🌟【技術大咖愚公搬代碼:全棧專家的成長之路,你關注的寶藏博主在這里!】🌟
📣開發者圈持續輸出高質量干貨的"愚公精神"踐行者——全網百萬開發者都在追更的頂級技術博主!
👉 江湖人稱"愚公搬代碼",用七年如一日的精神深耕技術領域,以"挖山不止"的毅力為開發者們搬開知識道路上的重重阻礙!
💎【行業認證·權威頭銜】
? 華為云天團核心成員:特約編輯/云享專家/開發者專家/產品云測專家
? 開發者社區全滿貫:CSDN博客&商業化雙料專家/阿里云簽約作者/騰訊云內容共創官/掘金&亞馬遜&51CTO頂級博主
? 技術生態共建先鋒:橫跨鴻蒙、云計算、AI等前沿領域的技術布道者
🏆【榮譽殿堂】
🎖 連續三年蟬聯"華為云十佳博主"(2022-2024)
🎖 雙冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余個技術社區年度杰出貢獻獎得主
📚【知識寶庫】
覆蓋全棧技術矩陣:
? 編程語言:.NET/Java/Python/Go/Node…
? 移動生態:HarmonyOS/iOS/Android/小程序
? 前沿領域:物聯網/網絡安全/大數據/AI/元宇宙
? 游戲開發:Unity3D引擎深度解析
每日更新硬核教程+實戰案例,助你打通技術任督二脈!
💌【特別邀請】
正在構建技術人脈圈的你:
👍 如果這篇推文讓你收獲滿滿,點擊"在看"傳遞技術火炬
💬 在評論區留下你最想學習的技術方向
? 點擊"收藏"建立你的私人知識庫
🔔 關注公眾號獲取獨家技術內參
?與其仰望大神,不如成為大神!關注"愚公搬代碼",讓堅持的力量帶你穿越技術迷霧,見證從量變到質變的奇跡!? |
文章目錄
- 🚀前言
- 🚀一、分布式爬取中文日報新聞數據
- 🔎1.網頁分析
- 🔎2.數據庫設計
- 🔎3.Scrapy項目搭建
- 🔎4.分布式配置 (`settings.py`)
- 🔎5.啟動分布式爬蟲
🚀前言
在前幾篇中,我們已經深入探討了 Scrapy 和 Redis 的基本應用,以及如何利用 Scrapy-Redis 實現分布式爬蟲系統。今天,我們將帶領大家實際操作,通過分布式爬取中文日報新聞數據,進一步提升我們在實際項目中的應用能力。
