
文章目錄
- 1、首先練習MySQL基本語句的練習
- ①查詢工資高于500或崗位為MANAGER的雇員,同時還要滿足他們的姓名首字母為大寫的J
- ②按照部門號升序而雇員的工資降序排序
- ③使用年薪進行降序排序
- ④顯示工資最高的員工的名字和工作崗位
- ⑤顯示工資高于平均工資的員工信息
- ⑥顯示每個部門的平均工資和最高工資
- ⑦顯示平均工資低于2000的部門號和它的平均工資
- ⑧顯示每種崗位的雇員總數,平均工資
- 2、多表查詢
- ①顯示部門號為10的部門名,員工名和工資
- ②顯示各個員工的姓名,工資,及工資級別
- 3、自連接
- ①顯示員工FORD的上級領導的編號和姓名(mgr是員工領導的編號--empno)
- 4、子查詢
- (1)where子語句的單行子查詢
- ①顯示SMITH同一部門的員工——之和SMITH這一行數據作比較
- (2)where子語句的多行子查詢
- ①in關鍵字:查詢和10號部門的工作崗位相同的雇員的名字,崗位,工資,部門號,但是不包含10自己的
- ②all關鍵字:顯示工資比部門30的所有員工的工資高的員工的姓名、工資和部門號
- ③any關鍵字:顯示工資比部門30的任意員工的工資高的員工的姓名、工資和部門號(包含自己部門的員工)
- (3)where子語句的多列子查詢
