文章目錄
- MySQL性能調優
- 數據庫設計優化
- 查詢優化
- 配置參數調整
- 硬件優化
- 1.MySQL的執行原理-2
- 1.1.MySQL的查詢成本
- 1.1.1.什么是成本
- 1.1.2.單表查詢的成本
- 1.1.2.1.基于成本的優化步驟實戰
- 1. 根據搜索條件,找出所有可能使用的索引
- 2. 計算全表掃描的代價
- 3. 計算使用不同索引執行查詢的代價
- 3.1使用idx_expire_time執行查詢的成本分析
- 3.2使用idx_order_no執行查詢的成本分析
- 3.3是否有可能使用索引合并(Index Merge)
- 4. 對比各種方案,找出成本最低的那一個
- 1.1.3.Explain與查詢成本
- 1.1.3.1.EXPLAIN輸出成本
- 1.1.3.2.Optimizer Trace
- 1.1.4.連接查詢的成本
- 1.1.4.1.Condition filtering介紹
- 1.1.4.2.兩表連接的成本分析
- 1.1.4.4.多表連接的成本分析
- 1.1.5.調節成本常數
- 1.1.5.1.mysql.server_cost表
- 1.1.5.2.mysql.engine_cost表

個人主頁:道友老李
歡迎加入社區:道友老李的學習社區
MySQL性能調優
MySQL 性能調優是一個復雜且多維度的過程,下面從數據庫設計、查詢優化、配置參數調整、硬件優化幾個方面為你介紹相關的調優方法。
數據庫設計優化
- 合理設計表結構:確保表結構遵循數據庫設計范式,減少數據冗余,同時要根據實際業務需求靈活調整,避免過度范式化導致的查詢復雜度過高。
- 選擇合適的數據類型:使用合適的數據類型可以減少存儲空間,提高查詢性能。例如,對于固定長度的字符串使用
CHAR,對于可變長度的字符串使用VARCHAR;對于整數類型,根據取值范圍選擇合適的類型,如TINYINT、SMALLINT等。 - 建立適當的索引:索引可以加快數據的查找速度,但過多的索引會增加寫操作的開銷,因此需要根據查詢需求建立適當的索引。例如,對于經常用于
WHERE子句、JOIN條件和ORDER BY子句的列,可以考慮創建索引。
查詢優化
- 避免全表掃描:盡量使用索引來避免全表掃描,例如在
WHERE子句中使用索引列進行過濾。 - 優化子查詢:子查詢可能會導致性能問題,可以考慮使用
JOIN來替代子查詢。 - 減少不必要的列:在查詢時只選擇需要的列,避免使用
SELECT *。
配置參數調整
- 調整內存分配:根據服務器的硬件資源和業務需求,調整
innodb_buffer_pool_size、key_buffer_size等參數,以提高緩存命中率。 - 調整日志參數:根據業務需求調整
log_bin、innodb_log_file_size等參數,以平衡數據安全性和性能。
硬件優化
- 使用高速存儲設備:如 SSD 可以顯著提高磁盤 I/O 性能。
- 增加內存:足夠的內存可以減少磁盤 I/O,提高查詢性能。
1.MySQL的執行原理-2
1.1.MySQL的查詢成本
1.1.1.什么是成本
MySQL執行一個查詢可以有不同的執行方案,它會選擇其中成本最低,或者說代價最低的那種方案去真正的執行查詢。不過我們之前對成本的描述是非常模糊的,其實在MySQL中一條查詢語句的執行成本是由下邊這兩個方面組成的:
I/O成本
我們的表經常使用的MyISAM、InnoDB存儲引擎都是將數據和索引都存儲到磁盤上的,當我們想查詢表中的記錄時,需要先把數據或者索引加載到內存中然后再操作。這個從磁盤到內存這個加載的過程損耗的時間稱之為I/O成本。
CPU成本
讀取以及檢測記錄是否滿足對應的搜索條件、對結果集進行排序等這些操作損耗的時間稱之為CPU成本。
對于InnoDB存儲引擎來說,頁是磁盤和內存之間交互的基本單位。
MySQL規定讀取一個頁面花費的成本默認是1.0(I/O成本)
讀取以及檢測一條記錄是否符合搜索條件的成本默認是0.2(CPU成本)
1.0、0.2這些數字稱之為成本常數,這兩個成本常數我們最常用到,當然還有其他的成本常數。
注意,不管讀取記錄時需不需要檢測是否滿足搜索條件,哪怕是空數據,其成本都算是0.2。
1.1.2.單表查詢的成本
1.1.2.1.基于成本的優化步驟實戰
在一條單表查詢語句真正執行之前,MySQL的查詢優化器會找出執行該語句所有可能使用的方案,對比之后找出成本最低的方案,這個成本最低的方案就是所謂的執行計劃,之后才會調用存儲引擎提供的接口真正的執行查詢,這個過程總結一下就是這樣:
1、根據搜索條件,找出所有可能使用的索引
2、計算全表掃描的代價
3、計算使用不同索引執行查詢的代價
4、對比各種執行方案的代價,找出成本最低的那一個
下邊我們就以一個實例來分析一下這些步驟,單表查詢語句如下:
SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S')