在爬蟲開發中,新聞數據的爬取是一個非常典型的應用場景。通過爬取中文日報網站的新聞數據,我們不僅可以獲取到實時的新聞信息,還能夠深入分析新聞內容,進行數據挖掘與應用。而使用分布式爬蟲架構,可以讓我們在面對大規模新聞數據時,輕松實現高效的數據抓取與處理。
在本篇文章中,我們將通過實際案例,學習如何分布式爬取中文日報的新聞數據,并實現以下功能:
- 分析中文日報網站結構:如何解析中文日報網站的 HTML 結構,定位新聞數據,提取有價值的信息。
- Scrapy-Redis 實現分布式抓取:結合 Scrapy 和 Redis,實現新聞數據的分布式爬取,提高爬取效率。
- 新聞數據存儲與清洗:如何存儲抓取到的新聞數據,并進行簡單的數據清洗和處理,使數據更加有用。
- 數據去重與分布式管理:使用 Redis 的去重功能,避免重復抓取新聞數據,實現任務的高效分發與管理。
- 處理中文文本:如何處理中文文本數據,并對新聞標題、內容等進行進一步的分析和存儲。
通過本篇文章的學習,你將能夠運用分布式爬蟲技術,抓取并存儲中文日報的新聞數據,為你后續的數據分析和項目開發打下堅實的基礎。如果你希望深入了解分布式爬蟲在實際項目中的應用,那么今天的教程將是一個絕佳的實踐機會。
🚀一、分布式爬取中文日報新聞數據
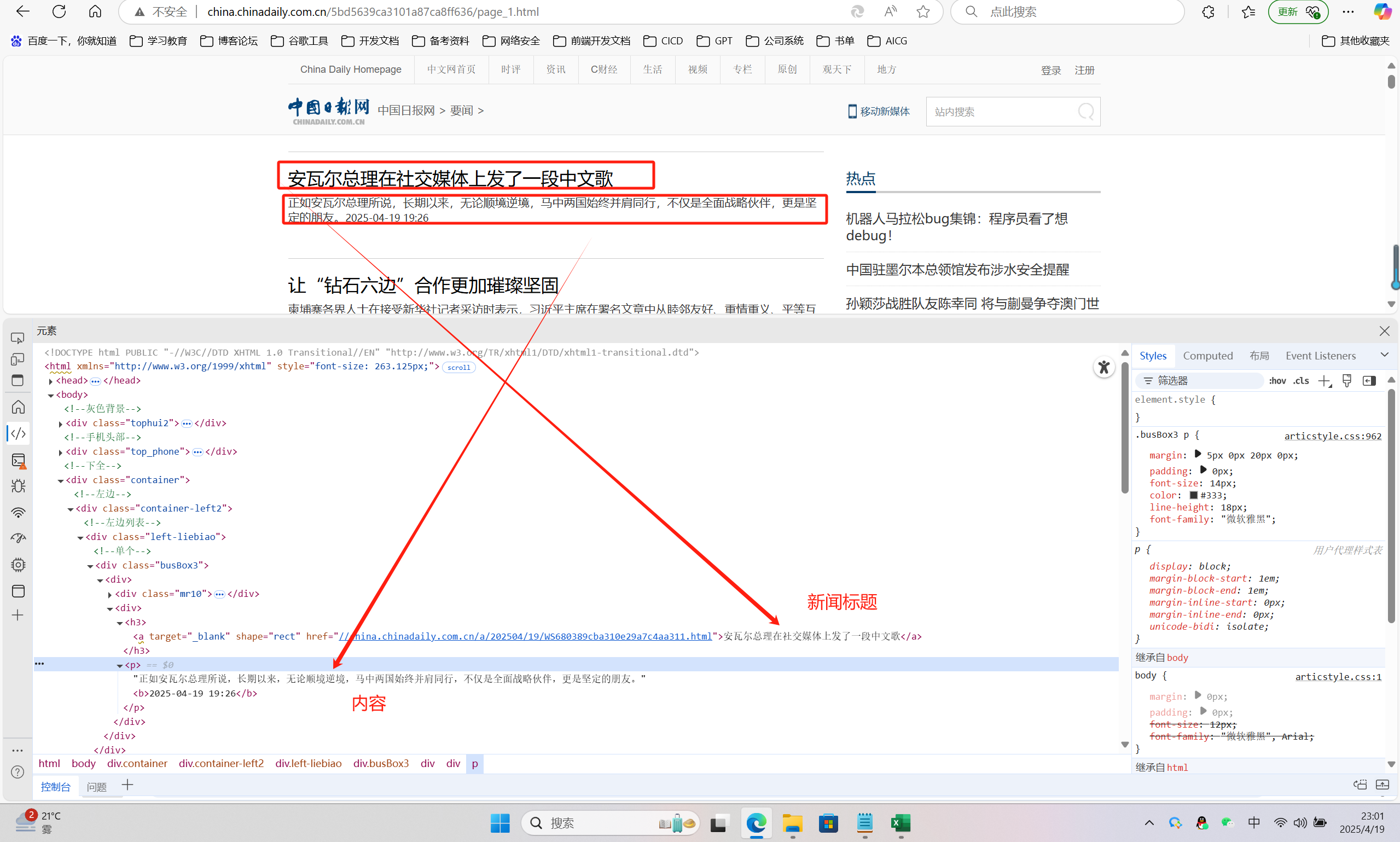
🔎1.網頁分析
-
目標網址
- 示例分頁地址規律:
http://china.chinadaily.com.cn/5bd5639ca3101a87ca8ff636/page_{頁碼}.html - 通過修改末尾頁碼實現翻頁(1-100頁)。
- 示例分頁地址規律:
-
數據定位
- 使用開發者工具定位以下字段的HTML位置:
- 新聞標題
<h3>標簽內文本 - 新聞簡介
<p>標簽內文本 - 新聞詳情頁地址
<a>標簽的href屬性 - 發布時間
<b>標簽內文本
- 新聞標題
- 使用開發者工具定位以下字段的HTML位置:
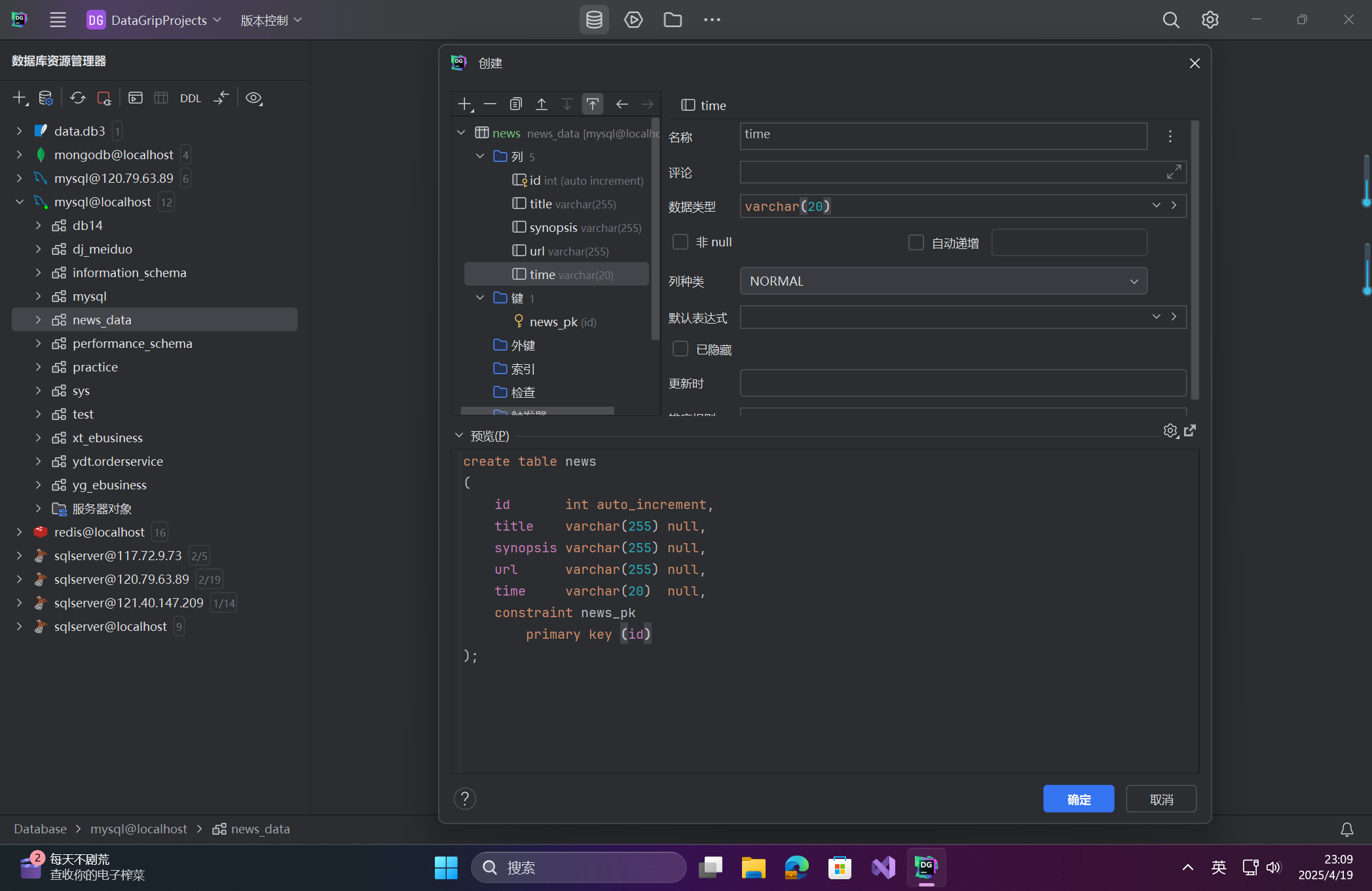
🔎2.數據庫設計
-
創建數據庫
- 數據庫名:
news_data - 字符集:
utf8mb4,排序規則:utf8mb4_0900_ai_ci
- 數據庫名:
-
數據表結構
- 表名:
news - 字段:
id(主鍵,自增)title(新聞標題,VARCHAR 255)synopsis(簡介,VARCHAR 255)url(詳情頁地址,VARCHAR 255)time(發布時間,VARCHAR 20)
- 表名:
🔎3.Scrapy項目搭建
-
創建項目
scrapy startproject distributed cd distributed scrapy genspider distributedSpider china.chinadaily.com.cn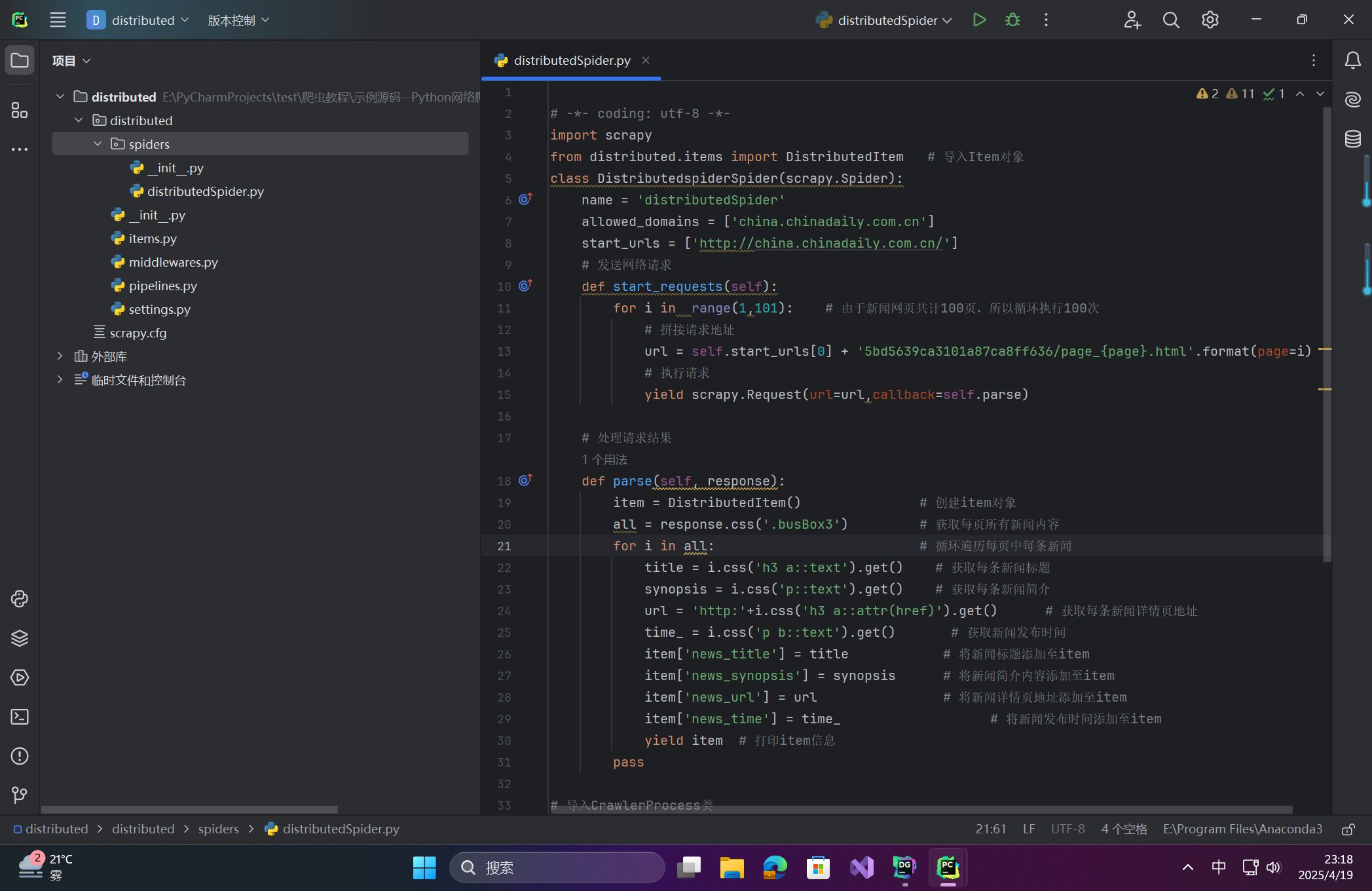
-
項目結構
items.py:定義數據字段middlewares.py:隨機請求頭中間件pipelines.py:MySQL數據存儲管道settings.py:分布式配置
核心代碼實現
-
隨機請求頭中間件 (
middlewares.py)from fake_useragent import UserAgent # 導入請求頭類 # 自定義隨機請求頭的中間件 class RandomHeaderMiddleware(object):def __init__(self, crawler):self.ua = UserAgent() # 隨機請求頭對象# 如果配置文件中不存在就使用默認的Google Chrome請求頭self.type = crawler.settings.get("RANDOM_UA_TYPE", "chrome")@classmethoddef from_crawler(cls, crawler):# 返回cls()實例對象return cls(crawler)# 發送網絡請求時調用該方法def process_request(self, request, spider):# 設置隨機生成的請求頭request.headers.setdefault('User-Agent', getattr(self.ua, self.type)) -
數據項定義 (
items.py)import scrapyclass DistributedItem(scrapy.Item):news_title = scrapy.Field() # 保存新聞標題news_synopsis = scrapy.Field() # 保存新聞簡介news_url = scrapy.Field() # 保存新聞詳情頁面的地址news_time = scrapy.Field() # 保存新聞發布時間pass -
