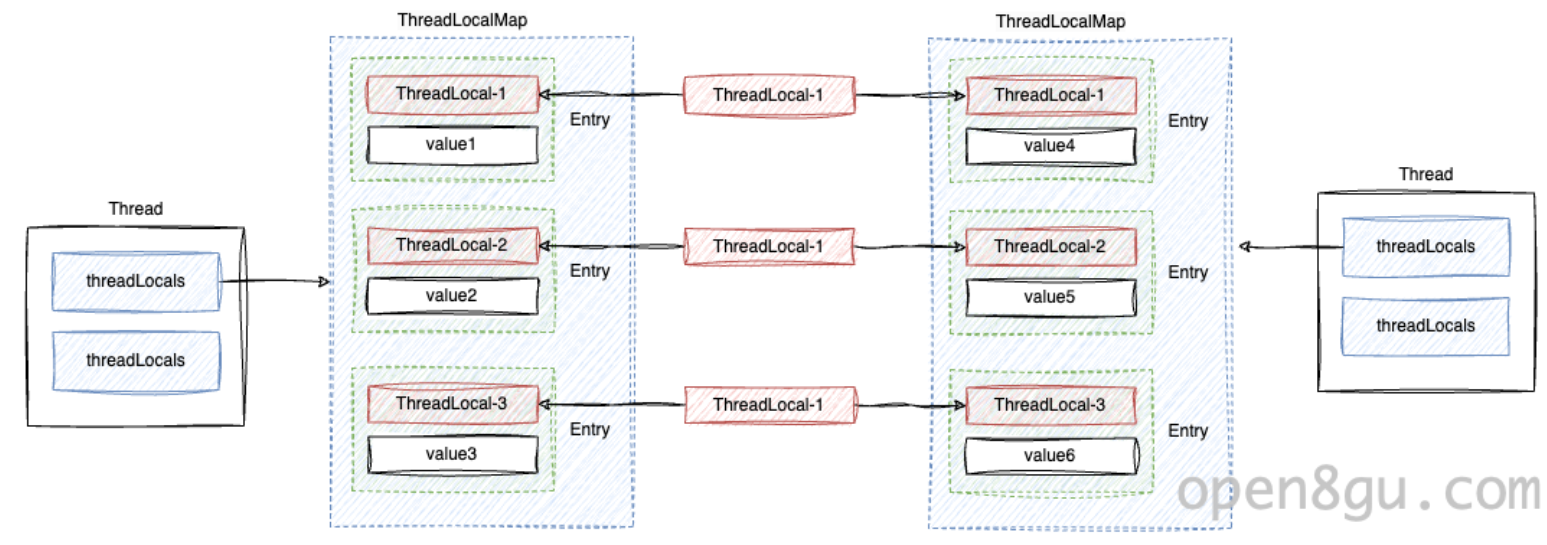
首先,ThreadLocal 本身并不提供存儲數據的功能,當我們操作 ThreadLocal 的時候,實際上操作線程對象的一個名為 threadLocals 成員變量。這個成員變量的類型是 ThreadLocal 的一個內部類 ThreadLocalMap,它是真正用來存儲數據的容器。因此,不同線程間的數據從物理上就是隔離的,所以 ThreadLocal 不需要任何同步機制也天然是線程安全的。
ThreadLocalMap 底層基于一個長度為 2 的次方的數組實現,所有的數據都會被封裝為以 ThreadLocal 作為 Key 的鍵值對對象 Entry 存放在數組中。底層數組默認大小為 16,擴容閾值為當前容量的三分之二,每次擴容容量都翻倍。
為了提高散列效率,ThreadLocalMap 采用斐波那契散列法作為哈希算法。具體而言,當在根據 ThreadLocal 計算下標的時候,不像 HashMap 那樣直接取 hashCode 方法的返回值作為哈希值,而是使用通過一個全局計數器,保證每個 ThreadLocal 實例創建的時候都采用一個特殊的魔數 0x61c88647 的倍數作為哈希值,比如第一個創建的 ThreadLocal 的哈希值為 1?*?0x61c88647,第二個則為 2?*?0x61c88647……以此類推。并且,由于 ThreadLocalMap 底層存放鍵值對的槽位數量總是 2 的次方,根據斐波那契散列法的特性,在這種情況下,可以大幅度降低計算得到相同下標的可能性,換而言之,就是可以減少哈希沖突發生的概率。
不過哈希沖突總是存在的,對此 ThreadLocalMap 使用線性探測的方式來解決,簡單的說,就是如果發生哈希沖突,它就檢查下一個槽位是否未被使用,如果未被使用就將值設置到該槽位,否則就繼續向后探測,直到找到一個可用槽位為止。
最后,由于數據是直接綁定到線程上的,為了防止用戶因為未及時清理數據而導致內存泄露,ThreadLocalMap 底層使用的鍵值對對象將其的 Key —— 也就是 ThreadLocal 本身 —— 設置為了弱引用,如此一來,當外界沒有對 ThreadLocal 的強引用時,鍵值對的 Key 將會隨著 GC 被回收,此時該數據相當于被自動標記為失效。在后續的增刪改查操作時,ThreadLocalMap 將會順帶檢查并清理這些失效數據。
問題詳解?