AND expire_time> '2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09'
AND insert_time> expire_time AND order_note LIKE '%7****排1%' AND order_status = 0;
看上去有點兒復雜,我們一步一步分析一下。
1. 根據搜索條件,找出所有可能使用的索引
我們前邊說過,對于B+樹索引來說,只要索引列和常數使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=(不等于也可以寫成<>)或者LIKE操作符連接起來,就可以產生一個所謂的范圍區間(LIKE匹配字符串前綴也行),MySQL把一個查詢中可能使用到的索引稱之為possible keys。
我們分析一下上邊查詢中涉及到的幾個搜索條件:
order_no IN (‘DD00_6S’, ‘DD00_9S’, ‘DD00_10S’) ,這個搜索條件可以使用二級索引idx_order_no。
expire_time> ‘2021-03-22 18:28:28’ AND expire_time<= ‘2021-03-22 18:35:09’,這個搜索條件可以使用二級索引idx_expire_time。
insert_time> expire_time,這個搜索條件的索引列由于沒有和常數比較,所以并不能使用到索引。
order_note LIKE ‘%hello%’,order_note即使有索引,但是通過LIKE操作符和以通配符開頭的字符串做比較,不可以適用索引。
order_status = 0,由于該列上只有聯合索引,而且不符合最左前綴原則,所以不會用到索引。
綜上所述,上邊的查詢語句可能用到的索引,也就是possible keys只有idx_order_no,idx_expire_time。
EXPLAIN SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S')
AND expire_time> '2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09'
AND insert_time> expire_time AND order_note LIKE '%7****排1%' AND order_status = 0;

2. 計算全表掃描的代價
對于InnoDB存儲引擎來說,全表掃描的意思就是把聚簇索引(主鍵索引)中的記錄都依次和給定的搜索條件做一下比較,把符合搜索條件的記錄加入到結果集,所以需要將聚簇索引對應的頁面加載到內存中,然后再檢測記錄是否符合搜索條件。由于查詢成本=I/O成本+CPU成本,所以計算全表掃描的代價需要兩個信息:
1、聚簇索引占用的頁面數
2、該表中的記錄數
這兩個信息從哪來呢?MySQL為每個表維護了一系列的統計信息,關于這些統計信息是如何收集起來的我們放在后邊再說,現在看看怎么查看這些統計信息。
MySQL給我們提供了SHOW TABLE STATUS語句來查看表的統計信息,如果要看指定的某個表的統計信息,在該語句后加對應的LIKE語句就好了,比方說我們要查看order_exp這個表的統計信息可以這么寫:
SHOW TABLE STATUS LIKE 'order_exp'\G
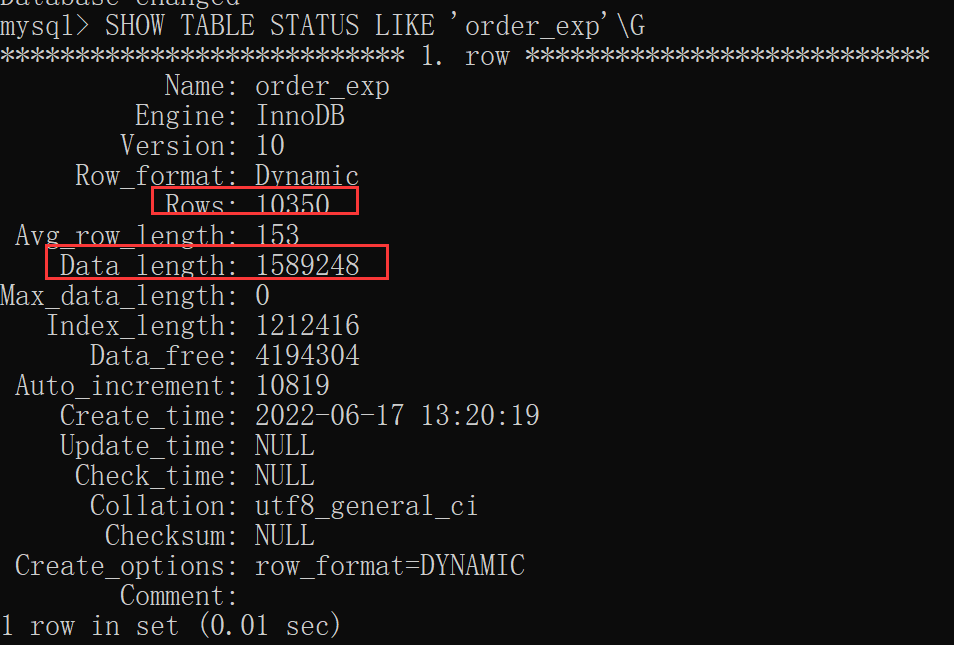
出現了很多統計選項,但我們目前只需要兩個:
Rows
本選項表示表中的記錄條數。對于使用MyISAM存儲引擎的表來說,該值是準確的,對于使用InnoDB存儲引擎的表來說,該值是一個估計值。從查詢結果我們也可以看出來,由于我們的order_exp表是使用InnoDB存儲引擎的,所以雖然實際上表中有10567條記錄,但是SHOW TABLE STATUS顯示的Rows值只有10350條記錄。但成本計算按照SHOW TABLE STATUS來計算。
Data_length
本選項表示表占用的存儲空間字節數。使用MyISAM存儲引擎的表來說,該值就是數據文件的大小,對于使用InnoDB存儲引擎的表來說,該值就相當于聚簇索引占用的存儲空間大小,也就是說可以這樣計算該值的大小:
Data_length = 聚簇索引的頁面數量 x 每個頁面的大小
我們的order_exp使用默認16KB的頁面大小,而上邊查詢結果顯示Data_length的值是1589248,所以我們可以反向來推導出聚簇索引的頁面數量:
聚簇索引的頁面數量 = 1589248 ÷ 16 ÷ 1024 = 97
我們現在已經得到了聚簇索引占用的頁面數量以及該表記錄數的估計值,所以就可以計算全表掃描成本了。
現在可以看一下全表掃描成本的計算過程:
I/O成本
97 x 1.0 + 1.1 = 98.1
97指的是聚簇索引占用的頁面數,1.0指的是加載一個頁面的成本常數,后邊的1.1是一個微調值。
關于這個微調值解釋如下:
MySQL在真實計算成本時會進行一些微調,這些微調的值是直接硬編碼到代碼里的,沒有注釋而且這些微調的值十分的小,并不影響我們分析。