MySQL存儲管道 (
pipelines.py)# -*- coding: utf-8 -*-# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlimport pymysql # 導入數據庫連接pymysql模塊 class DistributedPipeline(object):# 初始化數據庫參數def __init__(self,host,database,user,password,port):self.host = hostself.database = databaseself.user = userself.password = passwordself.port = port@classmethoddef from_crawler(cls, crawler):# 返回cls()實例對象,其中包含通過crawler獲取配置文件中的數據庫參數return cls(host=crawler.settings.get('SQL_HOST'),user=crawler.settings.get('SQL_USER'),password=crawler.settings.get('SQL_PASSWORD'),database=crawler.settings.get('SQL_DATABASE'),port=crawler.settings.get('SQL_PORT'))# 打開爬蟲時調用def open_spider(self, spider):# 數據庫連接self.db = pymysql.connect(self.host, self.user, self.password, self.database, self.port, charset='utf8')self.cursor = self.db.cursor() # 床架游標# 關閉爬蟲時調用def close_spider(self, spider):self.db.close()def process_item(self, item, spider):data = dict(item) # 將item轉換成字典類型# sql語句sql = 'insert into news (title,synopsis,url,time) values(%s,%s,%s,%s)'# 執行插入多條數據self.cursor.executemany(sql, [(data['news_title'], data['news_synopsis'],data['news_url'],data['news_time'])])self.db.commit() # 提交return item # 返回item -
爬蟲邏輯 (
distributedSpider.py)# -*- coding: utf-8 -*- import scrapy from distributed.items import DistributedItem # 導入Item對象 class DistributedspiderSpider(scrapy.Spider):name = 'distributedSpider'allowed_domains = ['china.chinadaily.com.cn']start_urls = ['http://china.chinadaily.com.cn/']# 發送網絡請求def start_requests(self):for i in range(1,101): # 由于新聞網頁共計100頁,所以循環執行100次# 拼接請求地址url = self.start_urls[0] + '5bd5639ca3101a87ca8ff636/page_{page}.html'.format(page=i)# 執行請求yield scrapy.Request(url=url,callback=self.parse)# 處理請求結果def parse(self, response):item = DistributedItem() # 創建item對象all = response.css('.busBox3') # 獲取每頁所有新聞內容for i in all: # 循環遍歷每頁中每條新聞title = i.css('h3 a::text').get() # 獲取每條新聞標題synopsis = i.css('p::text').get() # 獲取每條新聞簡介url = 'http:'+i.css('h3 