目錄
準備工作
編寫爬蟲代碼
運行爬蟲
查看結果
遇到的問題及解決
總結
前言和效果
本文記錄了使用 Python 實現一個簡單網頁爬蟲的過程,目標是爬取 quotes.toscrape.com 的名言和作者,并將結果保存到文本文件。以下是完整步驟,包含環境配置、依賴安裝和代碼運行。
網站截圖:
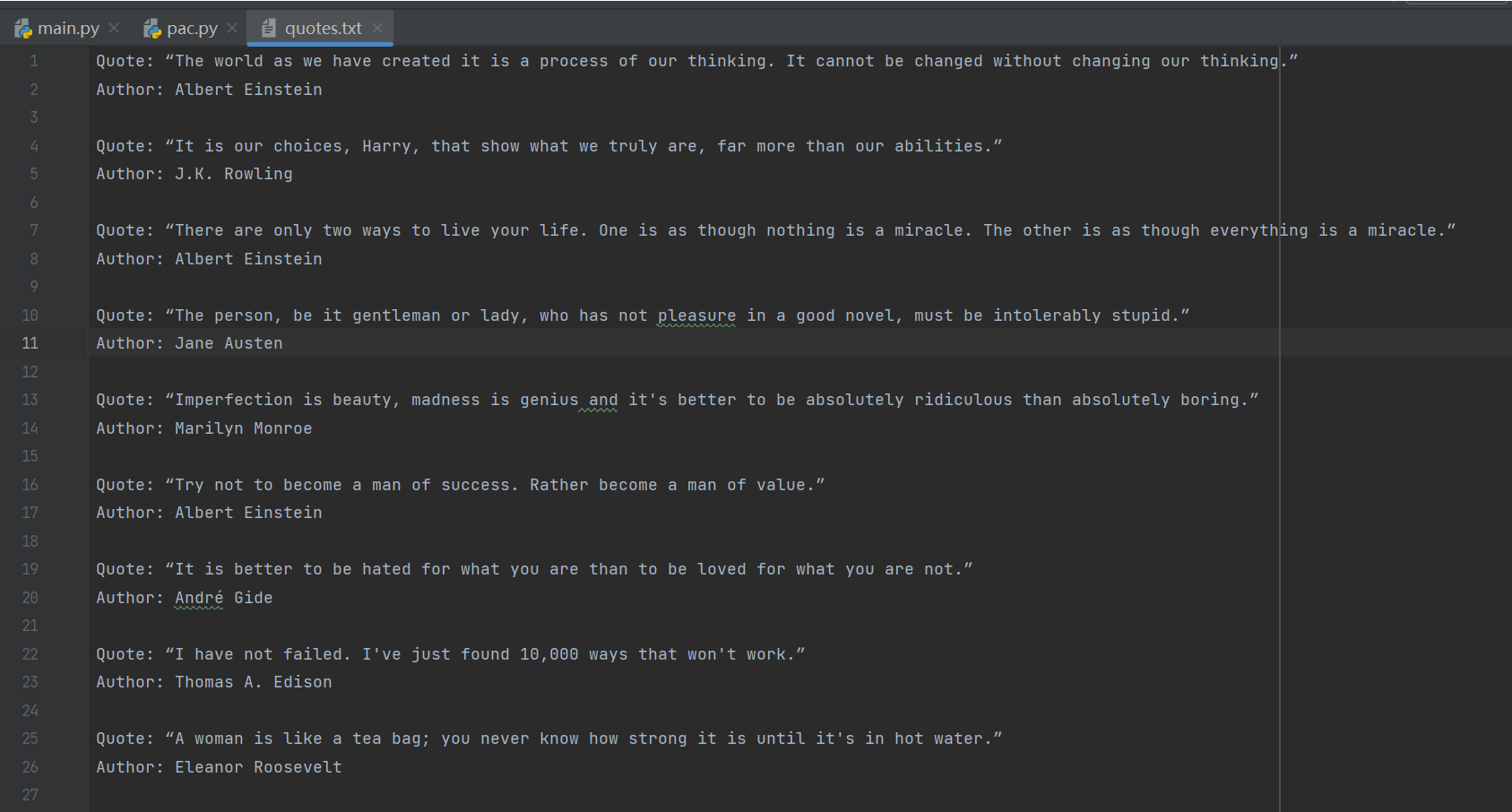
爬取到的內容截圖如下:?