CPU成本
10350x 0.2 + 1.0 = 2071
10350指的是統計數據中表的記錄數,對于InnoDB存儲引擎來說是一個估計值,0.2指的是訪問一條記錄所需的成本常數,后邊的1.0是一個微調值。
總成本:
98.1 + 2071 = 2169.1
綜上所述,對于order_exp的全表掃描所需的總成本就是2169.1。
3. 計算使用不同索引執行查詢的代價
從第1步分析我們得到,上述查詢可能使用到idx_order_no,idx_expire_time這兩個索引,我們需要分別分析單獨使用這些索引執行查詢的成本,最后還要分析是否可能使用到索引合并。
這里需要提一點的是,MySQL查詢優化器先分析使用唯一二級索引的成本,再分析使用普通索引的成本,我們這里兩個索引都是普通索引,先算哪個都可以。我們也先分析idx_expire_time的成本,然后再看使用idx_order_no的成本。
3.1使用idx_expire_time執行查詢的成本分析
idx_expire_time對應的搜索條件是:
expire_time>'2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09'
也就是說對應的范圍區間就是:(‘2021-03-22 18:28:28’ , ‘2021-03-22 18:35:09’ )。
使用idx_expire_time搜索會使用用二級索引 + 回表方式的查詢,MySQL計算這種查詢的成本依賴兩個方面的數據:
1 、范圍區間數量
不論某個范圍區間的二級索引到底占用了多少頁面,查詢優化器認為讀取索引的一個范圍區間的I/O成本和讀取一個頁面是相同的。本例中使用idx_expire_time的范圍區間只有一個,所以相當于訪問這個范圍區間的二級索引付出的I/O成本就是:1 x 1.0 = 1.0
2 、需要回表的記錄數
優化器需要計算二級索引的某個范圍區間到底包含多少條記錄,對于本例來說就是要計算idx_expire_time在(‘2021-03-22 18:28:28’ ,‘2021-03-22 18:35:09’)這個范圍區間中包含多少二級索引記錄,計算過程是這樣的:
**步驟1:**先根據expire_time>‘2021-03-22 18:28:28’這個條件訪問一下idx_expire_time對應的B+樹索引,找到滿足expire_time> ‘2021-03-22 18:28:28’這個條件的第一條記錄,我們把這條記錄稱之為區間最左記錄。我們前頭說過在B+數樹中定位一條記錄的過程是很快的,是常數級別的,所以這個過程的性能消耗是可以忽略不計的。
**步驟2:**然后再根據expire_time<=‘2021-03-22 18:35:09’這個條件繼續從idx_expire_time對應的B+樹索引中找出最后一條滿足這個條件的記錄,我們把這條記錄稱之為區間最右記錄,這個過程的性能消耗也可以忽略不計的。
**步驟3:**如果區間最左記錄和區間最右記錄相隔不太遠(在MySQL 5.7這個版本里,只要相隔不大于10個頁面即可),那就可以精確統計出滿足expire_time> ‘2021-03-22 18:28:28’ AND expire_time<= ‘2021-03-22 18:35:09’條件的二級索引記錄條數。否則只沿著區間最左記錄向右讀10個頁面,計算平均每個頁面中包含多少記錄,然后用這個平均值乘以區間最左記錄和區間最右記錄之間的頁面數量就可以了。
那么問題又來了,怎么估計區間最左記錄和區間最右記錄之間有多少個頁面呢?解決這個問題還得回到B+樹索引的結構中來。
我們假設區間最左記錄在頁b中,區間最右記錄在頁c中,那么我們計算區間最左記錄和區間最右記錄之間的頁面數量就相當于計算頁b和頁c之間有多少頁面,而它們父節點中記錄的每一條目錄項記錄都對應一個數據頁,所以計算頁b和頁c之間有多少頁面就相當于計算它們父節點(也就是頁a)中對應的目錄項記錄之間隔著幾條記錄。在一個頁面中統計兩條記錄之間有幾條記錄的成本就很小了。
不過還有問題,如果頁b和頁c之間的頁面實在太多,以至于頁b和頁c對應的目錄項記錄都不在一個父頁面中怎么辦?既然是樹,那就繼續遞歸,之前我們說過一個B+樹有4層高已經很了不得了,所以這個統計過程也不是很耗費性能。
知道了如何統計二級索引某個范圍區間的記錄數之后,就需要回到現實問題中來,MySQL根據上述算法測得idx_expire_time在區間(‘2021-03-22 18:28:28’ ,‘2021-03-22 18:35:09’)之間大約有39條記錄。
explain SELECT * FROM order_exp WHERE expire_time> '2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09';

讀取這39條二級索引記錄需要付出的CPU成本就是:
39 x 0.2 + 0.01 = 7.81
