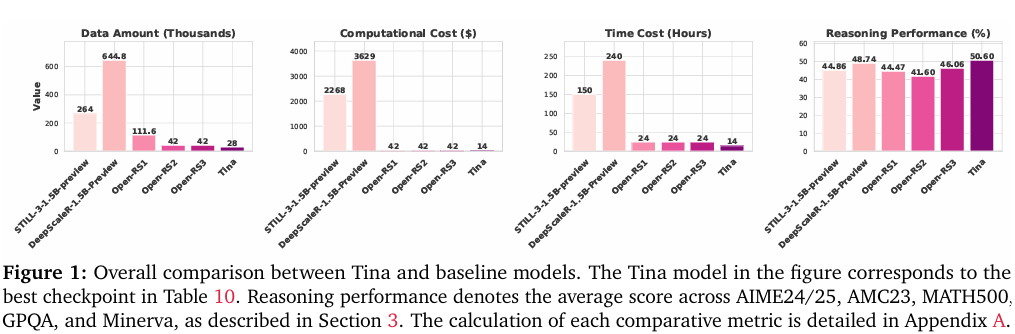
摘要:如何在語言模型中實現成本效益高的強大推理能力? 在這個基本問題的驅動下,我們提出了Tina,這是一個以高成本效益實現的小型推理模型家族。 值得注意的是,Tina 證明了僅使用最少的資源就可以開發出大量的推理性能,方法是在強化學習(RL)過程中應用參數高效的更新,使用低秩自適應(LoRA),對已經非常小的 15 億參數基礎模型進行更新。 這種極簡主義方法產生的模型實現了與基于相同基礎模型的SOTA RL推理模型相媲美,有時甚至超越的推理性能。 至關重要的是,這只需要現有SOTA模型所使用的計算后訓練成本的一小部分。 事實上,最好的Tina模型在AIME24上實現了>20%的推理性能提升和43.33%的Pass@1準確率,后訓練和評估成本僅為9美元(即估計成本降低260倍)。 我們的工作揭示了通過LoRA進行高效RL推理的驚人效果。 我們從一組固定的超參數開始,在多個開源推理數據集和各種消融設置中驗證了這一點。 此外,我們假設這種有效性和效率源于LoRA迅速使模型適應RL獎勵的推理結構格式,同時很大程度上保留了基礎模型的基礎知識。 為了實現可訪問性和開放研究,我們完全開源所有代碼、訓練日志和模型權重\檢查點。Huggingface鏈接:Paper page,論文鏈接:2504.15777
研究背景和目的
研究背景
隨著自然語言處理(NLP)領域的快速發展,語言模型(LMs)在各種任務中展現出了越來越強的能力。然而,實現魯棒、多步驟的推理能力仍然是語言模型面臨的一項前沿挑戰。盡管通過監督微調(SFT)來增強復雜推理能力是一種廣泛采用的技術,但這種方法依賴于高質量和可獲得的專家演示,獲取這些演示的成本往往很高。此外,SFT還可能導致學習模型僅僅模仿推理軌跡,而不是動態探索推理路徑。相比之下,強化學習(RL)使模型能夠直接從精心策劃的數據中可驗證的獎勵信號中學習,從而引導模型探索更多樣化的邏輯路徑,并可能發現更穩健的解決方案。然而,RL管道通常復雜且資源密集,涉及大量的計算成本。因此,如何在語言模型中實現成本效益高的強大推理能力成為了一個亟待解決的問題。
研究目的
針對上述問題,本研究旨在提出一種高效且成本效益高的方法來在語言模型中實現強大的推理能力。我們提出了Tina,這是一個通過LoRA(低秩自適應)實現的小型推理模型家族。Tina通過應用參數高效的更新,在強化學習過程中對已經非常小的15億參數基礎模型進行微調,從而僅用最少的資源就實現了顯著的推理性能提升。我們的目標是展示Tina能夠在保持高效的同時,實現與基于相同基礎模型的SOTA RL推理模型相媲美甚至更優的推理性能,并且顯著降低計算后訓練成本。
研究方法
1. Tina模型架構
Tina模型是在一個已經訓練好的小型語言模型基礎上,通過LoRA進行參數高效的更新得到的。LoRA通過分解權重矩陣為低秩矩陣的乘積,從而大大減少了需要更新的參數數量。在Tina中,我們僅對LoRA的適配矩陣進行更新,而不是整個模型權重,這使得訓練過程更加高效且計算成本更低。
2. 強化學習訓練
我們使用強化學習來訓練Tina模型,以學習如何在各種推理任務中表現優異。在訓練過程中,模型接收到一系列的問題和選項,并需要選擇正確的答案。我們設計了一個獎勵函數,根據模型的答案正確與否給予相應的獎勵或懲罰。通過不斷地試錯和學習,模型逐漸學會了如何更好地解決推理問題。
3. 低秩自適應(LoRA)
