C++入門
首先第一點,C++中可以混用C語言中的語法。但是C語言是不兼容C++的。C++主要是為了改進C語言而創建的一門語言,就是有人用C語言用不爽了,改出來個C++。
命名空間
c語言中會有如下這樣的問題:
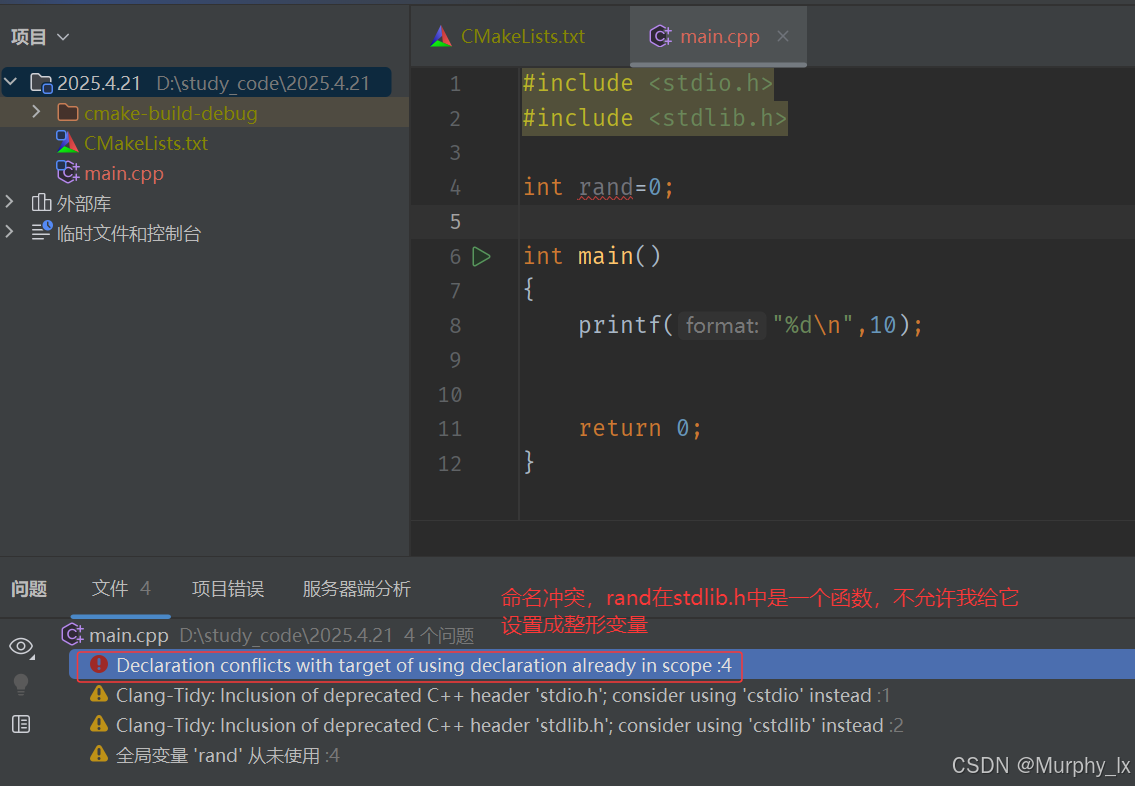
那么C++為了解決這個問題就整出了一個命名空間。因為在日常作業中,我們為了使得代碼的意思更加明確,我們創建的變量和函數有時候就會和c語言庫里面創建的變量或者函數命名沖突。
或者是我和同事之間寫的沖突,因為有可能大家負責不同板塊,但是都要用到這個名字去定義一個函數或者變量,分開的時候沒啥事,整合到一起就沖突了。
在C/C++中,變量、函數和后面要學到的類都是大量存在的,這些變量、函數和類的名稱將都存 在于全局作用域中,可能會導致很多沖突。使用命名空間的目的是對標識符的名稱進行本地化, 以避免命名沖突或名字污染,namespace關鍵字的出現就是針對這種問題的。
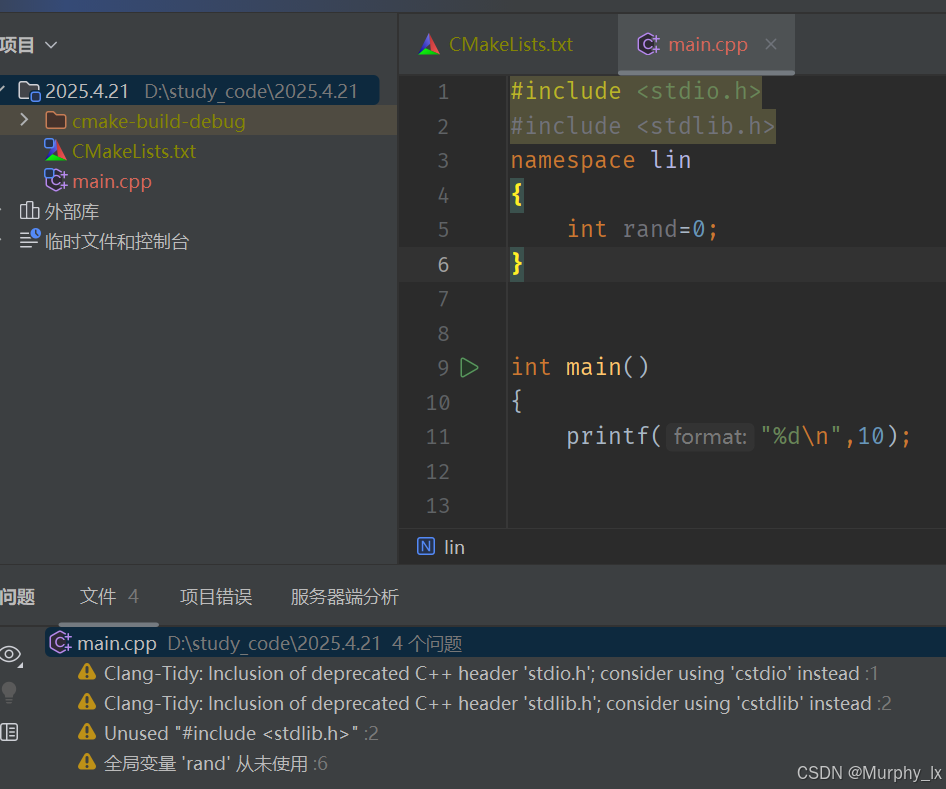
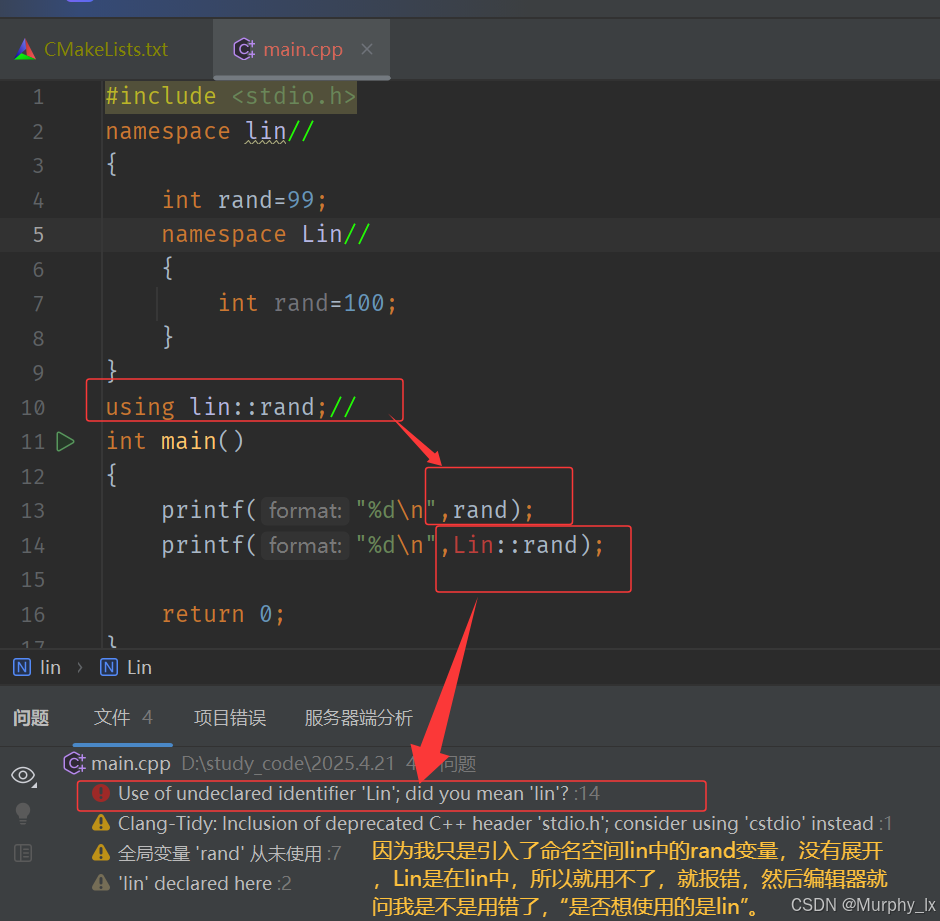
可以看到,當我把我創建出來的那個rand變量放進我創建的一個命名空間lin中,就不會有報錯了。
定義命名空間,需要使用到namespace關鍵字,后面跟命名空間的名字,然后接一對{}即可,{} 中即為命名空間的成員。
命名空間的名字盡量有意義些,一般最好不要和庫里面的命名空間重復。不然還是有較大概率沖突的。
注意事項
-
