1. 引言
大型語言模型(Large Language Models,簡稱LLM)如GPT-4、Claude和LLaMA等近年來取得了突破性進展,能夠生成流暢自然的文本、回答復雜問題、甚至編寫代碼。但這些模型究竟是如何理解人類語言的?它們如何表示和處理單詞?本文將深入探討大模型的基礎機制——詞嵌入向量,揭示AI是如何"理解"文字的。
2. 從符號到向量:語言表示的基礎
2.1 詞向量的概念
在傳統自然語言處理中,單詞通常被表示為獨熱編碼(One-Hot Encoding)——一個只有一個元素為1,其余都為0的稀疏向量。例如,在一個有10000個單詞的詞匯表中,"蘋果"這個詞可能被表示為一個長度為10000的向量,其中只有第345位是1,其余都是0。
然而,這種表示方法存在明顯缺陷:向量維度過高且稀疏,更重要的是,無法表達單詞之間的語義關系。例如,"蘋果"和"梨"在語義上很接近,但它們的獨熱編碼向量可能完全不同,計算相似度時得到的結果是0。
2.2 詞嵌入向量的基本原理
詞嵌入向量(Word Embedding)解決了上述問題,它是"通過將離散空間向連續空間映射后得到的詞向量"。每個單詞被映射到一個低維度(通常為幾百維)的稠密向量空間中,這些向量捕捉了單詞的語義和句法特性。
詞嵌入向量的核心優勢在于:語義上相似的詞在向量空間中的距離也相近。這種特性使得模型能夠理解詞與詞之間的關系,從而更好地處理自然語言。
3. 詞嵌入向量的實現方式
3.1 Word2Vec
Word2Vec是由Google在2013年開源的詞嵌入技術,它通過兩種模型來學習詞向量:
- CBOW (Continuous Bag of Words):使用上下文預測目標詞。給定一個詞的上下文(周圍的詞),預測這個詞是什么。
- Skip-gram:與CBOW相反,使用目標詞預測上下文。給定一個詞,預測它周圍可能出現的詞。

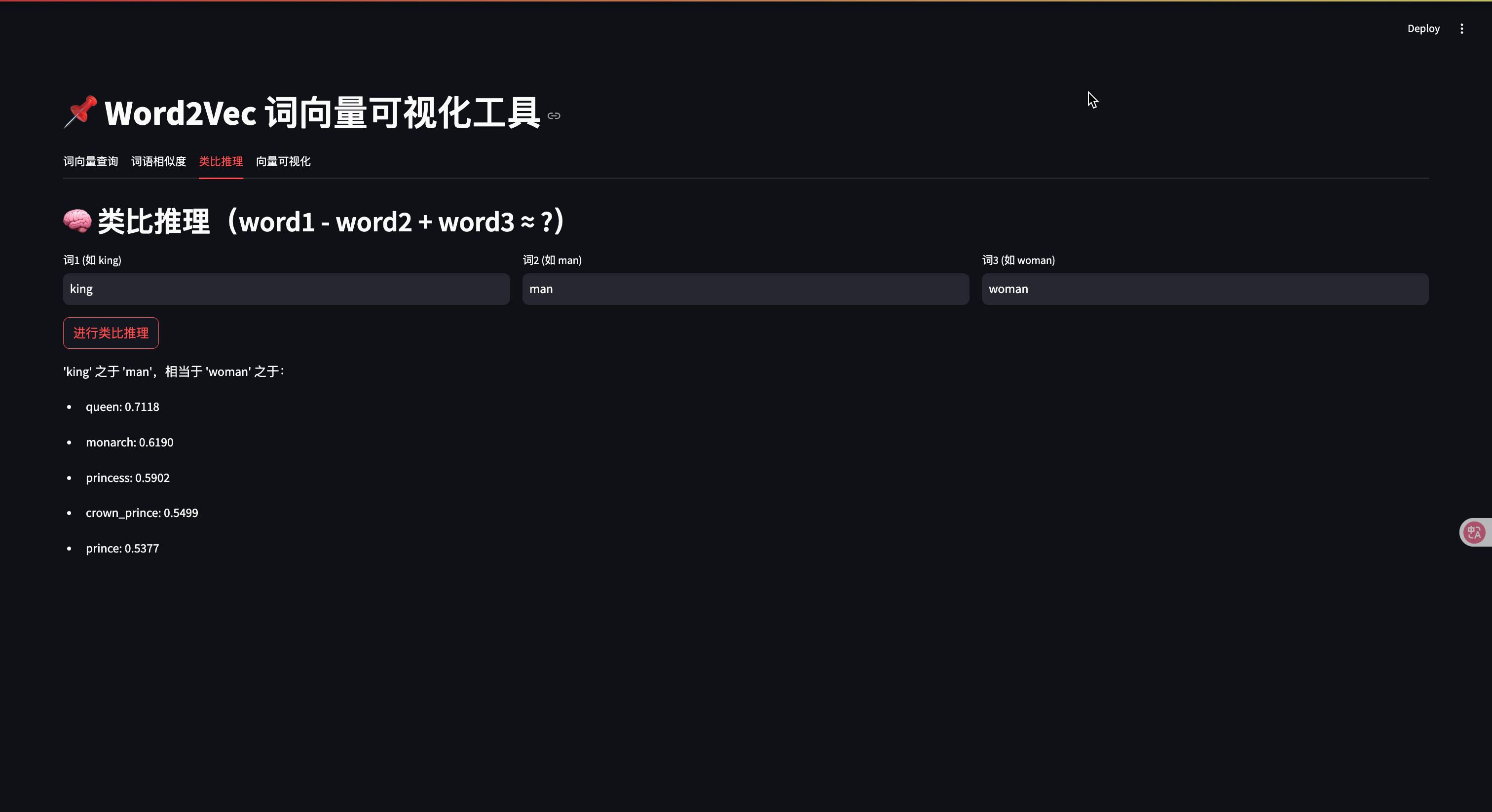
Word2Vec能夠捕捉到豐富的語義關系,最著名的例子是向量的代數運算能夠表示語義關系:
vector('國王') - vector('男人') + vector('女人') ≈ vector('女王')
vector('巴黎') - vector('法國') + vector('意大利') ≈ vector('羅馬')
這種現象表明,詞嵌入不僅能夠捕捉相似性,還能捕捉詞匯之間的語義關系和類比關系。
####案例代碼
import streamlit as st
import pandas as pd
from sklearn.decomposition import PCA
from openai import OpenAI