LoRA是Tina模型的核心技術之一。它通過分解語言模型的權重矩陣為兩個低秩矩陣的乘積,從而顯著減少了需要訓練的參數數量。在訓練過程中,我們僅對這兩個低秩矩陣進行更新,而不是整個權重矩陣。這種方法不僅提高了訓練效率,還降低了過擬合的風險,因為更新的參數數量大大減少。
4. 參數高效更新
除了使用LoRA進行參數分解外,我們還采用了其他技術來進一步提高參數更新的效率。例如,我們使用了梯度裁剪和正則化方法來防止模型在訓練過程中過擬合。此外,我們還對訓練數據進行了增強和平衡處理,以確保模型能夠學習到更加泛化的推理能力。
5. 實驗設置
為了驗證Tina模型的有效性,我們在多個開源推理數據集上進行了廣泛的實驗。這些數據集涵蓋了各種推理任務,包括邏輯推理、數學推理和常識推理等。我們還設置了不同的消融實驗來評估不同組件對模型性能的影響。所有實驗都使用了一組固定的超參數設置進行訓練和評估。
研究結果
1. 性能提升
實驗結果表明,Tina模型在多個推理數據集上實現了顯著的性能提升。與基于相同基礎模型的SOTA RL推理模型相比,Tina模型在保持高效的同時,實現了更高的推理準確率。特別是在一些具有挑戰性的推理任務上,Tina模型表現出了更強的泛化能力和魯棒性。
2. 成本效益
除了性能提升外,Tina模型還展現出了極高的成本效益。與現有SOTA模型相比,Tina模型在計算后訓練成本上實現了顯著的降低。這得益于LoRA技術的使用以及參數高效更新策略的實施。事實上,最好的Tina模型在AIME24數據集上實現了>20%的推理性能提升和43.33%的Pass@1準確率,而后訓練和評估成本僅為9美元(即估計成本降低260倍)。
3. 消融實驗
消融實驗的結果進一步驗證了不同組件對Tina模型性能的影響。我們發現,LoRA技術的使用對模型性能的提升起到了至關重要的作用。同時,參數高效更新策略和強化學習訓練方法的結合也是實現高效推理能力的關鍵因素。
研究局限
盡管Tina模型在推理任務中取得了顯著的性能提升和成本效益,但仍存在一些局限性。首先,Tina模型是基于一個小型語言模型基礎進行微調的,因此其基礎能力可能受到一定限制。其次,Tina模型目前僅在一些開源推理數據集上進行了測試和驗證,可能無法完全反映其在更復雜和現實世界場景中的表現。此外,盡管LoRA技術顯著降低了訓練成本,但其對模型性能的影響仍需進一步研究和探索。
未來研究方向
針對上述研究局限,未來可以從以下幾個方面展開進一步研究:
-
擴展基礎模型:可以嘗試將Tina模型擴展到更大的語言模型基礎上進行微調,以進一步提升其基礎能力和推理性能。同時,也可以探索不同基礎模型對Tina模型性能的影響。
-
更多數據集和場景測試:可以收集更多樣化的推理數據集并在更復雜的現實世界場景中對Tina模型進行測試和驗證。這將有助于更全面地評估Tina模型的泛化能力和魯棒性。
-
深入研究LoRA技術:可以進一步探索LoRA技術對模型性能的影響機制,并嘗試對其進行改進和優化。這將有助于提高Tina模型的訓練效率和推理性能。
-
結合其他技術:可以嘗試將Tina模型與其他先進技術(如知識蒸餾、遷移學習等)相結合,以進一步提升其性能和泛化能力。這將有助于推動語言模型在推理任務中的進一步發展和應用。
綜上所述,本研究通過提出Tina模型展示了如何在語言模型中實現高效且成本效益高的強大推理能力。盡管仍存在一些局限性,但Tina模型的成功為未來的研究提供了新的思路和方向。我們相信隨著技術的不斷進步和完善,語言模型在推理任務中的表現將會越來越出色。
)

2022 版安裝與下載教程)

Java/python/JavaScript/C/C++/GO最佳實現)
:深入剖析電子商務商業模式)