1. 數據結構?
1.1. ThreadLocal 與 ThreadLocalMap?
與通常的 Map 或 List 這類數據結構不同,ThreadLocal 本身并不直接存儲數據,真正的數據其實直接存儲在線程對象 Thread 中:
public class Thread implements Runnable {/* ThreadLocal values pertaining to this thread. This map is maintained* by the ThreadLocal class. */ThreadLocal.ThreadLocalMap threadLocals = null;/** InheritableThreadLocal values pertaining to this thread. This map is* maintained by the InheritableThreadLocal class.*/ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
}
我們可以看到,每個 Thread 都通過?threadLocals?和?inheritableThreadLocals?兩個成員變量各持有一個特殊的 ThreadLocalMap 集合,它就是實際存儲數據的地方:
static class ThreadLocalMap {static class Entry extends WeakReference<ThreadLocal<?>> {Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}}private static final int INITIAL_CAPACITY = 16;// 數組大小總是2的倍數private Entry[] table;private int size = 0;private int threshold; // Default to 0
}
由于每個線程只操作其獨有的數據,每個線程的數據都是彼此隔離的,因此不需要任何同步機制,ThreadLocal 也天然就是線程安全的。
inheritableThreadLocals 這個變量是專門為 InheritableThreadLocal 準備的,具體可參見:? ThreadLocal 有哪些擴展實現?
1.2. 鍵值對對象 Entry?
ThreadLocalMap 和我們熟悉的 HashMap 一樣,它使用數組最為最底層的數據結構,數組中的每個槽位都對應一個鍵值對對象 Entry ,其中 Key 就是對應的 ThreadLocal 本身,而 Value 則是要“存儲”到 ThreadLocal 里的數據。
static class Entry extends WeakReference<ThreadLocal<?>> {Object value; // 存儲的數據Entry(ThreadLocal<?> k, Object v) {super(k); // 對 ThreadLocal 的引用為弱引用value = v;}
}
此外,值得注意的是,Entry 繼承了 WeakReference,并且將 ThreadLocal 作為弱引用,這意味著當外界對 ThreadLocal 的強引用消失后,即使該 Entry 依然在槽中存在,但是它的 Key 卻已經變為了 null,這種鍵值對實際上是已經失效的。
在后文,我們會在 ThreadLocalMap 的增刪改方法中看到對槽位中失效的鍵值進行清理的操作。
1.3. 為什么需將 Key 設置為弱引用??
在理解這個問題之前,我們不妨想一下,如果 Entry 不設置為弱引用會怎么樣?