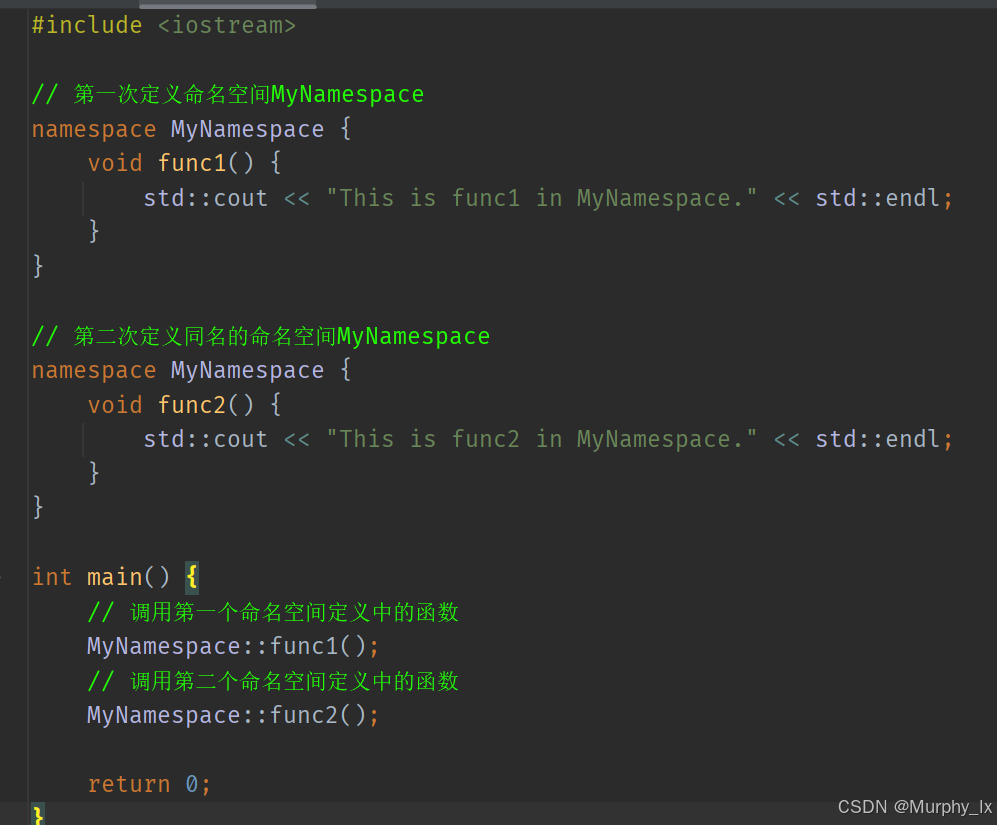
在 C++ 里,命名空間的名字是可以重復的。當重復定義命名空間時,這些同名的命名空間實際上會合并成一個命名空間,各個定義中的成員會被整合在一起。
-
命名空間的名字是區分大小寫的。
-
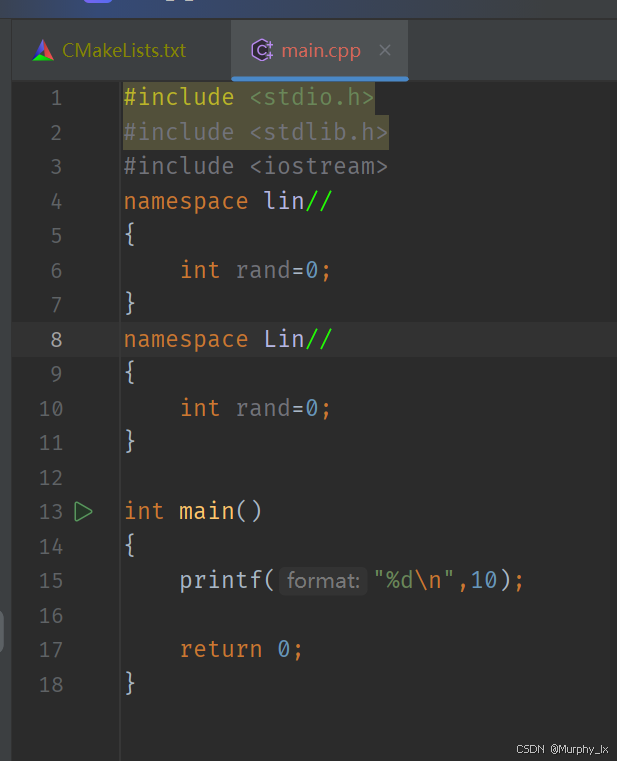
成員沖突:若在不同的同名命名空間定義中存在同名的成員,就會引發沖突,編譯時會報錯。
-
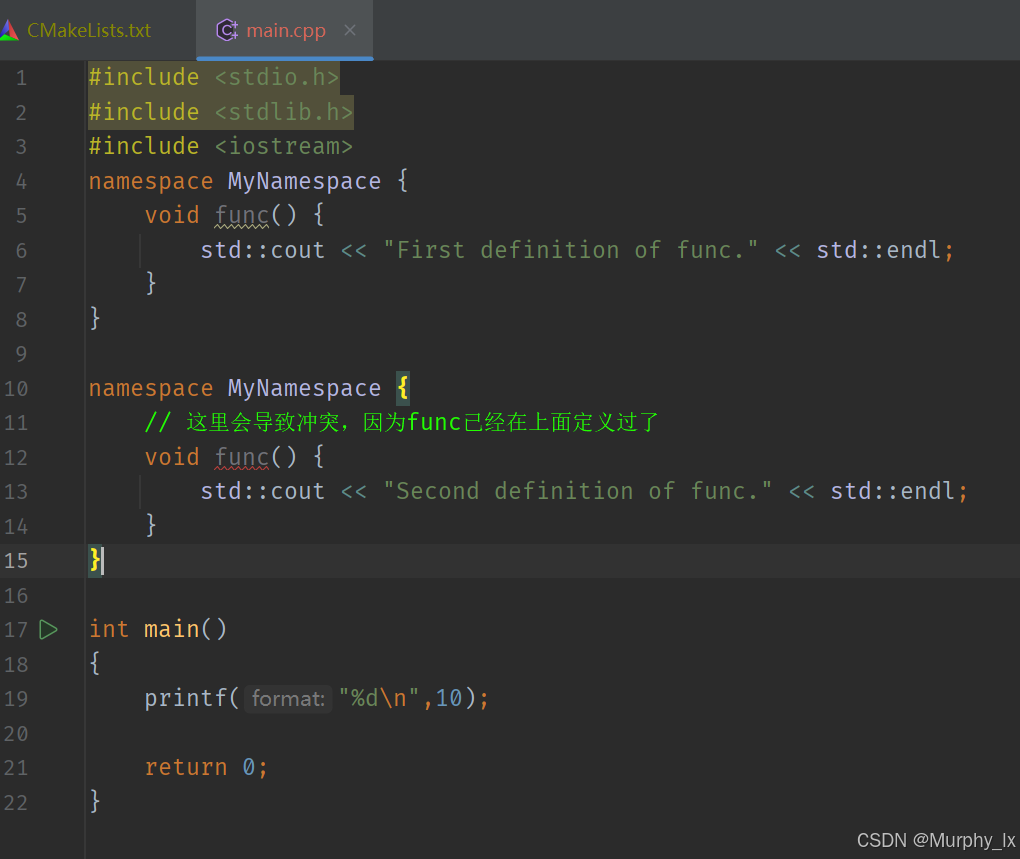
組織代碼:利用同名命名空間合并的特性,可將一個大型的命名空間拆分成多個文件進行定義,以此來組織代碼。例如,在不同的頭文件里定義同一個命名空間的不同部分,最后將這些頭文件包含到源文件中,就能夠使用完整的命名空間成員。
-
-
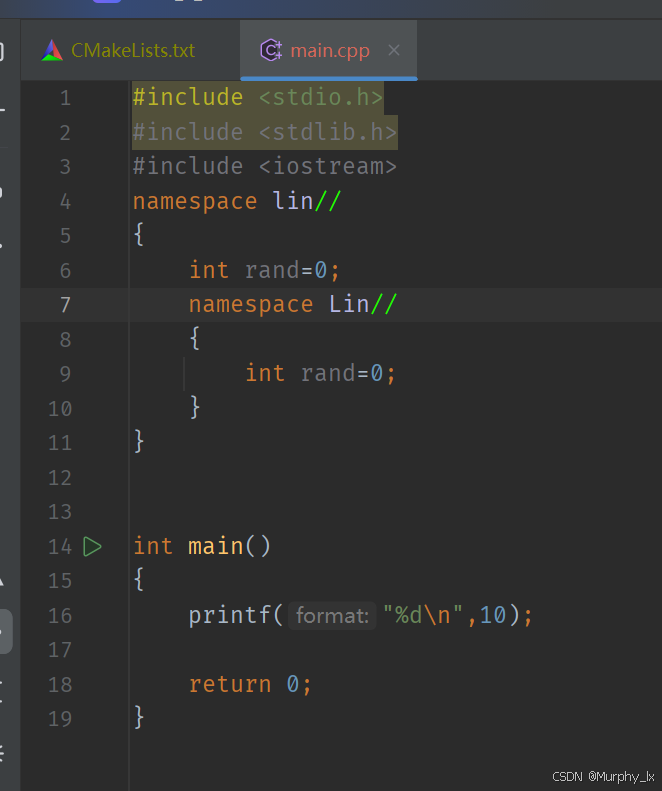
命名空間可以嵌套定義。也就是在一個命名空間內部能夠定義另一個命名空間。
命名空間的使用:
-
加命名空間名稱及作用域限定符:
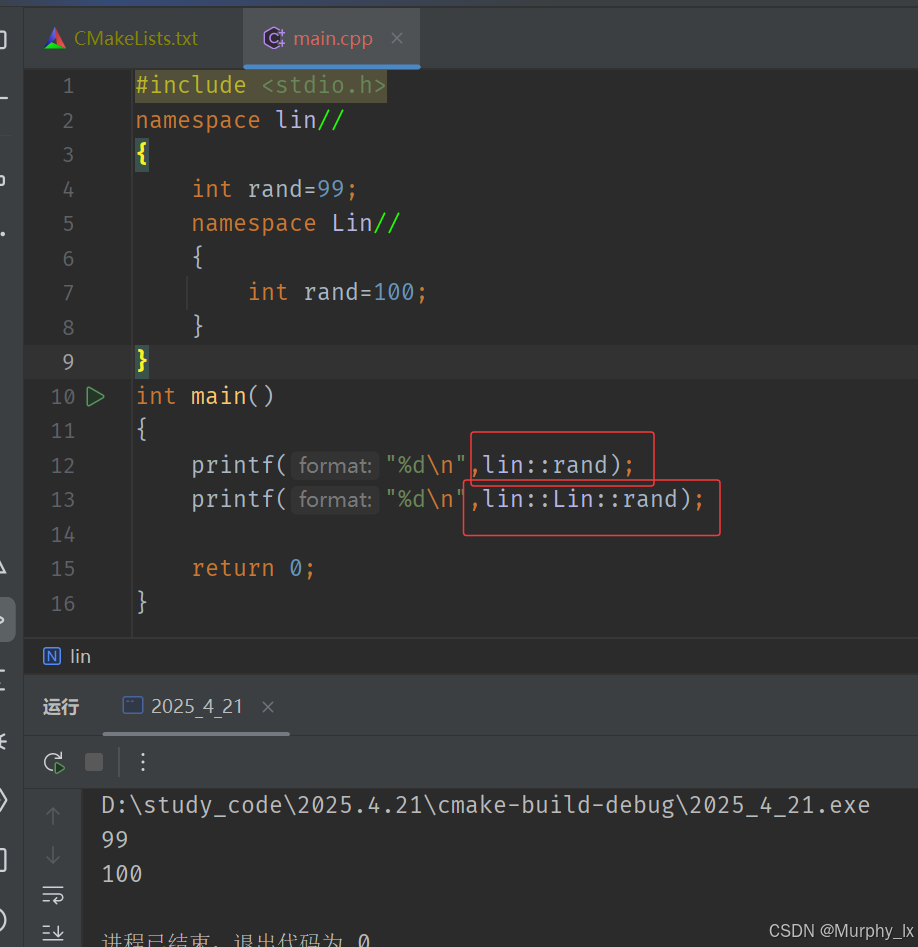
這樣使用起來就比較麻煩了。 -
使用using將命名空間中某個成員引入:
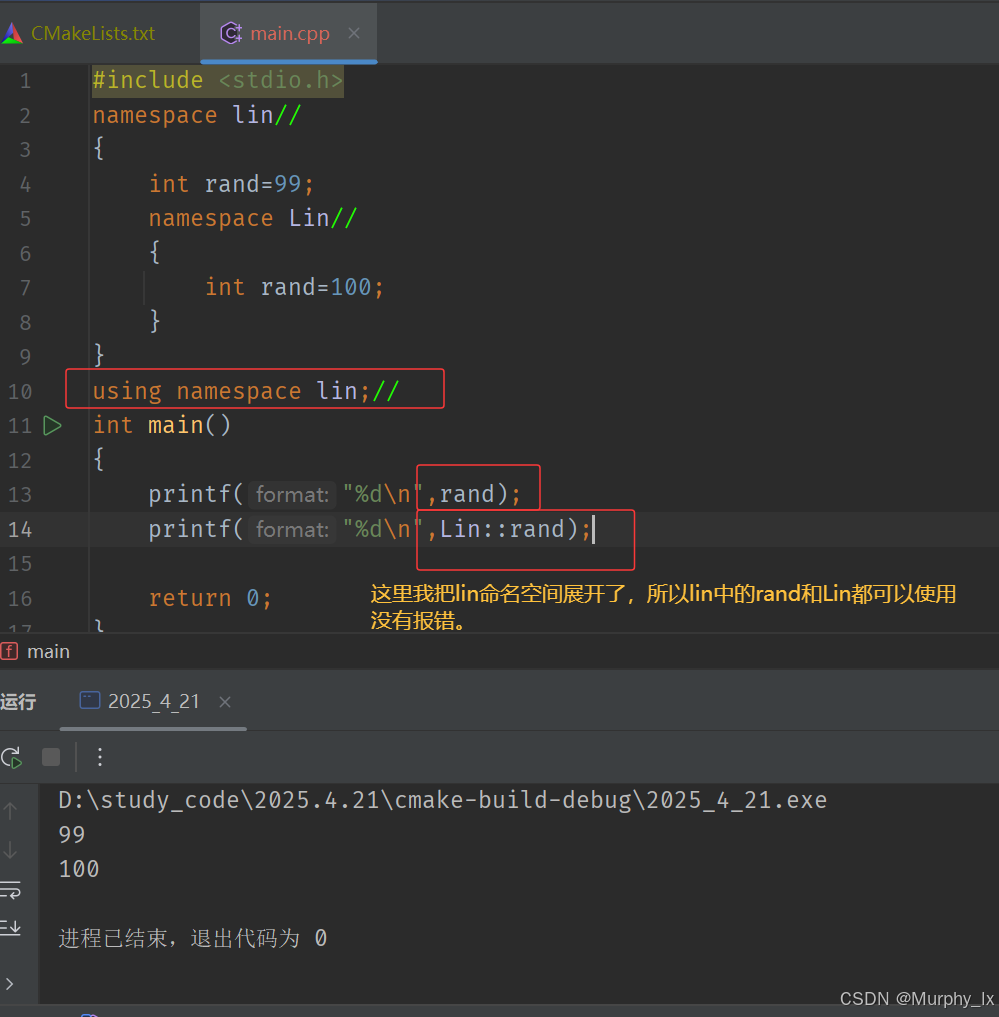
- 使用using namespace 命名空間名稱 引入:
"::"這個符號是域作用限定符。
注意事項:
- 在日常作業中,我們一般最好是不要使用第三種方式使用命名空間,尤其是C++官方庫中的命名空間std。我們一般使用的方式是第二種,“使用using將命名空間中某個成員引入”。這樣既可以方便使用,又可以避免一些不必要的麻煩。
- 畢竟使用命名空間把相關內容圈起來,肯定是不想你隨意就展開的,這樣命名空間的意義就不大了。當然了,如果只是平日的代碼練習,直接展開也無礙,但是盡量形成良好的使用習慣。
輸入(流提取)輸出(流插入)
說明:
-
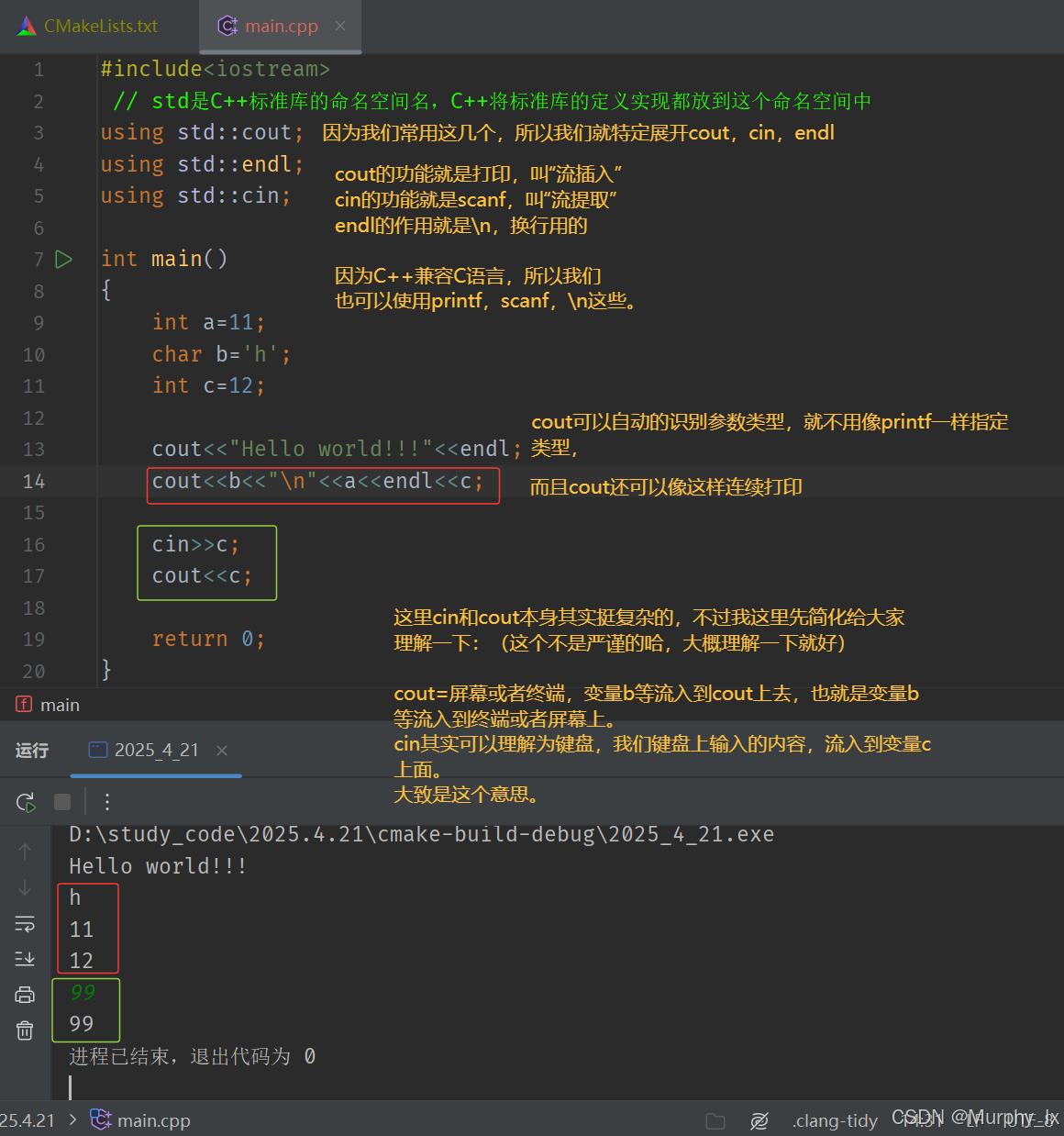
使用cout標準輸出對象(控制臺)和cin標準輸入對象(鍵盤)時,必須包含< iostream >頭文件 以及按命名空間使用方法使用std。
-
cout和cin是全局的流對象,endl是特殊的C++符號,表示換行輸出,他們都包含在包含< iostream >頭文件中。
-
<<是流插入運算符,>>是流提取運算符。
-
使用C++輸入輸出更方便,不需要像printf/scanf輸入輸出時那樣,需要手動控制格式。 C++的輸入輸出可以自動識別變量類型。
-
實際上cout和cin分別是ostream和istream類型的對象,>>和<<也涉及運算符重載等知識, 這些知識我們我們后續才會學習,所以我們這里只是簡單學習他們的使用。后面我們還有有 一個章節更深入的學習IO流用法及原理。
-
關于cout和cin還有很多更復雜的用法,比如控制浮點數輸出精度,控制整形輸出進制格式等 等。因為C++兼容C語言的用法,這些又用得不是很多,我們這里就不展開學習了。
缺省參數
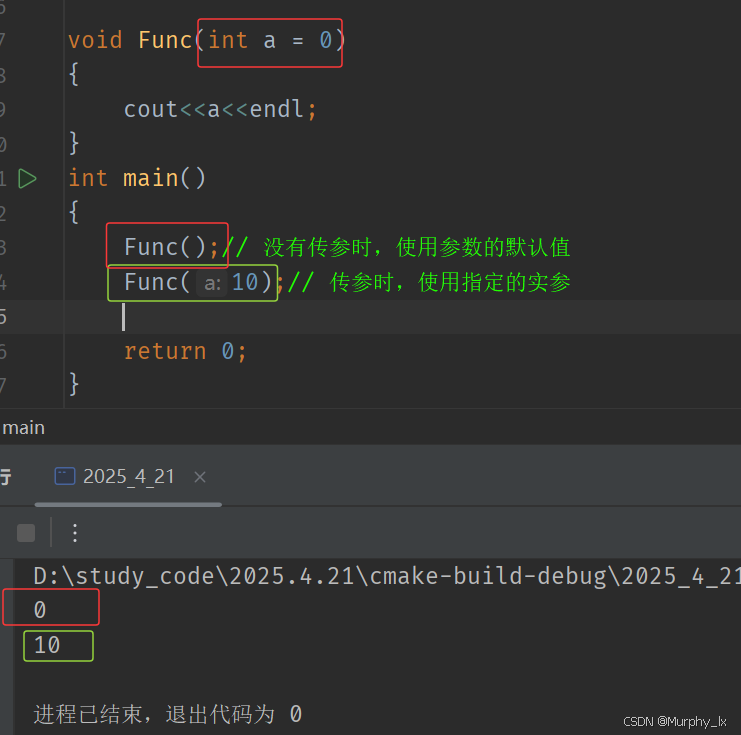
