概念
- Web機器人是能夠在無需人類干預的情況下自動進行一系列Web事務處理的軟件程序。人們根據這些機器人探查web站點的方式,形象的給它們取了一個飽含特色的名字,比如“爬蟲”、“蜘蛛”、“蠕蟲”以及“機器人”等!
爬蟲概述
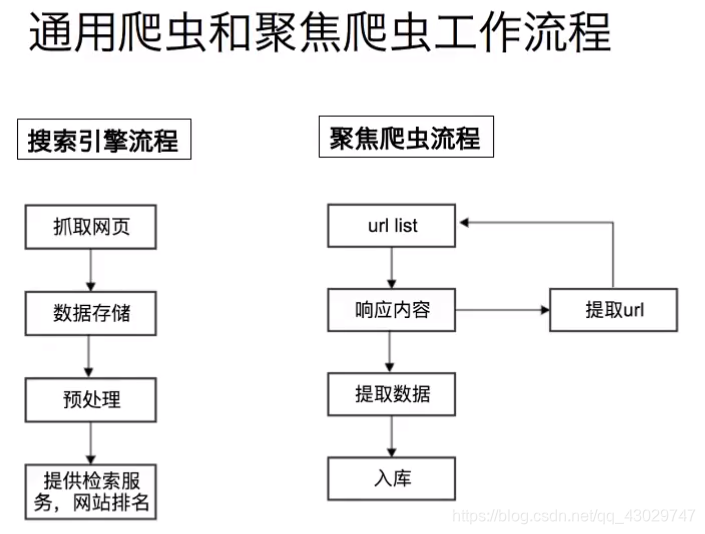
- 網絡爬蟲(英語:web crawler),也叫網絡蜘蛛(spider),是一種用來自動瀏覽萬維網的網絡機器人。其目的一般為編纂網絡索引。
網絡搜索引擎等站點通過爬蟲軟件更新自身的網站內容或其對其他網站的索引。網絡爬蟲可以將自己所訪問的頁面保存下來,以便搜索引擎事后生成索引供用戶搜索。
爬蟲訪問網站的過程會消耗目標系統資源。不少網絡系統并不默許爬蟲工作。因此在訪問大量頁面時,爬蟲需要考慮到規劃、負載,還需要講“禮貌”。 不愿意被爬蟲訪問、被爬蟲主人知曉的公開站點可以使用robots.txt文件之類的方法避免訪問。這個文件可以要求機器人只對網站的一部分進行索引,或完全不作處理。
-
網絡爬蟲始于一張被稱作種子的統一資源地址(URL)列表。當網絡爬蟲訪問這些統一資源定位器時,它們會甄別出頁面上所有的超鏈接,并將它們寫入一張“待訪列表”,即所謂爬行疆域。此疆域上的URL將會被按照一套策略循環來訪問。如果爬蟲在執行的過程中復制歸檔和保存網站上的信息,這些檔案通常儲存,使他們可以較容易的被查看。閱讀和瀏覽他們存儲的網站上并即時更新的信息,這些被存儲的網頁又被稱為“快照”。越大容量的網頁意味著網絡爬蟲只能在給予的時間內下載越少部分的網頁,所以要優先考慮其下載。高變化率意味著網頁可能已經被更新或者被取代。一些服務器端軟件生成的URL(統一資源定位符)也使得網絡爬蟲很難避免檢索到重復內容。
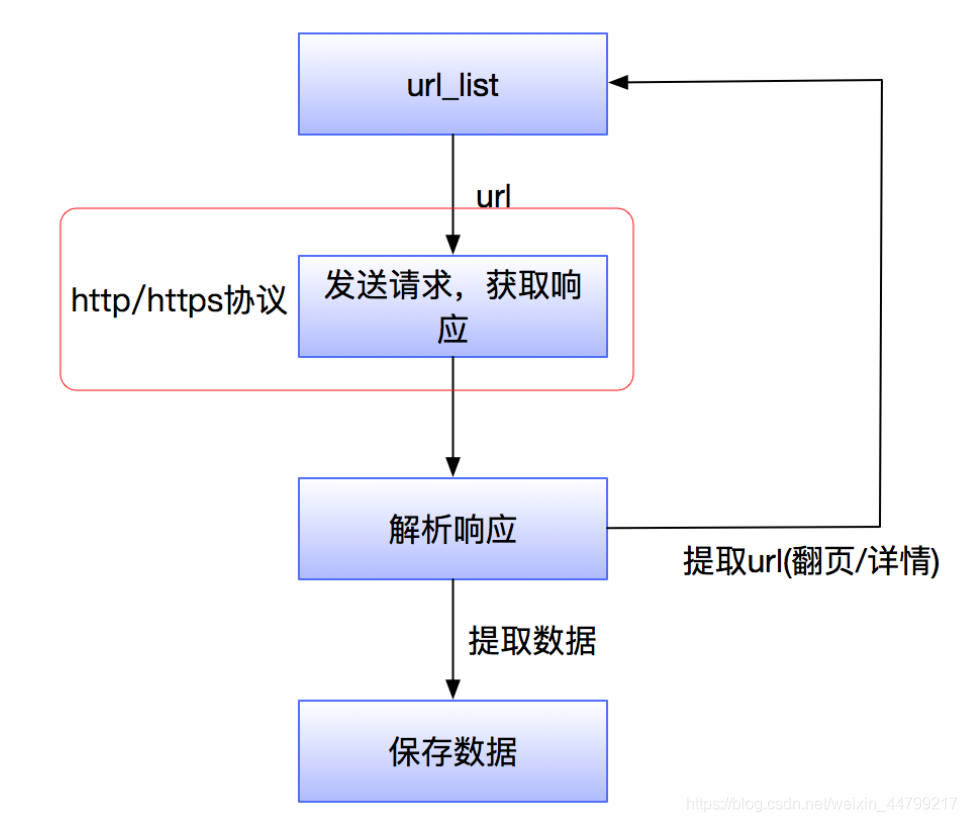
爬蟲流程
- 發送 HTTP 請求到目標網站:爬蟲模擬瀏覽器發送請求獲取網頁數據。
- 獲取服務器返回的 HTML 頁面:服務器響應請求并返回網頁內容。
- 解析 HTML 內容,提取所需數據:爬蟲使用解析庫提取網頁中的有用信息。 要避免環路的出現,因為這些環路會暫停或減緩機器人的爬行過程
- 保存數據以供后續使用:提取的數據被保存到文件或數據庫中。
環路對爬蟲有害的三個原因:
爬蟲會陷入循環之中,從而兜圈子,浪費帶寬,無法獲取新頁面!
爬蟲無限的請求服務器,從而阻塞了真正的用戶去



)




)







)


)