以下面的代碼為例:
public class static run() {ThreadLocal tl = new ThreadLocal();Object value = new Object();tl.set(value);
}
結合之前的例子,我們知道,當執行完上述代碼后,當前線程將會把?tl?和?value?作為一個 Entry 對象存儲在自己擁有的 ThreadLocalMap 中。
由于?tl?和?value?都間接的被當前線程對象強引用,也就是說,在當前線程對象的生命周期結束前, tl 和 value 一直都不會被回收。
并且,由于我們也沒有調用 remove 方法主動的讓線程對象把?tl?從它擁有的 ThreadLocalMap 中移除,這樣等于實質上的發生了內存泄露。
而當 Entry 里面的 Key —— 也就是 ThreadLocal —— 被設置為弱引用后,哪怕用戶沒有及時清空數據,在 GC 的時候 JVM 也會自動回收 ThreadLocal,這等于主動標記 Entry 為失效數據,如此一來,當后續進行增刪改等操作的時候,ThreadLocalMap 將會自動清除失效數據,實現內存的自動釋放,減小內存泄露的可能性。
關于 ThreadLocal 與內存泄露的問題,具體可以參見:? ThreadLocal 什么場景內存泄露?
1.4. 為什么不選擇把 Value 設置為弱引用??
從原理來說,要確認一個 Entry 是失效的,只要有辦法讓 Key 或者 Value 失效就行,從這個角度上來看,把 Key 或者 Value 設置為弱引用都可以實現自動回收的效果。
不過,把 Value 而不是 Key 作為弱引用,最大的問題在于?Value 的生命周期是不確定的。比如,如果緩存的值對象恰好是 String 或者 Integer 類型,由于值本身具備緩存機制導致很難被回收,會進而導致數據遲遲無法失效,進而導致內存泄露。因此,為了避免用戶使用常量或長生命周期的對象作為弱引用導致數據遲遲無法被回收,需要把 Key 而不是 Value 設置為弱引用。
2. 哈希算法?
鍵值對集合要實現高效的訪問,就需要一個合理的哈希算法,而要理解其哈希算法的運作過程,就要理解一個值是如何添加到集合中的。
我們查看 ThreadLocalMap 的?set方法:
private void set(ThreadLocal<?> key, Object value) {// 根據桶容量對哈希取模確定下標Entry[] tab = table;int len = tab.length;int i = key.threadLocalHashCode & (len-1);// 從指定下標開始遍歷槽,如果槽位不為空:for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {ThreadLocal<?> k = e.get();// 1、如果槽中的 ThreadLocal 就是當前要操作的,則更新值if (k == key) {e.value = value;return;}// 2、如果槽中的 ThreadLocal 已經被回收,則更新整個鍵值對if (k == null) {replaceStaleEntry(key, value, i);return;}}// 如果目標槽位仍然未被使用,則直接設置一個鍵值對tab[i] = new Entry(key, value);int sz = ++size;// 清空一些必要的槽位,如果已用槽位仍然大于擴容閾值,則進行擴容if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();
}private static int nextIndex(int i, int len) {return ((i + 1 < len) ? i + 1 : 0);
}
2.1. 斐波那契散列法?
根據上文的代碼,我們知道 ThreadLocalMap 通過?key.threadLocalHashCode & (len-1)?這段代碼計算下標。這段看似平平無奇的代碼其實暗藏玄機。
我們先從 ThreadLocal 哈希值的生成看起:
public class ThreadLocal<T> {private final int threadLocalHashCode = nextHashCode();private static AtomicInteger nextHashCode =new AtomicInteger();// 每次創建對象時,其哈希值都比上一次遞增 0x61c88647private static final int HASH_INCREMENT = 0x61c88647;private static int nextHashCode() {return nextHashCode.getAndAdd(HASH_INCREMENT);}}
簡單的來說,ThreadLocal 的哈希值并不像 HashMap 那樣,使用 Key 的?hashCode()?方法的返回值進行高低位混淆后作為哈希值,而是直接聲明了一個全局的靜態計數器?nextHashCode,以該計數器按特定規律生成的固定值作為哈希值。
每當創建一個 ThreadLocal 實例時,就獲取當前計數值并累加 0x61c88647,簡單的來說:第一個 ThreadLocal 的哈希值是 0x61c88647?*?1,而第二個是 0x61c88647?*?2…… 以此類推。
這里每次遞增的魔數?0x61c88647 轉為十進制是 1640531527,而 1640531527 則是整數位數(即 2^32)乘以黃金分割比例 0.68 得到的近似結果。當 ThreadLocal 底層槽位的大小 n 為 2 的次方時,key.threadLocalHashCode & (n-1)?計算將得到是?key.threadLocalHashCode?的低 n 位,換算成十進制數后得到的恰好是一個小于 n 且大概率不重合的數。
ThreadLocal 使用的這種哈希算法被稱為斐波那契散列,它是一種神奇而高效的哈希算法。
有的同學看到這里可能會感覺很懵,關于為當數組長度為 2 的次方的時候,哈希值每次遞增 0x61c88647 在計算下標的時候就可以得到很好的散列效果?這就是一個有意思的數學 & 計算機科學問題了,三言兩語很難講清楚,因此這里推薦直接閱讀文章,雖然是英文的,不過簡單機翻一下也可以看懂,感興趣的可以了解一下?斐波那契散列 sourl.cn/8Ucdag
2.2. 如何解決哈希沖突??
