一、生成式人工智能概述
生成式人工智能(Generative Artificial Intelligence)是一種先進的技術,能夠生成多種類型的內容,包括文本、圖像、音頻以及合成數據等。其用戶界面的便捷性極大地推動了其廣泛應用,用戶僅需在幾秒鐘內即可創建出高質量的文本、圖像和視頻內容。生成式人工智能作為機器學習的一個重要子集,其模型通過學習海量數據中隱藏的復雜模式統計,從而實現對自然語言的深入理解。例如,研究人員在訓練大型語言模型時,往往需要花費數周甚至數月的時間,借助強大的計算能力,使模型能夠深入理解自然語言的內在規律和結構。
二、大型語言模型的用例
大型語言模型(LLMs)是設計用于理解和生成類似人類文本的先進人工智能模型。它們在大量文本數據上進行訓練,以學習人類語言的結構和模式。LLMs的應用范圍遠遠超出聊天任務。雖然聊天機器人已經引起了廣泛關注,但LLMs在下一個詞預測方面表現出色,這是各種能力的基礎。LLMs的一些常見用例包括:
- 文本摘要:能夠將長篇文本內容進行壓縮,提取關鍵信息,生成簡潔明了的摘要,廣泛應用于新聞報道、學術論文等領域。
- 翻譯文本:可以將一種語言的文本轉換為另一種語言,甚至可以將文本轉換為代碼,為跨語言交流和編程提供了極大的便利。
- 文章生成:根據給定的主題或關鍵詞,自動生成完整的文章,幫助內容創作者快速生成初稿,提高創作效率。
- 信息提取:從大量文本中提取特定信息,如人名、地名、日期等,為信息檢索和知識管理提供了有力支持。
除了這些應用之外,增強LLMs是一個活躍的研究領域,重點是將LLMs與外部數據源連接起來并調用外部API。這種集成允許模型利用它在預訓練期間可能沒有學到的信息,從而進一步增強其能力。例如,通過與實時新聞數據源連接,LLMs可以生成最新的新聞報道;通過調用氣象數據API,可以生成天氣預報相關的文本。這些技術的應用前景廣闊,我們將在后續研究中進一步探討這些技術。
LLMs為自然語言生成提供了一個強大的工具,并有潛力通過自動化需要語言理解和生成的任務來革新各個領域。其在文本生成、信息處理和語言理解方面的卓越表現,使其成為人工智能領域的重要研究方向之一。
三、深入了解Transformer架構
3.1 為什么是Transformer?
你可能會好奇,LLMs是如何學得如此之好的?LLMs最關鍵的成分是什么?答案是Transformer架構,它在論文“Attention is All You Need”中被提出。當然,還有其他同樣重要的元素,例如LLMs使用的海量數據和訓練算法,但Transformer架構是使現代LLMs能夠充分利用其他組件的關鍵組成部分。與之前用于生成式人工智能任務的循環神經網絡(RNNs)相比,使用Transformer架構可以顯著提高性能。Transformer架構之所以能夠實現如此出色的性能,關鍵在于它能夠學習句子中所有單詞的相關性和上下文。