缺省參數是聲明或定義函數時為函數的參數指定一個缺省值。在調用該函數時,如果沒有指定實參則采用該形參的缺省值,否則使用指定的實參。
給大家舉個生活中的例子:你有個異性朋友,你很喜歡她/他。你這個異性朋友平時呢對你愛搭不理,因為他/她平時有很多比你更好的選項,她/他就去找別人玩。不過有時候呢,你這個異性朋友也有無聊的時候,沒人找他/她玩,這個時候,她/他就想到你了,她/他也知道你喜歡她/他。她/他就會跟逗狗一樣的逗你玩玩,或者讓你陪她/他看個電影吃個飯,把錢給付了。然后就又忘記你,找別人去了。
懂?
誒,所以說做人不要當“缺省參數”。明白不?別TM當舔狗,當備胎。
不過“缺省參數”在C++中是條好狗,還是很好用的有時候。
缺省參數分類
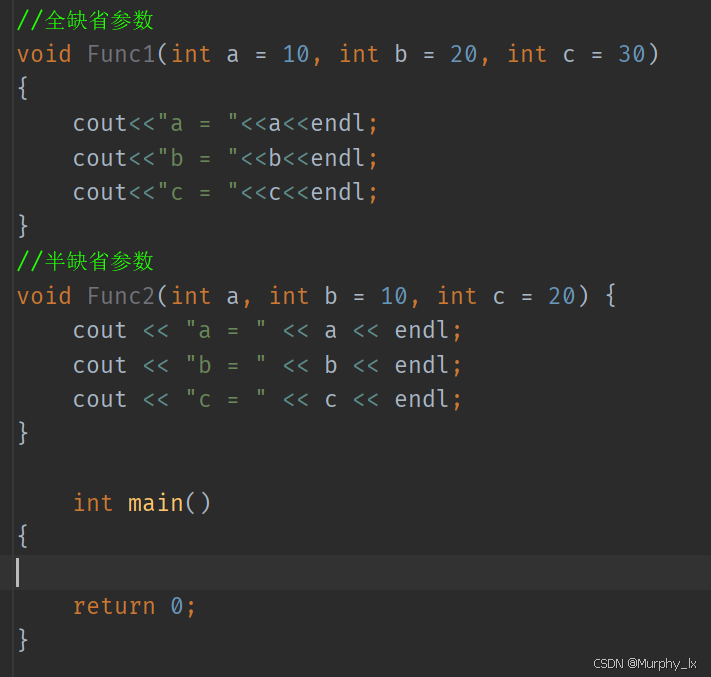
- 全缺省參數
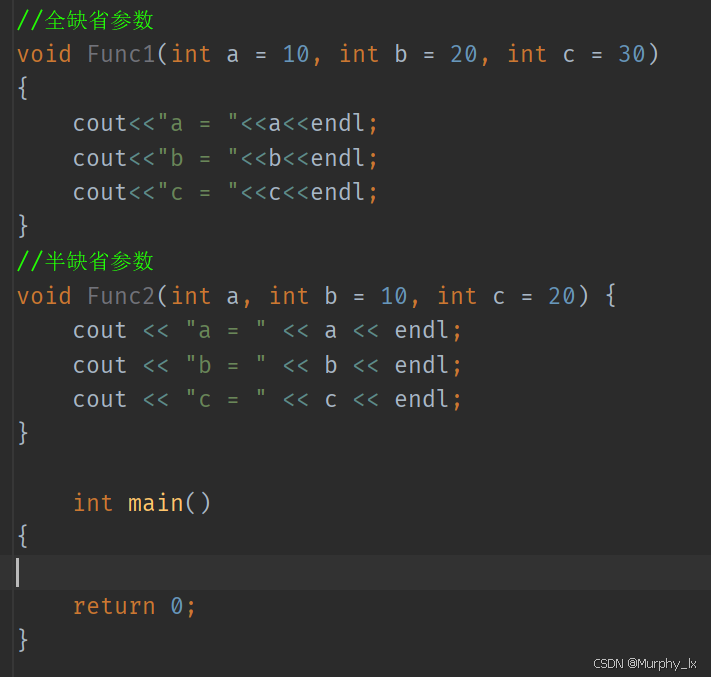
- 半缺省參數
注意:
- 半缺省參數必須從右往左依次來給出,不能間隔著給 ,必須是連續的給。
- 傳參數的時候也是,必須連續的傳,不能間隔,跳躍的傳參數,而且必須從左往右傳。
- 缺省參數不能在函數聲明和定義中同時出現。缺省參數規定只能在函數聲明時設置好,定義的時候就不用再設置缺省參數了。
- 如果聲明與定義位置同時出現缺省參數,恰巧兩個位置提供的值不同,那編譯器就無法確定到底該用那個缺省值。就存在歧義了。
函數重載
函數重載就是可以有重名函數,但是重名函數之間的參數不同。
參數不同又有哪幾種不同呢?