- ①案例:查詢和SMITH的部門和崗位完全相同的所有雇員,不含SMITH本人
- (4)from子句中的子查詢
- ①顯示每個高于自己部門平均工資的員工的姓名、部門、工資、平均工資
- ②查找每個部門工資最高的人的姓名、工資、部門、最高工資
- ③顯示每個部門的信息(部門名,編號,地址)和人員數量
- 5、合并查詢
- (1)union關鍵字:進行取兩個結果集的并集,會自動去重。
- 案例:將工資大于2500或職位是MANAGER的人找出來
- (2)union all:取得兩個結果集的并集。當使用該操作符時,不會去掉結果集中的重復行。
- 案例:將工資大于25000或職位是MANAGER的人找出來
1、首先練習MySQL基本語句的練習
語句練習的基礎數據:
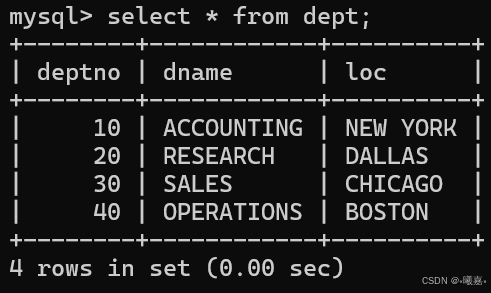
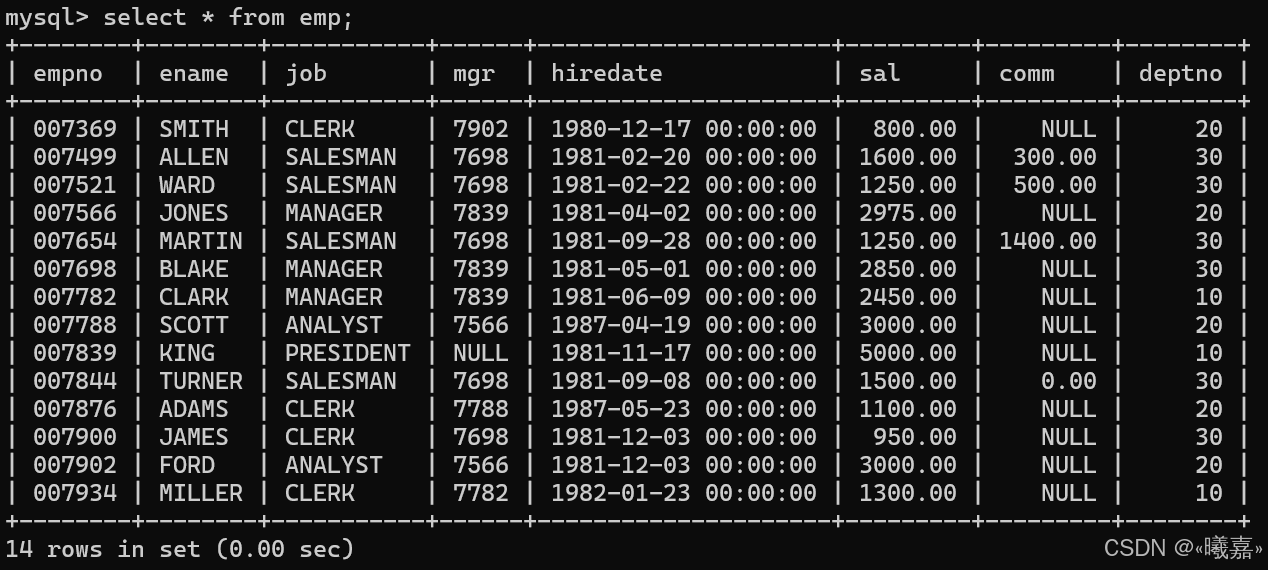
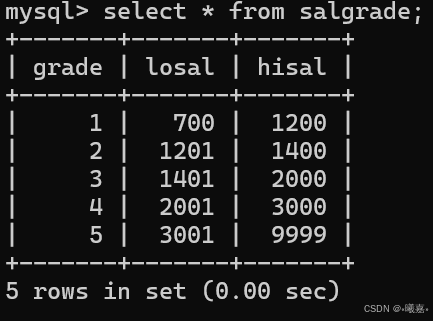
①一個關于公司員工部門工資的數據庫:
創建數據庫:scott。
create database scott;
②三張表:dept:部門表、emp:員工表、salarge:薪資表。
創建三張表,結構數據如下:
①查詢工資高于500或崗位為MANAGER的雇員,同時還要滿足他們的姓名首字母為大寫的J