其中39是需要讀取的二級索引記錄條數,0.2是讀取一條記錄成本常數,0.01是微調。
在通過二級索引獲取到記錄之后,還需要干兩件事兒:
1 、根據這些記錄里的主鍵值到聚簇索引中做回表操作
MySQL評估回表操作的I/O成本依舊很簡單粗暴,他們認為每次回表操作都相當于訪問一個頁面,也就是說二級索引范圍區間有多少記錄,就需要進行多少次回表操作,也就是需要進行多少次頁面I/O。我們上邊統計了使用idx_expire_time二級索引執行查詢時,預計有39 條二級索引記錄需要進行回表操作,所以回表操作帶來的I/O成本就是:
39 x 1.0 = 39
其中39 是預計的二級索引記錄數,1.0是一個頁面的I/O成本常數。
2 、回表操作后得到的完整用戶記錄,然后再檢測其他搜索條件是否成立
回表操作的本質就是通過二級索引記錄的主鍵值到聚簇索引中找到完整的用戶記錄,然后再檢測除expire_time> ‘2021-03-22 18:28:28’ AND expire_time<'2021-03-22 18:35:09’這個搜索條件以外的搜索條件是否成立。
因為我們通過范圍區間獲取到二級索引記錄共39條,也就對應著聚簇索引中39 條完整的用戶記錄,讀取并檢測這些完整的用戶記錄是否符合其余的搜索條件的CPU成本如下:
39 x 0.2 =7.8
其中39 是待檢測記錄的條數,0.2是檢測一條記錄是否符合給定的搜索條件的成本常數。
所以本例中使用idx_expire_time執行查詢的成本就如下所示:
I/O成本:
1.0 + 39 x 1.0 = 40 .0 (范圍區間的數量 + 預估的二級索引記錄條數)
CPU成本:
39 x 0.2 + 0.01+39 x 0.2 = 15.61 (讀取二級索引記錄的成本 + 讀取并檢測回表后聚簇索引記錄的成本)
綜上所述,使用idx_expire_time執行查詢的總成本就是:
40 .0 + 15.61 = 55.61
3.2使用idx_order_no執行查詢的成本分析
idx_order_no對應的搜索條件是:
order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S')
也就是說相當于3個單點區間。與使用idx_expire_time的情況類似,我們也需要計算使用idx_order_no時需要訪問的范圍區間數量以及需要回表的記錄數,計算過程與上面類似,我們不詳列所有計算步驟和說明了。
范圍區間數量
使用idx_order_no執行查詢時很顯然有3個單點區間,所以訪問這3個范圍區間的二級索引付出的I/O成本就是:
3 x 1.0 = 3.0
需要回表的記錄數
由于使用idx_expire_time時有3個單點區間,所以每個單點區間都需要查找一遍對應的二級索引記錄數,三個單點區間總共需要回表的記錄數是58。
explain SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S');

讀取這些二級索引記錄的CPU成本就是:58 x 0.2+0.01 = 11.61
得到總共需要回表的記錄數之后,就要考慮:
根據這些記錄里的主鍵值到聚簇索引中做回表操作,所需的I/O成本就是:58 x 1.0 = 58.0
回表操作后得到的完整用戶記錄,然后再比較其他搜索條件是否成立
此步驟對應的CPU成本就是:
58 x 0.2 = 11.6
所以本例中使用idx_order_no執行查詢的成本就如下所示:
I/O成本:
3.0 + 58 x 1.0 = 61.0 (范圍區間的數量 + 預估的二級索引記錄條數)
CPU成本:
58 x 0.2 + 58 x 0.2 + 0.01 = 23.21 (讀取二級索引記錄的成本 + 讀取并檢測回表后聚簇索引記錄的成本)
綜上所述,使用idx_order_no執行查詢的總成本就是:61.0 + 23.21 = 84.21
3.3是否有可能使用索引合并(Index Merge)
本例中有關order_no和expire_time的搜索條件是使用AND連接起來的,而對于idx_order_no和idx_expire_time都是范圍查詢,也就是說查找到的二級索引記錄并不是按照主鍵值進行排序的,并不滿足使用Intersection索引合并的條件,所以并不會使用索引合并。而且MySQL查詢優化器計算索引合并成本的算法也比較麻煩.
4. 對比各種方案,找出成本最低的那一個
下邊把執行本例中的查詢的各種可執行方案以及它們對應的成本列出來:
- 全表掃描的成本:2148.7
- 使用idx_expire_time的成本:55.61
- 使用idx_order_no的成本:84.21
很顯然,使用idx_expire_time的成本最低,所以當然選擇idx_expire_time來執行查詢。
最后請注意:MySQL的源碼中對成本的計算實際要更復雜,但是以上基本思想和算法是沒問題的。
1.1.3.Explain與查詢成本
1.1.3.1.EXPLAIN輸出成本