這種學習過程通過給定句子中每個單詞與其他單詞之間的加權連接來實現。在訓練過程中,模型會學習這些連接的權重,稱為注意力權重。這種能力通常被稱為自注意力。自注意力機制使模型能夠關注句子中不同單詞之間的關系,從而更好地理解句子的語義和結構。例如,在句子“我今天感覺很好”中,模型不僅會關注“我”“今天”“感覺”“很好”這四個單詞本身,還會關注它們之間的關系,如“我”和“感覺”之間的關系、“今天”和“很好”之間的關系等。通過這種方式,模型能夠更準確地理解句子的含義,從而生成更自然、更準確的語言文本。
3.2 從單詞到向量
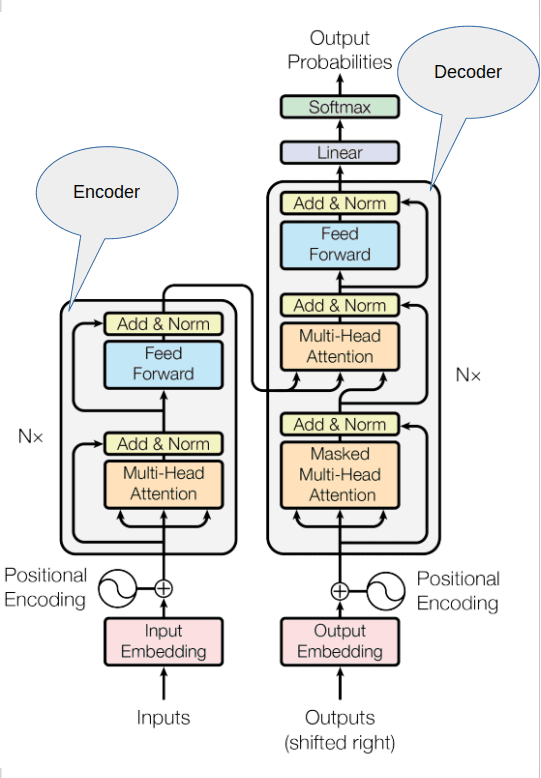
如上圖所示,Transformer架構主要由編碼器和解碼器組成。機器學習模型是大型統計計算器,它們使用數字進行工作。因此,在將文本傳遞之前,第一步是將輸入序列進行分詞。分詞過程將每個單詞映射到字典中的一個數字,有些分詞器將英語字典中的單詞映射為數字,而有些則將單詞的一部分進行映射。關鍵在于,一旦為訓練選擇了分詞器,你必須在文本生成任務中使用相同的分詞器。例如,對于句子“ Live what you love”,分詞器可能會將其映射為數字序列[716, 273, 328, 424]。
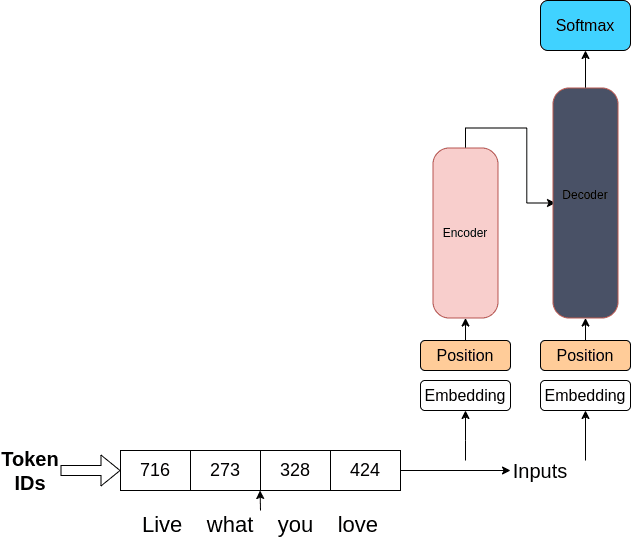
3.2.1 輸入部分
- Token IDs:文本首先要進行分詞處理,將文本中的單詞或子詞轉換為對應的數字標識,即Token IDs 。圖中“Live what you love”這句話被轉換成了716、273、328、424這樣的數字,這些數字代表了詞匯表中相應單詞或子詞的索引。
- Inputs:這些Token IDs組成的序列作為模型的輸入,進入后續的處理環節。
3.2.2 位置嵌入(Position Embedding)
- 輸入的Token IDs序列分別進入兩個“Position Embedding”模塊。由于Transformer架構本身不具備對單詞位置的感知能力,位置嵌入的作用就是為模型提供單詞在句子中的位置信息 ,幫助模型理解單詞間的順序關系。
3.2.3 編碼 - 解碼結構(Encoder - Decoder)
- Encoder(編碼器):經過位置嵌入后的輸入進入粉紅色的Encoder模塊。編碼器的主要功能是對輸入序列進行特征提取和編碼,將輸入信息轉換為更適合后續處理的隱藏表示 ,可以理解為對輸入文本進行深層次的理解和特征抽取,以便后續解碼階段使用。
- Decoder(解碼器):編碼器的輸出會作為解碼器的輸入之一。解碼器接收編碼器的輸出以及自身的位置嵌入信息,進一步處理這些信息 。在諸如機器翻譯、文本生成等任務中,解碼器負責生成最終的輸出,例如生成翻譯后的文本或者續寫的文本內容。
3.2.4 Softmax層