考察where條件篩選。

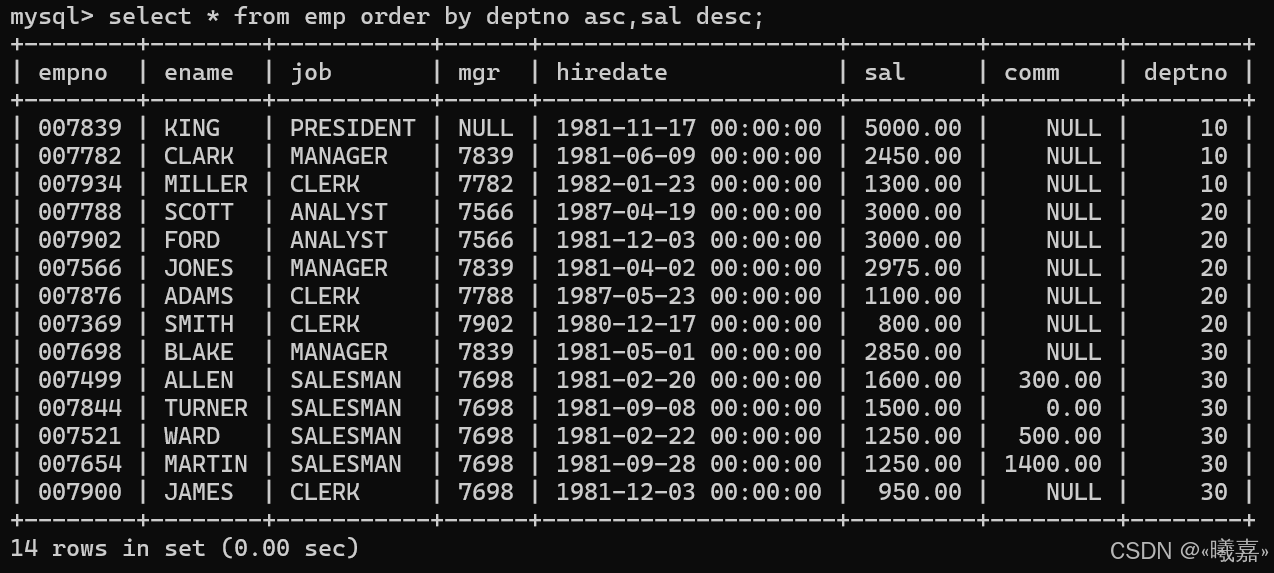
②按照部門號升序而雇員的工資降序排序
考察MySQL排序查詢,下面是先滿足部門號升序,存在相同部門號的,再按照工資降序排序。
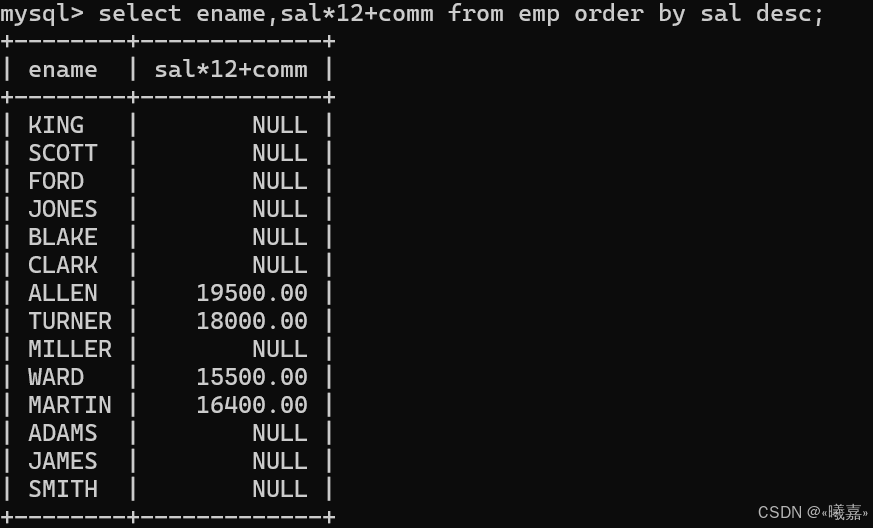
③使用年薪進行降序排序
此處需要注意的是在comm列屬性中的NULL不參與運算,任何數據和NULL運算都是NULL,因此用ifnull判斷。
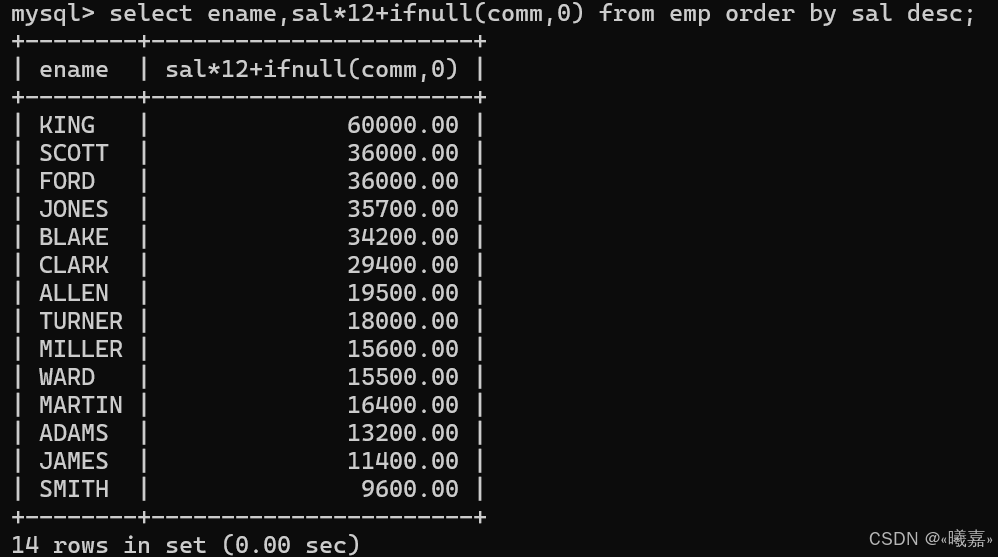
不作判斷就是為NULL:不符合。
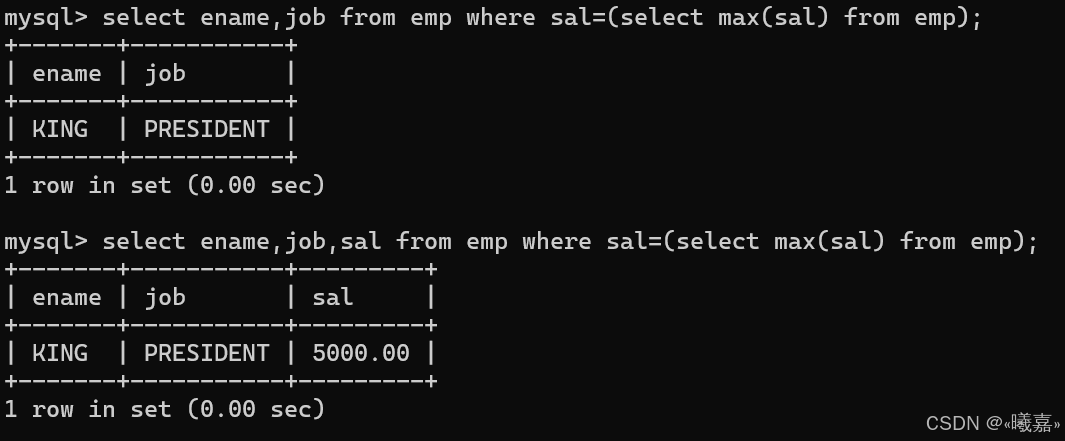
④顯示工資最高的員工的名字和工作崗位
考察數學函數的使用:max()。
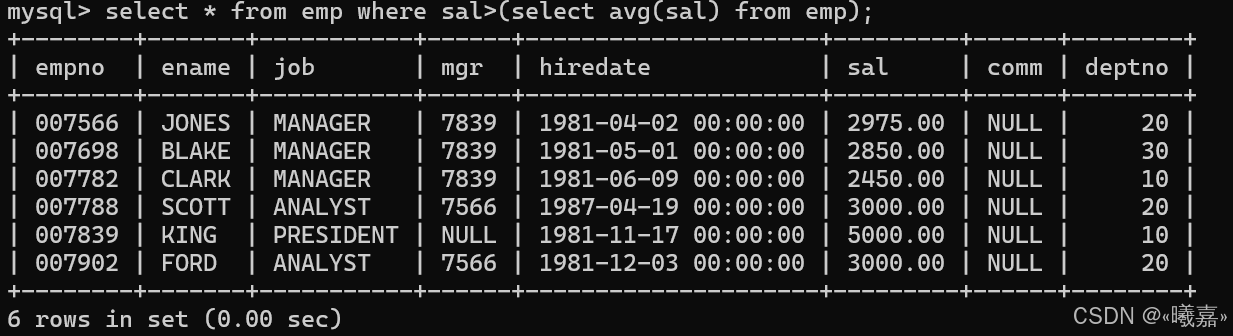
⑤顯示工資高于平均工資的員工信息
先查詢平均工資,然后再查詢工資高于平均工資的員工信息。
⑥顯示每個部門的平均工資和最高工資
先分組然后統計分組后的平均工資和在該部門中的最高工資
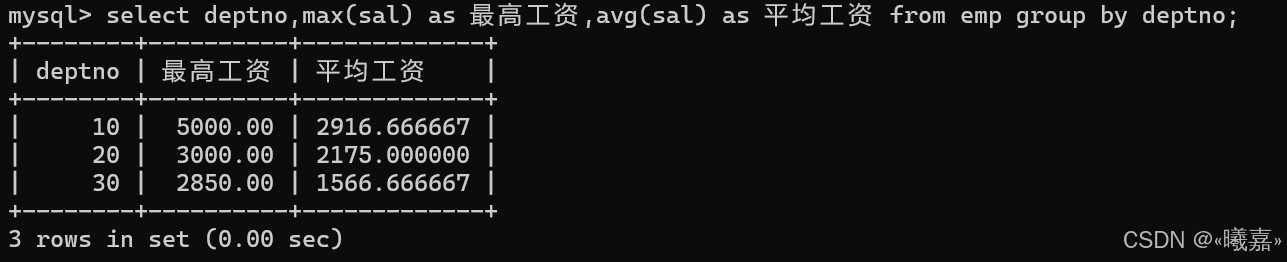
⑦顯示平均工資低于2000的部門號和它的平均工資