a::attr(href)').get() # 獲取每條新聞詳情頁地址time_ = i.css('p b::text').get() # 獲取新聞發布時間item['news_title'] = title # 將新聞標題添加至itemitem['news_synopsis'] = synopsis # 將新聞簡介內容添加至itemitem['news_url'] = url # 將新聞詳情頁地址添加至itemitem['news_time'] = time_ # 將新聞發布時間添加至itemyield item # 打印item信息pass# 導入CrawlerProcess類 from scrapy.crawler import CrawlerProcess # 導入獲取項目配置信息 from scrapy.utils.project import get_project_settings# 程序入口 if __name__=='__main__':# 創建CrawlerProcess類對象并傳入項目設置信息參數process = CrawlerProcess(get_project_settings())# 設置需要啟動的爬蟲名稱process.crawl('distributedSpider')# 啟動爬蟲process.start()
🔎4.分布式配置 (settings.py)
BOT_NAME = 'distributed'SPIDER_MODULES = ['distributed.spiders']
NEWSPIDER_MODULE = 'distributed.spiders'# Obey robots.txt rules
ROBOTSTXT_OBEY = True# 啟用redis調度存儲請求隊列
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
#確保所有爬蟲通過redis共享相同的重復篩選器。
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
#不清理redis隊列,允許暫停/恢復爬蟲
SCHEDULER_PERSIST =True
#使用默認的優先級隊列調度請求
SCHEDULER_QUEUE_CLASS ='scrapy_redis.queue.PriorityQueue'