from dotenv import load_dotenv
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib# 指定中文字體路徑(macOS)
font_path = "/System/Library/Fonts/PingFang.ttc" # macOS 中文字體
my_font = fm.FontProperties(fname=font_path)# 設置 matplotlib 默認字體
matplotlib.rcParams['font.family'] = my_font.get_name()
matplotlib.rcParams['axes.unicode_minus'] = False
# 加載環境變量
load_dotenv()# OpenAI 客戶端
client = OpenAI(
)# 嵌入生成函數
def get_word_embeddings(words, model="text-embedding-3-large"):try:response = client.embeddings.create(input=words, model=model)return [item.embedding for item in response.data]except Exception as e:st.error(f"Error occurred: {e}")return []# 主界面
st.title("🧠 詞嵌入向量空間可視化")st.write("輸入一些單詞,看看它們在二維空間里的分布!")# 文本輸入
user_input = st.text_area("請輸入單詞(每行一個單詞):","國王\n皇后\n男人\n女人\n貓\n狗\n蘋果\n橙子"
)if user_input:words = [w.strip() for w in user_input.split("\n") if w.strip()]if len(words) < 2:st.warning("請輸入至少兩個單詞!")else:with st.spinner("生成詞嵌入向量中..."):embeddings = get_word_embeddings(words)if embeddings:st.success("嵌入向量生成成功!")st.write(f"每個單詞的向量維度:**{len(embeddings[0])}**")# 用 PCA 降到 2Dpca = PCA(n_components=2)reduced = pca.fit_transform(embeddings)# 轉成 DataFramedf = pd.DataFrame(reduced, columns=["x", "y"])df["word"] = words# 畫出散點圖fig, ax = plt.subplots(figsize=(10, 6))ax.scatter(df["x"], df["y"], color="blue")# 在點旁邊標注單詞for i, word in enumerate(df["word"]):ax.text(df["x"][i]+0.01, df["y"][i]+0.01, word, fontsize=12)ax.set_title("詞嵌入二維空間可視化")ax.set_xlabel("主成分1 (PCA1)")ax.set_ylabel("主成分2 (PCA2)")st.pyplot(fig)# 圖的解釋st.subheader("圖表解釋 🧠")st.markdown("""- 每個點代表一個單詞在嵌入空間中的位置。- **相近的單詞**,在二維平面上會靠得更近,表示語義相似。- 方向和距離代表潛在的語義關系,比如“國王-男人+女人≈皇后”。- 注意:因為是降維展示,實際高維特征被簡化了,但依然可以直觀感知單詞間的語義結構。""")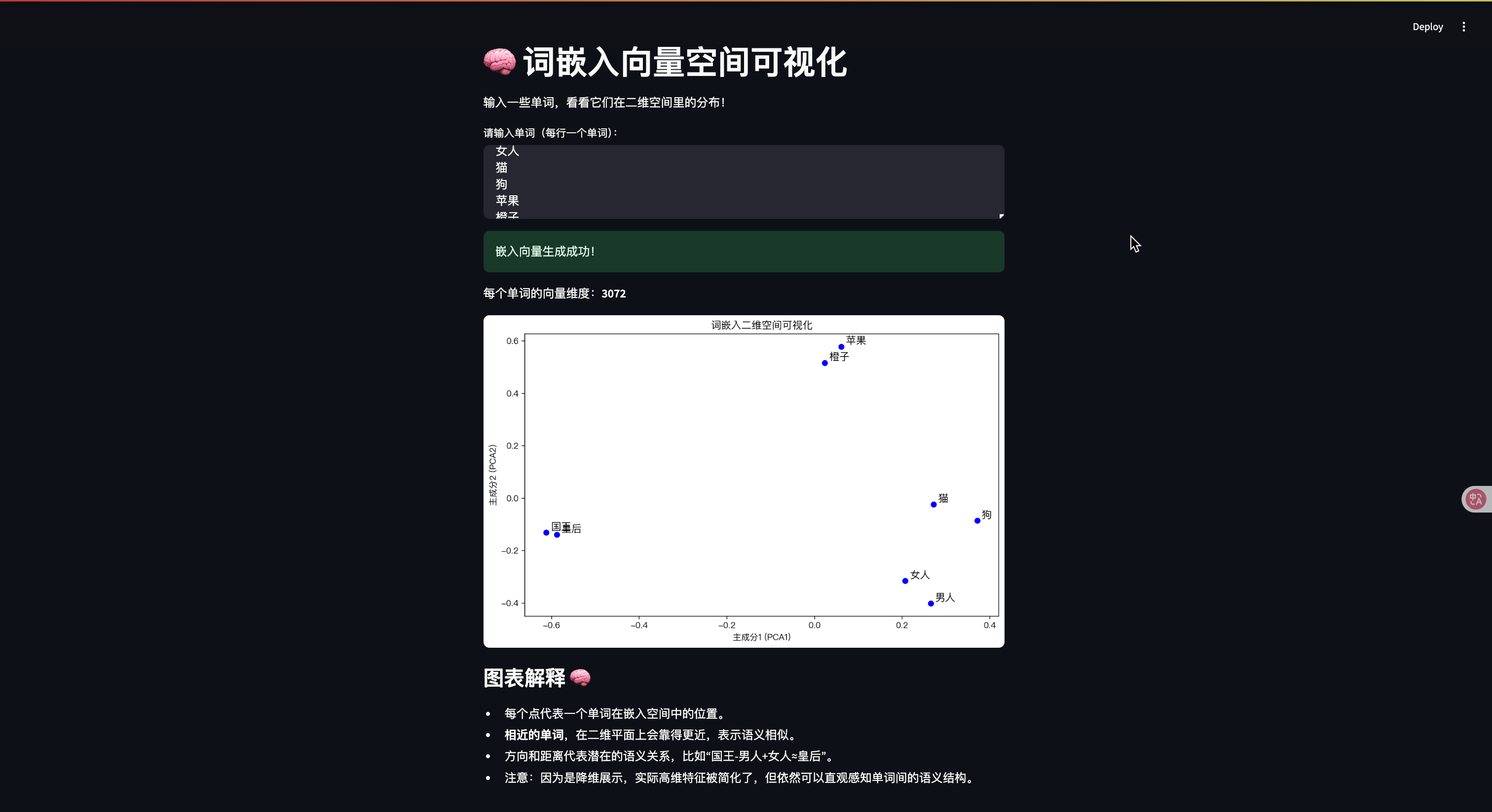
3.2 GloVe
GloVe (Global Vectors for Word Representation) 是由斯坦福大學開發的另一種流行的詞嵌入模型。與Word2Vec不同,GloVe結合了全局矩陣分解和局部上下文窗口方法的優點。
GloVe基于共現矩陣——記錄每個單詞與其上下文詞的共現頻率,然后通過矩陣分解技術學習詞向量。這使得GloVe能夠更好地捕捉全局統計信息。
3.3 FastText
FastText是Facebook AI Research開發的一種改進型詞嵌入模型。它的主要創新在于將單詞分解為子詞(subword)單元,通常是字符n-gram。
例如,單詞"apple"的3-gram表示為:<ap, app, ppl, ple, le>。這種方法的優勢在于:
- 能夠處理詞匯表外的詞(OOV問題)
- 對拼寫錯誤有一定的容忍度
- 特別適合處理形態豐富的語言(如芬蘭語、土耳其語等)
4. 大模型中的詞嵌入技術
在現代大型語言模型(如BERT、GPT系列、LLaMA等)中,詞嵌入技術得到了進一步的發展和應用。
4.1 上下文相關的詞嵌入
傳統的Word2Vec等模型為每個詞生成一個固定的向量,而不考慮上下文。這意味著多義詞(如"蘋果"可以指水果或公司)只有一個表示。
而現代大模型采用了上下文相關的詞嵌入技術。例如,BERT模型會根據詞出現的上下文生成不同的表示:
"我喜歡吃蘋果" → vector("蘋果") 表示水果意義
"蘋果公司發布新產品" → vector("蘋果") 表示公司意義
這種動態表示極大地提高了模型理解語言的能力。

4.2 Transformer中的詞嵌入
在Transformer架構(現代大模型的基礎)中,詞嵌入通常包含三個部分:
- 詞嵌入 (Token Embeddings):單詞本身的向量表示
- 位置嵌入 (Positional Embeddings):表示單詞在序列中的位置
- 段嵌入 (Segment Embeddings):用于區分不同段落或句子(主要用于BERT等模型)
這三種嵌入向量相加后,形成了輸入Transformer各層的初始表示。位置嵌入特別重要,因為它使模型能夠了解單詞的順序,這對于理解語言至關重要。
5. 大模型中的Token化過程
大模型處理文本的第一步是將輸入分解為"token"。這些token可以是完整單詞、子詞單元(subword units)或單個字符。
5.1 BPE算法
字節對編碼(Byte Pair Encoding, BPE)是GPT等模型常用的分詞算法。BPE首先將每個單詞分解為字符序列,然后反復合并最常見的字符對,形成新的子詞單元。
BPE的優勢在于能夠平衡詞匯表大小和表示能力,有效處理罕見詞和復合詞。
例如,英文單詞"unhappiness"可能被分解為:["un", "happiness"]或["un", "happy", "ness"],而中文"人工智能"可能被分解為:["人工", "智能"]。
5.2 SentencePiece和WordPiece
SentencePiece和WordPiece是其他常用的子詞分詞算法,它們與BPE類似,但在細節實現上有所不同。這些算法都允許模型處理開放詞匯表,提高了模型的靈活性和泛化能力。
6. 詞嵌入向量的特性與誤區
6.1 重要特性
- 語義相似性:語義相近的詞在向量空間中距離較近
- 類比關系:向量間的關系可以表示語義關系
- 降維可視化:通過t-SNE等技術降維后,可以直觀地看到詞匯聚類
6.2 常見誤區
注意點: 詞嵌入向量并不直接表示語義,而是詞與詞之間語義的相似度。因此,不必去糾結每個向量值到底代表什么意思。
許多人誤以為詞向量的每個維度對應某種具體的語義屬性(如第一維表示性別,第二維表示生物/非生物等)。實際上,詞嵌入空間通常是高度糾纏的,單個維度很少有明確的語義解釋。
詞嵌入是在特定任務和數據集上學習得到的分布式表示,它們捕捉的是詞與詞之間的相對關系,而非絕對語義。
7. 詞嵌入向量的實際應用
詞嵌入技術被廣泛應用于各種自然語言處理任務:
- 文本分類:通過詞向量表示文檔,進行情感分析、主題分類等