前面我們已經對MySQL查詢優化器如何計算成本有了比較深刻的了解。但是EXPLAIN語句輸出中缺少了一個衡量執行計劃好壞的重要屬性—— 成本。
不過MySQL已經為我們提供了一種查看某個執行計劃花費的成本的方式:
在EXPLAIN單詞和真正的查詢語句中間加上FORMAT=JSON。
這樣我們就可以得到一個json格式的執行計劃,里邊包含該計劃花費的成本,比如這樣:
explain format= json SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S') AND expire_time> '2021-03-22 18:28:28' AND expire_time<= '2021-03-22 18:35:09' AND insert_time> expire_time AND order_note LIKE '%7排1%' AND order_status = 0\G
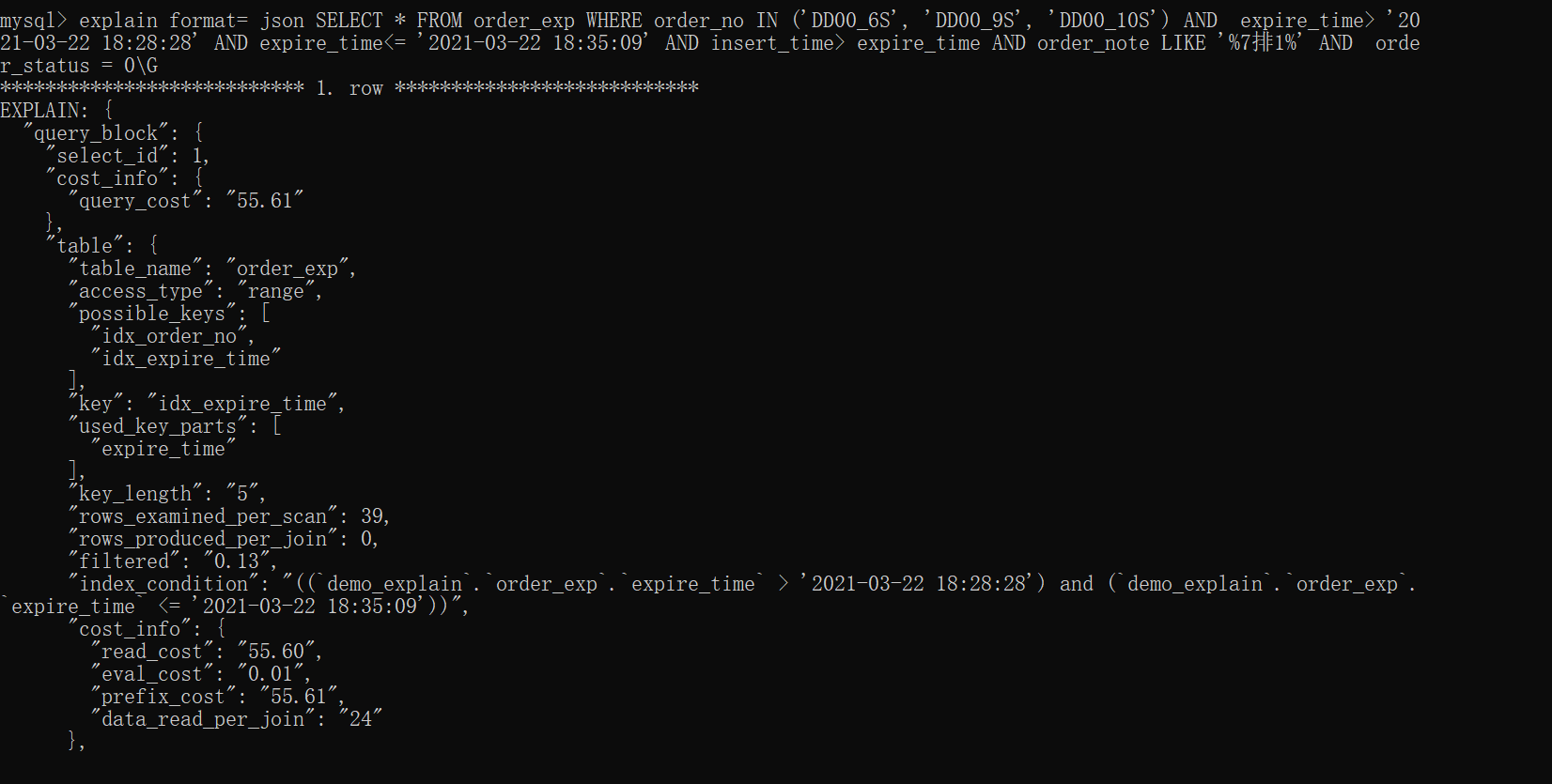
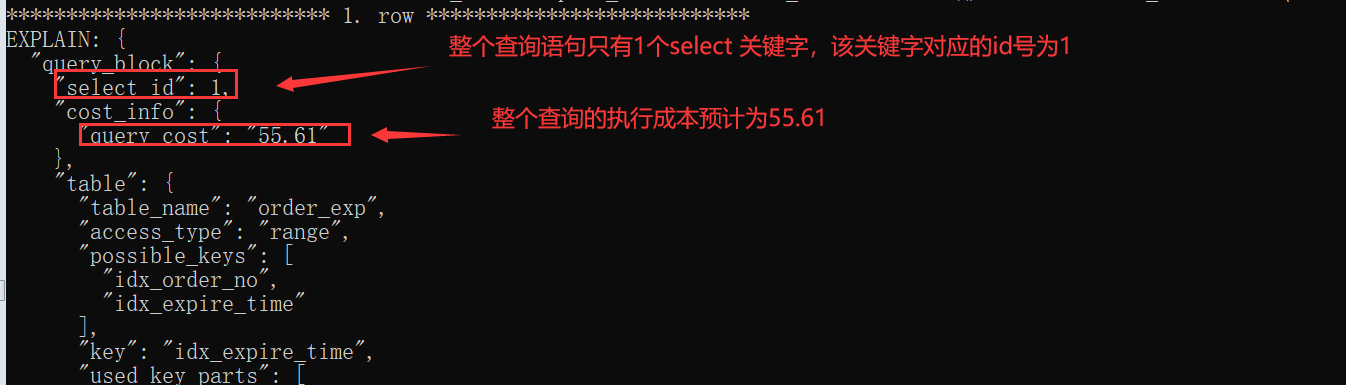
這么多字段怎么解釋,這里我用截圖的方式解釋一下

1.1.3.2.Optimizer Trace
自認為比較牛逼的同學可能有這樣的疑問:“我就覺得使用其他的執行方案比EXPLAIN輸出的這種方案強,憑什么優化器做的決定和我想的不一樣呢?為什么MySQL一定要全文掃描,不用索引呢?”,所以:在MySQL 5.6以及之后的版本中,MySQL提出了一個optimizertrace的功能,這個功能可以讓我們方便的查看優化器生成執行計劃的整個過程,這個功能的開啟與關閉由系統變量optimizer_trace決定:
SHOW VARIABLES LIKE 'optimizer_trace';
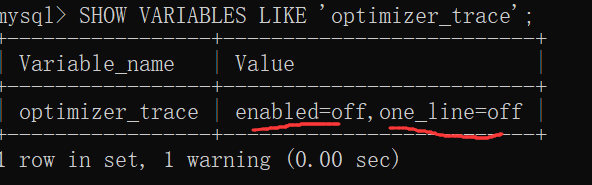
可以看到enabled值為off,表明這個功能默認是關閉的。
如果想打開這個功能,必須首先把enabled的值改為on,就像這樣:(注意這個開關是seesion級別)
SET optimizer_trace= 'enabled=on';
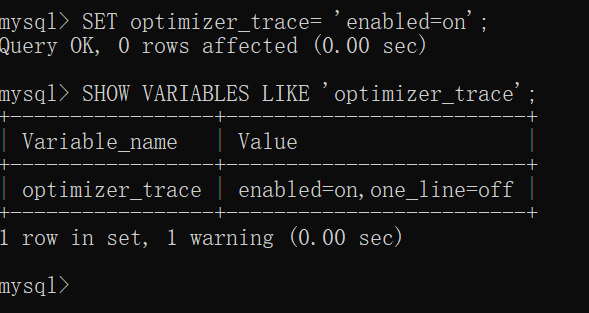
one_line的值是控制輸出格式的,如果為on那么所有輸出都將在一行中展示,我們就保持其默認值為off。
當停止查看語句的優化過程時,把optimizertrace功能關閉
SET optimizer_trace="enabled=off";
注意:開啟trace會影響mysql性能,所以只能臨時分析sql 使用,用完之后立即關閉 。
現在我們有一個搜索條件比較多的查詢語句,它的執行計劃如下:
explain
SELECT * FROM order_exp WHERE order_no IN ('DD00_6S', 'DD00_9S', 'DD00_10S')
AND expire_time> '2021-03-22 18:28:28' AND insert_time> '2021-03-22
18:35:09' AND order_note LIKE '%7****排1%';
可以看到該查詢可能使用到的索引有3個u_idx_day_status,idx_order_no,idx_expire_time,那么為什么優化器最終選擇了idx_order_no而不選擇其他的索引或者直接全表掃描呢?這時候就可以通過otpimzer trace功能來查看優化器的具體工作過程:(記得開啟optimizer trace功能)
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
然后我們就可以輸入我們想要查看優化過程的查詢語句,當該查詢語句執行完成后,就可以到information_schema數據庫下的OPTIMIZER_TRACE表中查看完整的優化過程。
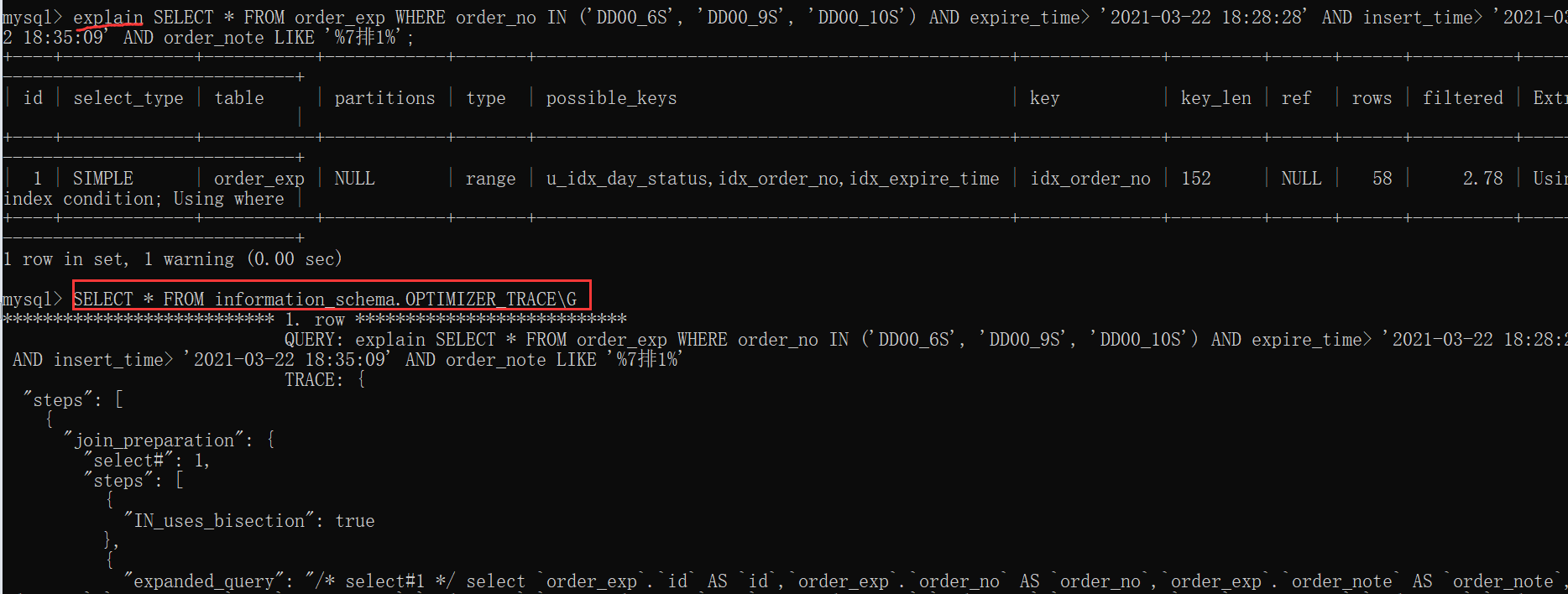

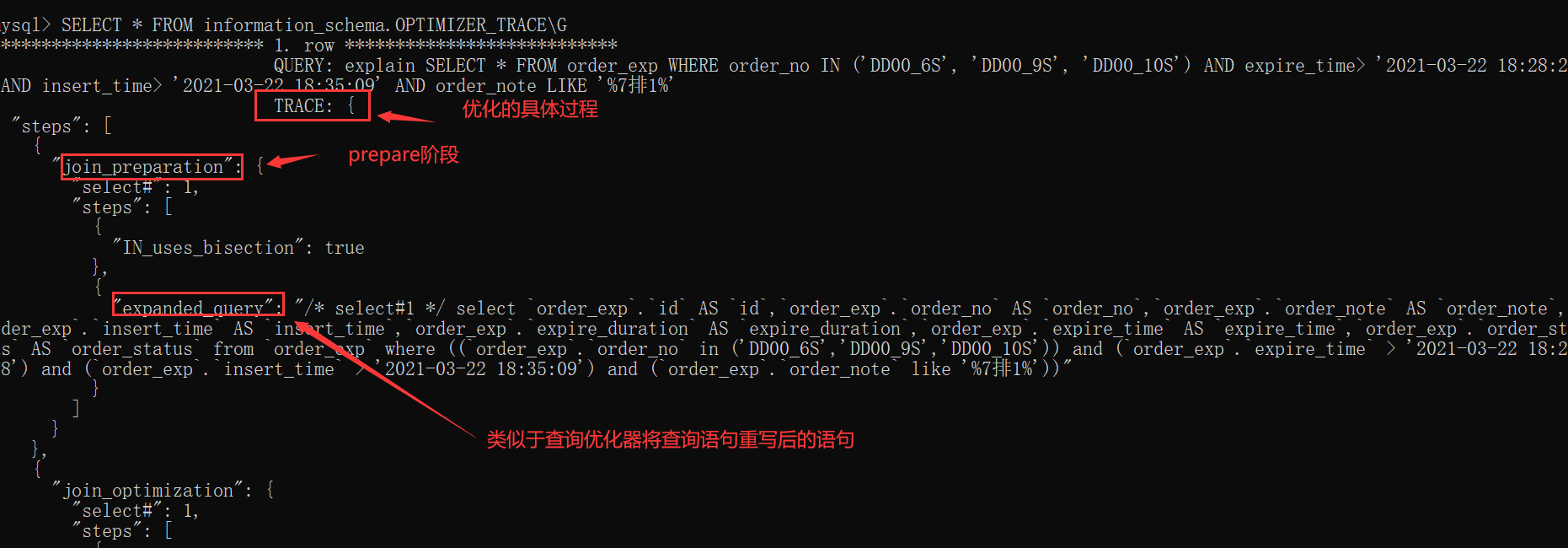
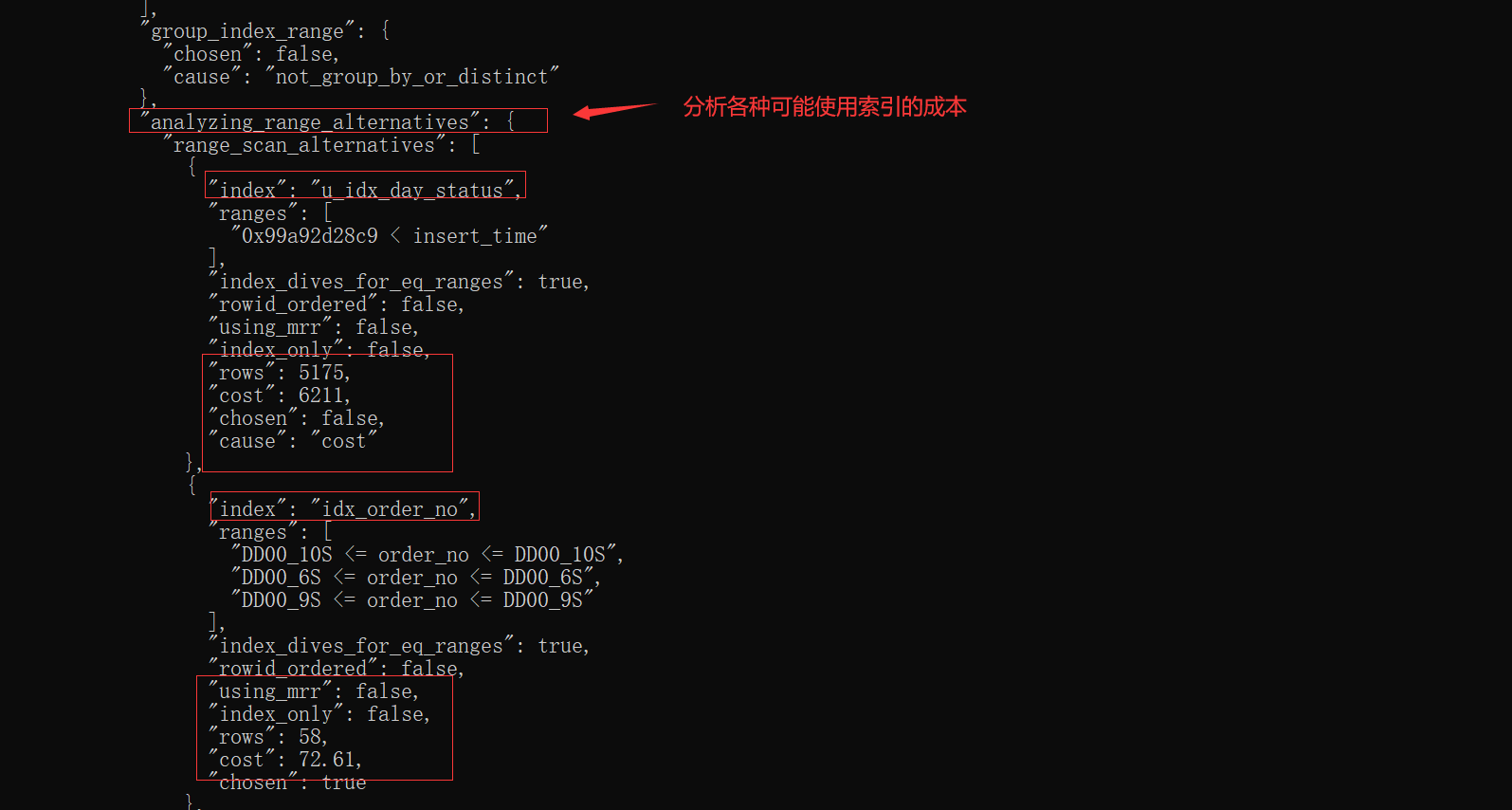
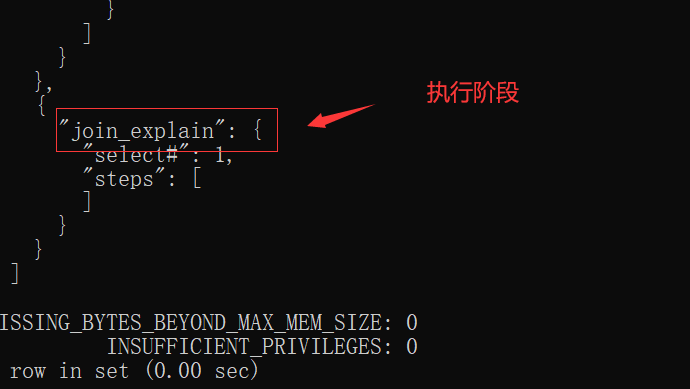
優化過程大致分為了三個階段:
prepare階段
optimize階段
execute階段
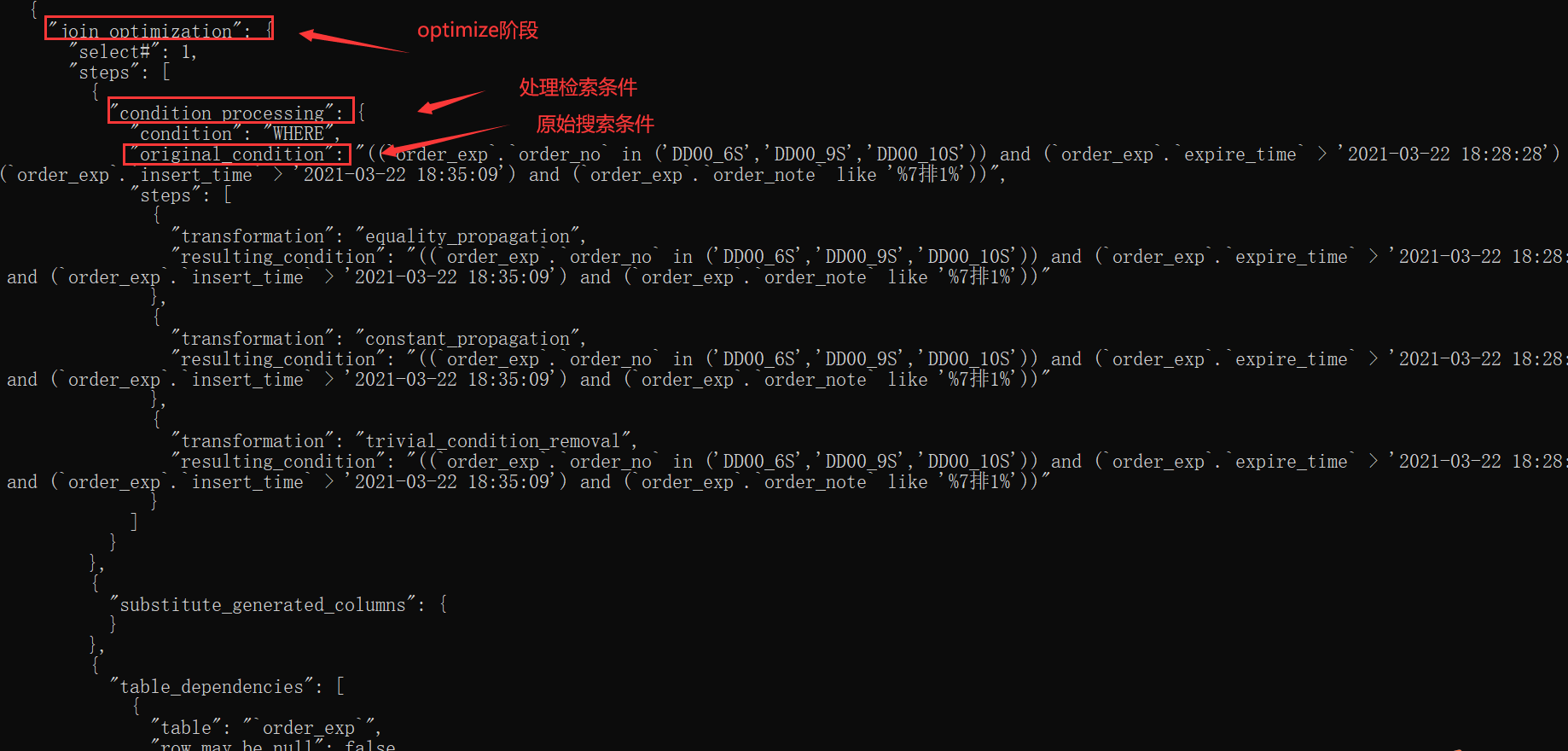
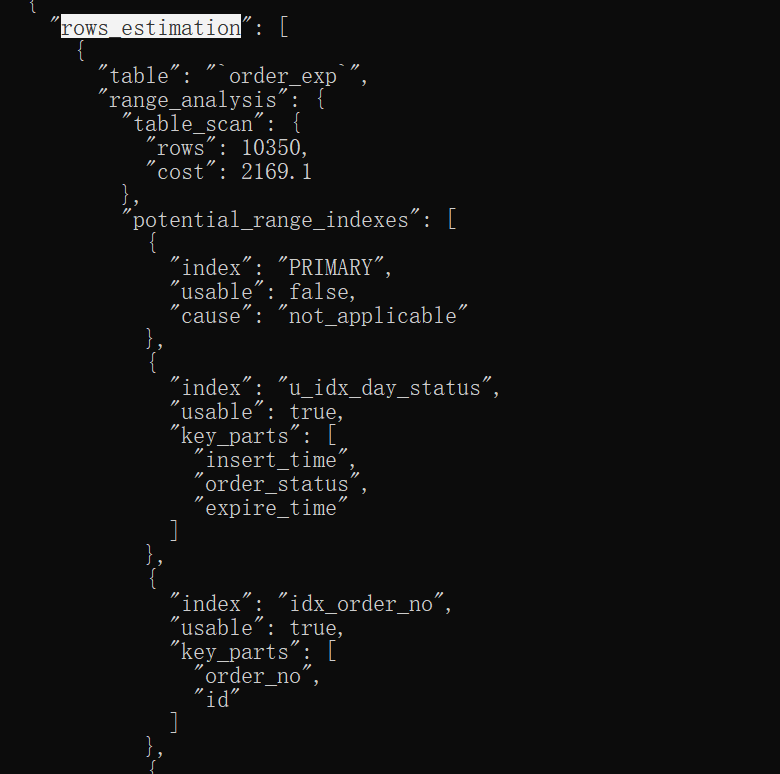
我們所說的基于成本的優化主要集中在optimize階段,對于單表查詢來說,我們主要關注optimize階段的"rows_estimation"這個過程,這個過程深入分析了對單表查詢的各種執行方案的成本;
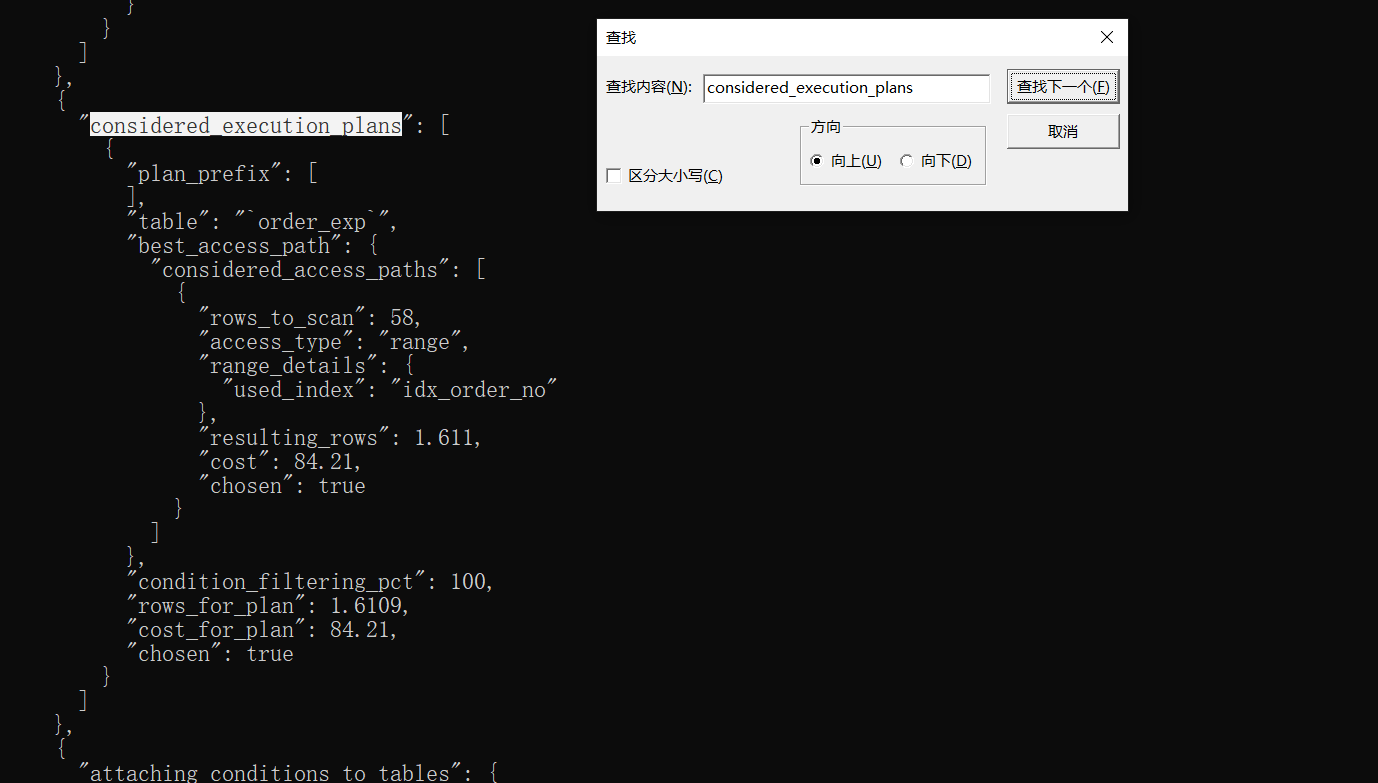
