目錄
1. 線性回歸損失函數
1.1 MAE損失
1.2 MSE損失
2. CrossEntropyLoss
2.1 信息量
2.2 信息熵
2.3 KL散度
2.4 交叉熵
3. BCELoss
4. 總結
1. 線性回歸損失函數
1.1 MAE損失
MAE(Mean Absolute Error,平均絕對誤差)通常也被稱為 L1-Loss,通過對預測值和真實值之間的絕對差取平均值來衡量他們之間的差異。。
MAE的公式如下:
其中:
-
n 是樣本的總數。
-
是第 i 個樣本的真實值。
-
是第 i 個樣本的預測值。
-
是真實值和預測值之間的絕對誤差。
特點:
-
魯棒性:與均方誤差(MSE)相比,MAE對異常值(outliers)更為魯棒,因為它不會像MSE那樣對較大誤差平方敏感。
-
物理意義直觀:MAE以與原始數據相同的單位度量誤差,使其易于解釋。
應用場景: MAE通常用于需要對誤差進行線性度量的情況,尤其是當數據中可能存在異常值時,MAE可以避免對異常值的過度懲罰。
使用torch.nn.L1Loss即可計算MAE:
import torch
import torch.nn as nn
?
# 初始化MAE損失函數
mae_loss = nn.L1Loss()
?
# 假設 y_true 是真實值, y_pred 是預測值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([2.5, 5.0, 3.0])
?
# 計算MAE
loss = mae_loss(y_pred, y_true)
print(f'MAE Loss: {loss.item()}')1.2 MSE損失
均方差損失,也叫L2Loss。
MSE(Mean Squared Error,均方誤差)通過對預測值和真實值之間的誤差平方取平均值,來衡量預測值與真實值之間的差異。
MSE的公式如下:
其中:
-
n 是樣本的總數。
-
y_i 是第 i 個樣本的真實值。
-
\hat{y}_i 是第 i 個樣本的預測值。
-
\left( y_i - \hat{y}_i \right)^2 是真實值和預測值之間的誤差平方。
特點:
-
平方懲罰:因為誤差平方,MSE 對較大誤差施加更大懲罰,所以 MSE 對異常值更為敏感。
-
凸性:MSE 是一個凸函數(國際的叫法,國內叫凹函數),這意味著它具有一個唯一的全局最小值,有助于優化問題的求解。
應用場景:
MSE被廣泛應用在神經網絡中。
使用 torch.nn.MSELoss 可以實現:
import torch
import torch.nn as nn
?
# 初始化MSE損失函數
mse_loss = nn.MSELoss()
?
# 假設 y_true 是真實值, y_pred 是預測值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([2.5, 5.0, 3.0])
?
# 計算MSE
loss = mse_loss(y_pred, y_true)
print(f'MSE Loss: {loss.item()}')2. CrossEntropyLoss
2.1 信息量
信息量用于衡量一個事件所包含的信息的多少。信息量的定義基于事件發生的概率:事件發生的概率越低,其信息量越大。其量化公式:
對于一個事件x,其發生的概率為 P(x),信息量I(x) 定義為:
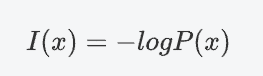
性質
-
非負性:I(x)≥0。