- 命名實體識別:識別文本中的人名、地名、組織名等專有名詞
- 機器翻譯:作為神經機器翻譯系統的基礎表示
- 問答系統:幫助理解問題和生成答案
- 文本相似度計算:判斷兩段文本的語義相似程度
7.1 實戰案例:使用Python實現詞向量計算
下面我們通過一個實際案例,展示如何使用Python和預訓練模型來計算和使用詞向量。我們將使用流行的Gensim庫和預訓練的Word2Vec模型來演示:
import streamlit as st
import gensim.downloader as api
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib# 指定中文字體路徑(macOS)
font_path = "/System/Library/Fonts/PingFang.ttc"
my_font = fm.FontProperties(fname=font_path)# 設置 matplotlib 中文字體和負號顯示
matplotlib.rcParams['font.family'] = my_font.get_name()
matplotlib.rcParams['axes.unicode_minus'] = False# 設置頁面配置
st.set_page_config(page_title="Word2Vec 詞向量可視化", layout="wide")@st.cache_resource(show_spinner=True)
def load_model():return api.load('word2vec-google-news-300')# 加載模型
model = load_model()st.title("📌 Word2Vec 詞向量可視化工具")# 分頁
tab1, tab2, tab3, tab4 = st.tabs(["詞向量查詢", "詞語相似度", "類比推理", "向量可視化"])# --- 1. 詞向量查詢 ---
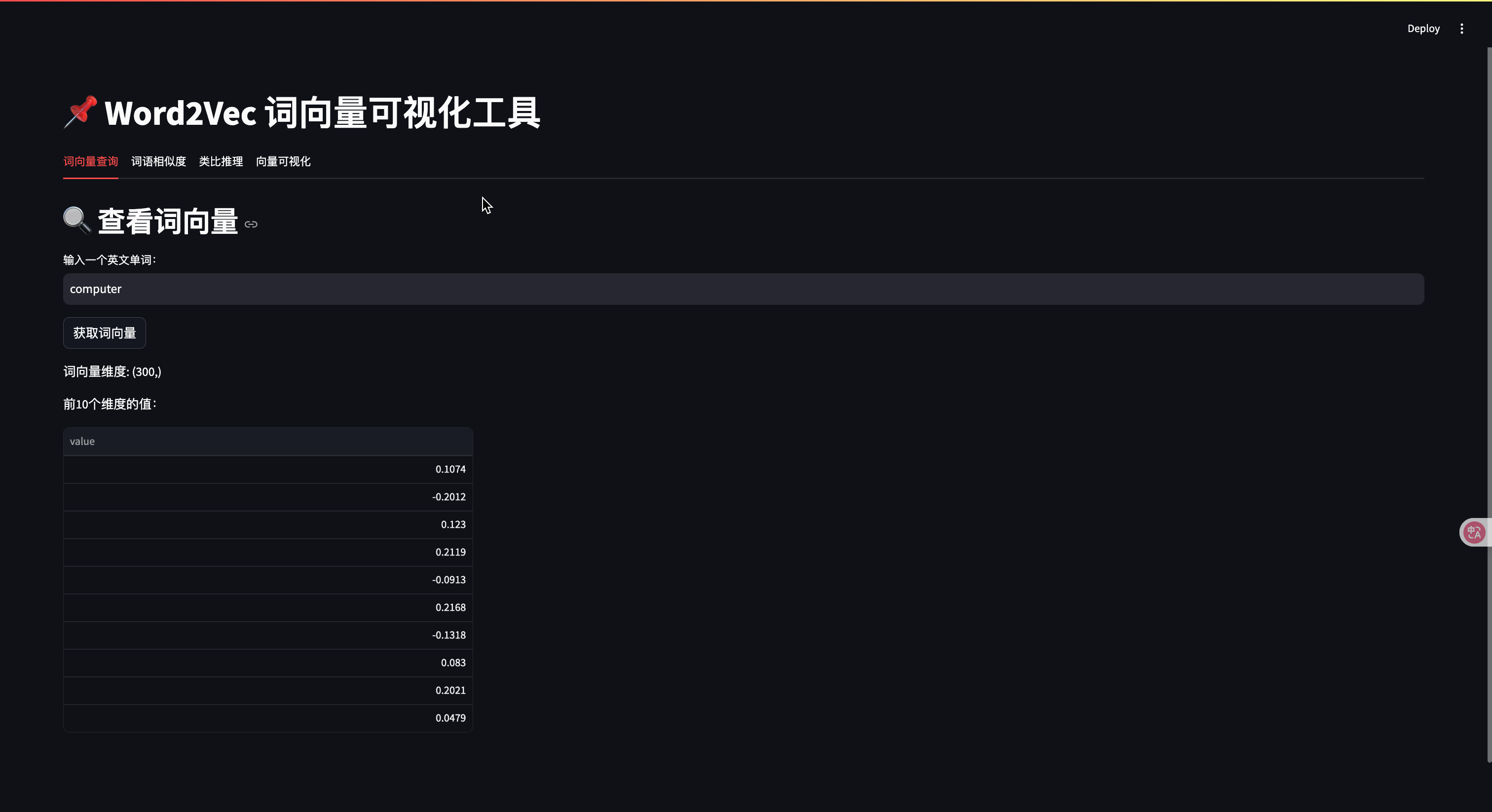
with tab1:st.header("🔍 查看詞向量")word = st.text_input("輸入一個英文單詞:", "computer")if st.button("獲取詞向量"):if word in model:vec = model[word]st.write(f"詞向量維度: {vec.shape}")st.write("前10個維度的值:", vec[:10])else:st.error("詞不在詞匯表中,請嘗試其他單詞")# --- 2. 詞語相似度 ---