不過,即使再強大的哈希算法,要把無限的數據映射到有限的空間里,總歸要面臨哈希沖突問題。目前主流解決哈希沖突的方案有兩種:
- 拉鏈法:發生哈希沖突的元素,在同一槽位中形成鏈表。
- 開放定址法:發生哈希沖突的元素,通過其他的方式轉移到另一個空閑槽位。
其中,ThreadLocalMap 選擇的使用開放定址法作為解決方案,而開放定址法根據二次定位的方式,又分為線性探測、隨機探測與平方探測等多種具體方案,而 ThreadLocalMap 使用了其中最為直觀的一種,也就是線性探測。
簡單的來說,當計算出下標后,如果下標對應的槽位已經被占用,ThreadLocalMap 會嘗試訪問下一個下標,直到找到一個可用的槽位位置。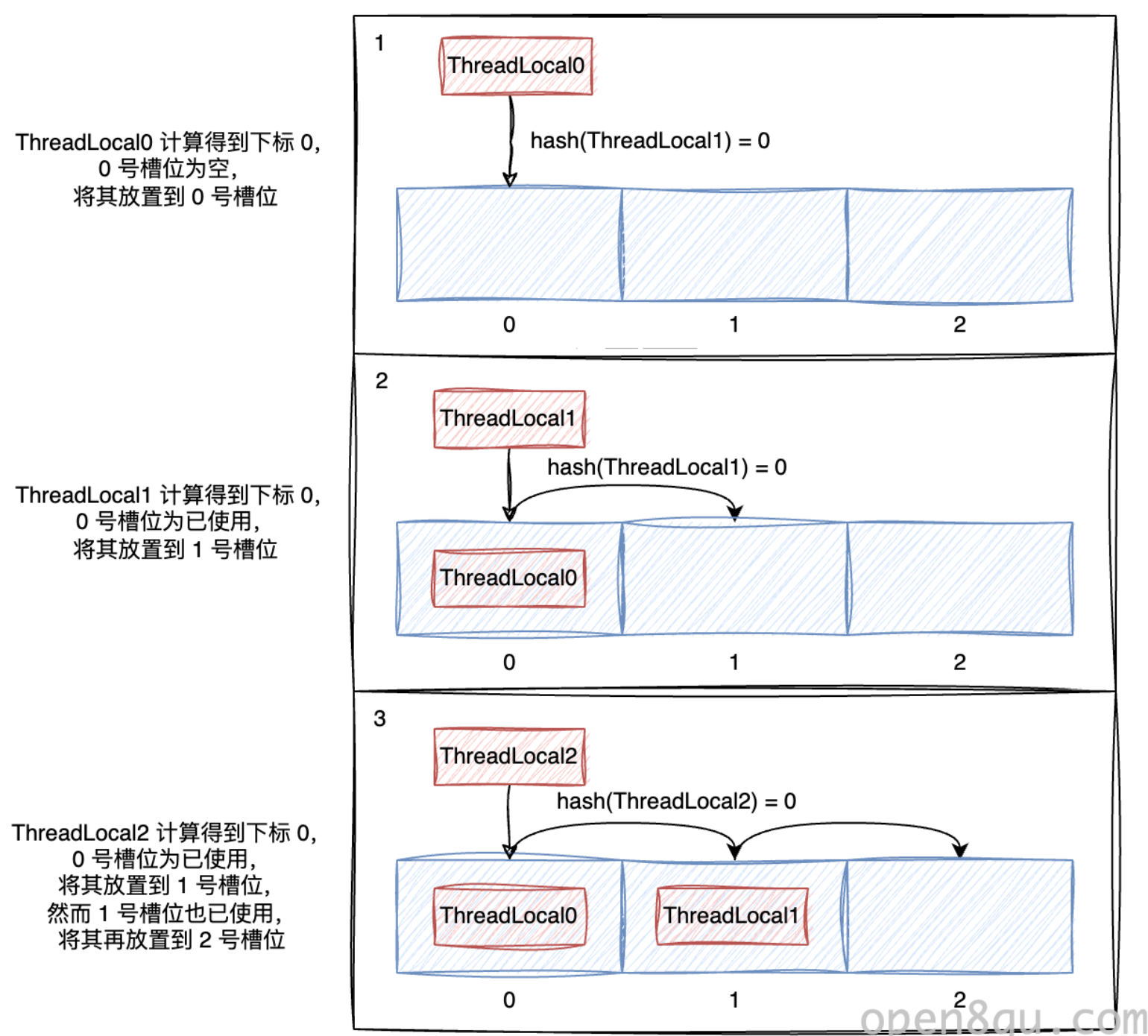
相比起 HashMap 使用的拉鏈法,這種解決方式實現起來更加簡單,并且更加節約內存,不過當頻繁發生哈希沖突時也會帶來額外的性能開銷。不過,考慮 ThreadLocal 本身的哈希算法十分高效,并且一個線程往往不會擁有太多的 ThreadLocal,哈希沖突的概率非常小,因此這個缺點也就不那么明顯了。
3. 無效數據的清理?
在上文,我們知道,ThreadLocalMap 通過將 Key —— 也就是 ThreadLocal 本身 —— 設置為弱引用,從而實現了讓數據自動失效的效果。
不過,失效不代表數據已經被移除,當 Entry 中的 Key 被回收后,Entry 實際上依然存在于槽位中。因此,ThreadLocalMap 會一些情況下被動的清理失效數據:
- 當進行增刪改查操作時,會清空指定范圍內的失效數據。
- 當進行擴容操作時,會清空所有失效數據。
3.1. expungeStaleEntry?