- 參數類型不同
- 參數類型不同中有一種是參數個數相同,但是參數類型的順序不同
- 參數個數不同
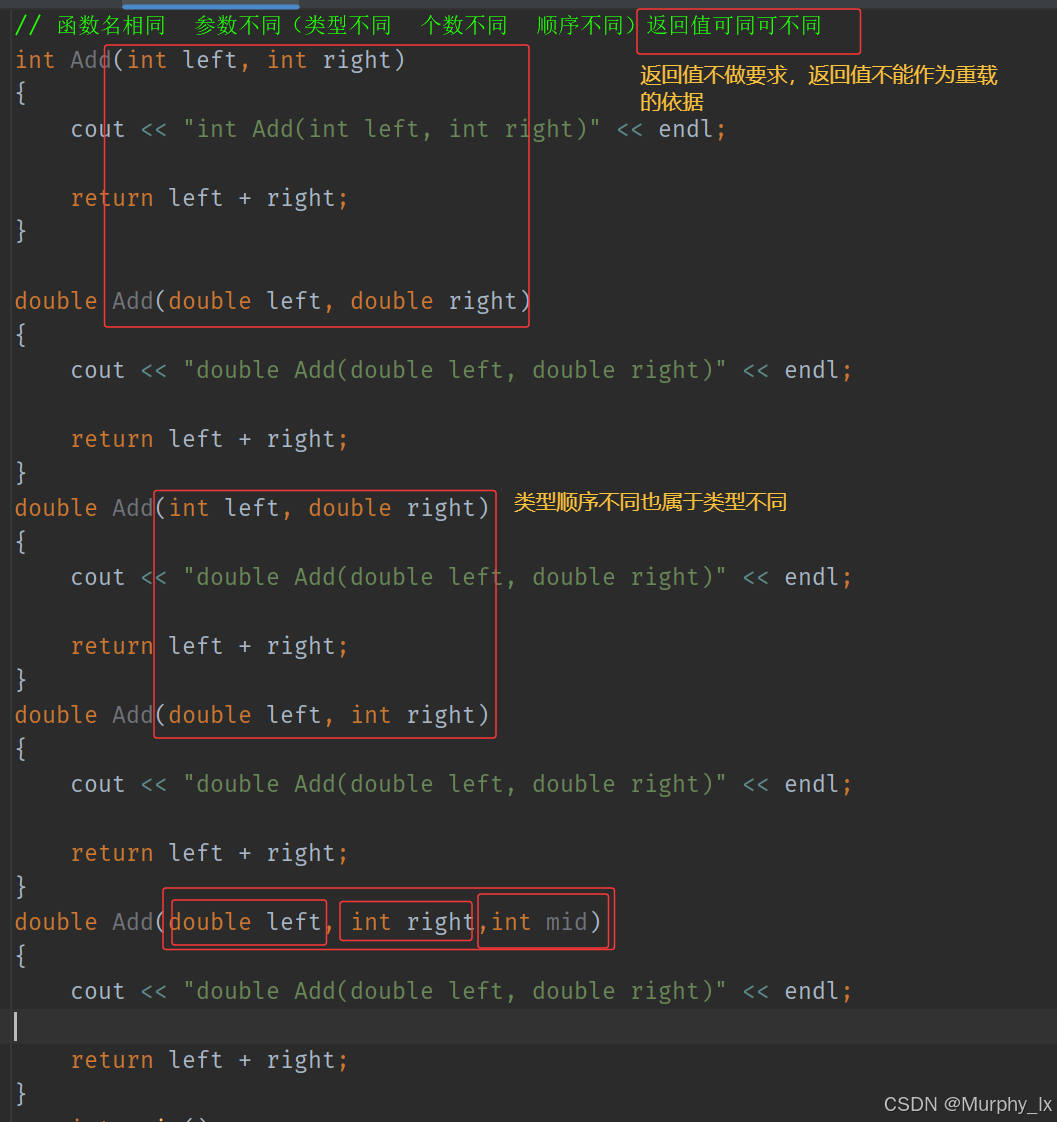
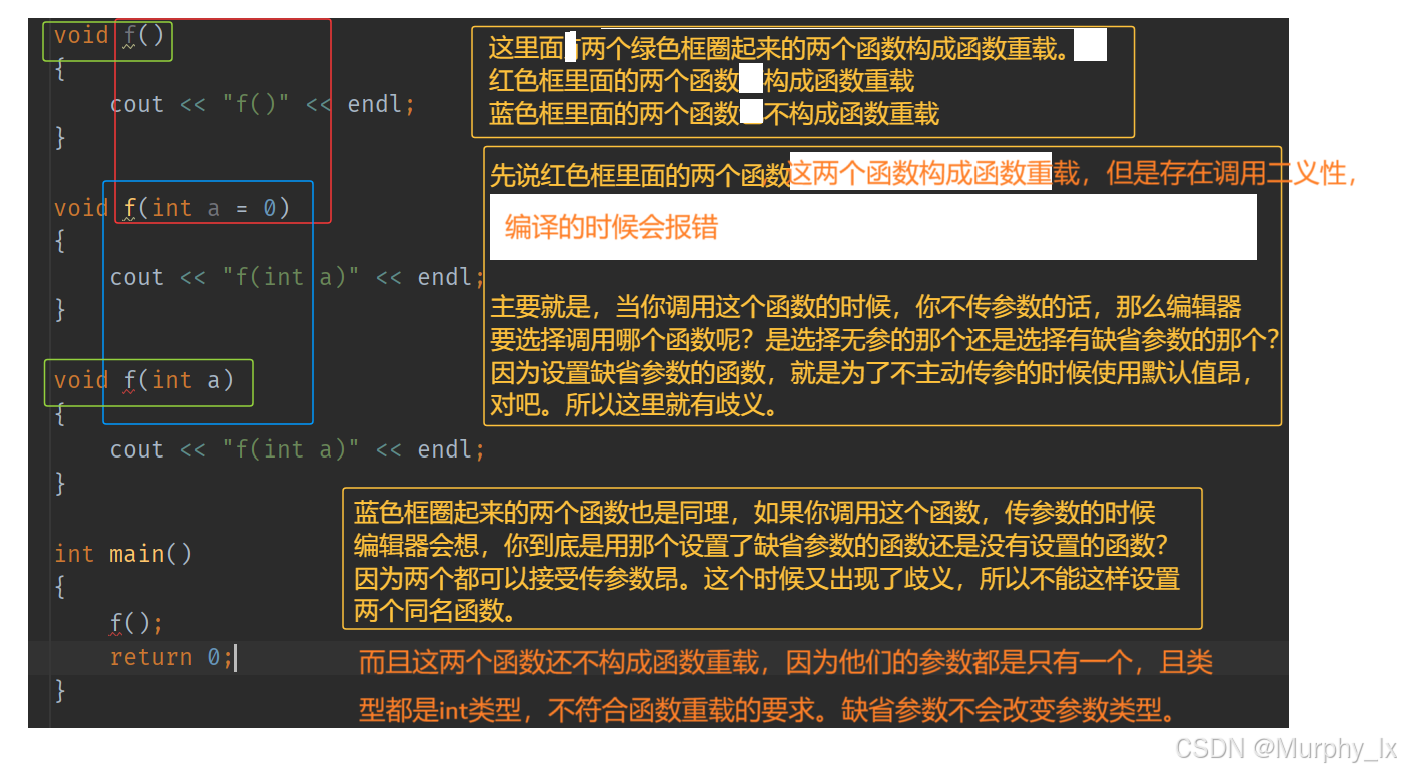
看了這兩幅圖的解釋之后,順便說一下為什么返回值不能作為函數重載的依據,一樣的,因為調用二義性。你只有返回值不同,鬼知道你到底要用哪個函數,對吧。
int func()
{return 0;
}double func()
{return 1.1;
}
來,你調用func()的時候,你說,你要調用哪個函數。這不就歧義了嘛,對吧。
這里還有個麻煩事,就是為什么C++支持函數重載,C語言不支持,這里我就不細說了,我把老師講課的時候畫的圖給大家放出來,大家自己看看吧,我就不再講了。
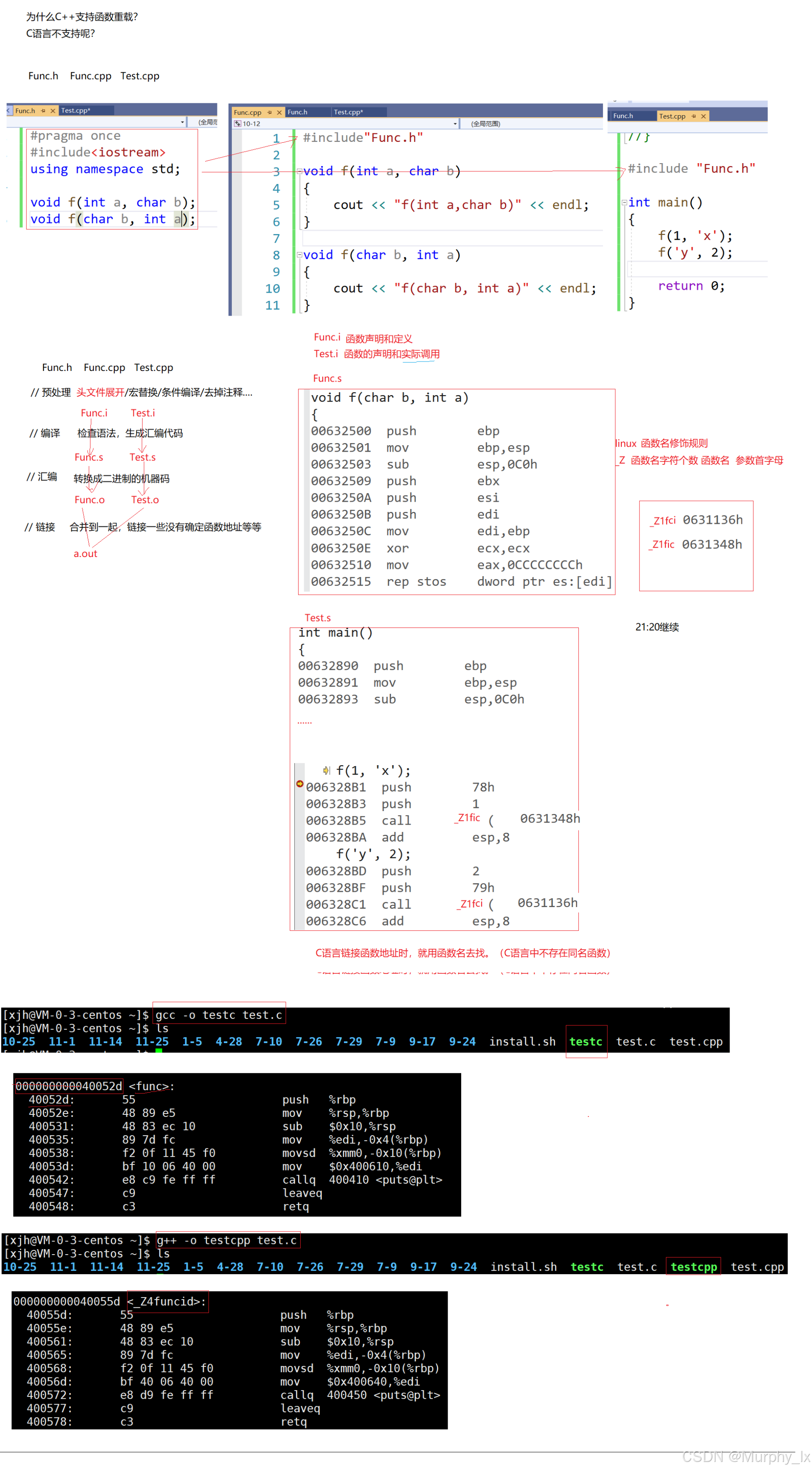
引用
引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空 間,它和它引用的變量共用同一塊內存空間。
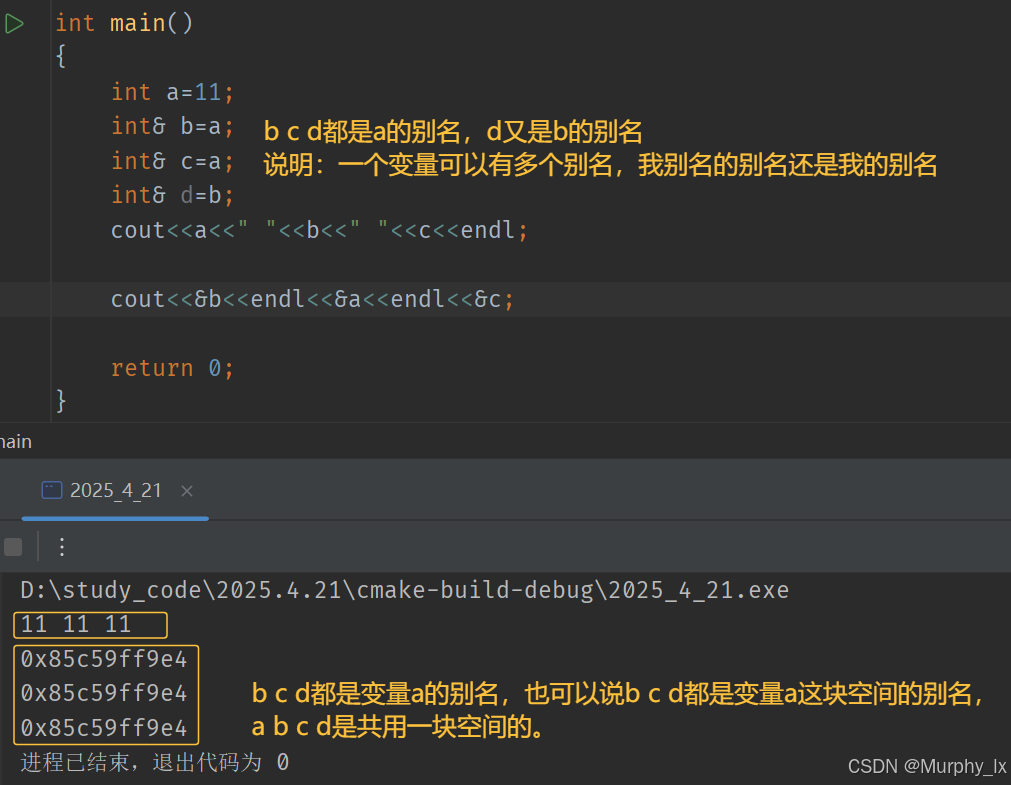
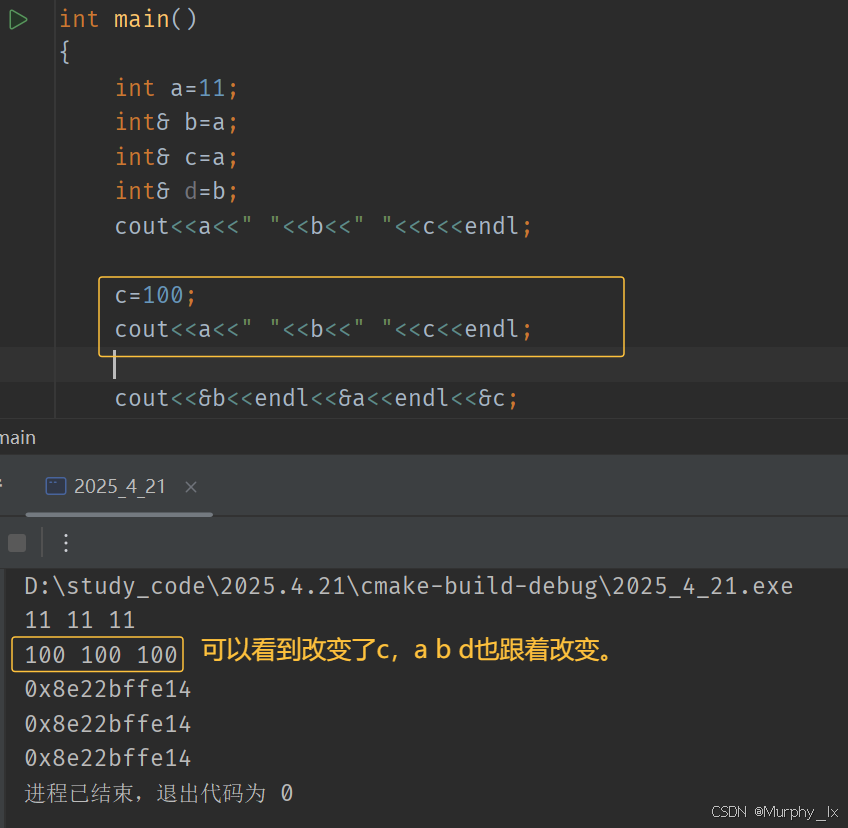
這就像啥,像孫悟空似的,a是孫悟空,b是齊天大圣,c是弼馬溫,d是大圣,d是b的別名,總的來說b c d都指向著a:孫悟空。
注意:
- 引用在定義時必須初始化
- 一個變量可以有多個引用
- 引用一旦引用一個實體,再不能引用其他實體。也就是說,你不能既是a的別名,還是另一個別的變量的別名
void TestRef(){int a = 10;int b = 100;// int& ra; // 該條語句編譯時會出錯int& ra = a;// int& ra = b;//這個也是會報錯的,不能引用多個實體int& rra = a;printf("%p %p %p\n", &a, &ra, &rra);