對于多表連接查詢來說,我們更多需要關注"considered_execution_plans"這個過程,這個過程里會寫明各種不同的連接方式所對應的成本。反正優化器最終會選擇成本最低的那種方案來作為最終的執行計劃,也就是我們使用EXPLAIN語句所展現出的那種方案。
如果對使用EXPLAIN語句展示出的對某個查詢的執行計劃很不理解,就可以嘗試使用optimizer trace功能來詳細了解每一種執行方案對應的成本。
1.1.4.連接查詢的成本
1.1.4.1.Condition filtering介紹
我們前邊說過,MySQL中連接查詢采用的是嵌套循環連接算法,驅動表會被訪問一次,被驅動表可能會被訪問多次,所以對于兩表連接查詢來說,它的查詢成本由下邊兩個部分構成:
1、單次查詢驅動表的成本
2、多次查詢被驅動表的成本(具體查詢多少次取決于對驅動表查詢的結果集中有多少條記錄)
對驅動表進行查詢后得到的記錄條數稱之為驅動表的 扇出 (英文名:fanout)。
很顯然驅動表的扇出值越小,對被驅動表的查詢次數也就越少,連接查詢的總成本也就越低。當查詢優化器想計算整個連接查詢所使用的成本時,就需要計算出驅動表的扇出值,有的時候扇出值的計算是很容易的,比如下邊這兩個查詢:
查詢一:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2;
假設使用s1表作為驅動表,很顯然對驅動表的單表查詢只能使用全表掃描的方式執行,驅動表的扇出值也很明確,那就是驅動表中有多少記錄,扇出值就是多少。統計數據中s1表的記錄行數是10573,也就是說優化器就直接會把10573當作在s1表的扇出值。
查詢二:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2 WHERE s1.expire_time> '2021-03-22 18:28:28' AND s1.expire_time<= '2021-03-22 18:35:09';
仍然假設s1表是驅動表的話,很顯然對驅動表的單表查詢可以使用idx_expire_time索引執行查詢。此時范圍區間( ‘2021-03-22 18:28:28’, ‘2021-03-22 18:35:09’)中有多少條記錄,那么扇出值就是多少。
但是有的時候扇出值的計算就變得很棘手,比方說下邊幾個查詢:
查詢三:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2 WHERE s1.order_note > 'xyz';
本查詢和查詢一類似,只不過對于驅動表s1多了一個order_note > 'xyz’的搜索條件。查詢優化器又不會真正的去執行查詢,所以它只能猜這10573記錄里有多少條記錄滿足order_note > 'xyz’條件。
查詢四:
SELECT * FROM order_exp AS s1 INNER JOIN order_exp2 AS s2 WHERE s1.expire_time>'2021-03-22 18:28:28' AND s1.expire_time<= '2021-03-22 18:35:09' AND s1.order_note > 'xyz';
本查詢和查詢二類似,只不過對于驅動表s1也多了一個order_note > 'xyz’的搜索條件。不過因為本查詢可以使用idx_expire_time索引,所以只需要從符合二級索引范圍區間的記錄中猜有多少條記錄符合order_note > 'xyz’條件,也就是只需要猜在39條記錄中有多少符合order_note > 'xyz’條件。

通過上面4個案例大家可以看到,MySQL很多時候在計算數據的時候很多時候只能靠猜。
MySQL把這個猜的過程稱之為 condition filtering 。當然,這個過程可能會使用到索引,也可能使用到統計數據,也可能就是MySQL單純的瞎猜,整個評估過程非常復雜,所以我們不去細講。
在MySQL 5.7之前的版本中,查詢優化器在計算驅動表扇出時,如果是使用全表掃描的話,就直接使用表中記錄的數量作為扇出值,如果使用索引的話,就直接使用滿足范圍條件的索引記錄條數作為扇出值。
在MySQL 5.7中,MySQL引入了這個condition filtering的功能,就是還要猜一猜剩余的那些搜索條件能把驅動表中的記錄再過濾多少條,其實本質上就是為了讓成本估算更精確。我們所說的純粹瞎猜其實是很不嚴謹的,MySQL稱之為啟發式規則。
1.1.4.2.兩表連接的成本分析
連接查詢的成本計算公式是這樣的:
連接查詢總成本 = 單次訪問驅動表的成本 + 驅動表扇出數 x 單次訪問被驅動表的成本
對于左(外)連接和右(外)連接查詢來說,它們的驅動表是固定的,所以想要得到最優的查詢方案只需要分別為驅動表和被驅動表選擇成本最低的訪問方法。
可是對于內連接來說,驅動表和被驅動表的位置是可以互換的,所以需要考慮兩個方面的問題:
不同的表作為驅動表最終的查詢成本可能是不同的,也就是需要考慮最優的表連接順序。然后分別為驅動表和被驅動表選擇成本最低的訪問方法。
很顯然,計算內連接查詢成本的方式更麻煩一些,下邊我們就以內連接為例來看看如何計算出最優的連接查詢方案。當然在某些情況下,左(外)連接和右(外)連接查詢在某些特殊情況下可以被優化為內連接查詢。
我們來看看內連接,比如對于下邊這個查詢來說:
SELECT*
FROMorder_exp AS s1
INNER JOIN order_exp2 AS s2 ON s1.order_no = s2.order_note
WHERE s1.expire_time > '2021-03-22 18:28:28'
AND s1.expire_time <= '2021-03-22 18:35:09'
AND s2.expire_time > '2021-03-22 18:35:09'
AND s2.expire_time <= '2021-03-22 18:35:59';
可以選擇的連接順序有兩種:
s1連接s2,也就是s1作為驅動表,s2作為被驅動表。
s2連接s1,也就是s2作為驅動表,s1作為被驅動表。
查詢優化器需要分別考慮這兩種情況下的最優查詢成本,然后選取那個成本更低的連接順序以及該連接順序下各個表的最優訪問方法作為最終的查詢計劃。我們定性的分析一下,不像分析單表查詢那樣定量的分析了:
具體都可以使用分析語句來執行
explain format=json SQL語句
1.1.4.4.多表連接的成本分析
首先要考慮一下多表連接時可能產生出多少種連接順序:
對于兩表連接,比如表A和表B連接只有 AB、BA這兩種連接順序。其實相當于2× 1 = 2種連接順序。
對于三表連接,比如表A、表B、表C進行連接有ABC、ACB、BAC、BCA、CAB、CBA這么6種連接順序。其實相當于3 × 2 × 1 = 6種連接順序。
對于四表連接的話,則會有4 × 3 × 2 × 1 = 24種連接順序。對于n表連接的話,則有 n × (n-1) × (n-2) × ··· × 1種連接順序,就是n的階乘種連接順序,也就是n!。
有n個表進行連接,MySQL查詢優化器要每一種連接順序的成本都計算一遍么?那可是n!種連接順序呀。其實真的是要都算一遍,不過MySQL用了很多辦法減少計算非常多種連接順序的成本的方法:
提前結束某種順序的成本評估
MySQL在計算各種鏈接順序的成本之前,會維護一個全局的變量,這個變量表示當前最小的連接查詢成本。如果在分析某個連接順序的成本時,該成本已經超過當前最小的連接查詢成本,那就壓根兒不對該連接順序繼續往下分析了。比方說A、B、C三個表進行連接,已經得到連接順序ABC是當前的最小連接成本,比方說10.0,在計算連接順序BCA時,發現B和C的連接成本就已經大于10.0時,就不再繼續往后分析BCA這個連接順序的成本了。
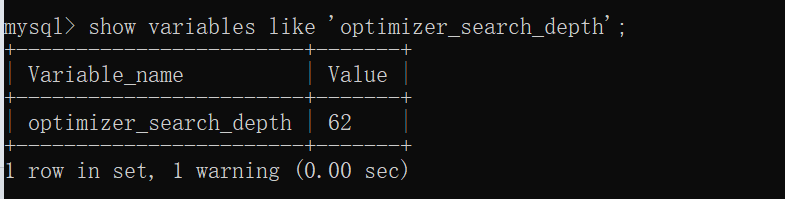
系統變量optimizer_search_depth
為了防止無窮無盡的分析各種連接順序的成本,MySQL提出了optimizer_search_depth系統變量,如果連接表的個數小于該值,那么就繼續窮舉分析每一種連接順序的成本,否則只對與optimizer_search_depth值相同數量的表進行窮舉分析。很顯然,該值越大,成本分析的越精確,越容易得到好的執行計劃,但是消耗的時間也就越長,否則得到不是很好的執行計劃,但可以省掉很多分析連接成本的時間。
根據某些規則壓根兒就不考慮某些連接順序
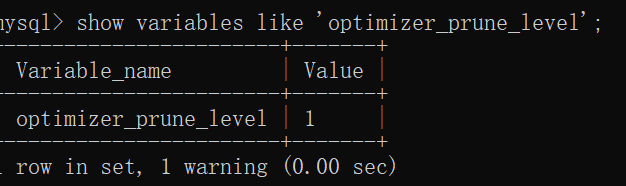
即使是有上邊兩條規則的限制,但是分析多個表不同連接順序成本花費的時間還是會很長,所以MySQL干脆提出了一些所謂的啟發式規則(就是根據以往經驗指定的一些規則),凡是不滿足這些規則的連接順序壓根兒就不分析,這樣可以極大的減少需要分析的連接順序的數量,但是也可能造成錯失最優的執行計劃。他們提供了一個系統變量optimizer_prune_level來控制到底是不是用這些啟發式規則。
1.1.5.調節成本常數
我們前邊已經介紹了兩個成本常數:
讀取一個頁面花費的成本默認是1.0
檢測一條記錄是否符合搜索條件的成本默認是0.2
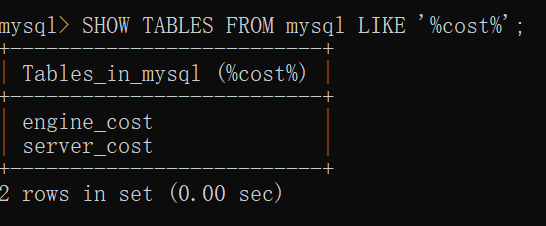
其實除了這兩個成本常數,MySQL還支持很多,它們被存儲到了MySQL數據庫的兩個表中:
SHOW TABLES FROM mysql LIKE '%cost%';
因為一條語句的執行其實是分為兩層的:server層、存儲引擎層。
在server層進行連接管理、查詢緩存、語法解析、查詢優化等操作,在存儲引擎層執行具體的數據存取操作。也就是說一條語句在server層中執行的成本是和它操作的表使用的存儲引擎是沒關系的,所以關于這些操作對應的成本常數就存儲在了server_cost表中,而依賴于存儲引擎的一些操作對應的成本常數就存儲在了engine_cost表中。