- 解碼器的輸出最終進入藍色的Softmax層。Softmax函數的主要作用是將解碼器輸出的數值轉換為概率分布 。在文本分類等任務中,這些概率代表了輸入文本屬于不同類別的可能性;在文本生成任務中,它可以表示生成下一個單詞的概率分布,從而確定最終的輸出類別或生成文本中的下一個單詞等。
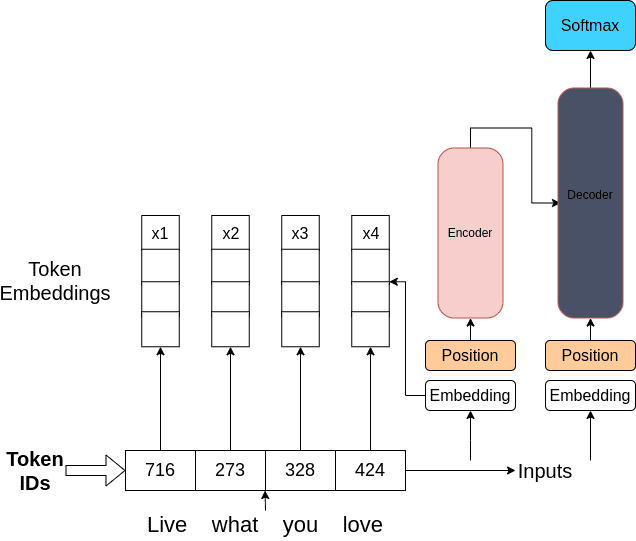
3.3 自注意力:理解文本中的關系
如前面所見,自注意力層學習輸入序列中一個單詞與其他所有單詞之間的關系。這是通過為輸入序列各部分之間的所有連接分配注意力權重來實現的。編碼器和解碼器都包含多個自注意力頭,每個頭獨立學習輸入序列中不同單詞之間的注意力權重。這里的直覺是每個頭可能會學習語言的不同方面。例如,一個頭可能關注句子中的情感,而另一個頭可能關注句子中命名實體之間的關系。這些權重在訓練過程中由模型學習。最初,權重是隨機分配的,只要有足夠的數據和時間,這些權重就會學會語言的不同方面。
經過多頭自注意力層后,將注意力權重應用于輸入序列。隨后,序列經過一個前饋網絡層進行處理,該層生成一個包含詞匯表中每個單詞概率的向量。這個向量可以傳遞到softmax層以獲得每個單詞的概率分數,有多種方法可以選擇最終輸出。
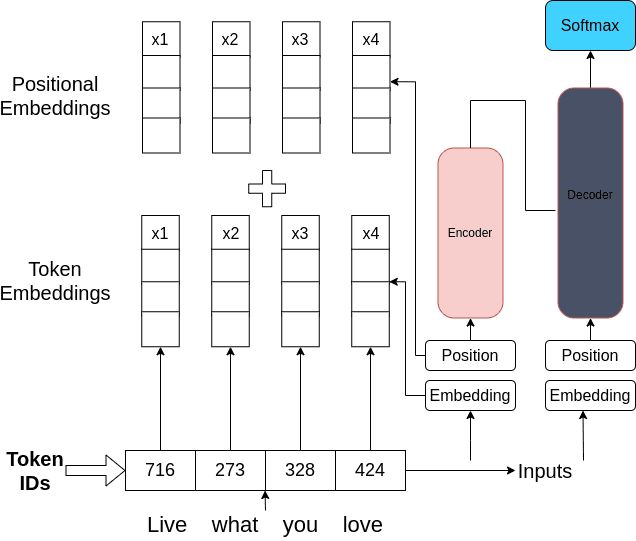
3.3.1 輸入部分
- Token IDs:文本首先要進行分詞處理,將文本中的單詞或子詞轉換為對應的數字標識,即Token IDs 。圖中“Live what you love”這句話被轉換成了716、273、328、424這樣的數字,這些數字代表了詞匯表中相應單詞或子詞的索引。
3.3.2 嵌入層(Embeddings)
- Token Embeddings:Token IDs進入Token Embeddings層。該層的作用是將離散的Token IDs映射到一個連續的向量空間中,每個Token ID都被轉換為一個固定維度的向量,這些向量能夠捕捉單詞的語義信息。例如,不同的單詞通過Token Embeddings會得到不同的向量表示,語義相近的單詞其向量在空間中的位置也較為接近。
- Positional Embeddings:同時,輸入還會進入Positional Embeddings層。由于Transformer架構本身不具備對單詞位置的感知能力,Positional Embeddings層為模型提供單詞在句子中的位置信息。它生成的向量表示了單詞在句子中的順序,幫助模型理解單詞間的先后關系。
- 求和操作:Token Embeddings和Positional Embeddings生成的向量會進行相加操作(圖中的“+”符號)。這樣做是為了將單詞的語義信息和位置信息融合在一起,得到包含語義和位置信息的輸入向量,作為后續Encoder的輸入。
3.3.3 編碼 - 解碼結構(Encoder - Decoder)
- Encoder(編碼器):融合后的輸入向量進入粉紅色的Encoder模塊。編碼器的主要功能是對輸入序列進行特征提取和編碼,通過自注意力機制等操作,將輸入信息轉換為更適合后續處理的隱藏表示 ,可以理解為對輸入文本進行深層次的理解和特征抽取,以便后續解碼階段使用。