-
單調性:P(x)越小,I(x)越大。
2.2 信息熵
信息熵是信息量的期望值。熵越高,表示隨機變量的不確定性越大;熵越低,表示隨機變量的不確定性越小。
公式由數學中的期望推導而來:
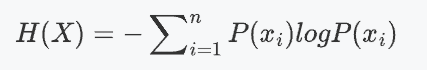
其中:
是信息量,
是信息量對應的概率
2.3 KL散度
KL散度用于衡量兩個概率分布之間的差異。它描述的是用一個分布 Q來近似另一個分布 P時,所損失的信息量。KL散度越小,表示兩個分布越接近。
對于兩個離散概率分布 P和 Q,KL散度定義為:
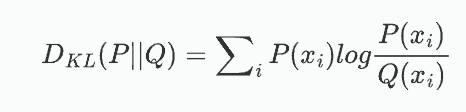
其中:P 是真實分布,Q是近似分布。
2.4 交叉熵
對KL散度公式展開:
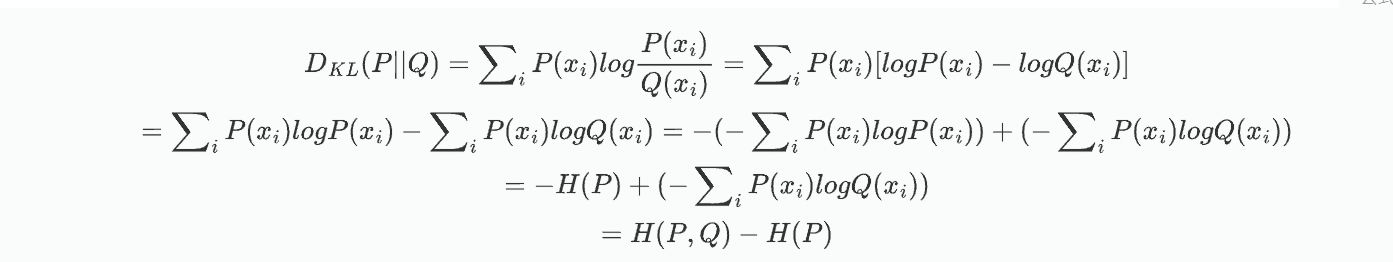
由上述公式可知,P是真實分布,H(P)是常數,所以KL散度可以用H(P,Q)來表示;H(P,Q)叫做交叉熵。
如果將P換成y,Q換成\hat{y},則交叉熵公式為:
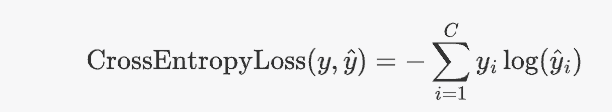
其中:
-
C 是類別的總數。
-
y 是真實標簽的one-hot編碼向量,表示真實類別。
-
\hat{y} 是模型的輸出(經過 softmax 后的概率分布)。
-
y_i 是真實類別的第 i 個元素(0 或 1)。
-
\hat{y}_i 是預測的類別概率分布中對應類別 i 的概率。
函數曲線圖:
特點:
-
概率輸出:CrossEntropyLoss 通常與 softmax 函數一起使用,使得模型的輸出表示為一個概率分布(即所有類別的概率和為 1)。PyTorch 的 nn.CrossEntropyLoss 已經內置了 Softmax 操作。如果我們在輸出層顯式地添加 Softmax,會導致重復應用 Softmax,從而影響模型的訓練效果。
-
懲罰錯誤分類:該損失函數在真實類別的預測概率較低時,會施加較大的懲罰,這樣模型在訓練時更注重提升正確類別的預測概率。
-
多分類問題中的標準選擇:在大多數多分類問題中,CrossEntropyLoss 是首選的損失函數。
應用場景:
CrossEntropyLoss 廣泛應用于各種分類任務,包括圖像分類、文本分類等,尤其是在神經網絡模型中。
nn.CrossEntropyLoss基本原理:
由交叉熵公式可知:
因為y_i是one-hot編碼,其值不是1便是0,又是乘法,所以只要知道1對應的index就可以了,展開后:
其中,m表示真實類別。
因為神經網絡最后一層分類總是接softmax,所以可以把\hat{y}_m直接看為是softmax后的結果。
?
所以,CrossEntropyLoss 實質上是兩步的組合:Cross Entropy = Log-Softmax + NLLLoss
-
Log-Softmax:對輸入 logits 先計算對數 softmax:
log(softmax(x))。 -
NLLLoss(Negative Log-Likelihood):對 log-softmax 的結果計算負對數似然損失。簡單理解就是求負數。原因是概率值通常在 0 到 1 之間,取對數后會變成負數。為了使損失值為正數,需要取負數。
對于softmax(x_i),在softmax介紹中了解到,需要減去最大值以確保數值穩定。
則:
所以:
?
總的交叉熵損失函數是所有樣本的平均值:
示例代碼如下:
import torch
import torch.nn as nn
?