即每個部門的平均工資,查詢在對應部門低于平均工資的部門號和該部門的平均工資

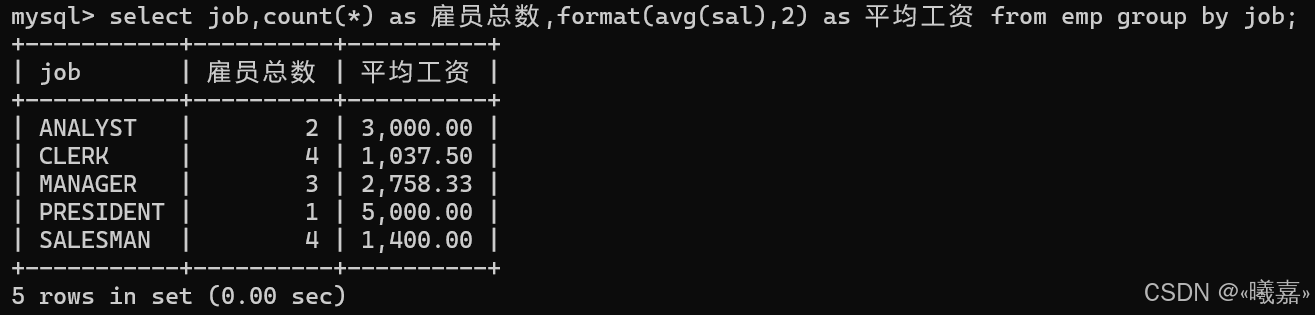
⑧顯示每種崗位的雇員總數,平均工資
看到每個崗位,就想到按崗位分組,然后統計,相同崗位的平均工資
上面是一些基本的查詢語句,接下來主要看一下:多表查詢、自連接、子查詢、合并查詢等相關知識。
2、多表查詢
首先,什么是多表查詢,即在多張表中查看想要的結果。上面來練習的語句中都是單表查詢,而此處的多表查詢實際上也可以看作是單表查詢,只不過是經過組合的一張表,通過笛卡爾積組合后就是一張表了,然后從整個大表中進行篩選即可。
什么是笛卡爾積?有圖簡易說明:
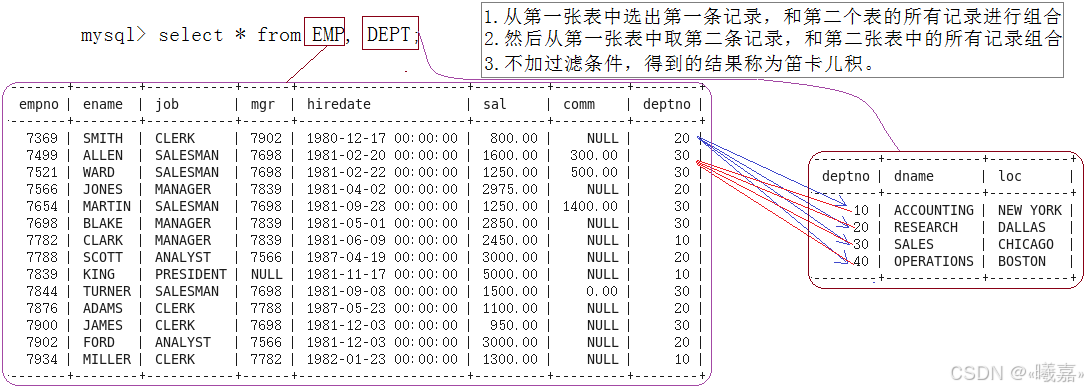
先通過下面語句看到笛卡爾積的現象:可以看到員工表和部門表進行笛卡爾積后得到很多數據,其中有些數據是不符合的,因此需要進行篩選,即我們只要emp表中的deptno = dept表中的deptno字段的記錄。
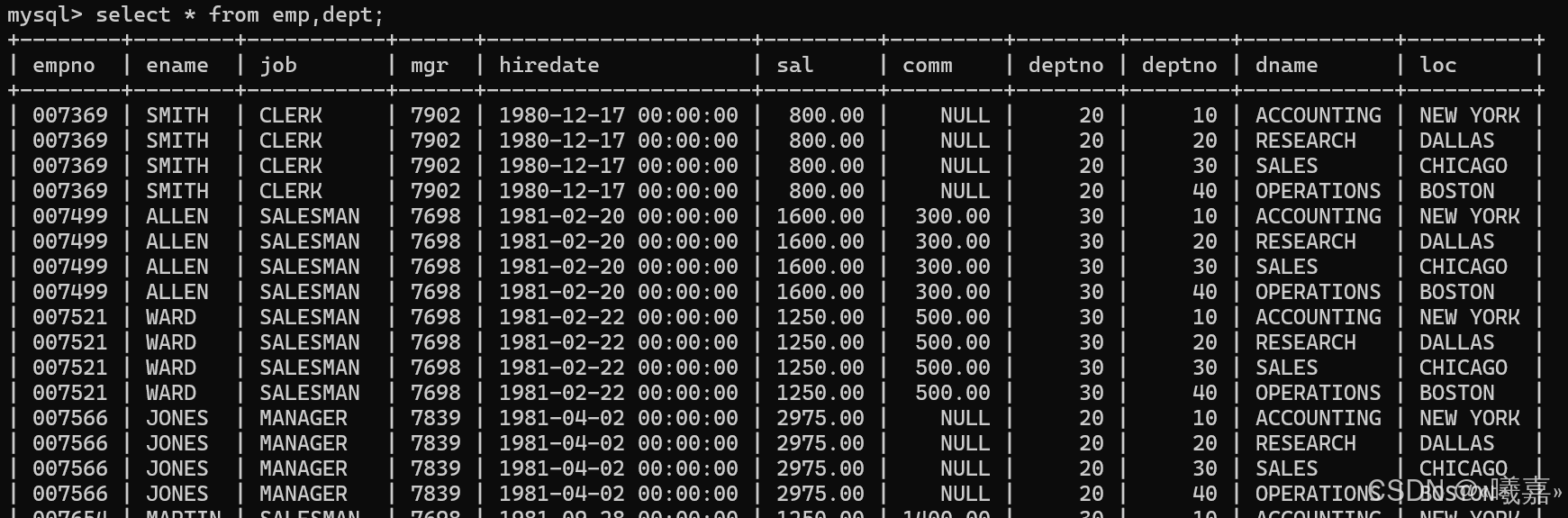
①顯示部門號為10的部門名,員工名和工資
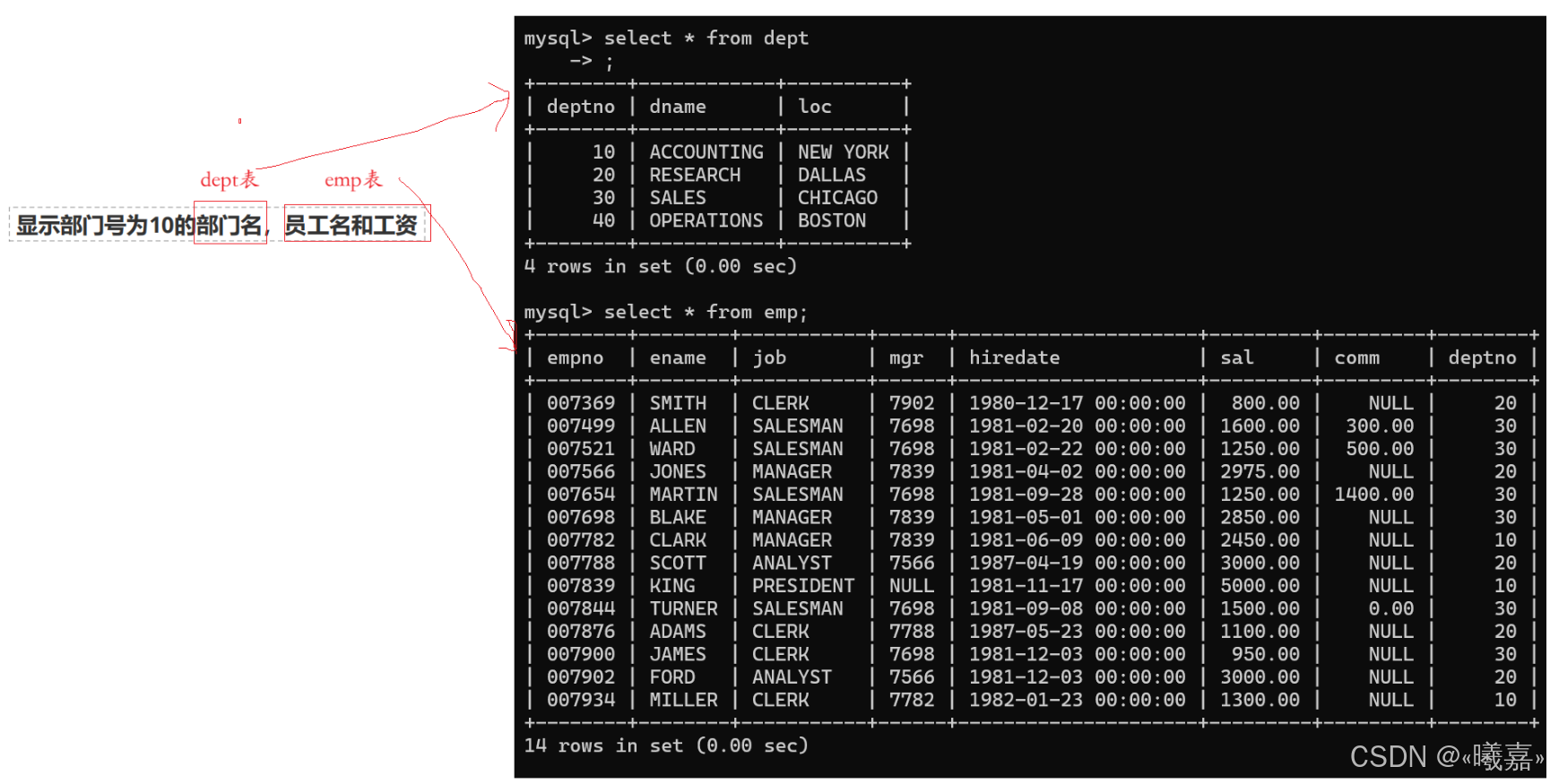

②顯示各個員工的姓名,工資,及工資級別