}
常引用
void TestConstRef(){const int a = 10;//int& ra = a; // 該語句編譯時會出錯,a為常量const int& ra = a;// int& b = 10; // 該語句編譯時會出錯,b為常量const int& b = 10;double d = 12.34;//int& rd = d; // 該語句編譯時會出錯,類型不同const int& rd = d;}
double d = 12.34;//int& rd = d; // 該語句編譯時會出錯,類型不同const int& rd = d;
這里大家可以會疑惑上面那個,為啥 //int& rd = d; // 該語句編譯時會出錯,類型不同,但是加了一個const修飾就可以了呢?首先呢大家可以看到,這里是double類型隱式轉換為int類型,這種類型轉換之間都會產生一個臨時變量,啥意思呢?意思就是隱式類型轉換不是原來那個變量真的改變類型了,是用了一個臨時變量存儲了改變類型的原變量。用這里的例子就是,不是變量d真的變成了int類型,而是有一個臨時變量存儲了變量d變成int類型的值,然后賦值給變成新變量rd,這個臨時變量是一個常量,所以引用的時候也要加一個const修飾。就像給常量10取別名一樣。
// 權限不能放大
const int a = 10;
//int& b = a;//這樣會報錯
//大概意思就是:
//菩薩讓孫悟空護唐僧取經,不能說你換個別名叫大圣了就不去護唐僧取經了
//或者說:小明在家里爸媽叫他有兩個稱呼,一個叫小明,一個是兒子
//現在爸媽不允許兒子吃飯,難道小明可以說:我叫小明,我可以吃飯。
//可以這樣嗎?不可以!