- Decoder(解碼器):編碼器的輸出會作為解碼器的輸入之一。解碼器接收編碼器的輸出以及自身的位置嵌入信息,進一步處理這些信息 。在諸如機器翻譯、文本生成等任務中,解碼器負責生成最終的輸出,例如生成翻譯后的文本或者續寫的文本內容。
四、綜合概述:Transformer架構
現在我們已經了解了各個組件,讓我們看看端到端的預測過程。以翻譯任務為例,輸入序列中的每個單詞都被分詞并通過編碼器的多頭自注意力層進行處理。編碼器的輸出影響解碼器的自注意力機制。添加一個序列開始標記以觸發下一個標記的預測。該過程持續進行,直到滿足停止條件,從而生成一個可以解碼為輸出單詞序列的標記序列。
總結一下架構的高級別內容,編碼器將輸入(提示)編碼為對輸入結構和含義的深入理解,并為每個輸入標記生成一個向量,解碼器接受輸入標記并使用編碼器提供的理解生成新標記。例如,在將英語句子“I love natural language processing”翻譯為中文時,編碼器會將該句子編碼為一個向量序列,解碼器會根據這些向量生成中文句子“我愛自然語言處理”。Transformer架構通過這種方式實現了高效的文本生成和翻譯,其在自然語言處理領域的廣泛應用也證明了其強大的性能和優越性。
四、微調技術
4.1 指令微調
與預訓練(通過自監督學習在大量非結構化文本數據上訓練LLM)不同,微調是一個監督學習過程,通過使用帶有標記示例的數據集更新權重來實現。這有助于你在特定任務上提高模型的性能。標記示例可以是情感分析任務、翻譯任務、摘要任務或其他任務的示例,也可以是上述任務的組合。標記示例包含兩部分:
- 提示:例如,在情感分析任務中,提示可以是“我今天感覺很好”。
- 完成:對于上述提示,完成可以是“積極的”。
許多公開可用的數據集可用于訓練語言模型,但其中大多數都沒有格式化為指令。幸運的是,有幾個提示模板庫為各種任務和各種數據集提供模板。這些庫可以處理流行的數據集,以創建可用于指令微調的數據。所有模型權重都在指令微調中更新,這被稱為全微調。像這樣的微調需要你存儲所有模型權重,因此這需要與預訓練期間相同的計算能力。你可以通過相關研究深入了解這種方法,并通過構建一些有趣的應用程序來實踐。
4.2 多任務微調
在多任務微調中,我們本質上是同時在多個任務上對模型進行微調。這需要大量的示例來進行訓練。適合多任務微調的任務包括情感分析、文本摘要、問答、機器翻譯等。多任務微調允許模型在一系列挑戰中學習和泛化,最終提高其整體性能。例如,一個經過多任務微調的模型可以在情感分析任務中準確判斷文本的情感傾向,同時在文本摘要任務中生成高質量的摘要。這種多任務學習方式使模型能夠更好地適應不同的應用場景,提高其在實際應用中的通用性和適應性。
4.3 參數高效微調(PEFT)
4.3.1 什么是PEFT?