所有的數據清理操作,最終都會調用?expungeStaleEntry來清理指定的槽位:
private int expungeStaleEntry(int staleSlot) {Entry[] tab = table;int len = tab.length;// 移除指定槽位上的數據tab[staleSlot].value = null;tab[staleSlot] = null;size--;// 一并向后清理,直到遇到空槽位為止Entry e;int i;for (i = nextIndex(staleSlot, len); // 下一個槽位(e = tab[i]) != null; // 如果該槽位不為空i = nextIndex(i, len)) {ThreadLocal<?> k = e.get();// 如果數據已失效,則將其移除if (k == null) {e.value = null;tab[i] = null;size--;} else {// 如果數據未失效,則對其重新哈希調整位置int h = k.threadLocalHashCode & (len - 1);if (h != i) {tab[i] = null;// Unlike Knuth 6.4 Algorithm R, we must scan until// null because multiple entries could have been stale.while (tab[h] != null)h = nextIndex(h, len);tab[h] = e;}}}return i;
}
我們需要注意的是,刪除數據并不是直接清空指定的槽位就可以了,由于 ThreadLocalMap 使用線性探測解決哈希沖突,因此連續的不為空的槽位中的數據有可能在最開始計算得到的是同一個下標,只是因為哈希沖突才挪到了這里。
