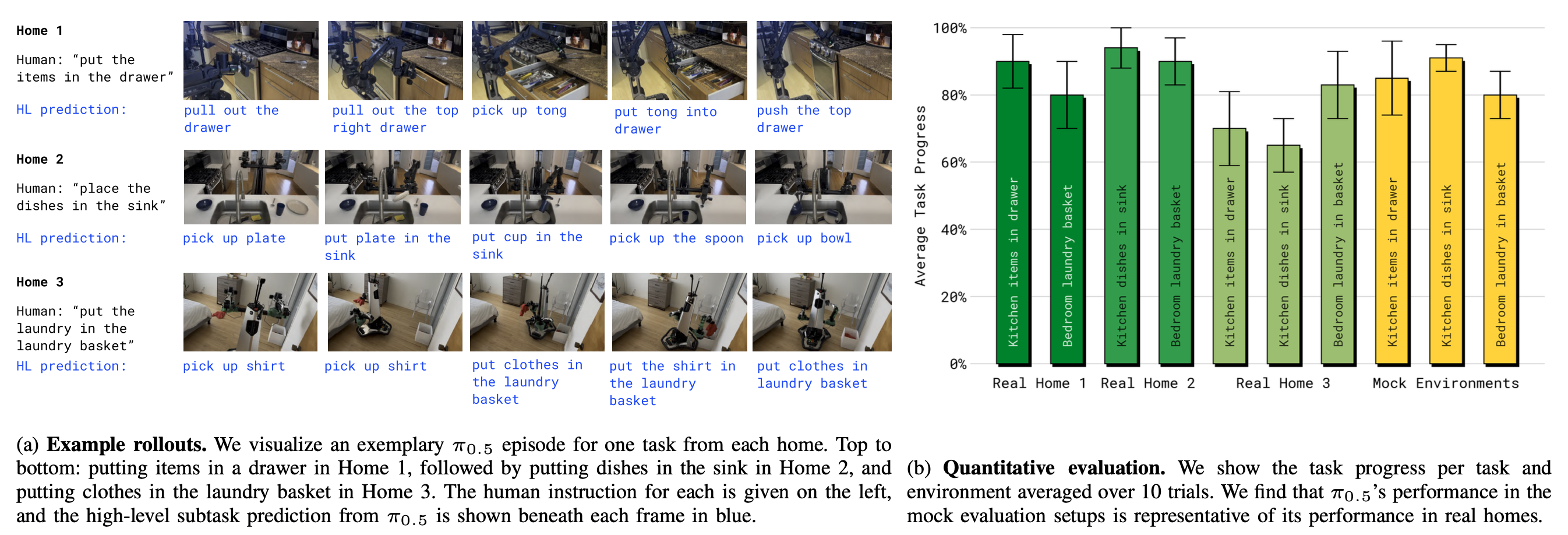
π0.5 模型旨在泛化到新環境。雖然在與訓練數據匹配的環境中評估 VLA 很常見,但所有的實驗都是在訓練中未曾見過的新環境中進行的。為了進行定量比較,使用一組模擬家庭環境來提供可控且可重復的設置,而最真實的最終評估是在三個不屬于訓練集的真實家庭中進行的(如圖所示)。

π0.5 的泛化能力表明,這種協同訓練方法能夠促進有效的遷移,僅使用中等規模的移動操作數據集即可實現對移動機械手的高度泛化控制。π0.5 并非沒有局限性。雖然 VLA 展現出泛化能力,但它仍然會犯錯。某些環境會持續帶來挑戰(例如,不熟悉的抽屜把手,或者機器人難以打開的櫥柜),某些行為會給部分可觀測性帶來挑戰(例如,機械臂遮擋應該擦拭的溢出物),并且在某些情況下,高級子任務推理很容易分散注意力(例如,在收拾物品時多次打開和關閉抽屜)。通過更好的協同訓練、遷移和更大的數據集來應對這些挑戰,是未來工作的一個有希望的方向。
其他未來的工作方向可以解決方法的技術限制。雖然 π0.5 可以執行各種行為來清潔廚房和臥室,但它處理的提示相對簡單。模型能夠適應的提示的復雜度取決于訓練數據,并且可以通過生成更復雜、更多樣化的注釋(使用人工標注器或合成方法)來整合更復雜的偏好和指令。該模型也使用相對有限的上下文,而融入更豐富的上下文和記憶,可以顯著提升模型在部分可觀測性更強的場景下的表現,例如需要在不同房間之間導航或記住物品存放位置的任務。更廣泛地說,π0.5 探索的是異構數據源的特定組合,但具體的數據源可以進行更廣泛的探索。例如,系統能夠從口頭指令中學習,這提供一種強大的新監督模式,未來的研究可以探索這種模式,以及人類能夠為機器人提供額外上下文知識的其他方式。






)


_常規的電源管理的基本概念和軟件架構)


)


![[創業之路-390]:人力資源 - 社會性生命系統的解構與重構:人的角色嬗變與組織進化論](http://pic.xiahunao.cn/[創業之路-390]:人力資源 - 社會性生命系統的解構與重構:人的角色嬗變與組織進化論)



