前言
為什么海量數據需要分布式存儲技術?
文件過大時,單臺服務器無法承擔,要靠數量來解決。數量的提升帶來的是網絡傳輸、磁盤讀寫、CPU、內存等各方面的提升。?
眾多的服務器一起工作,如何保證高效且不出錯??
大數據體系中,分布式的調度有2類架構模式:去中心化模式、中心化模式
大數據框架大多是:中心化模式:一個中心節點(服務器)來統籌其它服務器的工作,統一指揮,統一調派。 也稱:一主多從模式,簡稱主從模式(Master And Slaves)
去中心化模式:沒有明確的中心。 眾多服務器之間協調工作。
HDFS的簡介
- Hadoop三大組件(HDFS、MapReduce、YARN)之一
- 全稱:Hadoop Distributed File System(Hadoop 分布式文件系統)
- 是Hadoop技術棧內的分布式數據存儲解決方案
- 可以在多臺服務器上構建集群,存儲海量數據
- 典型的主從模式架構
HDFS的基礎架構
| 主角色:NameNode?? | 主角色的輔助: SecondaryNameNode |
| 從角色:DataNode |
| NameNode | SecondaryNameNode | DataNode |
|
|
|
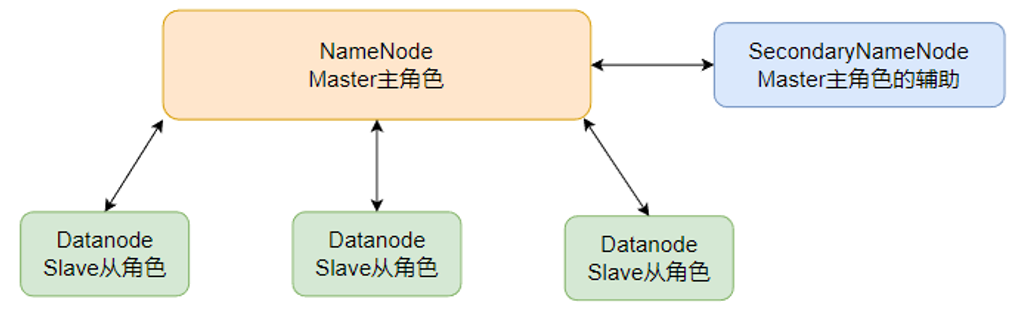
一個典型的HDFS集群,就是由1個DataNode加若干(至少一個)DataNode組成
在VMware 虛擬機中部署HDFS 集群
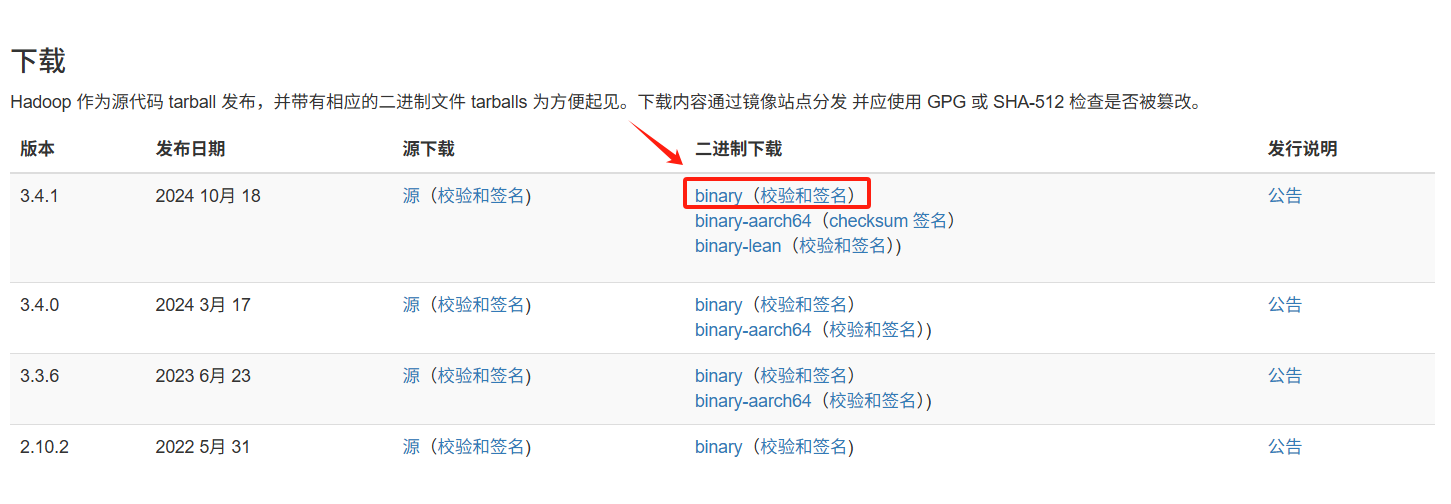
安裝包下載
下載地址:Apache Hadoop
集群規劃
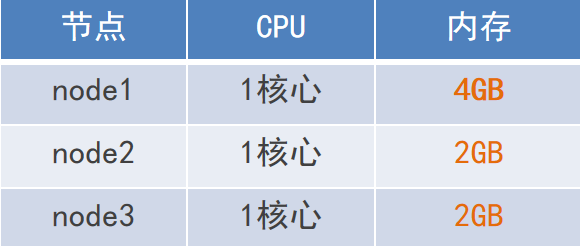
第一步:VMware 準備3臺虛擬機。硬件配置如下:
服務規劃

前言
什么是分布式計算?
分布式計算:多臺服務器協同工作,共同完成一個計算任務
分布式計算常見的 2 種工作模式
分散->匯總 ?(MapReduce是這種模式)
中心調度->步驟執行 (大數據體系的Spark、Flink是這種模式)





)





)