因此,在清除指定槽位后,還需要會向后遍歷,在這個過程中:
- 如果遇到的槽位中的數據已經失效,則將其移除。
- 如果遇到的槽位中的數據還未失效,則對其重新哈希,并進行遷移。
- 如果已經沒有下一個槽位了,或者下一個槽位為空,則終止遍歷。
在后面,我們還會在查找和更新數據的操作里面看到類似的做法,它們是思路基本都是一樣的。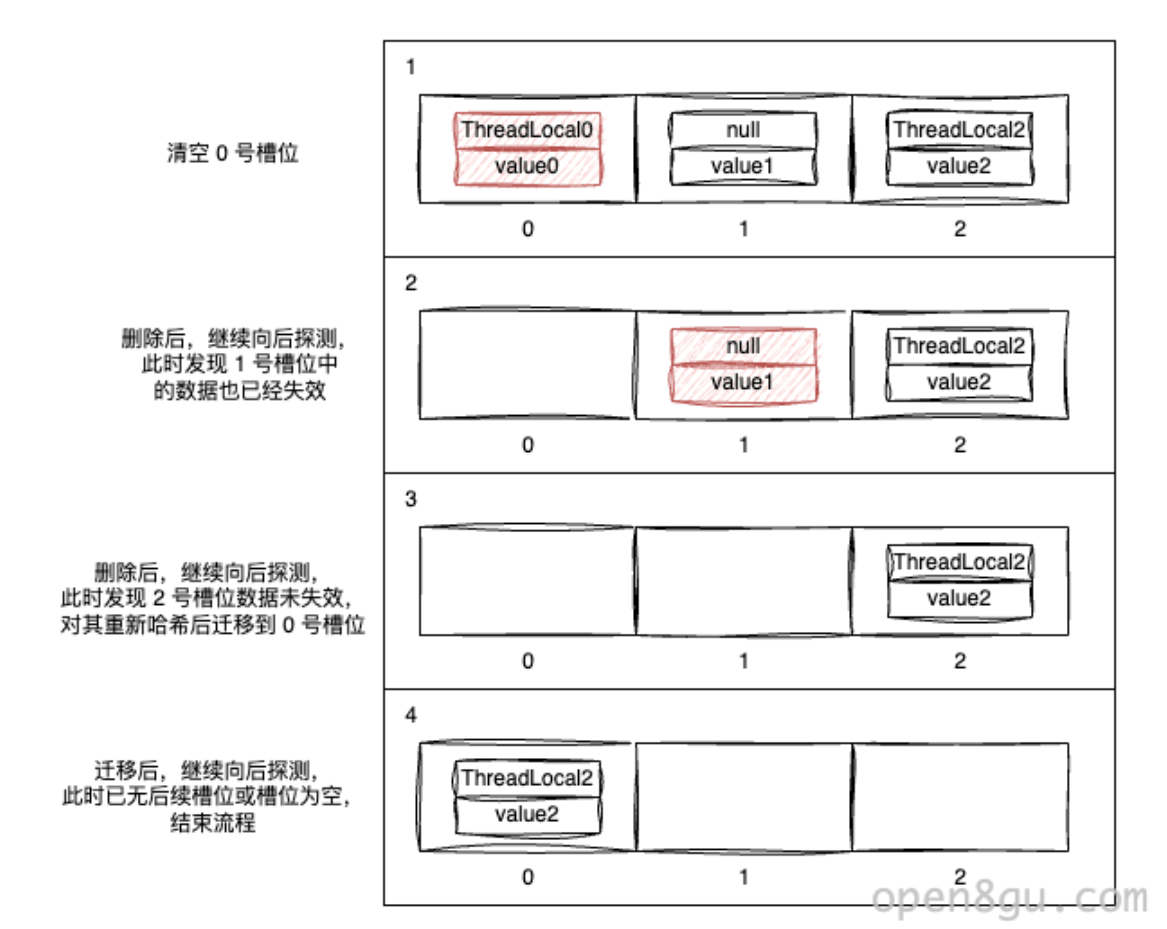
3.2. cleanSomeSlots?
expungeStaleEntry?方法每次只能清理一段相連的槽位,因此基于它, ThreadLocalMap 還提供了批量清理的方法?cleanSomeSlots,它通常在增刪改查等常規操作中調用:
private boolean cleanSomeSlots(int i, int n) {boolean removed = false;Entry[] tab = table;int len = tab.length;do {i = nextIndex(i, len);Entry e = tab[i];if (e != null && e.get() == null) {n = len;removed = true;// 清空一段連續的槽位i = expungeStaleEntry(i);}} while ( (n >>>= 1) != 0); // 清理范圍為 log(n)return removed;
}
�相比起?cleanSomeSlots,它的清理范圍是從指定下標開始向后延伸?log(n)長度。
3.3. expungeStaleEntries?
