一個很簡單的機器學習任務
前言
基于線上colab做的一個簡單的案例,應用了線性回歸算法,預測了大概加州3000多地區的房價中位數
過程
先導入了Pandas,這是一個常見的Python數據處理函數庫
用Pandas的read_csv函數把網上一個共享數據集(csv文件)讀入DataFrame數據結構df_housing
這個文件是加州某個時期的房價數據集
用DataFrame數據結構的head方法顯示數據集中的部分信息
import pandas as pd
df_housing = pd.read_csv("https://raw.githubusercontent.com/huangjia2019/house/master/house.csv")
df_housing.head()
結果如下
在這里插入圖片描述
然后構建特征集x和特征集y
x = df_housing.drop("median_house_value",axis=1) #構建特征集x
y = df_housing.median_house_value #構建特征集y
現在把數據集一分為二,80%用于機器訓練(訓練數據集),剩下的留著做測試(測試數據集)
from sklearn.model_selection import train_test_split #導入sklearn工具庫
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0) #以80%/20%的比例進行數據集的拆分
接下來開始訓練機器,首先選擇模型的類型,也就是算法
然后通過其中的fit方法來訓練機器,進行函數的擬合
擬合意味著找到最優的函數去模擬訓練集中的輸入(特征)和目標(標簽)的關系,這是確定模型的參數
from sklearn.linear_model import LinearRegression #導入線性回歸算法模型
model = LinearRegression() #確定線性回歸算法
model.fit(x_train,y_train) #根據訓練集數據,訓練機器,擬合函數
y_pred = model.predict(x_test) #預測驗證集的y值
print('房價的真值(測試集)',y_test)
print('預測的真值(測試集)',y_pred)
顯示預測可以多少評分
print('給預測評分',model.score(x_test,y_test)) #評估預測分數
也可以畫出來
import matplotlib.pyplot as plt
#用散點圖顯示家庭收入中位數和房價中位數的分布
plt.scatter(x_test.median_income,y_test,color='brown')
#畫出回歸函數(從特征到預測標簽)
plt.plot(x_test.median_income,y_pred,color='blue',linewidth=2)
plt.xlabel('median Income')
plt.ylabel('median House Value')
plt.show()
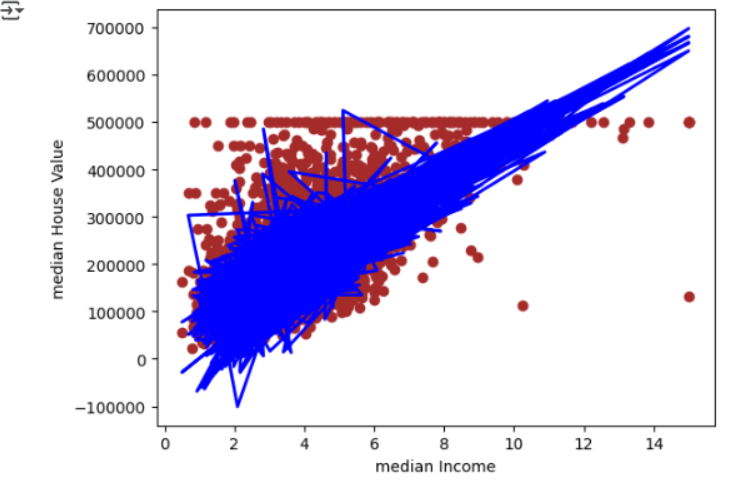
可以看出各個地區的平均房價中位數有隨該地區家庭收入中位數的上升而增加的趨勢,而機器學習到的函數也同意體現了著一點
后記
學習產出記錄

)






,適配器——stack,queue,priority_queue)






![[langchain教程]langchain03——用langchain構建RAG應用](http://pic.xiahunao.cn/[langchain教程]langchain03——用langchain構建RAG應用)
)


結合osg及osgEarth實現三維球經緯網格繪制及顯隱)