LLMs可能非常龐大,最大的LLMs需要數百GB的存儲空間。而且,要對LLM進行全微調,你不僅需要存儲所有模型權重,還需要存儲梯度、優化器狀態、前向激活以及訓練過程中所需的臨時狀態。這需要大量的計算能力,獲取這些資源可能相當困難。與全微調(在訓練期間更新每個權重)不同,參數高效方法專注于一個小的子集。這可以通過以下方式實現:
- 微調特定層或組件:只調整相關部分,而不是重新訓練整個模型。例如,只對模型的解碼器部分進行微調,以提高其在特定文本生成任務中的性能。
- 凍結LLM權重并添加新組件:原始模型變為只讀,同時引入并訓練特定于任務的額外層或參數。例如,在模型中添加一個情感分析模塊,只對該模塊進行訓練,而保持原始模型的權重不變。
總體而言,只更新大約15% - 20%的原始參數,這使得參數高效微調即使在單個GPU上也可以使用較少的計算資源進行。由于大多數LLM權重只被輕微修改或保持不變,因此顯著降低了災難性遺忘的風險。災難性遺忘是指模型在學習新任務時,忘記了之前學到的知識。通過參數高效微調,可以在一定程度上避免這種問題,使模型在學習新任務的同時,保留之前學到的知識。
4.3.2 PEFT的類別
PEFT方法主要有以下3個類別:
- 選擇性方法:這些方法專門對初始LLM參數的一部分進行微調。你可以選擇要修改哪些參數。例如,你可以選擇訓練模型的特定組件、特定層,甚至特定類型的參數。這種方法可以根據具體任務的需求,有針對性地調整模型的參數,從而提高模型在該任務上的性能。
- 重參數化方法:這些方法通過創建原始網絡權重的低秩變換來減少需要訓練的參數數量。在這些方法中,常用的一種技術是LoRA(Low-Rank Adaptation)。LoRA通過在原始權重矩陣中添加一個低秩矩陣來實現參數的調整,從而減少需要訓練的參數數量。這種方法可以在保持模型性能的同時,顯著降低訓練所需的計算資源。
- 加性方法:這些方法通過保持原始LLM權重不變并引入新的可訓練組件來進行微調。在這方面主要有兩種方法。適配器方法在模型架構中引入新的可訓練層,通常位于編碼器或解碼器組件中,跟隨注意力層或前饋層。相反,軟提示方法保持固定且凍結的模型架構,專注于通過操縱輸入來提高性能。這可以通過向提示嵌入添加可訓練參數或保持輸入不變并重新訓練嵌入權重來實現。例如,在適配器方法中,可以在模型的編碼器部分添加一個適配器層,該層專門用于處理特定任務的輸入數據,從而提高模型在該任務上的性能。
五、評估方法
在傳統機器學習方法中,我們可以在訓練集或驗證集上評估模型的性能,因為輸出是確定性的。我們可以使用準確率、精確率、召回率、F1分數等指標來確定模型的性能。然而,在LLMs的情況下,這可能很困難,因為輸出是非確定性的,基于語言的評估可能相當具有挑戰性。例如,考慮以下句子,“今天的天氣很好”和“今天的天氣很棒”。上述兩個句子的含義相似,但如何衡量這種相似性呢?例如,考慮以下句子,“今天的天氣很糟糕”,這個句子與其他兩個句子的含義相反。然而,所有三個句子只有一個詞的差異。我們人類可以輕松區分這些句子,但我們需要一個結構化且明確定義的方法來衡量不同句子之間的相似性,以便訓練LLMs。ROUGE和BLEU是兩種廣泛用于不同任務的評估指標。
5.1 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)分數