with tab2:st.header("🔗 計算詞語相似度")col1, col2 = st.columns(2)with col1:word1 = st.text_input("單詞1", "computer")with col2:word2 = st.text_input("單詞2", "laptop")if st.button("計算相似度"):if word1 in model and word2 in model:sim = model.similarity(word1, word2)st.success(f"'{word1}' 和 '{word2}' 的余弦相似度為:{sim:.4f}")else:st.error("一個或兩個詞不在詞匯表中")# --- 3. 類比推理 ---
with tab3:st.header("🧠 類比推理(word1 - word2 + word3 ≈ ?)")col1, col2, col3 = st.columns(3)with col1:w1 = st.text_input("詞1 (如 king)", "king")with col2:w2 = st.text_input("詞2 (如 man)", "man")with col3:w3 = st.text_input("詞3 (如 woman)", "woman")if st.button("進行類比推理"):try:result = model.most_similar(positive=[w3, w1], negative=[w2], topn=5)st.write(f"'{w1}' 之于 '{w2}',相當于 '{w3}' 之于:")for word, score in result:st.write(f"- {word}: {score:.4f}")except KeyError as e:st.error(f"詞匯錯誤: {e}")# --- 4. 向量可視化 ---
with tab4:st.header("📈 詞向量可視化(PCA降維)")words_input = st.text_area("輸入一組英文單詞,用逗號分隔(如:king,queen,man,woman,computer)","king, queen, man, woman, computer, banana, apple, orange, prince, princess")raw_words = [w.strip() for w in words_input.split(",")]words = [w for w in raw_words if w in model]skipped = [w for w in