準備工作
-
激活 Anaconda 虛擬環境
我的 Python 環境基于 Anaconda,使用的虛擬環境是SRCNN(路徑:D:\Anaconda\envs\SRCNN)。首先,需要激活該環境:
conda activate SRCNN
運行后,命令行前綴變為 (SRCNN),表示成功切換到虛擬環境。
-
安裝依賴包
爬蟲需要兩個庫:requests(發送 HTTP 請求)和beautifulsoup4(解析 HTML)。在SRCNN環境中安裝:
conda install requests beautifulsoup4
安裝報錯了,原因是未關閉科學上網,后關閉了這兩個包就裝好了。報錯如下: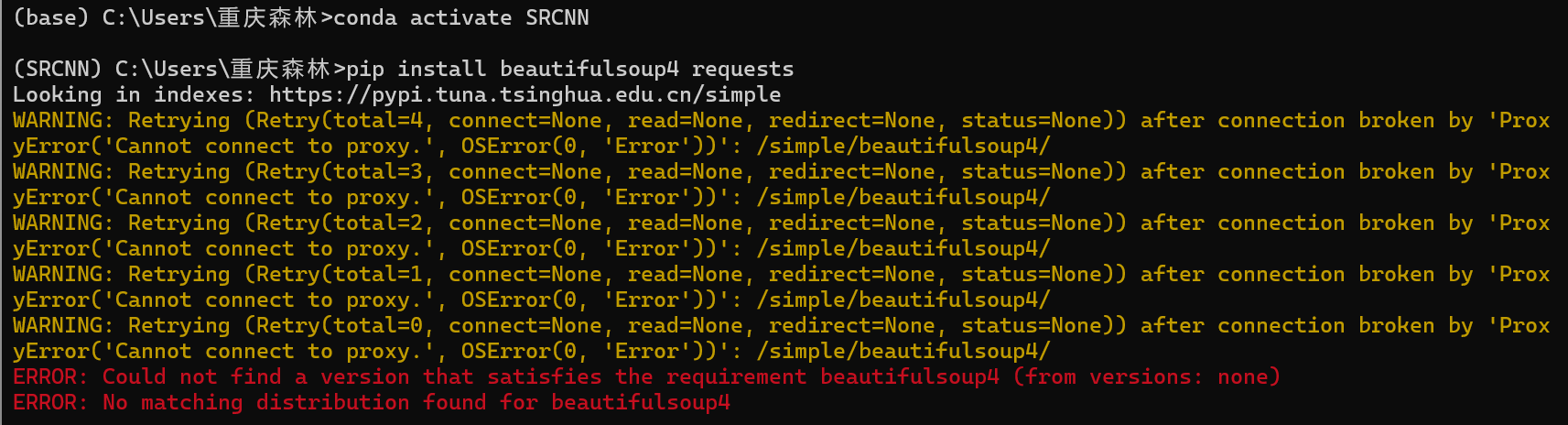
關閉科學上網后重新安裝
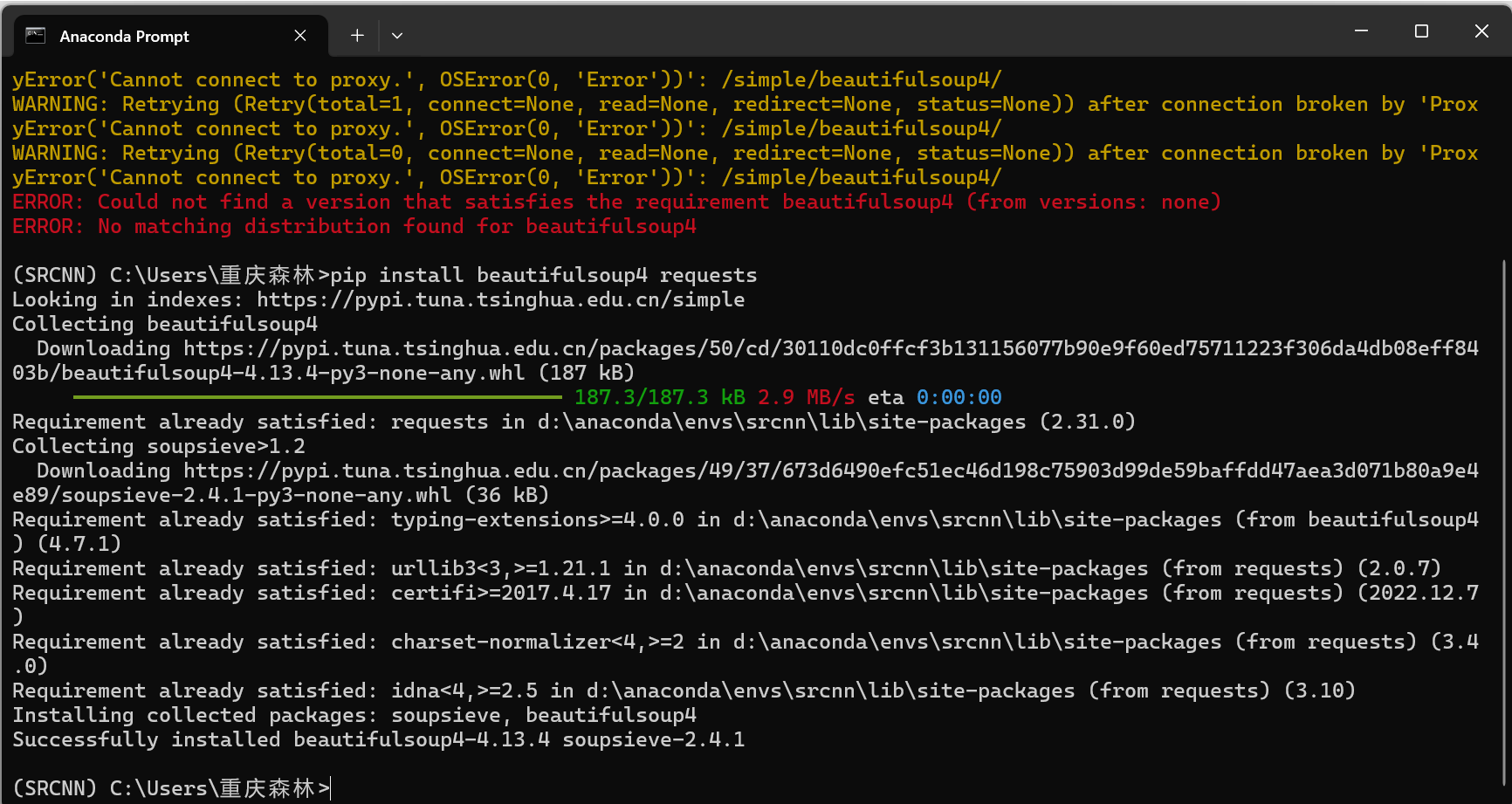
安裝完成后,命令行顯示安裝成功的提示。
-
驗證安裝
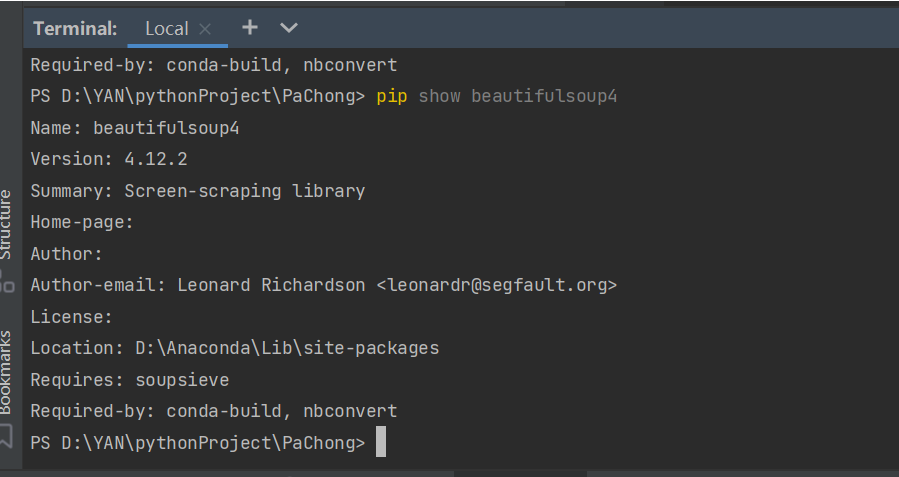
為確保beautifulsoup4正確安裝在SRCNN環境中,運行以下命令檢查:
pip show beautifulsoup4
輸出顯示模塊版本為 4.12.2,安裝路徑為 D:\Anaconda\envs\SRCNN\Lib\site-packages,確認安裝正確。
編寫爬蟲代碼,完整代碼:
以下是爬蟲代碼(pac.py),用于爬取 quotes.toscrape.com 的名言和作者,并保存到 quotes.txt:
import requests
from bs4 import BeautifulSoup# 目標網頁