ROUGE分數通常用于文本摘要任務。它用于客觀評估機器生成摘要與人類為較長文本提供的參考摘要之間的相似性。讓我們看看一些ROUGE分數的類型。
- ROUGE-1分數:它衡量機器生成文本和參考文本中單個單詞的重疊情況。它根據重疊單詞的數量計算精確率、召回率和F1分數等指標。盡管這種方法可以衡量兩個文本的相似性,但它可能會有點誤導。例如,考慮以下參考句子“這里很冷”,然后,考慮以下兩個機器生成的句子,“這里非常冷”和“這里不冷”,這兩個句子的測量值將相同,然而,其中一個句子與參考文本的含義相反。
- ROUGE-N分數:它衡量機器生成文本和參考文本中n-gram(給定句子中的n個連續單詞)的重疊情況。它根據重疊n-gram的數量計算精確率、召回率和F1分數等指標。由于這個指標在計算中考慮了二元組和n-gram,直觀上可以看出它也考慮了單詞的位置。例如,在句子“我愛自然語言處理”中,二元組“我愛”“愛自然”“自然語言”“語言處理”等的重疊情況可以更好地反映兩個句子之間的相似性。
- ROUGE-L分數:這是另一種常見的ROUGE分數,我們使用最長公共子序列的長度(不考慮順序)來計算精確率、召回率和F1分數等指標,這些指標統稱為ROUGE分數。例如,對于句子“我愛自然語言處理”和“自然語言處理我愛”,它們的最長公共子序列長度為4,因此ROUGE-L分數會相對較高,從而更好地反映兩個句子之間的相似性。
5.2 BLEU(Bilingual Evaluation Understudy)分數
BLEU分數是一種用于自動評估機器翻譯文本的指標。BLEU分數是一個介于零和一之間的數字,用于衡量機器翻譯文本與一組參考翻譯之間的相似性。簡單來說,你可以認為它是不同n-gram大小的精確率值的幾何平均值。例如,在將英語句子“I love natural language processing”翻譯為中文時,如果機器生成的翻譯是“我愛自然語言處理”,而參考翻譯是“我愛自然語言處理技術”,那么BLEU分數會根據這兩個句子之間的n-gram重疊情況來計算它們的相似性。
5.3 一些定性見解
現在,讓我們定量地看看這些指標如何隨著不同文本對的變化而變化。考慮以下參考文本、機器生成文本以及相應的指標:
| 參考文本 | 人工智能正在改變包括醫療和金融在內的各個行業。 |
|---|---|
| 預測1 | AI正在革新不同領域,如醫療和金融。 |
| 預測2 | 人工智能正在改變如醫療和金融等行業。 |
| 預測3 | 人工智能正在改變包括醫療和金融在內的各個行業。 |
| 預測 | BLEU分數 | ROUGE-1分數 | ROUGE-2分數 | ROUGE-L分數 |
|---|---|---|---|---|
| 預測1 | 0.23708 | 0.42105 | 0.23529 | 0.42105 |
| 預測2 | 0.44127 | 0.8 | 0.5555 | 0.8 |
| 預測3 | 1.0 | 1.0 | 1.0 | 1.0 |
可以看到,隨著我們越來越接近參考文本,BLEU分數和ROUGE分數都在提高。這表明這些指標能夠較好地反映機器生成文本與參考文本之間的相似性。你可以下載下面的代碼,自己嘗試不同的參考文本和預測文本,看看這些指標是如何變化的。
六、量化
6.1 為什么需要量化?