# 假設有三個類別,模型輸出是未經softmax的logits
logits = torch.tensor([[1.5, 2.0, 0.5], [0.5, 1.0, 1.5]])
?
# 真實的標簽
labels = torch.tensor([1, 2]) ?# 第一個樣本的真實類別為1,第二個樣本的真實類別為2
?
# 初始化CrossEntropyLoss
# 參數:reduction:mean-平均值,sum-總和
criterion = nn.CrossEntropyLoss()
?
# 計算損失
loss = criterion(logits, labels)
print(f'Cross Entropy Loss: {loss.item()}')在這個例子中,CrossEntropyLoss 直接作用于未經 softmax 處理的 logits 輸出和真實標簽,PyTorch 內部會自動應用 softmax 激活函數,并計算交叉熵損失。
分析示例中的代碼:
logits = torch.tensor([[1.5, 2.0, 0.5], [0.5, 1.0, 1.5]])第一個樣本的得分是 [1.5, 2.0, 0.5],分別對應類別 0、1 和 2 的得分。
第二個樣本的得分是 [0.5, 1.0, 1.5],分別對應類別 0、1 和 2 的得分
labels = torch.tensor([1, 2])第一個樣本的真實類別是 1。
第二個樣本的真實類別是 2。
CrossEntropyLoss 的計算過程可以分為以下幾個步驟:
(1) LogSoftmax 操作
首先,對每個樣本的 logits 應用 LogSoftmax 函數,將 logits 轉換為概率分布。LogSoftmax 函數的公式是: LogSoftmax(x_i) =x_i-\max(x)-log(\sum_{j=1}^ne^{x_j-\max(x)})
對于第一個樣本 [1.5, 2.0, 0.5]:
減去最大值:
計算:
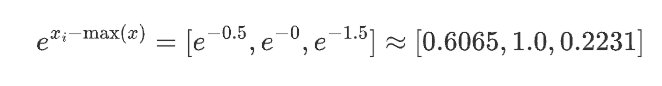
求和并取對數:
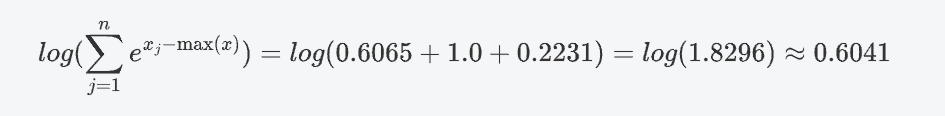
計算 log_softmax:
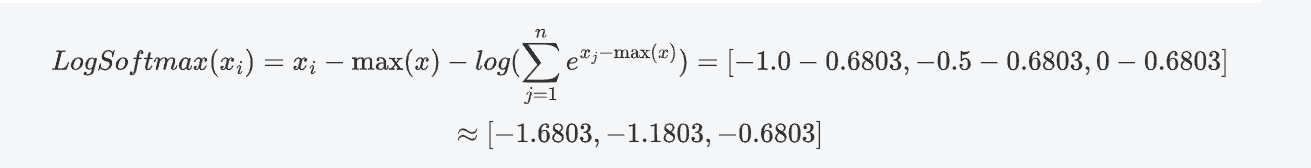
對于第二個樣本 [0.5, 1.0, 1.5]:
減去最大值:
計算:
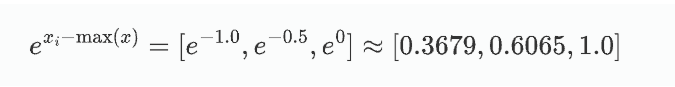
求和并取對數:
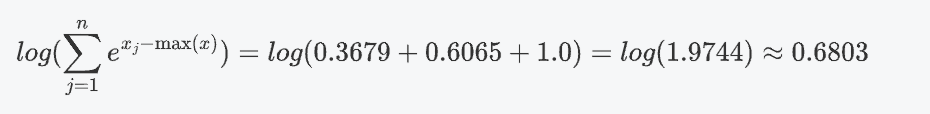
計算 log_softmax:
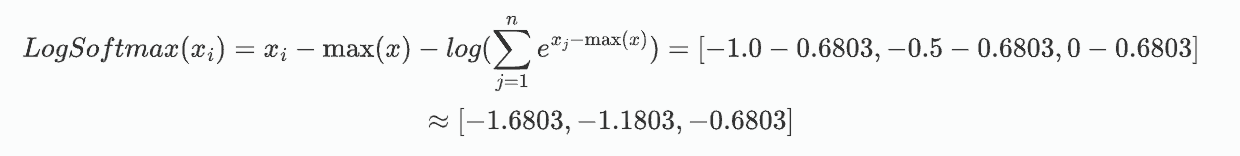
(2) 計算每個樣本的損失
接下來,根據真實標簽 z_t 計算每個樣本的交叉熵損失。交叉熵損失的公式是:
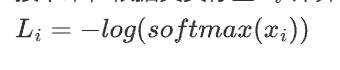
對于第一個樣本:
-
真實類別是 1,對應的 softmax 值是 -0.6041。
對于第二個樣本:
-
真實類別是 2,對應的 softmax 值是 -0.6803。
(3) 計算平均損失
最后,計算所有樣本的平均損失: 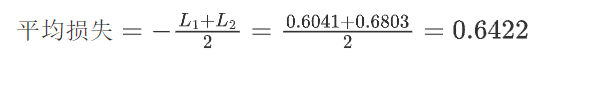
3. BCELoss
二分類交叉熵損失函數,使用在輸出層使用sigmoid激活函數進行二分類時。
由交叉熵公式:
對于二分類問題,真實標簽 y的值為(0 或 1),假設模型預測為正類的概率為 \hat{y},則:

所以:
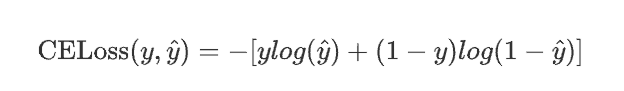
示例:
import torch
import torch.nn as nn
?
# y 是模型的輸出,已經被sigmoid處理過,確保其值域在(0,1)
y = torch.tensor([[0.7], [0.2], [0.9], [0.7]])
# targets 是真實的標簽,0或1
t = torch.tensor([[1], [0], [1], [0]], dtype=torch.float)
?
# 計算損失方式一:
bceLoss = nn.BCELoss()
loss1 = bceLoss(y, t)
?
#計算損失方式二: 兩種方式結果相同
loss2 = nn.functional.binary_cross_entropy(y, t)
?
print(loss1, loss2)逐樣本計算
| 樣本 | y_i | t_i | 計算項 t_i * log(y_i) + (1-t_i) * log(1-y_i) |
|---|---|---|---|
| 1 | 0.7 | 1 | 1*log(0.7) + 0*log(0.3) ≈ -0.3567 |
| 2 | 0.2 | 0 | 0*log(0.2) + 1*log(0.8) ≈ -0.2231 |
| 3 | 0.9 | 1 | 1*log(0.9) + 0*log(0.1) ≈ -0.1054 |
| 4 | 0.7 | 0 | 0*log(0.7) + 1*log(0.3) ≈ -1.2040 |
計算最終損失
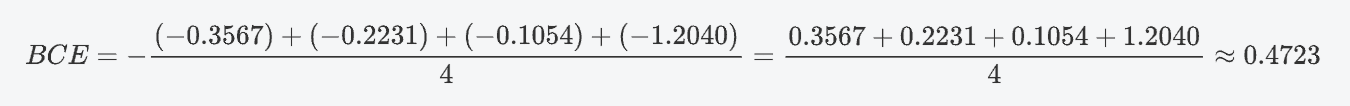
4. 總結
-
當輸出層使用softmax多分類時,使用交叉熵損失函數;
-
當輸出層使用sigmoid二分類時,使用二分類交叉熵損失函數, 比如在邏輯回歸中使用;
-
當功能為線性回歸時,使用均方差損失-L2 loss;








)


)
 與數組 (Array) 的定長世界)

 安全簡介)
)
)
(新手友好版~))