即姓名和工資屬于一張表,工資級別一張表,笛卡爾積后需要查詢工資在對應范圍的才是正確的:
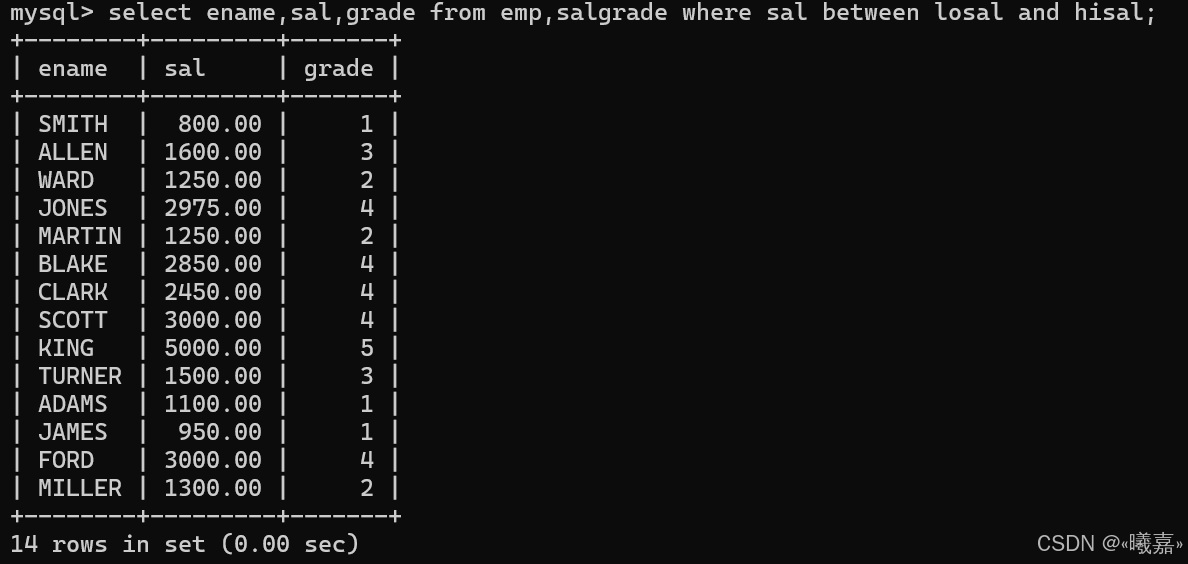
總結:在進行多表查詢的時候,先進行無腦笛卡爾積,然后通過唯一值條件篩選即可,唯一值條件即是能說明多張表組合后,只能有一條數據在符號要求的。
3、自連接
什么是自連接?即在同一張表中作連接查詢,有人會覺得這有真沒意義,通過下面例子說明:
①顯示員工FORD的上級領導的編號和姓名(mgr是員工領導的編號–empno)
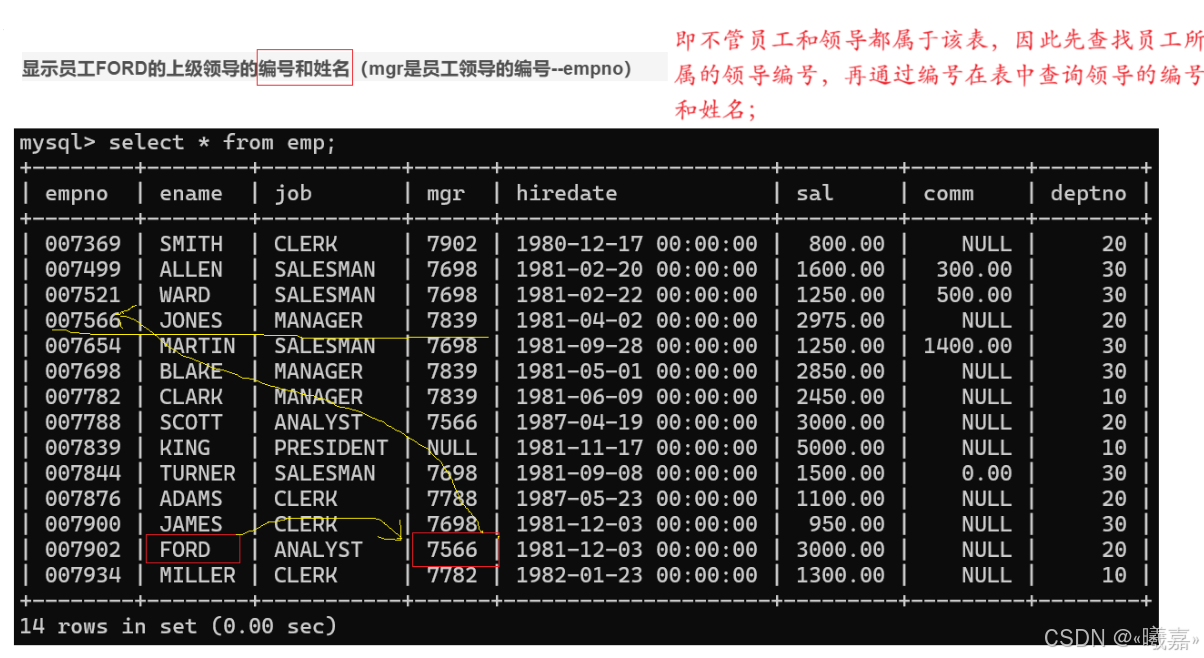

也可以通過給自己表取別名,得到新的表,作笛卡爾積,再進行判斷員工對應的mgr編號和領導表中的empno是否相同:

4、子查詢
子查詢:即嵌入在其他SQL語句中的select語句,也叫嵌套查詢。
(1)where子語句的單行子查詢
即在查詢過程中之和一行數據進行比較查詢,只返回一行數據的子查詢語句,這里的返回一行是字子查詢里面返回的數據是一行。
①顯示SMITH同一部門的員工——之和SMITH這一行數據作比較
即先查詢SMITH所在的部門,再通過部門信息查找和該部門相同的員工信息即可。
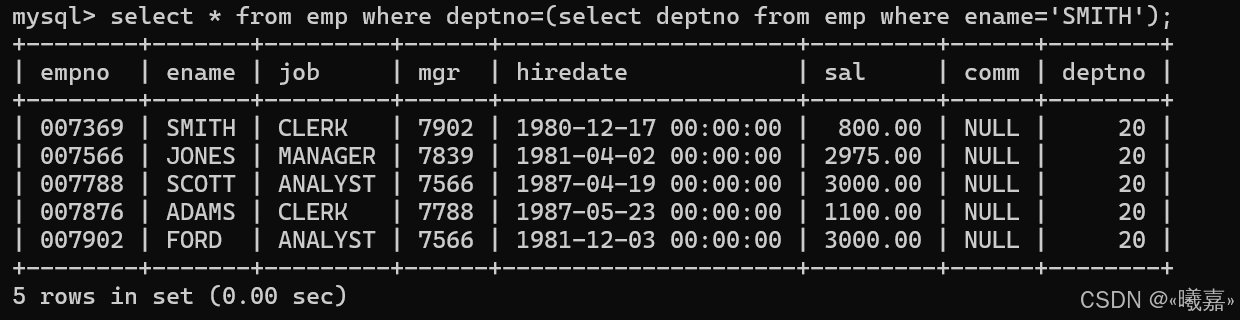
(2)where子語句的多行子查詢