1.1.5.1.mysql.server_cost表
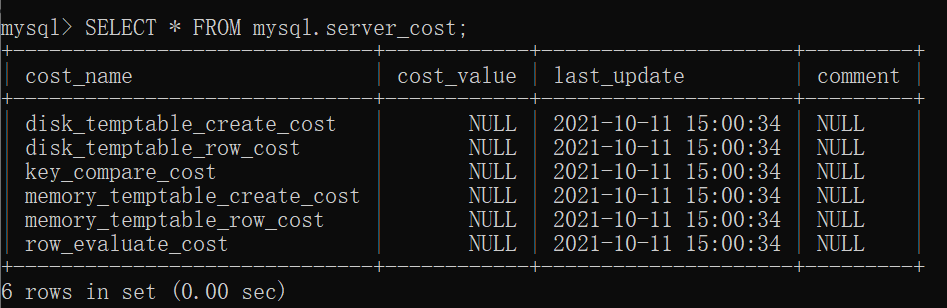
server_cost表中在server層進行的一些操作對應的成本常數,具體內容如下:
SELECT * FROM mysql.server_cost;
我們先看一下server_cost各個列都分別是什么意思:
cost_name
表示成本常數的名稱。
cost_value
表示成本常數對應的值。如果該列的值為NULL的話,意味著對應的成本常數會采用默認值。
last_update
表示最后更新記錄的時間。
comment
注釋。
從server_cost中的內容可以看出來,目前在server層的一些操作對應的成本常數有以下幾種:
disk_temptable_create_cost 默認值40.0
創建基于磁盤的臨時表的成本,如果增大這個值的話會讓優化器盡量少的創建基于磁盤的臨時表。
disk_temptable_row_cost 默認值1.0
向基于磁盤的臨時表寫入或讀取一條記錄的成本,如果增大這個值的話會讓優化器盡量少的創建基于磁盤的臨時表。
key_compare_cost 0.1
兩條記錄做比較操作的成本,多用在排序操作上,如果增大這個值的話會提升filesort的成本,讓優化器可能更傾向于使用索引完成排序而不是filesort。
memory_temptable_create_cost 默認值2.0
創建基于內存的臨時表的成本,如果增大這個值的話會讓優化器盡量少的創建基于內存的臨時表。
memory_temptable_row_cost 默認值0.2
向基于內存的臨時表寫入或讀取一條記錄的成本,如果增大這個值的話會讓優化器盡量少的創建基于內存的臨時表。
row_evaluate_cost 默認值0.2
這個就是我們之前一直使用的檢測一條記錄是否符合搜索條件的成本,增大這個值可能讓優化器更傾向于使用索引而不是直接全表掃描。
MySQL在執行諸如DISTINCT查詢、分組查詢、Union查詢以及某些特殊條件下的排序查詢都可能在內部先創建一個臨時表,使用這個臨時表來輔助完成查詢(比如對于DISTINCT查詢可以建一個帶有UNIQUE索引的臨時表,直接把需要去重的記錄插入到這個臨時表中,插入完成之后的記錄就是結果集了)。在數據量大的情況下可能創建基于磁盤的臨時表,也就是為該臨時表使用MyISAM、InnoDB等存儲引擎,在數據量不大時可能創建基于內存的臨時表,也就是使用Memory存儲引擎。大家可以看到,創建臨時表和對這個臨時表進行寫入和讀取的操作代價還是很高的就行了。
這些成本常數在server_cost中的初始值都是NULL,意味著優化器會使用它們的默認值來計算某個操作的成本,如果我們想修改某個成本常數的值的話,需要做兩個步驟:
對我們感興趣的成本常數做update更新操作,然后使用下邊語句即可:
FLUSH OPTIMIZER_COSTS;
當然,在你修改完某個成本常數后想把它們再改回默認值的話,可以直接把cost_value的值設置為NULL,再使用FLUSH OPTIMIZER_COSTS語句讓系統重新加載。
1.1.5.2.mysql.engine_cost表
engine_cost表表中在存儲引擎層進行的一些操作對應的成本常數,具體內容如下:
SELECT * FROM mysql.engine_cost;

與server_cost相比,engine_cost多了兩個列:
engine_name列
指成本常數適用的存儲引擎名稱。如果該值為default,意味著對應的成本常數適用于所有的存儲引擎。
device_type列
指存儲引擎使用的設備類型,這主要是為了區分常規的機械硬盤和固態硬盤,不過在MySQL 5.7.X這個版本中并沒有對機械硬盤的成本和固態硬盤的成本作區分,所以該值默認是0。
我們從engine_cost表中的內容可以看出來,目前支持的存儲引擎成本常數只有兩個:
io_block_read_cost 默認值1.0
從磁盤上讀取一個塊對應的成本。請注意我使用的是塊,而不是頁這個詞。對于InnoDB存儲引擎來說,一個頁就是一個塊,不過對于MyISAM存儲引擎來說,默認是以4096字節作為一個塊的。增大這個值會加重I/O成本,可能讓優化器更傾向于選擇使用索引執行查詢而不是執行全表掃描。
memory_block_read_cost 默認值1.0
與上一個參數類似,只不過衡量的是從內存中讀取一個塊對應的成本。
怎么從內存中和從磁盤上讀取一個塊的默認成本是一樣的?這主要是因為在MySQL目前的實現中,并不能準確預測某個查詢需要訪問的塊中有哪些塊已經加載到內存中,有哪些塊還停留在磁盤上,所以MySQL簡單的認為不管這個塊有沒有加載到內存中,使用的成本都是1.0。
與更新server_cost表中的記錄一樣,我們也可以通過更新engine_cost表中的記錄來更改關于存儲引擎的成本常數,做法一樣。


)
)

)

)