LLMs擁有數百萬甚至數十億個參數,每個參數通常使用32位或16位來表示。例如,假設一個模型有10億個參數,所有參數都使用32位浮點數存儲。該模型中的每個參數將占用4字節的內存。因此,總共需要4×10^9字節的內存,相當于4GB的內存。這意味著,要存儲一個具有10億個參數的32位模型,你需要4GB的內存。如果你想訓練這樣一個模型,那么你需要額外的內存來存儲梯度、激活、優化器狀態以及函數所需的其他臨時變量。這很容易導致每個模型參數大約需要20字節的額外內存。在考慮了所有這些額外的內存需求之后,訓練這樣一個模型大約需要6倍的GPU內存(大約24GB),此外,你還需要一些內存來存儲數據。這對于邊緣設備來說太多了。
6.2 量化的權衡
那么,你有什么選擇來減少訓練所需的內存呢?一種可以減少內存的技術稱為量化。通過將32位浮點數替換為16位甚至8位整數,量化顯著減少了大型語言模型和神經網絡的內存需求。為了確保準確性和靈活性,默認情況下,模型權重、激活和參數通常以32位浮點格式存儲。量化將原始的32位浮點數投影到低精度空間,使用縮放因子。然而,這種技術的缺點是通過降低原始參數的精度,你會失去性能。你降低的精度越多,你失去的性能就越多。例如,將32位浮點數量化為8位整數時,雖然內存需求大幅減少,但模型的性能可能會受到較大影響,導致生成文本的質量下降。
6.3 流行的量化技術
現在,讓我們嘗試了解如何以32位浮點表示法存儲一個數字,以及如何將其量化為16位浮點表示法。在深度學習中,由于浮點數能夠表示廣泛范圍的值且具有高精度,因此通常使用浮點數。通常,浮點數使用_n_位來存儲一個數值。這些_n_位進一步劃分為三個不同的部分:
- 符號:該位指示數字的正負。它使用一個位,其中0表示正數,1表示負數。
- 指數:指數是一段位,表示基數(在二進制表示中通常是2)的冪。指數可以是正數或負數,允許數字表示非常大或非常小的值。
- 尾數/有效數字:剩余的位用于存儲尾數,也稱為有效數字。它表示數字的有效數字。數字的精度在很大程度上取決于尾數的長度。
這種設計允許浮點數以不同的精度覆蓋廣泛的值。該表示法使用的公式為:
( ( ? 1 ) s i g n × b a s e e x p o n e n t × m a n t i s s a ((-1)^{sign} \times base^{exponent} \times mantissa ((?1)sign×baseexponent×mantissa
-
FP32使用32位來表示一個數字:1位用于符號,8位用于指數,剩余的23位用于尾數。盡管它提供了高度的精度,但FP32的缺點是其高計算和內存占用。考慮以下FP32表示的2.71828:

(?1)0 ? 2^(128?127) ? 1.35914003 = 2.71828007 -
FP16使用16位來存儲一個數字:1位用于符號,5位用于指數,10位用于尾數。盡管這使其更加內存高效并加速了計算,但減少的范圍和精度可能會引入數值不穩定,從而影響模型的準確性。看看2.71828的量化FP16表示:

(?1)0 ? 2^(128?127) ? 1.358398 = 2.716796 -
BF16也是一種16位格式,但有1位用于符號,8位用于指數,7位用于尾數。與FP16相比,BF16擴展了可表示的范圍,從而減少了下溢和上溢的風險。盡管由于有效數字位數減少,精度有所降低,但BF16通常不會顯著影響模型性能,是深度學習任務的一個有用折衷方案。看看2.71828的量化float16表示:

(?1)0 ? 2^(128?127) ? 1.3515625 = 2.703125



)



![[密碼學實戰]密評考試訓練系統v1.0程序及密評參考題庫(獲取路徑在文末)](http://pic.xiahunao.cn/[密碼學實戰]密評考試訓練系統v1.0程序及密評參考題庫(獲取路徑在文末))




)




)

:MySQL的執行原理(MYSQL的查詢成本))