即查詢的時候比較數據不止一行數據,子查詢返回的數據是多行的,也就再次查詢的時候比較就有多行數據
主要用到:in、all、any 查詢關鍵字。
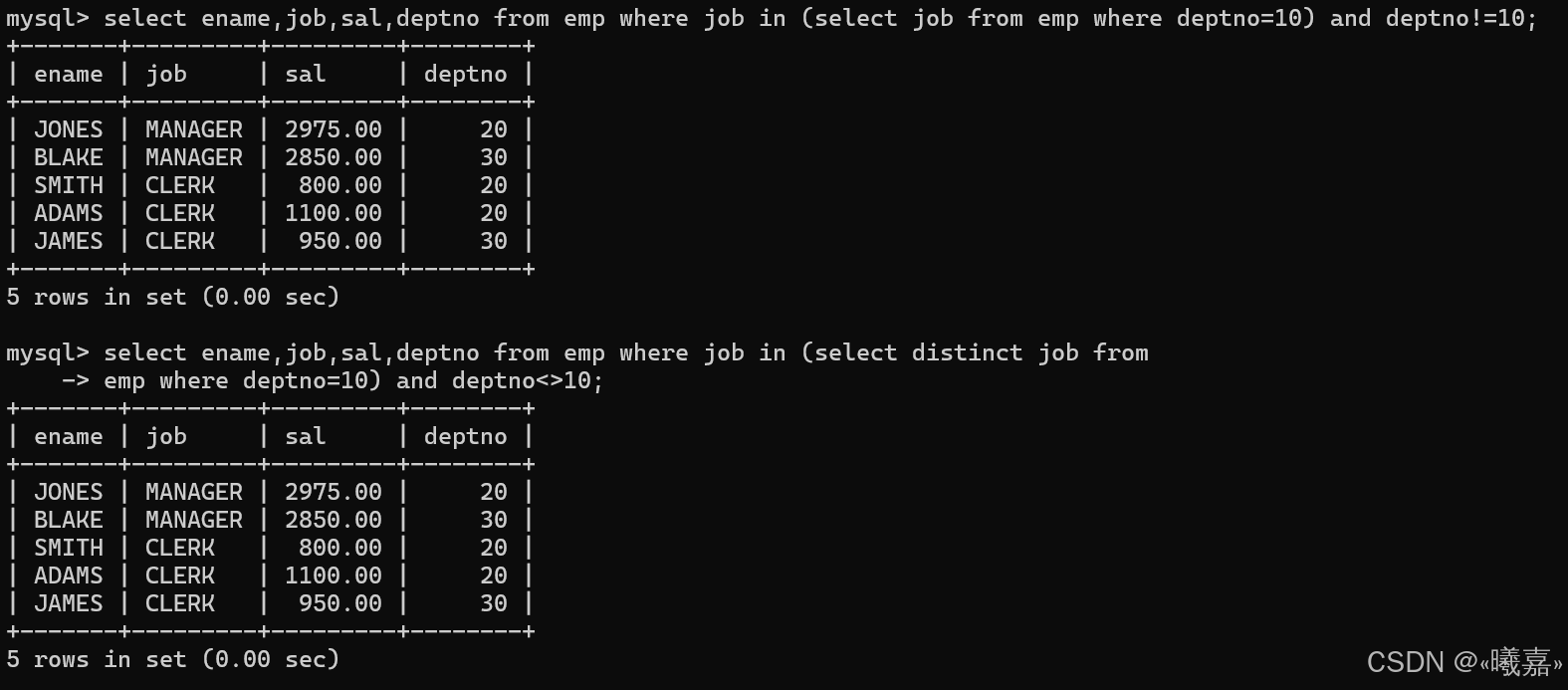
①in關鍵字:查詢和10號部門的工作崗位相同的雇員的名字,崗位,工資,部門號,但是不包含10自己的
即先查10部門的工作崗位有哪些?
然后根據更為查詢對應的員工。看查找的員工的崗位是否在上面查詢的崗位范圍內。

不等于的兩種寫法:!= 或者 <>
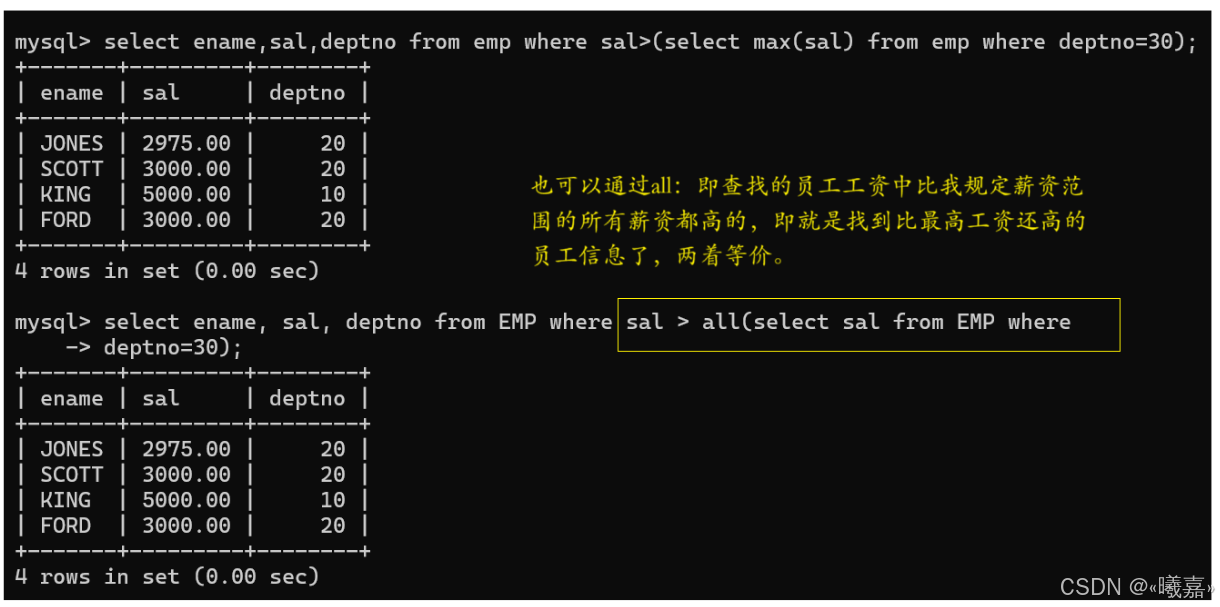
②all關鍵字:顯示工資比部門30的所有員工的工資高的員工的姓名、工資和部門號
可以先查找部門30號的員工中最高的工資,然后在其他部門查找比該工資還高的信息。
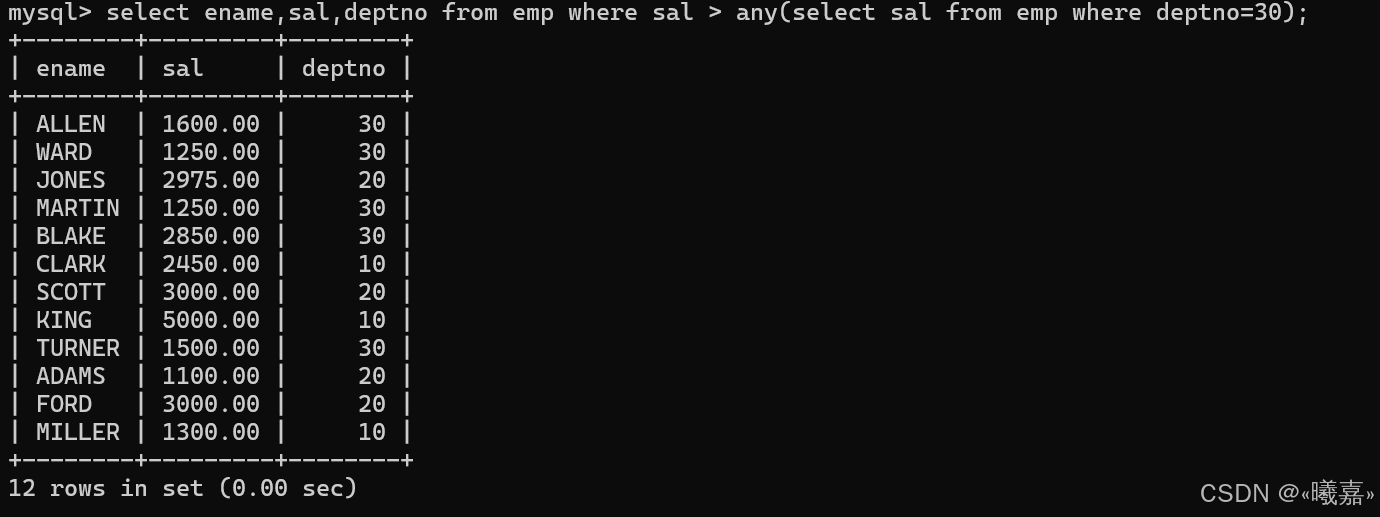
③any關鍵字:顯示工資比部門30的任意員工的工資高的員工的姓名、工資和部門號(包含自己部門的員工)
即這里的比部門30的任意員工工資高,是說只要查找到的員工工資高于部門30里面員工工資其中一個都滿足。
因此先統計部門30的所有員工工資,然后通過any進行查詢。
(3)where子語句的多列子查詢
多列子查詢則是指查詢返回多個列數據的子查詢語句。