//這就類似權限的放大,你該干啥就要干啥,你不能干啥就不能干啥。
const int& b = a;// 權限可以縮小
int c = 20;
const int& d = c;
const int& e = 10;
在語法概念上引用就是一個別名,沒有獨立空間,和其引用實體共用同一塊空間。
在底層實現上實際是有空間的,因為引用是按照指針方式來實現的。
下面這幅圖是反匯編:

在C++中引用是無法完全替換指針的,指針和引用更多是相輔相成,引用是優化了一些原來C語言使用指針麻煩的地方。
引用和指針的不同點:
- 引用概念上定義一個變量的別名,指針存儲一個變量地址。
- 引用在定義時必須初始化,指針沒有要求
- 引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何 一個同類型實體。比如指針a本來是變量1的地址,但是后面你想讓指針a變成變量2的地址,這是可以的。但是引用就不行,引用一旦確定,就不能再改變它引用的實體,也就是說引用無法改變指向,所以在一些需要改變指向的功能中,就只能使用指針。
- 沒有NULL引用,但有NULL指針
- 在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32 位平臺下占4個字節)
- 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小
- 有多級指針,但是沒有多級引用
- 訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理
- 引用比指針使用起來相對更安全
使用場景
引用一般兩個使用場景,一個是:做參數,一個是:做返回值。
兩種場景使用引用之后的主要效果都是:提高程序運行效率。
做參數的時候:(我們以傳值和傳引用做比較)
- 傳值:在調用函數時,會把實參的值復制一份給形參。函數內部操作的是這個復制的值,而并非實參本身。所以,函數內部對形參的修改不會影響到實參。
- 傳引用:調用函數時,傳遞給形參的是實參的引用,也就是實參的內存地址。函數內部對形參的操作實際上就是對實參本身進行操作,因此函數內部對形參的修改會影響到實參。
性能開銷
- 傳值:由于需要復制實參的值,當實參是較大的對象(如大型結構體、類對象)時,復制操作會消耗較多的時間和內存。
- 傳引用:只需要傳遞對象的引用(內存地址),無需復制對象本身,所以在處理大型對象時,傳引用的性能開銷通常比傳值小。
數據安全性
- 傳值:函數內部無法修改實參的值,因此實參的數據在函數調用過程中是安全的。
- 傳引用:函數內部可以直接修改實參的值,這可能會導致意外的數據修改。若不希望函數修改實參的值,可以使用
const引用。示例如下:
#include <iostream>// 使用 const 引用,防止函數內部修改實參
void printValue(const int& num) {std::cout << "num 的值: " << num << std::endl;// num = 20; // 編譯錯誤,不能修改 const 引用的值
}int main() {int num = 10;printValue(num);return 0;
}
引用做返回值的時候
在 C++ 中,使用引用作為函數的返回值有特定的條件、會產生相應的效果,同時也存在一些潛在的隱患。
使用引用做返回值的條件
1. 返回的對象必須在函數外部仍然有效
當函數返回一個引用時,這個引用所指向的對象必須在函數調用結束后仍然存在于內存中。如果返回的是函數內部的局部對象的引用,會導致未定義行為,因為局部對象在函數結束時會被銷毀。因此,通常可以返回以下幾種類型的引用:
- 全局變量或靜態變量的引用:全局變量和靜態變量的生命周期是整個程序運行期間,函數返回它們的引用是安全的。
#include <iostream>// 全局變量
int globalVar = 10;// 返回全局變量的引用
int& getGlobalVar() {return globalVar;
}// 靜態變量
int& getStaticVar() {static int staticVar = 20;return staticVar;
}int main() {int& ref1 = getGlobalVar();int& ref2 = getStaticVar();std::cout << "Global var: " << ref1 << std::endl;std::cout << "Static var: " << ref2 << std::endl;return 0;
}
- 作為參數傳入的對象的引用:如果函數接受一個對象的引用作為參數,那么可以安全地返回這個引用。
#include <iostream>int& modifyValue(int& num) {num *= 2;return num;
}int main() {int value = 5;int& result = modifyValue(value);std::cout << "Modified value: " << result << std::endl;return 0;
}
- 對象成員的引用:如果函數是類的成員函數,并且返回類對象的成員的引用,只要對象本身在函數調用結束后仍然有效,這種返回方式就是安全的。
#include <iostream>class MyClass {
public:int data;int& getData() {return data;}
};int main() {MyClass obj;obj.data = 10;int& ref = obj.getData();std::cout << "Data: " << ref << std::endl;return 0;
}
2. 函數的返回類型必須是引用類型
函數的返回類型需要明確指定為引用類型,即在類型后面加上 &。例如:
int& func(); // 返回 int 類型的引用
使用引用做返回值的效果
1. 避免復制開銷
返回引用可以避免對返回對象進行復制,特別是對于大型對象,這樣可以提高程序的性能。例如:
#include <iostream>
#include <vector>// 返回向量的引用
std::vector<int>& getVector(std::vector<int>& vec) {return vec;
}int main() {std::vector<int> myVector = {1, 2, 3};std::vector<int>& result = getVector(myVector);// 沒有進行復制操作,result 直接引用 myVectorreturn 0;
}
2. 可以作為左值使用
返回引用的函數可以作為左值,即可以出現在賦值語句的左邊。這使得函數調用可以直接修改所引用的對象。
#include <iostream>int& getValue(int& num) {return num;
}int main() {int value = 5;getValue(value) = 10; // 函數調用作為左值std::cout << "Value: " << value << std::endl;return 0;
}
使用引用做返回值的隱患
1. 懸空引用
