1、參考來源
論文《Generative Modeling by Estimating Gradients of the Data Distribution》
來源:NeurIPS 2019
論文鏈接:https://arxiv.org/abs/1907.05600
參考鏈接:
【AI知識分享】真正搞懂擴散模型Score Matching一定要理解的三大核心問題
2、布朗運動
布朗運動是描述花粉微粒在水中的運動情況的。可以看出,花粉微粒在水中的受力情況如下所示。因此根據牛頓第二定律,
F = m a m ? d v t d t = F 合力 = F 摩擦力 + F 碰撞力 = ? γ ? v t + η \begin{equation} \begin{split} F&=ma\\ m\cdot\frac{dv_t}{dt}&= F_{合力}\\ &=F_{摩擦力}+F_{碰撞力}\\ &=-\gamma\cdot v_t+\eta \end{split} \end{equation} Fm?dtdvt???=ma=F合力?=F摩擦力?+F碰撞力?=?γ?vt?+η???
其中, γ \gamma γ是摩擦力因子。 η \eta η是碰撞力,也是一個隨機的力,滿足高斯分布, η ~ N ( 0 , σ 2 ) \eta \sim N(0,\sigma^2) η~N(0,σ2)。
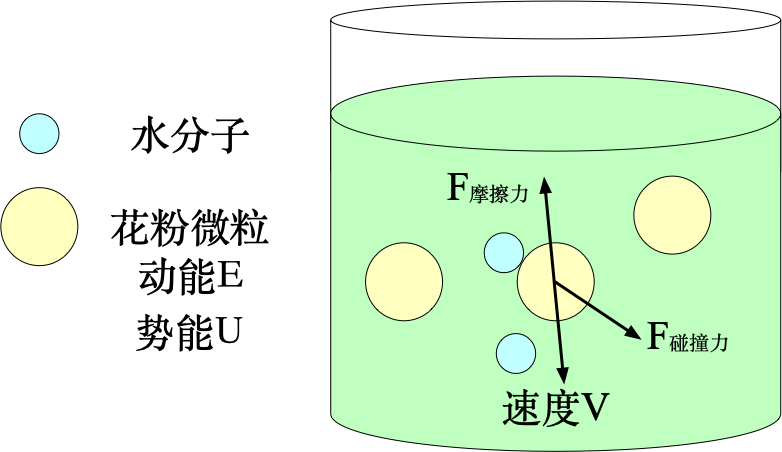
花粉微粒包含的總能量 E ω E_{\omega} Eω?包含動能 E E E和勢能 U U U。在合力的作用下,動能和勢能相互轉化,且總能量保持不變。動能定理,可以得到
F 合力 ? Δ x = Δ E ? F 合力 = Δ E Δ x = Δ E ω ? Δ U Δ x = ? Δ U Δ x \begin{equation} \begin{split} F_{合力}\cdot \Delta x&=\Delta E\\ &\Updownarrow\\ F_{合力}&=\frac{\Delta E}{\Delta x}\\ &=\frac{\Delta E_{\omega}-\Delta U}{\Delta x}\\ &=\frac{-\Delta U}{\Delta x} \end{split} \end{equation} F合力??ΔxF合力??=ΔE?=ΔxΔE?=ΔxΔEω??ΔU?=Δx?ΔU????
其中, x x x為位移。由于花粉微粒的總能力 E ω E_{\omega} Eω?保持不變,因此 Δ E ω Δ x = 0 \frac{\Delta E_{\omega}}{\Delta x}=0 ΔxΔEω??=0。
另一方面,花粉微粒在水中的分布,服從波爾茲曼分布。
P ( x ) = e ? U ( x ) z \begin{equation} \begin{split} P(x)=\frac{e^{-U(x)}}{z} \end{split} \end{equation} P(x)=ze?U(x)????
其中 U ( x ) U(x) U(x)表示在位置 x x x處的花粉微粒所具有的勢能。 z z z 是一個歸一化因子。也就是說,具有勢能越大的花粉,其對應的概率密度越小。波爾茲曼分布是描述粒子的熱運動的。玻爾茲曼分布體現了系統的穩定性傾向。系統中的粒子總是趨向于占據能量較低的狀態,因為低能量狀態更穩定。但由于熱運動的存在,粒子也有一定的概率處于較高能量的狀態,不過這種概率會隨著能量的升高而迅速減小。探秘玻爾茲曼分布:解鎖微觀粒子能量分布的神奇密碼
對公式(3)的兩邊分別取對數且求導
? x l o g ( P ( x ) ) = ? x l o g e ? U ( x ) z = ? x ? U ( x ) = F 合力 = ? γ ? v t + η = ? γ ? d x d t + η ? d x = ? d t γ ? x l o g ( P ( x ) ) + η γ ? d t ? x t + Δ t = x t ? Δ t γ ? x l o g ( P ( x ) ) + Δ t γ ? η = x t ? Δ t γ ? x l o g ( P ( x ) ) + Δ t γ ? σ ? z \begin{equation} \begin{split} \nabla_x log\big(P(x)\big)&=\nabla_x log \frac{e^{-U(x)}}{z} \\ &=\nabla_x-U(x) \\ &=F_{合力} \\ &=-\gamma\cdot v_t+\eta\\ &=-\gamma\cdot \frac{dx}{dt}+\eta \\ &\Updownarrow \\ dx&=-\frac{dt}{\gamma}\nabla_x log\big(P(x)\big) + \frac{\eta}{\gamma} \cdot dt \\ &\Updownarrow \\ x_{t+\Delta t}&=x_{t}-\frac{\Delta t}{\gamma}\nabla_x log\big(P(x)\big) + \frac{\Delta t}{\gamma} \cdot \eta\\ &=x_{t}-\frac{\Delta t}{\gamma}\nabla_x log\big(P(x)\big) + \frac{\Delta t}{\gamma} \cdot \sigma \cdot z\\ \end{split} \end{equation} ?x?log(P(x))dxxt+Δt??=?x?logze?U(x)?=?x??U(x)=F合力?=?γ?vt?+η=?γ?dtdx?+η?=?γdt??x?log(P(x))+γη??dt?=xt??γΔt??x?log(P(x))+γΔt??η=xt??γΔt??x?log(P(x))+γΔt??σ?z???
其中, z ~ N ( 0 , 1 ) z\sim N(0,1) z~N(0,1)。如果分別令 Δ t γ = ? 2 \frac{\Delta t}{\gamma}=\frac{\epsilon}{2} γΔt?=2??, Δ t γ ? σ = ? \frac{\Delta t}{\gamma} \cdot \sigma=\sqrt{\epsilon} γΔt??σ=??。公式(4)則變為
x t + Δ t = x t ? ? 2 ? x l o g ( P ( x ) ) + ? ? z \begin{equation} \begin{split} x_{t+\Delta t}=x_{t}-\frac{\epsilon}{2}\nabla_x log\big(P(x)\big) + \sqrt{\epsilon} \cdot z\\ \end{split} \end{equation} xt+Δt?=xt??2???x?log(P(x))+???z???
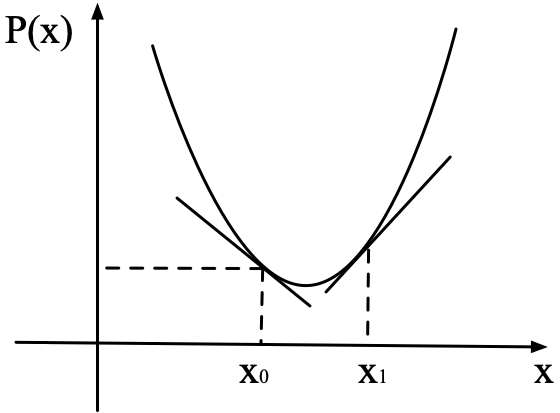
對于下圖中的概率分布來說,對于在 x 0 x_0 x0?處的花粉微粒來說,其對應的斜率是負數,對應于公式(4)中的 ? x l o g ( P ( x ) ) \nabla_x log\big(P(x)\big) ?x?log(P(x))是負數。因此,相對于 x t x_{t} xt?, x t + Δ t x_{t+\Delta t} xt+Δt?大概率會增大,因為是存在一個隨機高斯分布 η \eta η;對于在 x 1 x_1 x1?處的花粉微粒來說,其對應的斜率是正數,對應于公式(4)中的 ? x l o g ( P ( x ) ) \nabla_x log\big(P(x)\big) ?x?log(P(x))是正數。因此,相對于 x t x_{t} xt?, x t + Δ t x_{t+\Delta t} xt+Δt?大概率會減小。綜上所述,花粉微粒大概率會朝向密度低的位置移動。這是符合墨水滴入水中的運動常識的。
論文《Generative Modeling by Estimating Gradients of the Data Distribution》中的公式如公式(6)所示。可以看出,論文中的公式(6)是花粉擴散過程的逆過程
x t + Δ t = x t + ? 2 ? x l o g ( P ( x ) ) + ? ? z \begin{equation} \begin{split} x_{t+\Delta t}=x_{t}+\frac{\epsilon}{2}\nabla_x log\big(P(x)\big) + \sqrt{\epsilon} \cdot z\\ \end{split} \end{equation} xt+Δt?=xt?+2???x?log(P(x))+???z???
2、正篇
圖像生成別只知道擴散模型(Diffusion Models),還有基于梯度去噪的分數模型:
)




)







)


)

)