①案例:查詢和SMITH的部門和崗位完全相同的所有雇員,不含SMITH本人
這里的多列子查詢就體現在剛開始查詢的結果就存在多列,即部門和崗位,因此叫多列子查詢。
即先查詢到SMITH的部門和崗位。
包含SMITH的時候:

不包含本人的時候:

(4)from子句中的子查詢
從上買此查詢的語句中可以看到都是跟到where子語句中的,作為條件子查詢。而在from子語句后面的,則是通過select查詢出來的作為一張臨時表進行與其他表進行篩選的。下面 通過例子來看:
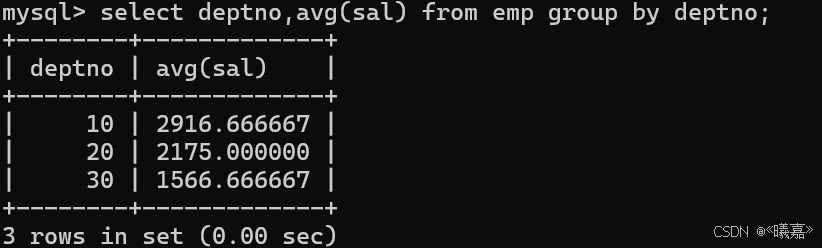
①顯示每個高于自己部門平均工資的員工的姓名、部門、工資、平均工資
即先按部門分組,分別計算出每個部門的平均工資,然后通過查詢表中高于平均工資的員工相關信息。但是真正編寫SQL語句返現執行報錯,因為需要顯示員工姓名,而多個員工會存在在同一個部門,但是又以部門分組,顯然不符合分組的條件,無法分組,因此需要通過from子句的子查詢來完成。
先通過分組得到對應部門的平均工資,然后把該結果作為臨時表,然后和emp表進行一起查詢。
臨時表

②查找每個部門工資最高的人的姓名、工資、部門、最高工資
即和上面一樣需要from子句的查詢,先根據分組得到每個部門的最高工資:
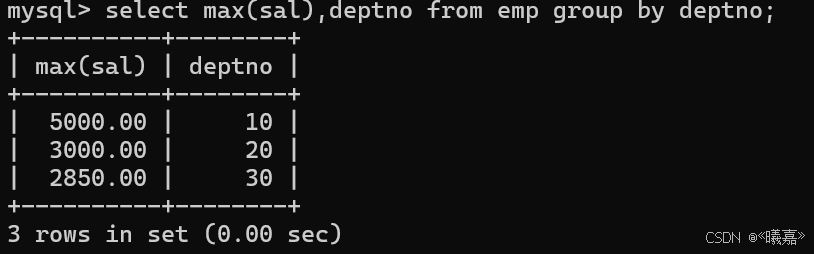