url = "http://quotes.toscrape.com/"try:# 發送 HTTP 請求response = requests.get(url)response.raise_for_status() # 檢查請求是否成功# 解析 HTMLsoup = BeautifulSoup(response.text, "html.parser")# 提取名言和作者quotes = soup.find_all("div", class_="quote")results = []for quote in quotes:text = quote.find("span", class_="text").get_text()author = quote.find("small", class_="author").get_text()results.append({"quote": text, "author": author})# 保存到文件with open("quotes.txt", "w", encoding="utf-8") as f:for item in results:f.write(f"Quote: {item['quote']}\nAuthor: {item['author']}\n\n")print("爬取完成,結果已保存到 quotes.txt")except requests.RequestException as e:print(f"請求錯誤: {e}")
except Exception as e:print(f"發生錯誤: {e}")
代碼說明:
-
使用
requests.get獲取網頁內容。 -
用
BeautifulSoup解析 HTML,提取class="quote"的<div>元素。 -
提取每條名言(
class="text")和作者(class="author"),保存到quotes.txt。
目標網站:
Quotes to Scrape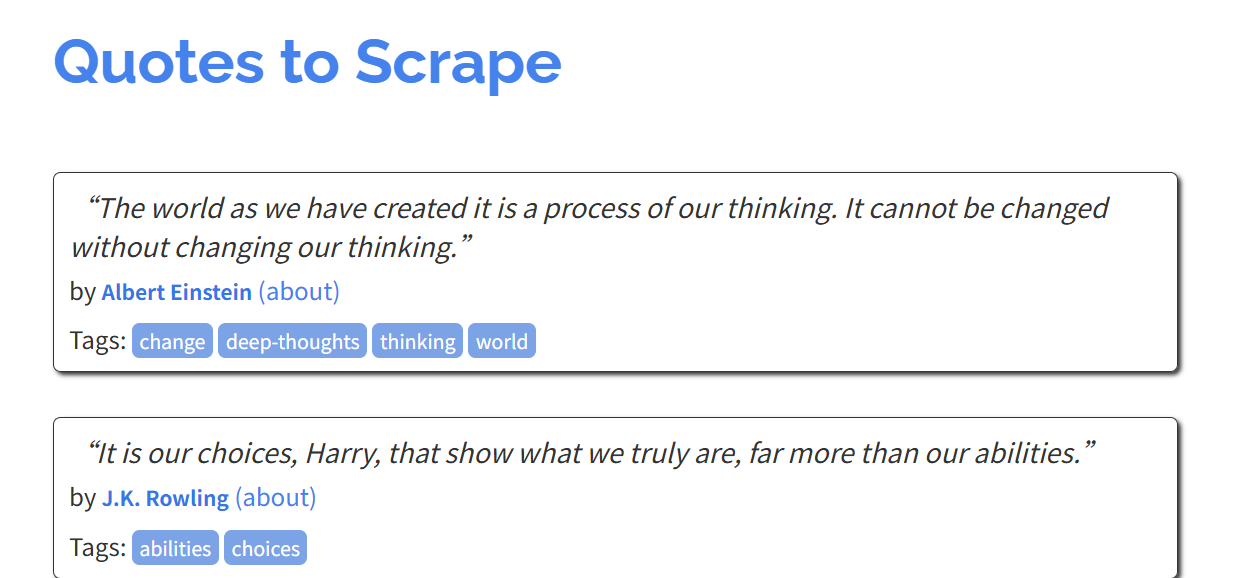
運行爬蟲
在 SRCNN 環境中運行代碼:
D:\Anaconda\envs\SRCNN\python.exe D:/YAN/pythonProject/PaChong/pac.py
運行后,程序輸出“爬取完成,結果已保存到 quotes.txt”,表示成功。
查看結果
爬取結果保存在 D:/YAN/pythonProject/PaChong/quotes.txt,內容為每條名言及其作者。
遇到的問題及解決
最初運行時,提示 ModuleNotFoundError: No module named 'bs4',因為 beautifulsoup4 安裝在 Anaconda 全局環境(D:\Anaconda\Lib\site-packages)而非 SRCNN 環境。解決方法是激活 SRCNN 環境并重新安裝:
conda activate SRCNN
conda install beautifulsoup4
此外,確認 requests 已安裝,避免類似錯誤。
總結
通過以上步驟,我成功實現了一個簡單的 Python 爬蟲:
-
激活
SRCNN虛擬環境。 -
安裝
requests和beautifulsoup4。 -
編寫并運行爬蟲代碼,爬取名言并保存到文本文件。
這個過程熟悉了 Anaconda 虛擬環境管理和爬蟲開發,適合初學者參考。未來可擴展功能,如處理多頁爬取或應對反爬機制。



)


)

)