�在進行擴容的時候,會調用?expungeStaleEntries?方法清空全局的無效數據:
private void expungeStaleEntries() {Entry[] tab = table;int len = tab.length;for (int j = 0; j < len; j++) {Entry e = tab[j];// 循環調用 expungeStaleEntry 方法if (e != null && e.get() == null)expungeStaleEntry(j);}
}
這個清理方法是最重的,因此一般只在擴容的時候調用。
4. 設置值?
在了解了 ThreadLocalMap 的數據結構,與哈希算法,還有失效數據的清理機制后,我們可以正式開始了解一個值是如何添加到 ThreadLocalMap 里面的了:
private void set(ThreadLocal<?> key, Object value) {// 確定下標Entry[] tab = table;int len = tab.length;int i = key.threadLocalHashCode & (len-1);// 從指定下標開始遍歷槽,如果槽位不為空:for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {ThreadLocal<?> k = e.get();// 1、如果槽中的 ThreadLocal 就是當前要操作的,則更新值if (k == key) {e.value = value;return;}// 2、如果槽中的 ThreadLocal 已經被回收,則更新整個鍵值對if (k == null) {replaceStaleEntry(key, value, i);return;}}// 如果目標槽位仍然未被使用,則直接設置一個鍵值對tab[i] = new Entry(key, value);int sz = ++size;// 清空一些必要的槽位,如果已用槽位仍然大于擴容閾值,則進行擴容if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();
}private static int nextIndex(int i, int len) {return ((i + 1 < len) ? i + 1 : 0);
}
在方法的最開始,自然是獲取 ThreadLocal 的哈希值,并根據哈希算法計算下標,然后又因為線性探測的特殊性,在得到下標后,我們還需要從這個下標開始依次向后遍歷每個槽位:
- 如果該槽位已被當前操作的 ThreadLocal 使用,則更新槽位中鍵值對的值;
- 如果該槽位已被使用,但是對應的 ThreadLocal 已經被回收,則替換該槽位中的鍵值對,并清空一些槽位;
- 如果該槽位尚未被使用,則直接創建并設置一個鍵值對,并終止遍歷。此外,如果有必要,清理一些槽位,并視情況決定是否要擴容。
5. 擴容?
在 ThreadLocalMap 的構造函數中,我們可以知道它的默認大小是 16,擴容閾值為當前容量的 2/3,且不可更改:
// 初始容量
private static final int INITIAL_CAPACITY = 16;// 擴容閾值為容量的三分之二
private void setThreshold(int len) {threshold = len * 2 / 3;
}ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {table = new Entry[INITIAL_CAPACITY];int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);table[i] = new Entry(firstKey, firstValue);size = 1;setThreshold(INITIAL_CAPACITY);
}
而在真正用于擴容的則是 resize 方法中,每次擴容容量都翻倍,且每個槽位中的數據都要進行重哈希:
private void resize() {Entry[] oldTab = table;int oldLen = oldTab.length;// 新長度為舊長度的兩倍int newLen = oldLen * 2;Entry[] newTab = new Entry[newLen];int count = 0;for (int j = 0; j < oldLen; ++j) {Entry e = oldTab[j];if (e != null) {ThreadLocal<?> k = e.get();// 如果 Key 已經被回收,則將 Value 也置空if (k == null) {e.value = null; // Help the GC} else {// 對每個 Key 進行重哈希int h = k.threadLocalHashCode & (newLen - 1);while (newTab[h] != null)h = nextIndex(h, newLen);newTab[h] = e;count++;}}}// 更新擴容閾值 setThreshold(newLen);size = count;table = newTab;
}
為什么選擇 2/3 作為負載系數?