然后和emp表進行結合查詢:

③顯示每個部門的信息(部門名,編號,地址)和人員數量
使用多表查詢的,即員工表和部門表,以部門表進行分組查詢:

使用子查詢:即先對員工表以部門分組進行人員統計
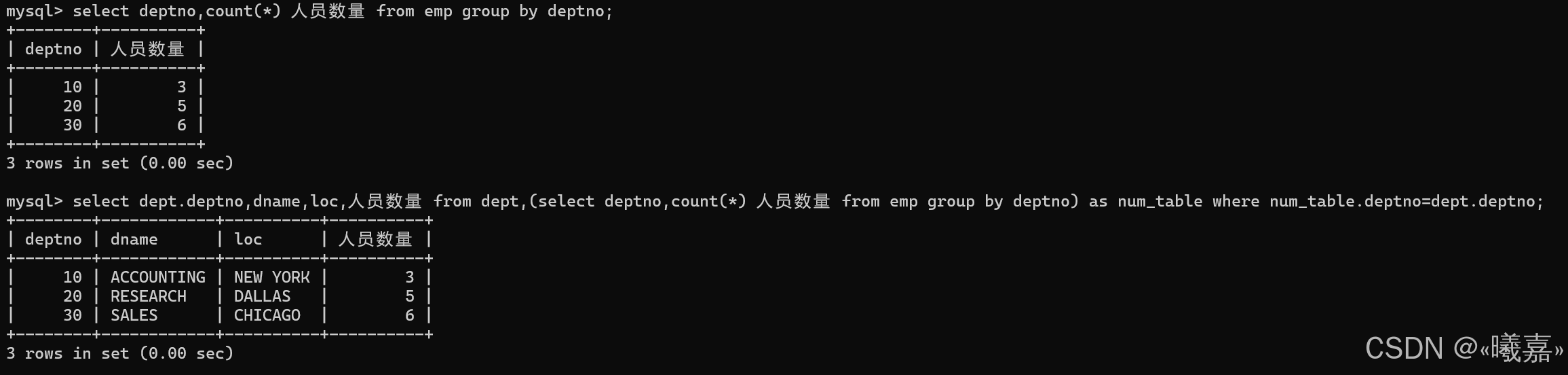
5、合并查詢
即合并多個selecct查詢出來的結果,使用集合操作符號:union,union all關鍵字。
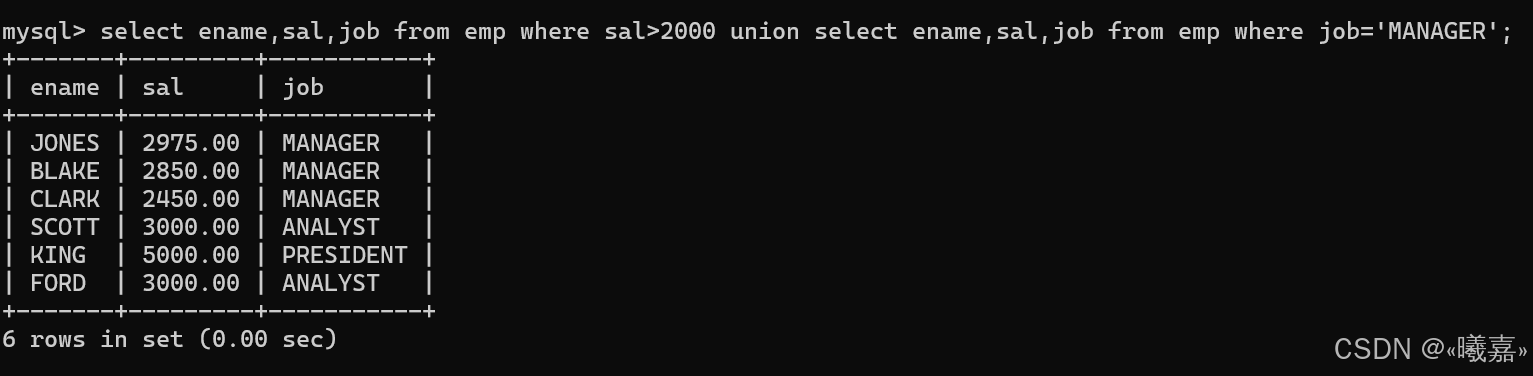
(1)union關鍵字:進行取兩個結果集的并集,會自動去重。
案例:將工資大于2500或職位是MANAGER的人找出來
使用子查詢:
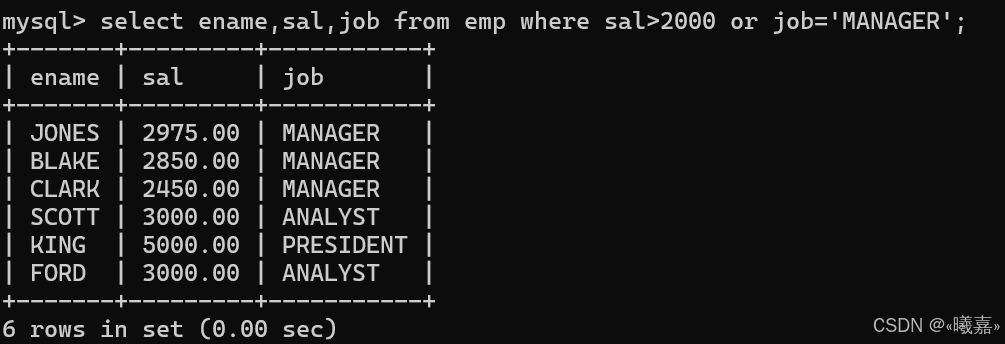
使用union取并集:必須保證兩張表的屬性列一樣,數量一樣才可以合并。
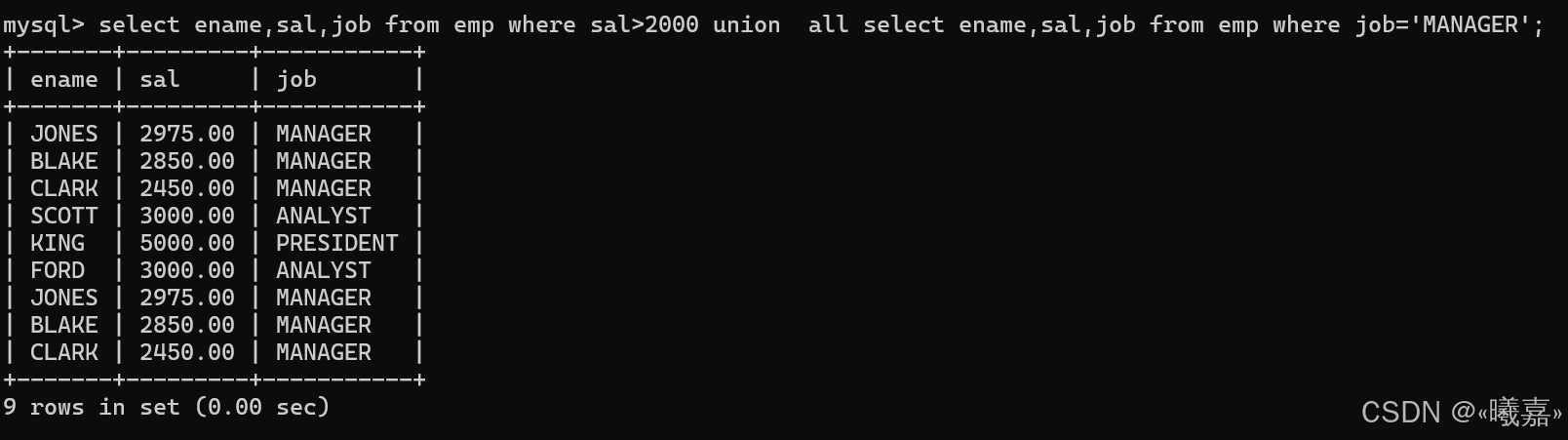
(2)union all:取得兩個結果集的并集。當使用該操作符時,不會去掉結果集中的重復行。
案例:將工資大于25000或職位是MANAGER的人找出來
即沒有去重的數據:union
靜態頁面抓取實戰:requests庫請求頭配置與反反爬策略詳解)









)







