在?AI?技術日新月異的今天,我們再次見證了歷史性的突破。
昆侖萬維?SkyReels?團隊于近日正式發布了全球首款支持無限時長的電影生成模型——SkyReels-V2,并免費開源。這無疑為?AI?視頻領域掀開了嶄新的一頁,標志著?AI?視頻正式邁入長鏡頭時代。

突破時長限制:AI視頻的里程碑式跨越
SkyReels-V2?模型集成了多模態大語言模型(MLLM)、多階段預訓練、強化學習以及創新的擴散強迫(Diffusion-forcing)框架,實現了在提示詞遵循、視覺質量、運動動態以及視頻時長等方面的全面突破。
此前,視頻生成大模型往往存在時長的限制。因此,生成的視頻大多為幾秒到一分鐘左右的短視頻,以?Sora?這樣的行業標桿為例,雖然能生成?60?秒視頻,但也受限于閉源和物理規律模擬的不足。
而?SkyReels-V2?通過擴散強迫框架和多階段優化技術,首次實現了單鏡頭?30?秒、40?秒的流暢輸出,并通過“Extend”無限延伸,徹底打破了時長枷鎖。
那么?SkyReels-V2?是如何實現無限時長的呢?
舉個例子,我們可以先通過一句提示詞生成?30?秒視頻,然后基于這個視頻,通過“Extend”增加下一個鏡頭的提示詞:
視頻將在原有內容不變的基礎上,增加幾秒的片段,最后,通過一次次的提示,不斷增加視頻時長,直至生成一個具有電影級效果的長視頻。
這一技術突破不僅將?AI?視頻生成從幾秒的碎片化動態推向了影視級長鏡頭時代,更在提示詞理解、運動連貫性、鏡頭語言表達等維度實現了質的飛躍。
在視覺質量上,SkyReels-V2?達到了好萊塢級別的畫質,為觀眾帶來了極致的觀影體驗。

【圖片來源于網絡,侵刪】
而在運動動態方面,通過強化學習訓練,模型能夠生成流暢且逼真的視頻內容,滿足電影制作中對高質量運動動態的需求。
值得一提的是,SkyReels-V2?支持無限時長的視頻生成這一特性徹底打破了現有技術在視頻時長上的限制,為長視頻的逼真合成和專業電影風格的生成提供了可能性。
技術內核:如何實現電影級理解?
為了提高提示詞遵循能力,團隊設計了一種結構化的視頻表示方法,將多模態?LLM?的一般描述與子專家模型的詳細鏡頭語言相結合。這種方法能夠識別視頻中的主體類型、外觀、表情、動作和位置等信息,從而更準確地理解并生成符合要求的視頻內容。
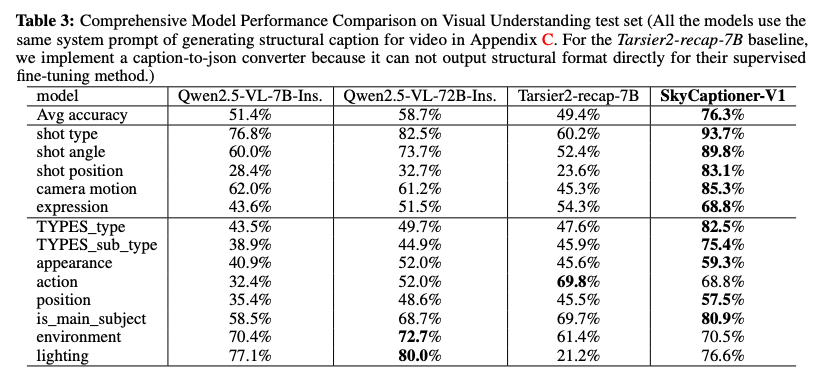
傳統?AI?視頻模型依賴通用多模態大語言模型(MLLM),難以解析電影專業術語。為此,團隊訓練了一個統一的視頻理解模型?SkyCaptioner-V1,它能夠高效地理解視頻數據,生成符合原始結構信息的多樣化描述。這相當于讓?AI?首次用導演的視角,根據文本指令生成具備專業敘事感的畫面。
在視頻理解測試集上的模型綜合性能比較中,SkyCaptioner-V1 表現優異,超越了 SOTA 的模型。
在運動質量優化方面,SkyReels-V2?采用了強化學習訓練,通過偏好優化提升運動動態質量。同時,為了降低數據標注成本,團隊設計了一個半自動數據收集管道,能夠高效地生成偏好對比數據對,進一步提升模型在運動動態方面的
效果。

同時,為了實現長視頻生成能力,SkyReels-V2?提出了一種創新的擴散強迫后訓練方法。通過微調預訓練的擴散模型,并將其轉化為擴散強迫模型。這一創新使得?SkyReels-V2?能夠生成幾乎無限時長的高質量視頻內容,為長視頻的逼真合成提供了強有力的技術支持。
SkyReels-V2?的開源,為 AI 創作帶來了新的轉變。
當 AI 模型能夠完成難度更高的細節處理,且視頻時長不受限制時,人類就可以將更多精力投入到更高層次的思維活動中,從而創作出更能體現人類獨特性的藝術作品。
AI視頻的長鏡頭時代已經到來
SkyReels-V2?的發布和開源,標志著?AI?視頻邁入了長鏡頭時代。這一突破性的技術成果不僅為觀眾帶來了更加逼真和流暢的觀影體驗,還為創作者提供了更加便捷和高效的創作工具。
隨著技術的不斷進步和應用場景的不斷拓展,相信?AI?視頻將在未來發揮更加重要的作用和影響,AI 創作的邊界也將不斷被打破。
 - 什么是MCP)


)






,適配器——stack,queue,priority_queue)






![[langchain教程]langchain03——用langchain構建RAG應用](http://pic.xiahunao.cn/[langchain教程]langchain03——用langchain構建RAG應用)
)