這里有個額外的問題,為什么擴容閾值要是 2/3 這么一個奇怪的數值?關于這方面,筆者目前沒有找到比較權威的解釋,不過我們可以大致推測一下:
首先,我們都知道,由于哈希函數的散列度直接受槽位數量的影響,槽位可用率較低的時候會導致哈希沖突比較嚴重。
因此,哈希函數的擴容閾值必定不能過大,否則擴容前的空閑槽位較少的那段時間哈希沖突會比較嚴重,并且 ThreadLocalMap 采用線性探測的方式解決哈希沖突,此時相比起 HashMap 使用的拉鏈法會更加消耗性能,所以 ThreadLocalMap 的負載系數起碼要小于 HashMap 的 0.75。 不過,如果設置的過小,又會導致槽位閑置率過高,浪費內存,因此起碼得大于 0.5。綜合考慮一下,2/3 就是一個比較合適的值。
6. 獲取值?
我們看看 ThreadLocal 的 get 方法,整個流程大概分為三步:
- 先確認線程里面的 ThreadLocalMap 是否初始化,如果未初始化則進行初始化,如果已初始化則開始進行查找;
- 通過哈希值計算得到下標,如果下標對應的槽位為空,或者直接找到了目標數據,則直接返回,否則說明存在哈希沖突,需要進行線性探測;
- 從指定下標開始向后探測:
- 如果找到了目標數據,則中斷探測,直接返回數據;
- 如果槽位不為空,且數據已經失效,則進行清理;
- 如果槽位為空或者已沒有下一個可遍歷的槽位,說明沒有要查找的數據,直接返回空。
public T get() {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);// 如果已經初始化,則獲取值if (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null) {@SuppressWarnings("unchecked")T result = (T)e.value;return result;}}// 如果尚未初始化,則進行初始化return setInitialValue();
}private Entry getEntry(ThreadLocal<?> key) {// 計算下標,獲取值int i = key.threadLocalHashCode & (table.length - 1);Entry e = table[i];// 如果能直接獲取到值,或者確認沒有值,直接返回if (e != null && e.get() == key)return e;// 否則說明存在哈希沖突,需要進行線性探測elsereturn getEntryAfterMiss(key, i, e);
}private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {Entry[] tab = table;int len = tab.length;// 線性探測,從指定下標開始遍歷槽位,直到找到為止while (e != null) {ThreadLocal<?> k = e.get();if (k == key)return e;if (k == null)// 如果發現槽位中的數據失效,則進行清理expungeStaleEntry(i);elsei = nextIndex(i, len);e = tab[i];}return null;
}
7. 數據的初始化?
這里我們關注一下 ThreadLocalMap 中數據的初始化。在最開始的時候,由于每個線程?threadLocals?和?inheritableThreadLocals?兩個變量都未初始化,此時就會在?setInitialValue?方法里面創建?ThreadLocalMap?實例,并對數據進行初始化:
private T setInitialValue() {// 為 ThreadLocal 設置初始值,// 不重寫 initialValue 方法的話默認都是 nullT value = initialValue();Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null) {map.set(this, value);} else {createMap(t, value);}// 注冊到 TerminatingThreadLocal 注冊表if (this instanceof TerminatingThreadLocal) {TerminatingThreadLocal.register((TerminatingThreadLocal<?>) this);}return value;
}
簡單的來說,這里先確認線程的?threadLocals?是否已經初始化,若沒有則初始化一個?ThreadLocalMap,并調用?initialValue?方法獲取并添加一個初始值。這里的 initialValue 方法是一個留給子類重寫的鉤子方法,默認返回的是一個 null。
中的腳本(Script))



:MCP錯誤處理與日志系統)

精講 卡碼網117.網站構建 卡碼網47.參加科學大會)


)
特征檢測-----在圖像中查找最顯著的角點函數goodFeaturesToTrack())








![BUUCTF-[GWCTF 2019]re3](http://pic.xiahunao.cn/BUUCTF-[GWCTF 2019]re3)