raw_words if w not in model]if st.button("生成可視化圖像"):if len(words) < 2:st.warning("請至少輸入兩個詞,并確保它們在詞匯表中")else:vectors = [model[w] for w in words]pca = PCA(n_components=2)reduced = pca.fit_transform(vectors)fig, ax = plt.subplots(figsize=(12, 8))ax.set_facecolor("#f9f9f9") # 淺色背景ax.grid(True, linestyle='--', alpha=0.5) # 顯示網格線# 繪制點ax.scatter(reduced[:, 0], reduced[:, 1],color="#1f77b4", s=100, alpha=0.7, edgecolor='k', linewidth=0.5)# 標簽字體大小適配數量font_size = max(8, 14 - len(words) // 5)# 添加標簽for i, word in enumerate(words):ax.annotate(word, xy=(reduced[i, 0], reduced[i, 1]),fontsize=font_size, fontproperties=my_font,xytext=(5, 2), textcoords='offset points',bbox=dict(boxstyle='round,pad=0.3', edgecolor='gray', facecolor='white', alpha=0.6),arrowprops=dict(arrowstyle='->', color='gray', lw=0.5))ax.set_title("📌 Word2Vec 詞向量 2D 可視化 (PCA)", fontsize=18, pad=15)st.pyplot(fig)if skipped:st.info(f"以下詞不在模型詞匯表中,已跳過:{', '.join(skipped)}")# 自動分析生成說明st.subheader("🧠 分析說明")explanation = []# 簡單聚類分析:找最近的詞對from scipy.spatial.distance import euclideanpairs = []for i in range(len(words)):for j in range(i + 1, len(words)):dist = euclidean(reduced[i], reduced[j])pairs.append(((words[i], words[j]), dist))pairs.sort(key=lambda x: x[1])top_similar = pairs[:3] # 取最相近的三個詞對for (w1, w2), dist in top_similar:explanation.append(f"🔹 **{w1}** 和 **{w2}** 在圖中非常接近,表明它們在語義上可能較為相關(距離約為 {dist:.2f})。")# 計算均值中心,找偏離大的詞(即“異類”)center = reduced.mean(axis=0)dists_to_center = [(words[i], euclidean(reduced[i], center)) for i in range(len(words))]dists_to_center.sort(key=lambda x: x[1], reverse=True)outlier_word, max_dist = dists_to_center[0]explanation.append(f"🔸 **{outlier_word}** 與其他詞的平均距離最大(約為 {max_dist:.2f}),可能表示它語義上偏離較遠。")# 輸出說明for line in explanation:st.markdown(line)運行結果示例:
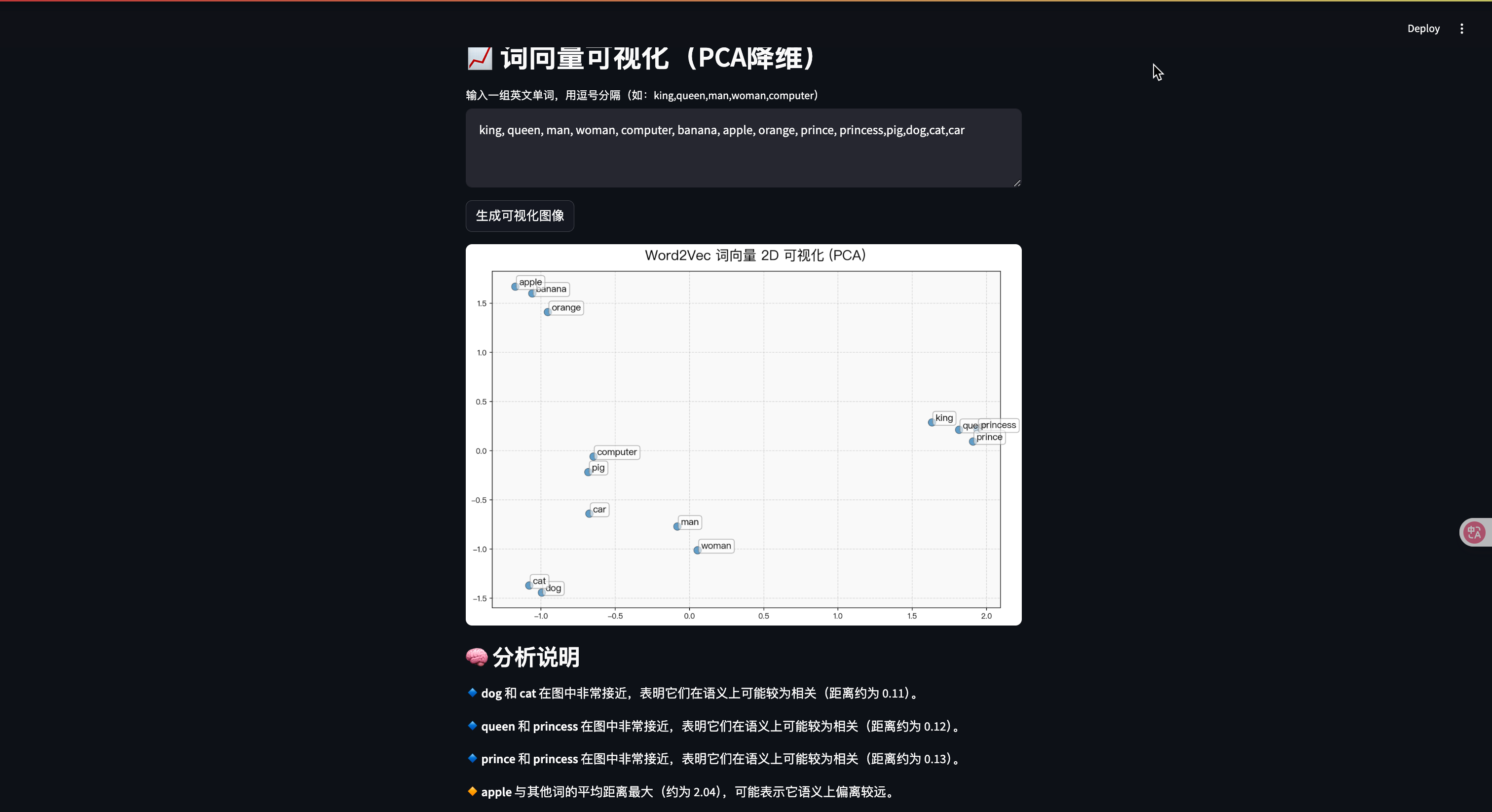
這個案例展示了詞向量的四個核心應用:
- 獲取詞語的向量表示
- 計算詞語之間的語義相似度
- 進行詞向量的代數運算來發現類比關系
- 可視化詞向量空間的語義結構
通過這個例子,我們可以直觀地理解詞嵌入如何捕捉單詞之間的語義關系,以及如何在實際應用中利用這些關系。這種能力是大模型理解自然語言的基礎。
8. 總結與展望
詞嵌入向量技術是大模型理解人類語言的基礎。從最初的Word2Vec到現代Transformer架構中的上下文相關表示,詞嵌入技術不斷發展,使AI能夠更精確地理解和生成自然語言。
未來,詞嵌入技術可能會向以下方向發展:
- 多模態嵌入:將文本、圖像、音頻等不同模態的信息統一表示
- 知識增強型嵌入:融合結構化知識庫信息的詞嵌入
- 更高效的計算方法:降低大模型中詞嵌入計算的資源消耗
- 多語言統一表示:開發能夠跨語言捕捉語義的通用嵌入空間
通過深入理解詞嵌入向量的原理,我們不僅能更好地應用大模型,也能洞察人工智能是如何"思考"的,為未來的AI發展提供思路。










![[C]基礎13.深入理解指針(5)](http://pic.xiahunao.cn/[C]基礎13.深入理解指針(5))



)