如果返回的引用指向的對象在函數調用結束后被銷毀,就會產生懸空引用。訪問懸空引用會導致未定義行為,可能會使程序崩潰或產生不可預測的結果。
#include <iostream>// 錯誤示例:返回局部變量的引用
int& getLocalValue() {int local = 10;return local; // 局部變量在函數結束時被銷毀
}int main() {int& ref = getLocalValue();std::cout << ref << std::endl; // 懸空引用,未定義行為return 0;
}
2. 數據修改的風險
由于返回的引用可以直接修改所引用的對象,可能會導致意外的數據修改,特別是在多線程環境下,這種風險會更加明顯。因此,在使用引用返回值時,需要謹慎考慮數據的安全性。
3. 代碼可讀性降低
過多使用引用返回值可能會使代碼的可讀性降低,因為引用的使用可能會讓代碼的邏輯變得復雜,尤其是在涉及多個函數調用和引用傳遞的情況下。開發者需要更加仔細地理解代碼的執行流程和數據流向。
內聯函數
那么內聯函數主要是改變C語言中的啥呢?主要改變的是宏定義的問題。
宏定義
宏定義是在預處理階段由預處理器處理的,它利用 #define 指令把一個標識符定義為一個字符串。在編譯代碼之前,預處理器會將代碼里所有該標識符替換成對應的字符串。
語法
#define 宏名 替換文本
示例
#include <iostream>
// 定義一個簡單的宏
#define PI 3.14159
// 定義一個帶參數的宏
#define ADD(a, b) ((a) + (b))int main() {double radius = 5.0;double area = PI * radius * radius;std::cout << "圓的面積: " << area << std::endl;int x = 3, y = 4;int sum = ADD(x, y);std::cout << "兩數之和: " << sum << std::endl;return 0;
}
優點
- 簡單靈活:宏定義非常簡單,能快速定義常量或者進行簡單的代碼替換,無需考慮類型。
- 無函數調用開銷:由于宏只是簡單的文本替換,不會產生函數調用的開銷,在一些簡單計算場景下能提高效率。
缺點
- 缺乏類型檢查:宏只是簡單的文本替換,預處理器不會對其進行類型檢查,容易引發錯誤。
- 可能導致代碼膨脹:如果宏在代碼中被大量使用,會使代碼體積增大,因為每次使用宏都會進行文本替換。
- 存在副作用:帶參數的宏可能會產生副作用,例如宏參數可能會被多次求值。
- 不能調試
- 容易出錯:在一些涉及運算符優先級的問題上,有時候你少一個括號,多一個括號就會有不同的后果。
內聯函數
內聯函數是一種特殊的函數,在編譯時,編譯器會嘗試把函數調用處用函數體替換,以此避免函數調用的開銷。
語法
inline 返回類型 函數名(參數列表) {// 函數體
}
//內聯函數其實就是原本的函數多加一個inline修飾
示例
#include <iostream>
// 定義一個內聯函數
inline int add(int a, int b) {return a + b;
}int main() {int x = 3, y = 4;int sum = add(x, y);std::cout << "兩數之和: " << sum << std::endl;return 0;
}
優點
- 類型安全:內聯函數是真正的函數,會進行類型檢查,能減少因類型不匹配導致的錯誤。
- 避免代碼膨脹:雖然內聯函數會在調用處展開,但編譯器會根據具體情況決定是否真正內聯,能避免不必要的代碼膨脹。一般函數內容如果超過10行就不會展開了。
- 代碼可維護性高:內聯函數和普通函數一樣,有明確的函數定義和作用域,便于代碼的維護和調試。
缺點
- 編譯器決策:是否真正內聯由編譯器決定,即使使用了
inline關鍵字,編譯器也可能不進行內聯。 - 不適合復雜函數:如果函數體比較復雜,內聯可能會導致代碼體積過大,反而降低性能。
宏定義和內聯函數的區別
- 處理階段不同:宏定義在預處理階段處理,只是簡單的文本替換;內聯函數在編譯階段處理,由編譯器決定是否內聯。
- 類型檢查:宏定義沒有類型檢查,內聯函數有類型檢查,更加安全。
- 代碼膨脹:宏定義容易導致代碼膨脹,內聯函數由編譯器控制,能避免不必要的代碼膨脹。
- 調試難度:宏定義調試比較困難,因為預處理器替換后的代碼可能和原始代碼差異較大;內聯函數和普通函數一樣,調試相對容易。
下面這幅圖就是假設函數內容是100行的時候,展開和不展開的時候反匯編的情況:(不嚴謹的)

這里補充一下,如果平時是分文件編寫,那么內聯函數聲明和定義是不能分離的,也就是說不能你在頭文件聲明之后再去.c文件中定義,這里大家就在.h頭文件里直接聲明加定義寫好就行了。因為雖說是內聯函數,但是內聯函數在編譯鏈接的時候是直接展開的,不嚴謹的可以說他沒有函數地址的,你要是聲明和定義分離,到時候編譯鏈接就會找不到你寫的那個函數,明白嘛。
auto關鍵字
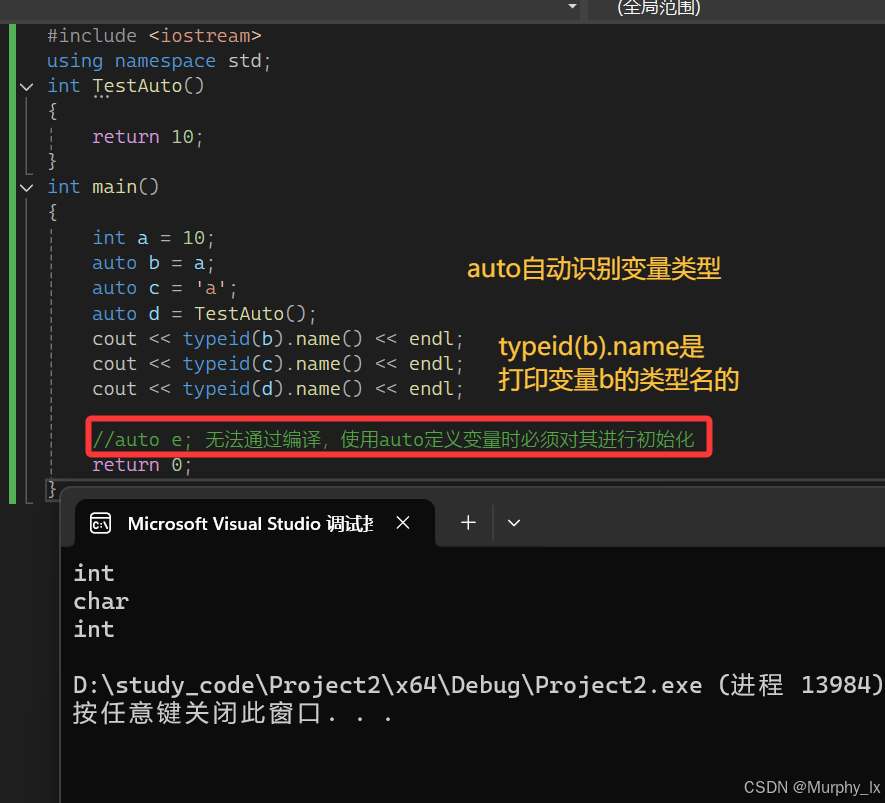
【注意】
使用auto定義變量時必須對其進行初始化,在編譯階段編譯器需要根據初始化表達式來推導auto的實際類型。因此auto并非是一種“類型”的聲明,而是一個類型聲明時的“占位符”,編譯器在編譯期會將auto替換為變量實際的類型。
auto的使用細則
- auto與指針和引用結合起來使用
用auto聲明指針類型時,用auto和auto*沒有任何區別,但用auto聲明引用類型時則必須加&
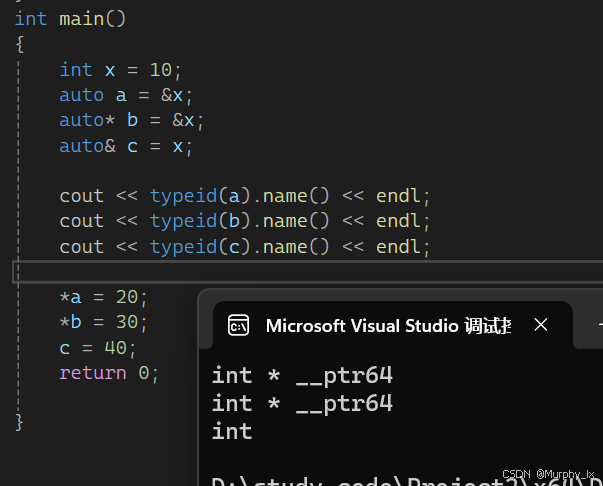
- 在同一行定義多個變量
當在同一行聲明多個變量時,這些變量必須是相同的類型,否則編譯器將會報錯,因為編譯器實際只對第一個類型進行推導,然后用推導出來的類型定義其他變量。
void TestAuto(){auto a = 1, b = 2; auto c = 3, d = 4.0; // 該行代碼會編譯失敗,因為c和d的初始化表達式類型不同}
auto不能推導的場景
- auto不能作為函數的參數
- auto不能直接用來聲明數組
這里沒有為啥,這主要是C++祖師爺的規定。然后這個auto的作用其實就是當一個變量的類型名很長的時候可以不用寫嘛,但是目前我們還沒有接觸到很長了,等到后面學了之后就會慢慢接觸到了。
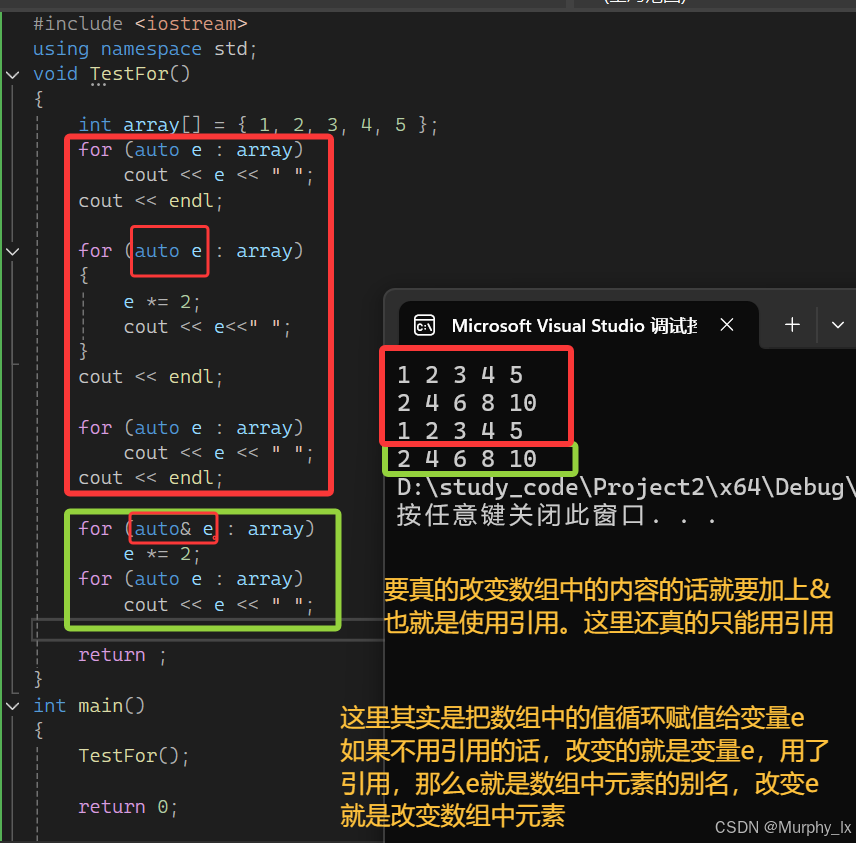
基于范圍的for循環
這里注意使用這個范圍for,數組大小一定得是確定了的。
指針空值nullptr
NULL實際是一個宏,在傳統的C頭文件(stddef.h)中,可以看到如下代碼:
void TestPtr() {
int* p1 = NULL;
int* p2 = 0;
// ……
}


NULL實際是一個宏,在傳統的C頭文件(stddef.h)中,可以看到如下代碼:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定義為字面常量0,或者被定義為無類型指針(void*)的常量。不論采取何種定義,在使用空值的指針時,都不可避免的會遇到一些麻煩,比如:
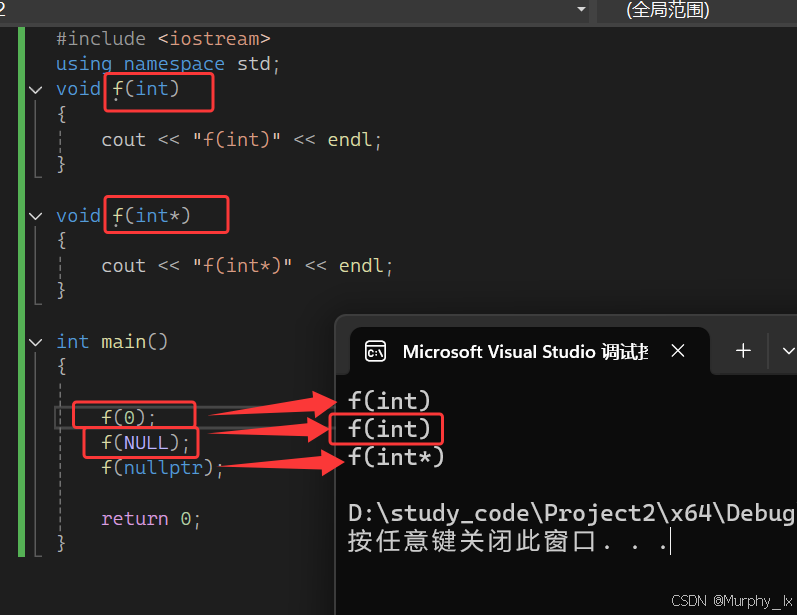
所以以后定義空指針換成nullptr就ok。















)


)
 與數組 (Array) 的定長世界)