REDIS_URL ='redis://127.0.0.1:6379'
DOWNLOADER_MIDDLEWARES = {# 啟動自定義隨機請求頭中間件'distributed.middlewares.RandomHeaderMiddleware': 200,# 'distributed.middlewares.DistributedDownloaderMiddleware': 543,
}
# 配置請求頭類型為隨機,此處還可以設置為ie、firefox以及chrome
RANDOM_UA_TYPE = "random"
ITEM_PIPELINES = {'distributed.pipelines.DistributedPipeline': 300,'scrapy_redis.pipelines.RedisPipeline':400
}
# 配置數據庫連接信息
SQL_HOST = '127.0.0.1' # 數據庫地址
SQL_USER = 'root' # 用戶名
SQL_PASSWORD='123456' # 密碼
SQL_DATABASE = 'news_data' # 數據庫名稱
SQL_PORT = 3306 # 端口
🔎5.啟動分布式爬蟲
-
數據庫遠程配置
- Redis:修改
redis.windows-service.conf的bind為服務器IP,重啟服務。 - MySQL:執行以下SQL開啟遠程連接:
UPDATE mysql.user SET host='%' WHERE user='root'; FLUSH PRIVILEGES;
- Redis:修改
-
多節點運行
- 在多臺機器部署爬蟲代碼,修改
settings.py中的數據庫IP為服務器地址。 - 同時啟動爬蟲,觀察Redis任務隊列與MySQL數據入庫情況。
- 在多臺機器部署爬蟲代碼,修改
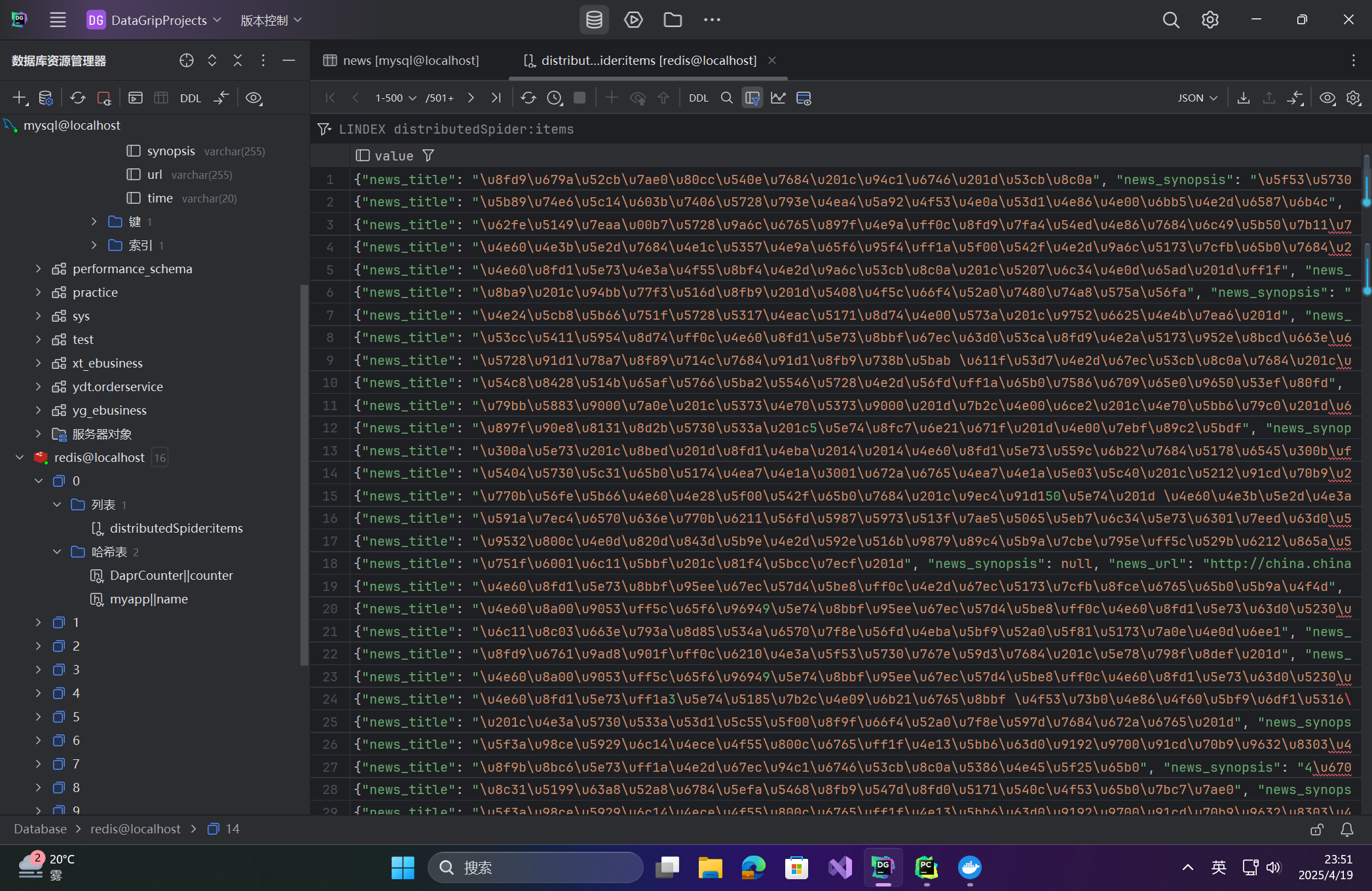
效果驗證
- Redis Desktop Manager 查看去重URL (
dupefilter) 和爬取數據 (items)。 - MySQL 中
news表應包含所有爬取的新聞數據。








)



)
含運行文檔)






)
